今天看我各个平台博客同步情况,发现我之前都是在csdn写完,直接复制粘贴到其它平台的,格式什么的完全没有了,而我也急于发布没有做任何处理。想象以后文章多起来,不仅管理起来不方便,而且对其它平台的阅读者很不友好。
顺势观察了一下各平台的导入、导出功能(针对于自己文章):有平台支持批量导入,亦有平台支持批量导出,还有的支持单篇导入,没有一个既可以批量导入又可以批量导出的(嘤嘤嘤)。
而CSDN同样仅支持单篇导入、导出,需要进到每篇文章的编辑页面再进行导出,如果文章超级多的时候,备份、搬迁时候进行此项操作都不是最佳方案。想想我之前那篇Hexo迁移博客的文章:Mac_如何利用Hexo发布、迁移博文?https://blog.csdn.net/pang787559613/article/details/102619683,竟然还是我手动导出的(可能之前文章少,没觉得费事儿吧),还是太年轻啊。
对于可以批量导入的平台,我本人甚是欢喜,就算新注册的账号,也不用一篇一篇去复制粘贴,那么前提是要先把自己已有文章导出为统一格式(如:Markdown),既做一次备份,也便于在其它平台共用。
延伸一下,只能导出自己的文章也不太好,毕竟如果遇到想要收藏的文章时候,存下的格式很乱,就很尴尬了。所以不仅限于导自己的博客,这篇文章的主题是:如何从CSDN批量导出markdown格式的文章?
