上周被问到一个问题,有两个cgroup,父子关系,如果子cgroup被throttle了,会影响到父cgroup吗?
先说结论,当子cgroup throttle的时候不会影响父cgroup,但如果父cgroup发生throttle,会影响子cgroup
进程是什么
struct task_struct {struct thread_info thread_info;}
/*
* how to get the current stack pointer in C
*/
register unsigned long current_stack_pointer asm ("sp");
/*
* how to get the thread information struct from C
*/
static inline struct thread_info *current_thread_info(void) __attribute_const__;
static inline struct thread_info *current_thread_info(void)
{
return (struct thread_info *)
(current_stack_pointer & ~(THREAD_SIZE - 1));
}
current macro 利用 thread_info 来获取当前执行的task,其实现和arch有关,例如在arm中,寄存器 sp 中存的是current_stack_pointer, 通过sp计算出栈顶,栈顶的位置就是存的当前task_struct的thread_info, 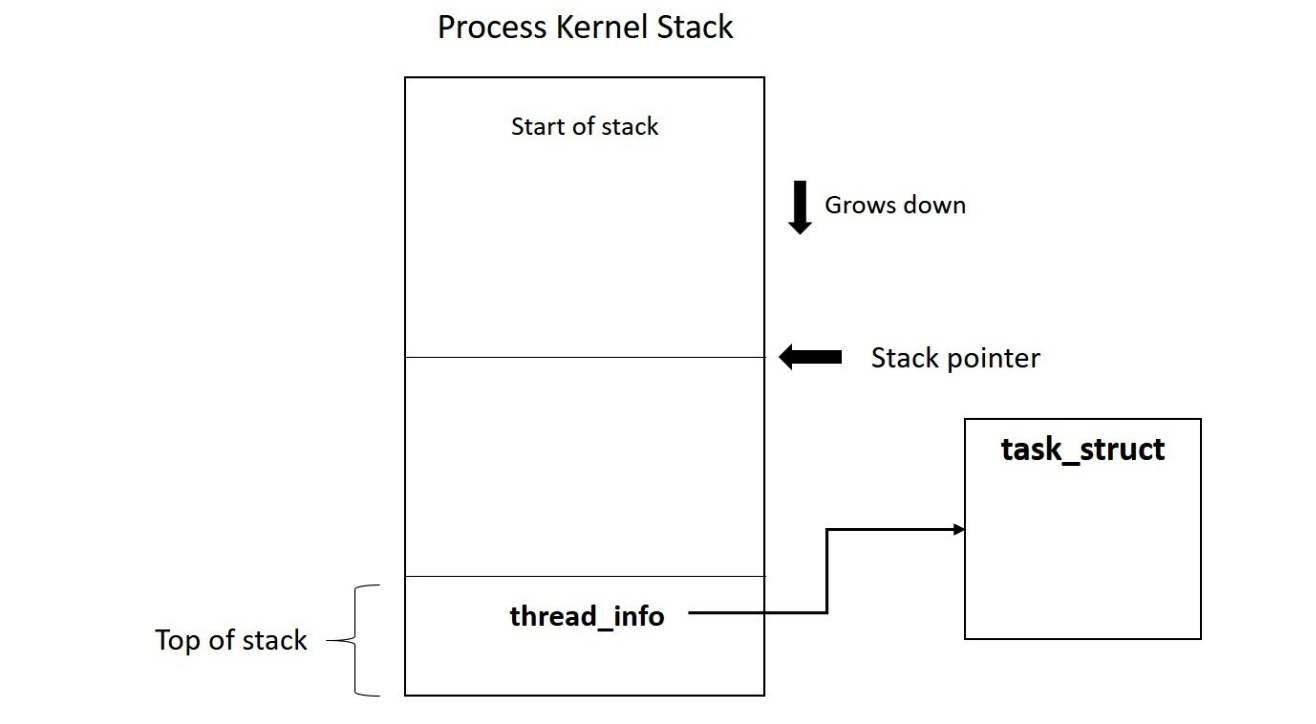
struct task_struct;
DECLARE_PER_CPU(struct task_struct *, current_task);
static __always_inline struct task_struct *get_current(void)
{
return this_cpu_read_stable(current_task);
}
#define current get_current()
#include <asm/current.h>
#define current_thread_info() ((struct thread_info *)current)
#endif
struct thread_info {
unsigned long flags; /* low level flags */
u32 status; /* thread synchronous flags */
};
x86中通过DECLARE_PRE_CPU 宏通定义PER_CPU变量,再通过this_cpu_read_stable 从PER_CPU变量读取
struct task_struct {
...
