
1-主键索引
默认情况下如果mysql会给主键id创建一个索引
show index from `order`;
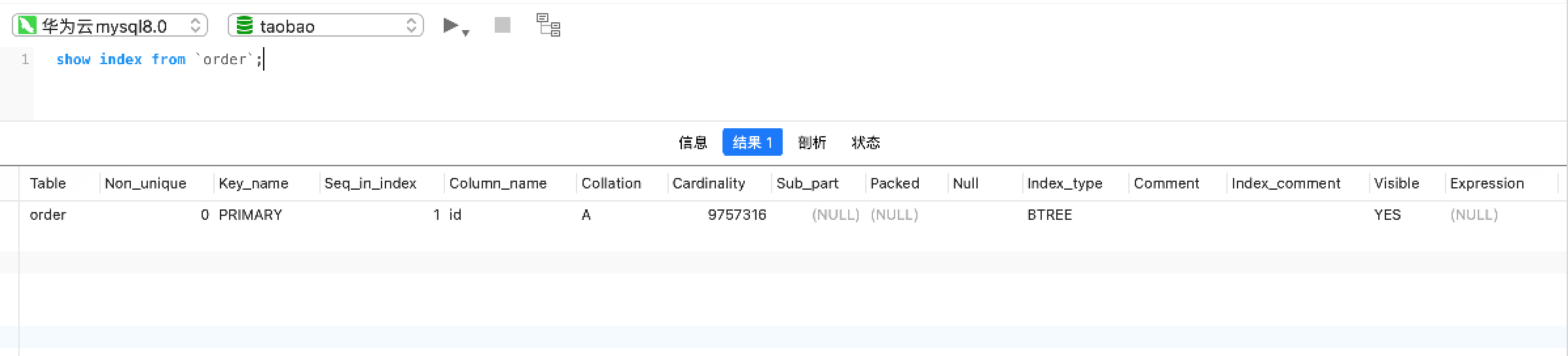
- Non_unique:如果是唯一索引,则值为 0,如果可以有重复值,则值为 1
- Key_name:索引名字
- Seq_in_index:索引中的列序号,比如联合索引 idx_a_b_c (a,b,c) ,那么三个字段分别对应 1,2,3
- Column_name:字段名
- Collation:字段在索引中的排序方式,A 表示升序,NULL 表示未排序
- Cardinality:索引中不重复记录数量的预估值,该值等会儿会详细讲解
- Sub_part:如果是前缀索引,则会显示索引字符的数量;如果是对整列进行索引,则该字段值为 NULL
- Null:如果列可能包含空值,则该字段为 YES;如果不包含空值,则该字段值为 ’ ’
- Index_type:索引类型,包括 BTREE、FULLTEXT、HASH、RTREE 等
没啥好说的,如果系统不添加,业务上肯定也要加的。普通索引和唯一索引没什么好讲的,就不讲了。
2-联合索引
2.1-使用联合索引
主键id索引或者单独的普通索引都是针对一个字段的,像我之前的需求需要根据user_id,,订单号,支付状态和支付类型来联合查询订单,就需要创建联合索引了
explain SELECT*FROM`order`WHEREuser_id = 1022AND order_id = 'c82388f1104a43118e3b5cf134c31195'AND STATUS = 1AND pay_type = 1;
我们先看看创建索引前的执行情况: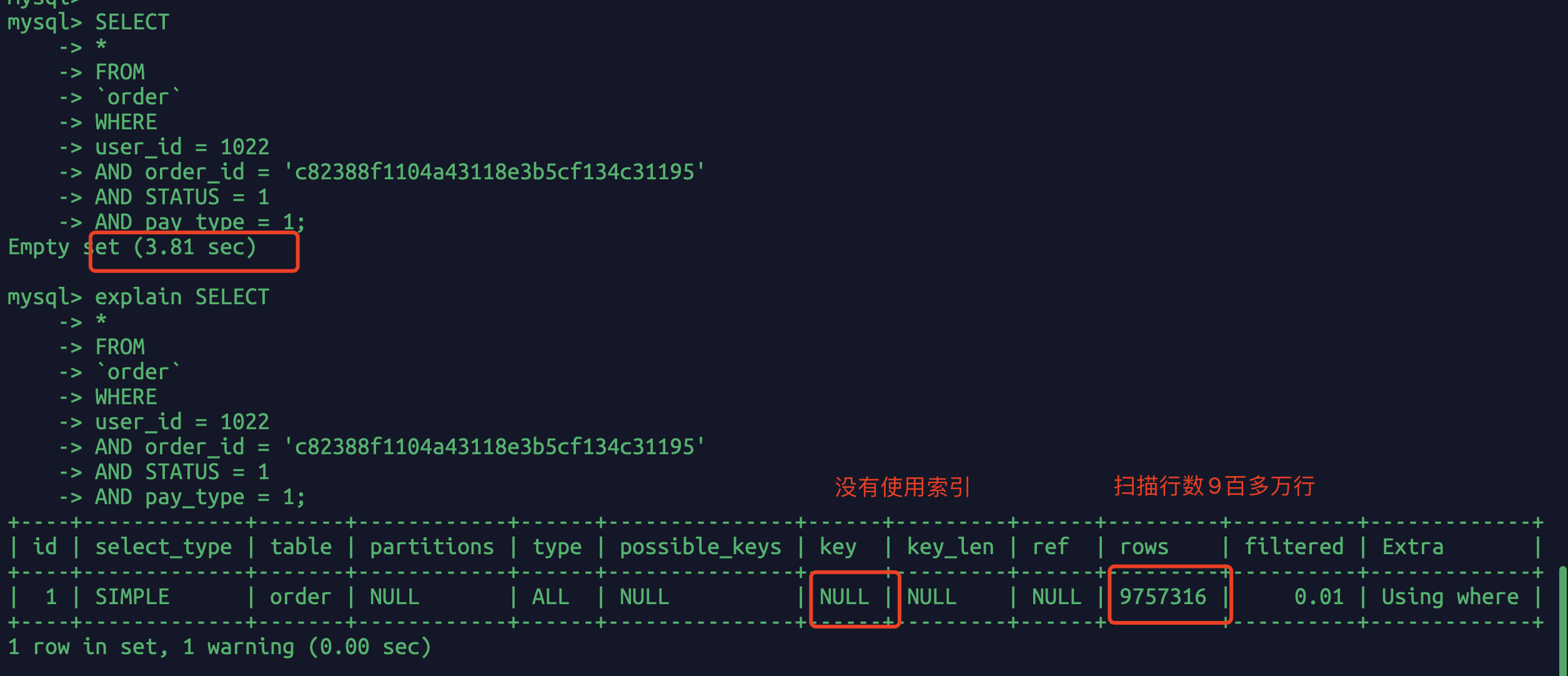
执行时长将近4s 扫面9百万行,几乎是全表扫描。
创建联合索引
alter table `order` add index order_together_index(`user_id`,`order_id`,`status`,`pay_type`);

注意因为我这个order表现在是有1千万数据的,添加索引耗时1分35秒。
当它在执行的时候,可以用show processlist命令查看当前后台正在执行的sql,查看执行情况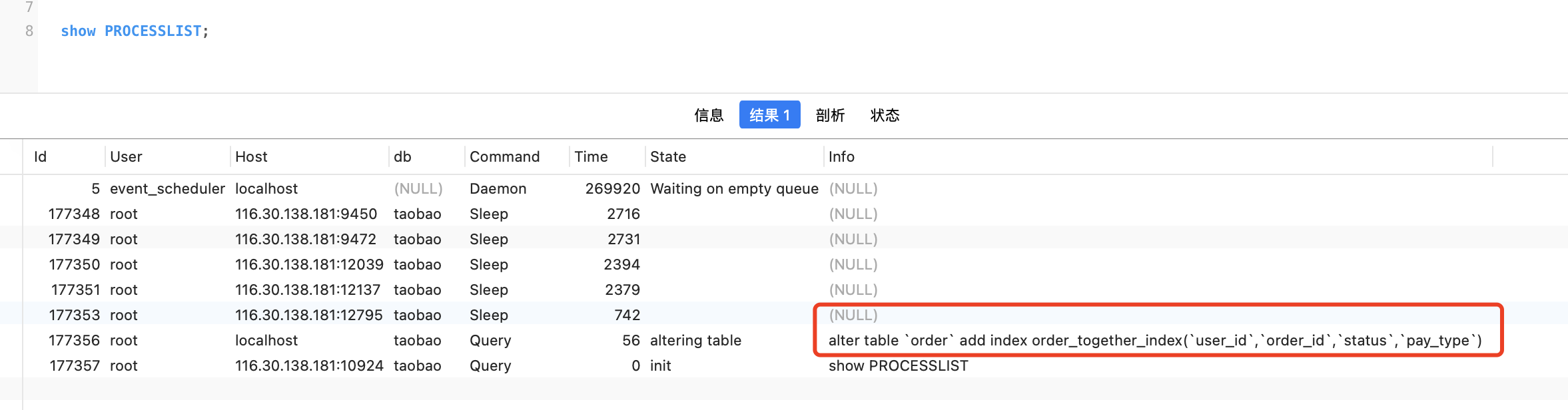
