Redis集群
Redis支持三种集群方案
- 主从复制模式
- Sentinel(哨兵)模式
- Cluster 模式
主从复制模式
通过持久化功能,Redis保证了即使在服务器重启的情况下也不会丢失(或少量丢失)数据,因为持久化会把内存中数据保存到硬盘上,重启会从硬盘上加载数据。 但是由于数据是存储在一台服务器上的,如果这台服务器出现硬盘故障等问题,也会导致数据丢失。
为了避免单点故障,通常的做法是将数据库复制多个副本以部署在不同的服务器上,这样即使有一台服务器出现故障,其他服务器依然可以继续提供服务。
为此, Redis 提供了复制(replication)功能,可以实现当一台数据库中的数据更新后,自动将更新的数据同步到其他数据库上
在复制的概念中,数据库分为两类,一类是主数据库(master),另一类是从数据库(slave)。主数据库可以进行读写操作,当写操作导致数据变化时会自动将数据同步给从数据库。而从数据库一般是只读的,只接受主数据库同步过来的数据。一个主数据库可以拥有多个从数据库,而一个从数据库只能拥有一个主数据库
主从复制原理
- 从数据库启动成功后,连接主数据库,发送
SYNC命令 - 主数据库接收到
SYNC命令后,开始执行BGSAVE命令生成rdb文件并使用缓冲区记录此后执行的所有写命令 - 主数据库
BGSAVE执行完后,向所有从数据库发送快照文件,并在发送期间继续记录被执行的写命令 - 从数据库收到快照文件后丢弃所有旧数据,载入收到的快照
- 主数据库快照发送完毕后开始向从数据库发送缓冲区中的写命令
- 从数据库完成对快照的载入,开始接收命令请求,并执行来自主数据库缓冲区的写命令;(从数据库初始化完成)
- 主数据库每执行一个写命令就会向从数据库发送相同的写命令,从数据库接收并执行收到的写命令(从数据库初始化完成后的操作)
- 出现断开重连后,2.8之后的版本会将断线期间的命令传给重数据库,增量复制
- 主从刚刚连接的时候,进行全量同步;全同步结束后,进行增量同步。当然,如果有需要 slave 在任何时候都可以发起全量同步。Redis 的策略是:无论如何,首先会尝试进行增量同步,如不成功,要求从机进行全量同步
主从复制优缺点
优点
- 支持主从复制,主机会自动将数据同步到从机,可以进行读写分离
- 为了分载
master的读操作压力,slave服务器可以为客户端提供只读操作的服务,写服务仍然必须由master来完成 slave同样可以接受其它slaves的连接和同步请求,这样可以有效的分载master的同步压力master/server是以非阻塞的方式为slaves提供服务。所以在master-slave同步期间,客户端仍然可以提交查询或修改请求slave server同样是以非阻塞的方式完成数据同步。在同步期间,如果有客户端提交查询请求,Redis则返回同步之前的数据
缺点
- Redis不具备自动容错和恢复功能,主机从机的宕机都会导致前端部分读写请求失败,需要等待机器重启或者手动切换前端的IP才能恢复(人工介入)
- 主机宕机,宕机前有部分数据未能及时同步到从机,切换IP后还会引入数据不一致的问题,降低了系统的可用性
- 如果多个
slave断线了,需要重启的时候,尽量不要在同一时间段进行重启。因为只要slave启动,就会发送sync请求和主机全量同步,当多个slave重启的时候,可能会导致masterIO剧增从而宕机 - Redis 较难支持在线扩容,在集群容量达到上限时在线扩容会变得很复杂
集群(主从复制)搭建
- Redis集群至少需要3个节点,因为投票容错机制要求超过半数节点认为某个节点挂了该节点才是挂了,所以低于3个节点无法构成集群
- 要保证集群的高可用,需要每个节点都有从节点,也就是备份节点。所以Redis集群至少需要6台服务器。因为我没有那么多服务器,也启动不了那么多虚拟机,所在这里搭建的是伪分布式集群(单机多实例)
- 默认情况下不指定主机的话,每台Redis都是主节点
1):单虚机运行3个redis实例(一主二从),修改端口号为(79-81)。复制2份redis.conf模拟2个从机实例
[root@wangpengliang bin]# lsconf dump.rdb redis-benchmark redis-check-aof redis-check-rdb redis-cli redis-sentinel redis-server[root@wangpengliang bin]# cd conf[root@wangpengliang conf]# lsredis.conf[root@wangpengliang conf]# cp redis.conf redis80.conf[root@wangpengliang conf]# cp redis.conf redis81.conf
| 类型 | 端口 | 配置文件 |
|---|---|---|
| master | 6379 | redis.conf |
| slave1 | 6380 | redis80.conf |
| slave2 | 6381 | redis81.conf |
2):修改配置
logfiledbfilenameportpidfile
redis.conf
logfile "6379.log"dbfilename dump6379.rdb
redis80.conf
logfile "6380.log"dbfilename dump6380.rdbport 6380pidfile /var/run/redis_6380.pid
redis81.conf
logfile "6381.log"dbfilename dump6381.rdbport 6381pidfile /var/run/redis_6381.pid
3):查看Redis进程信息
