按:
本文详细介绍了Node的运行机制,尤其是事件循环EventLoop
| 《新时期的Node.js入门》 | |||
|---|---|---|---|
| 作者 | 李锴 | 出版社 | 清华大学出版社 |
| ISBN | 9787302487807 | 出版时间 | 2018.1 |
| 豆瓣网址 | https://book.douban.com/subject/30170564/ | 是否有电子版 | 微信读书 |
| 阅读日期 | 2020-6-25 | 更新日期 | 2020-6-30 |
| 相关链接 | 备注 | github |
如果你想读这本书,使用微信扫码即可:

全书结构如下:
 本部分内容来自书中第一章,这一章主讲内部机制,说的很好,单独摘出来。
本部分内容来自书中第一章,这一章主讲内部机制,说的很好,单独摘出来。
围绕Node基础可讨论的话题
0 Node.js 的不擅长什么
js单线程,不用在意状态的同步问题,没有死锁。
都说Node.js 不擅长cpu密集服务,怎么解释?
单线程,如果有长时间运行的计算,会让cpu时间片不能释放,不能处理后续,可以适当调整和分解,就能让运算适时释放。 js的一个弱点是位运算,java有int,但js只有double
回答的核心,单线程计算不行,需要及时调整和分解。
如果是纯计算场景,应该采取多线程方式进行计算,可以私用node的c c++拓展,可以比java还快。
也可以使用子进程,把一部分node进程常驻,进程传递信息。
1 Node.js的内部机制
单线程运行的语言,在设计时候要考虑,如果有耗时操作,比如磁盘IO,要不要等待操作完成再执行下一步操作。
有的选择了等待,Node选了异步,遇到IO操作,发起一个调用,继续向下执行,等到操作完成再执行相应的回调函数。
虽然是单线程,但依靠异步+回调,实现了高并发的支持。
2 同步 VS 异步 阻塞 VS 非阻塞
同步和异步是描述的进程、线程的调用方式。
同步,好理解,是指调用之后等待返回才继续执行。
异步,调用之后继续向下执行,等到调用返回后,通过某种手段通知调用者。
(注:我们常说JS是一门异步语言,但es规范并没有异步的规范,是浏览器的支持让js看起来像异步语言。)
操作系统内核对 I/O 只有阻塞和非阻塞。阻塞和非阻塞是针对IO状态而言的:程序在 发出IO请求 —> IO返回结果 ,这个过程中的状态,是停止工作还是继续工作。
Node.js uses an event-driven , non-blocking I/O model that makes it lightweight and efficient.
关键词: 事件驱动 和 非阻塞IO 。
刚才提到了异步和非阻塞的概念,但这里不提异步,这里和异步没有必然关系。
为了处理IO,Linux下有多种编程模型:
- 同步+阻塞IO,进程会等待 准备数据和返回结果两个阶段完成,拿到结果继续运行。显然浪费性能。
- 同步+非阻塞IO。如果数据没有就绪,会返回结果告诉进程没准备好,进程会不断 轮询 状态,过程依旧是同步的。
- 同步+事件驱动IO,同样是轮询方式查询执行状态,和上一个区别是,一个进程可能管理多个IO请求,当某个IO有结果,返回对应结果
- 异步。 真正的异步 Asynchornonous I/O 也称AIO。和前面相比,进程发出调用后,系统立刻返回结果,进程继续做其他事情。有了结果会通知进程,给用户进程发送一个信号。
- 忽略一种 signal deiven I/O 不常用。
回到刚才的话题,Node 能写出异步代码,为什么还说自己是非阻塞IO,不加异步两个字呢?因为在底层实现中,异步的实现是依靠 Libuv 模拟出来的。
3 单线程 多线程
比如Java可以使用多个线程协同工作。Node里没有对多线程的支持,只能运行到当前线程中,但可以派生多个进程来达到并行开发的目的。
Node的底层实现不是单线程,libuv 通过类似线程池的实现来模拟兼容不同操作系统的异步调用,黑盒。
4 libuv
刚才提到node的用户代码是单线程,但node底层通过libuv是有线程池概念的。
node提供 libuv 作为抽象层,跨平台地实现了异步I/O。Libuv 是一个跨平台的异步IO库。专门给node兼容多平台异步IO支持的。忽略一些技术架构细节,总之在不同操作系统下,libuv的技术实现不同,这是一个黑盒功能。
5 并行parallel 并发concurrent
单线程要实现高并发,通常是依靠异步+事件驱动循环来实现的,异步让多个请求不会阻塞,事件循环提供IO调用结束调用callback的能力。
Java依靠多线程实现并发,Node依靠异步+时间驱动实现并发。
6 事件循环Event Loop
用户会产生事件,有同步和异步。
背后的循环一般情况下无需考虑。浏览器中的js会产生事件循环,比如同步 > 异步(微任务 > 宏任务)
阶段
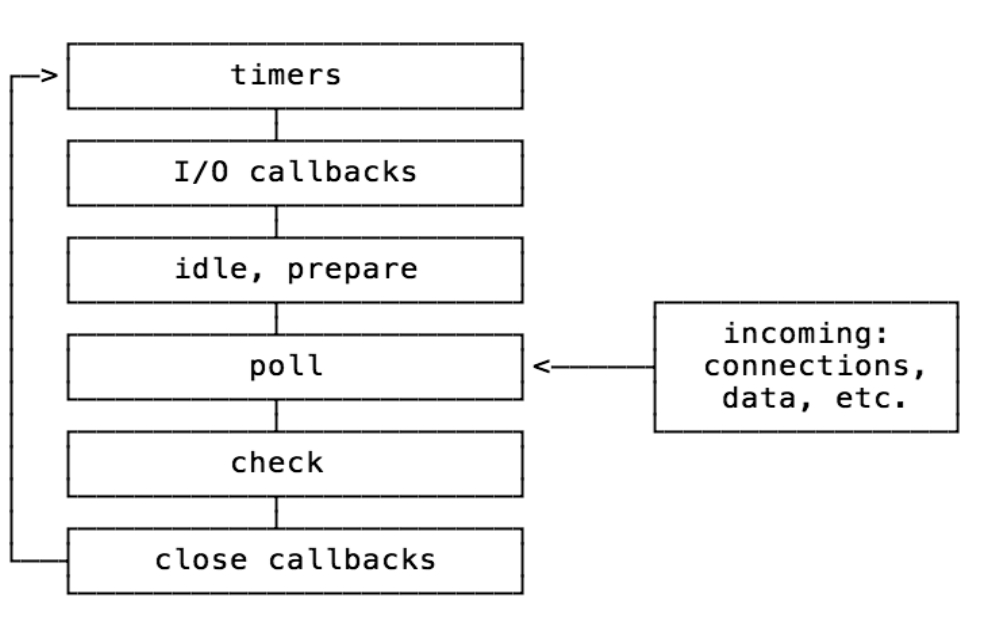
Node中的eventLoop 和浏览器略有不同:
简单说:
- timers 定时器,setTimeout setInterval
- IO 回调。“大多数”的回调方法,不用管
- idle, prepare 黑盒,内部使用,不用管
- poll 轮询,检查是否有新的IO事件,可能会阻塞到这里
- check,处理setImmediate
- close callbackss 处理close相关的事件
有六个阶段,每个阶段都维护一个回调函数的队列。先放入后执行。
单独解释每个阶段
timers
处理定时器的回调,定时器 超时之后 会把事件加入队列中。
由于是触发超时后尽可能早(as early as they can)调用,实际中的超时会比规定的时间长:如果正在处理一个耗时长的callback ,定时器智能等到当前回调结束了才能执行,会被阻塞。(timers的执行收到poll的控制)
IO callbacks
除了 timers, setImmediate, 和 close,其他的“大多数”回调都在这里执行。比如 fs.readFile 的回调是在poll阶段执行。
poll
等待新的事件出现。如果没有,事件循环可能会在此阻塞,具体细节可以参考 libuv的源码 src/unix/core.c 的 uv_run 方法
Poll做两件事:
- 如果有到期的定时器,就执行定时器的回调
- 处理poll阶段的事件队列中的事件
如果同时存在
setTimeout(()=>{},0)setImmediate()
目前不一定执行到哪了,随机执行。
伪代码:
stage is poll:if(poll 队列 === 空){if(代码中有setImmediate){go to check 去下一个阶段 执行setImmediate}else{事件循环等待,等待新的事件出现。这就是poll轮询的原因如有有定时器,就调到timers}}else{event loop 事件循环按顺序执行回调函数}
总结:
- 当前有任务就执行任务
- 如果没任务就进行下一项
check
只为 setImmediate 准备。如果上一个阶段poll,发现有setImmediate ,事件循环就会跳出poll进入check
close
如果有close,处理close,处理完,本轮事件循环结束,循环到下一轮。
总结
事件队列如果是一个,就需要在一个队列里加判断,代码复杂了。
如果事件队列不止一个,每个阶段各自维护,一层层遍历即可。
书中举了一个例子来解释:

观察这段代码:
- 检查timers,当前无timers跳过
- 检查poll,当前无事件,跳过
- 检查check,无,跳过
- 事件循环开始等待。
- 95ms之后读取文件完成,产生事件,加入poll
- 事件循环开始执行poll里的第一个事件,此时callback执行,啥也没做就等了10ms
- 此时等待的10ms就是阻塞的。什么也做不了,虽然95+10>100 也不能执行timers
- readFile回调完成,poll清空,循环到timers,执行timers里的回调
时间循环运行在单线程环境中,同一时间只能处理一个事件,做不到并行。
如果存在并行,也只是在libuv中
7 process.nextTick
书中举例:
process.nextTick(()=>console.log(1))console.log(2)// 2 1
process.nextTick 不是事件循环的一部分,回调方法是由事件循环调用的,调用方法会进入 nextTickQueue 队列中。
注意: 在事件循环的任何阶段,如果nextTickQueue不为空,都会在当前阶段结束后执行里面的回调,执行完才会进行下一个阶段。
有最大限制,不能无限递归。
总结:事件循环的每个阶段都有 nextTickQueue,如果不为空,执行完才会切换到下一阶段。
8 setImmediate
setImmediate 不是es标准,是node提出的方法,接收一个callback加入到时间队列中。
setImmediate和nextTick不同,后者总会早于前者,这和之前提到的阶段有关。
如果有递归的异步操作,只能使用 setImmediate,因为递归调用nextTick可能会超出队列最大限制。
和 setTimeout 相比。poll之后是check阶段, 由于无法预测执行代码时候出在哪个阶段 ,因此当两者同时存在,执行顺序并不固定。
但如果都在一个IO操作中,也就是poll中,check 会早于timers
注意:
setTimeout(()=>{})

若有收获,就点个赞吧
0 人点赞