网上搜了一下有java的脚本用到jsoap、也有python的selenium跟BeautifulSoap两种。相比之下我还是比较熟悉python,但是selenium是基于浏览器模拟导出,仅能在文章编辑页导出自己的文章,有局限性,所以就研究了下BeautifulSoap。基于这位大佬的代码:https://blog.csdn.net/qq_36962569/article/details/100167955,运行下来,仅能拿到前两页前三条(共计6条数据),而且写入报错。对于我非专业python来说有点小烦躁,好在坚持了下来,理清了思路,解决了报错,并成功导出。下面我来记录下我所理解的大佬思路,还有报错的解决方案,贴一下修改过的代码,给需要的人做参考。
一、思路:
1、csdn自带导出功能是如何导出的?
2、每篇文章怎么做区分的?怎么拿到所有文章的id?
3、分页如何处理?
4、拿到内容后解析写入文件?
二、分析过程:
1、csdn自带导出功能是如何导出的?
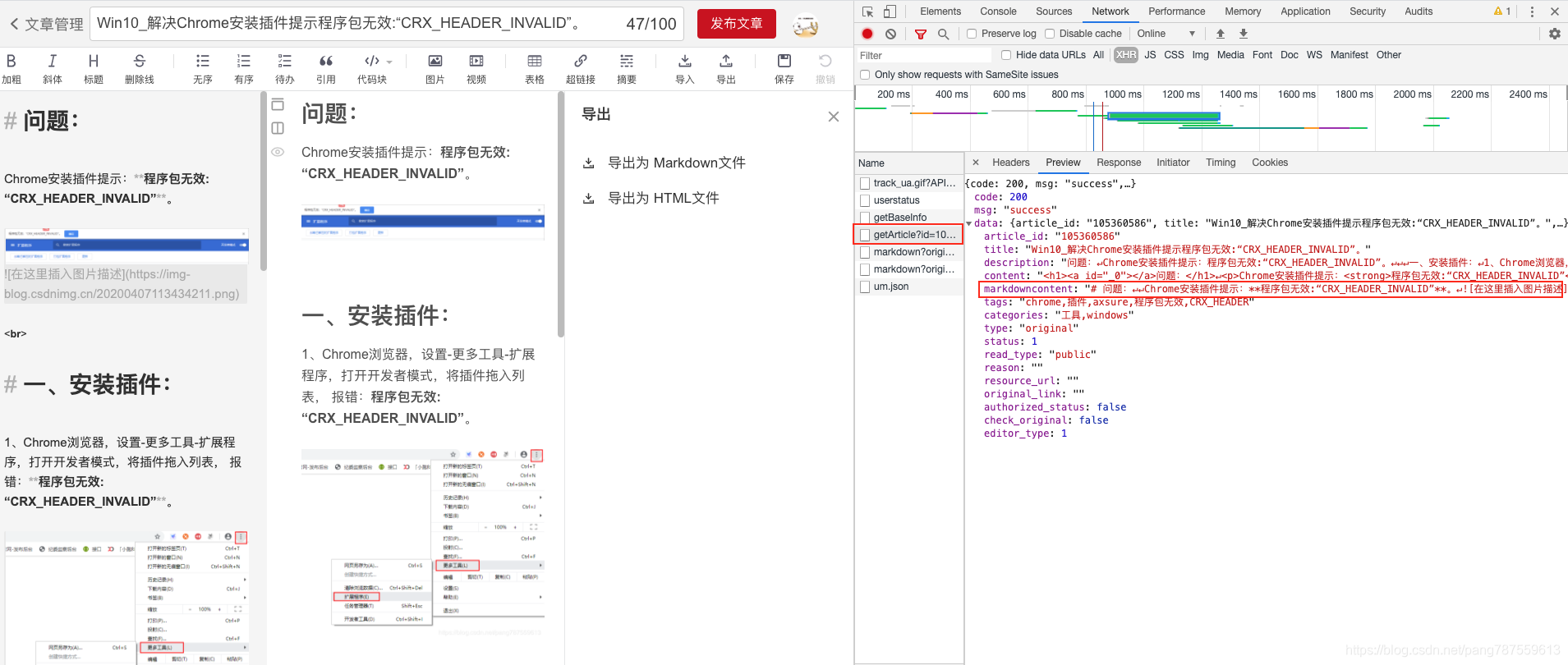
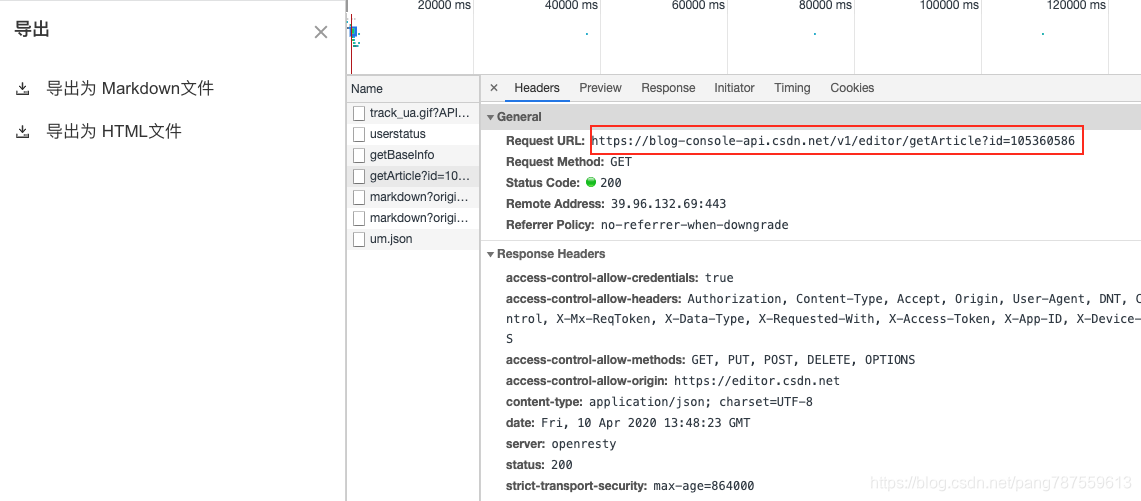
打开一片文章编辑页面,F12查看数据如何获取的,发现其为这样一个请求https://blog-console-api.csdn.net/v1/editor/getArticle?id=105360586,返回字段中有content和markdowncontent,我们要拿markdown格式,所以Markdowncontent就好了。

2、每篇文章怎么做区分的?怎么拿到所有文章的id?
