认识动态规划
- 动态规划(Dynamic Programming)算法的核心思想是:将大问题划分为小问题进行解决,从而一步步获取最优解的处理算法
- 动态规划算法与分治算法类似,其基本思想也是将待求解问题分解成若干个子问题,先求解子问题,然后从这些子问题的解得到原问题的解
- 与分治法不同的是,适合于用动态规划求解的问题,经分解得到子问题往往不是互相独立的。 ( 即下一个子阶段的求解是建立在上一个子阶段的解的基础上,进行进一步的求解 )
- 动态规划可以通过填表的方式来逐步推进,得到最优解.



借0-1背包问题深刻理解动态规划

如果每种物品只能选 0 个或 1 个(即要么将此物品装进包里要么不装),则此问题称为 0-1 背包问题;如果不限每种物品的数量,则称为无界(或完全)背包问题,我们这里暂时只讨论0-1背包问题
我们的题目是
背包的填表过程
我得说一下,这个填表的逻辑:
物品数量是从上而下不断增加的,也就是说吉他那一行只可以取吉他,音响那一行可以去音响和吉他,电脑那一行可以取电脑,音响和吉他
至于为什么第一行和第一列都是以0标记,你仔细分析可以知道0个物品当然价值都是0,0磅代表没有物品可以填入,价值也就是0。代码 表示为v[i][0]=v[0][j]=0;
动态规划就是过程最优,以至结果最优,就是每一步行走都是有对已有数据的观察比较得到的结果,下面介绍这两行关键的代码或公式
当 w[i] > j 时:v[i][j] = v[i-1][j]// 当准备加入新增的商品的容量大于 当前背包的容量时,就直接使用上一个单元格的装入策略//既然无法装入新物品,就意味着本行提供的新物品相当于没有,自然要取上一格的最优结果//而之所以是上一格,而不是上一行,是受到那一列的背包容量的限制当 j >= w[i]时: v[i][j] = max{v[i-1][j], v[i]+v[i-1][j-w[i]]}//不得不说,这里公式还比较复杂,但拆开来看就比较容易理解// 当 准备加入的新增的商品的容量小于等于当前背包的容量,是本公式的前提条件v[i-1][j]: 就是上一个单元格的装入的最大值v[i] : 表示当前商品的价值v[i-1][j-w[i]] : 装入i-1商品,到剩余空间j-w[i]的最大值当 j >=w [i]时: v[i][j] = max{v[i-1][j], v[i]+v[i-1][j-w[i]]} :
为了更具体一点,简单举两个实例,带入数据测试一下,建议参看前面已推出的价值表
v[1][1] =15001. i = 1, j = 12. w[i] = w[1] = 1w [1] = 1 j = 1 v[i][j]=max{v[i-1][j], v[i]+v[i-1][j-w[i]]} :v[1][1] = max {v[0][1], v[1] + v[0][1-1]} = max{0, 1500 + 0} = 1500--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------v[3][4]1. i = 3;j = 4w[i] = w[3] =3 j = 4j = 4 >= w[i] = 3 => 4 >= 3v[3][4] = max {v[2][4], v[3] + v[2][1]} = max{3000, 2000+1500} = 2000+1500
思路清晰,代码上场
