5.1 索引基础
索引从本质上来说是一种用于快速找到记录的数据结构,在MySQL中先通过索引找到对应的值,然后根据匹配的索引记录找到对应的数据数据行。索引的实现层是存储引擎。
5.1.1 索引的类型
B-Tree索引
- 1 所有的值必须按照顺序进行存储,并且每个叶子节点到根节点的距离是相同的。B-Tree索引能够加快访问数据的速度,因为存储引擎不在需要进行全表扫描来获取需要的数据,而是从索引的根部开始进行搜索。根节点中的槽存放了指向叶子节点的指针,存储引擎通过这些指针往下搜索数据,这些指针实际存储的是叶子节点中页的上限和下限,最终存储引擎要么没有找到数据,要么该记录不存在。
- 2 索引树种节点都是有序的,所以除了按照值查找以外,索引还可以用于查询中的ORDER BY操作,一般来说如果索引可以按照某种方式查找到值,那么也可以按照这种方式进行排序
- 3 索引最重要的原则为最左匹配原则。
哈希索引
- 1 哈希索引基于哈希表实现,只有精确匹配索引的所有列才有效,对于每一行数据,存储引擎会对所有的索引项计算一个哈希值,哈希索引将所有的哈希码存储在索引中,同时哈希表中保存指向每个数据行的指针。哈希索引值包含哈希值和行指针,而不存储字段值。在MySQL中只有memory限时支持哈希索引。
- 2 伪哈希索引
假如需要对很多的url进行搜索查找,如:select id from url where url= like “http://www.baidu.com",可在原来的表新增字段URL_CRC,然后通过程序或者触发器实时更新URL_CRC值,然后再该新字段上面添加索引, ALTER TABLE URL ADD INDEX IDX_URL_CRC(URL_CRC),搜索的时候使用select id from url where url=”http://www.baidu.com“ and url_crc=crc32(“http://www.baidu.com“)
空间索引
MyISAM表支持空间索引,可以用作地理数据存储,这类索引无需前缀查询,目前GIS做的比较出色的当属PG。
全文索引
全文索引查找的是文本中的关键字,而不是直接比较索引中的值。全文索引和其他索引很大的不同,不是简单的where的匹配。开源软件ES目前针对全文检索做的最为出色。
5.2 索引的优点
- 1 加快检索通过索引直接定位数据,减少服务器需要扫描的数据量
- 2 索引可以帮助服务器避免排序和临时表
- 3 索引将随机IO转化成顺序IO
索引是最好的方案吗?答案并非如此
- 1.当表数据量很小的时候,全表查询速度反而是高于索引的
- 2.对于中型表,索引是非常有效的,可以呈几何指数的提高查询性能
- 3.针对特大型表,建立索引和使用索引的代价反而也增高。这种情况下,需要一种技术可以很快的按照分区一块一块的定位数据,而不再是一行一行的匹配记录,比方说的分区表,分表分库的机制。
- 4.针对海量表,则有必要建立一个元数据信息表,用来查询需要用到的那些特性,比方说记录那个用户的数据存储在哪张表里面,常用的infobright就是使用类似的原理实现,针对TB级别的数据,定位单条的记录已经没有太大意义,取而代之的使用块级别元数据来替代索引。
5.3 高性能索引策略
- 1.必须是独立的列,换而言之,字段前面不能使用函数,不能是表达式的一部分。如果字段前面添加函数,那么我们就对原来整理好的索引项全部重新进行函数转化了,转化后的数据就失去了索引的顺序性。因而字段前面禁止增加函数和表达式。
- 2.前缀索引
计算前缀索引的长度选择原则是使前缀的选择性尽量的接近完整列的选择性。
selectcount(distinct city)/count(*) as demorate,count(distinct left(city,3))/count(*) as city3,count(distinct left(city,4))/count(*) as city4,count(distinct left(city,5))/count(*) as city5,count(distinct left(city,6))/count(*) as city6from city_demo;alter table city_demo add index idx_city(city(6));
