traverse组件用来遍历AST,简单说就是把AST上的各个节点都运行一遍,但单纯把节点都运行一遍是没有意义的,所以traverse需要配合visitor使用。
visitor是一个对象,它可以定义一些方法,用来过滤节点。接下来用一个实际案来解traverse和visitor的效果,代码如下;
const fs = require('fs');const parser = require("@babel/parser");const traverse = require("@babel/traverse").default;const t = require("@babel/types");const generator = require("@babel/generator").default;const jscode = fs.readFileSync("./demo.js", {encoding: "utf-8"});let ast = parser.parse(jscode);let visitor = {};visitor.FunctionExpression = function(path){console.log("javaScriptAST");};traverse(ast, visitor);let code = generator(ast).code;fs.writeFile('./demoNew.js', code, (err) => {});// 输出 javaScriptAST
首先声明对象,对象的名字可随意定义,再给对象增加一个名为FunctionExpression的
方法,它的名字是需要遍历的节点类型,需要注意大小写。traverse会遍历所有的节点,当节点类型为FunctionExpression时,调用visitor中相应的方法。如果想要处理其他节点类型,例如Identifier,可以在visitor中继续定义方法,以Identifier命名即可。visitor中的方法接收一个参数,traverse在遍历时,会把当前节点的Path对象传给它,传过来的是Path对象而非节点(Node)。最后把visitor作为第二个参数传到traverse里,传给traverse的第一个参数是整个AST。这段代码的意思是,从头开始遍历AST中的所有节点,过滤出
FunctionExpression节点,执行相应的方法。在原始代码中,有两个FunctionExpression节点,因此,会输出两次 javaScriptAST。
定义visitor的方式有以下三种,最常用的是visitor2这种形式。
const visitor1 = {FunctionExpression: function (path) {console.log("javaScriptAST");}};const visitor2 = {FunctionExpression (path) {console.log("javaScriptAST");}};const visitor3 = {FunctionExpression: {enter(path) {console.log("javaScriptAST");}}};
在visitor3中,存在一个enter。在遍历节点的过程中,有两次机会来访问一个节点,即进入节点时(enter)与退出节点时(exit)。以原始代码中的add函数为例,节点的遍历过程可描述如下:
进入FunctionExpression进入Identifier(params[0])走到尽头退出Identifier(params[0])进入Identifier(params[1])走到尽头退出Identifier(params[1])进入BlockStatement(body)进入ReturnStatement(body)进入BinaryExpression(argument)进入BinaryExpression(left)进入Identifier(left)走到尽头退出Identifier(left)进人Identifier(right)走到尽头退出Identifier(right)退出BinaryExpression(left)进入NumericLiteral(right)走到尽头退出NumericLiteral(right)退出BinaryExpression(argument)退出ReturnStatement(body)退出BlockStatement(body)退出FunctionExpression
正确选择节点处理时机,有助于提高代码效率。可以看出traverse是一个深度优先的遍历过程。因此,如果存在父子节点,那么enter的处理时机是先处理父节点,再处理子节点。而exit的处理时机是先处理子节点,再处理父节点。traverse默认是在enterI时处理,
如果要在exit时处理,必须在visitor中写明。
const fs = require('fs');const parser = require("@babel/parser");const traverse = require("@babel/traverse").default;const t = require("@babel/types");const generator = require("@babel/generator").default;const jscode = fs.readFileSync("./demo.js", {encoding: "utf-8"});let ast = parser.parse(jscode);const visitor3 = {FunctionExpression: {enter(path) {console.log("javaScriptAST enter");},exit(path) {console.log("javaScriptAST exit");}}};traverse(ast, visitor3);let code = generator(ast).code;fs.writeFile('./demoNew.js', code, (err) => {});
还可以把方法名用 “|” 连接成FunctionExpression | BinaryExpression 形式的字符串,把同一个函数应用到多个节点,例如:
const fs = require('fs');const parser = require("@babel/parser");const traverse = require("@babel/traverse").default;const t = require("@babel/types");const generator = require("@babel/generator").default;const jscode = fs.readFileSync("./demo.js", {encoding: "utf-8"});let ast = parser.parse(jscode);const visitor = {"FunctionExpression|BinaryExpression"(path){console.log("javaScriptAST");}};traverse(ast, visitor);let code = generator(ast).code;fs.writeFile('./demoNew.js', code, (err) => {});
也可以把多个函数应用于同一个节点。原先是把一个函数赋值给enter或者exit,现在改为函数的数组,会按顺序依次执行。示例代码如下:
const fs = require('fs');const parser = require("@babel/parser");const traverse = require("@babel/traverse").default;const t = require("@babel/types");const generator = require("@babel/generator").default;const jscode = fs.readFileSync("./demo.js", {encoding: "utf-8"});let ast = parser.parse(jscode);function func1(path){console.log('func1');}function func2(path){console.log('func2');}const visitor = {FunctionExpression: {enter: [func1, func2]}};traverse(ast, visitor);let code = generator(ast).code;fs.writeFile('./demoNew.js', code, (err) => {});
traverse并非必须从头遍历,它可在任意节点向下遍历。例如,想要把代码中所有函数的第一个参数改为x,代码如下:
const fs = require('fs');const parser = require("@babel/parser");const traverse = require("@babel/traverse").default;const t = require("@babel/types");const generator = require("@babel/generator").default;const jscode = fs.readFileSync("./demo.js", {encoding: "utf-8"});let ast = parser.parse(jscode);const updateParamNameVisitor = {Identifier(path) {if (path.node.name === this.paramName) {path.node.name = "x";}}};const visitor = {FunctionExpression(path) {const paramName = path.node.params[0].name;path.traverse(updateParamNameVisitor, {paramName});}};traverse(ast, visitor);let code = generator(ast).code;fs.writeFile('./demoNew.js', code, (err) => {});
处理后的输出结果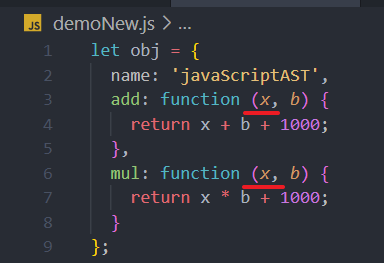
这段代码先用traverse根据visitor去遍历所有节点。当得到 FunctionExpression 节点时,用 path.traverse 根据 updateParamNameVisitor 去遍历当前节点下的所有子节点,然后修改与函数第一个参数相同的标识符。在使用path.traverse时,还可以额外传入一个对象,在对应的visitor中用this去引用它。其中 path.node 才是当前节点,所以path.node.params[0].name可以取出函数的第一个参数名。

若有收获,就点个赞吧
0 人点赞
