本章将学习JavaScript的安全防护的原理,后面会继续介绍AST抽象语法树的原理和实现和Bable的API的使用,学会这两个之后,就可以开始实现自动化混淆和还原JavaScript代码。
先来看一段原始代码,这段代码没有经过任何处理,任何查看脚本的开发者都可以清楚地理解本段代码,并且对他进行修改或者搬运
Date.prototype.format = function(formatStr) {var str = formatStr;var Week = ['日', '一', '二', '三', '四', '五', '六'];str = str.replace(/yyyy|YYYY/, this.getFullYear());str = str.replace(/MM/, (this.getMonth() + 1) > 9 ? (this.getMonth() + 1).toString() : '0' + (this.getMonth() + 1));str = str.replace(/dd|DD/, this.getDate() > 9 ? this.getDate().toString() : '0' + this.getDate());return str}console.log(new window['Date']()['format']('yyyy-MM-dd'));
常量混淆原理
对象属性的访问方式
function People(name) {this.name = name;}People.prototype.sayHello = function() {console.log('Hello');}var p = new People('JavaScript');// 通过点语法访问对象的属性console.log(p.name); //JavaScriptp.sayHello(); //Hello// 通过[]语法访问对象的属性console.log(p['name']); //JavaScriptp['sayHello'](); //Hello
我们通过对象属性的访问特性,我们可以把原始代码改成下面这个样子,原来的点语法改成 [ ] 的访问方式来进行访问
Date.prototype.format = function(formatStr) {var str = formatStr;var Week = ['日', '一', '二', '三', '四', '五', '六'];str = str['replace'](/yyyy|YYYY/, this['getFullYear']());str = str['replace'](/MM/, (this['getMonth']() + 1) > 9 ? (this['getMonth']() + 1)['toString']() : '0' + (this['getMonth']() + 1));str = str['replace'](/dd|DD/, this['getDate']() > 9 ? this['getDate']()['toString']() : '0' + this['getDate']());return str}console.log(new window['Date']()['format']('yyyy-MM-dd'));
十六进制字符串
通过改变属性访问方式的处理,原始代码的可读性还是很高,可以很清楚地知道代码做了什么,需要继续处理,这里我们使用十六进制来替换原有的字符串,原理就是将一个字符转换为 ASCII 编码,然后再将 ASCII 编码以十六进制输出。
在JS中,charCodeAt 方法用来取出字符串中对应索引的字符的 ASCII 码,然后用 toString(16) 转换为十六进制,再与 x 拼接。为了方便理解,这里只处理一个字符串,代码转换为:
console.log("a".charCodeAt(0).toString(16)) // 61
根据这个原理,可以使用下面这个函数,将字符串转为十六进制编码
function strToHex(str) {for (var hexStr = [], i = 0, c; i < str.length; i++) {c = str.charCodeAt(i).toString(16);hexStr += "\\x" + c;}return hexStr}
利用这个原理,将源代码继续处理一下
Date.prototype.format = function (formatStr) {var str = formatStr;var Week = ['日', '一', '二', '三', '四', '五', '六'];str = str['replace'](/yyyy|YYYY/, this['getFullYear']());str = str['replace'](/MM/, (this['getMonth']() + 1) > 9 ? (this['getMonth']() + 1)['toString']() : '0' + (this['getMonth']() + 1));str = str['replace'](/dd|DD/, this['getDate']() > 9 ? this['getDate']()['toString']() : '0' + this['getDate']());return str}console.log(new window['Date']()['format']('\x79\x79\x79\x79\x2d\x4d\x4d\x2d\x64\x64'));
Unicode字符串
在JS中,字符串除了可以表示成十六进制的形式以外,还支持用 unicode形式表示
// 原始的var Week = ['日', '一', '二', '三', '四', '五', '六']// Unicode替换后var Week = ['\u65e5', '\u4e00', '\u4e8c', '\u4e09', '\u56db', '\u4e94', '\u516d']
unicode的形式是:\u开头,后跟四位数的十六进制数,不足四位的补0可以使用以下代码完成 unicode转换
