Path与Node的区别
下面以一个案例来清楚地说明问题。其中path.stop用来停止遍历节点,Babel中的path.skip效果与之类似。这段代码的意思是,当在函数表达式中遍历到一个 Identifier 节点时,就输出path,然后停止遍历。根据 traverse 遍历规则,遍历到的这个Identifier节点肯定是 params[0],示例代码如下:
const fs = require('fs');const parser = require("@babel/parser");const traverse = require("@babel/traverse").default;const t = require("@babel/types");const generator = require("@babel/generator").default;const jscode = fs.readFileSync("./demo.js", {encoding: "utf-8"});let ast = parser.parse(jscode);const updateParamNameVisitor = {Identifier(path) {if (path.node.name === this.paramName) {path.node.name = "x";}console.log(path);path.stop();}};const visitor = {FunctionExpression(path) {const paramName = path.node.params[0].name;path.traverse(updateParamNameVisitor, {paramName});}};traverse(ast, visitor);let code = generator(ast).code;fs.writeFile('./demoNew.js', code, (err) => {});
path.node能取出Identifier所在的Node对象,该对象与AST Explorer网页中解析出来的AST节点结构一致。简单来说,节点是生成JS代码的”原料”,是Path中的一部分Path是一个对象,用来描述两个节点之间的连接.Path除了具有上述显示的这些属性以外,还包含添加、更新、移动和删除节点等很多有关的方法。
Path中的方法
1、获取子节点/Path
为了得到AST节点的属性值,一般会先访问到该节点,然后利用path.node.property方法获取属性,如下所示:
const fs = require('fs');const parser = require("@babel/parser");const traverse = require("@babel/traverse").default;const t = require("@babel/types");const generator = require("@babel/generator").default;const jscode = fs.readFileSync("./demo.js", {encoding: "utf-8"});let ast = parser.parse(jscode);const visitor = {BinaryExpression(path) {console.log(path.node.left);console.log(path.node.right);console.log(path.node.operator);}};traverse(ast, visitor);let code = generator(ast).code;fs.writeFile('./demoNew.js', code, (err) => {});
通过这个方法获取到的是Node或者具体的属性值,Node不能使用Path相关的方法,如果想要获取到该属性的Path,就需要使用Path对象的get,传递的参数为key(即该属性名的字符串形式)。如果是多级访问,那么以点连接多个key,例如:
const fs = require('fs');const parser = require("@babel/parser");const traverse = require("@babel/traverse").default;const t = require("@babel/types");const generator = require("@babel/generator").default;const jscode = fs.readFileSync("./demo.js", {encoding: "utf-8"});let ast = parser.parse(jscode);const visitor = {BinaryExpression(path) {console.log(path.get('left.name'));console.log(path.get('right'));console.log(path.get('operator'));}};traverse(ast, visitor);let code = generator(ast).code;fs.writeFile('./demoNew.js', code, (err) => {});
可以看到,任何形式的属性值,通过Path对象的get去获取,都会包装成Path对象再返回。不过,像operator、name这一类的属性值,没有必要包装成Path对象。
2、判断Path类型
回顾本章开头第一段代码中输出的Path对象,会发现最后有一个type属性,它与Node中的type基本一致。Path对象提供相应的方法来判断自身类型,使用方法与types组件差不多,只不过types组件判断的是Node。解析下原始代码中的第一个函数中的二项式,left是a+b,right是1000。因此,下面的代码执行以后依次输出false、true和报错,如下所示:
const fs = require('fs');const parser = require("@babel/parser");const traverse = require("@babel/traverse").default;const t = require("@babel/types");const generator = require("@babel/generator").default;const jscode = fs.readFileSync("./demo.js", {encoding: "utf-8"});let ast = parser.parse(jscode);const visitor = {BinaryExpression(path) {console.log(path.get('left').isIdentifier());console.log(path.get('right').isNumericLiteral({value: 1000}));path.get('left').assertIdentifier();}};traverse(ast, visitor);let code = generator(ast).code;fs.writeFile('./demoNew.js', code, (err) => {});
3、节点转代码
当代码比较复杂时,就要用动态调试。在vscode中调试,只需要单击行号,设置断点即可。启动调试后,代码运行到断点处会停止运行。这里的调试与调试普通J文件无异,还可以适时地插入console来排查错误,也可以基于当前节点生成代码来排查错误。即很多时候需要在执行过程中把部分节点转为代码,而不是在最后才把整个AT转成代码。
generator组件也可以把AST中的一部分节点转成代码,这对节点遍历过程中的调试很有帮助。示例代码如下:
