1、链式存储结构
1.1 定义
- 用一组任意未被使用的存储单元来存放线性表的数据元素。
- 相比顺序存储结构,链式存储结构中除了要存储数据元素信息外,还需要存储它的后继元素的存储地址(指针)。
- 最后一个结点的指针为null
1.2 链式存储结构相关术语
- 数据域:存储数据元素信息的域。
- 指针域:存储后继元素位置的域,存取的内容称为指针或者链。
- 结点:数据元素的存储映像,由数据域和指针域两部分组成。
链表:n个结点链接成一个链表,称为线性表的链式存储结构。
单链表、双链表、循环链表:
- 结点只有一个指针域的链表,称为单链表(存后继位置)。
- 每一个结点有两个指针域,称为双链表(第一个指针域存前驱,后一个指针域存后继)。
- 首尾相接的链表称为循环链表。
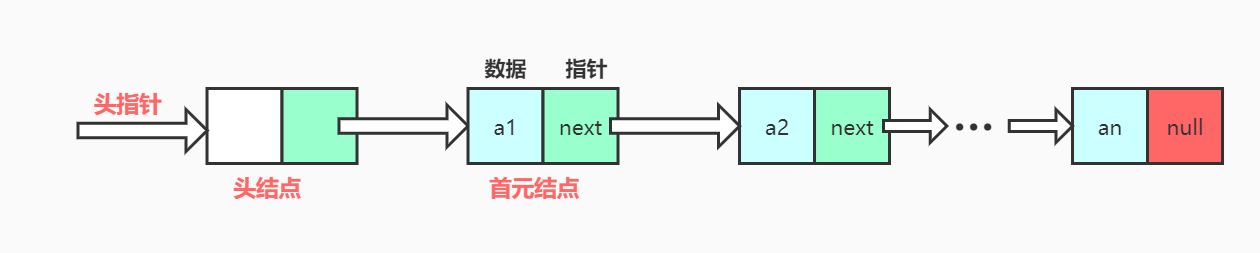
头指针、头结点和首元结点:
头指针(head):指向第一个结点的指针。这里第一个结点指的是首元结点或头结点;头指针是链表的必要元素。
头结点:是在链表的首元结点之前附设的一个结点,其数据域一般无意义,但也可以用来存放链表的长度;头结点不是必须的。
首元结点:是指链表中存储第一个数据元素a1的结点。
头结点作用:使所有链表(包括空表)的头指针非空,并使对单链表的插入、删除操作不需要区分是否为空表或是否在第一个位置进行,从而与其他位置的插入、删除操作一致。
单链表图例(有头结点)
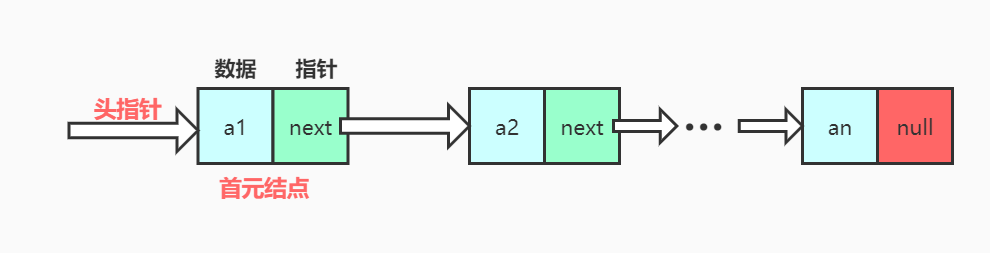
- 单链表图例(无头结点)
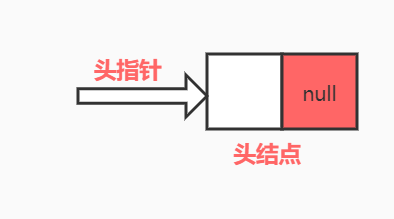
- 空链表图例
2、单链表
2.1 c语言描述单链表