function strToUnicode(str) {var value = '';for (var i = 0; i < str.length; i++)value += "\\u" + ("0000" + parseInt(str.charCodeAt(i)).toString(16)).substr(-4);return value;}
那么我们可以将源代码转换为一下形式
Date.prototype.\u0066\u006f\u0072\u006d\u0061\u0074 = function(formatStr) {var \u0073\u0074\u0072 = \u0066\u006f\u0072\u006d\u0061\u0074\u0053\u0074\u0072;var Week = ['\u65e5', '\u4e00', '\u4e8c', '\u4e09', '\u56db', '\u4e94', '\u516d'];str = str['replace'](/yyyy|YYYY/, this['getFullYear']());str = str['replace'](/MM/, (this['getMonth']() + 1) > 9 ? (this['getMonth']() + 1)['toString']() : '0' + (this['getMonth']() + 1));str = str['replace'](/dd|DD/, this['getDate']() > 9 ? this['getDate']()['toString']() : '0' + this['getDate']());return str;}console.log( new \u0077\u0069\u006e\u0064\u006f\u0077['\u0044\u0061\u0074\u0065']()['format']('\x79\x79\x79\x79\x2d\x4d\x4d\x2d\x64\x64') );
虽然看上去已经不可读,但是还原起来特别简单,在实际JS混淆的应用中,标识符一般不会替换成unicode形式,通常的混淆方式是替换成没有语义,但看上去很相似的名字,如O00Oo0、Oo0000、_0x21dd83、_0x21dd84
字符串的ASCI码混淆
先来看下 charCodeAt 和 fromCharCode 的用法
console.log("a".charCodeAt(0)); // 97console.log("b".charCodeAt(0)); // 98console.log(String.fromCharCode(97, 98)); // ab
将字符串的字符 ASCII 码存储到一个数组中,使用下面的代码可以进行转换
function stringToByte(str) {var byteArr = [];for (var i = 0; i < str.length; i++) {byteArr.push(str.charCodeAt(i));}return byteArr;}
可以使用下面代码将字符ASCII码数组转回字符串
function byteToString(byteArr) {return String.fromCharCode(...byteArr)}function byteToString(byteArr) {return String.fromCharCode.apply(null, byteArr)}
将原始代码进行字符ASCII码替换混淆,结果如下
Date.prototype.\u0066\u006f\u0072\u006d\u0061\u0074 = function(formatStr) {var \u0073\u0074\u0072 = \u0066\u006f\u0072\u006d\u0061\u0074\u0053\u0074\u0072;var Week = ['\u65e5', '\u4e00', '\u4e8c', '\u4e09', '\u56db', '\u4e94', '\u516d'];eval(String.fromCharCode(115, 116, 114, 32, 61, 32, 115, 116, 114, 91, 39, 114, 101, 112, 108, 97, 99, 101, 39, 93, 40, 47, 121, 121, 121, 121, 124, 89, 89, 89, 89, 47, 44, 32, 116, 104, 105, 115, 91, 39, 103, 101, 116, 70, 117, 108, 108, 89, 101, 97, 114, 39, 93, 40, 41, 41, 59));str = str['replace'](/MM/, (this['getMonth']() + 1) > 9 ? (this['getMonth']() + 1)['toString']() : '0' + (this['getMonth']() + 1));str = str['replace'](/dd|DD/, this['getDate']() > 9 ? this['getDate']()['toString']() : '0' + this['getDate']());return str;}console.log( new \u0077\u0069\u006e\u0064\u006f\u0077['\u0044\u0061\u0074\u0065']()[String.fromCharCode(102, 111, 114, 109, 97, 116)]('\x79\x79\x79\x79\x2d\x4d\x4d\x2d\x64\x64') );
字符串常量加密
字符串常量加密的核心思想是,先把字符串加密得到密文,在使用前,调用对应的解密函数去解密,得到明文。代码中仅出现解密函数和密文。当然,也可以使用不同的加密方法去加密字符串,再调用不同的解密函数去解密。将把代码中剩下的字符串都处理完,字符串加密方式采用最简单的Base64编码。
