原文:https://developers.google.com/web/updates/2018/09/inside-browser-part2
根据第一篇文章了解到,选项卡外的所有内容都由浏览器进程处理。浏览器 process 具有以下一些 thread。比如 负责绘制浏览器的按钮和输入字段 UI thread,负责从互联网接收并处理数据的网络堆栈的网络 thread ,控制对文件的访问的存储 thread 等。当在地址栏中键入URL时,您的输入内容将由浏览器 process 的UI thread 处理。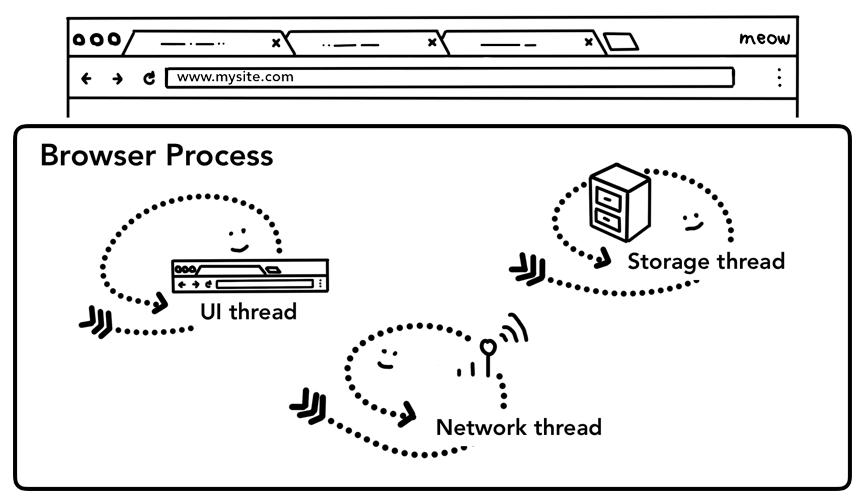
处理输入
当用户开始输入地址栏时,UI thread 首先问下自己“这是搜索查询还是URL?”。在 Chrome 中,地址栏也是可以直接调用搜索引擎进行搜索的,因此UI thread 需要解析并决定是将输入的内容发送到搜索引擎还是发送到请求的网站。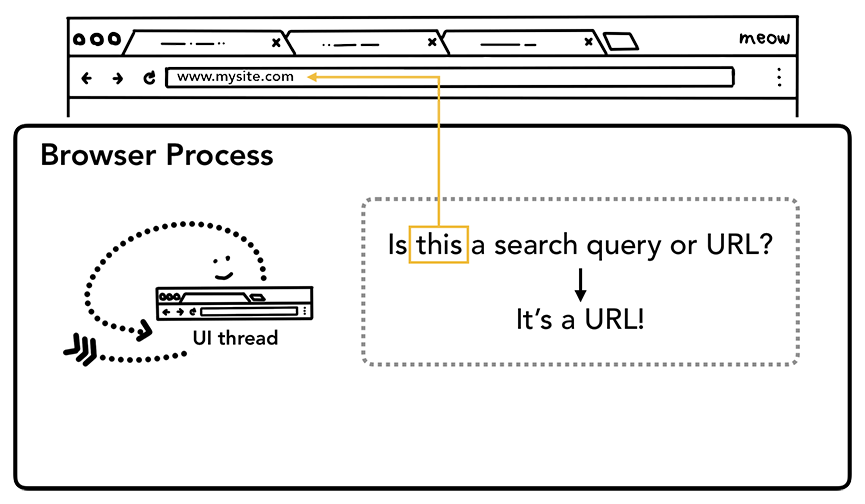
开始请求
当用户确认进入时,UI thread 启动网络功能获取站点内容。网页加载的进度条(loading)显示在选项卡上,网络 thread 通过适当的协议,比如 DNS 查找,为本次请求建立 TLS 连接。
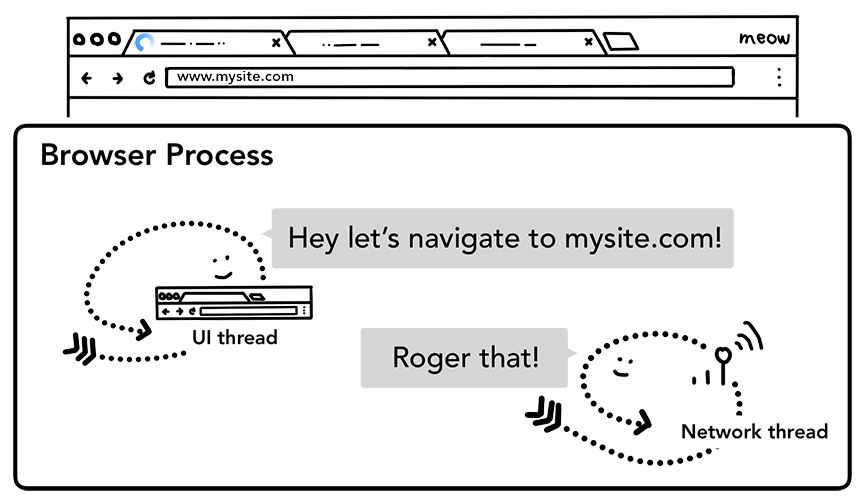
此时,网络 thread 可能会接收 HTTP 301 重定向头。此时,网络 thread 告知 UI thread 服务器请求需要重定向。然后,UI thread 将启动另一个URL请求。整个网络请求的过程比较复杂,这里先省略。
解析响应
一旦 response 的 body开始获取,网络 thread 会在必要时查看 stream 的前几个字节。response 的 Content-Type header 标示它应该是什么类型的数据。但是它可能丢失或设置错误, 所以需要在此时完成 MIME 类型嗅探。这是一件“棘手的任务” 。您可以查看源代码中的评论,以了解不同的浏览器如何处理 content-type。
https://cs.chromium.org/chromium/src/net/base/mime_sniffer.cc?sq=package:chromium&dr=CS&l=5
截取关键的注释如下:
// Detecting mime types is a tricky business because we need to balance// compatibility concerns with security issues. Here is a survey of how other// browsers behave and then a description of how we intend to behave.//// HTML payload, no Content-Type header:// * IE 7: Render as HTML// * Firefox 2: Render as HTML// * Safari 3: Render as HTML// * Opera 9: Render as HTML//// Here the choice seems clear:// => Chrome: Render as HTML//// HTML payload, Content-Type: "text/plain":// * IE 7: Render as HTML// * Firefox 2: Render as text// * Safari 3: Render as text (Note: Safari will Render as HTML if the URL// has an HTML extension)// * Opera 9: Render as text//// Here we choose to follow the majority (and break some compatibility with IE).// Many folks dislike IE's behavior here.// => Chrome: Render as text// We generalize this as follows. If the Content-Type header is text/plain// we won't detect dangerous mime types (those that can execute script).//// HTML payload, Content-Type: "application/octet-stream":// * IE 7: Render as HTML// * Firefox 2: Download as application/octet-stream// * Safari 3: Render as HTML// * Opera 9: Render as HTML//// We follow Firefox.