假设p是指向线性表第i个元素的指针,则:
- p->data:值是a的数据元素,
- p->next:值是一个指针,指向下一个元素结点a**
- p->next->data:指的是a的数据元素
2.2 单链表的读取
获取链表中的第i个元素
算法思路:
- 声明一个结点p指向链表的第一个结点,初始化j从1开始。
- 当j<i时,遍历链表,让p的指针向后移动,不断指向下一结点,j++。
- 若到链表末p为空,则说明第i个元素不存在。
- 否则查找成功,返回结点p的数据。
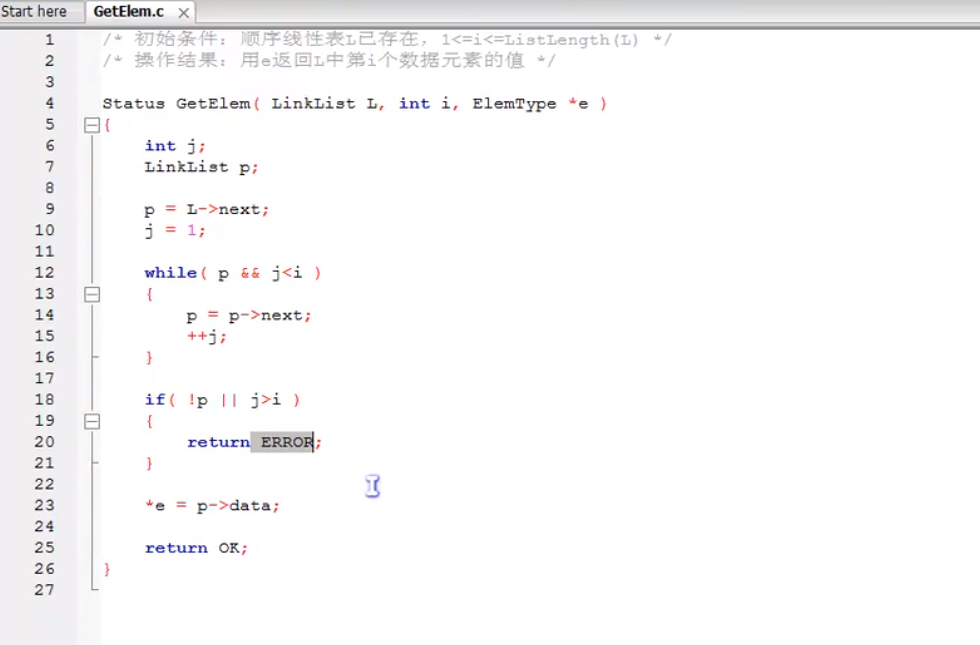
- 时间复杂度为O(n)。
- 由于单链表的结构中没有定义表长,所以不知道要循环多少次,因此就不方便使用for来检测循环。
- 核心思想:工作指针后移,也是很多算法常用的技术。
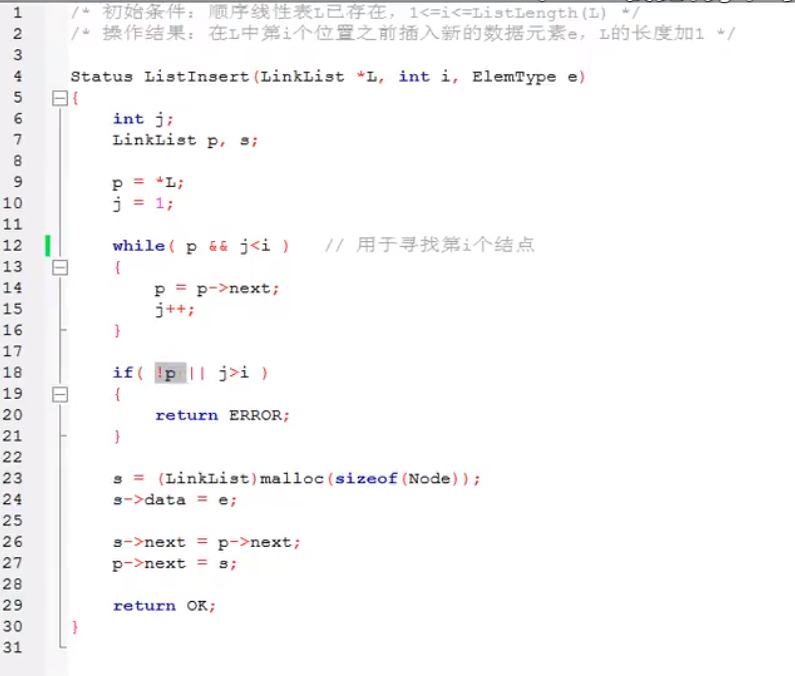
2.3 单链表的插入
- 假设存储元素e的结点为s,要实现将结点插到结点p,与p->next之间,应该如何实现?
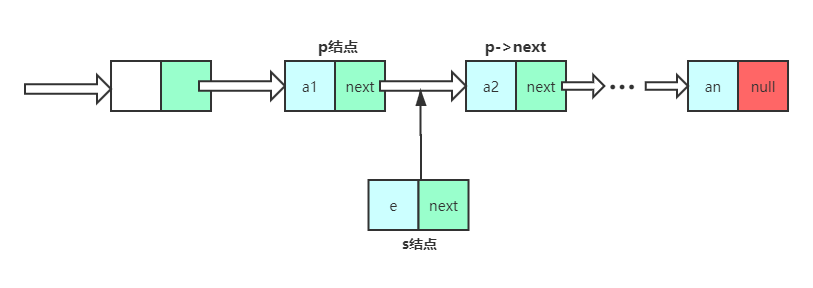
核心语句:
s->next = p->nextp->next = s# 这两句代码不可互换顺序
即:
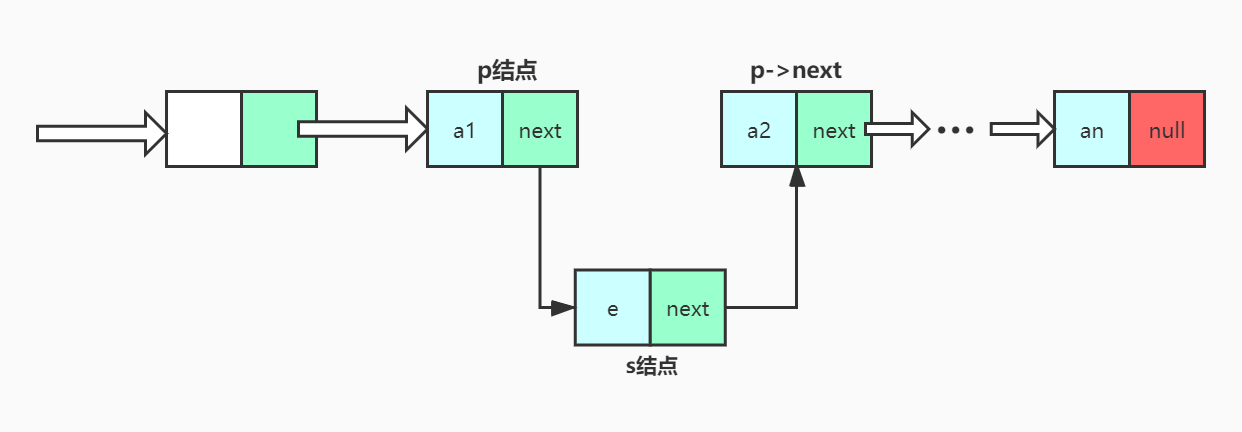
算法实现思路:声明一结点p指向链表头结点,初始化j从1开始;
- 当j<i时,遍历链表,让p的指针向后移动,不断指向下一结点,j累加1;
- 若到链表末尾p为空,则说明第i个元素不存在;
- 否则查找成功,在系统中生成一个空结点s;
- 将数据元素e赋值给s->data。
2.4 单链表的删除操作
- 假设元素a2的结点为q,要实现结点q的删除,假设a2的前驱元素的结点为p,则应如何操作?
核心语句:
p->next = p->next->next;或者:p->next = q->next;
算法实现思路
声明一结点p指向链表头结点,初始化j从1开始;
- 当j<i时,遍历链表,让p的指针向后移动,不断指向下一结点,j累加1;
- 若到链表末尾p为空,则说明第i个元素不存在;
- 否则查找成功,将欲删除结点p->next赋值给q;
- 删除的核心语句:p->next = q->next;
- 将q结点中的数据元素赋值给e,并返回;
- 释放q结点。
时间复杂度:
3、 单链表的整表创建与删除
- 对于顺序表的整表创建,我们可以用数组初始化来实现,那么对于存储单元不连续的单链表而言,我们应该如何创建整表呢?
3.1 算法实现思路
- 声明一结点p和计数器变量i;
- 初始化一空链表L;
- 让L的头结点指针指向null;
- 循环实现后继结点的赋值和插入。
3.2 头插法
- 从一个空链表开始,生成新节点,读取数据存放到新节点的数据域中,将新节点插入到当前链表中首元结点处,直到结束;
- 生成的链表中,结点的次序和输入的顺序相反;


