在我们使用node做Server端或者Electron客户端的时候,可能会遇到一个需求,就是解压zip文件以及写入到目录中。比较熟悉node的人应该知道node很早就携带了一个库zlib。可惜实际上这个库文档基本没有,以及提供的unzip的Api仅提供对gz文件的压缩以及解压缩。本文就在此对zip解压的node端实现做出一个详细的解析,让你知道如何处理实际的业务问题。
前提说明:如果你的项目很紧急,推荐直接使用成熟的第三方npm包解决;如果你们项目不能使用纯node环境,那你找对了。
快速预览:推荐使用JSZip库进行解压缩,这是一个兼容node和browser的库,min.js文件仅90Kb。
注:本文基于Node.js v14.15.0文档
抛出问题
首先我们对node的Api能力做一个简单的分析。
在node里,zlib提供了一些api:
zlib.unzip(buffer[, options], callback)使用unzip解压一个数据块zlib.inflateRaw(buffer[, options], callback)使用inflateRaw解压数据块zlip.deflateRaw(buffer[, options], callback)使用deflateRaw提供一个数据块
在初次面对解压问题的时候,假设我们有一个demo.zip等待解压,我们第一反应当然直接使用unzip方法:一键解压!五秒一个需求!嘿嘿~
于是会尝试写下一个这样的代码:
const {readFile,writeFile} = require('fs').promises;const zlib = require('zlib');const {promisify} = require('util');const unzip = promisify(zlib.unzip);const doUnzip = async()=>{try{const file = await readFile('./demo.zip');const unzipFile = await unzip(file);await writeFile('./demo',unzipFile);} catch(err){console.log(err);}}doUnzip();
但是事实可能没有想象中顺利,这时候node会给你的沾沾自喜报一个错:
Error: incorrect header check
at Zlib.zlibOnError [as onerror] (zlib.js:180:17) {
errno: -3,
code: 'Z_DATA_ERROR'
}
错误的header检测?实际上node的文档给出了暗示:node提供的是创建和解压gz的方法,当然无法用来处理zip文件了。那我们实际想解压zip怎么办呢?
如果你遇上了以上那个问题,恭喜你,你的疑惑可以在此得到解答。如果没遇到,那也可以提前学学呀!
zip文件详解
大部分遇到这个问题的时候,第一想法肯定是第三方库,在百度和npm都可以获得一些不错的开源库解决了这个问题。
但是我面临的这个需求有一个前提:因为我们实现一个electron嵌入的webview页面,而electron是另一个项目组的产品,他们不愿意在自己的项目中添加任何的新库,解压只能在我们的浏览器环境完成!然后再使用electron环境的fs模块进行写入。所以我在接到这个需求时,第一时间并没有找到合适的第三方方案,于是准备自己实现一个浏览器环境的解压功能。
既然要处理zip文件,我们知道,所有的文件其实都是二进制数据,只要找到其编码标准,我们就可以深入底层,对数据进行解析,然后提取出我们需要内容。我以前写过一个解析http body的库,所以比较得心应手。
(以下内容提取自另一篇文章:https://blog.csdn.net/a200710716/article/details/51644421,感谢大神的分享。)
简单说,在zip文件里,遵循以下的数据编码:
(为了大家看得舒服,我直接在下方以//注释)
Overall .ZIP file format:
[local file header 1] // 文件1的header:按一定的格式记载了这个文件的各种数据
[file data 1] // 文件1的数据:文件1的数据将会被压缩,到这里
[data descriptor 1] // 文件1的描述:后面分析
.
.
.