再次执行sql然后查看执行情况: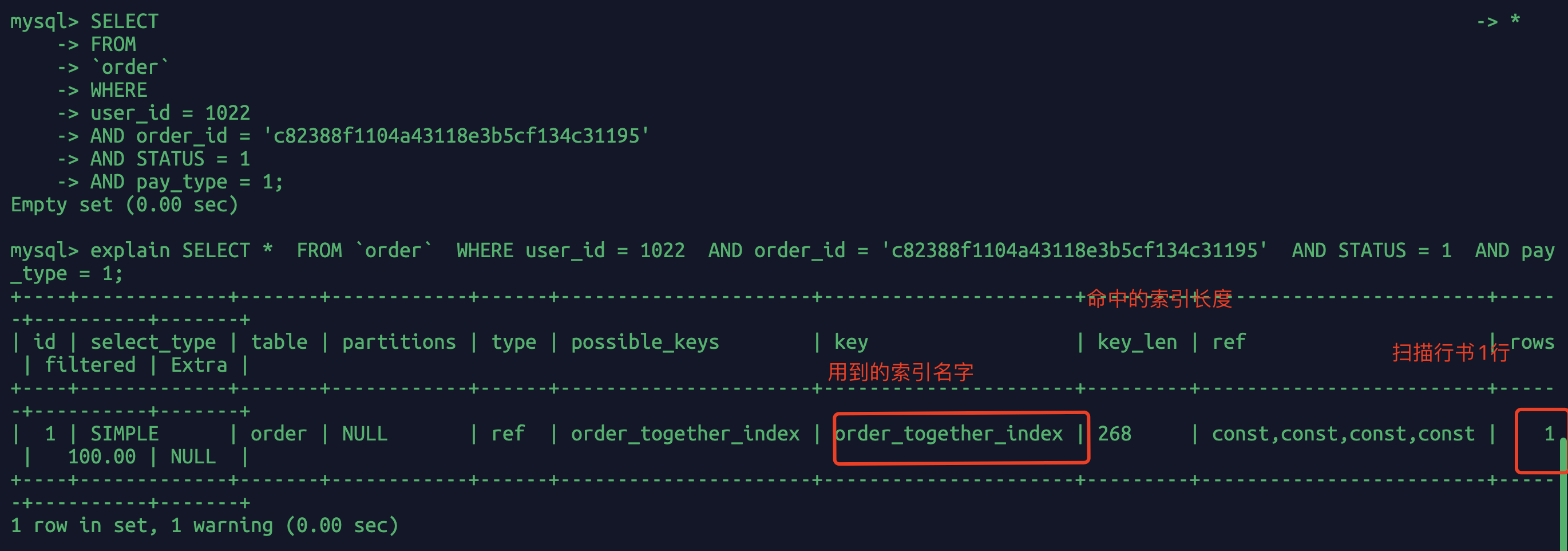
一下子从扫描9百多万行的sql优化成了只扫描1行。
2.2-索引失效
2.2.1-函数操作
为了控制变量,先删除之前的联合索引,再重新创建对user_id的索引,此时数据库只有一个user_id索引。
ALTER table `order` drop index order_together_index;ALTER table `order` add index user_id_index(`user_id`);
EXPLAIN SELECT*FROM`order`WHEREABS(user_id) = 1022;

rows这一列可以看出扫描了9百多万行数据
EXPLAIN SELECT*FROM`order`WHEREuser_id = 1002;
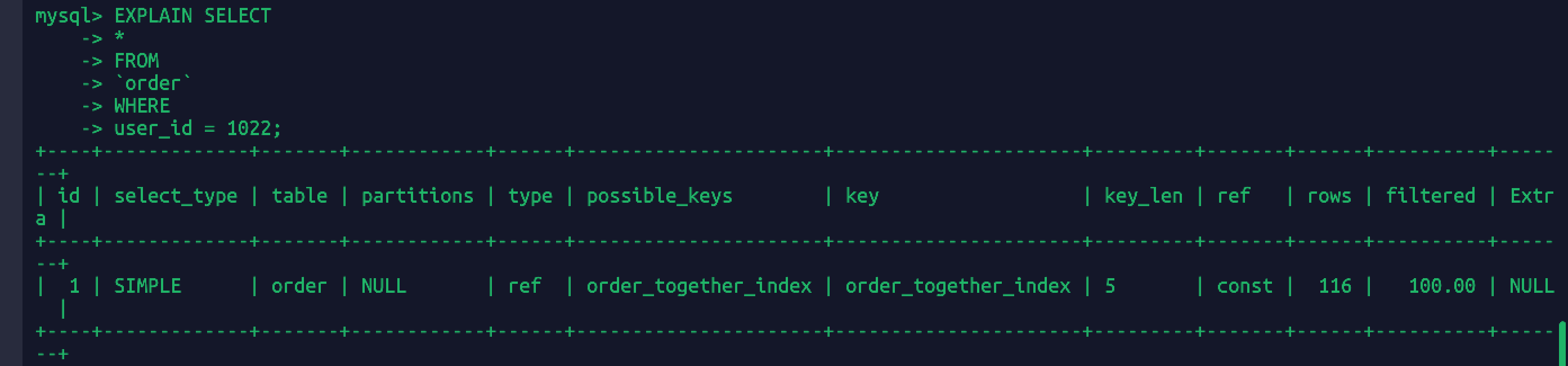
删除掉绝对值函数ABS后sql扫描行数变得正常
2.2.2-隐式转换
ALTER table `order` add index order_id_index(`order_id`);

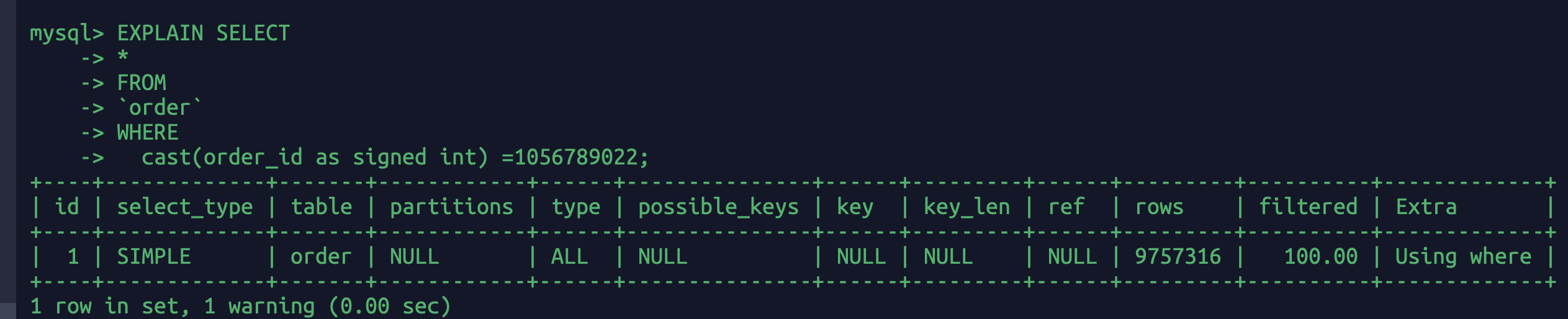
EXPLAIN SELECT*FROM`order`WHEREorder_id = 1056789022;

order_id字段是varchar类型,但是这里查询的sql给的是int,所以内部先要转换为str再去查询,多了一个步骤。相当于:
EXPLAIN SELECT*FROM`order`WHEREcast(order_id as signed int) =1056789022;
这相当于进行了函数操作
EXPLAIN SELECT*FROM`order`WHEREorder_id = "1056789022";

但是,请看这个sql:
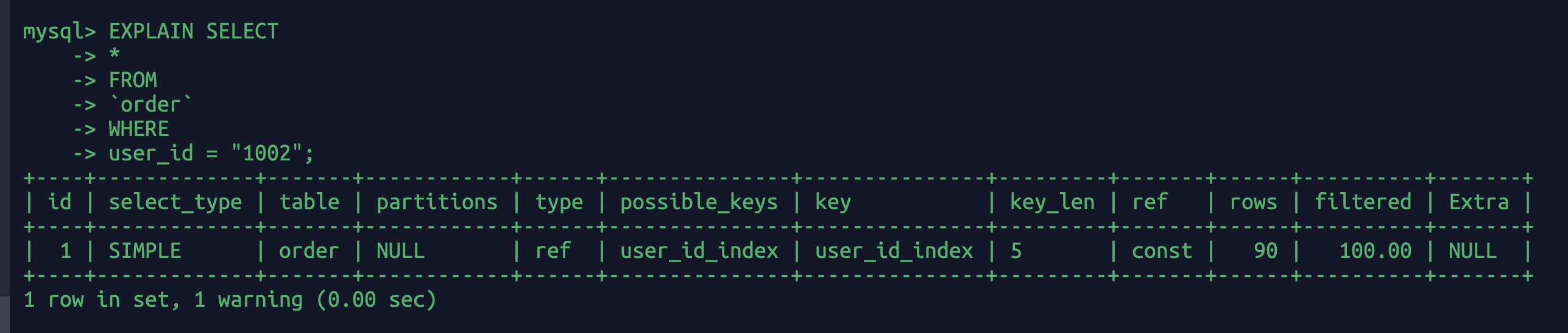
EXPLAIN SELECT*FROM`order`WHEREuser_id = "1002";
user_id在数据库中是int,这里查询是字符串传入,不应该也是隐士转换了么,怎么没有进行全表扫描?????