const fs = require('fs');const parser = require("@babel/parser");const traverse = require("@babel/traverse").default;const t = require("@babel/types");const generator = require("@babel/generator").default;const jscode = fs.readFileSync("./demo.js", {encoding: "utf-8"});let ast = parser.parse(jscode);const visitor = {FunctionExpression(path) {console.log(generator(path.node).code);//console.log( path.toString() );//console.log( path + '' );}};traverse(ast, visitor);let code = generator(ast).code;fs.writeFile('./demoNew.js', code, (err) => {});
Path对象复写了Objectl的toString。在Path对象的 toString 中,调用了generator组件把节点转为代码。因此,可以用 path.toString 把节点转为字符串,也可以用 path + “” 来隐式转成字符串。
4、替换节点属性
替换节点属性与获取节点属性方法相同,只是改为赋值。但也并非随意替换,需要注意的是,替换的类型要在允许的类型范围内。因此需要熟悉AT的结构,如下所示:
const fs = require('fs');const parser = require("@babel/parser");const traverse = require("@babel/traverse").default;const t = require("@babel/types");const generator = require("@babel/generator").default;const jscode = fs.readFileSync("./demo.js", {encoding: "utf-8"});let ast = parser.parse(jscode);const visitor = {BinaryExpression(path) {path.node.left = t.identifier("x");path.node.right = t.identifier("y");}};traverse(ast, visitor);let code = generator(ast).code;fs.writeFile('./demoNew.js', code, (err) => {});
5、替换整个节点
Path对象中与替换相关的方法有 replaceWith、replaceWithMultiple、replaceInline和replaceWithSourceString。
replaceWith是用一个节点替换另一个节点,并且是严格的一换一。示例代码如下:
const fs = require('fs');const parser = require("@babel/parser");const traverse = require("@babel/traverse").default;const t = require("@babel/types");const generator = require("@babel/generator").default;const jscode = fs.readFileSync("./demo.js", {encoding: "utf-8"});let ast = parser.parse(jscode);const visitor = {BinaryExpression(path) {path.replaceWith(t.valueToNode('javaScriptAST'));}};traverse(ast, visitor);let code = generator(ast).code;fs.writeFile('./demoNew.js', code, (err) => {});
replaceWithMultiple也是用节点换节点,不过是多换一。示例代码如下:
const fs = require('fs');const parser = require("@babel/parser");const traverse = require("@babel/traverse").default;const t = require("@babel/types");const generator = require("@babel/generator").default;const jscode = fs.readFileSync("./demo.js", {encoding: "utf-8"});let ast = parser.parse(jscode);const visitor = {ReturnStatement(path) {path.replaceWithMultiple([t.expressionStatement(t.stringLiteral("javaScriptAST")),t.expressionStatement(t.numericLiteral(1000)),t.returnStatement(),]);path.stop();}};traverse(ast, visitor);let code = generator(ast).code;fs.writeFile('./demoNew.js', code, (err) => {});
上述代码中有两处要特别说明:当表达式语句单独在一行时(没有赋值),最好用expressionStatement 包裹;替换后的节点,traverse也是能遍历到的、因此替换时要极其小心,否则容易造成不合理的递归调用。例如上述代码,把 return 语句进行替换,但是替换的语句里又有return语句,就会陷人死循环。解决方法是加入path.stop,替换完成之后,立刻停止遍历当前节点和后续的子节点。
replacelnline 接收一个参数。如果参数不为数组,那么 replacelnline 等同于replaceWith;如果参数是一个数组,那么 replacelnline 等同于 replaceWithMultiple,其中的数组成员必须都是节点。示例代码如下:
const fs = require('fs');const parser = require("@babel/parser");const traverse = require("@babel/traverse").default;const t = require("@babel/types");const generator = require("@babel/generator").default;const jscode = fs.readFileSync("./demo.js", {encoding: "utf-8"});let ast = parser.parse(jscode);const visitor = {StringLiteral(path) {path.replaceInline(t.stringLiteral('Hello AST!'));path.stop();},ReturnStatement(path) {path.replaceInline([t.expressionStatement(t.stringLiteral("javaScriptAST")),t.expressionStatement(t.numericLiteral(1000)),t.returnStatement(),]);path.stop();}};traverse(ast, visitor);let code = generator(ast).code;fs.writeFile('./demoNew.js', code, (err) => {});