// => Chrome: Download as application/octet-stream// One factor in this decision is that IIS 4 and 5 will send// application/octet-stream for .xhtml files (because they don't recognize// the extension). We did some experiments and it looks like this doesn't occur// very often on the web. We choose the more secure option.//// GIF payload, no Content-Type header:// * IE 7: Render as GIF// * Firefox 2: Render as GIF// * Safari 3: Download as Unknown (Note: Safari will Render as GIF if the// URL has an GIF extension)// * Opera 9: Render as GIF//// The choice is clear.// => Chrome: Render as GIF// Once we decide to render HTML without a Content-Type header, there isn't much// reason not to render GIFs.//// GIF payload, Content-Type: "text/plain":// * IE 7: Render as GIF// * Firefox 2: Download as application/octet-stream (Note: Firefox will// Download as GIF if the URL has an GIF extension)// * Safari 3: Download as Unknown (Note: Safari will Render as GIF if the// URL has an GIF extension)// * Opera 9: Render as GIF//// Displaying as text/plain makes little sense as the content will look like// gibberish. Here, we could change our minds and download.// => Chrome: Render as GIF//// GIF payload, Content-Type: "application/octet-stream":// * IE 7: Render as GIF// * Firefox 2: Download as application/octet-stream (Note: Firefox will// Download as GIF if the URL has an GIF extension)// * Safari 3: Download as Unknown (Note: Safari will Render as GIF if the// URL has an GIF extension)// * Opera 9: Render as GIF//// We used to render as GIF here, but the problem is that some sites want to// trigger downloads by sending application/octet-stream (even though they// should be sending Content-Disposition: attachment). Although it is safe// to render as GIF from a security perspective, we actually get better// compatibility if we don't sniff from application/octet stream at all.// => Chrome: Download as application/octet-stream//// Note that our definition of HTML payload is much stricter than IE's// definition and roughly the same as Firefox's definition.
