1、多层感知机与布尔函数
问题一:多层感知机表示异或逻辑时最少需要几个隐含层(仅考虑二元输入)?
答:最少需要一个隐藏层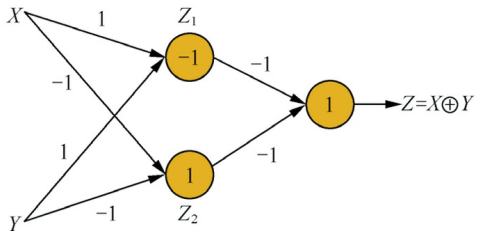
问题二:如果只使用一个隐层,需要多少隐节点能够实现包含 n 元输入的任意布尔函数?
答:对于单隐层的感知机,需要  个隐节点
个隐节点
- 布尔函数可以唯一表示为析取范式的形式(即有限个简单合取式(乘积)构成的析取式(和))
- 单个隐节点可以表示任意合取式
- n 元布尔函数的析取范式最多包含
 个不可规约的合取范式
个不可规约的合取范式 - 因此,对于单隐层的感知机,需要
 个隐节点
个隐节点
问题三:考虑多隐层的情况,实现包含 n 元输入的任意布尔函数最少需要多少个网络节点和网络层?
答:n 元异或操作函数需要 3(n-1) 个节点(包含最终输出节点),最少需要网络层数为 
- 参考问题 1,二元输入需要完成一次异或操作,需要使用 3 个节点
- n 元输入需要完成 n - 1 次异或操作,需要使用 3(n - 1) 个节点
- 根绝二分思想,每层节点两两分组进行异或操作,需要进行
 轮异或操作,每轮包含 2 层(单隐层和输出层),所以共需网络层数为
轮异或操作,每轮包含 2 层(单隐层和输出层),所以共需网络层数为 
2、深度神经网络中的激活函数
对于深度神经网络,在每一层线性变换后叠加一个非线性激活函数,以避免多层神经网络等效于单层线性函数
问题一:写出常用激活函数及其导数
| 激活函数名称 | 激活函数公式 | 导数 |
|---|---|---|
| Sigmoid |  |
 |
| Tanh |  |
|
| ReLU |  |
 |
问题二:为什么 Sigmoid 和 Tanh 激活函数会导致梯度消失的线性?
- 当 z 很大或很小时,Sigmoid 和 Tanh 的导数趋近于 0
- 实际上,Tanh 激活函数相当于 Sigmoid 的平移:


问题三:ReLU 系列的激活函数相对于 Sigmoid 和 Tanh 激活函数的优点是什么?它们有什么局限性以及如何改进?
ReLU 激活函数的优点:
- Sigmoid 和 Tanh 激活函数需要计算指数,复杂度高,而 ReLU 只需要一个阈值即可得到激活值
- ReLU 的非饱和性可以有效解决梯度消失问题,提供相对宽的激活边界
- ReLU 的单侧抑制提供了网络的稀疏表达能力
ReLU 激活函数的局限性:
- 训练过程会导致神经元死亡问题:如果学习率过大,可能到负梯度,而负梯度经过 ReLU 单元被置为 0,之后梯度永远为 0,不被任何数据激活
ReLU 的改进版本:
- Leakey ReLU:

- a 是一个很小的正常数,既实现了单侧抑制,又保留了部分负梯度信息以致不完全丢失
- 但是 a 是超参数需要人工选择
- PReLU:将 a 作为一个可学习的参数
- Random ReLU:在训练时将 a 作为某个分布的随机采样,在测试时再固定 a 的值
3、多层感知机的反向传播算法
- 前向传播:输入信号通过各个网络层的隐节点产生输出,在训练过程中还会产生一个标量损失函数
- 反向传播:将损失函数的信息沿网络层向后传播用以计算梯度,达到优化网络参数的目的
问题一:写出多层感知机的平方误差和交叉熵损失函数
- N 层感知机,第
 层节点数
层节点数 
- m 个样本集合:

- 代价函数/损失函数:

- 损失函数项 + L2 正则化项
- 平方误差:

- 平方误差的整体代价函数:

- 交叉熵损失函数:
- 二分类:

- 多分类:类别数为 k,
 代表第 i 个样本的预测属于类别 k 的概率
代表第 i 个样本的预测属于类别 k 的概率 
- 二分类:
问题二:根据问题一中定义的损失函数,推导各层参数更新的梯度计算公式
前向传播:
- 第
 层的线性变换:
层的线性变换:
- 第
 层的输出:
层的输出: ,f(·) 为非线性激活函数
,f(·) 为非线性激活函数 - 第
 层的输入:
层的输入: 
梯度下降 反向传播:(对权重矩阵和偏置矩阵的每个元素进行更新)

梯度计算推导:
- 损失函数对第
 层第 j 个节点的的偏导(残差)
层第 j 个节点的的偏导(残差) 

- 因此

- 对于平方误差损失

- 对于交叉熵损失

 ,其中
,其中  为实际类别
为实际类别- 当
 取 softmax 激活函数时,有
取 softmax 激活函数时,有 
- 对于平方误差损失
- 损失对权重参数的梯度:

- 损失对偏置参数的梯度:


问题三:平方误差损失函数和交叉熵损失函数分别适合什么场景?
- 平方损失函数:适合输出为连续,且最后一层不含 sigmoid 或 softmax 激活函数的神经网络
- 问题二推导出平方误差损失相对于输出层的导数为
 ,其中
,其中  是激活函数的导数,如果激活函数是 sigmoid,那么当
是激活函数的导数,如果激活函数是 sigmoid,那么当  的绝对值较大时梯度趋于饱和(接近 0,梯度消失),导致
的绝对值较大时梯度趋于饱和(接近 0,梯度消失),导致  的取值很小,梯度的学习速度缓慢
的取值很小,梯度的学习速度缓慢
- 问题二推导出平方误差损失相对于输出层的导数为
- 交叉熵损失函数:适合二分类或多分类的场景
- 问题二推导出交叉熵损失函数相对于输出层的导数为
 ,是线性的,不会出现梯度学习过慢的问题
,是线性的,不会出现梯度学习过慢的问题
- 问题二推导出交叉熵损失函数相对于输出层的导数为
4、神经网络训练技巧
问题一:神经网络训练时是否可以将全部参数初始化为 0?
答:不可以,会导致参数对称问题
- 对于全连接网络,同一层中的任意神经元是同构的,如果将参数初始化为相同值,那么前向传播和反向传播取值相同,无法打破这种对称性
- 应该随机初始化,可以将参数初始化为取值范围
 的均匀分布,d 是神经元的输入维度
的均匀分布,d 是神经元的输入维度
问题二:为什么 Dropout 可以抑制过拟合?它的工作原理和实现?
Dropout 的工作原理:
- 在训练时,给每个神经元节点增加一个概率系数 p,使得这个神经元节点的激活值以概率 p 被丢弃(暂停工作),也就是说,每次训练都是随机挑选一组不同的神经元集合进行优化,这能减弱全体神经元之间的联合适应性,减少过拟合的风险,增强返回能力
- 相当于每次迭代都在训练不同结构的神经网络,可以看作是一种模型集成算法,对于包含 N 个神经元节点的网络,可以看作
 个模型的集成。Dropout 作用于小批量训练数据,相较于 Bagging 方法所需时间和空间更少,能实现指数数量级神经网络的训练与评测
个模型的集成。Dropout 作用于小批量训练数据,相较于 Bagging 方法所需时间和空间更少,能实现指数数量级神经网络的训练与评测
注意:测试阶段每个神经元的参数需要预先乘上概率 p
问题三:批量归一化的基本动机与原理是什么?在卷积神经网络中如何使用?
归一化的动机:
- 神经网络的训练本质是学习数据分布,如果训练和测试数据的分布不同,会大大降低网络的泛化能力,因此需要对所有输入数据进行归一化
- 问题:训练的参数变化,使得每一层的输入的分布发生变化
批量归一化 BN:
- 针对每一批数据,在网络的每一层输入之间增加归一化处理(均值为 0,标准差为 1)
- 批量归一化网络层:
 ,针对每一层的每个神经元和,将其输入分布归一化到均值为 0,标准差为 1
,针对每一层的每个神经元和,将其输入分布归一化到均值为 0,标准差为 1- 这增强了模型的泛化能力,但同时降低了模型的拟合能力,因此引入变换重构和可学习参数 γ,β,来恢复原始数据分布