JS自带了base64编码和解码方法,分别是btoa编码和abot解码,在实际应用中最好是自己去实现解码和编码函数。
此处使用系统自带的的abot进行解码,源代码处理过的代码如下:
replace //cmVwbGFjZQ==getMonth //Z2V0TW9udGg=getDate //Z2V0RGF0ZQ==toString //dG9TdHJpbmc=Date.prototype.\u0066\u006f\u0072\u006d\u0061\u0074 = function(formatStr) {var \u0073\u0074\u0072 = \u0066\u006f\u0072\u006d\u0061\u0074\u0053\u0074\u0072;var Week = ['\u65e5', '\u4e00', '\u4e8c', '\u4e09', '\u56db', '\u4e94', '\u516d'];eval(String.fromCharCode(115, 116, 114, 32, 61, 32, 115, 116, 114, 91, 39, 114, 101, 112, 108, 97, 99, 101, 39, 93, 40, 47, 121, 121, 121, 121, 124, 89, 89, 89, 89, 47, 44, 32, 116, 104, 105, 115, 91, 39, 103, 101, 116, 70, 117, 108, 108, 89, 101, 97, 114, 39, 93, 40, 41, 41, 59));str = str[atob('cmVwbGFjZQ==')](/MM/, (this[atob('Z2V0TW9udGg=')]() + 1) > 9 ? (this[atob('Z2V0TW9udGg=')]() + 1)[atob('dG9TdHJpbmc=')]() : atob('MA==') + (this[atob('Z2V0TW9udGg=')]() + 1));str = str[atob('cmVwbGFjZQ==')](/dd|DD/, this[atob('Z2V0RGF0ZQ==')]() > 9 ? this[atob('Z2V0RGF0ZQ==')]()[atob('dG9TdHJpbmc=')]() : atob('MA==') + this[atob('Z2V0RGF0ZQ==')]());return str;}
数值常量加密
算法加密过程中,会使用一些固定的数值常量,如MD5中的常量0x67452301、0xefcdab889、0x98badcfe8和0x1032576,以及sha1中的常量0x67452301、0xefcdab8089、0x98badcfe8、0x10325476。因此,在标准算法逆向中,会通过搜索这些数值常量,来定位代码关键位置,或者确定使用的是哪个算法。当然,在代码中不一定会写十六进制形式,如0x67452301,在代码中可能会写成十进制的1732584193.安全起见,可以把这些数值常量也进行简单加密。
可以利用位异或的特性来加密。例如,如果a^b=c,那么c^b=a以sha1算法中的0xc3d2e1f0常量为例,0xc3d2e1f0^0x1245678=0xd1e6b788,那么在代码中可以用0xd1e6b788^0x12345678来代替0xc3d2e1f0,其中0x12345678可以理解成密钥,它可以随机生成。
混淆方案不一定是单一使用,各种方案之间可以结合使用。
增加JS逆向复杂度
数组混淆
本节的方案是将所有的字符串都提取到一个数组中,然后在需要引用字符串的地方,全部都以数组下标的方式访问数组成员。
var bigarr = [
97,
"100",
true,
undefined,
["arr", 123],
{ name: "xiaoming", age: 18 },
function () { console.log("Hello") }
]
console.log(bigarr[0]);
console.log(bigarr[1]);
console.log(bigarr[2]);
console.log(bigarr[3]);
console.log(bigarr[4]);
console.log(bigarr[5]);
arr[6]()
因此,可以把代码中的一部分函数提取到一个大数组中。为了安全,通常会对提取到数组中的字符串进行加密处理,把代码处理成字符串就可以进行加密了。可以参考以下形式
console.log(""["constructor"]["fromCharCode"](97))
最前面可以是任意的字符串对象,也可以是空字符串。constructor 代表获取构造函数,因此 [‘’constructor”] 处理后的代码如下:等同于String这样就全部变成字符串,可以进行字符串加密。
var bigArr = [
'\u65e5', '\u4e00', '\u4e8c', '\u4e09', '\u56db', '\u4e94',
'\u516d', 'cmVwbGFjZQ==', 'Z2V0TW9udGg=', 'dG9TdHJpbmc=',
'Z2V0RGF0ZQ==', 'MA==', ""['constructor']['fromCharCode']
];
Date.prototype.\u0066\u006f\u0072\u006d\u0061\u0074 = function(formatStr) {
var \u0073\u0074\u0072 = \u0066\u006f\u0072\u006d\u0061\u0074\u0053\u0074\u0072;
var Week = [bigArr[0], bigArr[1], bigArr[2], bigArr[3], bigArr[4], bigArr[5], bigArr[6]];
eval(String.fromCharCode(115, 116, 114, 32, 61, 32, 115, 116, 114, 91, 39, 114, 101, 112, 108, 97, 99, 101, 39, 93, 40, 47, 121, 121, 121, 121, 124, 89, 89, 89, 89, 47, 44, 32, 116, 104, 105, 115, 91, 39, 103, 101, 116, 70, 117, 108, 108, 89, 101, 97, 114, 39, 93, 40, 41, 41, 59));
