

准备环境
虚拟机:CentOS Linux release 7.6.1810
jdk:jdk-15.0.0
elasticsearch:elasticsearch-7.10.0
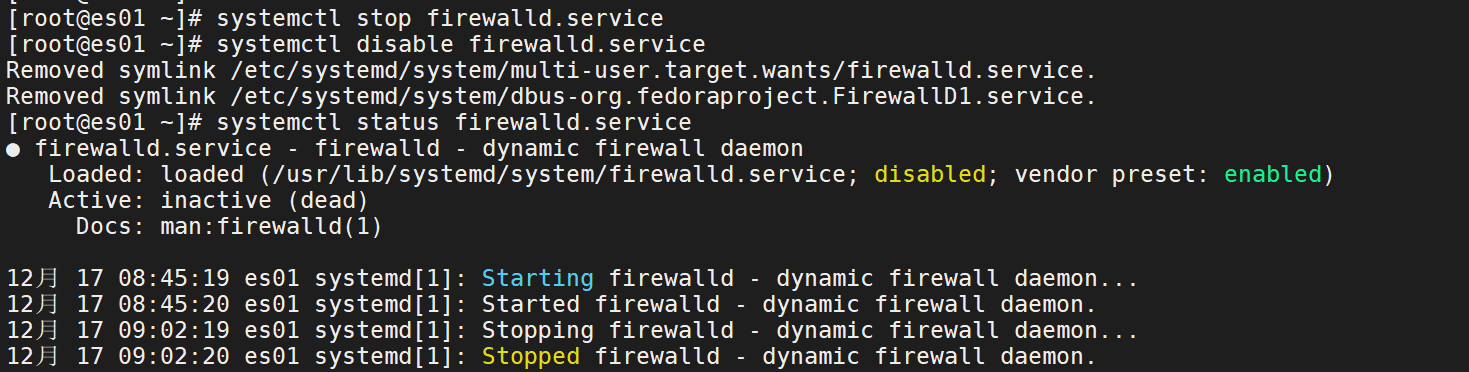
0、关闭防火墙
systemctl stop firewalld.servicesystemctl disable firewalld.servicesystemctl status firewalld.service
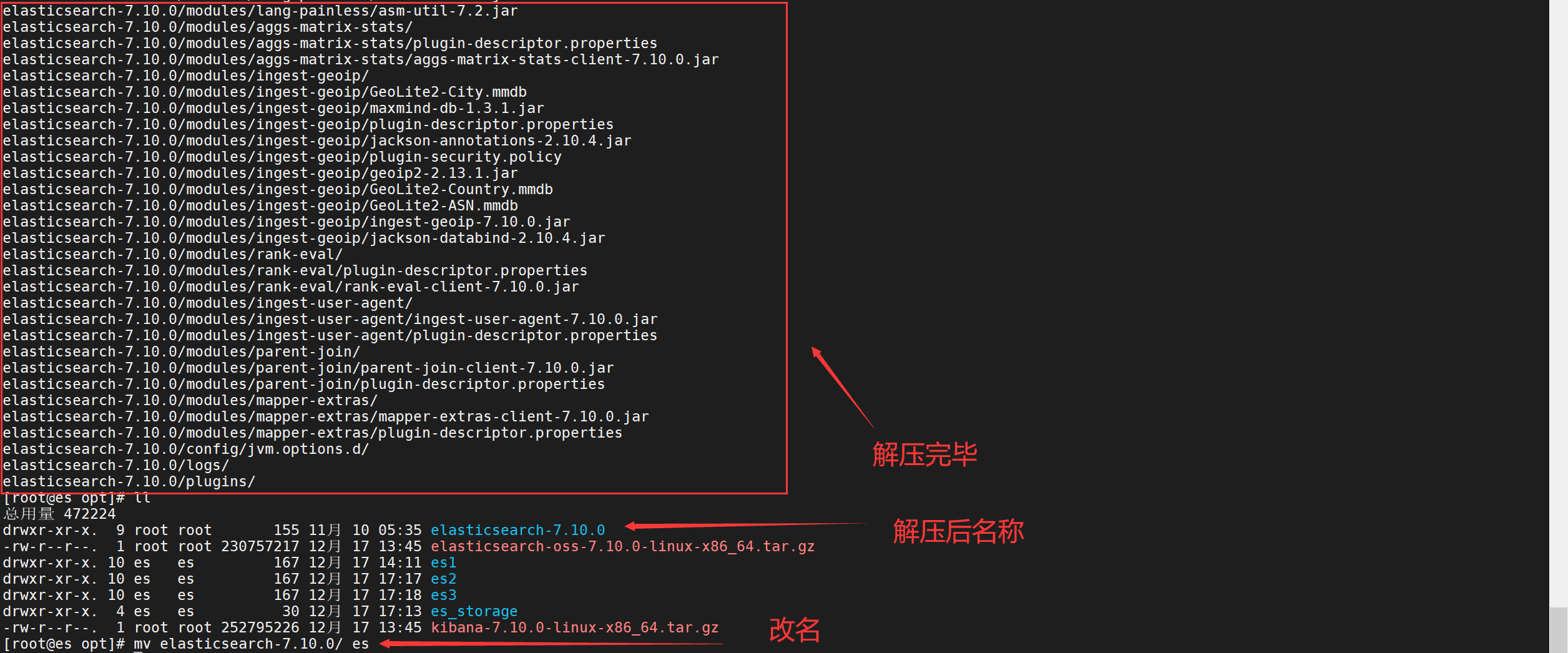
0.1、将elasticsearc的tar包上传解压并修改文件名
tar -zxvf elasticsearch-oss-7.10.0-linux-x86_64.tar.gzmv elasticsearch-oss-7.10.0/ es1
0.2、复制两份
cp -r es1 es2cp -r es1 es3
0.3、添加elasticsearch专属账户和组
groupadd esuseradd es -g es -p eschown -R es:es /opt/es1/
0.4、修改es1、es2、es3的用户组和用户为es
chown -R es:es /opt/es1/ /opt/es2/ /opt/es3/
0.4、配置jdk环境变量
vim /etc/profile
找到es自带JDK目录,复制路径,文件末添加:
export JAVA_HOME=/opt/es1/jdkexport PATH=${JAVA_HOME}/bin:$PATH
使配置立即生效:
source /etc/profile
查看jdk,确认环境变量配置成功:
java -version

0.5、提高线程个数、es用户描述权限、内存权限、限制swap交换空间、TCP重传最大次数
cat >> /etc/security/limits.conf << EOF* soft nofile 65536* hard nofile 65536* soft nproc 4096* hard nproc 4096EOF
cat >> /etc/sysctl.conf << EOFvm.max_map_count=262144vm.swappiness = 1net.ipv4.tcp_retries2=5EOF
注:在更庞大的集群内,建议将swap空间提升至10,提高系统性能。
加载sysctl.conf参数
sysctl -p
1、配置elasticsearch
1.0、调整jvm堆空间大小
vim /opt/es1/config/jvm.options
找到
-Xms1G -Xmx1G 修改为:
-Xms256m-Xmx256m将jvm.options传给其他节点:
cp /opt/es1/config/jvm.options /opt/es2/config/cp /opt/es1/config/jvm.options /opt/es3/config/1.1、修改elasticsearch.yml
角色配置:
elasticsearch默认将所有节点都设置为数据节点,这会降低集群的运行效率,因此将集群角色和数据节点分开有利于集群的任务分配和效率
es1:
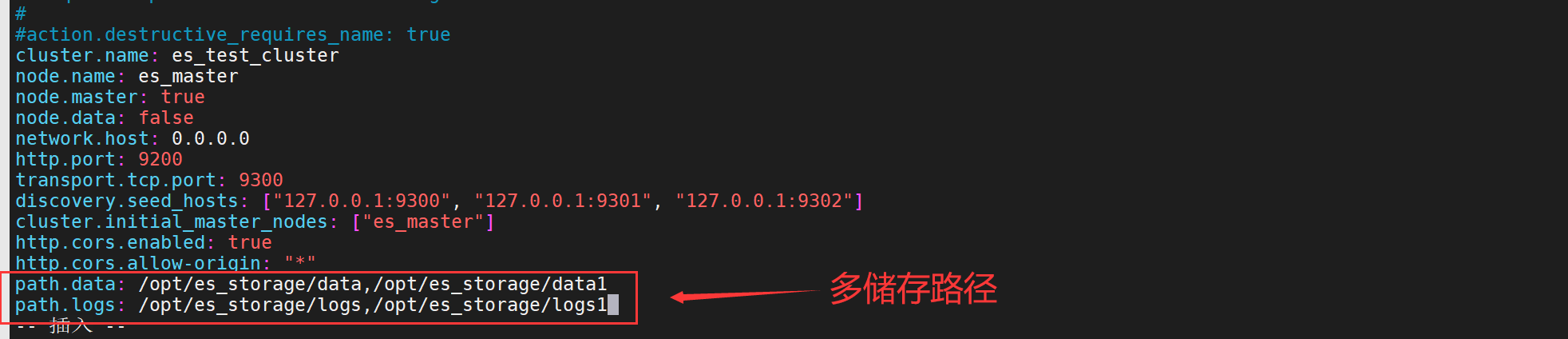
cluster.name: es_test_clusternode.name: es_masternode.master: truenode.data: falsenetwork.host: 0.0.0.0http.port: 9200transport.tcp.port: 9300discovery.seed_hosts: ["127.0.0.1:9300", "127.0.0.1:9301", "127.0.0.1:9302"]cluster.initial_master_nodes: ["es_master"]http.cors.enabled: truehttp.cors.allow-origin: "*"path.data: /opt/es_storage/datapath.logs: /opt/es_storage/logs创建es用户组和用户的专属的数据存储和日志存储目录
mkdir -p /opt/es_storage/{data,logs}chown -R es:es /opt/es_storage注:以下推荐在搭建时就完成。搭建并运行后再配置储存位置,会造成从节点报错,删除data才能运行
可以添加多个储存路径,例:
1.2、启动es1
切换到es用户,到es1的bin目录下:
su escd /opt/es1/bin启动es启动脚本:
./elasticsearch2、配置elasticsearch_slaves
2.0、修改elasticsearch.yml
切换到root用户:
exites2:
cat >> /opt/es2/config/elasticsearch.yml << EOFcluster.name: es_test_clusternode.name: es_slaves1node.master: falsenode.data: truenetwork.host: 0.0.0.0http.port: 9201transport.tcp.port: 9301discovery.seed_hosts: ["127.0.0.1:9300", "127.0.0.1:9301", "127.0.0.1:9302"]http.cors.enabled: truehttp.cors.allow-origin: "*"EOFes3:
cat >> /opt/es3/config/elasticsearch.yml << EOFcluster.name: es_test_clusternode.name: es_slaves2node.master: falsenode.data: truenetwork.host: 0.0.0.0http.port: 9202transport.tcp.port: 9302discovery.seed_hosts: ["127.0.0.1:9300", "127.0.0.1:9301", "127.0.0.1:9302"]http.cors.enabled: truehttp.cors.allow-origin: "*"2.1、尝试单独启动es2、es3节点
切换到es用户,到es2的bin目录下:
su escd /opt/es2/bin启动es启动脚本:
./elasticsearches2:
Ctrl+C:强制结束当前进程
到es3的bin目录下:
cd /opt/es3/bin启动es启动脚本:
./elasticsearch
Ctrl+C:强制结束当前进程
实例:

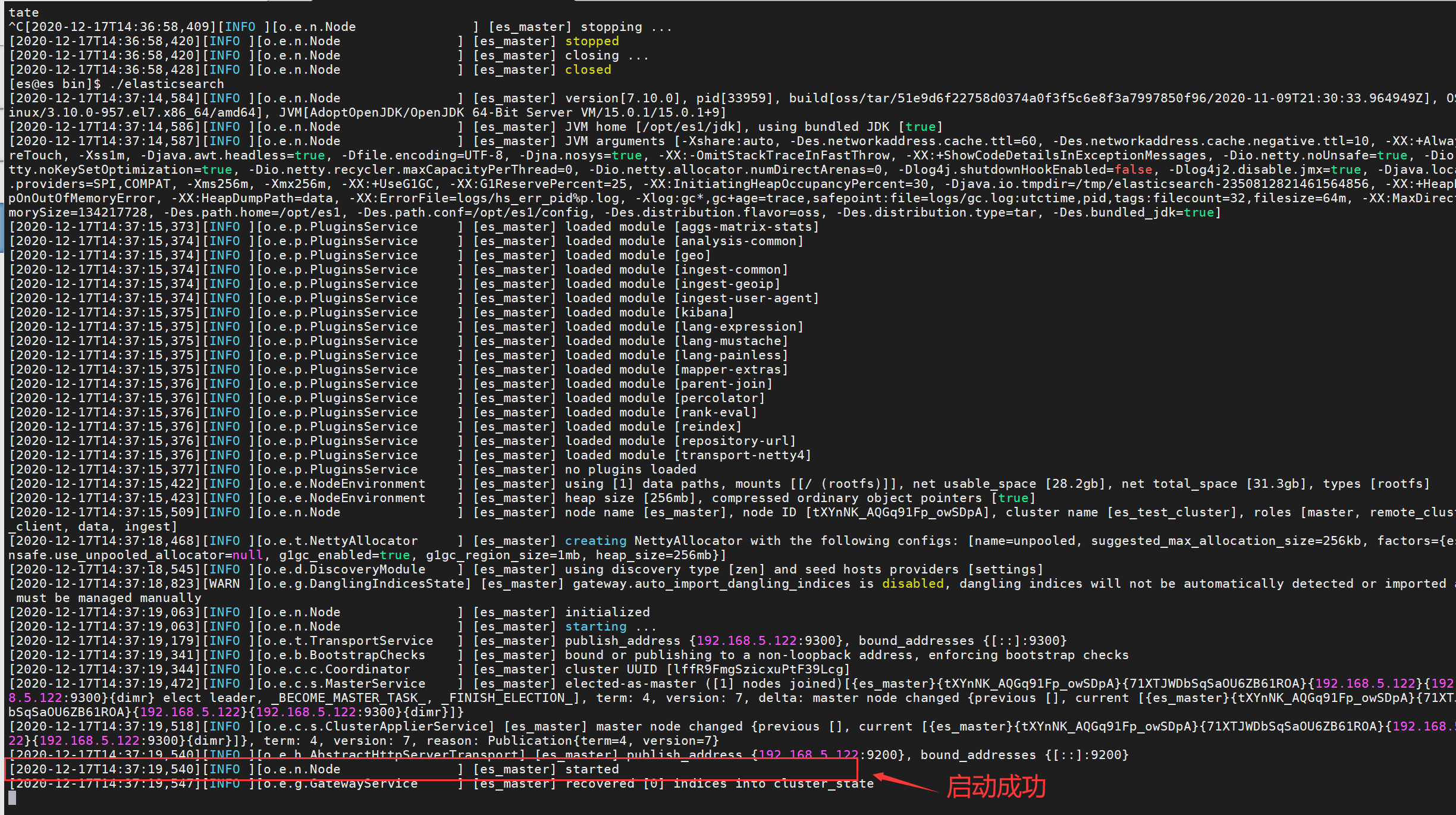
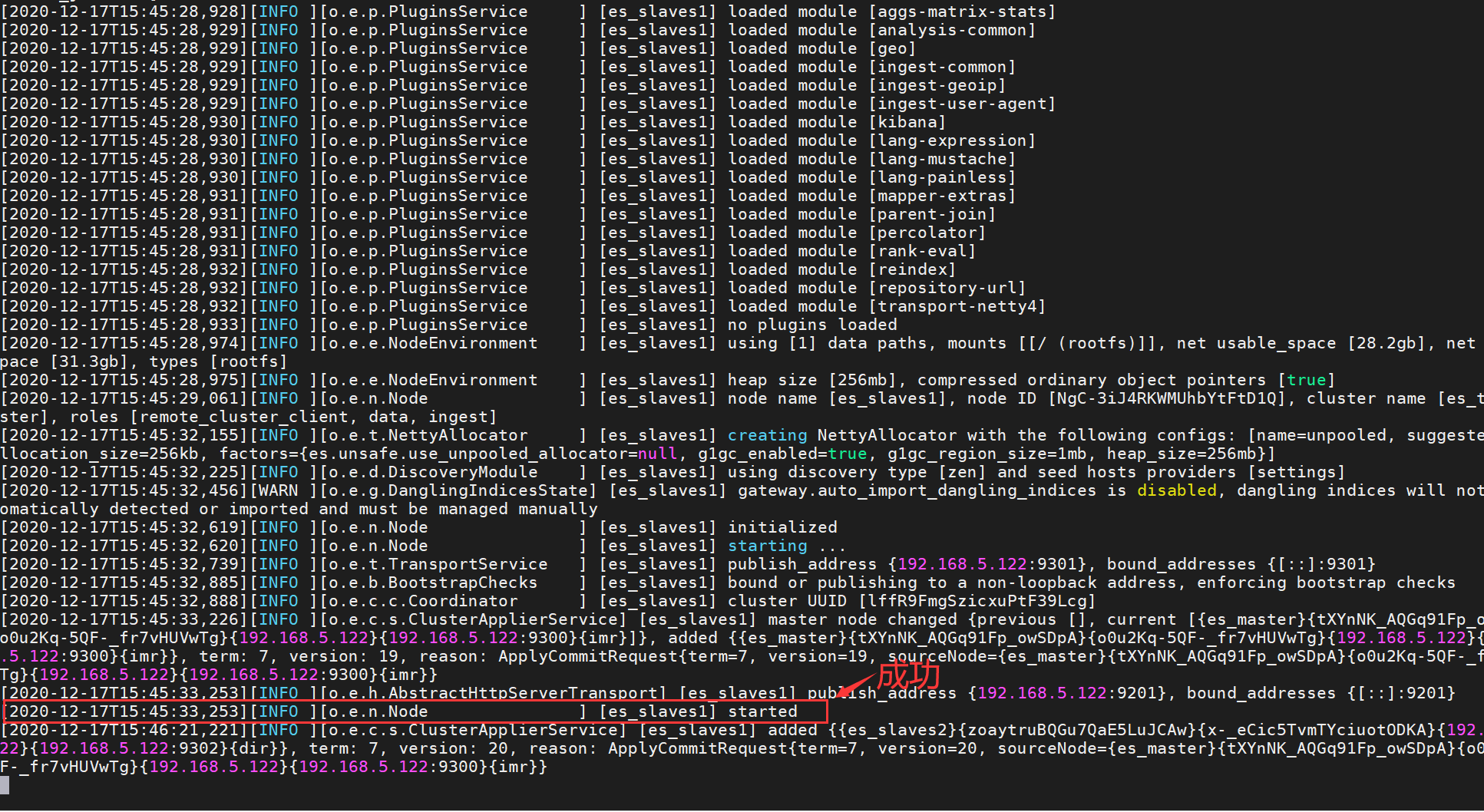
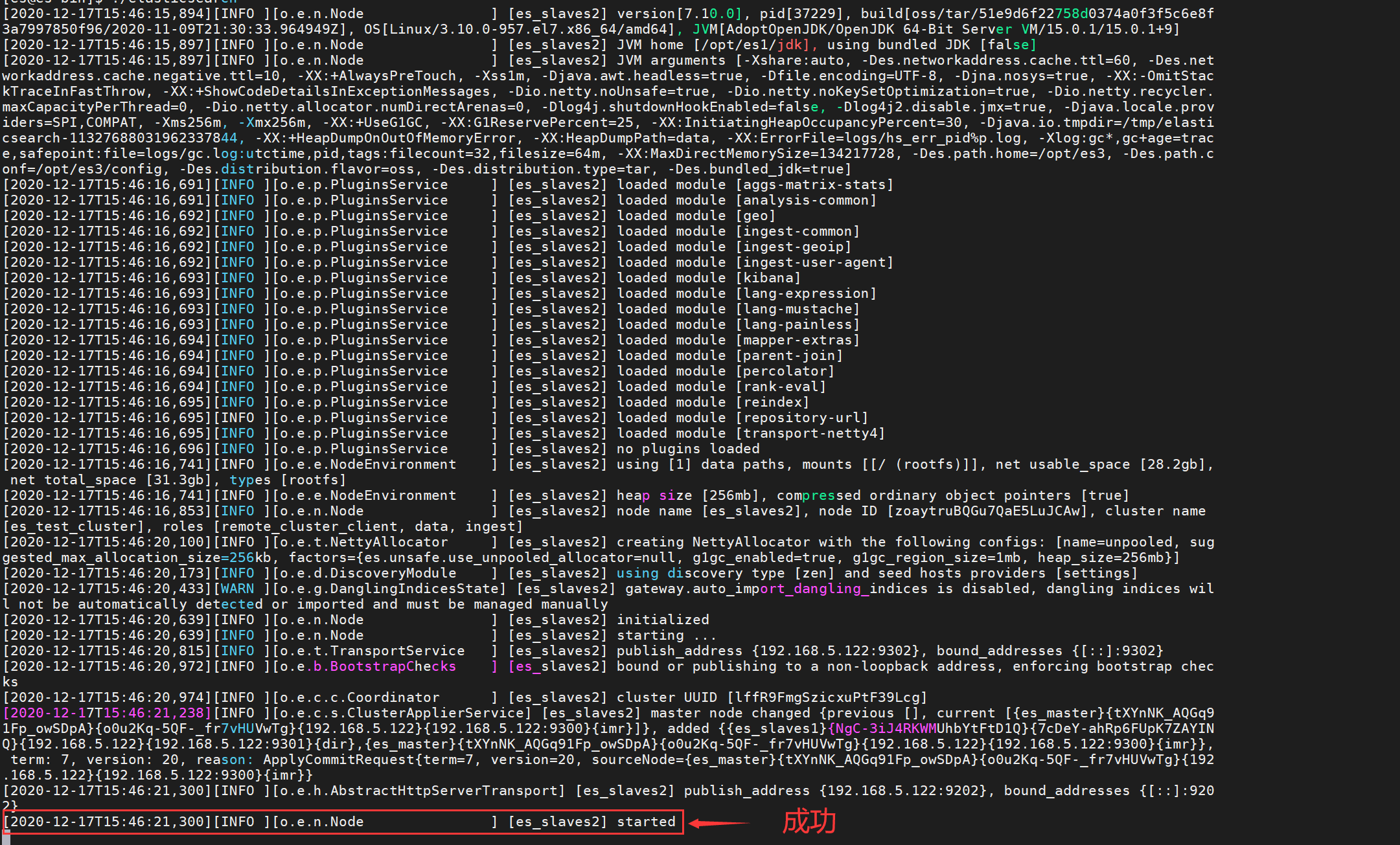

3 启动所有节点的elasticsearch:
es1:
cd /opt/es1/bin./elasticsearch -dcd /opt/es2/bin./elasticsearch -dcd /opt/es3/bin./elasticsearch -d
网页输入本机ip地址+端口查看群节点情况:
192.168.100.155:9200/_cat/nodes?v
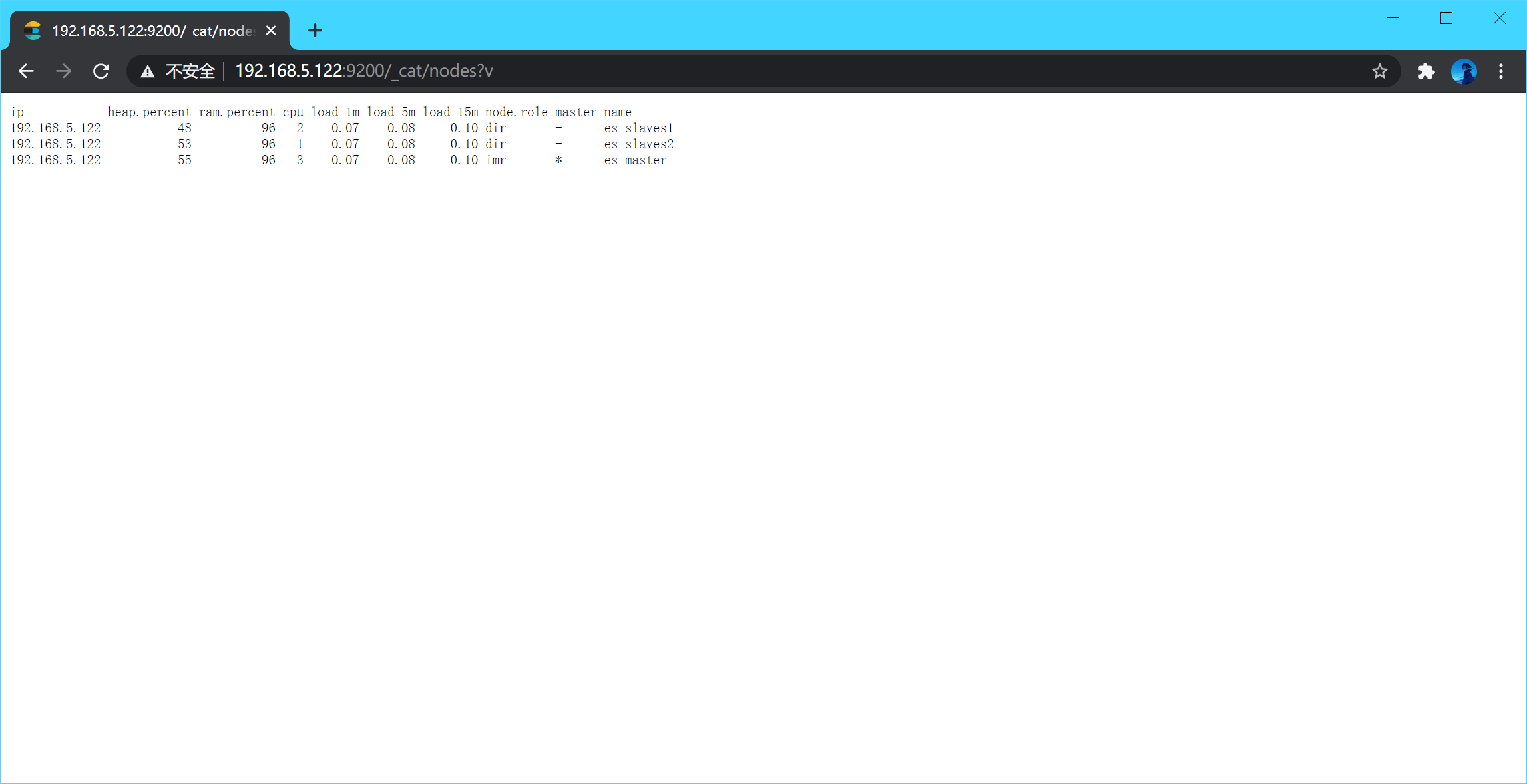
小知识:
| http://192.168.5.122:9200/_cat/ | ||
|---|---|---|
| 1 | /_cat/allocation | 提供一个快照,反映当前节点有多少个分片(shard)以及用了多少磁盘空间(disk) |
| 2 | /_cat/shards | 反应每个节点有那些分片,告诉我们,那些是主分片,那些是从分片,每个分片的document数量,以及在该节点占用的磁盘空间 |
| 3 | /_cat/shards/{index} | 查看具体索引的分片信息 |
| 4 | /_cat/master | 查看master信息 |
| 5 | /_cat/nodes | 查看节点信息 |
| 6 | /_cat/tasks | 查看任务 |
| 7 | /_cat/indices | 查看索引信息 |
| 8 | /_cat/indices/{index} | 查看具体索引信息 |
| 9 | /_cat/segments | 查看存储片段信息 |
| 10 | /_cat/segments/{index} | 查看具体索引的存储片段信息 |
| 11 | /_cat/count | 该指令可以获取当前集群中有多少个document,类似mysql中有多少条记录,**查看文档总数** |
| 12 | /_cat/count/{index} | 查看具体索引的文档总数 |
| 13 | /_cat/recovery | 反应当前系统中,索引分片的恢复信息,包括正在进行的以及已经完成了的。 恢复,指的是当节点添加或者减少时发生的数据移动造成的。 |
