问题
目前为止,k8s 提供2种 readiness/liveness probe方法,tcp和exec,1.23中新增了grpc probe,处于历史原因(更多的是偷懒…) 很多应用采用exec的方式做健康检查,通过exec进入容器的pidns执行一个脚本探测业务进程的健康。在我司内部这种方式已经正常工作很多年,直到最近开始将内核版本升级到4.19,发现有些业务容器中出现了大量的僵尸进程,但同样的pod在4.9的节点上表现正常。
排查
发现僵尸进程都是sh进程,父进程是容器的1号进程,容器1号进程是业务进程,没有收割能力,但仔细看了业务逻辑,不会fork进程,并且看到僵尸进程出现的频率在10s一个,所以怀疑是由于健康检查导致的,看了容器的readiness,是exec一个脚本,基本能确定是由于这个导致的,但是为什么4.9的节点上没有出现这个问题?到这里出现个疑问,docker exec的进程是如何创建的,应该由谁回收。那就先搞清楚这点
exec进程由谁创建?
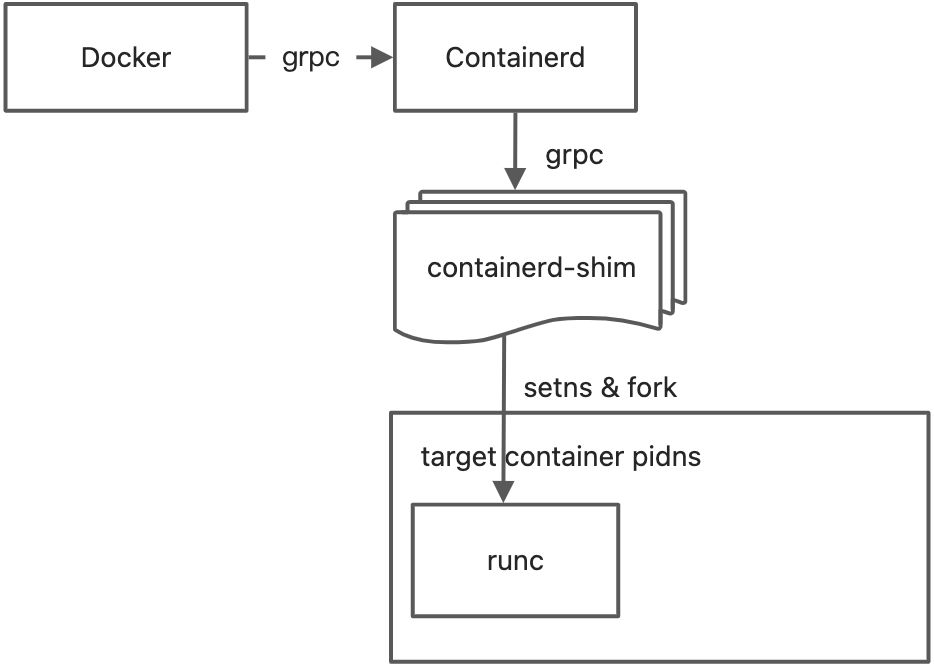
- docker 调用containerd