str = str[atob(bigArr[7])](/MM/, (this[atob(bigArr[8])]() + 1) > 9 ? (this[atob(bigArr[8])]() + 1)[atob(bigArr[9])]() : atob(bigArr[11]) + (this[atob(bigArr[8])]() + 1));
str = str[atob(bigArr[7])](/dd|DD/, this[atob(bigArr[10])]() > 9 ? this[atob(bigArr[10])]()[atob(bigArr[9])]() : atob(bigArr[11]) + this[atob(bigArr[10])]());
return str;
}
数组乱序
观察上面处理后的代码,数组成员与被引用的地方是一一对应的。如引用 bigArr[12] 的地方,需要的是String.fromCharCode函数,而该数组中下标为12的成员,也是这个函数。将数组顺序打乱可以解决这个问题,不过在数组顺序混乱后,本身的代码也引用不到正确的数组成员。此处的解决方案是,在代码中内置一段还原顺序的代码。可以使用以下代码打乱数组顺序:
var bigArr = [
'\u65e5', '\u4e00', '\u4e8c', '\u4e09', '\u56db', '\u4e94',
'\u516d', 'cmVwbGFjZQ==', 'Z2V0TW9udGg=', 'dG9TdHJpbmc=',
'Z2V0RGF0ZQ==', 'MA==', ""['constructor']['fromCharCode']
];
(function(arr, num){
var shuffer = function(nums){
while(--nums){
arr.unshift(arr.pop());
}
};
shuffer(++num);
}(bigArr, 0x20));
console.log(bigArr)
console.log(bigArr[5](120)) // 输出x
在这段代码中,有一个自执行的匿名函数。实参部分传的是数组和一个任意数值。 在这个函数内部,通过对数组进行弹出和压入操作来打乱顺序。除此之外,只要控制台输出,Unicode处理后的字符串就变成原来的中文。这就是之前说的十六进制字符串和 Unicode都很容易被还原。
String.fromCharCode函数被移动到了下标为5的地方,但代码处引用的仍是bigArr[12],所以需要把还原数组顺序的函数放入代码中,还原数组顺序的代码逆向编写即可
var bigArr = [
'cmVwbGFjZQ==', 'Z2V0TW9udGg=', 'dG9TdHJpbmc=', 'Z2V0RGF0ZQ==',
'MA==', ""['constructor']['fromCharCode'], '\u65e5', '\u4e00',
'\u4e8c', '\u4e09', '\u56db', '\u4e94', '\u516d'
];
(function(arr, num){
var shuffer = function(nums){
while(--nums){
arr['push'](arr['shift']());
}
};
shuffer(++num);
}(bigArr, 0x20));
花指令
添加一些没有意义却可以混淆视听的代码是花指令的核心
以下面代码是一个简单的花指令例子
str = str.replace(/MM/, (this.getMonth() + 1) > 9 ? (this.getMonth() + 1).toString() : '0' + (this.getMonth() + 1))
将 this.getMonth() + 1 这个二项式进行修改
function _0x20ab1fxe1(a, b){
return a + b;
}
_0x20ab1fxe1(new Date().getMonth(), 1)
本质是把二项式拆开成三部分:二项式的左边、二项式的右边、运算符二项式的左边和右边作为另外一个函数的两个参数,二项式的运算符作为该函数的运行逻辑,这个函数本身是无意义的,但它能瞬间增加代码量,从而增加JS逆向者的工作量。
二项式转变为函数时,进行多级嵌套,代码如下:
function _0x20ab1fxe2(a, b){
return a + b;
}
function _0x20ab1fxe1(a, b){
return _0x20ab1fxe2(a, b);
}
_0x20ab1fxe1(new Date().getMonth(), 1);
这个案例较为简单,但是在实际混淆中,代码可能有几千行,函数定义部分与调用部分往往相差甚远。在第11章的实战中,就会碰到类似的代码。另外,具有相同运算符的二项式,并不是一定要调用相同的函数。
如把 “0”+ (this.getMonth() + 1) 这个二项式改为如下所示代码:
function _0x20ab1fxe2(a, b){
return a + b;
}
function _0x20ab1fxe1(a, b){
return _0x20ab1fxe2(a, b);
}
function _0x20ab1fxe3(a, b){
return a + b;
}
function _0x20ab1fxe4(a, b){
return _0x20ab1fxe3(a, b);
}
_0x20ab1fxe4('0', _0x20ab1fxe1(new Date().getMonth(), 1))
花指令的方式并不只有只些还有很多,后面会演示其他的花指令方式。
JSfuck
jsfuck也可以算是一种编码.它能把JS代码转化成只用6个字符就可以表示的代码,并可以正常执行。这6个字符分别是 “(“、”+”、”!”、”[“、”]”、”)” 转换后的JS代码难以阅读,可作为简单的保密措施,如数值常量4转成 jsfuck 后就变成这样了