因为mysql认为order_id是字符串,如果你where order_id = 1,他会把数据库的order_id 为”1”和” 1”(注意这里有个空格在1的前面)的都返回给你,所以他怕返回错误数据只有一个个对比才行。但是user_id是int,你的sql为:where user_id = “xxxx” 最后的结果要么对要么不对,不会有有其他奇异。
SELECT * from `order` where order_id = "9942161ec956448588cecd97eb00ce2f" limit 10;SELECT * from `order` where order_id = "6a42c09fabbe44b3abc2925d740e59cc" limit 10;
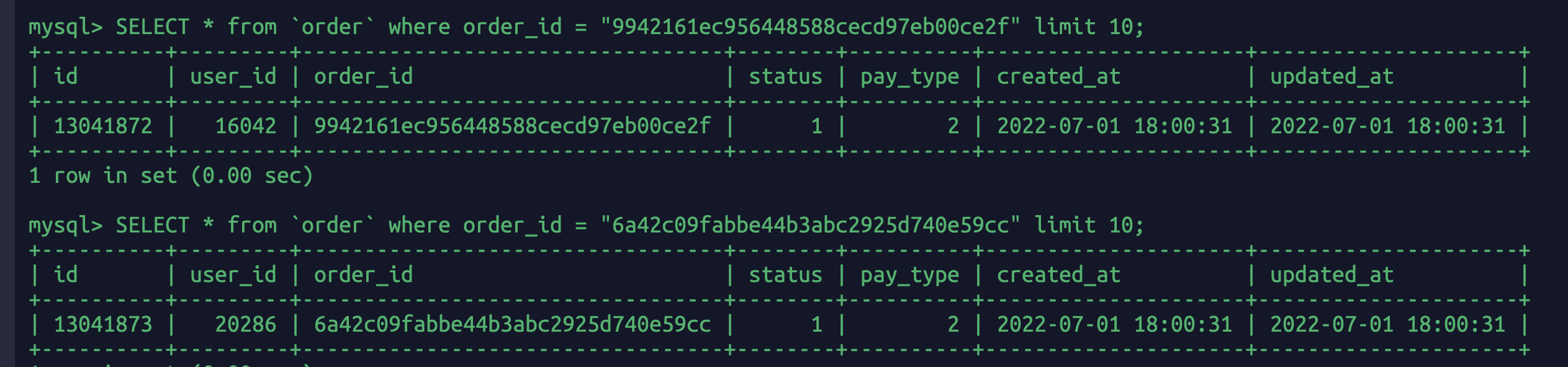
update `order` set order_id =' 12345678' where order_id="6a42c09fabbe44b3abc2925d740e59cc";update `order` set order_id ='12345678' where order_id="9942161ec956448588cecd97eb00ce2f";
“12345678”前面这有空格!!!

根据官方说法这条sql应该有两条数据出来:
SELECT * from `order` where order_id = 12345678 limit 10;

官方文档:https://dev.mysql.com/doc/refman/5.7/en/type-conversion.html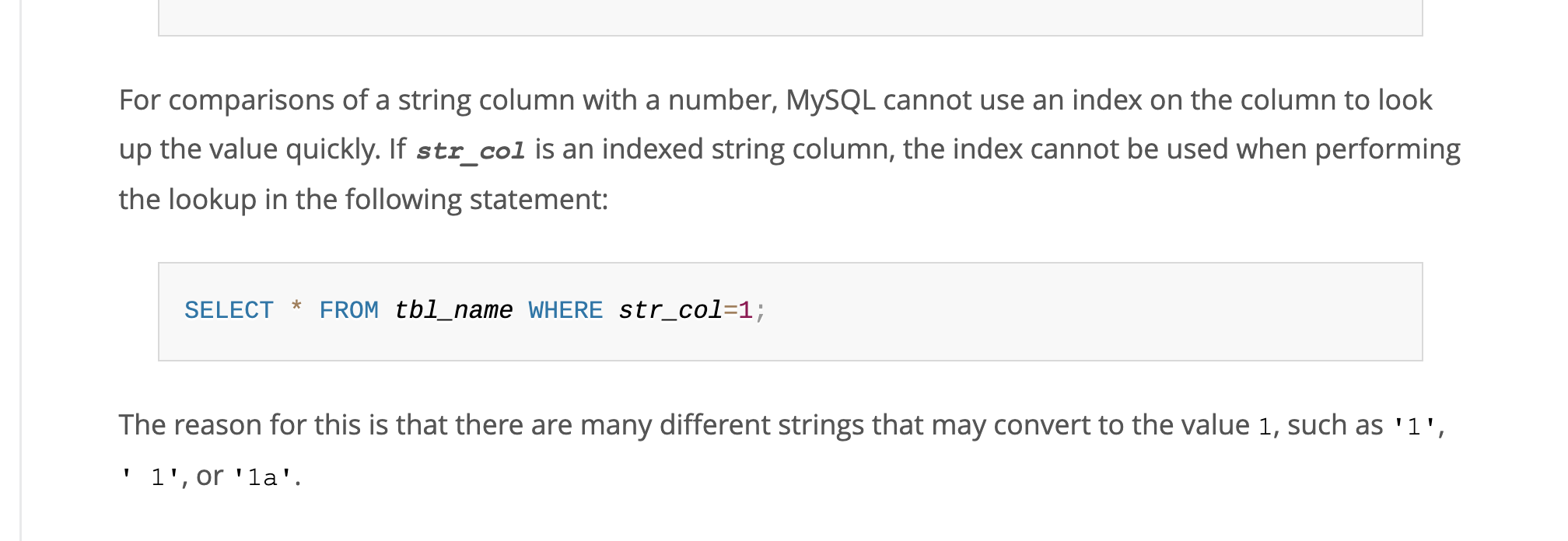
意思就是str_col这个字段是string类型的但是你传int 1,”1” “ 1” “1a”都可以转换成int 1,所以字段是string的索引列你传入int就会索引失效。
2.2.3-模糊查询
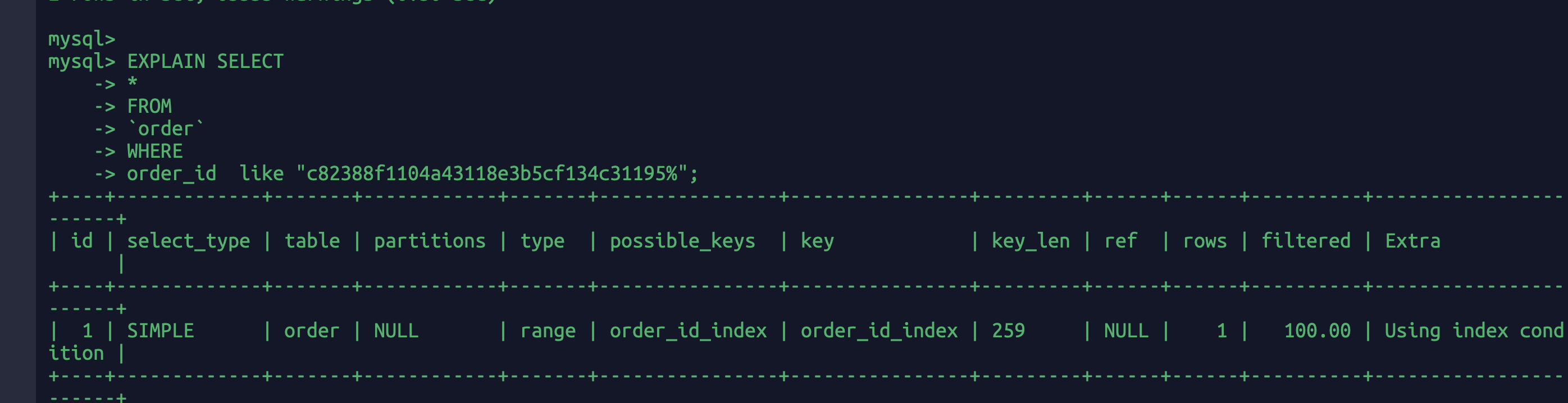
EXPLAIN SELECT*FROM`order`WHEREorder_id like "%c82388f1104a43118e3b5cf134c31195";
虽然order_id是有索引,但是因为通配符%实在最前面的,相当于一个贪婪匹配的感觉。意味着前面为都不晓得是什么,所以只能一个个全表扫描。
EXPLAIN SELECT*FROM`order`WHEREorder_id like "c82388f1104a43118e3b5cf134c31195%";
2.2.4-范围查询
explain select * from `order` where user_id >1 and user_id <10000;

sql优化器会根据检索比例、表大小、I/O块大小等进行评估是否使用索引。比如单次查询的数据量过大,优化器将不走索引。
explain select * from `order` where user_id >=1 and user_id <=1000;

2.2.5-计算操作
explain select * from `order` where user_id-1=1000;

这个和前面的函数操作我理解是一样的,只不过那些事内置的函数,这里是自己写一个计算
explain select * from `order` where user_id=1001;

2.2.6-最左匹配原则
为了控制变量,删除之前的user_id和order_id的两个索引
alter table `order` drop index user_id_index;alter table `order` drop index order_id_index;show index from `order`;
