
代码拆分的四种方式
- 入口起点
- 入口依赖(dependOn)
- SplitChunksPlugin
- 动态导入
在项目中常见的四种文件
- xxx.bundle.js
- xxx.vendros.js
- xxx.chunk.js
- runtime
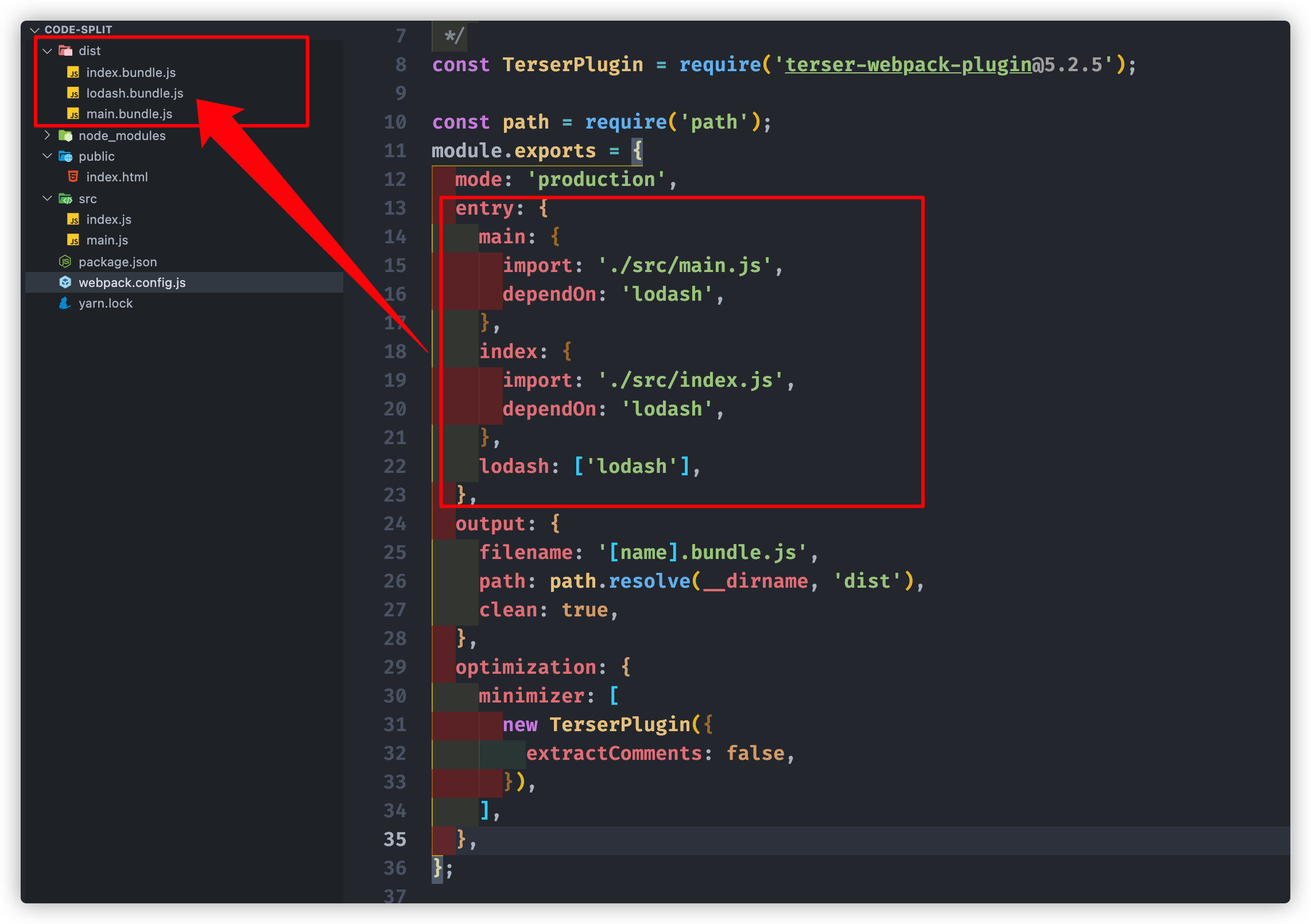
代码拆分
入口起点bundle
entry:{main:"./src/main.js",index:"./src/index.js"},output:{path:path.resolve(__dirname,'dist'),filename:"[name].bundle.js"}
dependOnbundle
entry:{main:{import:"./src/main.js",dependOn:"shared"},index:{import:"./src/index.js",dependOn:"shared"},shared:['lodash','axios']},output:{path:path.resolve(__dirname,'dist'),filename:"[name].bundle.js"}
或
entry:{main:{import:"./src/main.js",dependOn:["shared","lodash"]},index:{import:"./src/index.js",dependOn:"shared"},shared:"shared",lodash:"lodash"},output:{path:path.resolve(__dirname,'dist'),filename:"[name].bundle.js"}
splitChunksvendors
可以将node_modules中的代码单独打包一个chunk
多入口中可以自动分析入口文件中有没有公共的依赖,如果有会打包成一个文件
module.exports = {//...optimization: {splitChunks: {//在cacheGroups外层的属性设定适用于所有缓存组,不过每个缓存组内部可以重设这些属性chunks: "async", //将什么类型的代码块用于分割,三选一: "initial":入口代码块 | "all":全部 | "async":按需加载的代码块minSize: 30000, //大小超过30kb的模块才会被提取maxSize: 0, //只是提示,可以被违反,会尽量将chunk分的比maxSize小,当设为0代表能分则分,分不了不会强制minChunks: 1, //某个模块至少被多少代码块引用,才会被提取成新的chunkmaxAsyncRequests: 5, //分割后,按需加载的代码块最多允许的并行请求数,在webpack5里默认值变为6maxInitialRequests: 3, //分割后,入口代码块最多允许的并行请求数,在webpack5里默认值变为4automaticNameDelimiter: "~", //代码块命名分割符name: true, //每个缓存组打包得到的代码块的名称cacheGroups: {vendors: {test: /[\\/]node_modules[\\/]/, //匹配node_modules中的模块priority: -10, //优先级,当模块同时命中多个缓存组的规则时,分配到优先级高的缓存组filename:'[id]_vendors.js'},default: {minChunks: 2, //覆盖外层的全局属性priority: -20,reuseExistingChunk: true, //是否复用已经从原代码块中分割出来的模块},},},},};
chunkIds
| 选项值 | 描述 |
|---|---|
| ‘natural’ | 按使用顺序的数字 id。 |
| ‘named’ | 对调试更友好的可读的 id。 |
| ‘deterministic’ | 在不同的编译中不变的短数字 id。有益于长期缓存。在生产模式中会默认开启。 |
| ‘size’ | 专注于让初始下载包大小更小的数字 id。 |
| ‘total-size’ | 专注于让总下载包大小更小的数字 id。 |
chunkIds: 'deterministic',
提取所有的资源到一个文件中
创建一个 commons chunk,其中包括入口(entry points)之间所有共享的代码。