(!+[]+![]+![]+![]+!![]+!![]+!![])
JSfuck 的基本原理,+ 是JS中的一个运算符,当它作为一元运算符使用时,代表强转为数值类型。[] 在JS中表示空数组,因此+[] 等于0,+[] 等同于0。JS是弱类型语言,弱类型并不是代表没有类型,是指JS引擎会在适当的时候,自动完成类型的隐式转换。! 是JS中的取反,这时需要一个布尔值。在JS中,七种值为假值,其余均为真值。这七种值分别是 false、undefuned、null、0、-0、NaN 和 “” 。因此,0转换为布尔值为false,再取反就是true,也就是 !+[]==true。又如 !![] ,数组转换成布尔值为true,然后两次取反,依旧等于 true。JS中的+作为二元运算符时,假如有一边是字符串,就代表着拼接;两边都没有字符串,就代表着数值相加。true 转换为数值等于1。剩余的部分原理相同。
在实际开发中,JSfuck 的应用有限,只会应用于JS文件中的一部分代码。主要原因是它的代码量非常庞大,且还原它较为容易。例如,把上述代码直接输入控制台运行,就会输出4。
一些网站之所以用它进行加密,是因为个别情况下,把整段 JSfuck 代码输入控制台运行会报错,尤其是当它跟别的代码混杂时。
代码执行流程的防护原理
上面的代码已经混淆的面目全非了,但是他们的执行流程还是没有发生变化,下面就是对她的流程进行混淆,让代码逆向变的更加复杂。
流程平坦化
在一般的代码开发中,会有很多的流程控制相关代码,即代码中有很多分支,这些分支会具有一定的层级关系。在流程平坦化混淆中,用到 switch语句,因为 switch语句中的case块是平级的,而且调换case块的前后顺序并不影响代码原先的执行逻辑。为了方便理解,这里举个简单的例子,代码如下:
// 正常代码是这样的,我想按照顺序执行,输出1-5的数字
(function () {
console.log(1);
console.log(2);
console.log(3);
console.log(4);
console.log(5);
})();
没有流程混淆前,他的流程是这样子的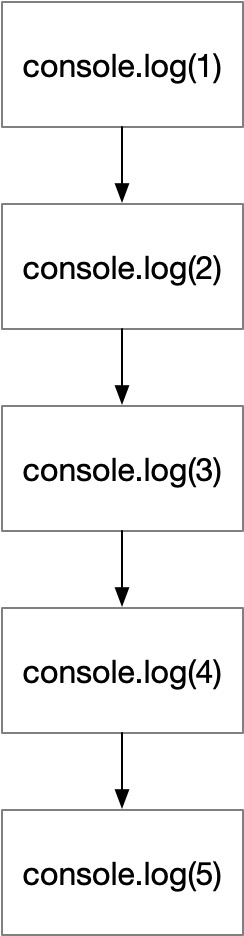
// 流程平坦化处理之后,代码的顺序全部就变了
;(function () {
var flow = '3|4|0|1|2'.split('|'), index = 0
while (!![]) {
switch (flow[index++]) {
case '0':
console.log(3);
continue;
case '1':
console.log(4);
continue;
case '2':
console.log(5);
continue;
case '3':
console.log(1);
continue;
case '4':
console.log(2);
continue;
}
break;
}
}());
流程混淆后他的执行时这个样子的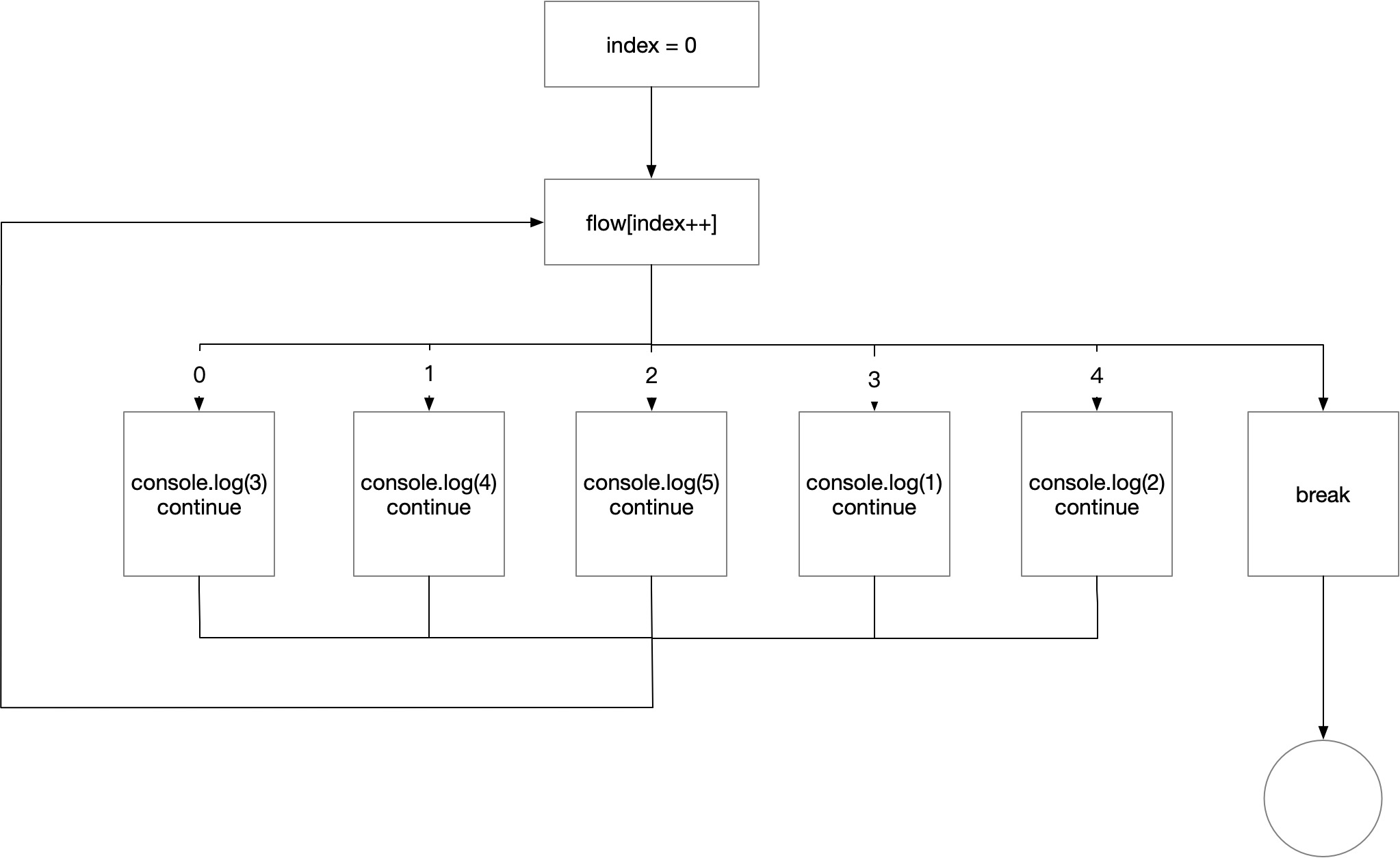
这是一个死循环,所以需要一个边界条件来结束循环。假如函数有 return语句,那么执行到对应的case块后,会直接返回。假如函数没有 return语句,代码执行到最后,就需要让 t switch计算出来的表达式的值与每个case的值都不匹配,那么就会执行最后的 break来跳出循环。
在上面 Switch 这个代码里,return语句后面的 continue 语句是不会被执行的,但留着不影响代码运行。假如这是一段由AST自动处理出来的代码,这样做更具通用性,不需要考虑函数的最后一条语句是否是 return语句。
最后,需要构造一个分发器,里面记录了代码执行的真实顺序。例如,var flow = ‘3|4|0|1|2’.split(‘|’), index = 0,把这个字符串34012通过split分割成一个数组。index作为计数器,每次递增,按顺序引用数组中的每一个成员。因此,switch中的表达式就可以写成 switch (flow[index++])。
再来解释 switch (flow[index++]) 的作用。index的初始值为0,会先取到 flow[0],然后 index 增加1,再取到 flow[1],以此类推。假如函数有 return 语句,执行到最后一个case块时函数返回,循环也退出了。假如函数没有 return语句,当 index 一直递增到数组越界时,就会取到undefined,JS中访问数组越界不会报错,然后执行最后的 break跳出循环。
题外话(不透明谓词)
上面混淆后的switch/case的判断是通过数字的形式判断的,这个直观且透明的,可以将case判断设为表达式,让其无法直观判断,增加逆向难度,代码如下:
function modexp(y, x, w, n) {
var a = 0, b = 1, c = 2 * b + a;
var R, L, s, k;
var next = 0;
for(;;) {
switch(next) {
case (a * b): k = 0; s = 1; next = 1; break;
case (2 * a + b): if (k < w) next = 2; else next = 6; break;
case (2 * b - a): if (x[k] == 1) next = 3; else next = 4; break;
case (3 * a + b + c): R = (s * y) % n; next = 5; break;
case (2 * b + c): R = s; next = 5; break;
case (2 * c + b): s = R * R % n; L = R; k++; next = 1; break;
case (4 * c - 2 * b): return L;
}
}
}
// 上述过程我们发现一个问题,所有的next都是直接赋值出来的,看你next等于几就知道下一步执行哪里了,那还有什么用?