- 3.多列索引
索引合并策略有时候是一种优化后的结果,但是在某种程度上面来说说明SQL写的不好或者索引建立的很糟糕- 当服务器出现多个索引做相交操作,通常来说是多个and,这意味着需要一个包含所有相关列的符合索引,而不是单个的索引。
- 当服务器需要对多个索引做联合操作的时候,通常来说是多个or,这意味着需要耗费CPU进行排序、联合、分组、合并等昂贵的操作。
5.4 索引列顺序
假设有如下SQL,请问如何建立有效索引:
select * from ta where staff_id=2 and customer_id=584
到底是建立idx_staff_id_customer_id(staff_id,customer_id),还是建立idx_customer_id_staff_id(customer_id,staff_id)。在没有其他因素干扰的情况下,那个字段辨识度越高越放前面。
selectcount(distinct customer_id)/count(*) as customer_id_rate,count(distinct staff_id)/count(*) as staff_id_ratefrom payment;alter table payment add index idx_customer_id_staff_id(customer_id,staff_id);
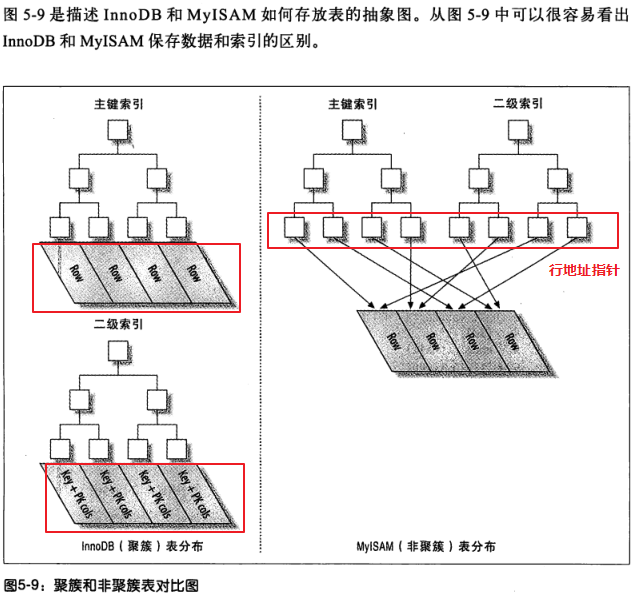
5.5 聚簇索引
聚簇索引不是一种单独的索引类型,而是一种数据存储方式,在innodb的聚簇索引中同一个机构中B-Tree不仅保存索引值,又保存了数据行。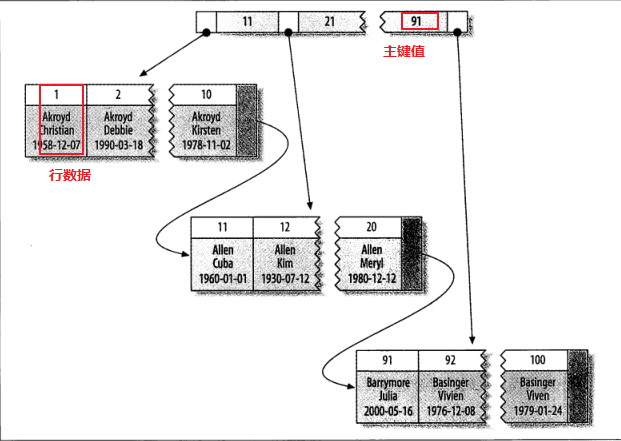
聚集索引在oracle里面又被称之为索引组织表,聚簇索引的优点有如下几点:
把相关的数据保存在一起,这样用户只需要从磁盘读取少量的数据页就可以获取这个用户的全部邮件,通过主键获取行数据非常快。但是同时也存在缺点,插入数据严重依赖顺序,如果需要更新聚簇索引列那么代价非常高,同时也存在页分裂和合并等问题,二级索引访问数据需要两次索引查找。这个是因为二级索引的叶子索引保存的不是物理地址,而是主键索引的值。
myisam索引图: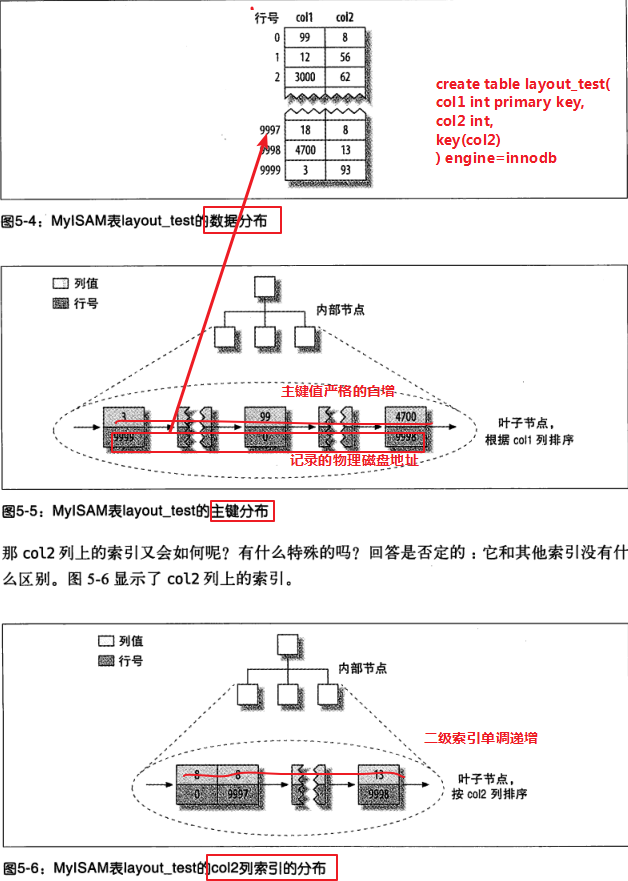
innodb索引图: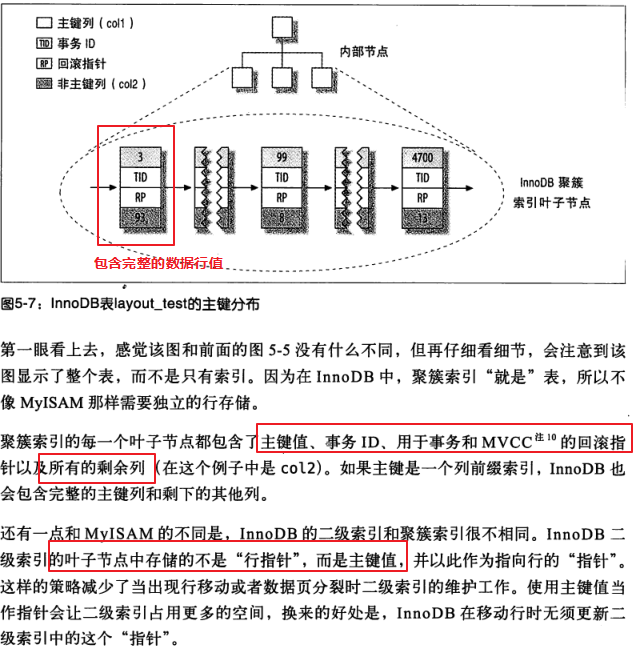
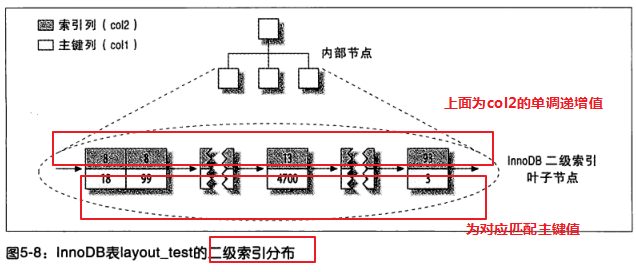
5.6 索引覆盖
索引确实是一种查找数据的方式,但是MySQL可以通过索引直接拿取数据,这样就不再直接读取数据行。如果索引的叶子节点已经包含了要查询的数据,那么就没有必要再回表查询一次,如果一个索引中包含了所有需要查询字段的值,我们称之为覆盖索引。
覆盖索引是一种很有效的优化方式,能够极大的提高性能,考虑一下如何查询只扫描索引而无需回表,那么带来的好处如下:
- 索引条目通常来说远远小于数据行的大小,如果只需要扫描索引,那么就会极大的减少数据访问量。
- 如果索引是按照列值顺序排列的,那么对于IO密集型的范围查询比随机从磁盘读取数据的IO要少得多,这使得范围查询能够使用完全顺序的索引查找方式变得可能。
- 一些存储引擎如MyISAM在内存中只缓存索引,数据则严重的依赖操作系统来缓存,因此要访问数据就需要一次系统调用。
- 由于Innodb的聚簇索引,覆盖索引对Innodb表非常有用,Innodb的二级索引在叶子节点中保存了行的主键值,所以如果二级索引可以完成覆盖查询,则可避免对主键索引的二次查询。
