- edit">一 Config files locationedit
- 二 elasticsearch.yml
elasticsearch configuration:Original configuration:- # ————————————————— Cluster —————————————————-
- # —————————————————— Node ——————————————————
- # —————————————————- Paths ——————————————————
- # —————————————————- Memory —————————————————-
- # ————————————————— Network —————————————————-
- # ————————————————- Discovery —————————————————
- # ————————————————— Gateway —————————————————-
- # ————————————————— Various —————————————————-
- 三 jvm.options
- ## IMPORTANT: JVM heap size
- ##########################################################
## You should always set the min and max JVM heap size to the same value.
## For example, to set the heap to 4 GB, set:
## -Xms4g
## -Xmx4g - ##########################################################
# Xms represents the initial size of total heap space
# Xmx represents the maximum size of total heap space
-Xms500m
-Xmx500m - #
- ##########################################################
- ## Expert settings
- ## GC configuration
- ## G1GC Configuration
- NOTE: G1GC is only supported on JDK version 10 or later
# to use G1GC, uncomment the next two lines and update the version on the following three lines to your version of the JDK
# 10-13:-XX:-UseConcMarkSweepGC - 10-13:-XX:-UseCMSInitiatingOccupancyOnly
- generate a heap dump when an allocation from the Java heap fails heap dumps are created in the working directory of the JVM
- specify an alternative path for heap dumps; ensure the directory exists and has sufficient space
-XX:HeapDumpPath=data - specify an alternative path for JVM fatal error logs
-XX:ErrorFile=logs/hs_err_pid%p.log - 四 log4j2.properties
- ######## Server - old style pattern
- ######## Deprecation JSON
- ######## Deprecation - old style pattern
- ######## Search slowlog JSON
- ######## Indexing slowlog JSON
- ######## Indexing slowlog - old style pattern
一 Config files locationedit
版本:elasticsearch-oss-7.10.0-linux-x86_64.tar.gz
Elasticsearch has three configuration files:
elasticsearch.ymlfor configuring Elasticsearchjvm.optionsfor configuring Elasticsearch JVM settingslog4j2.propertiesfor configuring Elasticsearch logging
These files are located in the config directory, whose default location depends on whether or not the installation is from an archive distribution (
tar.gzorzip) or a package distribution (Debian or RPM packages). For the archive distributions, the config directory location defaults to$ES_HOME/config. The location of the config directory can be changed via theES_PATH_CONFenvironment variable as follows:
ES_PATH_CONF=/path/to/my/config ./bin/elasticsearch
Alternatively, you can
exporttheES_PATH_CONFenvironment variable via the command line or via your shell profile. For the package distributions, the config directory location defaults to/etc/elasticsearch. The location of the config directory can also be changed via theES_PATH_CONFenvironment variable, but note that setting this in your shell is not sufficient. Instead, this variable is sourced from/etc/default/elasticsearch(for the Debian package) and/etc/sysconfig/elasticsearch(for the RPM package). You will need to edit theES_PATH_CONF=/etc/elasticsearchentry in one of these files accordingly to change the config directory location.
elasticsearch_version:elasticsearch-oss-7.10.0-linux-x86_64.tar.gz
Important System Configurationedit
Ideally, Elasticsearch should run alone on a server and use all of the resources available to it. In order to do so, you need to configure your operating system to allow the user running Elasticsearch to access more resources than allowed by default.
Disable swapping
Another option available on Linux systems is to ensure that the sysctl value vm.swappiness is set to 1. This reduces the kernel’s tendency to swap and should not lead to swapping under normal circumstances, while still allowing the whole system to swap in emergency conditions.
临时设置(重启或者时网络重置都会导致失效)
sysctl -w vm.swappiness=1vm.swappiness = 1查看cat /proc/sys/vm/swappiness1
永久设置
在/etc/sysctl.conf中编辑
vim /etc/sysctl.conf#文件末添加vm.swappiness = 1#不重启生效/sbin/sysctl -p
Ensure sufficient virtual memory
mmapfs(内存映射文件系统)
The MMap FS type stores the shard index on the file system (maps to Lucene MMapDirectory) by mapping a file into memory (mmap). Memory mapping uses up a portion of the virtual memory address space in your process equal to the size of the file being mapped. Before using this class, be sure you have allowed plenty of virtual address space.
Elasticsearch uses a mmapfs directory by default to store its indices. The default operating system limits on mmap counts is likely to be too low, which may result in out of memory exceptions.
临时设置
sysctl -w vm.max_map_count=262144
永久设置
vim /etc/sysctl.conf#文件末添加vm.max_map_count=262144#不重启生效sysctl -p
Increase file descriptors
On Linux systems, ulimit can be used to change resource limits on a temporary basis. Limits usually need to be set as ulimit -n)to 65,536, you can do the following:
临时设置
ulimit -n 65535
永久设置
vim /etc/security/limits.conf用户名称(*代指所有用户) soft nofile 65536用户名称(*代指所有用户) hard nofile 65536
Ensure sufficient threads
Elasticsearch uses a number of thread pools for different types of operations. It is important that it is able to create new threads whenever needed. Make sure that the number of threads that the Elasticsearch user can create is at least 4096.