const struct sched_class *sched_class;
struct sched_entity se;
#ifdef CONFIG_CGROUP_SCHED
struct task_group *sched_task_group;
#endif
}
sched_class 代表调度类型,有fair rt idle, 我们通常说的cfs调度就是 fair_sched_class, sched_entity是调度算法中很重要的一个结构体, sched_entity可以是一个task_struct, 也可以使task_group
最后task_group, 公平调度保证每个task_struct在一个调度周期内,都能得到相同的调度,但如果2个进程,A进程clone了3个线程,B进程clone了2个线程,那A进程就要比B进程调度的时间要长,这样对B进程显然不公平了,所以出现了cgroup,通过cgroup可以让两个进程在2个不同的task_group.
进程的诞生
进程通过fork创建,fork调用do_fork函数创建新的进程,fork函数主要调用的是copy_process函数
static __latent_entropy struct task_struct *copy_process(
unsigned long clone_flags,
unsigned long stack_start,
unsigned long stack_size,
int __user *child_tidptr,
struct pid *pid,
int trace,
unsigned long tls,
int node)
{
这个函数首先会做clone_flags的校验,比如不允许CLONE_NEWNS和CLONE_FS一起设置,因为CLONE_FS表示父子进程共享文件系统,但是CLONE_NEWNS则是一个新的netns
if (signal_pending(current))
goto fork_out;
如果当前进程存在pending signal, 则退出fork,也就是说如果在fork过程中,进程收到signal,则会退出fork
struct task_struct *dup_task_struct(current, node) {
...
clear_tsk_need_resched(tsk);
}
current代表当前parent进程,node代表 numa节点,如果node传入-1则代表不是numa,这个函数主要做的就是生成struct task_struct 结构体,并将父进程的内容复制到子进程中,再通过clear_tsk_need_resched将thread_info中的TIF_NEED_RESCHED flag清除掉,因为新进程还未诞生,不希望现在被调度。
接着回到clone_process, 然后判断用户的进程数是否超过例如rlimit,如果用户不是root,并且没有CAP_SYS_RESOURCE 以及 CAP_SYS_ADMIN 那就无法fork,也就是说,root用户可以超过rlimit的限制
接下来判断线程数量是否超过max_threads, 如果超过了也会直接退出
if (nr_threads >= max_threads)
goto bad_fork_cleanup_count;
然后设置task-flags |= PF_FORKNOEXEC; 表示这个进程还不能执行,然后初始化新晋task的子进程链表以及兄弟进程链表, 以及一系列task字段的初始化。
p->flags |= PF_FORKNOEXEC;
INIT_LIST_HEAD(&p->children);
INIT_LIST_HEAD(&p->sibling);
接下去跳到 sched_fork 函数
retval = sched_fork(clone_flags, p);
if (retval)
goto bad_fork_cleanup_policy;
int sched_fork(unsigned long clone_flags, struct task_struct *p)
{
unsigned long flags;
__sched_fork(clone_flags, p);
/*
* We mark the process as NEW here. This guarantees that
* nobody will actually run it, and a signal or other external
* event cannot wake it up and insert it on the runqueue either.
*/
p->state = TASK_NEW;
...
}
__sched_fork 初始化struct sched_entity结构体,这个结构体是进程调度相关,每个进程,线程都是一个调度实体,包括cgroup也是
然后将task状态设置为TASK_NEW, 在之前的版本,这里就直接设置成TASK_RUNNING了,尽管task还没实际上running。
设置task的sched_class, 大部分进程使用的是fair_sched_class,
p->sched_class = &fair_sched_class;
然后就是对p的调度实体初始化 load_avg
init_entity_runnable_average(&p->se);
/* Give new sched_entity start runnable values to heavy its load in infant time */
void init_entity_runnable_average(struct sched_entity *se)
{
struct sched_avg *sa = &se->avg;
memset(sa, 0, sizeof(*sa));
/*
* Tasks are intialized with full load to be seen as heavy tasks until
* they get a chance to stabilize to their real load level.
* Group entities are intialized with zero load to reflect the fact that
* nothing has been attached to the task group yet.