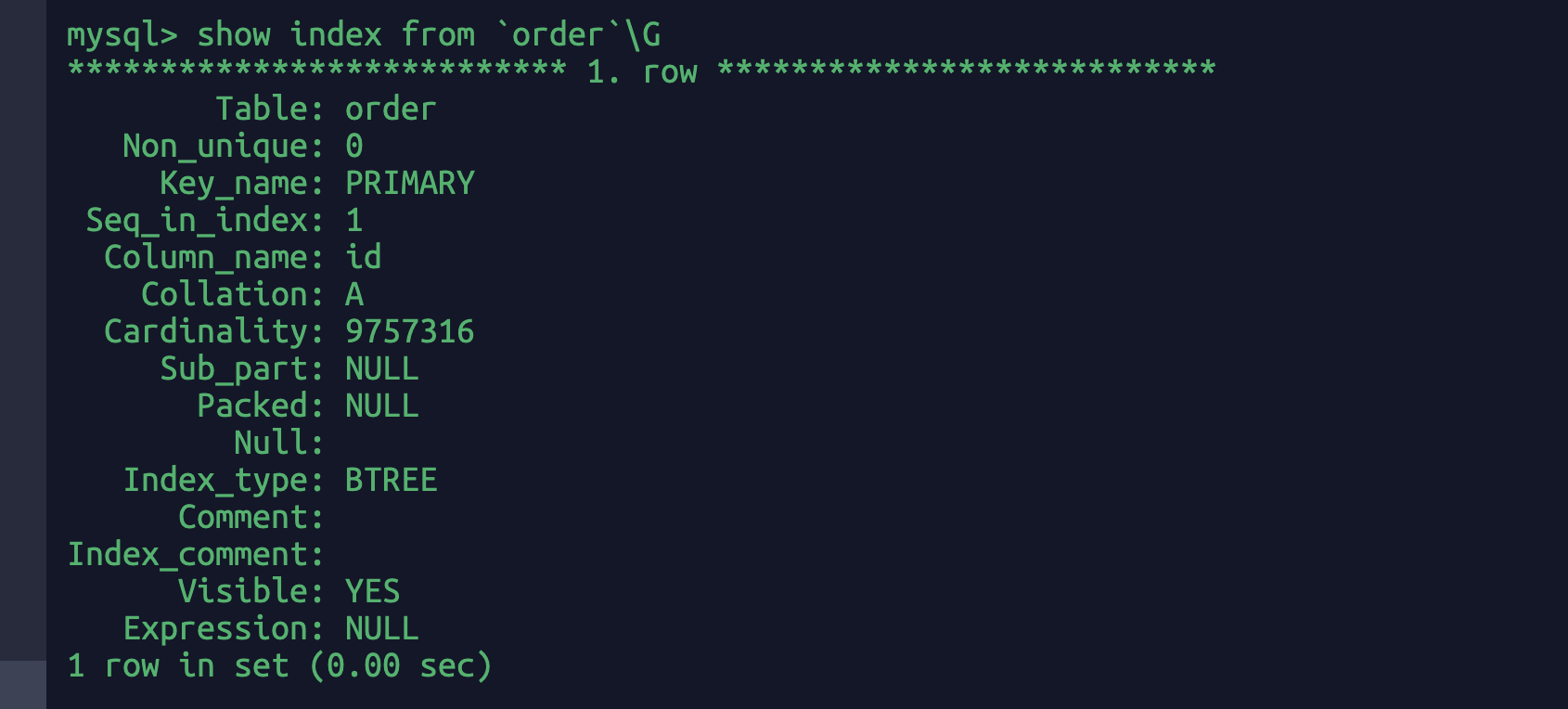
现在只剩下一个id索引了
对user_id,order_id,status,pay_type四个字段创建联合索引
alter table `order` add index order_together_index(`user_id`,`order_id`,`status`,`pay_type`);
那么什么是“最左匹配原则”呢?这种概念的东西还是看文档吧:https://dev.mysql.com/doc/refman/8.0/en/column-indexes.html
在创建联合索引后,如果顺序事abcd,那么请使用的查询sql也按照这个顺序(最左匹配)去执行,不然出现索引失效的问题。
//下面sql都会命中sql(命中率的问题后面再说)explain SELECT * FROM `order` WHERE user_id = 1022 ;explain SELECT * FROM `order` WHERE user_id = 1022 AND order_id = 'c82388f1104a43118e3b5cf134c31195' ;explain SELECT * FROM `order` WHERE user_id = 1022 AND order_id = 'c82388f1104a43118e3b5cf134c31195' AND status = 1 ;explain SELECT * FROM `order` WHERE user_id = 1022 AND order_id = 'c82388f1104a43118e3b5cf134c31195' AND status = 1 AND pay_type = 1;explain SELECT * FROM `order` WHERE user_id = 1022 AND order_id = 'c82388f1104a43118e3b5cf134c31195' AND pay_type = 1;//下面sql都没有命中sqlexplain SELECT * FROM `order` WHERE order_id = 'c82388f1104a43118e3b5cf134c31195' AND status = 1;explain SELECT * FROM `order` WHERE order_id = 'c82388f1104a43118e3b5cf134c31195' AND status = 1 AND pay_type = 1;explain SELECT * FROM `order` WHERE order_id = 'c82388f1104a43118e3b5cf134c31195' AND pay_type = 1;explain SELECT * FROM `order` WHERE status = 1 AND pay_type = 1;
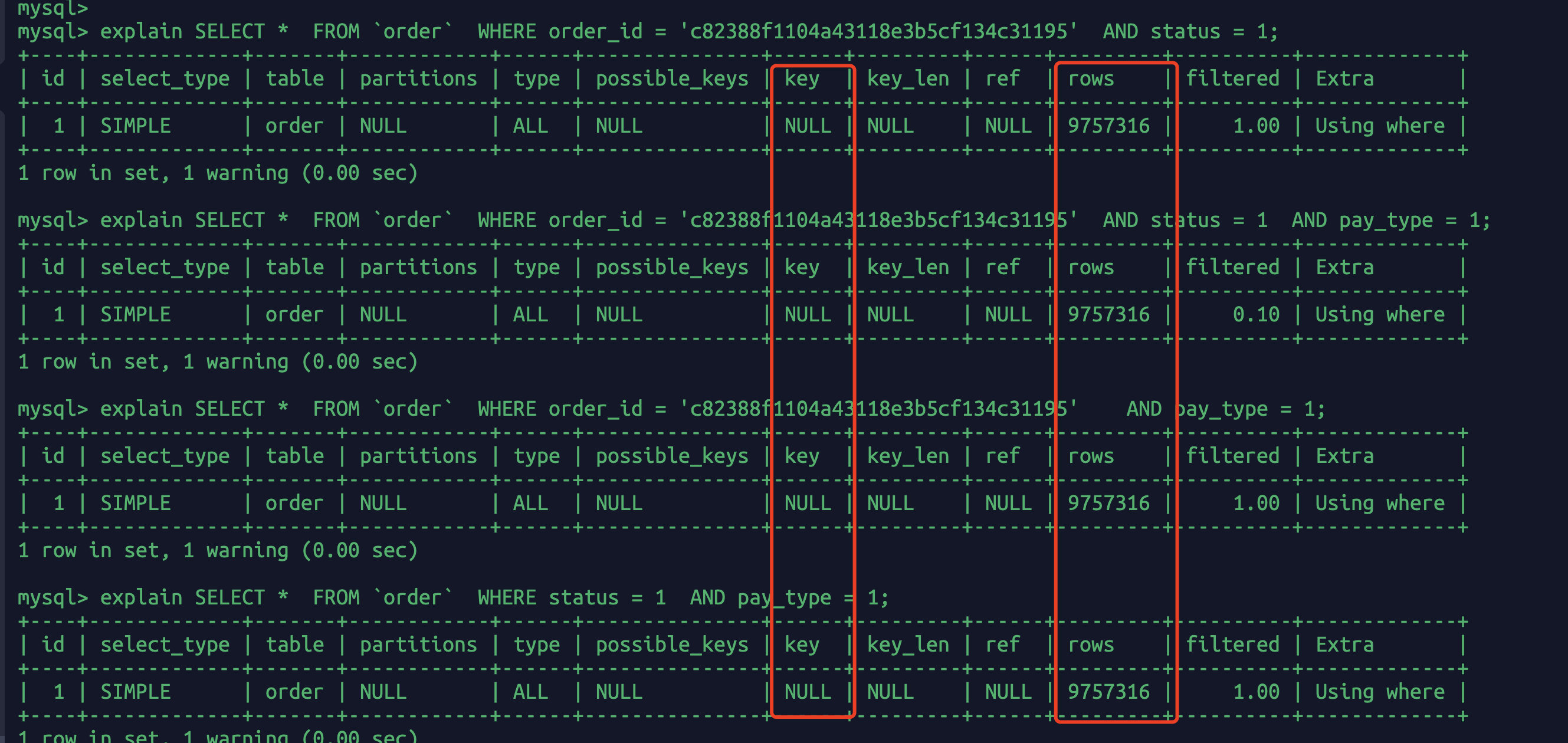
这就是最左匹配原则,因为索引创建的顺序是:user_id order_id status pay_type,所以你能命中这个联合索引的前提是必须user_id在查询sql的where条件的第一位,或者说你要按照索引的顺序写sql。
2.3-聚簇索引和非聚簇索引
2.3.1-聚簇索引概念
聚簇索引的概念:https://dev.mysql.com/doc/refman/5.7/en/innodb-index-types.html