临时设置
ulimit -u 4096
永久设置
vim /etc/security/limits.conf用户名称(*代指所有用户) soft nproc 4096用户名称(*代指所有用户) hard nproc 4096
TCP retransmission timeout
Highly-available clusters must be able to detect node failures quickly so that they can react promptly by reallocating lost shards, rerouting searches and perhaps electing a new master node. Linux users should therefore reduce the maximum number of TCP retransmissions.
临时设置
sysctl -w net.ipv4.tcp_retries2=5
永久设置
vim /etc/sysctl.conf#文件末添加net.ipv4.tcp_retries2=5#不重启生效sysctl -p
二 elasticsearch.yml
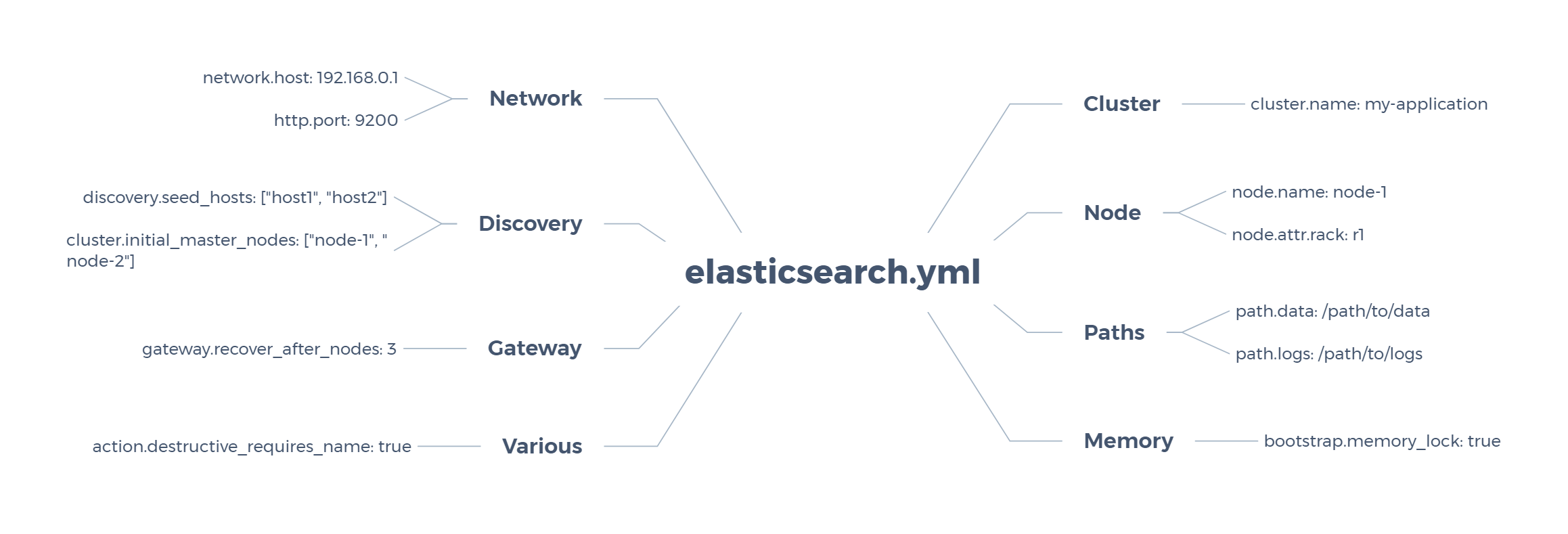
elasticsearch configuration:
| 1 | Cluster | 集群模块 |
|---|---|---|
| 2 | Node | 节点模块 |
| 3 | Paths | 存储模块 |
| 4 | Menory | 内存模块 |
| 5 | Network | 网络模块 |
| 6 | Discovery | 发现模块(不确定) |
| 7 | Gateway | 网关模块 |
| 8 | Various | 其他模块(不确定) |
Original configuration:
# ————————————————— Cluster —————————————————-
#cluster.name: my-application
A node can only join a cluster when it shares its
cluster.namewith all the other nodes in the cluster. The default name iselasticsearch, but you should change it to an appropriate name that describes the purpose of the cluster. IMPORTANT:Do not reuse the same cluster names in different environments. Otherwise, nodes might join the wrong cluster.