*/
if (entity_is_task(se))
sa->runnable_load_avg = sa->load_avg = scale_load_down(se->load.weight);
se->runnable_weight = se->load.weight;
/* when this task enqueue'ed, it will contribute to its cfs_rq's load_avg */
}
smp_processor_id 返回的是当前的cpuid,将当前正在执行的cpuid分配给新fork的task_struct,并且执行sched_class的task_fork函数, 即cfs_sched的task_fork函数
__set_task_cpu(p, smp_processor_id());
if (p->sched_class->task_fork)
p->sched_class->task_fork(p);
static void task_fork_fair(struct task_struct *p)
{
struct cfs_rq *cfs_rq;
struct sched_entity *se = &p->se, *curr;
struct rq *rq = this_rq();
struct rq_flags rf;
rq_lock(rq, &rf);
update_rq_clock(rq);
cfs_rq = task_cfs_rq(current); // 找到父进程的cfs_rq
curr = cfs_rq->curr;
if (curr) {
update_curr(cfs_rq);
se->vruntime = curr->vruntime; // 新创建的vruntime初始化成父进程的vruntime
}
place_entity(cfs_rq, se, 1); // place_entity 调整新创建进程的vruntime
// 如果设置了子进程先运行,且父进程的vruntime小于子进程,则交换vruntime,确保子进程优先运行 (pick_next会选择vruntime最小的进程)
if (sysctl_sched_child_runs_first && curr && entity_before(curr, se)) {
/*
* Upon rescheduling, sched_class::put_prev_task() will place
* 'current' within the tree based on its new key value.
*/
swap(curr->vruntime, se->vruntime);
resched_curr(rq);
}
se->vruntime -= cfs_rq->min_vruntime; // 减去cfs_rq的最小vruntime
rq_unlock(rq, &rf);
}
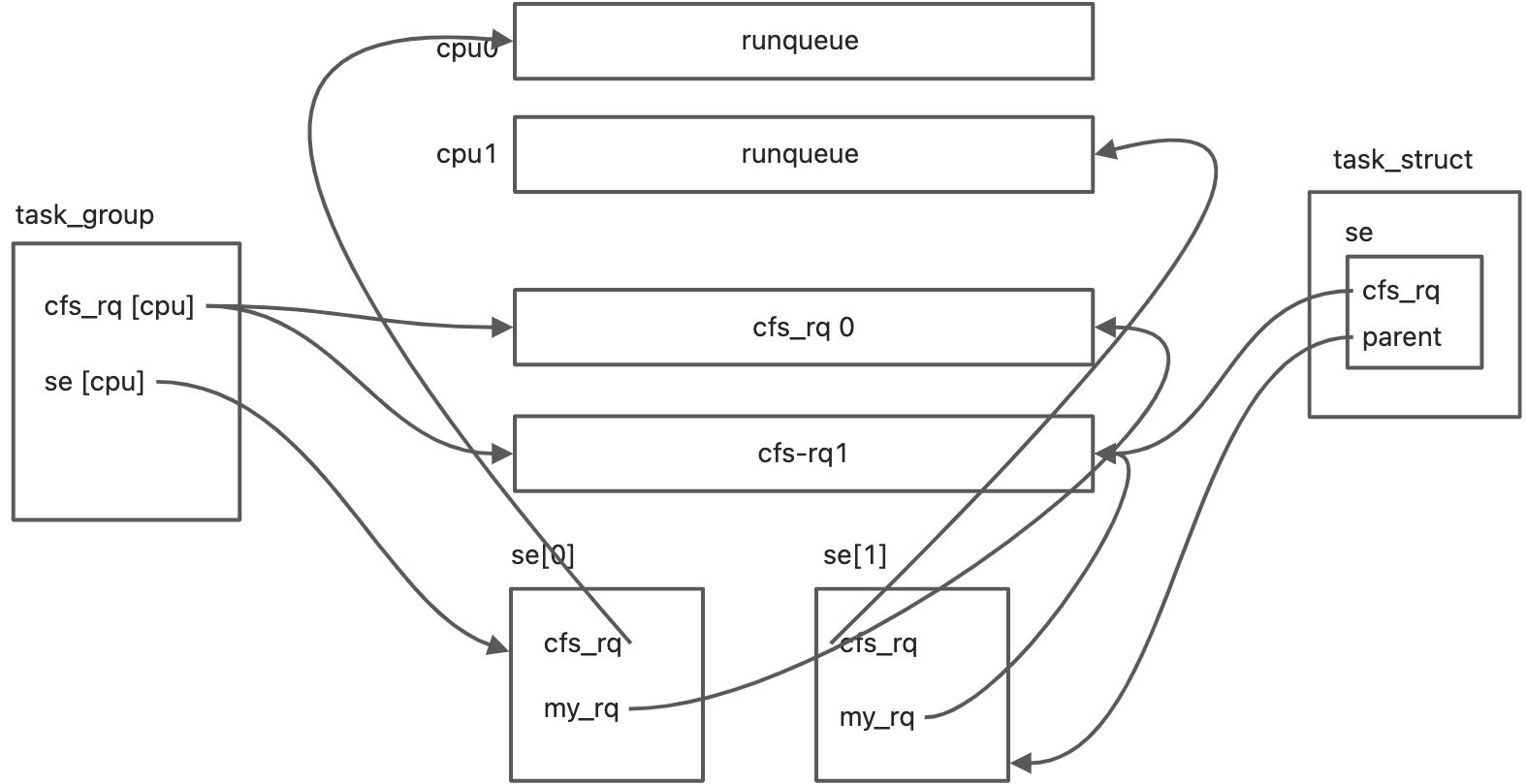
struct rq *rq = this_rq(); 返回的是当前cpu上的rq结构体实例,每个cpu都有一个runqueue队列,struct rq
/*
* This is the main, per-CPU runqueue data structure.