批量归一化在卷积网络中的应用:
- 设每一批训练样本数为 b
- 每一个卷积核生成一个特征图,大小 w×h
- 因此,每个特征图对应的全部神经元个数为 b×w×h,使用一组待学习的参数 γ,β 对每个输入数据进行批量归一化
5、深度卷积神经网络 CNN
问题一:卷积操作的本质特性包括稀疏交互和参数共享,具体解释这两种特性及其作用
稀疏交互:由于卷积核尺度远小于输入的维度,这样每个输出神经元仅与前一层特定局部区域内的神经元存在连接权重
- 作用:
- 相较于全连接,优化过程的时间复杂度将会减小几个数量级,也减少了过拟合现象
- 物理意义:通常图像、文本、语音等现实世界中的数据都具有局部的特征结构,可以先学习局部的特征,再将局部的特征组合起来形成更复杂和抽象的特征
参数共享:同一个卷积核(相当于同一组参数集合)作用于输入的每个局部位置
- 作用:
- 只需要学习一组参数集合,而不需要针对每个未知的每个参数都进行优化
- 物理意义:使得卷积层具有平移等变性
- eg. 假设图像中有一只猫,不论它在什么位置,都应被识别为猫
问题二:常用的池化操作有哪些?池化的作用是什么?
常用的池化操作(针对非重叠区域):
- 均值池化:对邻域内特征数值求平均实现
- 能够抑制由邻域大小受限造成估值方差增大的现象
- 对背景的保留效果好
- 最大池化:取邻域内特征的最大值
- 能够抑制网络参数误差造成估计均值偏移的现象
- 更好地提取纹理信息
特殊的池化方式:
- 相邻重叠区域的池化:窗口滑动存在重叠区域
- 空间金字塔池化:考虑多尺度信息的描述,eg. 同时计算 1×1、2×2、4×4 的矩阵的池化并将结果拼接在一起作为下一网络层的输入
池化操作的作用:
- 池化操作的本质是降采样,能显著降低参数量
- 还能保持对平移、伸缩、旋转操作的不变性
问题三:卷积神经网络如何用于文本分类任务?
6、深度残差网络 ResNet
深度残差网络 ResNet 极大地提高了可以有效训练的深度神经网络的层数
问题一:ResNet 的提出背景和核心力量是什么?
ResNet 的提出背景:
- 为了解决或缓解深度神经网络训练中的梯度消失问题:反向传播通过链式法则计算梯度,那么误差传播到离输入较近(也就是离输出较远)的网络层时,就很可能产生消失或膨胀,导致离输入近的网络层较难训练
梯度消失问题:在梯度的反向传播过程中,后层的梯度以连乘方式叠加到前层。尤其是当激活函数如果使用 sigmoid 函数时,由于它具有饱和特性,当输入的绝对值大到一定值,输出就不会发生明显变了。而后层的梯度本身就比较小,误差梯度反向传播到前层时几乎会衰减为 0,因此无法对前层的参数进行有效的学习
ResNet 的核心力量:
- 给网络层增加直连边(短接),使得离输入近的网络层可以短接到更靠近输出的层
- 残差单元如下图所示,其输出

 即下图的两个网络层,被设计为只需要拟合输入 x 与目标输出
即下图的两个网络层,被设计为只需要拟合输入 x 与目标输出  的残差
的残差 
- 使用了残差单元(短接),增加一层就不会导致模型变得更差,因为短接相当于直接学习了一个恒等映射

若有收获,就点个赞吧
0 人点赞