# —————————————————— Node ——————————————————
#node.name: node-1
Elasticsearch uses
node.nameas a human-readable identifier for a particular instance of Elasticsearch. This name is included in the response of many APIs. The node name defaults to the hostname of the machine when Elasticsearch starts, but can be configured explicitly inelasticsearch.yml:
node.name: prod-data-2
#node.attr.rack: r1
attr,attr.name(Default) Attribute name, such asrack
# —————————————————- Paths ——————————————————
#path.data: /path/to/data
#path.logs: /path/to/logs
For macOS
.tar.gz, Linux.tar.gz, and Windows.zipinstallations, Elasticsearch writes data and logs to the respectivedataandlogssubdirectories of$ES_HOMEby default. However, files in$ES_HOMErisk deletion during an upgrade. In production, we strongly recommend you set thepath.dataandpath.logsinelasticsearch.ymlto locations outside of$ES_HOME. TIP:Docker, Debian, RPM, macOS Homebrew, and Windows.msiinstallations write data and log to locations outside of$ES_HOMEby default.Linux and macOS installations support Unix-style paths:
path:data: /var/data/elasticsearchlogs: /var/log/elasticsearch
If needed, you can specify multiple paths in
path.data. Elasticsearch stores the node’s data across all provided paths but keeps each shard’s data on the same path. WARNING:Elasticsearch does not balance shards across a node’s data paths. High disk usage in a single path can trigger a high disk usage watermark for the entire node. If triggered, Elasticsearch will not add shards to the node, even if the node’s other paths have available disk space. If you need additional disk space, we recommend you add a new node rather than additional data paths.Linux and macOS installations support multiple Unix-style paths in
path.data:
path:data:- /mnt/elasticsearch_1- /mnt/elasticsearch_2- /mnt/elasticsearch_3
# —————————————————- Memory —————————————————-
#bootstrap.memory_lock: true
disable all swap files instead. NOTE: Some platforms still swap off-heap memory when using a memory lock. To prevent off-heap memory swaps, disable all swap files instead. Disable all swap filesedit: Usually Elasticsearch is the only service running on a box, and its memory usage is controlled by the JVM options. There should be no need to have swap enabled. On Linux systems, you can disable swap temporarily by running: sudo swapoff -a This doesn’t require a restart of Elasticsearch. To disable it permanently, you will need to edit the
/etc/fstabfile and comment out any lines that contain the wordswap.
# ————————————————— Network —————————————————-
#network.host: 192.168.0.1
To form a cluster with nodes on other servers, your node will need to bind to a non-loopback address. Defaults to
_local_. The following special values may be passed tonetwork.host:_[networkInterface]_Addresses of a network interface, for example_en0_._local_Any loopback addresses on the system, for example127.0.0.1._site_Any site-local addresses on the system, for example192.168.0.1._global_Any globally-scoped addresses on the system, for example8.8.8.8.
#http.port: 9200http.port
(Static) A bind port range. Defaults to 9200-9300.
# ————————————————- Discovery —————————————————
#discovery.seed_hosts: [“host1”, “host2”]
Out of the box, without any network configuration, Elasticsearch will bind to the available loopback addresses and scan local ports 9300 to 9305 to connect with other nodes running on the same server. This behavior provides an auto-clustering experience without having to do any configuration.
When you want to form a cluster with nodes on other hosts, use the static discovery.seed_hosts setting.
#cluster.initial_master_nodes: [“node-1”, “node-2”]
When you start a brand new Elasticsearch cluster for the very first time, there is a cluster bootstrapping step, which determines the set of master-eligible nodes whose votes are counted in the very first election.
# ————————————————— Gateway —————————————————-
#gateway.recover_after_nodes: 3
(Static) Recover as long as this many data or master nodes have joined the cluster.
# ————————————————— Various —————————————————-
#action.destructive_requires_name: true
(Dynamic) When set to true, you must specify the index name to delete an index. It is not possible to delete all indices with _all or use wildcards.