[root@wangpengliang conf]# ps -ef|grep redisroot 2679 1 0 02:53 ? 00:00:00 ./redis-server 0.0.0.0:6379root 2685 1 0 02:54 ? 00:00:00 ./redis-server 0.0.0.0:6380root 2691 1 0 02:54 ? 00:00:00 ./redis-server 0.0.0.0:6381root 2697 2643 0 02:54 pts/3 00:00:00 grep --color=auto redis
4):设置主从
SLAVEOF {host} {port}
80
[root@wangpengliang bin]# ./redis-cli -p 6380127.0.0.1:6380> SLAVEOF 0.0.0.0 6379OK127.0.0.1:6380> info replication# Replicationrole:slavemaster_host:0.0.0.0master_port:6379master_link_status:upmaster_last_io_seconds_ago:0master_sync_in_progress:0slave_repl_offset:28slave_priority:100slave_read_only:1connected_slaves:0master_failover_state:no-failovermaster_replid:fb828085ccb5c0b804cfa2e8112656aef5f561c8master_replid2:0000000000000000000000000000000000000000master_repl_offset:28second_repl_offset:-1repl_backlog_active:1repl_backlog_size:1048576repl_backlog_first_byte_offset:1repl_backlog_histlen:28
81
[root@wangpengliang bin]# ./redis-cli -p 6381127.0.0.1:6381> clear127.0.0.1:6381> SLAVEOF 0.0.0.0 6379OK127.0.0.1:6381> info replication# Replicationrole:slavemaster_host:0.0.0.0master_port:6379master_link_status:upmaster_last_io_seconds_ago:1master_sync_in_progress:0slave_repl_offset:210slave_priority:100slave_read_only:1connected_slaves:0master_failover_state:no-failovermaster_replid:fb828085ccb5c0b804cfa2e8112656aef5f561c8master_replid2:0000000000000000000000000000000000000000master_repl_offset:210second_repl_offset:-1repl_backlog_active:1repl_backlog_size:1048576repl_backlog_first_byte_offset:183repl_backlog_histlen:28
79(master)
127.0.0.1:6379> info replication# Replicationrole:masterconnected_slaves:2slave0:ip=127.0.0.1,port=6380,state=online,offset=210,lag=0slave1:ip=127.0.0.1,port=6381,state=online,offset=210,lag=0master_failover_state:no-failovermaster_replid:fb828085ccb5c0b804cfa2e8112656aef5f561c8master_replid2:0000000000000000000000000000000000000000master_repl_offset:210second_repl_offset:-1repl_backlog_active:1repl_backlog_size:1048576repl_backlog_first_byte_offset:1repl_backlog_histlen:210
注意:使用命令的方式集群是暂时的;如果需要永久生效需要修改配置文件
5):修改配置文件设置主从
replicaof <masterip> <masterport>
redis80.conf
replicaof 0.0.0.0 6379
redis81.conf
replicaof 0.0.0.0 6379
如果主机有密码可以通过
masterauth <master-password>设置
注意事项
- 主机可写,从机只能读取不能写
- 主机中数据会自动备份到从机
6):主机宕机测试
127.0.0.1:6379> SHUTDOWNnot connected> exit
[root@wangpengliang bin]# ps -ef|grep redisroot 2723 1 0 03:12 ? 00:00:00 ./redis-server 0.0.0.0:6380root 2728 2605 0 03:12 pts/1 00:00:00 ./redis-cli -p 6380root 2730 1 0 03:12 ? 00:00:00 ./redis-server 0.0.0.0:6381root 2735 2624 0 03:12 pts/2 00:00:00 ./redis-cli -p 6381root 2738 2643 0 03:16 pts/3 00:00:00 grep --color=auto redis