上述代码中,visitor中的函数也要加人path.stop,原因和之前介绍的等同。
最后看replace WithSourceString的用法,该方法用字符串源码替换节点,如把原始代码中的函数改为闭包形式,示例代码如下:
const fs = require('fs');const parser = require("@babel/parser");const traverse = require("@babel/traverse").default;const t = require("@babel/types");const generator = require("@babel/generator").default;const jscode = fs.readFileSync("./demo.js", {encoding: "utf-8"});let ast = parser.parse(jscode);traverse(ast, {ReturnStatement(path) {let argumentPath = path.get('argument');argumentPath.replaceWithSourceString('function(){return ' + argumentPath + '}()');path.stop();}});let code = generator(ast).code;fs.writeFile('./demoNew.js', code, (err) => {});
首先遍历ReturnStatement.然后通过Path的get获取子Path,才能调用Path的相关方法去操作argument节点。同时,replaceWithSourceString替换后的节点也会被解析,也就是说会被traverse遍历到。因为里面也有return语句,所以需要加上path.stop,上述代码中还用节点转代码,只不过是隐式转换。
凡是需要修改节点的操作,都推荐使用Pth对象的方法。当调用一个修改节点的方法后,Babel会更新Path对象。
6、删除节点
示例代码如下:
const fs = require('fs');const parser = require("@babel/parser");const traverse = require("@babel/traverse").default;const t = require("@babel/types");const generator = require("@babel/generator").default;const jscode = fs.readFileSync("./demo.js", {encoding: "utf-8"});let ast = parser.parse(jscode);traverse(ast, {EmptyStatement(path){path.remove();}});let code = generator(ast).code;fs.writeFile('./demoNew.js', code, (err) => {});
EmptyStatement指的是空语句,就是多余的分号。使用path.remove删除当前节点。
7、插入节点
想要把节点插入到兄弟节点中,可以使用insertBefore和insertAfter分别在当前节点的前后插入节点。代码如下:
const fs = require('fs');const parser = require("@babel/parser");const traverse = require("@babel/traverse").default;const t = require("@babel/types");const generator = require("@babel/generator").default;const jscode = fs.readFileSync("./demo.js", {encoding: "utf-8"});let ast = parser.parse(jscode);traverse(ast, {ReturnStatement(path) {path.insertBefore(t.expressionStatement(t.stringLiteral("Before")));path.insertAfter(t.expressionStatement(t.stringLiteral("After")));}});let code = generator(ast).code;fs.writeFile('./demoNew.js', code, (err) => {});
在上述代码中,如果只想操作某一个函数中的 ReturnStatement,可以在 visitor 的函数中进行判断,不符合要求的直接 return 即可。需要注意,使用 path.stop 是不可行的。
父级Path
观察前面输出的Path对象,可以看到有 parentPath 和 parent 两个属性。其中 parentPath类型为 NodePath,所以它是父级 Path.parent 类型为Node,所以它是父节点。
只要获取到父级Path,就可以调用Path对象的各种方法去操作父节点。父级Path的获取可以使用 path.parentPath。path.parentPath.node 等同于 path.parent,也就是说parent是parentPath 中的一部分。
1、path.findParent
个别情况下,需要从一个路径向上遍历语法树,直到满足相应的条件。这时可以使用
Path对象的findParent,示例如下:
const fs = require('fs');const parser = require("@babel/parser");const traverse = require("@babel/traverse").default;const t = require("@babel/types");const generator = require("@babel/generator").default;const jscode = fs.readFileSync("./demo.js", {encoding: "utf-8"});let ast = parser.parse(jscode);traverse(ast, {ReturnStatement(path) {console.log(path.findParent((p) => p.isObjectExpression()));//path.findParent(function(p){return p.isObjectExpression()});}});let code = generator(ast).code;fs.writeFile('./demoNew.js', code, (err) => {});
Path对象的 findParent 接收一个回调函数,在向上遍历每一个父级Path时,会调用该回调函数,并传人对应的父级Path对象作为参数。当该回调函数返回真值时,则将对应的父级Path返回。上述代码会遍历 ReturnStatement,然后向上找父级Path,当找到Path对象类型为 ObjectExpression 的情况时,就返回该Path对象。
2、path.find