三 jvm.options
Original configuration:
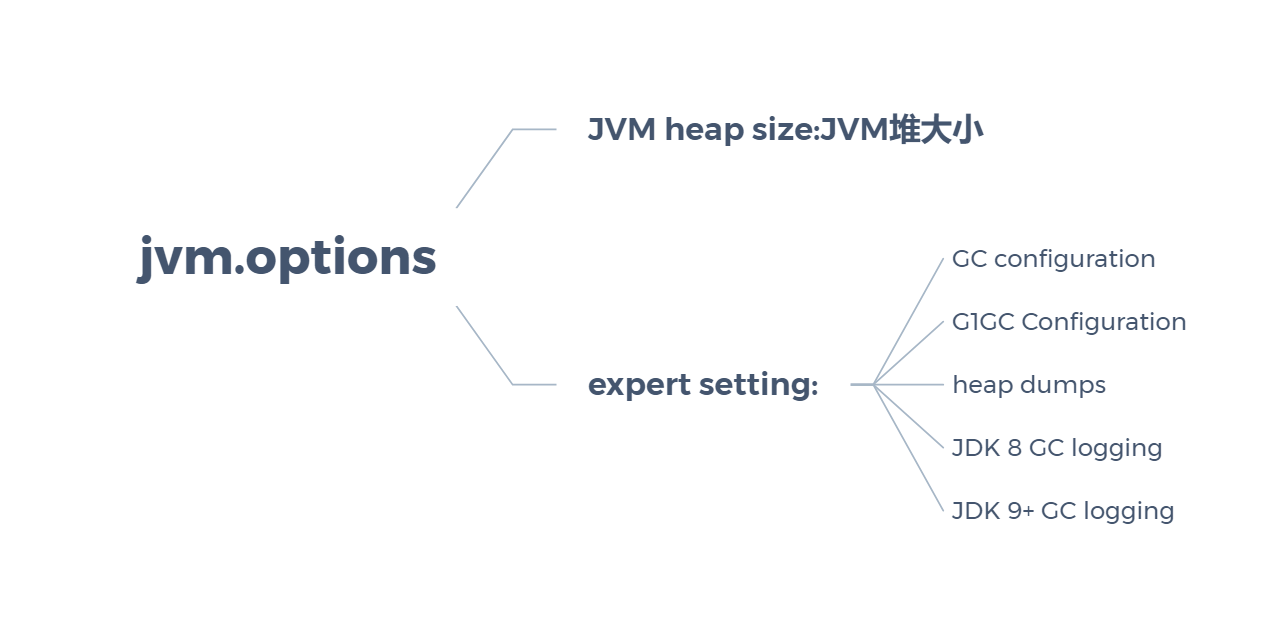
expert setting:
| GC configuration | GC配置 | GC全称:Garbage collector,垃圾收集器 |
|---|---|---|
| G1GC Configuration | G1GC配置 | G1GC全称:Garbage-First Garbage Collector,字面意思个人理解为优化的垃圾收集器 |
| heap dumps | 堆转储 | HeapDumps是指定时刻的Java堆栈的快照,是一种镜像文件。 |
| JDK 8 GC logging | JDK 8 GC日志记录 | jdk8垃圾回收日志 |
| JDK 9+ GC logging | JDK 9+ GC日志记录 | jdk9+垃圾回收日志 |
JVM configuration:
#
## IMPORTANT: JVM heap size
##########################################################
## You should always set the min and max JVM heap size to the same value.
## For example, to set the heap to 4 GB, set:
## -Xms4g
## -Xmx4g
##########################################################
# Xms represents the initial size of total heap space
# Xmx represents the maximum size of total heap space
-Xms500m
-Xmx500m
lines beginning with a
-are treated as a JVM option that applies independent of the version of the JVM
#
## Expert settings
##########################################################
## All settings below this section are considered expert settings.
## Don’t tamper with them unless you understand what you are doing
## GC configuration
8-13:-XX:+UseConcMarkSweepGC
设置年老代为并发收集
8-13:-XX:CMSInitiatingOccupancyFraction=75
触发cms gc的老年代占用率,那么在老年代占用率达到75%时触发cms gc。 cms(并发)收集器
8-13:-XX:+UseCMSInitiatingOccupancyOnly
设置检测到老年代内存占用率达到75%时触发垃圾收集。
lines beginning with a number followed by a
-followed by a number followed by a:are treated as a JVM option that applies only if the version of the JVM falls in the range of the two numbers
## G1GC Configuration
NOTE: G1GC is only supported on JDK version 10 or later
# to use G1GC, uncomment the next two lines and update the version on the following three lines to your version of the JDK
# 10-13:-XX:-UseConcMarkSweepGC
设置老年代为并发收集
10-13:-XX:-UseCMSInitiatingOccupancyOnly
设置检测到年老代内存占用达到75%时触发垃圾收集
14-:-XX:+UseG1GC
G1(并发)收集器 使用G1做为GC收集器
14-:-XX:G1ReservePercent=25
G1为分配担保预留的空间比例为25%
lines beginning with a number followed by a
-followed by a:are treated as a JVM option that applies only if the version of the JVM is greater than or equal to the number
-Djava.io.tmpdir=${ES_TMPDIR}
自定义一个用于 io操作的临时目录,默认为ES下的tmp目录 -D表示自定义的意思,是defintion缩写 io 是 in / out ,指用于输入输出 tmp,表示临时,是temp的缩写 dir,表示目录 是directory的缩写
## heap dumps
generate a heap dump when an allocation from the Java heap fails heap dumps are created in the working directory of the JVM
-XX:+HeapDumpOnOutOfMemoryError
配置这项参数可以让JVM在遇到OutOfMemoryError时生成Dump文件 该命令通常用来分析内存泄漏OOM
specify an alternative path for heap dumps; ensure the directory exists and has sufficient space
-XX:HeapDumpPath=data
指定发生内存泄漏导出堆信息时的路径或文件名
specify an alternative path for JVM fatal error logs
-XX:ErrorFile=logs/hs_err_pid%p.log
当jvm出现致命错误时,生成一个错误文档 hs_err_pid.log,其中包含了jvm crash的重要信息 可以通过分析该文件定位到导致crash的根源,从而改善以保证系统稳定。 该文件包含如下几类关键信息:
- 日志头文件
- 导致crash的线程信息
- 所有线程信息
- 安全点和锁信息
- 堆信息
- 本地代码缓存
- 编译事件
- gc相关记录
- jvm内存映射
- jvm启动参数
- 服务器信息
## JDK 8 GC logging
8:-XX:+PrintGCDetails
打印GC详细日志信息
8:-XX:+PrintGCDateStamps
打印CG发生的时间戳(以基准时间的形式)
8:-XX:+PrintTenuringDistribution
JVM 在每次新生代GC时,打印出幸存区中对象的年龄分布。
8:-XX:+PrintGCApplicationStoppedTime
