网络请求一直是前端应用最为核心的部分之一。从 jQuery 对 ajax 的封装开始,请求库这几年已经得到了快速的发展。尤其是随着 hooks 的出现,现在请求库终于可以做到更好用、更快捷了。
在传统的请求模型里,一个请求的完整流程是这样的:
- 用户点击,触发请求流程
- 设置相关视图的状态为 loading
- 发起请求
- 处理响应结果,关闭视图的 loading 状态
那现在的 hooks 请求库,是怎么针对这个流程,把请求这件事变得简单的呢?
🌊更简单的请求处理
状态更简单:Effect 状态封装
在代码层面,现在的请求库基本已经将 loading 状态封装到 hooks 中。只要你触发了请求,只需要关心 hooks 中暴露出的 data 和 error 以及 loading 状态。这一点,无论是 useRequest 和 swr 都做了通用的封装:
// ahooks 的 useRequestconst { data, error, loading } = useRequest(fetcher);// swrconst { data, error, isValidating } = useSwr('/getList', fetcher);
缓存更简单:cacheKey 机制
针对一个场景:我们在首页列表页进入一个子页面,然后再返回。一般情况下,页面需要重新发起请求,获取最新的列表。如果我们从用户体验的角度来看,刚刚的数据也许没有过期,或者我希望返回时能看到我刚刚看到的数据,这样的体验将会更加“顺滑”。如果我们能将前页的数据缓存储存起来同时去更新数据,再由 react 的 diff 机制去更新页面,这样可以无缝得更新数据。
在 useRequest 中,可以为请求设置了一个 cacheKey 的字段,在需要重新拉取数据时,先读取缓存数据,再发起数据请求。而 SWR 和 react-query 的机制则更为激进,请求的 path 即是 key,针对这个 key 发起的请求将会被自动缓存。
const { data, error, loading } = useRequest(getList, {
cacheKey: 'list',
});
const { data, error, isValidating } = useSwr('/getList', TodoService);
基于缓存的分页预加载
因为是根据请求 path 作为 key 对数据进行缓存,那么我们可以设置一个隐藏的 dom,请求当前页的下一页。当用户进入下一页的时候,已经存在下一页的缓存数据,可以达成秒开。
分页预加载 Demo
更新更简单:Refetching 机制
都 2021 年了,网速对于大部分电脑来说已经不是紧张的资源了。在传统的场景下,我们只有在页面加载和用户操作主动触发时会更新数据。而对于现在的请求库来说,对于更新场景已经可以做到方便且节约了。在 SWR 中,主要实现的了聚焦重新请求、定期重新请求和重连的重新请求三种常用的场景。
对于大部分应用来说,重连重新请求是非常常用的场景。聚焦重新请求适合用在对数据即时性敏感的应用,例如商家后台。而对于即时性要求高的 App,例如协同办公型或者股票应用,可以使用 SWR 快速地实现重新请求。
编辑更简单:mutate 机制
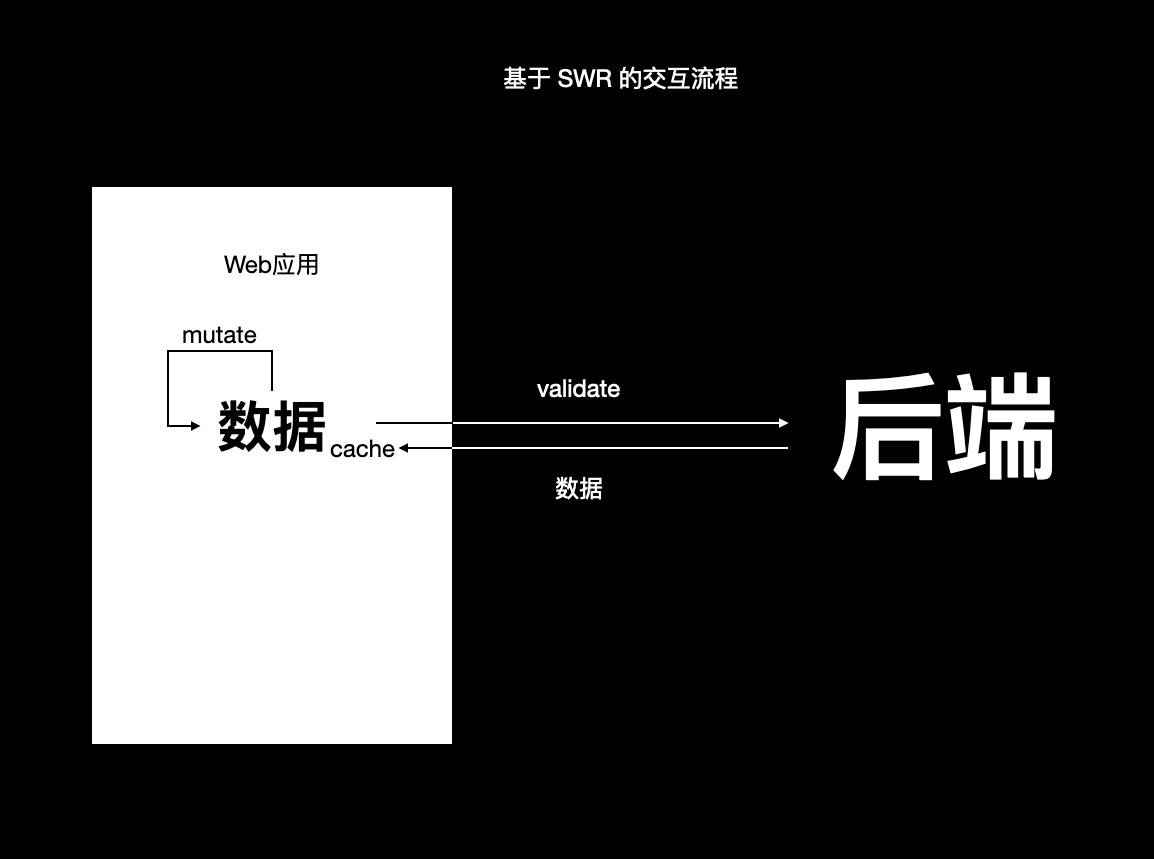
先拉取服务端数据,进行编辑再将数据更新到服务端,这是一个很常见的场景。传统的编辑逻辑,是在用户编辑后,实时将结果传送到服务端,再从服务端拉取编辑后的结果。如果在网络不好的场景下,会造成编辑有严重的滞后感。而在 SWR 中,编辑的思路为:通过 mutate 优先更改本地数据,然后将本地数据发送到服务端,最后从服务端拉取“验证”结果。这样,即是在网络较慢的场景下,也可以让用户很顺滑地编辑数据。
const { data, error, isValidating } = useSwr('/getList', TodoService);
return (
<div>
{isValidating && <span className="spin" />}
{data}
{error}
<button
onClick={() => {
mutate('/getList', 'local edit', false);
}}
>
mutate
</button>
</div>
)
mutate Demo
(在 useRequest 中,mutate 的行为和 swr 不一致 Demo)
当然,SWR 的 feature 还有很多,大家可以去看文档,接下来讲一下我对这些请求库的理解。