*
* Locking rule: those places that want to lock multiple runqueues
* (such as the load balancing or the thread migration code), lock
* acquire operations must be ordered by ascending &runqueue.
*/
struct rq {
struct cfs_rq cfs;
struct rt_rq rt;
struct dl_rq dl;
...
}
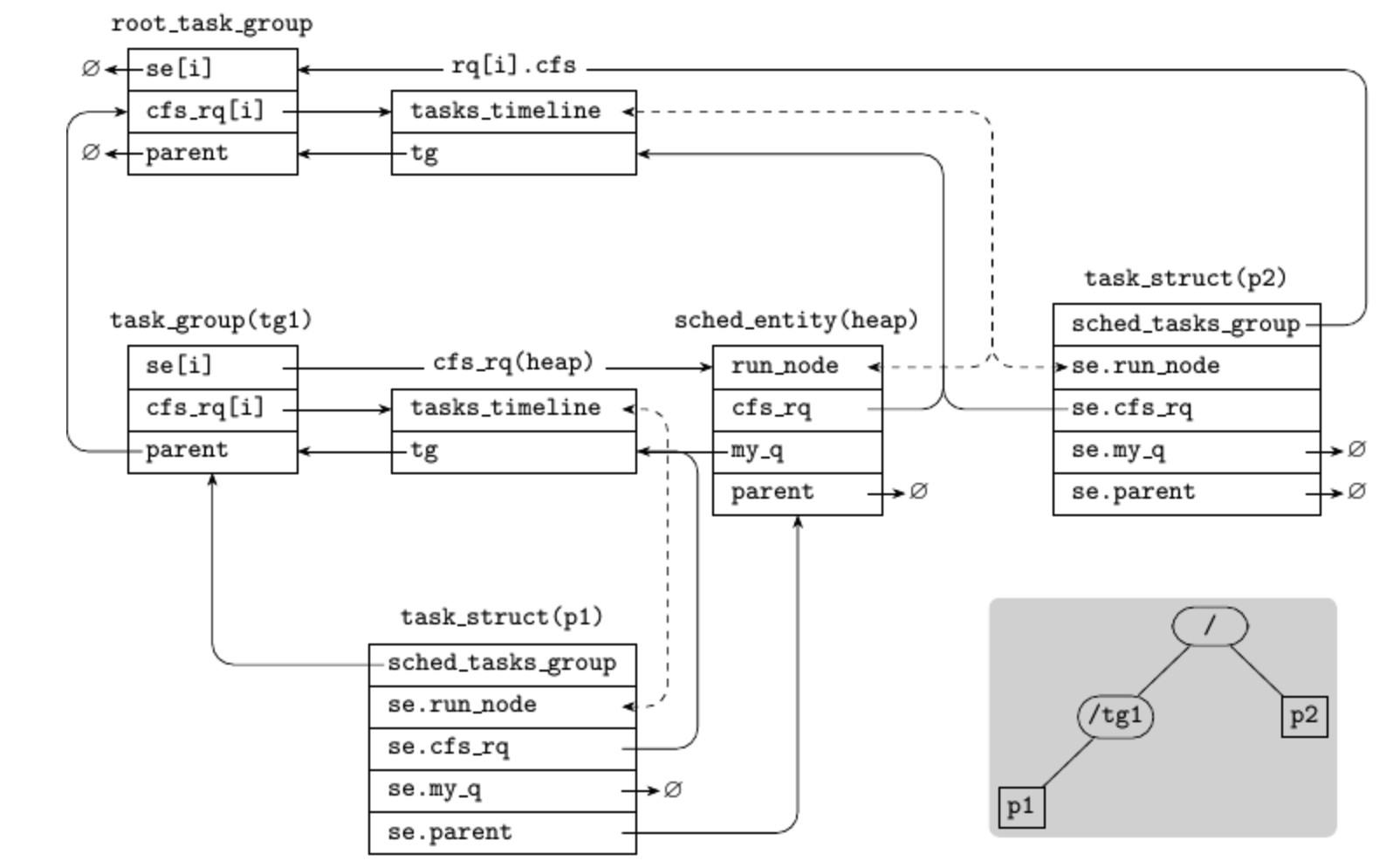
rq可以理解为一个抽象类,具体的runqueue由 cfs_rq rt_rq dl_rq 实现,rq cfs_rq sched_entity task_struct task_group 这几个实体之间的关系
static void
place_entity(struct cfs_rq *cfs_rq, struct sched_entity *se, int initial)
{
u64 vruntime = cfs_rq->min_vruntime;
/*
* The 'current' period is already promised to the current tasks,
* however the extra weight of the new task will slow them down a
* little, place the new task so that it fits in the slot that
* stays open at the end.