不是所有的存储引擎都支持覆盖查询,覆盖索引必须满足的是索引里面存储索引列对应的值。因而只有Innodb索引可以实现覆盖索引
Create Table: CREATE TABLE `inventory` (`inventory_id` mediumint(8) unsigned NOT NULL AUTO_INCREMENT,`film_id` smallint(5) unsigned NOT NULL,`store_id` tinyint(3) unsigned NOT NULL,`last_update` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,PRIMARY KEY (`inventory_id`),KEY `idx_fk_film_id` (`film_id`),KEY `idx_store_id_film_id` (`store_id`,`film_id`),CONSTRAINT `fk_inventory_film` FOREIGN KEY (`film_id`) REFERENCES `film` (`film_id`) ON UPDATE CASCADE,CONSTRAINT `fk_inventory_store` FOREIGN KEY (`store_id`) REFERENCES `store` (`store_id`) ON UPDATE CASCADE) ENGINE=InnoDB AUTO_INCREMENT=4582 DEFAULT CHARSET=utf8mb4;explain select store_id,film_id from inventory\G*************************** 1. row ***************************id: 1select_type: SIMPLEtable: inventorytype: indexpossible_keys: NULLkey: idx_store_id_film_idkey_len: 3ref: NULLrows: 4581Extra: Using index1 row in set (0.00 sec)
通过观察我们看到extra列展示的using index,代表该查询通过索引覆盖的方式完成了查询。
针对部分无法使用索引的情况下,巧用延迟关联使用索引覆盖进行数据查询:
如果
具体案例
原SQL:mysql> explain select * from inventory where store_id=1 and film_id like '%25%';+----+-------------+-----------+------+----------------------+----------------------+---------+-------+------+-----------------------+| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |+----+-------------+-----------+------+----------------------+----------------------+---------+-------+------+-----------------------+| 1 | SIMPLE | inventory | ref | idx_store_id_film_id | idx_store_id_film_id | 1 | const | 2269 | Using index condition |新SQL:mysql> explain select * from inventory ta join ( select inventory_id from inventory where