1-MySQL基本配置
1.1-安装mysql
apt-get install mysql-server #一路回车不用管
此时mysql默认是在linux系统root账号下能登陆,不输入密码也能直接登陆,
mysql #直接回车
换成普通用户就无法登陆
这是因为mysql刚安装完成,默认是允许linux系统的root账户本地通过socket直接登陆不需要密码。
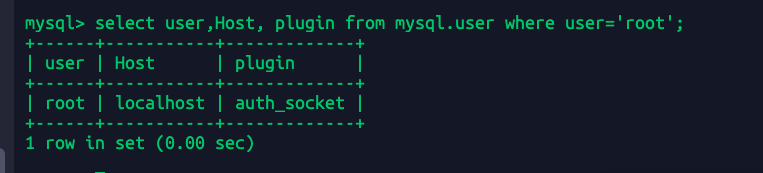
select user,Host, plugin from mysql.user where user='root';
1.2 MySQL初始化
ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY 'root123456...';// mysql8.0只允许通过alter方式修改密码
mysql8.0之后密码的变更方式和5.7不一样了
mysql_secure_installation
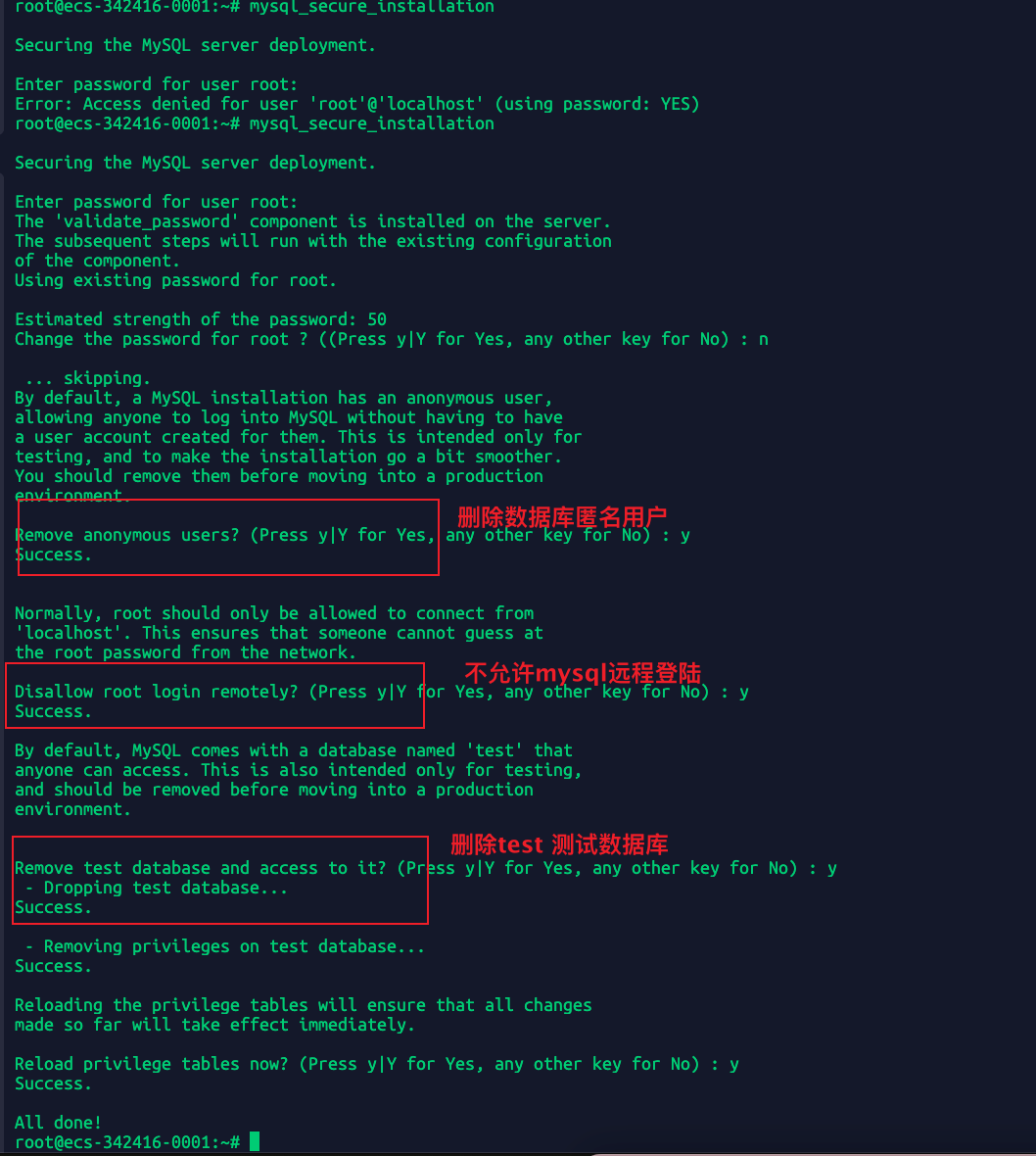
但是为了方便我这里还是允许root远程登录,并且允许mysql远程访问,并且开放了华为云的3306端口
update mysql.user set Host='%' where User='root';
vim /etc/mysql/mysql.conf.d/mysqld.cnf// 32行 bind-address = 0.0.0.0
service mysql restart
2-数据准备
2.1-创建实验数据库
create database taobao charset=utf8mb4; //utf8mb4编码只是表情包是真正的utf8
创建一张订单表
CREATE TABLE `order` (`id` BIGINT ( 20 ) UNSIGNED NOT NULL AUTO_INCREMENT,`user_id` INT ( 32 ) DEFAULT 0 COMMENT '下单用户id',`order_id` VARCHAR ( 64 ) DEFAULT NULL COMMENT '订单号',`status` TINYINT ( 1 ) DEFAULT 1 COMMENT '该笔交易的状态0进行中;1支付完成;2支付失败;3取消支付;',`pay_type` TINYINT ( 1 ) DEFAULT 1 COMMENT '1支付宝2微信3银行卡',`created_at` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',`updated_at` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',PRIMARY KEY ( `id` )) ENGINE = INNODB DEFAULT CHARSET = utf8mb4;
2.2-生成1000w数据到表中
import datetimeimport osimport randomimport pymysql.cursorsimport uuiddef handler():mysql_connect = pymysql.connect(host="",user="root",port=3306,password="",database="taobao",cursorclass=pymysql.cursors.DictCursor,)with mysql_connect.cursor() as mysql_cursor:# 每次插入10000条values = "('c02f8f06b6bc468892328ab97c212562',32120,1,2)"for i in range(10000):order_id = str(uuid.uuid4()).replace("-", "")user_id = random.randint(1, 100000)# 从数仓数据库查询数据values += f",('{order_id}',{user_id},1,2)"sql_string = f"INSERT INTO `order`(order_id,user_id,`status`,pay_type) VALUES {values};"# print(sql_string)mysql_cursor.execute(sql_string, args=())mysql_connect.commit()mysql_connect.close()if __name__ == "__main__":print(f"开始时间:{datetime.datetime.now()}")from multiprocessing import Poolworkers = os.cpu_count() * 2 + 1p = Pool(workers)# 1000个任务,每个任务同时插入1w条数据=1千万条数据for i in range(0, 1000):p.apply_async(handler, args=())p.close()p.join()# 开始时间:2022-07-01 17:45:14.296009# 结束时间:2022-07-01 17:50:08.484511print(f"结束时间:{datetime.datetime.now()}")