*/
if (initial && sched_feat(START_DEBIT))
vruntime += sched_vslice(cfs_rq, se);
/* sleeps up to a single latency don't count. */
if (!initial) {
unsigned long thresh = sysctl_sched_latency;
/*
* Halve their sleep time's effect, to allow
* for a gentler effect of sleepers:
*/
if (sched_feat(GENTLE_FAIR_SLEEPERS))
thresh >>= 1;
vruntime -= thresh;
}
/* ensure we never gain time by being placed backwards. */
se->vruntime = max_vruntime(se->vruntime, vruntime);
}
place_entity做的事情就是调整se的vruntime,来决定se的位置
参数inital表示改task是新创建的,还是被唤醒的。
cfs_rq->min_vruntime 存放的是此运行队列中最小虚拟运行时间, sched_feat(START_DEBIT)可以根据 /sys/kernel/debug/sched_features 判断,如果是新进程,并且配置START_DEBIT特性,那么就会为这个进程的vruntime增加一定的时间,通过sched_vslice 计算这个时间时间片,如果不是initial, 则vruntime要减去 sysctl_sched_latency, 如果打开了 GENTEL_FAIR_SLEEPERS, 调度特性,则减去sysctl_sched_latency的一半,最后通过max(父进程的vruntime, cfs->min_vruntime + sched_vslice)
为什么要给新进程一个初始的vruntime? 如果不设置,那vruntime就是0,那么只要是新进程,就会长时间霸占cpu,所以给他一个初始的vruntime,避免将老家伙们饿死。
至于父子进程谁先运行,内核也是根据vruntime来控制的,但这只是一个偏好,并不保证,所以即使配置了sched_child_runs_first,在写代码的时候也不能认为一定是子进程先运行。
回到do_fork函数,在copy_process结束后,就会调用wake_up_new_task来唤醒新创建的task,在SMP架构中,
void wake_up_new_task(struct task_struct *p)
{
struct rq_flags rf;
struct rq *rq;
raw_spin_lock_irqsave(&p->pi_lock, rf.flags);
p->state = TASK_RUNNING; //将task的state设置为 RUNNING,之前是NEW
#ifdef CONFIG_SMP
/*
* Fork balancing, do it here and not earlier because:
* - cpus_allowed can change in the fork path
* - any previously selected CPU might disappear through hotplug
*
* Use __set_task_cpu() to avoid calling sched_class::migrate_task_rq,
* as we're not fully set-up yet.
*/
p->recent_used_cpu = task_cpu(p); // recent_used_cpu是parent进程的cpu,当前thread_info里存的是parent的cpuid
rseq_migrate(p);
__set_task_cpu(p, select_task_rq(p, task_cpu(p), SD_BALANCE_FORK, 0)); // 选择新的cpu调度上去
#endif
rq = __task_rq_lock(p, &rf);
update_rq_clock(rq);
post_init_entity_util_avg(&p->se);
activate_task(rq, p, ENQUEUE_NOCLOCK);
p->on_rq = TASK_ON_RQ_QUEUED;
trace_sched_wakeup_new(p);
check_preempt_curr(rq, p, WF_FORK);
#ifdef CONFIG_SMP
if (p->sched_class->task_woken) {
/*
* Nothing relies on rq->lock after this, so its fine to
* drop it.