- containerd 找到目标容器对应的shim进程,通过grpc over uds调用shim提供的service
- shim进程调用runc执行exec
- runc exec过程比较复杂,简单说就是自己fork自己,然后将自进程setns到目标容器的pidns以及mountns中,通过pipe将指令从parent send 到子进程,子进程执行指令
所以exec的进程是由runc fork的,runc进程是由containerd-shim fork的,所以从进程树上看,top是containerd-shim
谁应该回收exec进程
shim进程启动时会通过 prctl 设置 subreaper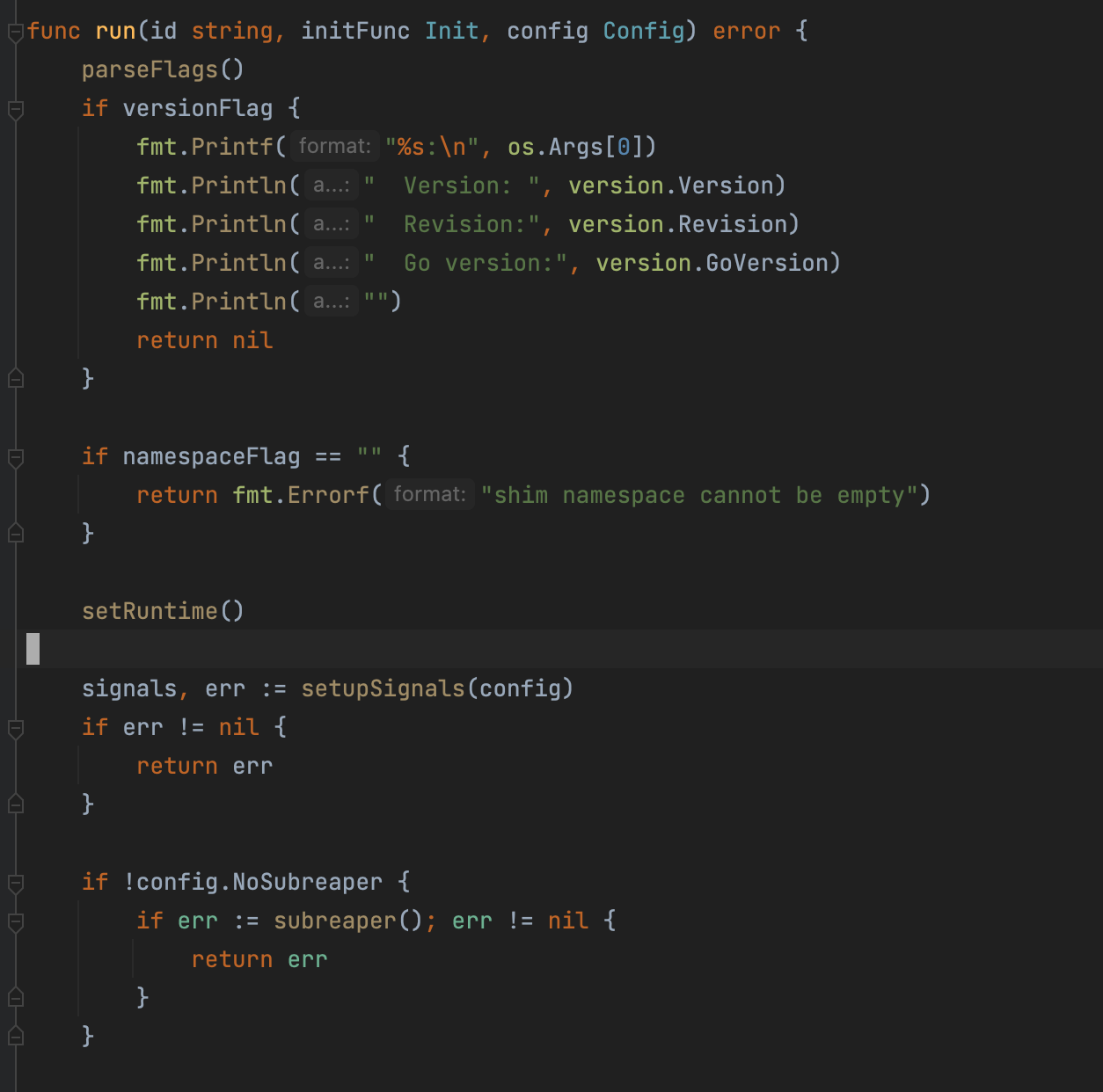
prctl 在收到 PR_SET_CHILD_SUBREAPER指令后,会将设置当前进程 struct task_struct -> signal -> is_child_subreaper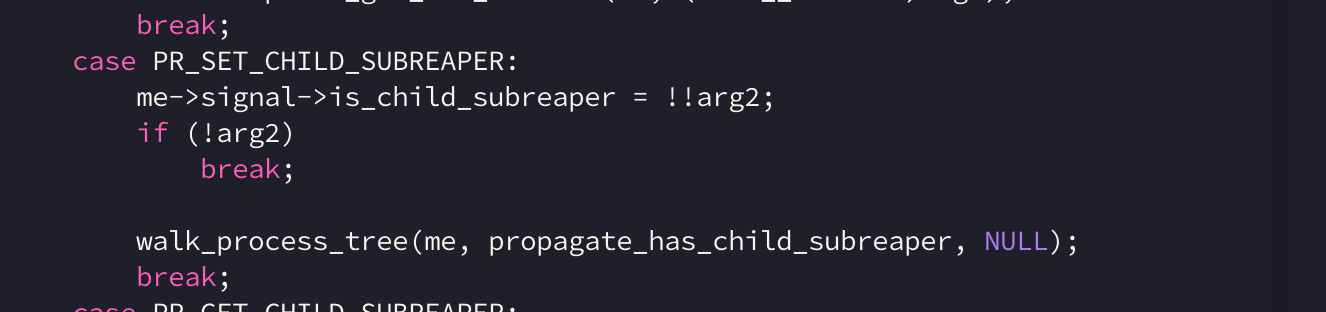
