7.1分区表
对用户来说分区表是一个独立的逻辑单元,对应用是透明的。但是底层是由多个物理表组成的,实现分区表的代码实际上对一组底层表的句柄对象的封装。分区表额主要目的就是将数据按照一个粗的粒度分到不同的表中。
原理:分区表实际上是很多的普通表,底层表都是由句柄对象调用存储引擎来执行。无论是增删改查都是先锁住底层所有表,然后根据分区键找到对应的分区,再调用对应的存储引擎接口来访问各个分区的数据。
类型:比较常用的按照范围进行分区
create table sales(order_date datetime not null comment "订单日期") engine =innodb partition by range(year(order_date))(partition p_2010 values less than (2010),partition p_2011 values less than (2011),partition p_catchaall values less than MAXVALUE);
弊端:当分区列和索引列不匹配的时候,可能会造成查询无法进行分区过滤。相当于每个查询都必须带上分区键,这样才可能有效的锁定到某个范围。
注意点:由于分区表在MySQL并不成熟,实际上生产环境使用该特性的比较少,但是我们需要理解这种思想,对于更大的数据量其实inforbrigth使用基于块数据的访问思路。
7.2视图
- 1 MySQL视图,视图本来就是一个虚拟的表,不存放数据,只有表定义的语句。在SQL访问视图的时候,本质是通过视图语句转化成原来的物理表的SQL操作。这里有两个重要算法:
- 2 合并算法,如果原表记录和视图记录建立的是一对一的衍射关系,那么通过视图查询就是合并算法,索引利用率则更高。
CREATE VIEW `view_check_info` ASselect APPLY_HOSPITAL_FK,check_no,adm_id,patient_name from `check_info`where (`check_info`.`APPLY_HOSPITAL_FK` = 100149)mysql> explain select * from view_check_info where check_no='457878';+----+-------------+------------+------+-----------------+-----------------+---------+-------------+------+-----------------------+| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |+----+-------------+------------+------+-----------------+-----------------+---------+-------------+------+-----------------------+| 1 | SIMPLE | check_info | ref | idx_hos_checkno | idx_hos_checkno | 68 | const,const | 1 | Using index condition |+----+-------------+------------+------+-----------------+-----------------+---------+-------------+------+-----------------------+
- 3 临时表算法,如果原表记录和视图记录建立的非一对一的衍射关系,比方说视图中使用group by,distinct,聚合函数,union等,在外层视图查询的使用只能使用派生表的查询方式。
CREATE VIEW `view_check_info` ASselect distinct APPLY_HOSPITAL_FK,check_no,adm_id,patient_name from `check_info`where (`check_info`.`APPLY_HOSPITAL_FK` = 100149)mysql> explain select * from view_check_info where check_no='457878';mysql> explain select * from view_distinct_check_info where check_no='457878';+----+-------------+------------+------+-----------------+-----------------+---------+-------+--------+-------------+| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |+----+-------------+------------+------+-----------------+-----------------+---------+-------+--------+-------------+| 1 | PRIMARY | <derived2> | ref | <auto_key0> | <auto_key0> | 63 | const | 10 | Using where || 2 | DERIVED | check_info | ref | idx_hos_checkno | idx_hos_checkno | 5 | const | 285348 | NULL |+----+-------------+------------+------+-----------------+-----------------+---------+-------+--------+-------------+
下面为两者示意图: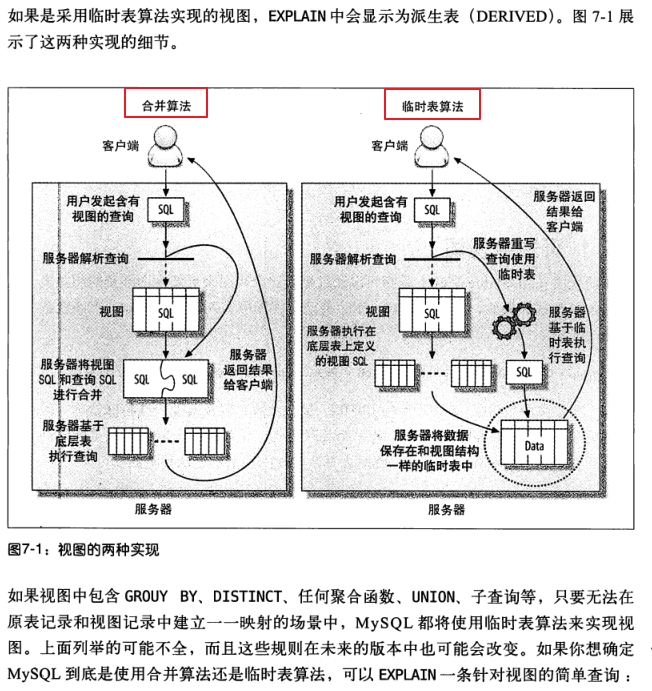
- 4 物化视图:不仅存储了最新的表结构而且存储了最新的数据,只是说数据的同步做到了实时,且对用户无感知。
7.3分布式(XA)事务
存储引擎的事务特性能够保证在存储引擎级别实现ACID,而分布式事务则让存储引擎级别的ACID拓展到数据库层面,甚至是多个数据库实例之间,这就需要大名鼎鼎的二阶段提交。
在MySQL中主要存在两种XA事务。一方面,MySQL可以参与到外部的分布式事务中;第二方面,自己可以通过XA事务来协调存储引擎和binlog数据的同步问题。
在这里面我们假设MySQL记录binlog看做是一个独立的存储引擎,那么原来innodb和这个存储引擎就构成了XA分布式事务。

若有收获,就点个赞吧
0 人点赞