*/
rq_unpin_lock(rq, &rf);
p->sched_class->task_woken(rq, p);
rq_repin_lock(rq, &rf);
}
#endif
task_rq_unlock(rq, p, &rf);
}
static inline
int select_task_rq(struct task_struct *p, int cpu, int sd_flags, int wake_flags)
{
lockdep_assert_held(&p->pi_lock);
if (p->nr_cpus_allowed > 1)
cpu = p->sched_class->select_task_rq(p, cpu, sd_flags, wake_flags);
else
cpu = cpumask_any(&p->cpus_allowed);
/*
* In order not to call set_task_cpu() on a blocking task we need
* to rely on ttwu() to place the task on a valid ->cpus_allowed
* CPU.
*
* Since this is common to all placement strategies, this lives here.
*
* [ this allows ->select_task() to simply return task_cpu(p) and
* not worry about this generic constraint ]
*/
if (unlikely(!is_cpu_allowed(p, cpu)))
cpu = select_fallback_rq(task_cpu(p), p);
return cpu;
}
如果nr_cpus_allowed > 1, 那么就是调用的实际调度类的 select_task_rq函数,例如 select_task_rq_fair, 然后选出一个cpu,将task调度上去,所以子进程的父进程不一定在同一个cpu/runq 上执行,所以在task_fork_fair最后要减去当前runq的vruntime,就是因为wakeup的时候不一定和parent在一个runq上,在确定了wakeup的cfs_rq后再加上min_vruntime.
回到 wake_up_new_task
rq = __task_rq_lock(p, &rf); // 根据当前task的 cpuid获取到global rq (PER_CPU变量)
update_rq_clock(rq);
post_init_entity_util_avg(&p->se); //更行cfs_rq的utilavg以及parent(task_group)的utilavg
activate_task(rq, p, ENQUEUE_NOCLOCK);
p->on_rq = TASK_ON_RQ_QUEUED;
trace_sched_wakeup_new(p);
check_preempt_curr(rq, p, WF_FORK);
然后就到了activate_task,这时候才算是真正进入调度

除了在创建新进程 wake_up_new_task时会调用activate_task, 当睡眠进程醒来时也会调用activate_task
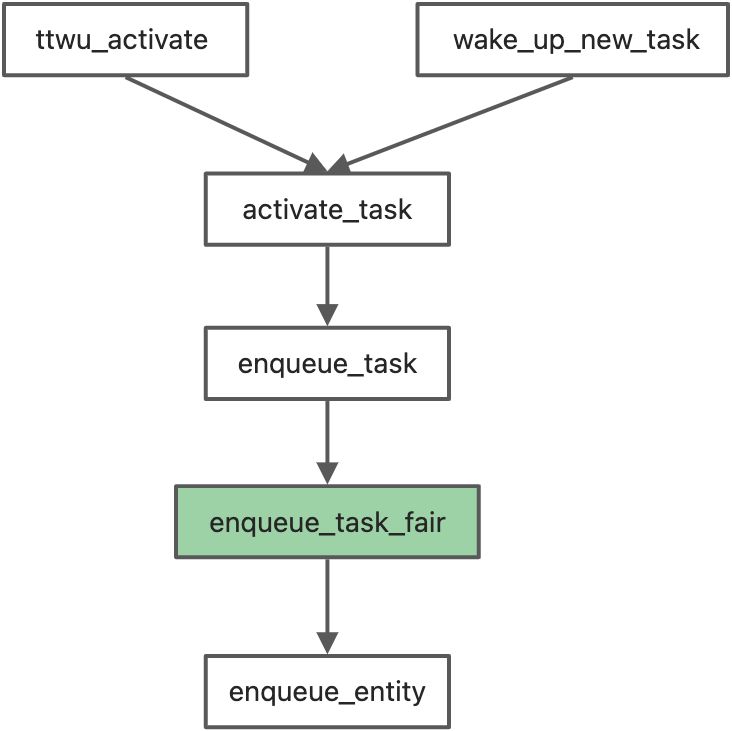
enqueue_task_fair 函数遍历 当前task_struct 的 se,如果se已经在队列上 se->on_rq = 1, 那么退出,否则就调用enqueue_entity 将se放到 cfs_rq上
for_each_sched_entity(se) {
if (se->on_rq)
break;
cfs_rq = cfs_rq_of(se);
enqueue_entity(cfs_rq, se, flags);
/*
* end evaluation on encountering a throttled cfs_rq
*
* note: in the case of encountering a throttled cfs_rq we will
* post the final h_nr_running increment below.