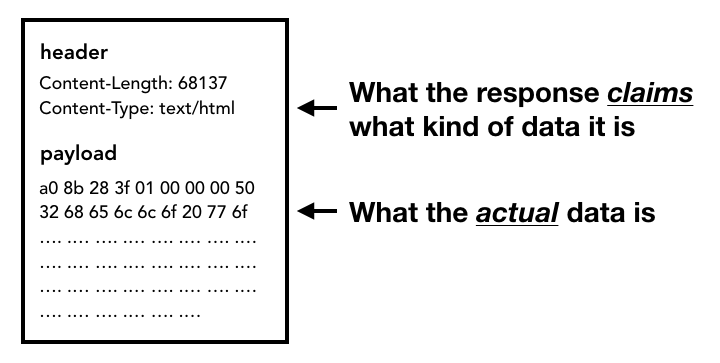
如果 response 是 HTML 文件,那么下一步就是将数据传递给渲染 process 。但如果是zip文件或其他文件,则表示它是下载请求,因此需要将数据传递给下载管理器。
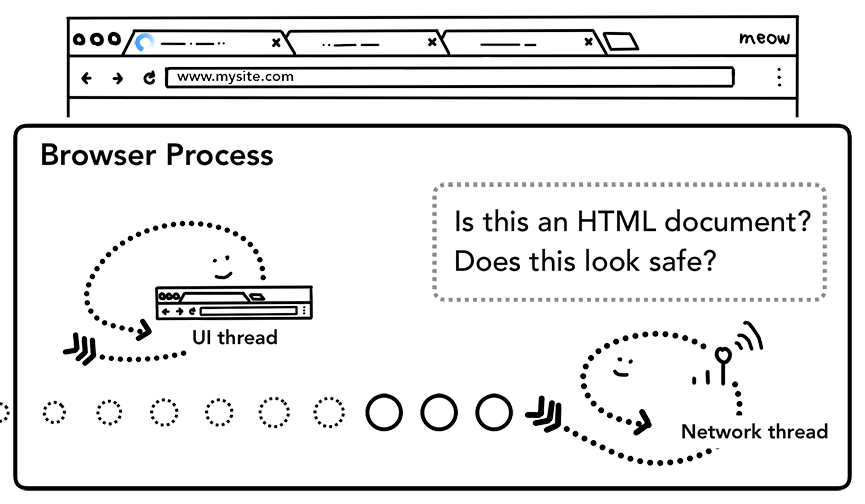
这里也会进行 SafeBrowsing (https://safebrowsing.google.com/)检查。如果域和响应数据可能与已知的恶意站点匹配,则网络 thread 会发出警告以显示警告页面。此外, 还会进行Cross Origin Read Blocking (CORB)检查,以确保敏感的跨站点数据无法进入渲染 process。
渲染 process
完成了所有的检查,并且网络 thread 确信浏览器应该导航到所请求的站点后,网络 thread 会告知UI thread 数据已 ok。然后UI thread 找到渲染 process 继续渲染网页。
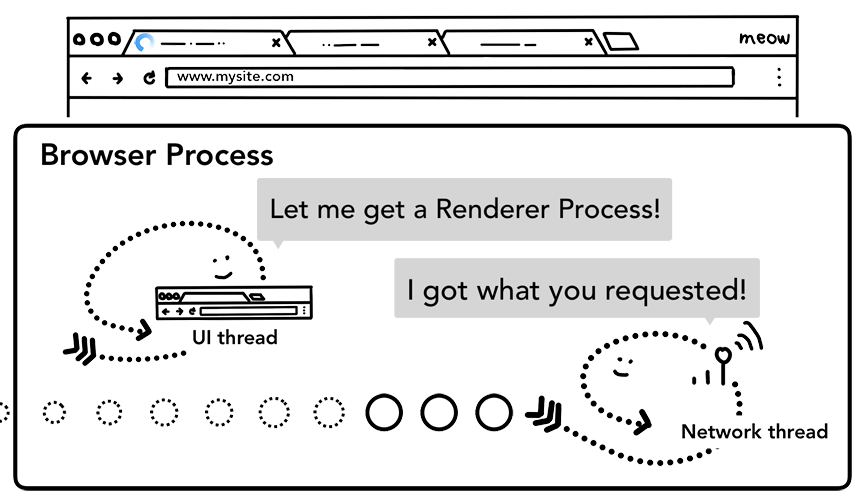
由于网络请求可能需要几百 ms 才能得到响应,因此加速了这个过程。当UI thread 向网络 thread 发送URL请求时,它已经知道正在导航到哪个站点。UI thread 尝试主动查找或启动与网络请求并行的渲染器进程。当网络 thread 接收数据时,渲染 process 已经准备好了。如果请求重定向了,则可能不会使用这个备用的渲染 process,可能此时需要另一个渲染 process。
提交
现在数据和渲染 process 已ok,IPC 将从浏览器 process 发送到渲染 process,把本次的url获取的数据提交。同时还传递数据流,所以渲染 process 可以继续接收 HTML 数据。一旦浏览器 process 确认在渲染 process 中已提交,本次url导航的过程就完成了,文档加载阶段就开始。