这个方法使用场景较少,使用方法与findParent一致,只不过find方法查找的范围包含当前节点,而 findParent 不包含。
const fs = require('fs');const parser = require("@babel/parser");const traverse = require("@babel/traverse").default;const t = require("@babel/types");const generator = require("@babel/generator").default;const jscode = fs.readFileSync("./demo.js", {encoding: "utf-8"});let ast = parser.parse(jscode);traverse(ast, {ObjectExpression(path) {console.log( path.find((p) => p.isObjectExpression()) );}});let code = generator(ast).code;fs.writeFile('./demoNew.js', code, (err) => {});
3、path.getFunctionParent
向上查找与当前节点最接近的父函数 path.getFunctionParent,返回的也是Path对象。
4、path.getStatementParent
向上遍历语法树直到找到语句父节点。例如,声明语句、return语句、if语句、switch语句和while语句等,返回的也是Path对象。该方法从当前节点开始找,如果想要找到return语句的父语句,就需要从 parentPath 中去调用,代码如下:
const fs = require('fs');const parser = require("@babel/parser");const traverse = require("@babel/traverse").default;const t = require("@babel/types");const generator = require("@babel/generator").default;const jscode = fs.readFileSync("./demo.js", {encoding: "utf-8"});let ast = parser.parse(jscode);traverse(ast, {ReturnStatement(path) {console.log( path.parentPath.getStatementParent() );}});let code = generator(ast).code;fs.writeFile('./demoNew.js', code, (err) => {});
5、父级Path的其他方法
其他方法的使用与之前介绍的类似,如替换父节点 path.parentPath.replaceWith(Node)和删除父节点 path.parentPath.remove 等。
同级Path
在介绍同级Path之前,需要先介绍下容器(container)。先来看以下这个例子:
const fs = require('fs')const parser = require('@babel/parser')const traverse = require('@babel/traverse').defaultconst t = require('@babel/types')const generator = require('@babel/generator').defaultconst jscode = fs.readFileSync('./demo.js', {encoding: 'utf-8'})let ast = parser.parse(jscode)traverse(ast, {ReturnStatement (path) {console.log(path)}})// 其中的一个节点信息如下图所示
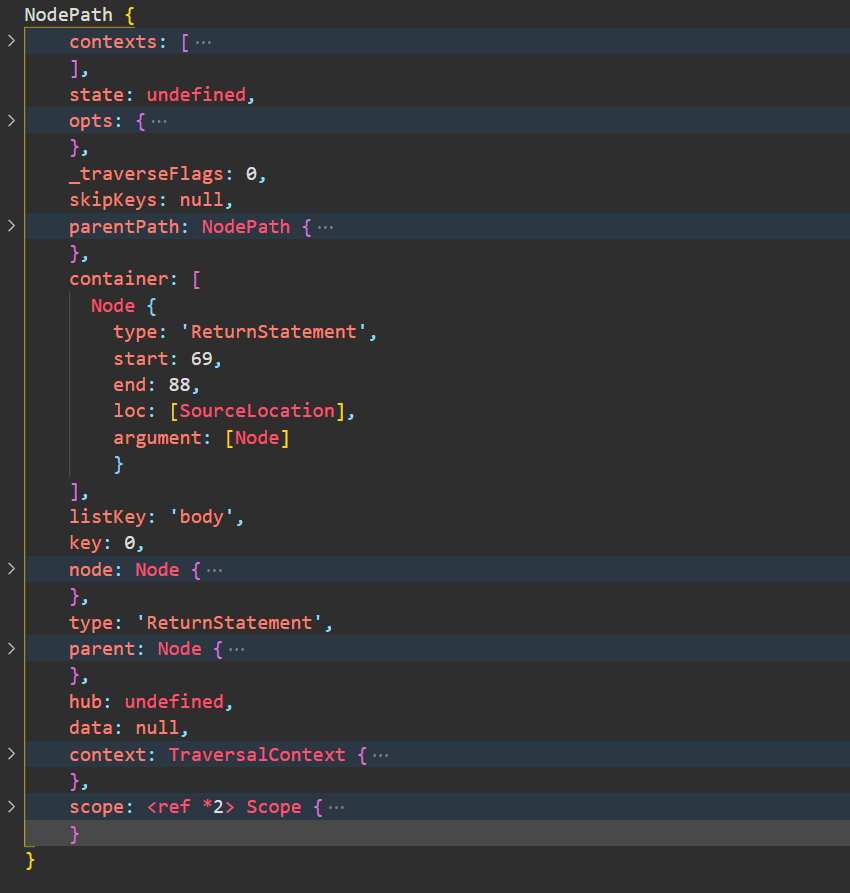
上述代码遍历ReturnStatement节点,并直接输出Path对象。之前介绍的AST结构,ReturnStatement 是放在 BlockStatement 的body节点中的,并且该body节点是一个数组。输出的Path对象中的几个关键属性里,container 就是容器,在这个例子中它是一个数组,里面只有一个 ReturnStatement 节点,与原始代码吻合。listKey是容器名,ReturnStatement 是放在 BlockStatement 的body节点中的,因此把body节点当作容器。
接下来介绍key。在上述代码输出的Path对象中,可以看到有一个key属性,这个key就是之前介绍的 path.get 方法的参数。实际上它就是容器对象的属性名,或者说是容器数组的索引。这里的容器是一个数组,key代表当前节点在容器中的位置。
并非只有body节点才是容器。再来看以下这个例子:
traverse(ast, {ObjectProperty (path) {console.log(path)}})
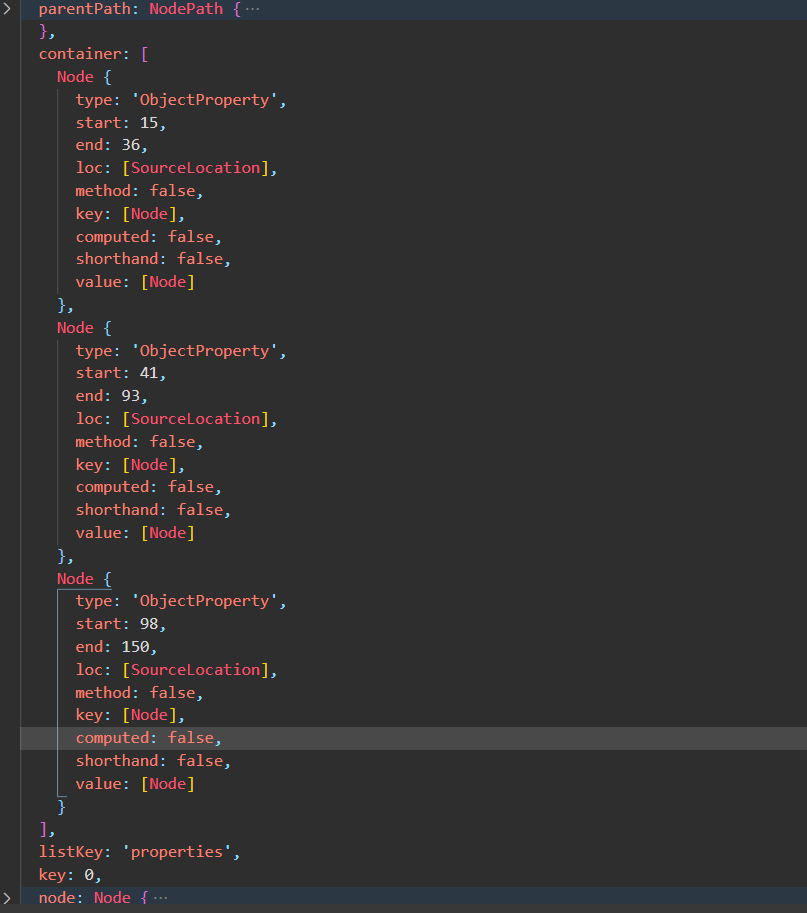
上述代码遍历ObjectProperty节点,然后直接输出Path对象。ObjectProperty是在ObjectExpression 的 properties 属性中的。查看Path对象中的几个关键属性,container是容器,listKey 是容器名。在原始代码中,有三个 ObjectProperty ,对应容器中的三个Node对象。key为,表示当前节点是容器中索引为0的成员,也就是说容器中的节点互为兄弟(同级)节点。
container 并非一直都是数组,例如以下这个例子:
traverse(ast, {ObjectExpression (path) {console.log(path)}})
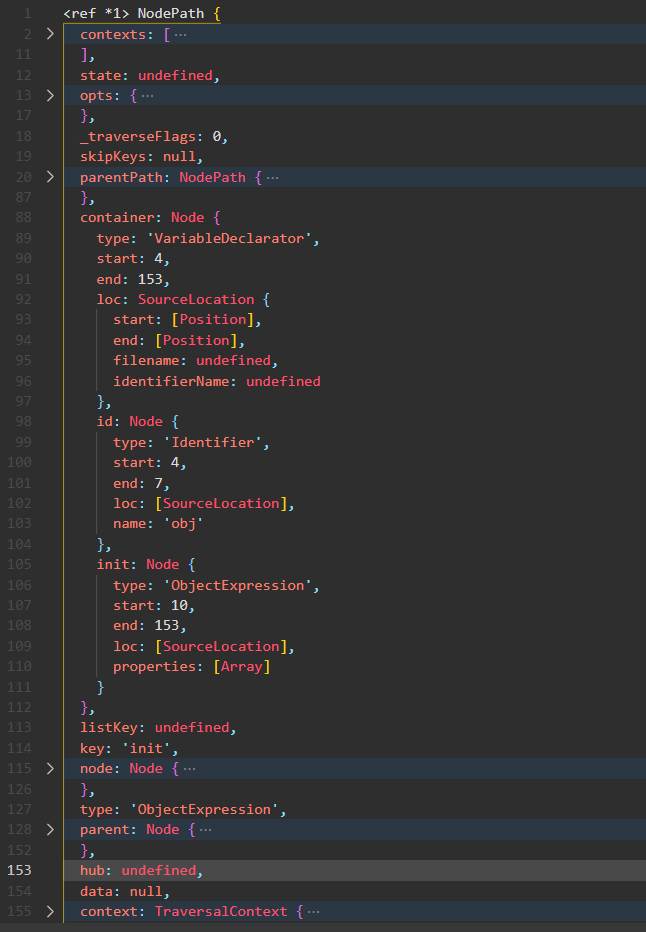
在上述代码中,container 是一个Node对象,listKey为 undefined,其实可以说它没有容器,也就是没有兄弟(同级)节点。在原始代码解析后的AST结构中,ObjectExpression是 VariableDeclarator 的初始化值(nt节点)。此时ky不是数组下标,而是对象的属性名。
了解容器之后,接着介绍同级Path相关的属性和方法。一般container为数组时就有同级节点,以下内容只考虑container为数组的情况,只有这种情况才有意义。示例代码如下:
traverse(ast, {ReturnStatement (path) {console.log(path.inList)console.log(path.container)console.log(path.listKey)console.log(path.key)console.log(path.getSibling(path.key))}})
1、path.inList
用于判断是否有同级节点。注意,当 container 为数组,但只有一个成员时,会返回
true。
2、path.key、path.container、path.listKey
使用 path.key 获取当前节点在容器中的索引。使用 path.container 获取容器(包含所
有同级节点的数组)。使用 path.listKey 获取容器名。
3、path.getSibling(index)
它用于获取同级Path,其中参数index为容器数组中的索引。index可以通过path
key来获取。可以对 path.key 进行加减操作来定位到不同的同级Path.