至于第1步里的id,跟这篇文章详情链接https://blog.csdn.net/pang787559613/article/details/105360586,是一致的,再观察几篇文章详情,仅后轴id不一样, 所以不同文章是以此来区分的。
查看所有文章id:
个人主页,F12打开检查,刷新页面(windows—>>F5,mac—>>command+r):
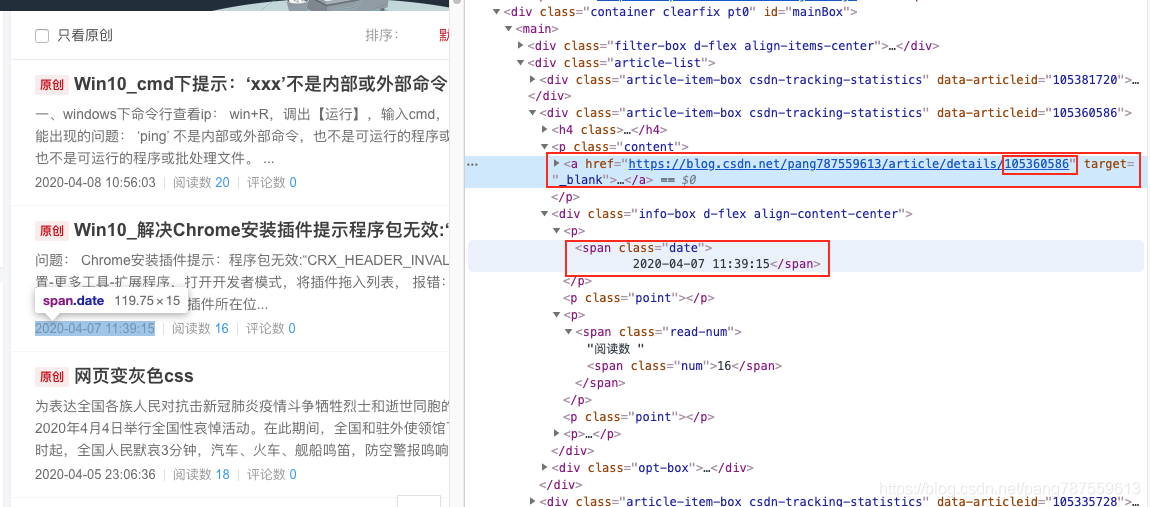
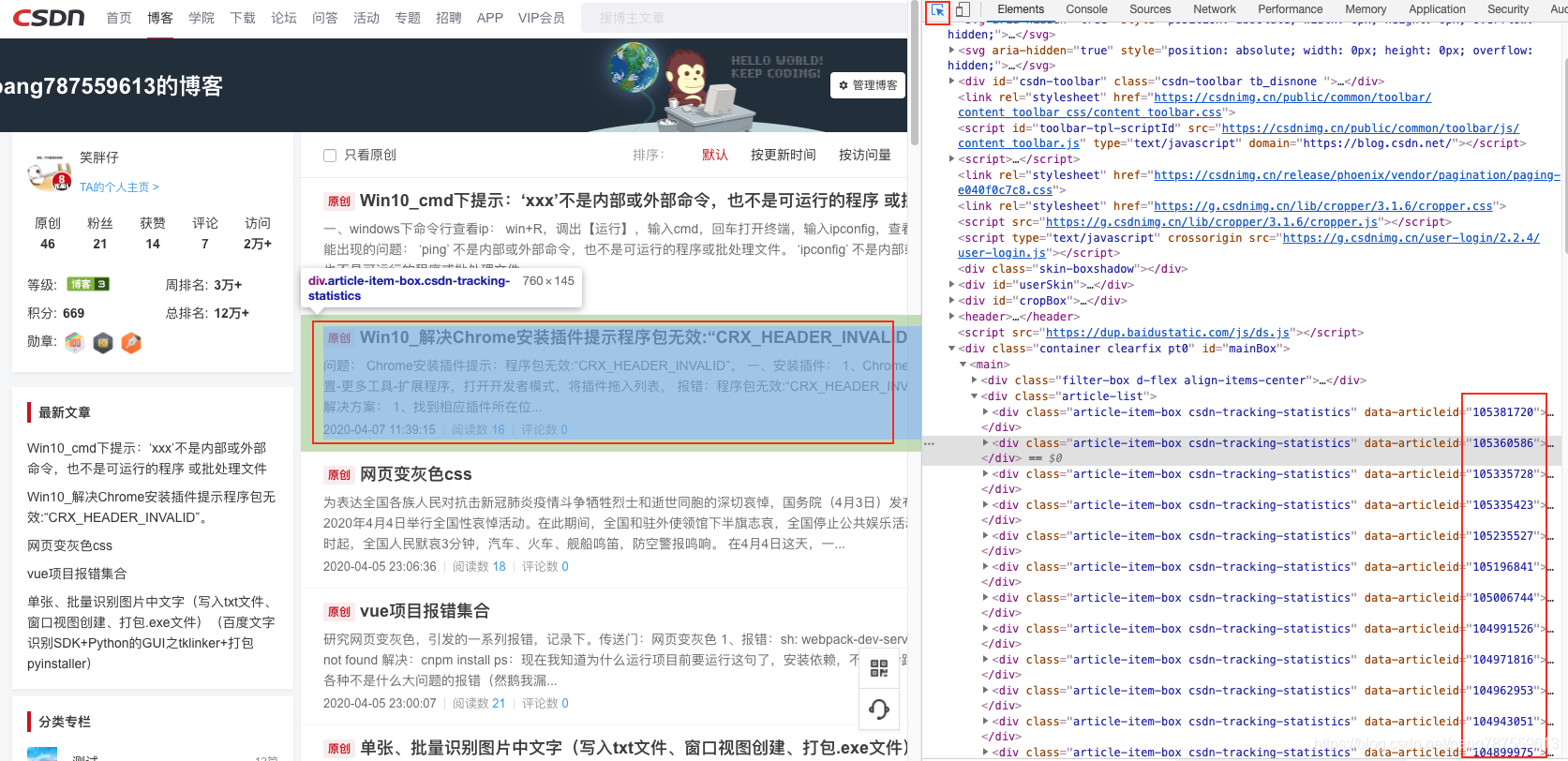 可以分析以下源码,用BeautifulSoap库解析,能获取id、发布时间等内容:
可以分析以下源码,用BeautifulSoap库解析,能获取id、发布时间等内容:
3、分页如何处理?
翻到个人主页底部页码出,点开第二页,发现调用接口为:https://blog.csdn.net/pang787559613/article/list/2
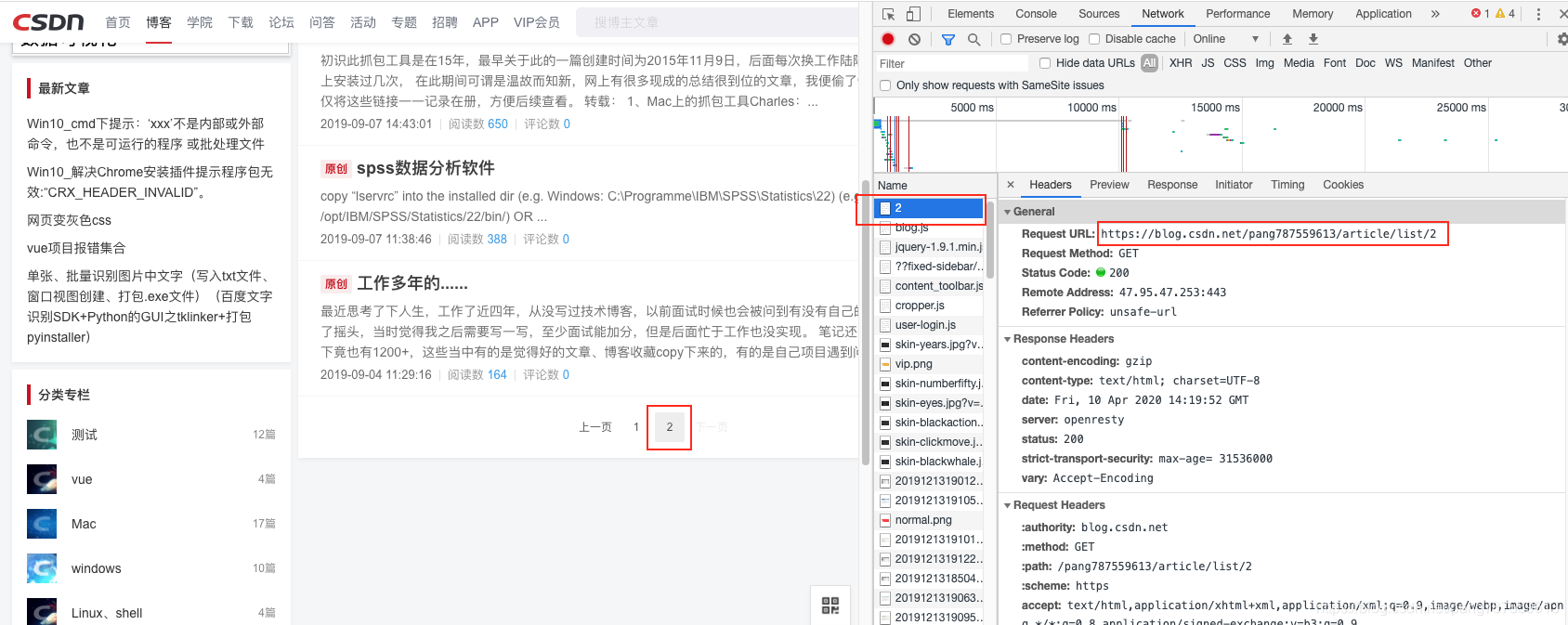
切回第一页时,调用的请求为:https://blog.csdn.net/pang787559613/article/list/1
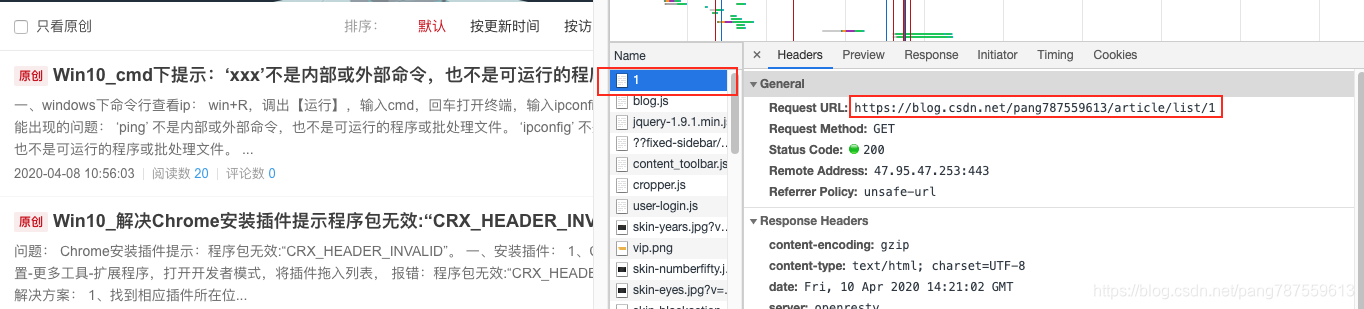
4、拿到内容后解析写入文件?
