1 优先级队列PriorityQueue
1.1概念
用数组按层序遍历顺序存放二叉树
一般都是完全二叉树,因为数组存放的特性,如果二叉树有空则会导致空间的浪费
1.2下标关系
已知父亲节点推测孩子节点下标:
左孩子:2parent+1
右孩子:2parent+2
一致孩子节点推测双亲结点下标:
(child-1)/2
2 堆
2.1概念
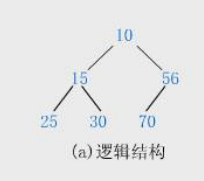
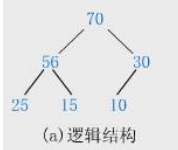
- 堆逻辑上是一颗完全二叉树
- 堆物理上是保存在数组中的
- 满足任意节点的值都大于其子树终结点的值,叫作大堆,或者大根堆,或者最大堆
- 反之,则是小堆,或者小根堆,或者最小堆
- 堆的基本作用是:款苏找集合中的最值
2.2操作—向下调整
前提:左右子树必须已经是一个堆,才能调整
说明:
- array 代表存储堆的数组
- size 代表数组中被视为堆数据的个数
- index 代表要调整位置的下标
- left 代表 index 左孩子下标
- right 代表 index 右孩子下标
- min 代表 index 的最小值孩子的下标
2.3操作—建堆
看起来是建立了一个数组,但是逻辑上可以看作是一棵完全二叉树
通过算法将其构建成堆
从最后一个节点开始调整,一直到根节点
最后调整成堆
3 堆的应用—优先级队列
3.1概念
在很多应用中,我们通常需要按照优先级情况对待处理对象进行处理
比如首先处理优先级最高的对象,然后处理次高的对象
最简单的一个例子就是,在手机上玩游戏的时候,如果有来电,那么系统应该优先处理打进来的电话
在这种情况下,我们的数据结构应该提供两个最基本的操作:
- 一个是返回最高优先级对象
- 一个是添加新的对象
这种数据结构就是优先级队列(Priority Queue)
3.2原理
优先级队列的实现方式有很多,但最常见的是使用堆来构建
3.3操作—入队列
过程(以大堆为例):
1. 首先按尾插方式放入数组
2. 比较其和其双亲的值的大小,如果双亲的值大,则满足堆的性质,插入结束
3. 否则,交换其和双亲位置的值,重新进行 2、3 步骤
4. 直到根结点
public static void shiftUp(int[] array, int index) {while (index > 0) {int parent = (index - 1) / 2;if (array[parent] >= array[index]) {break;}int t = array[parent];array[parent] = array[index];array[index] = t;index = parent;}}
3.4操作—出队列
为了防止破坏堆的结构,删除时并不是直接将堆顶元素删除,而是用数组的最后一个元素替换堆顶元素,然后通过向 下调整方式重新调整成堆
3.5返回队首元素(优先级最高)
3.6java的优先级队列
PriorityQueueimplements Queue
| 错误处理 | 抛出异常 | 返回特殊值 |
|---|---|---|
| 入队列 | add(e) | offer(e) |
| 出队列 | remove() | poll() |
| 队首元素 | element() | peek() |
4 对的其他应用—TopK问题
4.1TopK问题
1000个数据,找出k个最大的数据
思路:
关键记得,找前 K 个最大的
要建大小为 K 的小堆
前K个建成一个小堆
从K+1个数据开始每个数据和堆顶元素比较如果比堆顶大,就入队
topk问题的时间复杂度:**_n_**``**logk**
public static int[] topk(int k) {//建立大小为k的小堆PriorityQueue<Integer> priorityQueue = new PriorityQueue<>(k);//遍历数组元素,将前k个元素放到小堆int[] a = new int[1000];for (int i = 0; i < a.length; i++) {a[i] = i;}for (int j = 0; j < k; j++) {priorityQueue.offer(j);}//从第1个值开始,和堆顶元素进行比较//应该本来就是个小堆//当前元素比堆顶大,那么先出pop 再入offerfor (int m = k; m < a.length; m++) {if (a[m] >= priorityQueue.peek()) {priorityQueue.poll();priorityQueue.offer(a[m]);}}//输出堆中最大元素//因为是小堆 所以是堆底元素不是堆顶int[] b = new int[k];for (int i = 0; i < k; i++) {b[i] = priorityQueue.poll();}return b;}
4.2topk反向问题
找最小的K个
建一个大小为K的大堆
4.3求第K大的数据
topk问题的堆顶元素就是第K大的
5 堆排序算法

从小到大排序——大堆
从大到小排序——小堆
每一次排序,确定一个当前最大的数,useSize--;
时间复杂度 O(n*logn)
空间复杂度O(1) 稳定性
原理
使用end = array.length-1最后的结点与0下标交换
调用adjust方法调整使其再次成为大根堆
轮转至end = 0意味着每个位置都放到堆顶调整过,保证其数组整体顺序
adjust调整
传入树,parent结点,以及长度len
利用双亲结点得到其子节点下标
在确认其子节点存在后,进行调整
子节点val大于双亲结点val,则交换,同时交换下标
否则,跳出循环
_
createHeap创建大根堆
将二叉树的每个双亲结点放入调整函数
创建出来的尽管是大根堆,但是并不能够保证其左右同高度结点之间的顺序是否正确
heapSort堆排序主体
创建大根堆
end 与 0 交换
end遍历调整堆
得到顺序数组
方法:
- adjust——>调整
- createHeap——>创建堆
heapSort——>堆排序主体 ```java public static void adjust(int[] array, int parent, int len) {
int child = parent*2+1;while (child < len) {if(child+1 < len ) {child++;}if(array[child] > array[parent]) {int tmp = array[child];array[child] = array[parent];array[parent] = tmp;parent = child;child = 2*parent+1;}else{break;}}
}
public static void createHeap(int[] array){
for (int i = (array.length-1-1)/2; i >= 0; i--) {//i为每棵树的parent结点adjust(array,i,array.length);}
}
public static void heapSort(int[] array) {
//大堆——>O(n)createHeap(array);//排序——>O(n*logn)int end = array.length-1;//最后一位,用于交换while(end > 0) {//当前节点与0位置交换位置int tmp = array[0];array[0] = array[end];array[end] = tmp;//换完调整adjust(array,0,end);end--;}
}
*稳定性判断原则
判断排序的稳定性: 有重复元素存在时,相同数字本来在前排序后还在前就意味着稳定 主要依据是否存在跳跃式的交换

若有收获,就点个赞吧
0 人点赞