⛰️ react-query、useRequest 和 swr 的区别
在对上述 feature 的处理中,基本三个请求库都实现了。但是在具体的实现细节上,三个库的定位有各自的差别。
react-query:更细🪡
react-query几乎为每一个 feature 都提供了定制的能力,可以说是请求 hooks 里的瑞士军刀。例如,针对「浏览器窗口 focus 后重新请求这一点」,swr 和 useRequest 都只是提供开关,而 react-query 可以这样做:
focusManager.setEventListener(handleFocus => {
// Listen to visibillitychange and focus
if (typeof window !== 'undefined' && window.addEventListener) {
window.addEventListener('visibilitychange', handleFocus, false)
window.addEventListener('focus', handleFocus, false)
}
return () => {
// Be sure to unsubscribe if a new handler is set
window.removeEventListener('visibilitychange', handleFocus)
window.removeEventListener('focus', handleFocus)
}
})
/** 在 swr 中 */
const {} = useSWR('/getList',{
revalidateOnFocus : false,
});
这个 hooks 的细也体现在请求的状态中。
const {
data,error,isLoading,isError,isSuccess,isIdle,isPaused,status
} = useMutation('name', getName);
/** 简单点~请求的状态简单点~ */
基于 react-query 的定制化能力,其很适合用来定制特定业务场景下的专属 hooks。
useRequest:更贴近 Antd🪞
毕竟亲儿子。
const { data, loading, pagination } = useRequest(
({ current, pageSize }) => getUserList({ current, pageSize }),
{
paginated: true,
}
);
<Pagination {...pagination} />
/** 不说了,懂的都懂 */
swr:更顺滑……
例如对于 mutate 这个名字,有意思的是,三个库对于它的理解都是不一样的。
- react-query:实现了 useMutation,效果类似 useRequest 里的 manual 模式。
- useRequest:mutate 仅在本地生效。
- swr:mutate 后,触发相关 key 全部更新。也可以暂时不发起请求,修改本地数据后再“验证”数据。
如果说 react-query 像是安卓系统,那么 swr 就像是苹果系统:简单优雅而顺滑。swr 不认为自己在 loading 数据,而是从服务端拉取数据后,以后仅去“验证”数据是否和服务端一致。从 swr 的特性来说,我认为它更适合用来处理重前端体验的 Web App 场景。
❓为什么是 Hooks
以上热门的现在请求处理库,都是基于 hooks 来封装的,为什么 class 组件不能做到呢?这里体现了 Function Component 和 Class Component 的设计理解区别。
在 Class Component 里,如果要对逻辑进行复用,可以使用 mixin 模式或者 HOC 模式。mixin 模式已经被历史抛弃了;而 HOC 模式只能复用一段逻辑,同时也不能将逻辑彻底隐藏起来(一个简单的 HOC 封装 request Demo),而且也容易和 redux connect 以及组件的 props 混淆。
而 hooks 在设计之初,就是用来对可以复用逻辑进行封装。因此在 hooks 出现后,无论是对 redux 的封装还是今天的请求处理库,都给组件复用逻辑的能力带来了质的飞跃。
One More Thing… 现代的 hooks 模型
现在的请求库更多做的是对请求相关的逻辑进行处理。通过 swr 对于请求的优化,前端应用更加独立,在使用 swr 时,可以将后端看作一个数据的来源,其作用是为前端应用存储数据。


若有收获,就点个赞吧
0 人点赞