此时,地址栏会更新,loading状态和站点设置UI会反映新页面的站点信息。选项卡的 session 历史记录将更新,因此后退/前进按钮可以使用 window.history 的数据。为了便于在关闭选项卡或窗口时进行选项卡/会话还原,session 历史记录将存储在磁盘上。
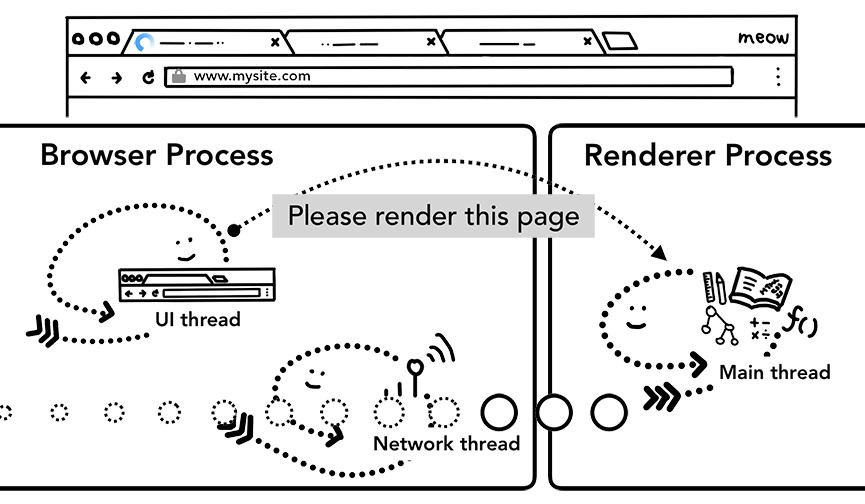
初始化加载
上一步的提交完成后,渲染 process 将继续加载资源并呈现页面。我们将在下一篇文章中详细介绍现阶段的情况。一旦渲染 process “完成”渲染,它就会将 IPC 发送回浏览器 process(这是在所有 onload 事件都在页面中的所有帧上触发并且已经完成执行之后)。此时,UI thread 会干掉选项卡上 loading 标识。
这里的“完成”只是表达本次 html 渲染已经完成 JavaScript 仍然可以加载额外的资源并在此之后呈现新的视图
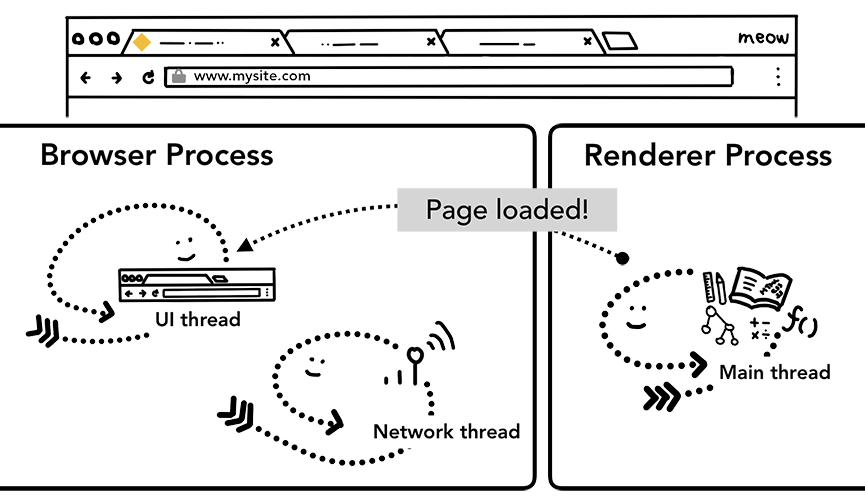
切换到其他站点
如果用户再次将不同的URL输入到地址栏会发生什么?浏览器 process 会执行相同的步骤来导航到不同的站点。但在这之前需要检查当前渲染的网站的 beforeunload 事件 。
beforeunload 可以创建一个“离开这个网站吗?”的 alert 框,当尝试导航或关闭选项卡时发出警报。包含当前选项卡内的所有内容(包括JavaScript 代码)都由渲染 process 处理,因此当新的导航请求进入时,浏览器 process 必须检查当前渲染 process。
不要滥用 beforeunload。应当只在需要时添加此事件并绑定回调函数 例如,需要警告用户他们可能会丢失他们在页面上输入的数据。
