模型评估分为离线评估 & 在线评估两个阶段。针对不同的机器学习问题,评估指标的选择也有所不同。
1、评估指标的局限性
问题一:准确率的局限性
场景假设和问题描述: Hulu 的奢侈品广告主们希望将广告定向投放给奢侈品用户。Hulu 拿到了一部分奢侈品用户的数据作为训练集和测试集,对 Hulu 的用户进行二分类,分为奢侈品用户和非奢侈品用户。训练出来的模型分类准确率达到了 95%,但在实际广告投放中,该模型还是把大部分广告投给了非奢侈品用户,这是为什么?
可能的原因:使用准确率作为评估指标不合理;模型过拟合/欠拟合;测试机和训练集划分不合理;线下评估和线上测试的样本分布存在差异
准确率:
- 即分类正确的样本占总样本数的比例
准确率的优点:简单直观
准确率的缺点:当不同类别的样本占比非常不均衡时,占比大的类别往往成为影响准确率的最主要因素
- 针对上面的具体问题,奢侈品用户之占 Hulu 全体用户的一小部分,虽然模型的整体分类准确率高,但不代表对奢侈品用户的分类准确率也高。而在线上投放的过程中,只对模型判定为奢侈品用户的用户投放,就放大了对奢侈品用户分类准确率不高的问题
解决方法:可以使用更为有效的平均准确率(每个类别下的样本准确率的算术平均)作为评估指标
问题二:精确率与召回率的权衡
场景假设和问题描述: Hulu 提供视频的模糊搜索功能,搜索排序模型返回的 Top 5 的精确率(Precision@5)非常高,但在实际使用过程中,用户还是经常找不到想要的视频,特别是一些比较冷门的剧集,这可能是哪个环节出了问题呢?

精确率 Precision:
- 分类正确的正样本数占分类器判定为正样本的样本个数的比例
召回率 Recall:
- 分类正确的正样本数占真正的正样本个数的比例
精确率和召回率是既矛盾又统一的两个指标:
- 为了提高精确率,分类器需要尽量在更有把握时才将样本预测为正样本
- 但分类器过于保守会漏掉很多“不够有把握”的正样本,导致召回率降低
上面的场景描述中,只用精确率作为评估指标,Top 5 的精确率 Precision@5 非常高,但用户经常找不到想要的视频,那么问题应该出现在召回率上。对于排序问题,模型返回的 Top N 结果就是判定的正样本。如果实际的正样本(即和用户搜索相关的样本)有 100 个,那么召回率 Recall@5 相当于只有 5%,非常低
为了综合评估一个排序模型的好坏:
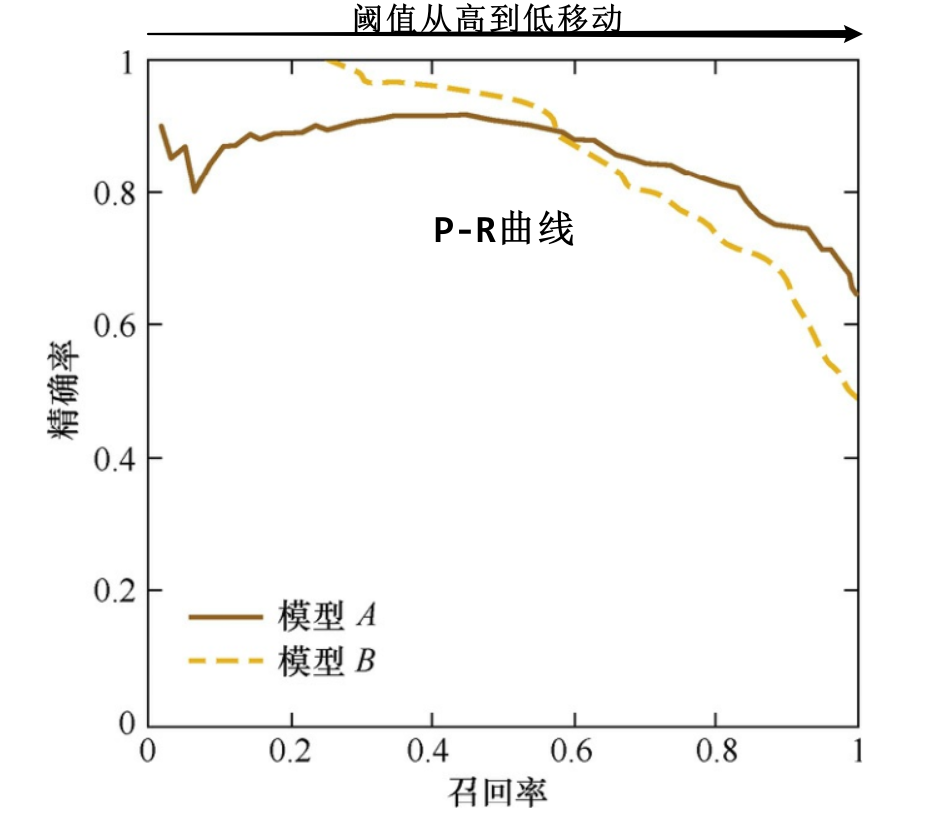
- 不仅要看模型在不同 Top N 下的 Precision@N 和 Recall@N,而且最好还要绘制出模型的 P-R 曲线
- P-R 曲线纵轴是精确率,横轴是召回率
- 整条 P-R 曲线是阈值从高到低移动生成的。对于每个阈值,模型将大于该阈值的点预测为正样本,其余为负样本,计算得到该阈值对应的精确率和召回率
- 还可以使用:
- F1 score:

- ROC 曲线
- F1 score:
问题三:平方根误差的“意外”
2、ROC 曲线
二值分类器的评估指标:precision、recall、F1 score、P-R 曲线
ROC 曲线是评估二值分类器最重要的指标之一
问题一:什么是 ROC 曲线?
ROC 曲线:
- 横坐标:假阳性率
 ,FP 是 N 个负样本中被错误预测为正样本的个数,N 是真实的负样本个数
,FP 是 N 个负样本中被错误预测为正样本的个数,N 是真实的负样本个数 - 纵坐标:真阳性率 ,TP 是 P 个正样本中被正确预测为正样本的个数,P 是真实的正样本个数
问题二:如何绘制 ROC 曲线?
在二值分类问题中,模型的输出一般并不是 0、1 二值,而是预测样本为正例的概率。因此,为了得到最后的预测结果(判定为正例 or 负例),就要设定一个阈值,如果预测概率大于等于该阈值,则被判定为正例,否则为负例
绘制 ROC 曲线的两种方法:
- 方法一:通过从高到低调整阈值(截断点)来生成曲线上的一组关键点
- 初始将阈值设为正无穷,然后从高到低遍历各样本的预测概率作为阈值,每个阈值都对应一个 FPR 和 TPR,就得到 ROC 曲线的一个关键点。连接所有的关键点就得到 ROC 曲线
- 方法二:更直观的方法:
- 根据样本标签统计出正样本的数量 P,负样本的数量 N
- 把横轴的刻度间隔设置为 1/N,纵轴的刻度间隔设置为 1/P
- 根据模型输出的预测概率从高到低对样本进行排序
- 依次遍历样本,同时从零点开始绘制曲线
- 每遇到一个正样本就沿纵轴方向绘制一个刻度间隔的曲线
- 每遇到一个负样本就沿横轴方向绘制一个刻度间隔的曲线
- 遍历完所有样本,曲线最终停在点 (1, 1)
示例:
| 样本序号 | 真实标签 | 模型输出概率 | 样本序号 | 真实标签 | 模型输出概率 |
|---|---|---|---|---|---|
| 1 | P | 0.9 | 11 | P | 0.4 |
| 2 | P | 0.8 | 12 | N | 0.39 |
| 3 | N | 0.7 | 13 | P | 0.38 |
| 4 | P | 0.6 | 14 | N | 0.37 |
| 5 | P | 0.55 | 15 | N | 0.36 |
| 6 | P | 0.54 | 16 | N | 0.35 |
| 7 | N | 0.53 | 17 | P | 0.34 |
| 8 | N | 0.52 | 18 | N | 0.33 |
| 9 | P | 0.51 | 19 | P | 0.30 |
| 10 | N | 0.505 | 20 | N | 0.1 |

问题三:如何计算 AUC?
AUC 是 ROC 曲线下的面积大小,AUC 的取值一般在 0.5~1 之间(如果低于 0.5,将模型预测的概率反转为 1-p 即可得到一个更好的分类器)
- 作用:能够量化地反映基于 ROC 曲线衡量出的模型性能
- AUC 越大,说明分类器的分类性能越好
- 计算方式:沿着 ROC 横轴做积分
问题四:ROC 曲线相比 P-R 曲线有什么特点?
特点:当正负样本的分布发生变化时,ROC 曲线的形状能够基本保持不变,而 P-R 曲线的形状一般会发生较剧烈的变化
因此,ROC 曲线能尽量降低不同测试集带来的干扰,更加客观地衡量模型本身的性能
- 实际意义:很多实际问题中,正负样本数量往往很不均衡,eg. 广告领域地转化率模型,正样本的数量往往是负样本数量地 1/1000 甚至 1/ 10000,若选择不同的测试集,P-R 曲线的变化就会非常大,而 ROC 曲线则能更加稳定地反映模型本身的好坏。因此,ROC 曲线能适应更多场景
反之,如果希望能更多地看到模型在特定数据集上的表现,P-R 曲线则能更直观地反映其性能
3、余弦距离的应用
问题一:结合你的学习 or 研究经历,探讨为什么在一些场景中要使用余弦相似度而不是欧氏距离?
问题二:余弦距离是否是一个严格定义的距离?
4、A/B 测试的陷阱
问题一:在对模型进行过充分的离线评估之后,为什么还要进行在线的 A/B 测试?
- 离线评估无法完全消除模型过拟合的影响,因此离线评估结果无法完全替代线上评估结果
- 离线评估无法完全还原线上的工程环境(eg. 延迟、数据丢失、标签数据缺失等情况)
- 线上系统的某些商业指标在离线评估中无法计算
问题二:如何进行线上 A/B 测试?
进行用户分桶:即将用户分为实验组(使用新模型)和对照组(使用旧模型),
- 分桶时要注意样本的独立性(同个用户每次只能在同一个桶)和无偏性(随机选取 user_id 进行分桶)
问题三:如何划分实验组和对照组?
5、模型评估的方法
问题一:在模型评估过程中,有哪些主要的验证方法,它们的优缺点是什么?
Holdout 检验:
- 按一定比例将数据集随机划分为训练集和验证集
- 缺点:在验证集上计算出来的评估指标与原始分组有很大关系(存在随机性)
交叉验证:
- k-fold 交叉验证:将全部样本划分为 k 个相同大小的样本子集,每次以其中一个样本子集作为验证集,其余所有样本子集作为训练集,进行模型的训练和评估。将 k 次评估指标的平均值作为最终的评估值指标
- k 经常取 10
- 优点:能避免 Holdout 检验带来的随机性
- 留一验证:每次只留下一个样本作为验证集
- 缺点:在样本总数较多的情况下,时间开销极大
自助法:
- 对于总数为 n 的样本集合,进行 n 次有放回的随机抽样,得到大小为 n 的训练集(可能包含被重复采样的样本),剩余未被抽样过的样本作为验证集
- 优点:当样本规模较小时,避免划分训练集和测试集导致的训练集进一步减小,影响模型训练效果
问题二:在自助法的采样过程中,对 n 个样本进行 n 次自助抽样,当 n 趋于无穷大时,最终有多少数据从未被选择过?
- 一个样本在一次抽样中未被抽中的概率为