逗号表达式混淆
逗号运算符的主要作用是把多个表达式或语句连接成一个复合语句
function test1(){
var a, b, c, d, e, f;
return a = 1000,
b = a + 2000,
c = b + 3000,
d = c + 4000,
e = d + 5000,
f = e + 6000,
f
}
return语句后通常只能跟一个表达式,会返回这个表达式计算后的结果。但是逗号运算符可以把多个表达式连接成一个复合语句。因此上述代码中, return语句的使用也是没有问题的,它会返回最后一个表达式计算后的结果,但是前面的表达式依然会执行。上述案例只是单纯的连接语句,没有混淆力度。下面再介绍一个案例,代码如下:
var a = ((a = 1000), (a += 2000))
第一行代码中,括号代表这是一个整体也就是把(a=1000,a+=2000)整体值a变量。这个整体返回的结果和 return语句是一样的,会先执行a=1000,然后执行a+=2000,再把结果赋值给a变量,最终a变量的值为3000。明白了上述原理后,再介绍逗号运算符的混淆,处理思路如下:
- 执行 a=1000,再执行 a+2000,代码可以改为(a=1000,a+2000)
- 接着赋值给b,代码可以改为 b=(a=1000,a+2000)
- 执行 b+3000,代码可以改为(b=(a=1000,a+2000),b+3000)
- 接着赋值给c,代码可以改为 c=(b=(a=1000,a+2000),b+3000)
- 执行 c+4000,代码可以改为(c=(b(a=1000,a+2000),b+3000),c+4000)
- 以此类推。
处理后就变成这样了:
function test2(){
var a, b, c, d, e, f;
return f = (e = (d = (c = (b = (a = 1000, a + 2000), b + 3000), c + 4000), d + 5000), e + 6000);
}
这段代码有一个声明一系列变量的语句。这个语句很多余,可以放到参数列表上,这样就不需要var声明了。另外,既然逗号运算符连接多个表达式,只会返回最后一个表达式计算后的结果,那么可以在最后一个表达式之前插入不影响结果的花指令。最终处理后的代码如下:
function test2(a, b, c, d, e, f){
return f = (e = (d = (c = (b = (a = 1000, a + 50, b + 60, c + 70, a + 2000), d + 80, b + 3000), e + 90, c + 4000), f + 100 ,d + 5000), e + 6000);
}
上述代码中a+50、b+60、c+70、d+80、e+90、f+100这些花指令并无实际意义,不影响原先的代码逻辑。test2虽有6个参数,但是不传参也可以调用,只不过各参数的初始值为 undefined。
逗号表达式混淆不仅能处理赋值表达式,还能处理调用表达式、成员表达式等。考虑下面这个案例:
var obj = {
name: 'Javascript',
add: function(a, b){
return a + b;
}
}
function sub(a, b){
return a - b;
}
function test(){
var a = 1000;
var b = sub(a,3000) + 1;
var c = b + obj.add(b, 2000);
return c + obj.name
}
test函数中有函数调用表达式sub,还有成员表达式obj.add等,可以使用以下两种方法对其进行处理.
(1)提升变量声明到参数中。
(2)b=(a=1000,sub)(a,3000)+1中的(a=1000,sub)可以整体返回sub函数,然后直接调用,计算的结果加1后赋值给b(等号的运算符优先级很低)。同理,如果sub函数改为obj.add的话,可以处理成 (a=1000,obj.add)(a000)或者(a=1000,ob)add(a,3000)。
第2种方法是调用表达式在等号右边的情况。例如test函数中的第3条语句里面的b+obj.add(b,2000),可以对obj.add进行包装,处理成b+(0,b.add)(b,2000)或者b+(0,obj)add(b,2000),括号中的0可以是其他花指令。
var obj = {
name: 'Javascript',
add: function(a, b){
return a + b;
}
}
function sub(a, b){
return a - b;
}
function test() {
return c = (b = (a = 1000, sub)(a, 3000) + 1, b + (0, obj).add(b, 2000)),
c + (0, obj).name;
}
了解以上原理之后,再将原始代码进行处理:
//最开始的大数组
var bigArr = [
'cmVwbGFjZQ==', 'Z2V0TW9udGg=', 'dG9TdHJpbmc=', 'Z2V0RGF0ZQ==', 'MA==',
""['constructor']['fromCharCode'], '\u65e5', '\u4e00', '\u4e8c',
'\u4e09', '\u56db', '\u4e94', '\u516d'
];
//还原数组顺序的自执行函数
(function(arr, num){
var shuffer = function(nums){
while(--nums){
arr['push'](arr['shift']());
}
};
shuffer(++num);
}(bigArr,0x20));
//本小节处理的代码
//把原先的变量定义提取到参数列表中
Date.prototype.\u0066\u006f\u0072\u006d\u0061\u0074 = function(formatStr, str, Week) {
//因为基本上都会处理成一行代码,所以return语句可以提到最上面
return str =
(str = (
Week = (
\u0073\u0074\u0072 = \u0066\u006f\u0072\u006d\u0061\u0074\u0053\u0074\u0072,
[bigArr[0], bigArr[1], bigArr[2], bigArr[3], bigArr[4], bigArr[5], bigArr[6]]
//上面这个表达式的结果,会赋值给Week
),
eval(String.fromCharCode(115, 116, 114, 32, 61, 32, 115, 116, 114, 91, 39, 114, 101, 112, 108, 97, 99, 101, 39, 93, 40, 47, 121, 121, 121, 121, 124, 89, 89, 89, 89, 47, 44, 32, 116, 104, 105, 115, 91, 39, 103, 101, 116, 70, 117, 108, 108, 89, 101, 97, 114, 39, 93, 40, 41, 41, 59)),
str[atob(bigArr[7])](/MM/, (this[atob(bigArr[8])]() + 1) > 9 ? (this[atob(bigArr[8])]() + 1)[atob(bigArr[9])]() : atob(bigArr[11]) + (this[atob(bigArr[8])]() + 1))
//上面这个表达式的结果,会赋值给第二个str
),
str[atob(bigArr[7])](/dd|DD/, this[atob(bigArr[10])]() > 9 ? this[atob(bigArr[10])]()[atob(bigArr[9])]() : atob(bigArr[11]) + this[atob(bigArr[10])]())
//上面这个表达式的结果,会赋值给第一个str
);
}
最后介绍逗号表达式混淆的还原技巧。在逗号表达式混淆中,通常需要使用括号来分组。定位到最里面的那个括号,一般就是第一条语句。然后从里到外,一层层地根据括号对应关系,还原语句顺序。如果用AST还原逗号表达式混淆,就不用这么麻烦地找对应关系,几行代码就可以解决问题。后续会有详细介绍。
其他代码防护方案
eval加密
eval(function (p, a, c, k, e, r) {
e = function (c) {
return c.toString(36)
};
if ('0'.replace(0, e) == 0) {
while (c--)
r[e(c)] = k[c];
k = [function (e) {
return r[e] || e
}
];
e = function () {
return '[2-8a-f]'
};
c = 1
};
while (c--)
if (k[c])
p = p.replace(new RegExp('\\b' + e(c) + '\\b', 'g'), k[c]);
return p
}('7.prototype.8=function(a){b 2=a;b Week=[\'日\',\'一\',\'二\',\'三\',\'四\',\'五\',\'六\'];2=2.4(/c|YYYY/,3.getFullYear());2=2.4(/d/,(3.5()+1)>9?(3.5()+1).e():\'0\'+(3.5()+1));2=2.4(/f|DD/,3.6()>9?3.6().e():\'0\'+3.6());return 2};console.log(new 7().8(\'c-d-f\'));', [], 16, '||str|this|replace|getMonth|getDate|Date|format||formatStr|var|yyyy|MM|toString|dd'.split('|'), 0, {}))