store_id=1 and film_id like '%25%' ) tb on ta.inventory_id=tb.inventory_id;+----+-------------+------------+--------+----------------------+----------------------+---------+-----------------+------+--------------------------+| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |+----+-------------+------------+--------+----------------------+----------------------+---------+-----------------+------+--------------------------+| 1 | PRIMARY | <derived2> | ALL | NULL | NULL | NULL | NULL | 2269 | NULL || 1 | PRIMARY | ta | eq_ref | PRIMARY | PRIMARY | 3 | tb.inventory_id | 1 | NULL || 2 | DERIVED | inventory | ref | idx_store_id_film_id | idx_store_id_film_id | 1 | const | 2269 | Using where; Using index |+----+-------------+------------+--------+----------------------+----------------------+---------+-----------------+------针对二级索引列是包含主键值的,那么返回主键的查询是可以使用索引扫描```sqlexplain select actor_id last_name from actor where last_name ='fdafd'\G*************************** 1. row ***************************id: 1select_type: SIMPLEtable: actortype: refpossible_keys: idx_actor_last_namekey: idx_actor_last_namekey_len: 182ref: constrows: 1Extra: Using where; Using index
5.7 使用索引扫描实现排序
MySQL中可以使用两种方案实现排序,方案一 通过排序操作;方案二 通过索引顺序扫描,如果EXPLAIN出来的type列出现了index,则说明MySQL使用率索引扫描来做排序
扫描索引本身是比较快的,因为只需要从一个索引的记录移动到下一条记录,但是如果索引扫描不能覆盖查询所需要的全部列,那就不得不每扫描一条索引记录就都回表查询一次对应的行,这基本是随机IO,因此按照索引顺序读取数据的速度通常要比顺序的读取全表扫描慢。
所以在设计的时候,可以使用同一个索引既满足排序,又用于查找数据行
5.8 冗余和重复索引
假设表A主键为id,有属性值name,其实创建索引IDX_NAME(name),他是包含主键ID.
索引检查工具 pt-duplicate-key-checker
索引使用频率工具 pt-index-usage
查询对应表 select * from information_schema.statistics
5.9 索引和锁