*/
if (cfs_rq_throttled(cfs_rq))
break;
cfs_rq->h_nr_running++;
flags = ENQUEUE_WAKEUP;
}
enqueue_entity 调用 __enqueue_entity将 se 插入runqueue的rbtree上,并且将parent (如果在cgroup内,parent就是task_cgroup的se)
static void __enqueue_entity(struct cfs_rq *cfs_rq, struct sched_entity *se)
{
struct rb_node **link = &cfs_rq->tasks_timeline.rb_root.rb_node;
struct rb_node *parent = NULL;
struct sched_entity *entry;
bool leftmost = true;
/*
* Find the right place in the rbtree:
*/
while (*link) {
parent = *link;
entry = rb_entry(parent, struct sched_entity, run_node);
/*
* We dont care about collisions. Nodes with
* the same key stay together.
*/
if (entity_before(se, entry)) {
link = &parent->rb_left;
} else {
link = &parent->rb_right;
leftmost = false;
}
}
rb_link_node(&se->run_node, parent, link);
rb_insert_color_cached(&se->run_node,&cfs_rq->tasks_timeline, leftmost);
}
根据se的vruntime,插入到rbnode中,并且cache, leftmost节点,这是为了在后面pick_next的时候快速获取到下一个se, 最后如果当前cfs_rq 的task数量等于1,检查是否需要throttle
static void check_enqueue_throttle(struct cfs_rq *cfs_rq)
{
if (!cfs_bandwidth_used())
return;
/* an active group must be handled by the update_curr()->put() path */
if (!cfs_rq->runtime_enabled || cfs_rq->curr)
return;
/* ensure the group is not already throttled */
if (cfs_rq_throttled(cfs_rq))
return;
/* update runtime allocation */
account_cfs_rq_runtime(cfs_rq, 0);
if (cfs_rq->runtime_remaining <= 0)
throttle_cfs_rq(cfs_rq);
}
如果没有开启cfs_bandwidth_used, 也就是cgroup_cfs_quota, 直接退出,如果runtime_remaining 用完,则throttle_cfs_rq, 如果task在cgroup内这里的cfs_rq则是task_group的cfs_rq, 每个taskgroup在每个cpu上都有一个cfs_rq.
这个函数在这3中情况会被调用
- enqueue_task_fair() -> enqueue_entity() -> check_enqueue_throttle() -> throttle_cfs_rq()
- put_prev_task_fair() -> put_prev_entity() -> check_cfs_rq_runtime() -> throttle_cfs_rq()
- pick_next_task_fair() -> check_cfs_rq_runtime() -> throttle_cfs_rq()
static void throttle_cfs_rq(struct cfs_rq *cfs_rq)
{
struct rq *rq = rq_of(cfs_rq);
struct cfs_bandwidth *cfs_b = tg_cfs_bandwidth(cfs_rq->tg);
struct sched_entity *se;
long task_delta, dequeue = 1;
bool empty;
se = cfs_rq->tg->se[cpu_of(rq_of(cfs_rq))];
/* freeze hierarchy runnable averages while throttled */
rcu_read_lock();
walk_tg_tree_from(cfs_rq->tg, tg_throttle_down, tg_nop, (void *)rq);
rcu_read_unlock();
task_delta = cfs_rq->h_nr_running;
for_each_sched_entity(se) {
struct cfs_rq *qcfs_rq = cfs_rq_of(se);
/* throttled entity or throttle-on-deactivate */
if (!se->on_rq)
break;
if (dequeue)
dequeue_entity(qcfs_rq, se, DEQUEUE_SLEEP);
qcfs_rq->h_nr_running -= task_delta;
if (qcfs_rq->load.weight)
dequeue = 0;
}
if (!se)
sub_nr_running(rq, task_delta);
cfs_rq->throttled = 1;
cfs_rq->throttled_clock = rq_clock(rq);
raw_spin_lock(&cfs_b->lock);
empty = list_empty(&cfs_b->throttled_cfs_rq);
/*
* Add to the _head_ of the list, so that an already-started
* distribute_cfs_runtime will not see us. If disribute_cfs_runtime is
* not running add to the tail so that later runqueues don't get starved.
*/
if (cfs_b->distribute_running)
list_add_rcu(&cfs_rq->throttled_list, &cfs_b->throttled_cfs_rq);
else
list_add_tail_rcu(&cfs_rq->throttled_list, &cfs_b->throttled_cfs_rq);
/*
* If we're the first throttled task, make sure the bandwidth
* timer is running.