显示应用程序在安全点停止的时间.大多数情况下,安全点是由垃圾收集的世界各个阶段引起的
8:-Xloggc:logs/gc.log
日志文件的输出路径
8:-XX:+UseGCLogFileRotation
日志循环。 使用该项设定时建议给GC的文件后添加时间戳 例:
-XX:+PrintGCDetails-XX:+PrintGCDateStamps-Xloggc:/home/GCEASY/gc-%t.log
8:-XX:NumberOfGCLogFiles=32
设置滚动日志文件的个数,必须大于1 日志文件命名策略是,
.0, .1, …, .n-1,其中n是该参数的值
8:-XX:GCLogFileSize=64m
The size of the log file at which point the log will be rotated, must be >= 8K. 设置滚动日志文件的大小,必须大于8k 当前写日志文件大小超过该参数值时,日志将写入下一个文件
lines beginning with a number followed by a
:followed by a-are treated as a JVM option that applies only if the version of the JVM matches the number
# JDK 9+ GC logging
9-:-Xlog:gc*,gc+age=trace,safepoint:file=logs/gc.log:utctime,pid,tags:filecount=32,filesize=64m
-Xlog:gc*:表示包含 gc 标签的所有日志 gc+age=trace ||Enables printing of tenuring age information > 启用打印保有权年龄信息。|| safepoint:file=logs/gc.log:utctime 设置安全日志存储位置为/logs/gc.log pid,tags:filecount=32 设置当日志存储数量达到32个时阻塞端口 filesize=64m 设置每个存储日志文件的大小为64m
四 log4j2.properties
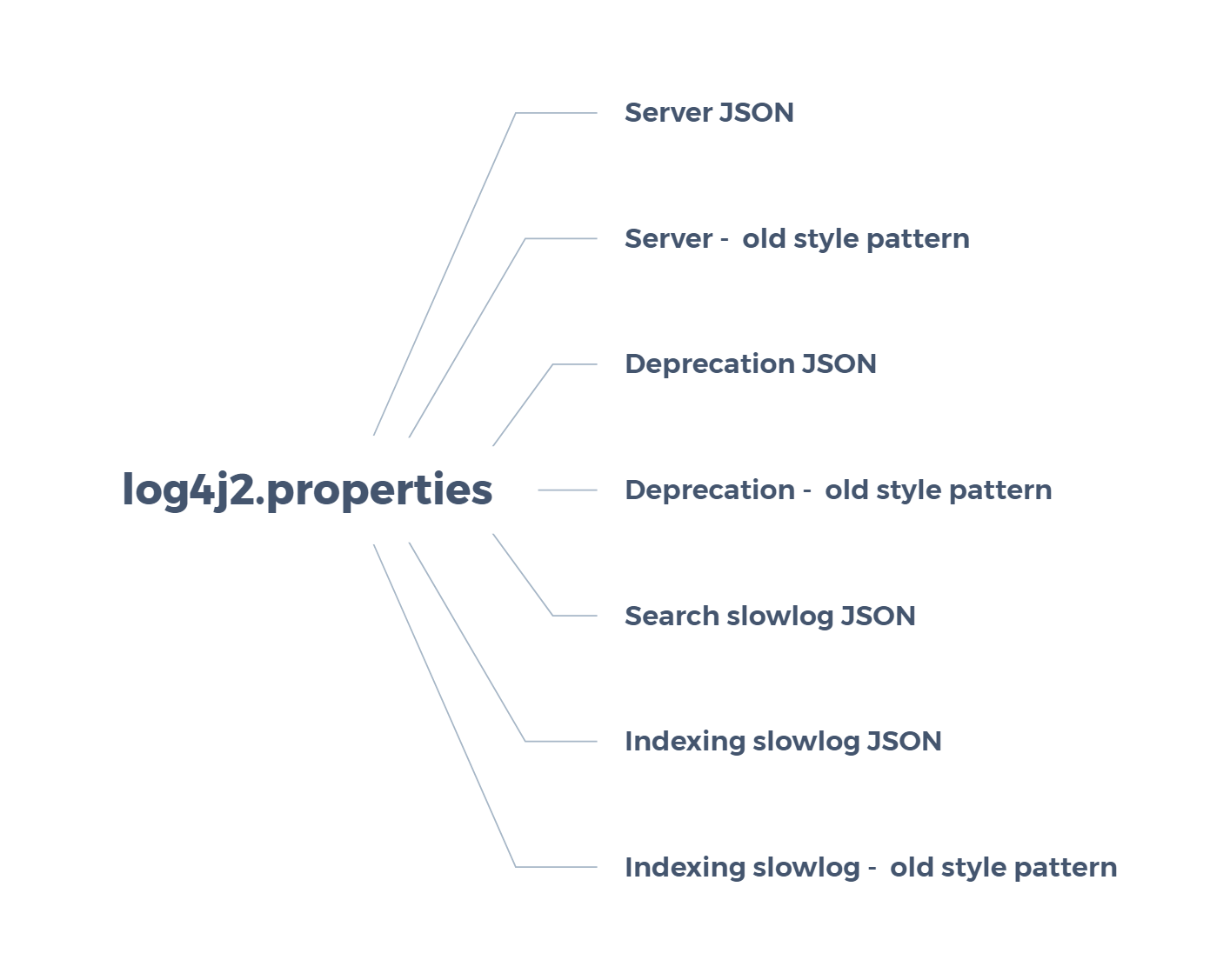
log4j2.properties |
||
|---|---|---|
| 1 | Server JSON | 服务器-JSON |
| 2 | Server - old style pattern | 服务器-旧样式模式 |
| 3 | Deprecation JSON | 弃用JSON |
| 4 | Deprecation - old style pattern | 弃用-旧样式模式 |
| 5 | Search slowlog JSON | 搜索慢日志JSON |
| 6 | Indexing slowlog - old style pattern | 旧样式模式的配置 |
| 7 | Indexing slowlog JSON | 索引慢日志JSON |
status = error
状态码为错误
appender.console.type = Console
输出源的名称
appender.console.name = console
输出布局类型
appender.console.layout.type = PatternLayout
输出模板
appender.console.layout.pattern = [%d{ISO8601}][%-5p][%-25c{1.}] [%node_name]%marker %m%n
######## Server JSON
appender.rolling.type = RollingFile
配置RollingFile追加器
appender.rolling.name = rolling
appender.rolling.fileName = ${sys:es.logs.base_path}${sys:file.separator}${sys:es.logs.cluster_name}_server.json
指定当前日志文件的位置和文件名称,可以单独指定
appender.rolling.layout.type = ESJsonLayout
使用JSON的布局
appender.rolling.layout.type_name = server
type_name是在ESJsonLayout中填充type字段的标志。在解析不同类型的日志时,可以使用它更容易地区分它们。
appender.rolling.filePattern = ${sys:es.logs.base_path}${sys:file.separator}${sys:es.logs.cluster_name}-%d{yyyy-MM-dd}-%i.json.gz
将日志滚到/var/log/elasticsearch/production-yyyy-MM-dd-i.json;日志将在每个卷上被压缩,将增加
appender.rolling.policies.type = Policies
appender.rolling.policies.time.type = TimeBasedTriggeringPolicy
使用基于时间的滚动策略
appender.rolling.policies.time.interval = 1
每天滚动日志
appender.rolling.policies.time.modulate = true
在一天的边界上对齐滚动(而不是每24小时滚动一次)
appender.rolling.policies.size.type = SizeBasedTriggeringPolicy
使用基于大小的滚动策略
appender.rolling.policies.size.size = 128MB
在128 MB之后滚动日志
appender.rolling.strategy.type = DefaultRolloverStrategy
文件封存的覆盖策略(RolloverStrategy)
appender.rolling.strategy.fileIndex = nomax
appender.rolling.strategy.action.type = Delete
在滚动日志时使用delete操作
appender.rolling.strategy.action.basepath = ${sys:es.logs.base_path}
Elasticsearch日志的基本路径
appender.rolling.strategy.action.condition.type = IfFileName
只删除与文件模式匹配的日志
appender.rolling.strategy.action.condition.glob = ${sys:es.logs.cluster_name}-*
该模式是只删除主日志
appender.rolling.strategy.action.condition.nested_condition.type = IfAccumulatedFileSize
只有当我们积累了太多的压缩日志时才删除,用于匹配glob的文件的嵌套条件
appender.rolling.strategy.action.condition.nested_condition.exceeds = 2GB