module.exports = {//...optimization: {splitChunks: {cacheGroups: {commons: {name: 'commons', // 值得是这个namechunks: 'initial',minChunks: 2,},},},},};W
此配置可以扩大你的初始 bundles,建议在不需要立即使用模块时使用动态导入
基于入口提取
const path = require("path");const MiniCssExtractPlugin = require("mini-css-extract-plugin");module.exports = {entry: {foo: path.resolve(__dirname, "src/foo"),bar: path.resolve(__dirname, "src/bar"),},optimization: {splitChunks: {cacheGroups: {fooStyles: {type: "css/mini-extract",name: "styles_foo",chunks: (chunk) => {return chunk.name === "foo";},enforce: true,},barStyles: {type: "css/mini-extract",name: "styles_bar",chunks: (chunk) => {return chunk.name === "bar";},enforce: true,},},},},plugins: [new MiniCssExtractPlugin({filename: "[name].css",}),],module: {rules: [{test: /\.css$/,use: [MiniCssExtractPlugin.loader, "css-loader"],},],},};
懒加载chunk
import 动态导入语法(目前浏览器没有原生支持,需要babel)(???我在使用中并没有发现报错,也没用到syntax-dynamic-import)
依赖
yarn add @babel/plugin-syntax-dynamic-import --save-dev
babel.config.js
{"presets": [["@babel/preset-env",{"useBuiltIns": "entry","corejs": {"version": 3,"proposals": false}}]],"plugins":['@babel/plugin-syntax-dynamic']}
import(/* webpackChunkName:'test' */"./test").then().catch()
chunkFilename
此选项决定了非初始(non-initial)chunk 文件的名称,就是懒加载的文件
管理懒加载进入的文件名字,如果没有添加webpack魔法名,此时的name和id一样,如果添加了webpackChunkName,那么name就是webpackChunkName
output:{chunkFilename:'chunk/chunk_[name].js'}
runtimeruntime
注意
如果不提供runtimeChunk模块,那么公共chunk改变还是会影响到chunks,会导致缓存失效
optimization:{// 将当前模块的记录其他模块的hash单独打包一个文件的runtimeruntimeChunk:{name:entryPoint=>`runtime-${entryPoint.name}`}}
runtime运行时文件就是,import懒加载的文件会有一些引入之类的路径打入到bundle文件内,基于contentHas的缓存,当懒加载的文件变化的时候,has会变化,导致bundle文件的has也发生了改变
所以开启runtimeChunnk就能够提取runtime文件,保证bundle文件不改变
两个属性值
- true 或 ‘multiple’
- single
分别是如下两个配置的别名
// multiple// 给每个文件打包出runtime文件module.exports = {//...optimization: {runtimeChunk: {name: (entrypoint) => `runtime~${entrypoint.name}`,},},};// single// 引入相同的文件会共享一个runtimemodule.exports = {//...optimization: {runtimeChunk: {name: 'runtime',},},};

若有收获,就点个赞吧
0 人点赞