*/
if (empty)
start_cfs_bandwidth(cfs_b);
raw_spin_unlock(&cfs_b->lock);
}
- walk_tg_tree_from 从当前task_group遍历,找children(子task_group), 然后inc throttle_count,
- 然后for_each_sched_entity(se) 遍历se, 往parent找,这里的se是task_group的,所以它的parent是他上一层的cgroup
- dequeue_entity 调用 __dequeue_entity将 se从 cfs_rq的rbtree上删除
- 如果cfs_rq->load.weight 不为0, 说明 cfs_rq的runq上不止se一个,所以parent不可以再被dequeue
- 将throttle的cfs_rq加到 cfs_b 链表中,方便后续unthrottle的时候找到
- throttle_cfs_rq所做的事情就是将当前进程组dequeue出cpu的运行队列,并加入到throttled_list里。进程组的cfs_rq既然不在cpu的运行队列里,自然就不会被调度运行了,然后必须等到下一个周期才能重新进入到cpu队列里。
__schedule()
/*
* __schedule() is the main scheduler function.
*
* The main means of driving the scheduler and thus entering this function are:
*
* 1. Explicit blocking: mutex, semaphore, waitqueue, etc.
*
* 2. TIF_NEED_RESCHED flag is checked on interrupt and userspace return
* paths. For example, see arch/x86/entry_64.S.
*
* To drive preemption between tasks, the scheduler sets the flag in timer
* interrupt handler scheduler_tick().
*
* 3. Wakeups don't really cause entry into schedule(). They add a
* task to the run-queue and that's it.
*
* Now, if the new task added to the run-queue preempts the current
* task, then the wakeup sets TIF_NEED_RESCHED and schedule() gets
* called on the nearest possible occasion:
*
* - If the kernel is preemptible (CONFIG_PREEMPT=y):
*
* - in syscall or exception context, at the next outmost
* preempt_enable(). (this might be as soon as the wake_up()'s
* spin_unlock()!)
*
* - in IRQ context, return from interrupt-handler to
* preemptible context
*
* - If the kernel is not preemptible (CONFIG_PREEMPT is not set)
* then at the next:
*
* - cond_resched() call
* - explicit schedule() call
* - return from syscall or exception to user-space
* - return from interrupt-handler to user-space
*
* WARNING: must be called with preemption disabled!
*/
schedule —> pick_next_task
/*
* Optimization: we know that if all tasks are in the fair class we can
* call that function directly, but only if the @prev task wasn't of a
* higher scheduling class, because otherwise those loose the
* opportunity to pull in more work from other CPUs.
*/
if (likely((prev->sched_class == &idle_sched_class ||
prev->sched_class == &fair_sched_class) &&
rq->nr_running == rq->cfs.h_nr_running)) {
p = fair_sched_class.pick_next_task(rq, prev, rf);
if (unlikely(p == RETRY_TASK))
goto again;
/* Assumes fair_sched_class->next == idle_sched_class */
if (unlikely(!p))
p = idle_sched_class.pick_next_task(rq, prev, rf);
return p;
}
如果global rq的数量和cfs_rq的running数量一致,那么说明rq上只有cfs_rq的task,那么直接用,fair_sched_class.pick_next_task,否则将会从3个schedclass遍历
- 如果不支持组调度,也就是最小se单元就是task_struct,那就直接到simple label
- 将当前task放回队列
- 选择下一个entity pick_next_entity (pick_next_entity 再仔细阅读一下代码,下一个entity的逻辑?)
- p = task_of(se) 得到task_struct
- 返回p
如果支持组调度 ```c do {
struct sched_entity *curr = cfs_rq->curr; /* * Since we got here without doing put_prev_entity() we also * have to consider cfs_rq->curr. If it is still a runnable * entity, update_curr() will update its vruntime, otherwise * forget we've ever seen it. */ if (curr) { if (curr->on_rq) update_curr(cfs_rq); else curr = NULL; /* * This call to check_cfs_rq_runtime() will do the * throttle and dequeue its entity in the parent(s). * Therefore the nr_running test will indeed * be correct. */ if (unlikely(check_cfs_rq_runtime(cfs_rq))) { cfs_rq = &rq->cfs; if (!cfs_rq->nr_running) goto idle; goto simple; } } se = pick_next_entity(cfs_rq, curr); // 找到下一个可调度实体 cfs_rq = group_cfs_rq(se); // 如果 se 是一个task_group, 因为my_q 不为空,那就drill down进去到新的task_group中 // 直到找到一个是task_struct的se} while (cfs_rq);
``` 每个 task group 在每个 cpu 上都有一个 cfs_rq(group cfs_rq),调度器调度时要保证最后选择的时一个 task se

若有收获,就点个赞吧
0 人点赞