[local file header n] // 假设有n个文件,n个文件都遵循这样的结构进行排序
[file data n]
[data descriptor n]
[archive decryption header] (EFS)
[archive extra data record] (EFS)
[central directory] // 核心目录标志开始
[zip64 end of central directory record]
[zip64 end of central directory locator]
[end of central directory record] // 核心目录标志结束
每一个zip文件的开始,在二进制的维度来看,都有一个约定好的hex值确定数据的位置:
- 文件的开始0x04034b50
- 核心目录开始0x02014b50
- 核心目录结束0x06054b50
你可以随便压缩一个zip文件(当然如果你是Mac用户,会被打包进很多Mac系统的文件,严重影响学习),然后使用二进制阅读器打开这个文件,这里我举个例子,假设我只对以下文件1.txt进行压缩:
我是111
在二进制阅读器中打开这个压缩文件(1.txt.zip),你会看到这样的:
504B0304 14000800 08001A72 67510000 00000000 00000900 00000500 2000312E 74787455 540D0007 D43BA65F D63BA65F D43BA65F 75780B00 0104F501 00000414 0000007B D631F1D9 8CF58686 8600504B 07081A1A 0DE00B00 00000900 0000504B 01021403 14000800 08001A72 67511A1A 0DE00B00 00000900 00000500 20000000 00000000 0000A481 00000000 312E7478 7455540D 0007D43B A65FD63B A65FD43B A65F7578 0B000104 F5010000 04140000 00504B05 06000000 00010001 00530000 005E0000 000000
以及对应的UTF-8编码结果为:
PK���rgQ�������� ���� �1.txtUT
��;�_�;�_�;�_ux
�������{�1�ٌ�����PK
�
��� ���PK���rgQ
�
��� ���� ���������������1.txtUT
��;�_�;�_�;�_ux
�������PK������S���^�����
虽然看起来很让人头秃,但是你挑能看懂的看,是不是感受到一股重复的规律?PK.......reQ......1.txt然后PK......,这个文件好像很嚣张,总想找人PK··,其实PK就是0x4b50在字符编码的表示,在zip文件的标志里,都是以0x4b50开始,所以PK对应的就是一个个文件开始标志符或者核心目录开始/结束标志符号。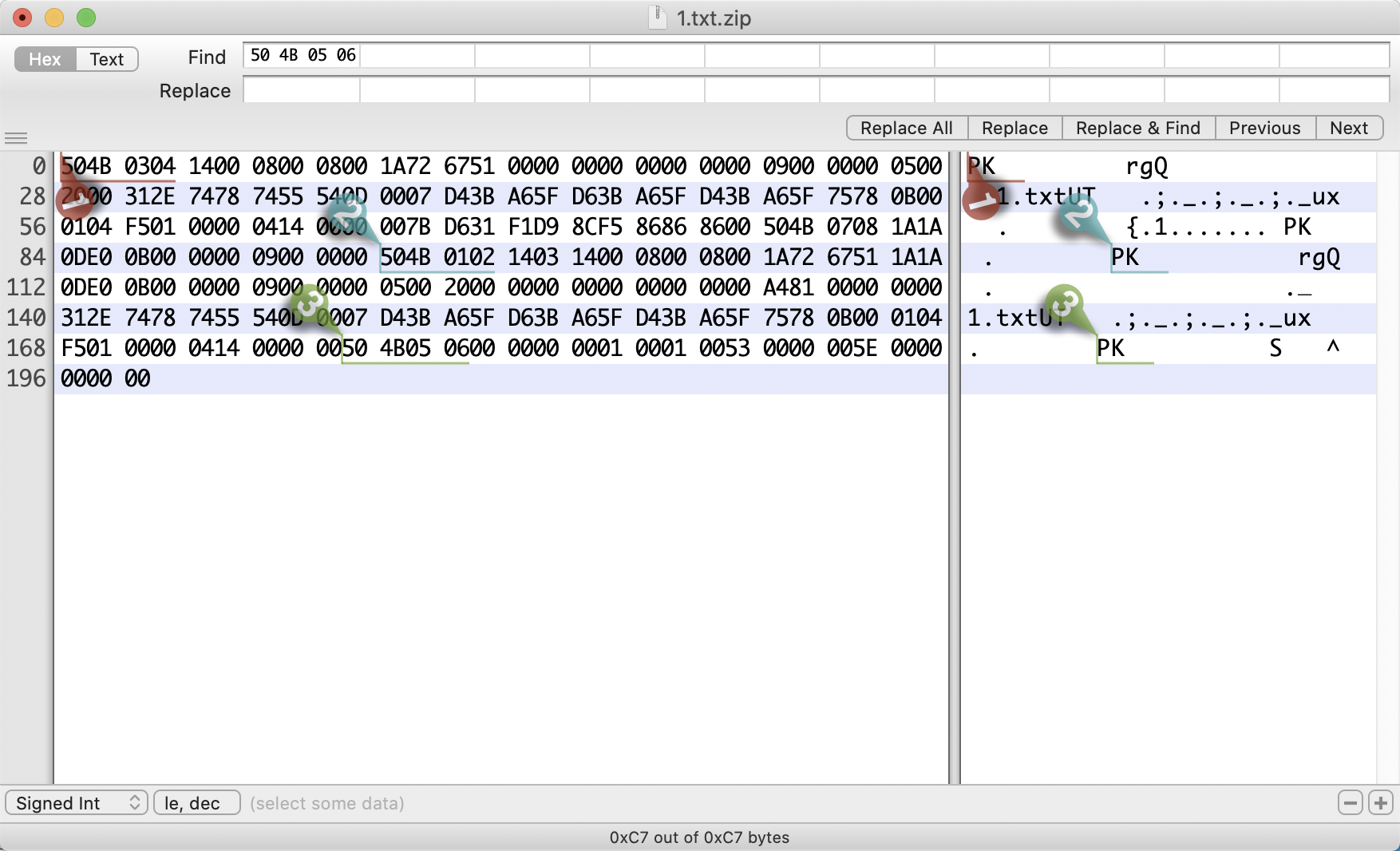
上图标出的三个bookmark,1号是文件开始标志,2是核心目录开始标志,3是核心目录结束标志。
如果我们想解压文件,只要按照这个规律去解析二进制数据,就可以把文件内容解压出来了!
更加详细的文件编码格式,可以去看我上面链接的那篇文章,他对header字段做了更详细的分析。对于本文来说,我们要开始研究node中的解压zip技术方案了。
TODO:以后这里会补上某个文件的详细分析
how to unzip
任何一个npm包对zip解压都是一样的处理方式:解析文件,对文件的header进行进一步分析,获得这个文件的详细信息,然后对文件内容进行解析,最后返回一个包装好的对象。
这里提供一个很简单的代码,以上文那个压缩文件,仅处理第一个压缩文件为例:
- 获取下一个标志的位置end,为bookmark2(504B0102)的位置;