4、unshiftContainer与pushContainer
示例代码如下:
const fs = require('fs')const parser = require('@babel/parser')const traverse = require('@babel/traverse').defaultconst t = require('@babel/types')const generator = require('@babel/generator').defaultconst jscode = fs.readFileSync('./demo.js', {encoding: 'utf-8'})let ast = parser.parse(jscode)traverse(ast, {ReturnStatement (path) {path.parentPath.unshiftContainer('body', [t.expressionStatement(t.stringLiteral('Before1')),t.expressionStatement(t.stringLiteral('Before2'))])console.log(path.parentPath.pushContainer('body',t.expressionStatement(t.stringLiteral('After'))))}})let code = generator(ast).codefs.writeFile('./demoNew.js', code, err => {})
输出结果为如下: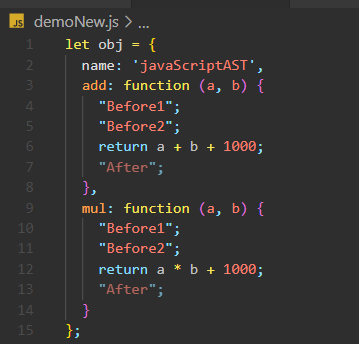
从上述代码中,可以看出 unshiftContainer 往容器最前面加人节点,pushContainer 往容器最后面加入节点。它们在ts文件中的定义如下:
pushContainer<Nodes extends Node | Node[]>(listKey: ArrayKeys < T >, nodes: Nodes): NodePaths<Nodes>;unshiftContainer < Nodes extends Node | Node[]]> (listKey: ArrayKeys < T >, nodes:Nodes ): NodePaths<Nodes>;
可以看出,第一个参数给 listKey,第二个参数给 Nodes.Nodes 是 Nodes extends Node | Node[],因此可以给 Node 或者 Node 的数组,最后函数返回加入的 Nodes 的Path对象。
scope详解
scope提供了一些属性和方法,可以方便地查找标识符的作用域,获取并修改标识符的所有引用,以及判断标识符是否为参数或常量。如果不是常量,也可以知道在哪里修改了它。本节以下面的代码为例:
const a = 1000let b = 2000let obj = {name: 'javaScriptAST',add: function (a) {a = 400b = 300let e = 700function demo () {let d = 600}demo()return a + a + b + 1000 + obj.name}}obj.add(100)
在上述代码中,有一个add,并且在add中又定义了一个demo.以这种方式定义的demo,在AST中的类型为FunctionDeclaration。
获取标识符作用域
scope.block属性可以用来获取标识符作用域,返回Node对象。使用方法分为两种情况:变量和函数。以下为标识符为变量的情况,如下所示:
const fs = require('fs');const parser = require("@babel/parser");const traverse = require("@babel/traverse").default;const t = require("@babel/types");const generator = require("@babel/generator").default;const jscode = fs.readFileSync("./demo.js", {encoding: "utf-8"});let ast = parser.parse(jscode);traverse(ast, {Identifier(path) {if (path.node.name == 'e') {console.log(generator(path.scope.block).code);}}});let code = generator(ast).code;fs.writeFile('./demoNew.js', code, (err)=>{});
既然 path.scope.block 返回Node对象,那么就可以使用 generator 来生成代码。上述代码遍历所有 Identifier,当名字为e时,把当前节点的作用域转代码。变量e是定义在add内部的,作用域范围是整个add。但是如果遍历的是一个函数,它的作用域会有些特别。来看下面这个例子:
const fs = require('fs')const parser = require('@babel/parser')const traverse = require('@babel/traverse').defaultconst t = require('@babel/types')const generator = require('@babel/generator').defaultconst jscode = fs.readFileSync('./demo.js', {encoding: 'utf-8'})let ast = parser.parse(jscode)traverse(ast, {FunctionDeclaration (path) {console.log(generator(path.scope.block).code)}})let code = generator(ast).codefs.writeFile('./demoNew.js', code, err => {})/*function demo () {let d = 600}*/
上述代码遍历 FunctionDeclaration,在原始代码中只有demo符合要求,但是 demo 的作用域实际上应该是整个add的范围。因此输出与实际不符,这时需要去获取父级作用域。获取函数的作用域代码如下:
const fs = require('fs');const parser = require("@babel/parser");const traverse = require("@babel/traverse").default;const t = require("@babel/types");const generator = require("@babel/generator").default;const jscode = fs.readFileSync("./demo.js", {encoding: "utf-8"});let ast = parser.parse(jscode);traverse(ast, {FunctionDeclaration(path) {console.log(generator(path.scope.parent.block).code);}});let code = generator(ast).code;fs.writeFile('./demoNew.js', code, (err)=>{});/*function (a) {a = 400b = 300let e = 700function demo () {let d = 600}demo()return a + a + b + 1000 + obj.name}*/
scope.getBinding
scope.getBinding 接收一个类型为 string 的参数,用来获取对应标识符的绑定。为了更直观地说明绑定的含义,先来看下面这段代码。遍历 FunctionDeclaration,符合要求的只有demo,然后获取当前节点下的绑定a,直接输出 binding,代码如下:
const fs = require('fs')const parser = require('@babel/parser')const traverse = require('@babel/traverse').defaultconst t = require('@babel/types')const generator = require('@babel/generator').defaultconst jscode = fs.readFileSync('./demo.js', {encoding: 'utf-8'})let ast = parser.parse(jscode)traverse(ast, {FunctionDeclaration (path) {let binding = path.scope.getBinding('a')console.log(binding)}})let code = generator(ast).codefs.writeFile('./demoNew.js', code, err => {})
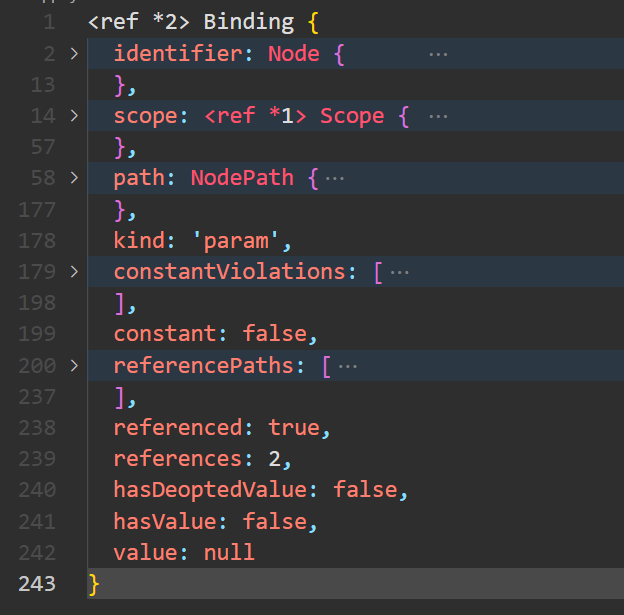
getBinding 中传的值必须是当前节点能够引用到的标识符名。如传入 g ,这个标识符并不存在,或者说当前节点引用不到,那么 getBinding 会返回 undefined。
接下来介绍 Binding 中关键的属性。identifier 是 a 标识符的 Node 对象。path是a标识符的Path对象。kind 中表明了这是一个参数,但它并不代表就是当前 demo 的参数。实际上在原始代码中,a是 add 的参数(当函数中局部变量与全局变量重名时,使用的是局部变量)。constant 表示是否常量。referenced 表示当前标识符是否被引用。references 表示当前标识符被引用的次数。constant Violations与referencePaths会在后续内容中单独讲述。
另外可以看出,Binding 中也有 scope 。因为获取的是a的 Binding,所以是 a 的 scope。
将其中的 block 节点转为代码后,可以看出它的作用域范围就是 add。值得一提的是,假如获取的是 demo 的 Binding,将其中的 block 节点转为代码后,输出的也是 add。因此,获取函数作用域也可以用如下方式:
const fs = require('fs')const parser = require('@babel/parser')const traverse = require('@babel/traverse').defaultconst t = require('@babel/types')const generator = require('@babel/generator').defaultconst jscode = fs.readFileSync('./demo.js', {encoding: 'utf-8'})let ast = parser.parse(jscode)traverse(ast, {FunctionExpression (path) {let bindingA = path.scope.getBinding('a')let bindingDemo = path.scope.getBinding('demo')console.log(bindingA.referenced)console.log(bindingA.references)console.log(generator(bindingA.scope.block).code)console.log(generator(bindingDemo.scope.block).code)}})let code = generator(ast).codefs.writeFile('./demoNew.js', code, err => {})
scope.getOwnBinding
该函数用于获取当前节点自己的绑定,也就是不包含父级作用域中定义的标识符的绑定。但是该函数会得到子函数中定义的标识符的绑定,来看下面这个例子:
const fs = require('fs')const parser = require('@babel/parser')const traverse = require('@babel/traverse').defaultconst t = require('@babel/types')const generator = require('@babel/generator').defaultconst jscode = fs.readFileSync('./demo.js', {encoding: 'utf-8'})let ast = parser.parse(jscode)function TestOwnBinding (path) {path.traverse({Identifier (p) {let name = p.node.nameconsole.log(name, !!p.scope.getOwnBinding(name))}})}traverse(ast, {FunctionExpression (path) {TestOwnBinding(path)}})let code = generator(ast).codefs.writeFile('./demoNew.js', code, err => {})