| 14 | /_cat/recovery/{index} | 查看具体索引的数据恢复状态 |
| 15 | /_cat/health | 反应当前集群的健康指数信息 |
| 16 | /_cat/pending_tasks | 查看待处理任务 |
| 17 | /_cat/aliases | 可以查询出当前索引的filter以及routing所配置的别名信息。 |
| 18 | /_cat/aliases/{alias} | 指定别名查看信息 |
| 19 | /_cat/thread_pool | 查看线程池信息 |
| 20 | /_cat/thread_pool/{thread_pools} | 查看线程池下插件 |
| 21 | /_cat/plugins | 提供一个视图,反应当前节点中处在运行状态的插件。 |
| 22 | /_cat/fielddata | 查看fielddata占用内存情况(查询时es会把fielddata信息load进内存) |
| 23 | /_cat/fielddata/{fields} | 针对某一字段进行查看 |
| 24 | /_cat/nodeattrs | 反应出当前数据节点的属性信息 |
| 25 | /_cat/repositories | 查看存储库 |
| 26 | /_cat/snapshots/{repository} | 查看快照库 |
| 27 | /_cat/templates | 查看模板 |
ElasticSearch的基本概念
| 1 | Index |
类似于mysql数据库中的database |
|---|---|---|
| 2 | Type |
类似于mysql数据库中的table表,es中可以在Index中建立type(table),通过mapping进行映射 |
| 3 | Document |
由于es存储的数据是文档型的,一条数据对应一篇文档即相当于mysql数据库中的一行数据row,一个文档中可以有多个字段也就是mysql数据库一行可以有多列 |
| 4 | Field |
es中一个文档中对应的多个列与mysql数据库中每一列对应 |
| 5 | Mapping |
可以理解为mysql或者solr中对应的schema,只不过有些时候es中的mapping增加了动态识别功能 |
| 6 | indexed |
就是名义上的建立索引 |
| 7 | Query DSL |
类似于mysql的sql语句,只不过在es中是使用的json格式的查询语句,专业术语就叫:QueryDSL GET/PUT/POST/DELETE |
使用curl命令操作ElasticSearch 格式如下:
curl -X<REST Verb> <Node>:<Port>/<Index>/<Type>/<ID><REST Verb>:REST风格的语法谓词<Node>:节点ip<Index>:索引名<Type>:索引类型<ID>:操作对象的ID号

若有收获,就点个赞吧
0 人点赞