3.3 尾插法
- 将新节点插入到链表的末端。
- 假设要插入的结点为p,末端结点为r,则
r->next = pr = p # 移动指针到末端结点r->next = null

3.4 单链表的整表删除
算法实现思路
- 声明结点p和q;
- 将第一个结点赋值给p,第二个结点赋值给q;
- 循环执行释放p,将q赋值给p。

4、单链表与顺序表的优缺点
4.1 从存储分配方式上看
- 顺序存储结构用一段连续的存储单元依次存储线性表的数据元素。
- 单链表采用链式存储结构,用一组任意的存储单元存放线性表的元素。
4.2 从时间性能上看
- 查找
- 顺序表为O(1)
- 单链表为O(n)
- 插入和删除
- 顺序表每一次插入或删除都为O(n)
- 单链表在计算出某位置的指针后,插入或删除仅为O(1)
4.3 从空间性能上看
- 顺序表需要预分配存储空间,分大了,容易造成空间浪费,分小了,容易溢出。
- 单链表不需要预分配存储空间,只要有就可以分配,且元素个数也不受限制。
4.4 总结
- 若线性表需要频繁查找,很少进行插入和删除操作,宜采用顺序存储结构。
- 若需要频繁插入和删除时,宜采用单链表结构。
- 若事先知道线性表的大致长度,如一年12个月,一周7天,这种采用顺序存储结构效率会高很多。
- 若线性表中元素个数变化较大,或者根本不知道有多大时,采用单链表结构更好。

若有收获,就点个赞吧
0 人点赞