压缩日志的大小条件是2 GB
#
######## Server - old style pattern
appender.rolling_old.type = RollingFile
appender.rolling_old.name = rolling_old
appender.rolling_old.fileName = ${sys:es.logs.base_path}${sys:file.separator}${sys:es.logs.cluster_name}.log
旧样式模式的配置。这些日志将保存在.log文件中,存档保存在.log .gz文件中。请注意,这些应该被认为是不赞成的,并将在未来删除。
appender.rolling_old.layout.type = PatternLayout
appender.rolling_old.layout.pattern = [%d{ISO8601}][%-5p][%-25c{1.}] [%node_name]%marker %m%n
appender.rolling_old.filePattern = ${sys:es.logs.base_path}${sys:file.separator}${sys:es.logs.cluster_name}-%d{yyyy-MM-dd}-%i.log.gz
appender.rolling_old.policies.type = Policies
appender.rolling_old.policies.time.type = TimeBasedTriggeringPolicy
appender.rolling_old.policies.time.interval = 1
appender.rolling_old.policies.time.modulate = true
appender.rolling_old.policies.size.type = SizeBasedTriggeringPolicy
appender.rolling_old.policies.size.size = 128MB
appender.rolling_old.strategy.type = DefaultRolloverStrategy
appender.rolling_old.strategy.fileIndex = nomax
appender.rolling_old.strategy.action.type = Delete
appender.rolling_old.strategy.action.basepath = ${sys:es.logs.base_path}
appender.rolling_old.strategy.action.condition.type = IfFileName
appender.rolling_old.strategy.action.condition.glob = ${sys:es.logs.cluster_name}-*
appender.rolling_old.strategy.action.condition.nested_condition.type = IfAccumulatedFileSize
appender.rolling_old.strategy.action.condition.nested_condition.exceeds = 2GB
################################################
rootLogger.level = info
rootLogger.appenderRef.console.ref = console
rootLogger.appenderRef.rolling.ref = rolling
rootLogger.appenderRef.rolling_old.ref = rolling_old
######## Deprecation JSON
appender.deprecation_rolling.type = RollingFile
appender.deprecation_rolling.name = deprecation_rolling
appender.deprecation_rolling.fileName = ${sys:es.logs.base_path}${sys:file.separator}${sys:es.logs.cluster_name}_deprecation.json
appender.deprecation_rolling.layout.type = ESJsonLayout
appender.deprecation_rolling.layout.type_name = deprecation
appender.deprecation_rolling.layout.esmessagefields=x-opaque-id
appender.deprecation_rolling.filter.rate_limit.type = RateLimitingFilter
appender.deprecation_rolling.filePattern = ${sys:es.logs.base_path}${sys:file.separator}${sys:es.logs.cluster_name}_deprecation-%i.json.gz
appender.deprecation_rolling.policies.type = Policies
appender.deprecation_rolling.policies.size.type = SizeBasedTriggeringPolicy
appender.deprecation_rolling.policies.size.size = 1GB
appender.deprecation_rolling.strategy.type = DefaultRolloverStrategy
appender.deprecation_rolling.strategy.max = 4
appender.header_warning.type = HeaderWarningAppender
appender.header_warning.name = header_warning
#################################################
######## Deprecation - old style pattern
appender.deprecation_rolling_old.type = RollingFile
appender.deprecation_rolling_old.name = deprecation_rolling_old
appender.deprecation_rolling_old.fileName = ${sys:es.logs.base_path}${sys:file.separator}${sys:es.logs.cluster_name}_deprecation.log
appender.deprecation_rolling_old.layout.type = PatternLayout