package com.xy.dynamic;import java.util.Iterator;public class KnapsackProblem {public static void main(String[] args) {//先用数组表示已有的信息int[] w = {1,4,3};//重量信息int[] val = {1500,3000,2000};//价值信息int m = 4; //总重量最大值int n = val.length;//总商品数量//分析知道,第一行和第一列都是以0标记,所以创建二维数组的第一步是要干这事int [][] sumval = new int[n+1][m+1];//之所以要+1操作,其原因就是第一行和第一列都是以0标记for (int i = 0; i < sumval.length; i++) { //设置第一列为0sumval[i][0] = 0;}for (int j = 0; j < sumval[0].length; j++) { //设置第一行为0sumval[0][j] = 0;}//基本操作以后,实际就是带入公式就行,但是大家要注意,我们在分析得出公式的时候没有考虑到第一行和第一列都是以0标记的情况//所以,这里我们要对公式进行一些调整for (int i = 1; i < sumval.length; i++) {for (int j = 1; j < sumval[0].length; j++) {if (w[i-1] > j) {sumval[i][j] = sumval[i-1][j];}else {sumval[i][j] = Math.max(sumval[i-1][j],val[i-1]+sumval[i-1][j-w[i-1]]);}}}for (int i = 0; i < sumval.length; i++) {for (int j = 0; j < sumval[0].length; j++) {System.out.print(sumval[i][j]);System.out.print("\t");}System.out.println("\n");}}}

问题1:代码中关于数组长度那部分有些不了解,测试一下,清晰明了
1.不确定行数,得到的结果就是行数 2.确定行数,得到的结果就是列数
问题二:v[i][0]=v[0][j]=0;其代码表达本不是必要的
既然int声明数组默认值为0,自然就是多次一举了,我自己也做删除代码测试,效果一样
这里我就不把代码复制过来,不行你删除一下试一试
第一行和第一列为0是事实,但价值就在让公式具有普遍性,因为公式你明显有借用前面结果的操作,而这行和列的置0就弥补了这个问题,图像呈现一种包裹状态
上述代码只是简单操作,也许我们还想实现,具体是哪几个商品加进去的,实际上就是要求我们记录路径
package com.atguigu.dynamic;
public class KnapsackProblem {
public static void main(String[] args) {
// TODO Auto-generated method stub
int[] w = {1, 4, 3};//物品的重量
int[] val = {1500, 3000, 2000}; //物品的价值 这里val[i] 就是前面讲的v[i]
int m = 4; //背包的容量
int n = val.length; //物品的个数
//创建二维数组,
//v[i][j] 表示在前i个物品中能够装入容量为j的背包中的最大价值
int[][] v = new int[n+1][m+1];
//为了记录放入商品的情况,我们定一个二维数组
int[][] path = new int[n+1][m+1];