80
此时并没有配置哨兵,所以在主机79宕机后,80依旧是从机
127.0.0.1:6380> info replication# Replicationrole:slavemaster_host:0.0.0.0master_port:6379master_link_status:downmaster_last_io_seconds_ago:-1master_sync_in_progress:0slave_repl_offset:1130master_link_down_since_seconds:17slave_priority:100slave_read_only:1connected_slaves:0master_failover_state:no-failovermaster_replid:fb828085ccb5c0b804cfa2e8112656aef5f561c8master_replid2:0000000000000000000000000000000000000000master_repl_offset:1130second_repl_offset:-1repl_backlog_active:1repl_backlog_size:1048576repl_backlog_first_byte_offset:771repl_backlog_histlen:360
主机断线重连后,从机还是可以读取到主机的值 从机断线重连后,从机还是可以读取到主机的值
7):层层链路
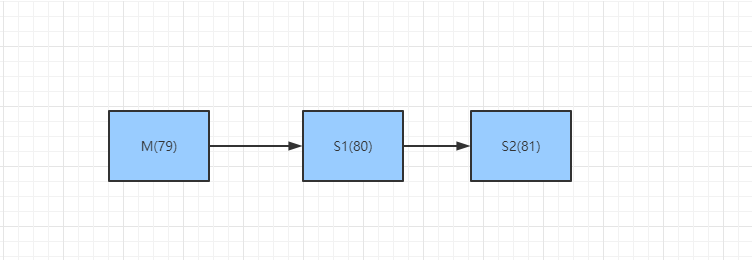
这种模式也可以做到主从复制
8):手动切换主节点
使用Slaveof no one命令可以使自己变成主机
Sentinel(哨兵)模式
主从切换的方法是:当主服务器宕机后,需要手动把一台从服务器切换为主服务器,这就需要人工干预,费事费力,还会造成一段时间内服务不可用。这不是一种推荐的方式。
概述
哨兵模式是一种特殊的模式,首先Redis提供了哨兵的命令,哨兵是一个独立的进程,作为进程,它会独立运行。其原理是 哨兵通过发送命令,等待Redis服务器响应,从而监控运行的多个Redis实例
哨兵的作用
- 通过发送命令,让Redis服务器返回监控其运行状态,包括主服务器和从服务器
- 当哨兵监测到
master宕机,会自动将slave切换成master,然后通过 发布订阅模式 通知其他的从机修改配置文件,让它们切换主机 master-slave切换后,master_redis.conf、slave_redis.conf和sentinel.conf的内容都会发生改变,即master_redis.conf中会多一行slaveof的配置,sentinel.conf的监控目标会随之调换- 一个哨兵进程对
Redis服务器进行监控,可能会出现问题,为此可以使用多个哨兵进行监控。各个哨兵之间还会进行监控,这样就形成了多哨兵模式
故障切换(failover)过程
假设主服务器宕机,哨兵1先检测到这个结果,系统并不会马上进行 failover 过程,仅仅是哨兵1主观的认为主服务器不可用,这个现象称为主观下线。
当后面的哨兵也检测到主服务器不可用,并且数量达到一定值时,那么哨兵之间就会进行一次投票,投票的结果由一个哨兵发起,进行failover操作。切换成功后,就会通过发布订阅模式,让各个哨兵把自己监控的从服务器实现切换主机,这个过程称为客观下线。
哨兵工作方式
- 每个
sentinel以每秒钟一次的频率向它所知的master,slave以及其他sentinel实例发送一个PING命令 - 如果一个实例(instance)距离最后一次有效回复
PING命令的时间超过down-after-milliseconds选项所指定的值, 则这个实例会被sentinel标记为主观下线 - 如果一个
master被标记为主观下线,则正在监视这个master的所有sentinels要以每秒一次的频率确认master的确进入了主观下线状态 - 当有足够数量的
sentinel(大于等于配置文件指定的值)在指定的时间范围内确认master的确进入了主观下线状态,则master会被标记为客观下线 - 在一般情况下, 每个
sentinel会以每 10 秒一次的频率向它已知的所有master,slave发送INFO命令 - 当
master被sentinel标记为客观下线时,sentinel向下线的master的所有slave发送INFO命令的频率会从 10 秒一次改为每秒一次 - 若没有足够数量的
sentinel同意master已经下线,master的客观下线状态就会被移除;若master重新向sentinel的PING命令返回有效回复,master的主观下线状态就会被移除
哨兵模式优缺点
优点
- 哨兵模式是基于主从模式的,所有主从的优点哨兵模式都具有
- 主从可以自动切换。系统更健壮、可用性更高(可以看作自动版的主从复制)
缺点
- Redis 较难支持在线扩容,在集群容量达到上限时在线扩容会变得很复杂
集群(哨兵模式)搭建
1):Redis安装目录下有一个sentinel.conf文件,copy一份进行修改
2):配置哨兵
# 配置监听的主服务器,这里sentinel monitor代表监控,mymaster代表服务器的名称,可以自定义# 192.168.11.128代表监控的主服务器,6379代表端口,2代表只有两个或两个以上的哨兵认为主服务器不可用的时候,才会进行failover操作。权值为2,这里的权值,是用来计算我们需要将哪一台服务器升级升主服务器sentinel monitor mymaster 0.0.0.0 6379 2
3):启动哨兵