appender.deprecation_rolling_old.layout.pattern = [%d{ISO8601}][%-5p][%-25c{1.}] [%node_name]%marker %m%n
appender.deprecation_rolling_old.filePattern = ${sys:es.logs.base_path}${sys:file.separator}${sys:es.logs.cluster_name}\
_deprecation-%i.log.gz
appender.deprecation_rolling_old.policies.type = Policies
appender.deprecation_rolling_old.policies.size.type = SizeBasedTriggeringPolicy
appender.deprecation_rolling_old.policies.size.size = 1GB
appender.deprecation_rolling_old.strategy.type = DefaultRolloverStrategy
appender.deprecation_rolling_old.strategy.max = 4
#################################################
logger.deprecation.name = org.elasticsearch.deprecation
#logger.deprecation.level = deprecation
logger.deprecation.level = false
logger.deprecation.appenderRef.deprecation_rolling.ref = deprecation_rolling
logger.deprecation.appenderRef.deprecation_rolling_old.ref = deprecation_rolling_old
logger.deprecation.appenderRef.header_warning.ref = header_warning
logger.deprecation.additivity = false
######## Search slowlog JSON
appender.index_search_slowlog_rolling.type = RollingFile
appender.index_search_slowlog_rolling.name = index_search_slowlog_rolling
appender.index_search_slowlog_rolling.fileName = ${sys:es.logs.base_path}${sys:file.separator}${sys:es.logs\
.cluster_name}_index_search_slowlog.json
appender.index_search_slowlog_rolling.layout.type = ESJsonLayout
appender.index_search_slowlog_rolling.layout.type_name = index_search_slowlog
appender.index_search_slowlog_rolling.layout.esmessagefields=message,took,took_millis,total_hits,types,stats,search_type,total_shards,source,id
appender.index_search_slowlog_rolling.filePattern = ${sys:es.logs.base_path}${sys:file.separator}${sys:es.logs\
.cluster_name}_index_search_slowlog-%i.json.gz
appender.index_search_slowlog_rolling.policies.type = Policies
appender.index_search_slowlog_rolling.policies.size.type = SizeBasedTriggeringPolicy
appender.index_search_slowlog_rolling.policies.size.size = 1GB
appender.index_search_slowlog_rolling.strategy.type = DefaultRolloverStrategy
appender.index_search_slowlog_rolling.strategy.max = 4
#################################################
######## Search slowlog - old style pattern ####
appender.index_search_slowlog_rolling_old.type = RollingFile
appender.index_search_slowlog_rolling_old.name = index_search_slowlog_rolling_old
appender.index_search_slowlog_rolling_old.fileName = ${sys:es.logs.base_path}${sys:file.separator}${sys:es.logs.cluster_name}\
_index_search_slowlog.log
appender.index_search_slowlog_rolling_old.layout.type = PatternLayout
appender.index_search_slowlog_rolling_old.layout.pattern = [%d{ISO8601}][%-5p][%-25c{1.}] [%node_name]%marker %m%n
appender.index_search_slowlog_rolling_old.filePattern = ${sys:es.logs.base_path}${sys:file.separator}${sys:es.logs.cluster_name}\
_index_search_slowlog-%i.log.gz
appender.index_search_slowlog_rolling_old.policies.type = Policies
appender.index_search_slowlog_rolling_old.policies.size.type = SizeBasedTriggeringPolicy
appender.index_search_slowlog_rolling_old.policies.size.size = 1GB
appender.index_search_slowlog_rolling_old.strategy.type = DefaultRolloverStrategy