//初始化第一行和第一列, 这里在本程序中,可以不去处理,因为默认就是0
for(int i = 0; i < v.length; i++) {
v[i][0] = 0; //将第一列设置为0
}
for(int i=0; i < v[0].length; i++) {
v[0][i] = 0; //将第一行设置0
}
//根据前面得到公式来动态规划处理
for(int i = 1; i < v.length; i++) { //不处理第一行 i是从1开始的
for(int j=1; j < v[0].length; j++) {//不处理第一列, j是从1开始的
//公式
if(w[i-1]> j) { // 因为我们程序i 是从1开始的,因此原来公式中的 w[i] 修改成 w[i-1]
v[i][j]=v[i-1][j];
} else {
//说明:
//因为我们的i 从1开始的, 因此公式需要调整成
//v[i][j]=Math.max(v[i-1][j], val[i-1]+v[i-1][j-w[i-1]]);
//v[i][j] = Math.max(v[i - 1][j], val[i - 1] + v[i - 1][j - w[i - 1]]);
//为了记录商品存放到背包的情况,我们不能直接的使用上面的公式,需要使用if-else来体现公式
if(v[i - 1][j] < val[i - 1] + v[i - 1][j - w[i - 1]]) {
v[i][j] = val[i - 1] + v[i - 1][j - w[i - 1]]; //之所以对此处进行标记,是因为只有这个地方会出现多个商品的情况
//把当前的情况记录到path
path[i][j] = 1;
} else {
v[i][j] = v[i - 1][j];
}
}
}
}
//输出一下v 看看目前的情况
for(int i =0; i < v.length;i++) {
for(int j = 0; j < v[i].length;j++) {
System.out.print(v[i][j] + " ");
}
System.out.println();
}
System.out.println("============================");
//从后往前来处理,是因为动态规划是不断优化以至结果最优,那么必然要从后往前看
int i = path.length - 1; //行的最大下标
int j = path[0].length - 1; //列的最大下标
while(i > 0 && j > 0 ) { //从path的最后开始找
if(path[i][j] == 1) { //因为只允许一个商品,所以判断完一行,就该下一行了
System.out.printf("第%d个商品放入到背包\n", i);
j -= w[i-1]; //w[i-1],i代表商品的重量,j代表能容纳的重量,所以确定剩余的可容纳重量,就直接确定行数了
}
i--; //确定完一个商品后,进入下一个商品的确定
}
}
}
公式化处理大部分动态规划问题
套路简介


为了验证这一点,我们看一个例题代码,你再看我前面那个例题,可以说相似度极高

以两道例题开始概念的理解
斐波那契数列
int fib(int N) {
if (N == 1 || N == 2) return 1;
return fib(N - 1) + fib(N - 2);
}