- 把0~end的代码截取出来,这是第一个文件的内容;
- 按照zip格式约定的header标准,把文件名和文件内容截取出来; ```javascript const {promisify} = require(‘util’); const fs = require(‘fs’).promises;
// buf转为整数型 const buf2Int = (buf) => { let count = 0 let index = 0 while (buf[index]) { count += buf[index] index++ } return count; }
(async () => { const buf = await fs.readFile(‘../1.txt.zip’); const end = buf.indexOf(Buffer.from([0x50,0x4b,0x01,0x02])); // 构建一个核心目录标志,获得index const sliceBuf = buf.slice(0, end); // 把这个文件提取出来 // 文件名长度 const n = buf2Int(sliceBuf.slice(26, 28)); // zip中的一个文件中,26-28位表示文件名长度 // 拓展域长度 const m = buf2Int(sliceBuf.slice(28, 30)); // 26-28位表示文件拓展域长度
console.log(
n, // 文件名长度为:5(我们的文件为1.txt),刚好为5个字节
m // 拓展域长度为:32
);
const filename = sliceBuf.slice(30, 30 + n); // 把文件名解析出来
console.log(filename.toString()); // 1.txt
const fileContent = sliceBuf.slice(30+n+m); // 文件拓展域直到文件结尾都为文件内容
console.log(fileContent.toString()) // ��1�ٌ����PK
// todo 把文件内容解压出来
})();
上面的一段代码是一段很简单的例子,按照我们已知的1.txt.zip的格式,解析未知的文件名长度n和文件拓展域长度m(快问快答:为什么这两个值是未知的呢,其实很简单,因为文件名长度是不一定的,这里使用两个16进制值表示文件名长度,那么请问允许的最长文件名为多少?)。接下来,30+n+m直至最后都是文件内容。
但是这里还有一个小小的坑,在33行我们对文件内容进行toString之后,发现得到的还是一段乱码。很简单,因为zip的核心任务是压缩,所以这一段数据是使用压缩算法进行压缩后的数据。如果要进一步得到文件内容,就需要对文件内容进行进一步处理。
还好,这里的解压算法不需要你亲手去实现,因为node已经携带了这个功能。在zip文件的header里,每一个文件数据的4-6位都标记了该文件的压缩pkware算法最低版本,以及8-10位标记了该文件的解压方法。具体可以看一下那篇文章。
对于常规的解压业务,zip中压缩的数据都可以使用`inflateRaw`方法对数据进行解压:
```javascript
const zilb = require('zlib');
const inflateRaw = promisify(zilb.inflateRaw);
// 上一段代码的35行中加入
await inflateRaw(fileContent); // 我是111
恭喜你,当你看到这里,你已经对zip文件有了一个系统的认识和初步实践啦,接下来说一下JSZip解压库的使用。
JSZip实践
在面对一个zip文件的时候,zip解压库做的事情一般都是:
- 实现一个parse函数,用于数据的解析
- 解析出文件及目录
- 解析文件的header和内容
- 使用pkware算法对压缩后的内容再进行解压。
如果是在node环境的库,会直接提供了一站式api服务,但是JSZip还需要进行进一步处理。直接上代码!