Each InnoDB table has a special index called the clustered index that stores row data. Typically, the clustered index is synonymous with the primary key. To get the best performance from queries, inserts, and other database operations, it is important to understand how InnoDB uses the clustered index to optimize the common lookup and DML operations. When you define a PRIMARY KEY on a table, InnoDB uses it as the clustered index. A primary key should be defined for each table. If there is no logical unique and non-null column or set of columns to use a the primary key, add an auto-increment column. Auto-increment column values are unique and are added automatically as new rows are inserted. If you do not define a PRIMARY KEY for a table, InnoDB uses the first UNIQUE index with all key columns defined as NOT NULL as the clustered index. If a table has no PRIMARY KEY or suitable UNIQUE index, InnoDB generates a hidden clustered index named GEN_CLUST_INDEX on a synthetic column that contains row ID values. The rows are ordered by the row ID that InnoDB assigns. The row ID is a 6-byte field that increases monotonically as new rows are inserted. Thus, the rows ordered by the row ID are physically in order of insertion. How the Clustered Index Speeds Up Queries Accessing a row through the clustered index is fast because the index search leads directly to the page that contains the row data. If a table is large, the clustered index architecture often saves a disk I/O operation when compared to storage organizations that store row data using a different page from the index record. How Secondary Indexes Relate to the Clustered Index Indexes other than the clustered index are known as secondary indexes. In InnoDB, each record in a secondary index contains the primary key columns