观察递归树,很明显发现了算法低效的原因:存在大量重复计算,比如 f(18) 被计算了两次,而且你可以看到,以 f(18) 为根的这个递归树体量巨大,多算一遍,会耗费巨大的时间。更何况,还不止 f(18) 这一个节点被重复计算,所以这个算法及其低效。这就是动态规划问题的第一个性质:重叠子问题
对代码进行一个优化,创建备忘录
- 即然耗时的原因是重复计算,那么我们可以造一个「备忘录」,每次算出某个子问题的答案后别急着返回,先记到「备忘录」里再返回;每次遇到一个子问题先去「备忘录」里查一查,如果发现之前已经解决过这个问题了,直接把答案拿出来用,不要再耗时去计算了。 ```java int fib(int N) { // 备忘录全初始化为 0 int[] memo = new int[N + 1]; // 进行带备忘录的递归 return helper(memo, N); }
int helper(int[] memo, int n) { // base case if (n == 0 || n == 1) return n; // 已经计算过,不用再计算了 if (memo[n] != 0) return memo[n]; memo[n] = helper(memo, n - 1) + helper(memo, n - 2); return memo[n]; }
明显看到,我们创建备忘录memo,我们将状态方程的数据进行了存储,方便他人调用<br />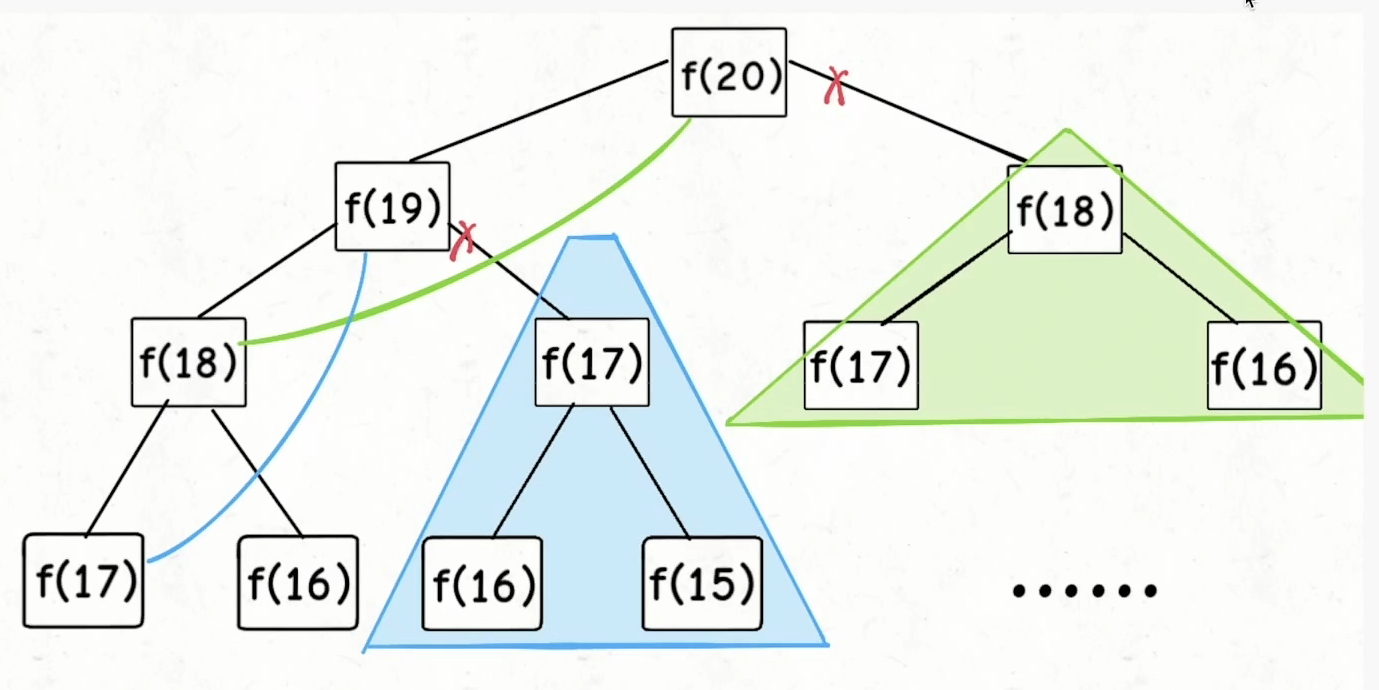
---
啥叫「自顶向下」?注意我们刚才画的递归树(或者说图),是从上向下延伸,都是从一个规模较大的原问题比如说 f(20),向下逐渐分解规模,直到 f(1) 和 f(2) 这两个 base case,然后逐层返回答案,这就叫「自顶向下」。
啥叫「自底向上」?反过来,我们直接从最底下、最简单、问题规模最小、已知结果的 f(1) 和 f(2)(base case)开始往上推,直到推到我们想要的答案 f(20)。这就是「递推」的思路,这也是动态规划一般都脱离了递归,而是由循环迭代完成计算的原因
我们更常见的动态规划代码是「自底向上」进行「递推」求解
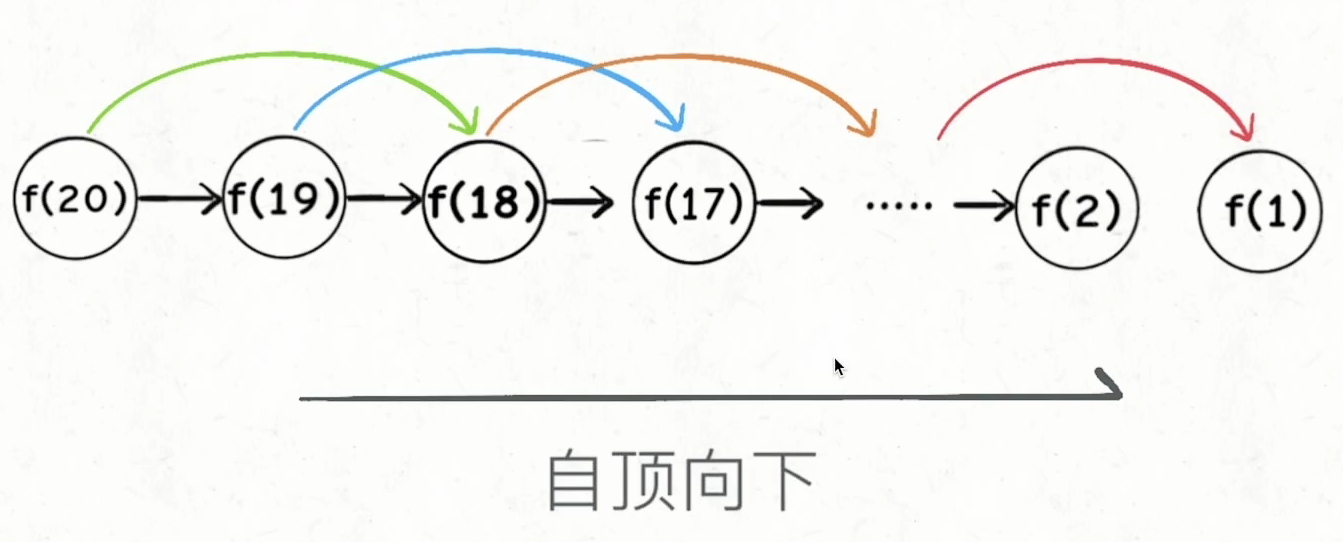<br />有了上一步「备忘录」的启发,我们可以把这个「备忘录」独立出来成为一张表,通常叫做 DP table
```java
int fib(int N) {
if (N == 0) return 0;
int[] dp = new int[N + 1];
// base case
dp[0] = 0; dp[1] = 1;
// 状态转移
for (int i = 2; i <= N; i++) {
dp[i] = dp[i - 1] + dp[i - 2];
}
return dp[N];
}


我觉得大家可以理解为,规律的总结,就是得到一个公式
int fib(int n) {
if (n == 0 || n == 1) {
// base case
return n;
}
// 分别代表 dp[i - 1] 和 dp[i - 2]
int dp_i_1 = 1, dp_i_2 = 0;
for (int i = 2; i <= n; i++) {
// dp[i] = dp[i - 1] + dp[i - 2];
int dp_i = dp_i_1 + dp_i_2;
// 滚动更新
dp_i_2 = dp_i_1;
dp_i_1 = dp_i;
}
return dp_i_1;
}
零钱兑换问题

若有收获,就点个赞吧
0 人点赞