appender.index_search_slowlog_rolling_old.strategy.max = 4
#################################################
logger.index_search_slowlog_rolling.name = index.search.slowlog
logger.index_search_slowlog_rolling.level = trace
logger.index_search_slowlog_rolling.appenderRef.index_search_slowlog_rolling.ref = index_search_slowlog_rolling
logger.index_search_slowlog_rolling.appenderRef.index_search_slowlog_rolling_old.ref = index_search_slowlog_rolling_old
logger.index_search_slowlog_rolling.additivity = false
######## Indexing slowlog JSON
appender.index_indexing_slowlog_rolling.type = RollingFile
appender.index_indexing_slowlog_rolling.name = index_indexing_slowlog_rolling
appender.index_indexing_slowlog_rolling.fileName = ${sys:es.logs.base_path}${sys:file.separator}${sys:es.logs.cluster_name}\
_index_indexing_slowlog.json
appender.index_indexing_slowlog_rolling.layout.type = ESJsonLayout
appender.index_indexing_slowlog_rolling.layout.type_name = index_indexing_slowlog
appender.index_indexing_slowlog_rolling.layout.esmessagefields=message,took,took_millis,doc_type,id,routing,source
appender.index_indexing_slowlog_rolling.filePattern = ${sys:es.logs.base_path}${sys:file.separator}${sys:es.logs.cluster_name}\
_index_indexing_slowlog-%i.json.gz
appender.index_indexing_slowlog_rolling.policies.type = Policies
appender.index_indexing_slowlog_rolling.policies.size.type = SizeBasedTriggeringPolicy
appender.index_indexing_slowlog_rolling.policies.size.size = 1GB
appender.index_indexing_slowlog_rolling.strategy.type = DefaultRolloverStrategy
appender.index_indexing_slowlog_rolling.strategy.max = 4
#################################################
######## Indexing slowlog - old style pattern
appender.index_indexing_slowlog_rolling_old.type = RollingFile
appender.index_indexing_slowlog_rolling_old.name = index_indexing_slowlog_rolling_old
appender.index_indexing_slowlog_rolling_old.fileName = ${sys:es.logs.base_path}${sys:file.separator}${sys:es.logs.cluster_name}\
_index_indexing_slowlog.log
appender.index_indexing_slowlog_rolling_old.layout.type = PatternLayout
appender.index_indexing_slowlog_rolling_old.layout.pattern = [%d{ISO8601}][%-5p][%-25c{1.}] [%node_name]%marker %m%n
appender.index_indexing_slowlog_rolling_old.filePattern = ${sys:es.logs.base_path}${sys:file.separator}${sys:es.logs.cluster_name}\
_index_indexing_slowlog-%i.log.gz
appender.index_indexing_slowlog_rolling_old.policies.type = Policies
appender.index_indexing_slowlog_rolling_old.policies.size.type = SizeBasedTriggeringPolicy
appender.index_indexing_slowlog_rolling_old.policies.size.size = 1GB
appender.index_indexing_slowlog_rolling_old.strategy.type = DefaultRolloverStrategy
appender.index_indexing_slowlog_rolling_old.strategy.max = 4
#################################################
logger.index_indexing_slowlog.name = index.indexing.slowlog.index
logger.index_indexing_slowlog.level = trace
logger.index_indexing_slowlog.appenderRef.index_indexing_slowlog_rolling.ref = index_indexing_slowlog_rolling
logger.index_indexing_slowlog.appenderRef.index_indexing_slowlog_rolling_old.ref = index_indexing_slowlog_rolling_old
logger.index_indexing_slowlog.additivity = false

若有收获,就点个赞吧
0 人点赞