for the row, as well as the columns specified for the secondary index. InnoDB uses this primary key value to search for the row in the clustered index. If the primary key is long, the secondary indexes use more space, so it is advantageous to have a short primary key. For guidelines to take advantage of InnoDB clustered and secondary indexes, see Section 8.3, “Optimization and Indexes”.
也就是在mysql看来索引就分两大类:Clustered Index(聚集索引)和Secondary Indexes(非聚集索引)。前面我们说的什么联合索引,唯一索引都是非聚集索引。
那么聚集索引到底是什么?拿我我们的order表来讲,id是主键innodb引擎默认创建了一个索引,这个索引就是聚集索引(有的地方也叫主键索引)。同时有一个隐形的rowid记录数据的个数,用这个rowid在磁盘上排序。比如这里的order表主键是id,所以rowid的值就是主键id的值。如果你创建一个别的表没有主键那么rowid和主键的值就不会想等,此时rowid的意义就更在于做数据排序了,免得或许查询数据无序导致磁盘io过大。因为如果不创建一个索引的话数据是没有顺序的,io查询数据会很乱。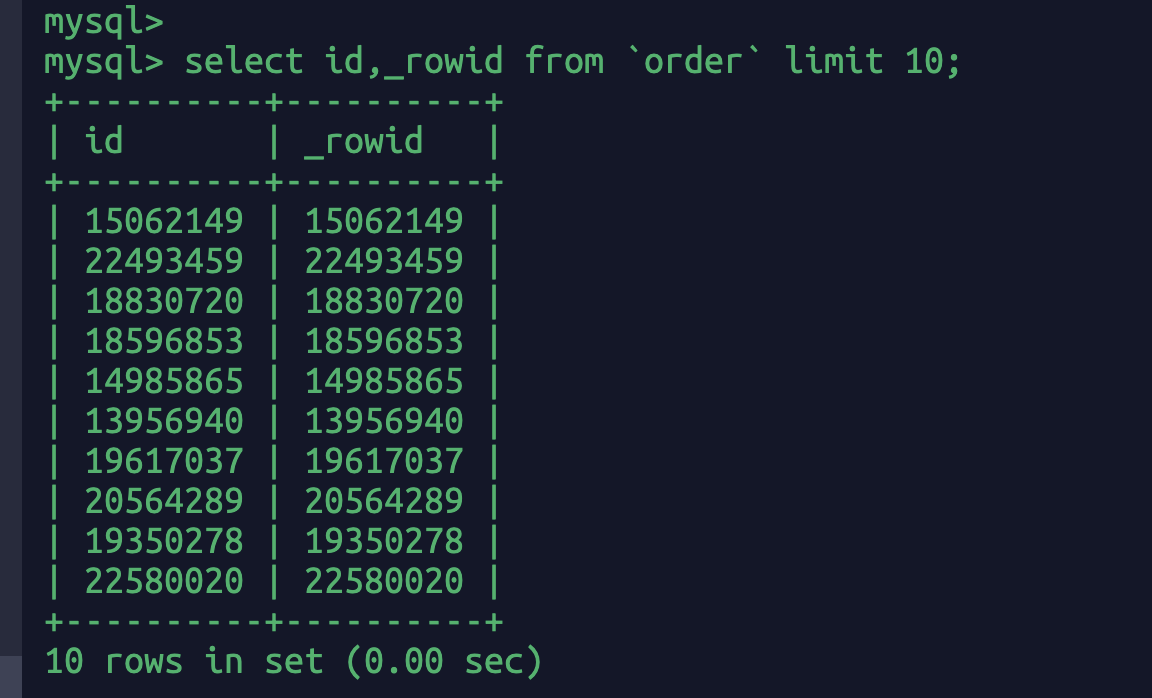
有主键的情况下id和_rowid的值是一样的
2.4-索引命中
2.4.1-回表
sql命中索引后,还需要通过索引找到那一行数据取到其他字段值,这一行为叫做回表。
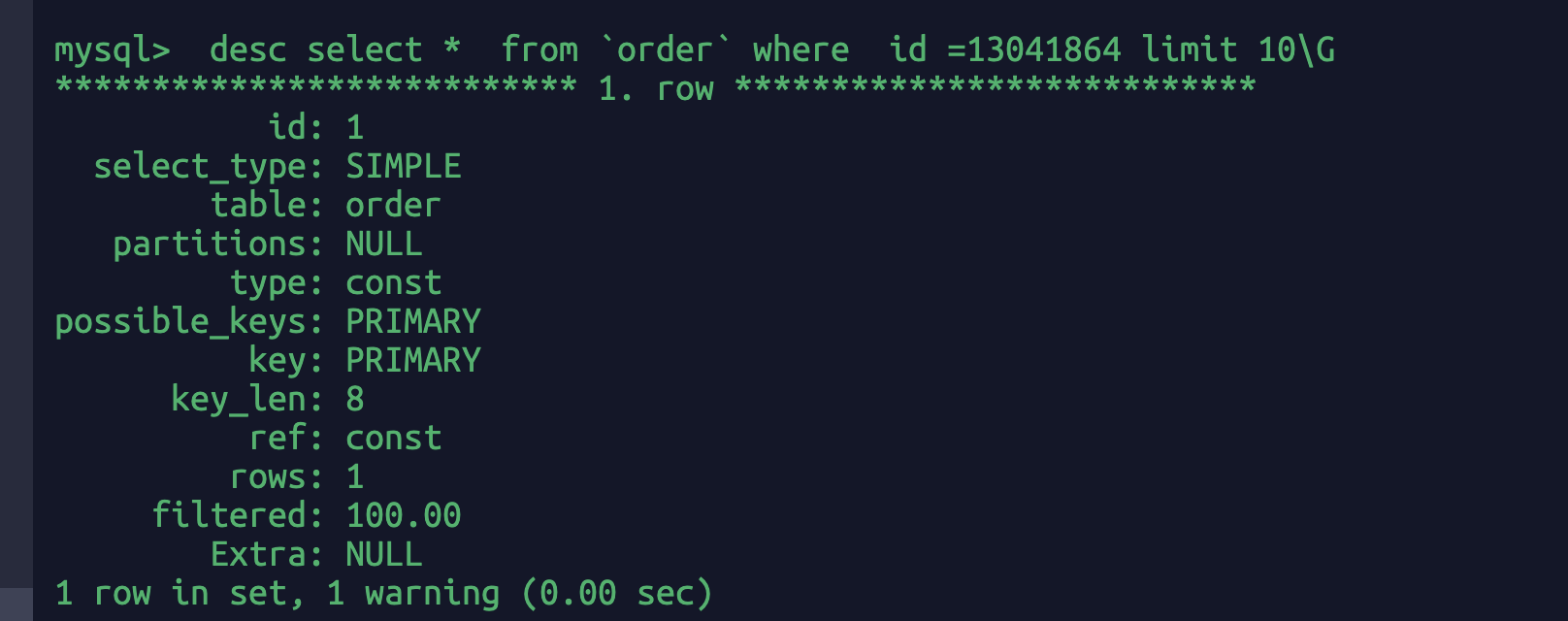
desc select id from `order` where id =13041864 limit 10;

因为id是索引字段,我只select id所以命中索引id后直接可以返回这个id的值,不需要再去查询其他字段。这里的extra=useing index就表示用的索引,没有回表的意思。
desc select * from `order` where id =13041864 limit 10;
2.4.2-索引覆盖
当一个索引包含需要查询的所有字段时,就称之为覆盖索引
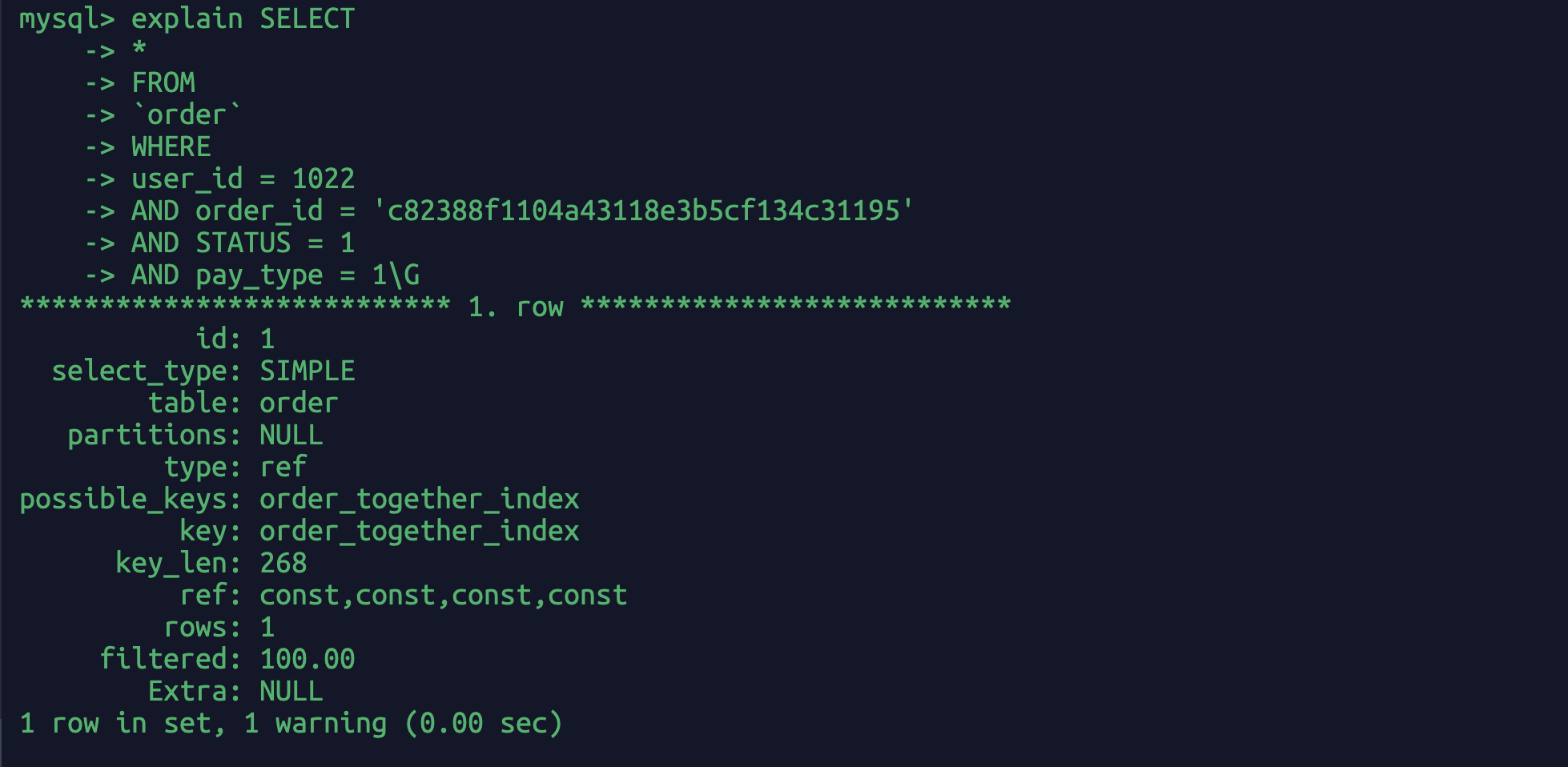
explain SELECT*FROM`order`WHEREuser_id = 1022AND order_id = 'c82388f1104a43118e3b5cf134c31195'AND STATUS = 1AND pay_type = 1\G
explain SELECTuser_idFROM`order`WHEREuser_id = 1022AND order_id = 'c82388f1104a43118e3b5cf134c31195'AND STATUS = 1AND pay_type = 1\G
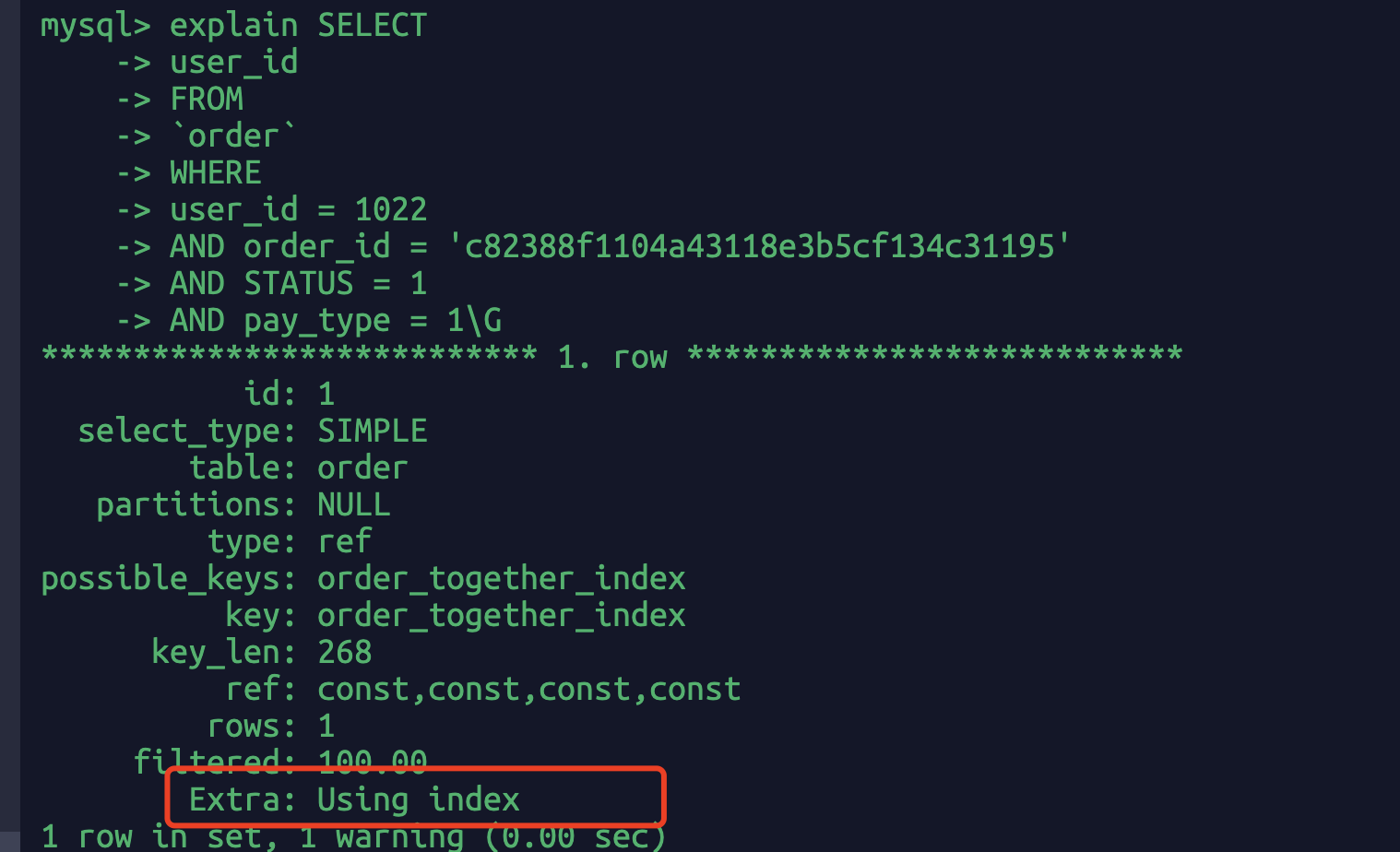
联合索引四个字段,我只查询user_id字段,所以联合索引覆盖了我的目标查询字段user_id,这种行为叫做索引覆盖。此时extra:”using index”表示没有回表。
2.4.3-命中率
前面已经创建了联合索引user_id order_id status pay_type,虽然目前为止我们能看到是否命中索引,那么是否可以知道具体命中的索引率来进一步优化我们的sql呢?