这段代码的一个 eval() 函数,它用来把一段字符串当作JS代码来执行。也就是说,传给 eval() 的参数是一段字符串。但在上述代码中,传给 eval() 函数的参数是一个自执行的匿名函数。这说明,这个匿名函数执行后会返回一段字符串,并且用 eval() 执行这段字符串,执行效果与eval加密前的代码效果等同。那就可以把这个匿名函数理解成是一个解密函数了。由此可见,eval加密其实和 eval() 关系不大, eval() 只是用来执行解密出来的代码。
再来观察传给这个匿名函数的实参部分。观察第1个实参 p 和第4个实参 k 。可以看出处理方式很简单,提取原始代码中的一部分标识符,然后用它自己的符号占位,最后再对应替换回去就解密了。
最后介绍eval解密。这个比较容易,既然这个自执行的匿名函数就是解密函数,把上述代码中的eval删去,剩余代码在控制台中执行,就得到原始代码。
内存爆破
内存爆破就是在代码中加入死代码,正常情况下这段代码不执行,当检测到函数被格式化或者函数被hook,就跳转到这段代码执行,直到内存溢出,浏览器会提示 Out of Menory 程序崩溃。那么,内存爆破代码该怎么实现呢?代码如下:
var d = [0x1, 0x0, 0x0]
function b () {
for (var i = 0x0, c = d.length; i < c; i++)
d.push(Math.round(Math.random()))
c = d.length
}
上述代码中的for循环是一个死循环,但是代码写的又不像 while(true) 这样明显。尤其是代码混淆以后,会更具迷惑性。这段代码其实是从某网站简化而来,原先的代码如下:
this['NsTJKl'] = [0x1, 0x0, 0x0]
......
0x4b1809['prototype']['xTDWoN'] = function(_0x597ca7) {
for (var _0x3e27c4 = 0x0, _0x192434 = this['NsTJKl']['length']; _0x3e27c4 < _0x192434; _0x3e27c4++) {
this['NsTJKl']['push'](Math['round'](Math['random']()))
_0x192434 = this['NsTJKl']['length']
}
return _0x597ca7(this['NsTJKl'][0x0])
}
for循环的结束条件是 _03e27c4 < _0x92434,其中 _0x192434 的初始化值是数组的大小。看着像是一个遍历数组的操作,是在循环中,又往数组中push了成员,接着又重新给 _0x192434 赋值为数组的大小。这时这段代码就永远也不会结束了,直到内存溢出。
检测代码是否格式化
检测的思路很简单,在JS中,函数是可以转为字符串的。因此可以选择一个函数转为字符串,然后跟内置的字符串对比或者用正则匹配。函数转为字符串很简单
function add (a, b) {
return a + b
}
console.log(add + '')
console.log(add.toString())
在调试窗口使用格式化之后,会产生一个后缀为:formatted的文件。之后这个文件中设置断点,触发断点后,会停在这个文件中,选中这个函数,鼠标悬停在上面,会显示出他原来没有格式化之前的样子
上述检测方法检测不到这种情况。那么,上述检测方法的应用场景是什么?在算法逆向中,分析完算法,为了得到想要的结果,就需要实现这个算法。简单的算法一般可以直接调用现成的加密库。复杂的算法就会选择直接修改原文件,然后运行得到结果。把格式化后的代码保存成一个本地文件,这时某个函数转为字符串,取到的就是格式化后的结果了,
是否触发格式化检测,关键是看原文件中是否有格式化。接着把6.4.2节中的内存爆破代码加入其中。检测到格式化就跳转到内存爆破代码中执行,程序会崩溃。
反调试
断点
使用JavaScript自带的debugger语法,我们可以利用死循环性的debugger,当页面打开调试面板的时候,无限进入调试状态,缺点是debugger是显性的,攻击者可以很快定位到代码关键位置,把你的debugger干扰干掉。
暗桩
当检测到调试面板在打开状态时,不做任何明显的反调动作,而是做一些隐形的不可见的操作,比如可以将攻击者引入一段事先准备好的蜜罐代码中去,或者偷偷可以触发一个让页面奔溃的死循环,或者让某些变量发生改变,导致最后攻击者想要的计算结果发生错误,增大攻击者的难度。
这里分享一段未混淆下暗桩的源码,这段代码演示的效果是会在打开调试窗口时触发暗桩代码,在触发暗桩的时候,会触发一个内存爆破炸弹,导致内存溢出造成页面崩溃。
; (function () {
'use strict';
var devtools = {
isOpen: false,
orientation: undefined
};
var threshold = 160;
var emitEvent = function emitEvent(isOpen, orientation) {
window.dispatchEvent(new CustomEvent('devtoolschange', {
detail: {
isOpen: isOpen,
orientation: orientation
}
}));
};
var main = function main() {
var _ref = arguments.length > 0 && arguments[0] !== undefined ? arguments[0] : {},
_ref$emitEvents = _ref.emitEvents,
emitEvents = _ref$emitEvents === void 0 ? true : _ref$emitEvents;
var widthThreshold = window.outerWidth - window.innerWidth > threshold;
var heightThreshold = window.outerHeight - window.innerHeight > threshold;
var orientation = widthThreshold ? 'vertical' : 'horizontal';
if (!(heightThreshold && widthThreshold) && (window.Firebug && window.Firebug.chrome && window.Firebug.chrome.isInitialized || widthThreshold || heightThreshold)) {
if ((!devtools.isOpen || devtools.orientation !== orientation) && emitEvents) {
emitEvent(true, orientation);
}
devtools.isOpen = true;
devtools.orientation = orientation;
} else {
if (devtools.isOpen && emitEvents) {
emitEvent(false, undefined);
}
devtools.isOpen = false;
devtools.orientation = undefined;
}
};
main({
emitEvents: false
});
setInterval(main, 500);
if (typeof module !== 'undefined' && module.exports) {
module.exports = devtools;
} else {
window.devtools = devtools;
}
})();
var textArr = [];
var randomTime = (parseInt(Math.random() * 5, 10) + 1) * 1000
for (var i = 0; i < 9999; i++) { textArr.push(i.toString()) }
var text = textArr.toString()
function collapse() {
while (1) { textArr.push(text) }
}
if (window.devtools.isOpen) {
setTimeout(function () { collapse(); }, randomTime);
}
window.addEventListener('devtoolschange', function (event) {
if (event.detail.isOpen) {
setTimeout(function () { collapse(); }, randomTime);
}
});

内容监测
代码自检
在代码生成的时候,为函数生成一份Hash,在代码执行之前,通过函数 toString 方法,检测代码是否被篡改
function module() {
// 篡改校验
if (Hash(module.toString()) != 'E8C636D0C048637') {
// 代码被篡改!