索引可以让查询锁定更少的行,如果你的查询不访问那些你不需要的行,那么就会锁定更少的行。如果索引无法有效的过滤掉无效的行,那么在innodb检索到数据并返回给服务器层以后,MySQL服务器才能应用到WHERE子句,这时候就无法避免锁定行了:innodb已经锁住了这些行,到适当的时候才释放【MySQL5.1版本以后是服务器端过滤掉了就释放了锁】。通过一个例子证明索引锁定的行数:
会话1:mysql> use sakila;Reading table information for completion of table and column namesYou can turn off this feature to get a quicker startup with -ADatabase changedmysql>mysql> set autocommit=0;Query OK, 0 rows affected (0.00 sec)mysql> begin;Query OK, 0 rows affected (0.00 sec)mysql> select actor_id from actor where actor_id < 5 and actor_id <> 1 for update;+----------+| actor_id |+----------+| 2 || 3 || 4 |+----------+3 rows in set (0.00 sec)mysql> explain select actor_id from actor where actor_id < 5 and actor_id <> 1 for update;+----+-------------+-------+-------+---------------+---------+---------+------+------+--------------------------+| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |+----+-------------+-------+-------+---------------+---------+---------+------+------+--------------------------+| 1 | SIMPLE | actor | range | PRIMARY | PRIMARY | 2 | NULL | 3 | Using where; Using index |+----+-------------+-------+-------+---------------+---------+---------+------+------+--------------------------+1 row in set (0.00 sec)
虽然只返回了2,3,4三条数据,但是实际上了锁定了4行数据。因为在EXTRA里面出现了USING where,证明有条件actor_id <> 1是在服务器端进行where过滤的。下面的例子证明第一行确实被锁住了
会话二:mysql> set autocommit=0;Query OK, 0 rows affected (0.00 sec)mysql> begin;Query OK, 0 rows affected (0.00 sec)mysql> select actor_id from actor where actor_id=1 for update;
发现会话2迟迟无法得到返回,证明被第一个查询锁住了。
关于Innodb,在二级索引上使用共享锁,但访问主键索引需要排他锁
5.10 索引实战
- 1.标识度越高的建议放到前面
- 2.针对枚举类型,使用in代替范围查询
- 3.针对排序,可以使用延迟关联的方案进行优化
5.11 维护索引和表
analyze table ta;— 收集索引信息,不锁表,速度快
optimize table ta;— 整理碎片等优化索引,会锁表
alter table ta engine=innodb;— 重建表

若有收获,就点个赞吧
0 人点赞
