link * p = NULL;//创建头指针这种定义下来就是创建一个指针,但目前这个指针实际上没有指向,非要说那就是指向NULL,那不就是无吗?
link * temp = (link*)malloc(sizeof(link));//创建首元节点这种定义下来就是创建一个节点,但目前这个节点没有任何数据(data) ,也没有任何指向(next)temp->elem = 1;//存储数据 1temp->next = NULL;//指向无
p = temp;//头指针指向首元节点 //二者能写 = 说明两个都是指针,当然两个都是link定义的由于p是一个指针,而temp是个节点(包含数据域data,指针域next)可见这种定义方式就是 指针 p 指向节点 temp
以上代码实际图
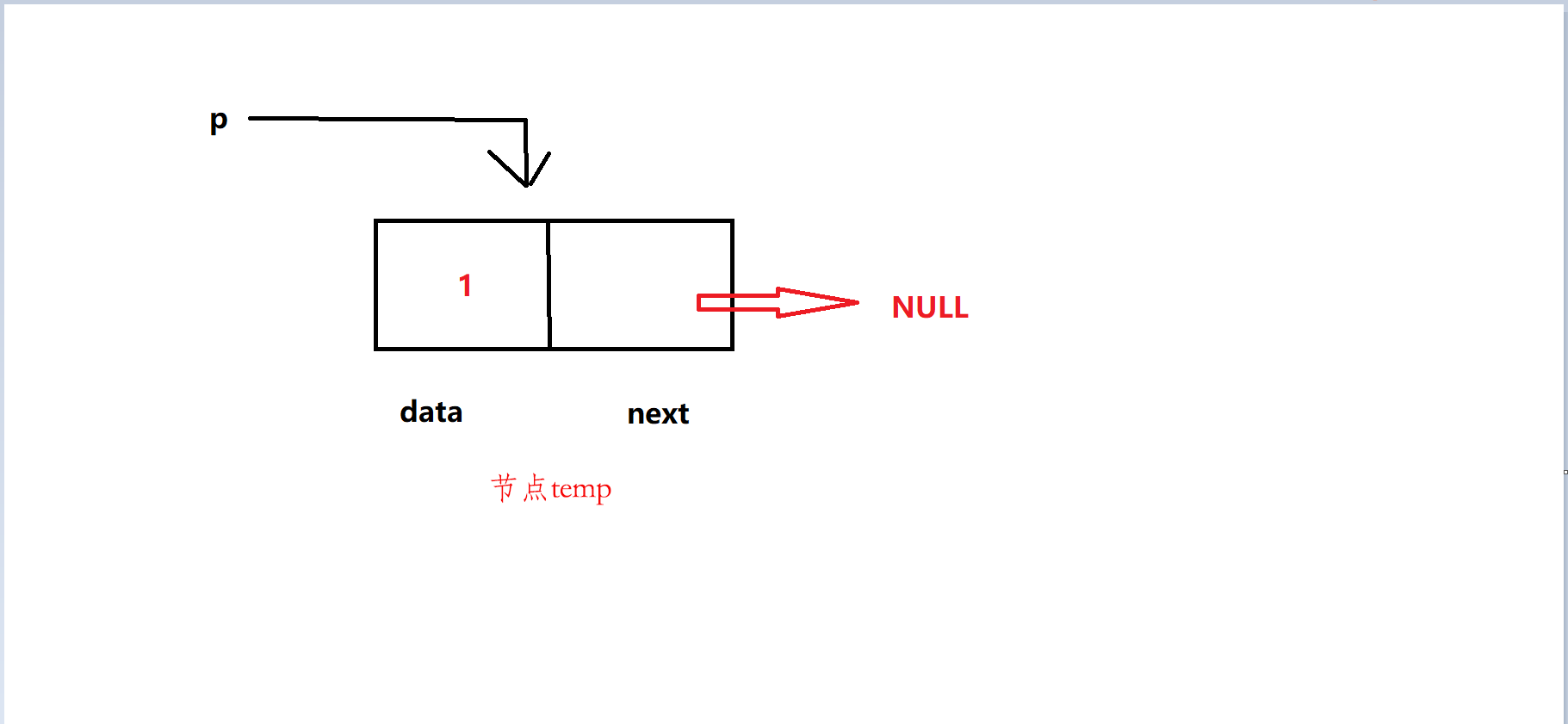
下面有一行代码非常关键 temp = temp->next
for (i = 2; i < 5; i++) {link *a = (link*)malloc(sizeof(link));//创建一个新节点a->elem = i; //赋值dataa->next = NULL; //指向无temp->next = a;//temp指向节点a//指针temp每次都指向新链表的最后一个节点,其实就是 a节点,这里写temp=a也对temp = temp->next;}
接下来呈现循环第一次的图
这是在还没有执行 temp = temp->next 的情况图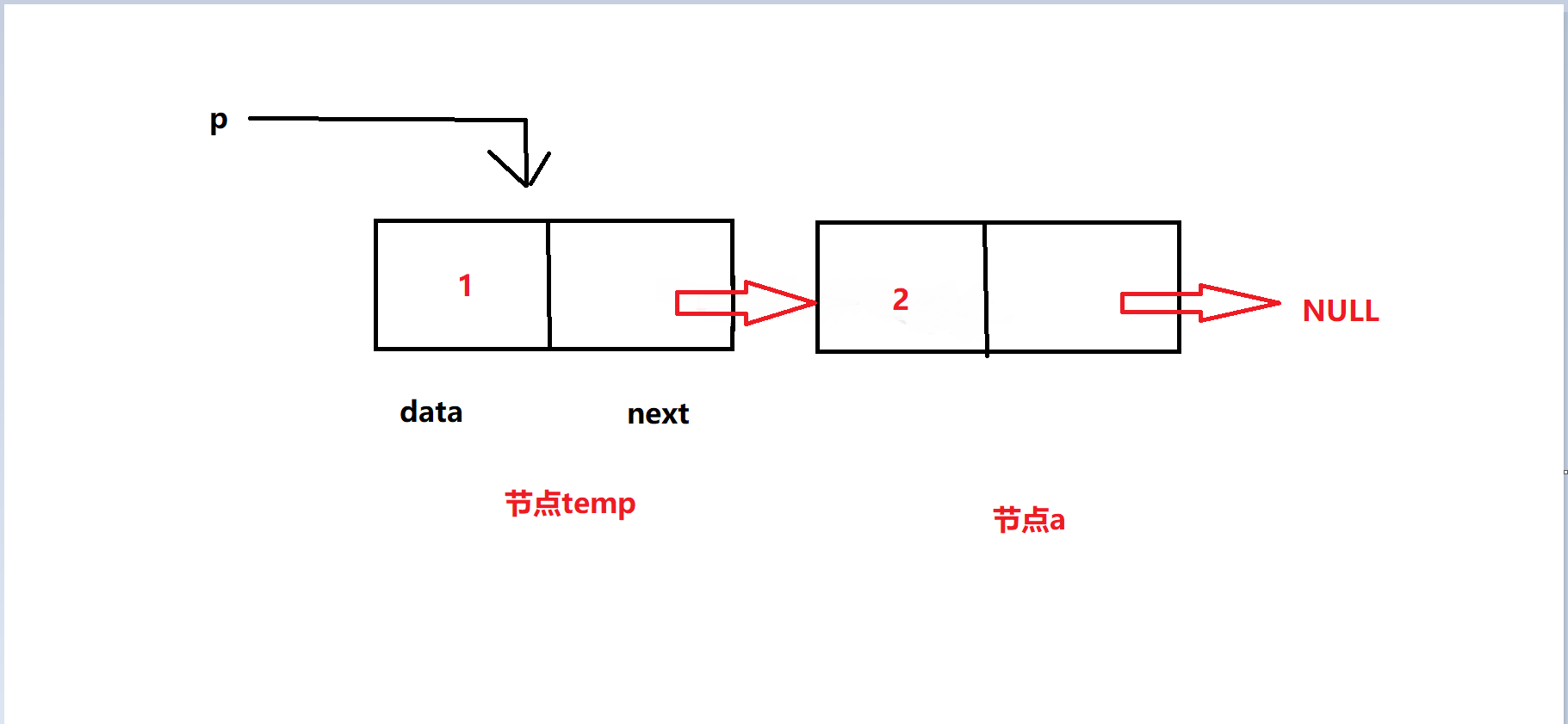
我们之所以执行 temp = temp->next 因为我们的循环代码中是 创建新节点 a 然后用temp连接这个新节点 a
我们知道temp->next等价于节点a
这地方不好理解的是认为是节点a 替换掉 节点 temp,因为等式temp = a 的缘故,但其实并非如此