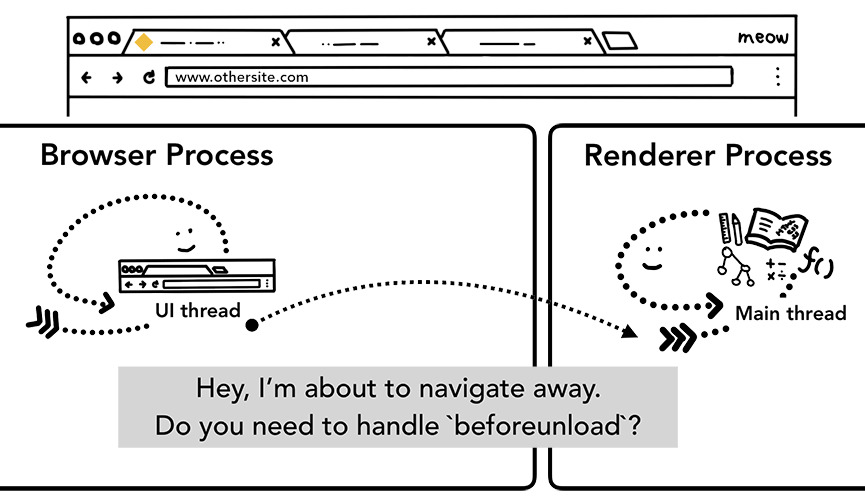
如果切换是从渲染 process 发起的(用户单击链接或客户端 JavaScript 已运行window.location = “https://newsite.com"),则渲染 process 首先检查 beforeunload 事件的回调函数。然后,它经历与浏览器 process 启动导航相同的过程。唯一的区别是这样的请求从渲染 process 启动到浏览器 process。
当新url进行到与当前渲染的不同的站点时,将调用单独的渲染 process 来处理新导航,同时保持当前渲染 process 处理诸unload等。
更多信息参见:
https://developers.google.com/web/updates/2018/07/page-lifecycle-api#overview_of_page_lifecycle_states_and_events
https://developers.google.com/web/updates/2018/07/page-lifecycle-api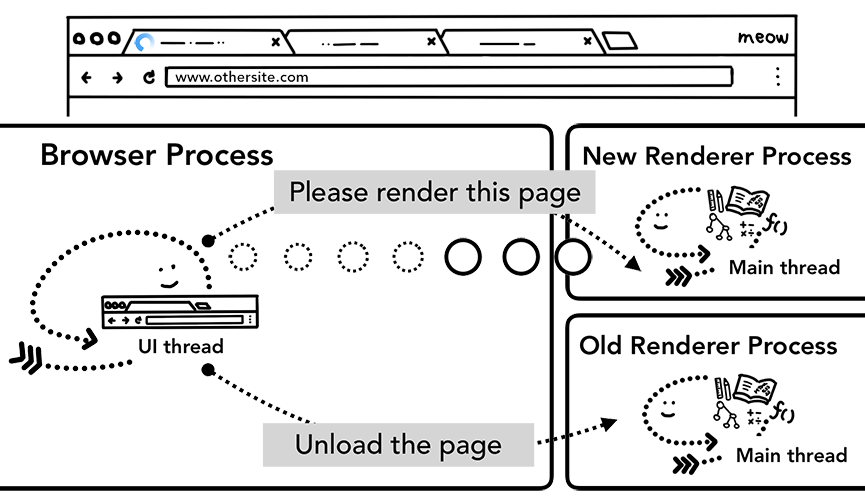
Service Worker
Service Worker: https://developers.google.com/web/fundamentals/primers/service-workers/ 如果将 service worker设置为从缓存加载页面,则无需从网络请求数据。
service worker是渲染 process 中运行的JavaScript代码。但是当导航请求进来时,浏览器 process 怎么知道该站点有木有 service worker?