当一个进程歇逼的时候,会将所有的子进程reparent到另外一个进程,如果设置了subreaper, 那当前进程就会被当成新的parent,注意613行代码,这是关键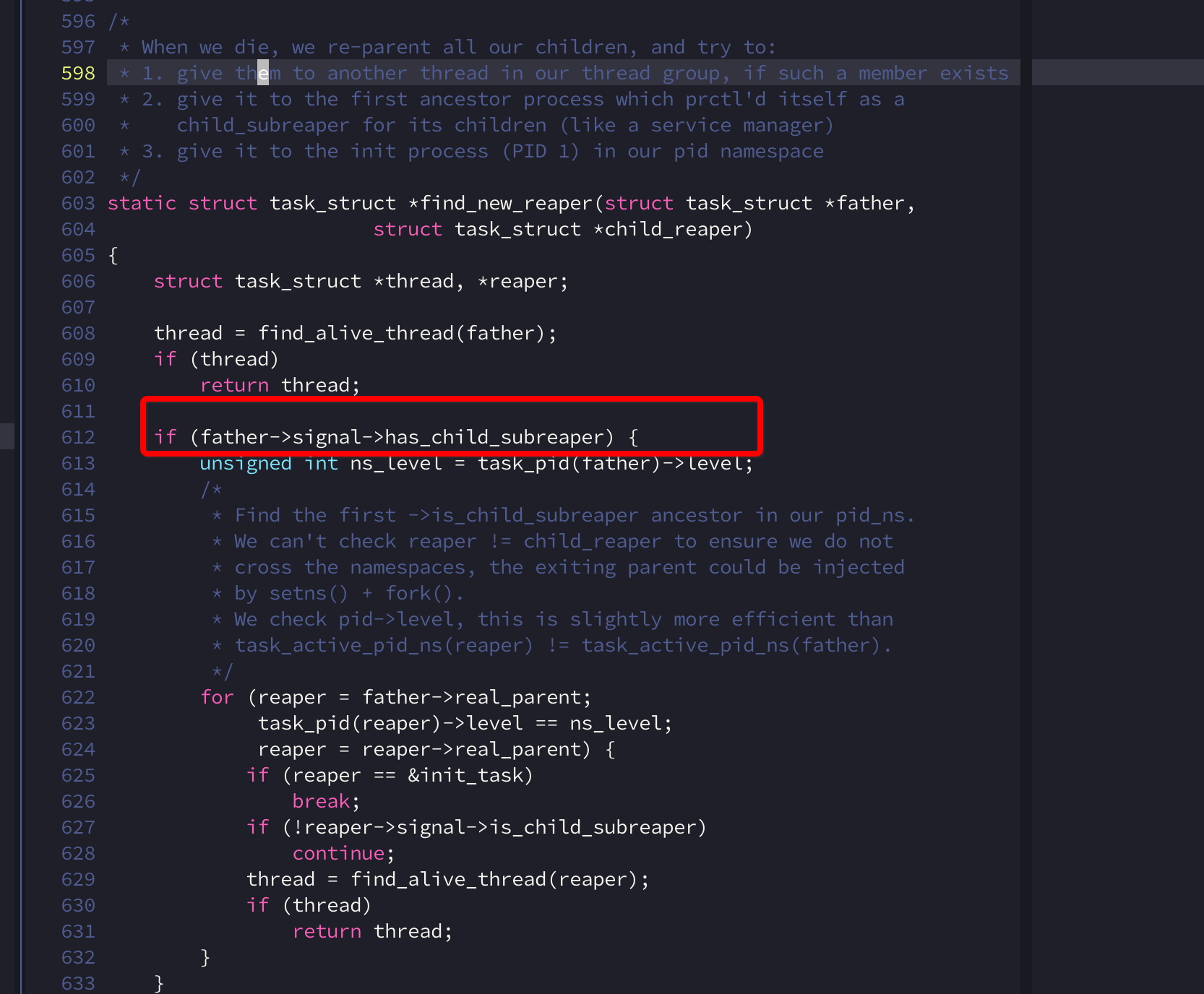
所以,containerd-shim应该作为subreaper来收割exec进程。
为什么4.19没能成功收割?
问题就出在find_new_reaper #613 #623, 4.9中没有这两行代码,从这段代码的注释中大约也能看出来,4.19中,限制了subreaper只能在当前pid_ns中,因为runc通过setns进到容器的pidns中,containerd-shim和目标容器不在同一个pidns中,所以无法作为这个进程的 new_reaper. 而当前容器的pid1进程称为了exec进程的new_reaper,但这个进程并没有reaper能力。
结论
- 尽量使用pod,sharepidns的能力,用pause容器做1号进程
- 如果无法使用sharepidns,无论容器是否是单进程,1号进程一定需要有收割能力,建议采用tini作为1号进程
- 尽量不要使用exec做健康检查,exec链路太长也容易出问题

若有收获,就点个赞吧
0 人点赞