- 一个样本在 n 次抽样中均为被抽中的概率为

- 当 n 趋于无穷大时,

- 当 n 趋于无穷大时,
- 因此,当样本数很大时,大约有 36.8% 的样本从未被选择过,这些样本可以作为验证集
6、超参数调优
问题一:超参数有哪些调优方法?
超参数搜索算法的几个要素:
- 目标函数:即算法需要最大化/最小化的目标
- 搜索范围:一般通过上限和下限来确定
- 算法的其他参数:eg. 搜索步长等
网格搜索:
- 通过查找搜索范围内的所有的点来确定最优值。若采用较大的搜索范围 & 较小的步长,就有很大概率找到全局最优值
- 缺点:十分消耗计算资源和时间,特别是需要调优的超参数比较多的时候
- 改进:网格搜索的快速版
- 先使用较广的搜索范围和较大的步长,来寻找全局最优值可能的位置;然后逐渐缩小搜索范围和步长,来寻找更精确的最优值
- 缺点:由于目标函数一般是非凸的,所以很可能会错过全局最优值
随机搜索:
- 在搜索范围内随机选取样本点。如果样本点集足够大,那么也能找到全局最优值 or 近似值
- 优点:比网格搜索要快一点
- 缺点:同网格搜索的快速版,没法保证找打的结果是全局最优值
贝叶斯优化算法:
- 充分利用之前的信息:通过对目标函数形状进行学习,找到使目标函数向全局最优值提升的参数
- 学习目标函数形状的方法:首先根据先验分布,假设一个搜集函数;然后,每一次使用新的采样点来测试目标函数时,利用这个信息来更新目标函数的先验分布;最后,算法测试由后验分布给出的全局最优值可能出现的位置的点
- 缺陷:一旦找到一个局部最优值,就会在该区域不断采样,很容易陷入局部最优值
- 改进:在探索 & 利用之间找到一个平衡点
- 探索:在还未取样的区域内获取采样点
- 利用:根据后验分布在最可能出现全局最优值的区域进行采样
7、过拟合与欠拟合
问题一:在模型评估过程中,过拟合和欠拟合具体指什么现象?
过拟合:
- 模型对训练数据拟合过当,在训练集上表现很好,但在测试集和新数据上表现较差
- 可能是模型过于复杂,把噪声数据的特征也学习到模型中,导致模型泛化能力下降
欠拟合:
- 模型在训练和预测时表现都不好

问题二:能否说出几种降低过拟合和欠拟合风险的方法?
降低过拟合风险的方法:
- 使用更多的训练数据(最有效的方法),更多的样本能让模型学习到更多更有效的特征,减小噪声的影响
- 直接增加实验数据(一般很困难)
- 数据增强
- 生成对抗网络合成新训练数据
- 适当降低模型复杂度:eg. 减少网络层数、神经元个数,降低决策树深度、剪枝等
- 正则化方法:
- L2 正则化:

- 即,将权值大小加入到损失函数
 中,避免权值过大带来的过拟合风险
中,避免权值过大带来的过拟合风险
- 即,将权值大小加入到损失函数
- L2 正则化:
- 集成学习方法:将多个模型集成在一起,来降低单一模型的过拟合风险
降低欠拟合风险的方法:
- 添加新特征:特征不足 or 现有特征与样本标签的相关性不强使,就容易出现欠拟合
- 可以挖掘新的特征(深度学习模型可以帮助完成特征工程)
- 增加模型复杂度:
- 减小正则化系数:

若有收获,就点个赞吧
0 人点赞