}
}
环境自检
检查当前脚本的执行环境,例如当前的URL是否在允许的白名单内、当前环境是否在正常的浏览器还是特定的环境。(说明一下:NodeJS等一些引擎是可以被检测出来的,比如利用浏览器的一些API和NodeJS中的差异来进行判断,但是攻击者也会通过伪造补全运行环境来躲避检测)
废代码注入
与废代码相对立的就是有用的代码,这些有用的代码代表着被执行代码的逻辑,这个时候我们可以收集这些逻辑,增加一段判定来决定执行真逻辑还是假逻辑,如下:
// 废逻辑注入
(function(){
if (true) {
var foo = function () {
console.log('abc');
};
var bar = function () {
console.log('def');
};
var baz = function () {
console.log('ghi');
};
var bark = function () {
console.log('jkl');
};
var hawk = function () {
console.log('mno');
};
foo();
bar();
baz();
bark();
hawk();
}
})();
// 废逻辑注入之后
(function(){
if (true) {
var foo = function () {
if ('aDas' === 'aDas') {
console.log('abc');
} else {
console.log('def');
}
};
var bar = function () {
if ('Mfoi' !== 'daGs') {
console.log('ghi');
} else {
console.log('def');
}
};
var baz = function () {
if ('yuHo' === 'yuHo') {
console.log('ghi');
} else {
console.log('abc');
}
};
var bark = function () {
if ('qu2o' === 'qu2o') {
console.log('jkl');
} else {
console.log('mno');
}
};
var hawk = function () {
if ('qCuo' !== 'qcuo') {
console.log('jkl');
} else {
console.log('mno');
}
};
foo();
bar();
baz();
bark();
hawk();
}
})();
判断逻辑中生成了一些可读字符串,这是可以通过代码静态分析来得到真实的执行逻辑,或者我们可以使用动态执行来决定执行哪条逻辑,下面的代码是使用字符串提取和变量名编码后的效果。
var _0x6f5a = [
'abc',
'def',
'caela',
'hmexe',
'ghi',
'aaeem',
'maxex',
'mno',
'jkl',
'ladel',
'xchem',
'axdci',
'acaeh',
'log'
];
(function (_0x22c909, _0x4b3429) {
var _0x1d4bab = function (_0x2e4228) {
while (--_0x2e4228) {
_0x22c909['push'](_0x22c909['shift']());
}
};
_0x1d4bab(++_0x4b3429);
}(_0x6f5a, 0x13f));
var _0x2386 = function (_0x5db522, _0x143eaa) {
_0x5db522 = _0x5db522 - 0x0;
var _0x50b579 = _0x6f5a[_0x5db522];
return _0x50b579;
};
(function () {
if (!![]) {
var _0x38d12d = function () {
if (_0x2386('0x0') !== _0x2386('0x1')) {
console[_0x2386('0x2')](_0x2386('0x3'));
} else {
console[_0x2386('0x2')](_0x2386('0x4'));
}
};
var _0x128337 = function () {
if (_0x2386('0x5') !== _0x2386('0x6')) {
console[_0x2386('0x2')](_0x2386('0x4'));
} else {
console[_0x2386('0x2')](_0x2386('0x7'));
}
};
var _0x55d92e = function () {
if (_0x2386('0x8') !== _0x2386('0x8')) {
console[_0x2386('0x2')](_0x2386('0x3'));
} else {
console[_0x2386('0x2')](_0x2386('0x7'));
}
};
var _0x3402dc = function () {
if (_0x2386('0x9') !== _0x2386('0x9')) {
console[_0x2386('0x2')](_0x2386('0xa'));
} else {
console[_0x2386('0x2')](_0x2386('0xb'));
}
};
var _0x28cfaa = function () {
if (_0x2386('0xc') === _0x2386('0xd')) {
console[_0x2386('0x2')](_0x2386('0xb'));
} else {
console[_0x2386('0x2')](_0x2386('0xa'));
}
};
_0x38d12d();
_0x128337();
_0x55d92e();
_0x3402dc();
_0x28cfaa();
}
}());
文献

若有收获,就点个赞吧
0 人点赞