要知道节点也是指针,你要区分清楚结构体指针(如节点temp)和结构体的指针(如节点temp的指针域next)
temp代表节点temp,节点 a 代表节点 a ,这显然是废话
由于我们的for循环代码,我们需要temp->next指向新节点 a
如果我们没有操作 temp = temp->next
就会是 旧节点a = 新节点a,二者并没有建立逻辑练习
但要是有操作 temp = temp->next,下次循环的temp->next就代表 旧节点a->next = 新节点a,建立了逻辑关系
文字总是让是迷糊,实属无奈
基于有头结点的链表创建
//声明节点结构typedef struct Link {int elem;//存储整形元素struct Link *next;//指向直接后继元素的指针}link;//创建链表的函数link * initLink() {link * p = (link*)malloc(sizeof(link));//创建一个头结点link * temp = p;//声明一个指针指向头结点,用于遍历链表int i = 0;//生成链表for (i = 1; i < 5; i++) {//创建节点并初始化link *a = (link*)malloc(sizeof(link));a->elem = i;a->next = NULL;//建立新节点与直接前驱节点的逻辑关系temp->next = a;temp = temp->next;}return p;}
关于删除操作中一行代码的说明

这行代码的含义是 //新建一个指针temp,初始化为头指针 p
至于为什么这样做,以及为什么最后返回p
解释如下:
首先新建一个指针temp,目的是去进行删除操作
返回p,而不是temp
因为p一直指向链表的头指针,返回p就可以直接利用它找到整个链表
而temp因为去干删除操作位置已经不再头指针,不利于去查找整个链表
这你想到temp存在的意义,就是为了更简单的返回头指针p

若有收获,就点个赞吧
0 人点赞