注册 service worker 时,会保留 service worker 的范围,具体参见:https://developers.google.com/web/fundamentals/primers/service-workers/lifecycle。
当导航发生时,网络 thread 根据注册的 service worker 范围检查域,如果为该URL注册了 service worker,则UI thread 找到渲染 process 执行 service worker 代码。service worker 可以从缓存加载数据,无需从网络请求数据,或者可以从网络请求新资源。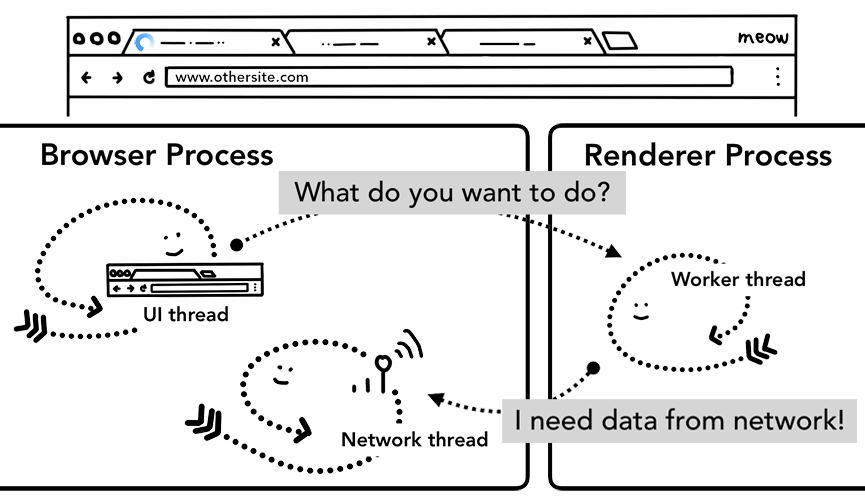
url 预加载
导航预加载:https://developers.google.com/web/updates/2017/02/navigation-preload
如果 service worker 最终决定从网络请求数据,则浏览器 process 和渲染 process 之间的往返可能会导致延迟。 url 预加载通过与 service worker 启动并行加载资源来加速此过程。它用 header 标记这些请求,允许服务器决定给这些请求发送不同的内容。例如,只更新数据而不是完整文档。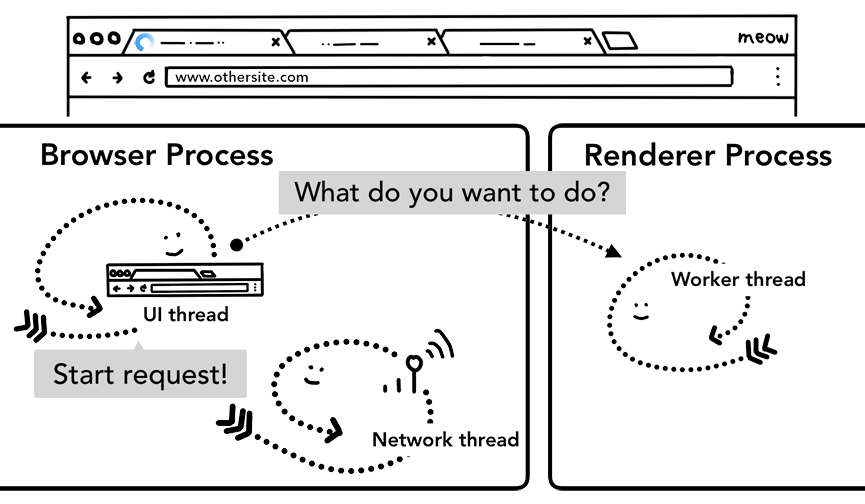

若有收获,就点个赞吧
0 人点赞