explain SELECT * FROM `order` WHERE user_id = 1022 AND order_id = 'c82388f1104a43118e3b5cf134c31195' AND STATUS = 1 AND pay_type = 1\G
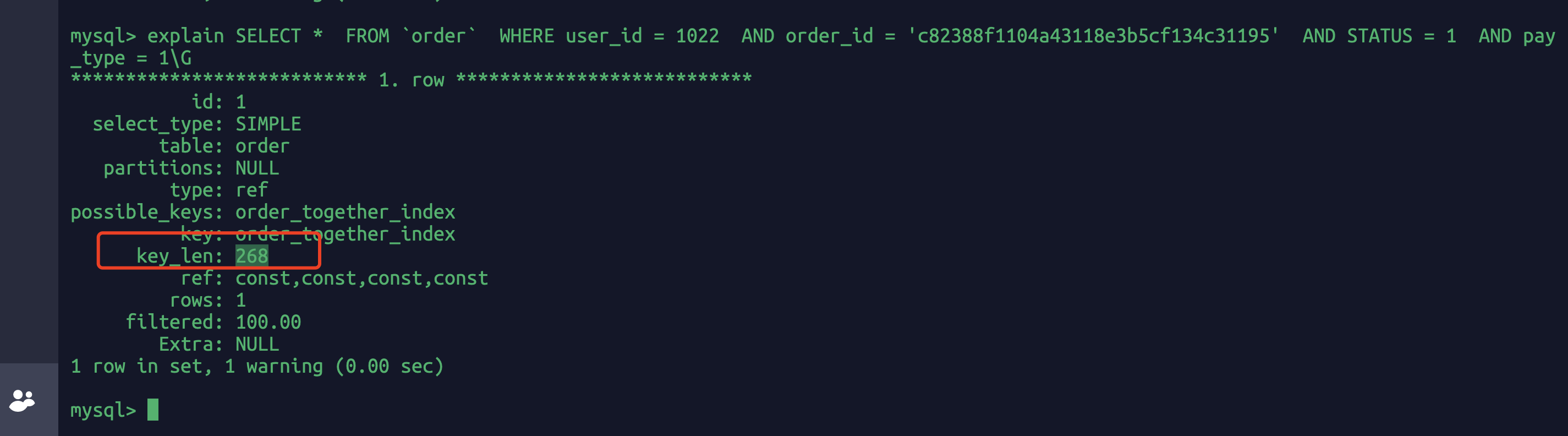
命中的索引的长度为268,key_len=268.
explain 中的 key_len 列用于表示这次查询中,所选择的索引长度有多少字节,常用于判断联合索引有多少列被选择了。下表总结了常用字段类型的 key_len:
| 列类型 | KEY_LEN | 备注 |
|---|---|---|
| int | key_len = 4+1 | int 为 4 bytes,允许为 NULL,加 1 byte |
| int not null | key_len = 4 | 不允许为 NULL |
| bigint | key_len=8+1 | bigint 为 8 bytes,允许为 NULL 加 1 byte |
| bigint not null | key_len=8 | bigint 为 8 bytes |
| char(30) utf8 | key_len=30*3+1 | char(n)为:n * 3 ,允许为 NULL 加 1 byte |
| char(30) not null utf8 | key_len=30*3 | 不允许为 NULL |
| varchar(30) not null utf8 | key_len=30*3+2 | utf8 每个字符为 3 bytes,变长数据类型,加 2 bytes |
| varchar(30) utf8 | key_len=30*3+2+1 | utf8 每个字符为 3 bytes,允许为 NULL,加 1 byte,变长数据类型,加 2 bytes |
| datetime | key_len=8+1 (MySQL 5.6.4之前的版本);key_len=5+1(MySQL 5.6.4及之后的版本) | 允许为 NULL,加 1 byte |
show create table `order`;
CREATE TABLE `order` (`id` bigint unsigned NOT NULL AUTO_INCREMENT,`user_id` int DEFAULT '0' COMMENT '下单用户id',`order_id` varchar(64) DEFAULT NULL COMMENT '订单号',`status` tinyint(1) DEFAULT '1' COMMENT '该笔交易的状态0进行中;1支付完成;2支付失败;3取消支付;',`pay_type` tinyint(1) DEFAULT '1' COMMENT '1支付宝2微信3银行卡',`created_at` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',`updated_at` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',PRIMARY KEY (`id`),KEY `order_together_index` (`user_id`,`order_id`,`status`,`pay_type`)) ENGINE=InnoDB AUTO_INCREMENT=23041964 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