上述代码遍历 FunctionExpression 节点,当前案例中符合要求的只有 add 函数,然后遍历该函数下所有 Identifier,输出标识符名和 getOwnBinding 的结果。查看输出结果,可以发现子函数 demo 中定义的 d 变量,该变量也可以通过 getOwnBinding 得到。也就是说,如果只想获取当前节点下定义的标识符,而不涉及子函数的话,还需要进一步判断。可以通过判断标识符作用域是否与当前函数一致来确定,如:
const fs = require('fs')const parser = require('@babel/parser')const traverse = require('@babel/traverse').defaultconst t = require('@babel/types')const generator = require('@babel/generator').defaultconst jscode = fs.readFileSync('./demo.js', {encoding: 'utf-8'})let ast = parser.parse(jscode)function TestOwnBinding (path) {path.traverse({Identifier (p) {let name = p.node.namelet binding = p.scope.getBinding(name)binding &&console.log(name, generator(binding.scope.block).code == path + '')}})}traverse(ast, {FunctionExpression (path) {TestOwnBinding(path)}})let code = generator(ast).codefs.writeFile('./demoNew.js', code, err => {})
上述代码通过 binding.scope.block 获取标识符作用域,转为代码后,再与当前节点的代码比较,就可以确定是否是当前函数中定义的标识符。因为子函数中定义的标识符,作用域范围是子函数本身,添加判断作用域的代码后,使用 getBinding 和 getOwnBinding 得到的结果是一样的。
referencePaths与constant Violations
首先介绍 referencePaths。假如标识符被引用,referencePaths 中会存放所有引用该标识符的节点的Path对象。查看referencePaths中的内容,如下所示: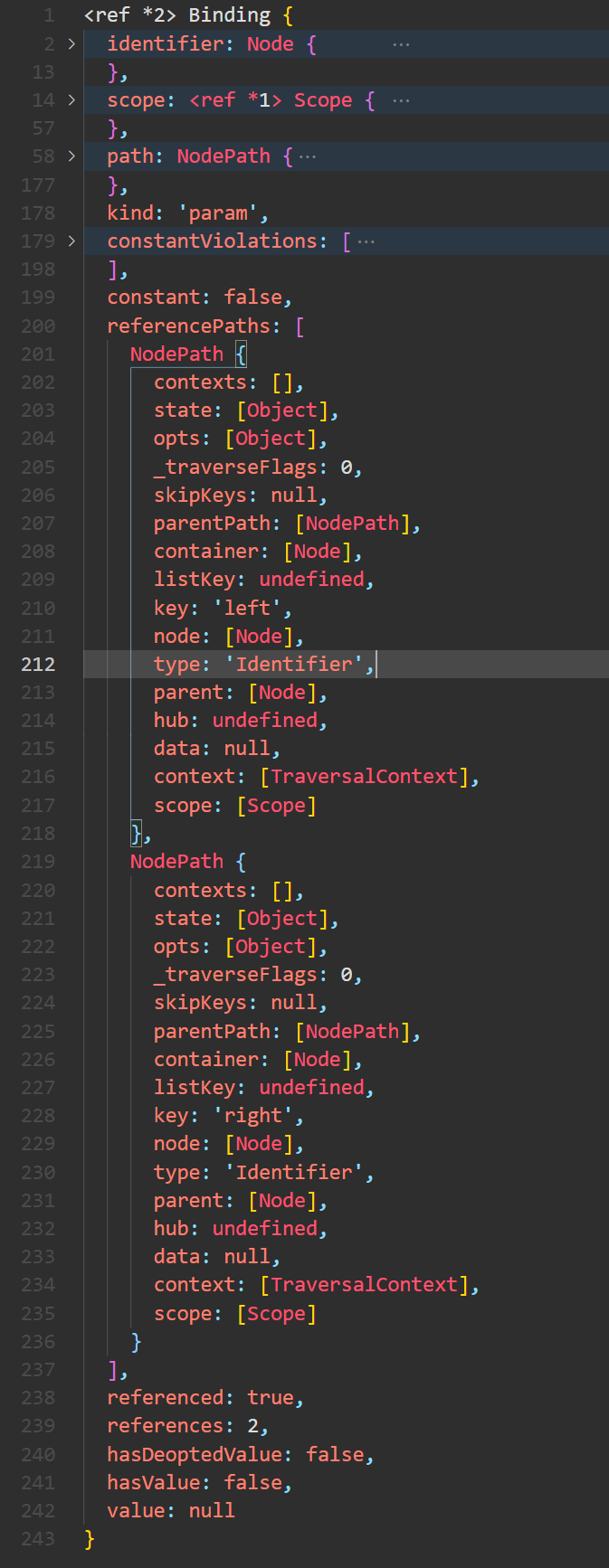
可以看出,referencePaths 是一个数组。在原始代码中使用的是 a+a,所以有两处引用,对应这里的两个成员。其中Node对象是引用处的 a 标识符本身。因为这是一个二项式,所以两处引用分别是 BinaryExpression 的 left 和 right ,它们的父节点自然是二项式没有兄弟节点,所以 container 是一个对象,listKey 是 undefined。
再看介绍 constant Violations。假如标识符被修改,t中会存放所有修改该标识符节点的Path 对象。查看 constant Violations 中的内容、原始代码中有一处修了 a 变量,它是一个赋值表达式,left是a,right 是 400,如下所示: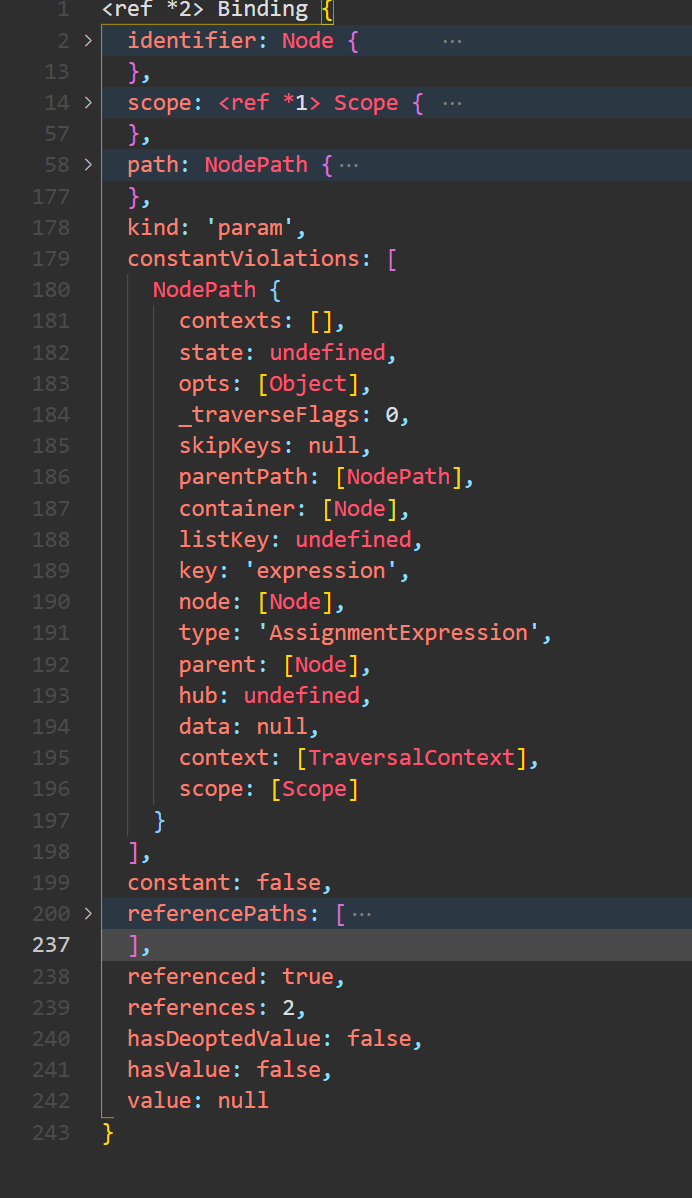
遍历作用域
scope.traverse 方法可以用来遍历作用域中的节点。可以使用 Path 对象中的 scope,也可以使用 Binding 中的scope。推荐使用后者。来看下面这个例子:
const fs = require('fs')const parser = require('@babel/parser')const traverse = require('@babel/traverse').defaultconst t = require('@babel/types')const generator = require('@babel/generator').defaultconst jscode = fs.readFileSync('./demo.js', {encoding: 'utf-8'})let ast = parser.parse(jscode)traverse(ast, {FunctionDeclaration (path) {let binding = path.scope.getBinding('a')binding.scope.traverse(binding.scope.block, {AssignmentExpression (p) {if (p.node.left.name == 'a') p.node.right = t.numericLiteral(500)}})}})let code = generator(ast).codefs.writeFile('./demoNew.js', code, err => {})
原始代码中,a=400,上述代码的作用是将它改为a=500。假如是从 demo 这个函数入手,那么只要获取 demo 函数中的a的 Binding,然后遍历 binding.scope.block(也就是a的作用域),找到赋值表达式是 left 为a的,将对应的 right 改掉。
标识符重命名
可以使用 scope.rename 将标识符进行重命名这个方法会同时修改所有引用该标识符的地方。例如将add函数中的b变量重命名为 x ,代码如下:
const fs = require('fs')
const parser = require('@babel/parser')
const traverse = require('@babel/traverse').default
const t = require('@babel/types')
const generator = require('@babel/generator').default
const jscode = fs.readFileSync('./demo.js', {
encoding: 'utf-8'
})
let ast = parser.parse(jscode)
traverse(ast, {
FunctionExpression (path) {
let binding = path.scope.getBinding('b')
binding.scope.rename('b', 'x')
}
})
let code = generator(ast).code
fs.writeFile('./demoNew.js', code, err => {})
上述方法很方便,但是如果指定一个名字,可能会与现有标识符冲突。这时可以使用scope.generateUidIdentifier 来生成一个标识符,生成的标识符不会与任何本地定义的标识符相冲突,如:
const fs = require('fs')
const parser = require('@babel/parser')
const traverse = require('@babel/traverse').default
const t = require('@babel/types')
const generator = require('@babel/generator').default
const jscode = fs.readFileSync('./demo.js', {
encoding: 'utf-8'
})
let ast = parser.parse(jscode)
traverse(ast, {
FunctionExpression (path) {
path.scope.generateUidIdentifier('uid')
// Node { type: "Identifier", name: "_uid" }
path.scope.generateUidIdentifier('uid')
// Node { type: "Identifier", name: "_uid2" }
}
})
let code = generator(ast).code
fs.writeFile('./demoNew.js', code, err => {})
使用这两种方法,就可以实现一个简单的标识符混淆方案。代码如下:
const fs = require('fs')
const parser = require('@babel/parser')
const traverse = require('@babel/traverse').default
const t = require('@babel/types')
const generator = require('@babel/generator').default
const jscode = fs.readFileSync('./demo.js', {
encoding: 'utf-8'
})
let ast = parser.parse(jscode)
traverse(ast, {
Identifier (path) {
path.scope.rename(
path.node.name,
path.scope.generateUidIdentifier('_0x2ba6ea').name
)
}
})
let code = generator(ast).code
fs.writeFile('./demoNew.js', code, err => {})
实际上标识符混淆方案还可以做得更复杂。例如,上述代码中,如果再多定义一些函数,会发现各函数之间的局部变量名是不重复的。假如把各个函数之间的局部变量定义成重复的,甚至还可以让函数中的局部变量跟当前函数中没有引用到的全局变量重名,原始代码中的全局变量a与add中的a参数。
scope的其他方法
1、scope.hasBinding(‘a’)
该方法查询是否有标识符a的绑定,返回true或false。可以用 scope.getBinding(‘a’) 代替,scope.getBinding(‘a’) 返回 undefined,等同于 scope.hasBinding(‘a’) 返回false。
2、scope.hasOwnBinding(‘a’)
该方法查询当前节点中是否有自己的绑定,返回true或false。例如,对于 demo 函数,OwnBinding 只有一个d。函数名 demo 虽然也是标识符,但不属于 demo 函数的OwnBinding 范畴,是属于它的父级作用域的,如:
const fs = require('fs')
const parser = require('@babel/parser')
const traverse = require('@babel/traverse').default
const t = require('@babel/types')
const generator = require('@babel/generator').default
const jscode = fs.readFileSync('./demo.js', {
encoding: 'utf-8'
})
let ast = parser.parse(jscode)
traverse(ast, {
FunctionDeclaration (path) {
console.log(path.scope.parent.hasOwnBinding('demo'))
}
})
let code = generator(ast).code
fs.writeFile('./demoNew.js', code, err => {})
同样可以使用 scope.getOwnBinding(‘a’) 代替它,scope.getOwnBinding(‘a’) 返回undefined。等同于 scope.hasOwnBinding(‘a’) 返回false。原始代码中scope.hasOwnBinding(‘a’) 也是通过 scope.getOwnBinding(‘a’) 来实现的。
3、scope.getAllBindings
该方法获取当前节点的所有绑定,会返回一个对象。该对象以标识符名为属性名,对应的Binding 为属性值,代码如下:
const fs = require('fs')
const parser = require('@babel/parser')
const traverse = require('@babel/traverse').default
const t = require('@babel/types')
const generator = require('@babel/generator').default
const jscode = fs.readFileSync('./demo.js', {
encoding: 'utf-8'
})
let ast = parser.parse(jscode)
traverse(ast, {
FunctionDeclaration (path) {
console.log(path.scope.getAllBindings())
}
})
let code = generator(ast).code
fs.writeFile('./demoNew.js', code, err => {})

4、scope.hasReference(‘a’)
该方法查询当前节点中是否有a标识符的引用,返回 true 或 false。
5、scope.getBindingldentifier(‘a’)
该方法获取当前节点中绑定的a标识符,返回 Identifier 的 Node 对象。同样,这个方法也有Own版本,为 scope.getOwnBindingIdentifier(‘a’)。

若有收获,就点个赞吧
0 人点赞