通过调用第3步,拿到所有文章,再用第2步,解析获得文章id以及发布时间,最后调用第1步,解析拿到markdowncontent、文章标题、tags、key等等,保存为hexo格式的markdown(由于我的hexo博客仅有标题+内容,所以代码仅写入了标题跟内容,其余注释了,需要的可自行修改。后来仅保留了内容,做博客迁移)。
三、完整代码:
# encoding:utf-8# author:笑胖仔import jsonimport uuidimport timeimport requestsimport datetimefrom bs4 import BeautifulSoupdef request_blog_list(page):"""获取博客列表主要包括博客的id以及发表时间等"""url = f'https://blog.csdn.net/pang787559613/article/list/{page}'reply = requests.get(url)parse = BeautifulSoup(reply.content, "lxml")spans = parse.find_all('div', attrs={'class':'article-item-box csdn-tracking-statistics'})blogs = []for span in spans[:40]:try:href = span.find('a', attrs={'target':'_blank'})['href']read_num = span.find('span', attrs={'class':'num'}).get_text()date = span.find('span', attrs={'class':'date'}).get_text()blog_id = href.split("/")[-1]blogs.append([blog_id, date, read_num])except:print('Wrong, ' + href)return blogsdef request_md(blog_id, date):"""获取博客包含markdown文本的json数据"""url = f"https://blog-console-api.csdn.net/v1/editor/getArticle?id={blog_id}"headers = {"cookie":"uuid_tt_dd=10_20621362900-1586421086666-163599; dc_session_id=10_1586421086666.420623; Hm_lvt_6bcd52f51e9b3dce32bec4a3997715ac=1586421618; dc_sid=d4ceee41911ac755c162110ff811aee3; __gads=ID=608336bee91baf3d:T=1586421689:S=ALNI_MZozulzITWLw3Hxzo3jrnu5fmz8CA; c_ref=https%3A//blog.csdn.net/pang787559613/article/list/2; c-toolbar-writeguide=1; SESSION=3b5e7c88-b27d-4fcc-a2d5-4e97c1438a3c; UN=pang787559613; Hm_ct_6bcd52f51e9b3dce32bec4a3997715ac=6525*1*10_20621362900-1586421086666-163599!5744*1*pang787559613; announcement=%257B%2522isLogin%2522%253Atrue%252C%2522announcementUrl%2522%253A%2522https%253A%252F%252Fblog.csdn.net%252Fblogdevteam%252Farticle%252Fdetails%252F105203745%2522%252C%2522announcementCount%2522%253A0%252C%2522announcementExpire%2522%253A3600000%257D; UserName=pang787559613; UserInfo=604f13922dc04f2d8071fe0834e95db3; UserToken=604f13922dc04f2d8071fe0834e95db3; UserNick=%E7%AC%91%E8%83%96%E4%BB%94; AU=5FE; BT=1586422795507; p_uid=U000000; Hm_lpvt_6bcd52f51e9b3dce32bec4a3997715ac=1586422842; TY_SESSION_ID=ffc735f4-f5ae-40ed-9b98-ff01e337bf76; dc_tos=q8ijsv","user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.120 Safari/537.36"}data = {"id": blog_id}reply = requests.get(url, headers=headers, data=data)try:write_hexo_md(reply.json(), date)except Exception as e:print("***********************************")print(e)print(url)# print(reply.json())def write_hexo_md(data, date):"""将获取的json数据解析为hexo的markdown格式"""title = data["data"]["title"]title = title.replace("[", "【")title = title.replace("]", "】")tags = data["data"]["tags"]# 页面唯一标识符,用于统计系统和评论系统key = "key" + str(uuid.uuid4())name = f"{date[0]}-{date[1]}-{date[2]}-{title}"tag = "tags:\n - " + "\n - ".join(tags.split(","))# #hexo内容顶部拼接:title、tag、key# header = "---\n" + f"title: {title}\n" + tag + "\n" + f"key: {key}\n" + "---\n\n"# #hexo内容顶部拼接:仅title# header = "---\n" + f"title: {title}\n" + "---\n\n"content = data["data"]["markdowncontent"].replace("", "")# hexo格式markdown# with open(f"blogs/{name}.md", "w", encoding="utf-8") as f:# f.write(header + content)# print(f"写入 {name}")# 用来博客迁移。遂仅保留内容with open(f"blogs/{title}.md", "w", encoding="utf-8") as f:f.write(content)print(f"写入 {title}")def main(total_pages=2):"""获取博客列表,包括id,时间获取博客markdown数据保存hexo格式markdown"""blogs = []for page in range(1, total_pages + 1):blogs.extend(request_blog_list(page))for blog in blogs:blog_id = blog[0]date = blog[1].split()[0].split("-")request_md(blog_id, date)time.sleep(1)if __name__ == '__main__':main()

若有收获,就点个赞吧
0 人点赞