user_id order_id status pay_type的类型分别是int varchar(64) tinyint tinyint,所以整个联合索引的长度
| user_id | int类型 允许NULL | 4+1=5字节 | |
|---|---|---|---|
| order_id | utf8mb4 每个字符为 4bytes,变长数据类型,加 2 byte,允许NULL加1byte | 64*4+2+1=259字节 | |
| status | tinyint类型 允许NULL | 1+1=2字节 | |
| pay_type | tinyint类型 允许NULL | 1+1=2字节 |
total=5+259+2+2=268字节
EXPLAIN SELECT*FROM`order`WHEREuser_id = 1022AND order_id = 'c82388f1104a43118e3b5cf134c31195'AND STATUS = 1AND pay_type = 1 \G
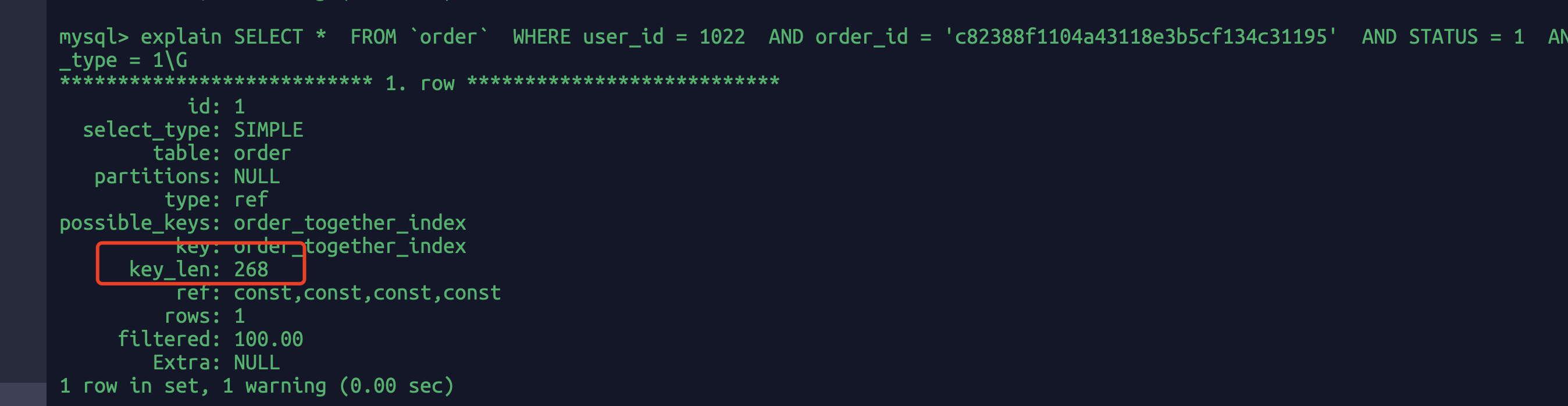 key_len=268 全部命中,因为where条件四个字段都用到了
key_len=268 全部命中,因为where条件四个字段都用到了
EXPLAIN SELECT*FROM`order`WHEREuser_id = 1022AND order_id = 'c82388f1104a43118e3b5cf134c31195' \G
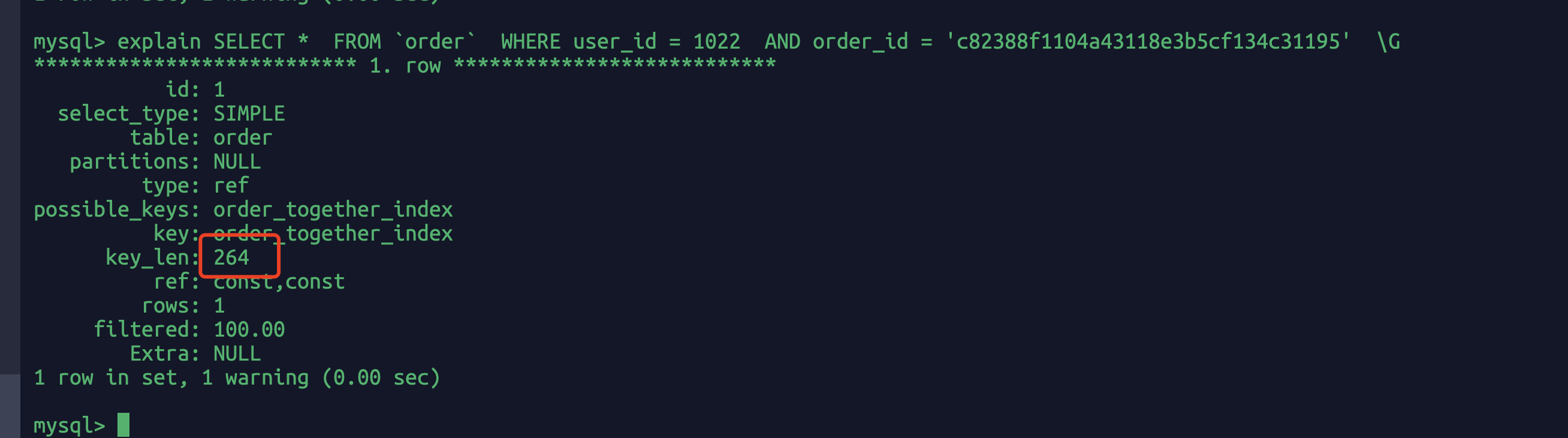
key_len=264 可以反向推出少了status和pay_type两个字段的索引
EXPLAIN SELECT*FROM`order`WHEREuser_id = 1022AND STATUS = 1AND pay_type = 1 \G
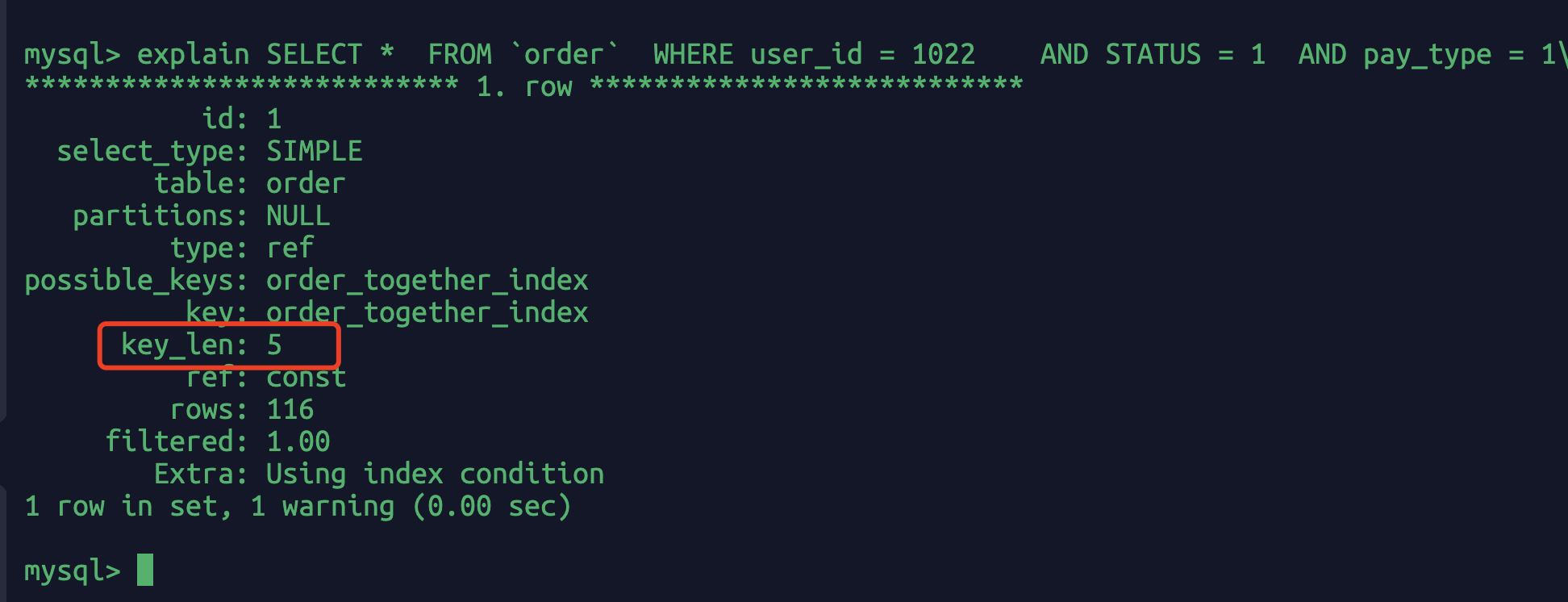
根据前面的情况也就是只用到了user_id这个字段的索引,后面status pay_status没用到。从“最左匹配”原则也可以解释:因为中间order_id没有匹配到,后面的status和pay_type字段没有走索引。
EXPLAIN SELECT*FROM`order`WHERESTATUS = 1AND pay_type = 1 \G
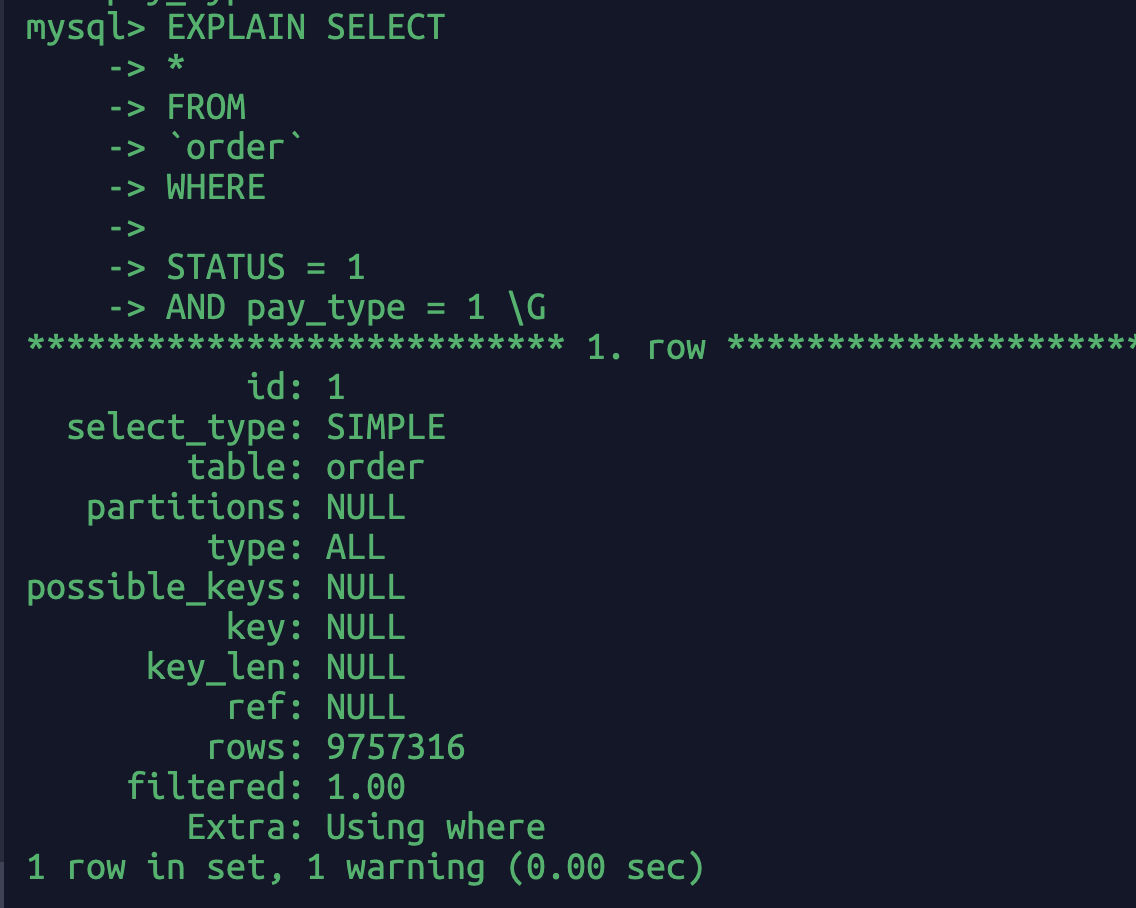
此时key_len长度为NULL。
发现规律没,如果四个字段abcd是联合索引且顺序也为abcd,根据“最左匹配”原则你能命中索引的条件为:
a ab abc
abd(d没有走index,因为中间隔了c字段)
ac(c没有走index 因为中间隔了b字段 )
acd(cd没有走index 因为中间隔了b字段 )
ad(d没有走index 因为中间隔了bc字段 )

若有收获,就点个赞吧
0 人点赞