const JSZip = require('jszip'); // 引入JSZip,怎么安装就不用教了吧?
const fs = require('fs').promises;
const unzipFile = async()=>{
const file = await fs.readFile('../1.txt.zip');
const unzipResult = await JSZip.loadAsync(file);
console.log(unzipResult);
/*
{
files: {
'1.txt': {
name: '1.txt',
dir: false,
date: 2020-11-07T14:16:52.000Z,
comment: null,
unixPermissions: 33188,
dosPermissions: null,
_data: [Object], // 数据将会携带在这个位置
_dataBinary: true,
options: [Object]
}
},
comment: null,
root: '',
clone: [Function]
}
*/
console.log(unzipResult.files['1.txt']);
/* {
name: '1.txt',
dir: false,
date: 2020-11-07T14:16:52.000Z,
comment: null,
unixPermissions: 33188,
dosPermissions: null,
_data: {
compressedSize: 11,
uncompressedSize: 9,
crc32: -536012262,
compression: {
magic: '\b\u0000',
compressWorker: [Function],
uncompressWorker: [Function]
},
compressedContent: <Buffer 7b d6 31 f1 d9 8c f5 86 86 86 00> // 看到熟悉的buffer,你懂怎么办啦?
},
_dataBinary: true,
options: { compression: null, compressionOptions: null }
}*/
}
unzipFile();
在上面的代码中可以看出,JSZip库已经把每一个文件解析到返回对象中,并以文件名为key存储了。而且,也按照zip的标准格式,把所有的header数据都解析出来了,同时文件内容存储在files[‘1.txt’]._data.compressedContent中,当时我使用的方式是直接对数据进行处理:
await infalteRaw(files['1.txt']._data.compressedContent);
本来想阅读一下文档进一步完善本文,但是由于github莫名挂了,所以这一部分简单说一下,如果读者看了文档找到了“正确”的处理方式,麻烦告诉我一声。
这个方法有个巨大的缺陷。因为实践中,JSZip包对数据进行解析时,已经对txt文件做了解析,直接写入文件就可以用,但是如果使用inflateRaw进行解压会直接报错并且影响进程继续执行。这个feature导致测试直接给我提了一个High的缺陷,害怕。
所以这里实践中如果你也使用了这个方法,可以考虑这样处理:
let fileContent = files['1.txt']._data.compressedContent;
try{
fileContent = await infalteRaw(files['1.txt']._data.compressedContent);
} catch(err){
}
await writeFile(fileContent....)
好了,这是本文的全部内容,如果有不懂的地方或者纰漏,欢迎和我联系沟通,email为xieniangao@126.com。

若有收获,就点个赞吧
0 人点赞