1百万只用了20几秒, 100个任务 每次一千条,插入100万用了20几秒 100个任务每次一万条,插入1000万用五分钟: 2022-07-01 17:45:14.296009~2022-07-01 17:50:08.484511 100个任务每次十万条,插入1000万用:五分半钟:2022-07-01 18:00:04.418370~2022-07-01 18:05:27.181354 值得注意的是我刚开始是写的单线程for循环估计得几小时,后面改成了多进程但是一次只提交一条sql发现还是很慢,后面改成了现在这个多进程且批量提交多条数据。
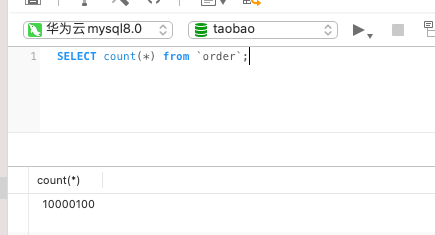
2.3-count(*)的替代方案
这种count()会进行聚簇索引扫描,如果频繁操作count()肯定会出现性能影响,这就相当于一个大表查询。如果不需要知道某个表的准确数据可以利用
show table status like "order"\G
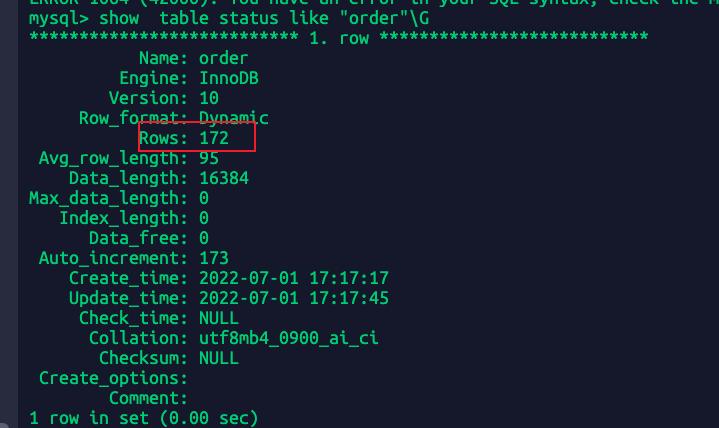
很明显这个值不是准确的是个大概数字,这里不准应该是与我频繁删除清空数据库有关。
重新创建一个表order_tmp然后重新插入1千万条数据再次执行上面命令看看: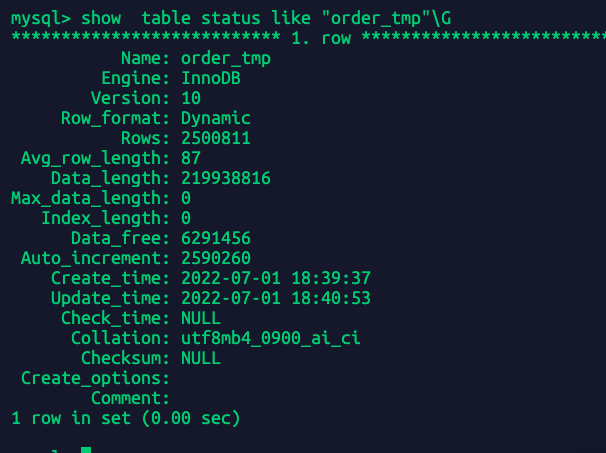
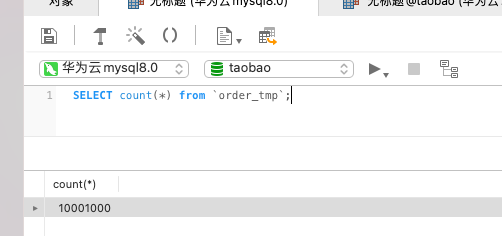
很明显 也不准
目前来讲如果是那种频繁需要计算count()的,直接查数据库肯定是不好的,而且万一以后分表分库之后怎么算?
所以一般来讲会用redis计数一下(下一小节会遇到count()导致慢sql的例子)。
2.4-count(1) 比 count(*) 快么
很早之前你问我这个问题我没法回答,现在我会从事实出发直接expalin两条语句:
explain select count(*) from `order`;explain select count(1) from `order`;explain select count(id) from `order`;



从执行计划来看三条命令是一样的,所以count(*),count(id)是一样的意义。

若有收获,就点个赞吧
0 人点赞