[root@wangpengliang bin]# ./redis-sentinel conf/sentinel.conf2821:X 19 Apr 2021 04:13:16.075 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo2821:X 19 Apr 2021 04:13:16.075 # Redis version=6.2.1, bits=64, commit=00000000, modified=0, pid=2821, just started2821:X 19 Apr 2021 04:13:16.075 # Configuration loaded2821:X 19 Apr 2021 04:13:16.076 * Increased maximum number of open files to 10032 (it was originally set to 1024).2821:X 19 Apr 2021 04:13:16.076 * monotonic clock: POSIX clock_gettime_.__.-``__ ''-.__.-`` `. `_. ''-._ Redis 6.2.1 (00000000/0) 64 bit.-`` .-```. ```\/ _.,_ ''-._( ' , .-` | `, ) Running in sentinel mode|`-._`-...-` __...-.``-._|'` _.-'| Port: 26379| `-._ `._ / _.-' | PID: 2821`-._ `-._ `-./ _.-' _.-'|`-._`-._ `-.__.-' _.-'_.-'|| `-._`-._ _.-'_.-' | http://redis.io`-._ `-._`-.__.-'_.-' _.-'|`-._`-._ `-.__.-' _.-'_.-'|| `-._`-._ _.-'_.-' |`-._ `-._`-.__.-'_.-' _.-'`-._ `-.__.-' _.-'`-._ _.-'`-.__.-'2821:X 19 Apr 2021 04:13:16.076 # WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.2821:X 19 Apr 2021 04:13:16.077 # Sentinel ID is fdcb482b76a22f67429b1473ddc33d0d3769f7f32821:X 19 Apr 2021 04:13:16.077 # +monitor master mymaster 0.0.0.0 6379 quorum 12821:X 19 Apr 2021 04:13:16.078 * +slave slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 0.0.0.0 63792821:X 19 Apr 2021 04:13:16.080 * +slave slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 0.0.0.0 6379
Sentinel 启动之后,就会监视到现在有一个主服务器,两个从服务器;当把其中一个从服务器器关闭之后,可以看到日志
2821:X 19 Apr 2021 04:14:03.125 # +sdown master mymaster 0.0.0.0 63792821:X 19 Apr 2021 04:14:03.125 # +odown master mymaster 0.0.0.0 6379 #quorum 1/12821:X 19 Apr 2021 04:14:03.125 # +new-epoch 12821:X 19 Apr 2021 04:14:03.125 # +try-failover master mymaster 0.0.0.0 63792821:X 19 Apr 2021 04:14:03.132 # +vote-for-leader fdcb482b76a22f67429b1473ddc33d0d3769f7f3 12821:X 19 Apr 2021 04:14:03.132 # +elected-leader master mymaster 0.0.0.0 63792821:X 19 Apr 2021 04:14:03.132 # +failover-state-select-slave master mymaster 0.0.0.0 63792821:X 19 Apr 2021 04:14:03.199 # +selected-slave slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 0.0.0.0 63792821:X 19 Apr 2021 04:14:03.199 * +failover-state-send-slaveof-noone slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 0.0.0.0 63792821:X 19 Apr 2021 04:14:03.282 * +failover-state-wait-promotion slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster0.0.0.0 63792821:X 19 Apr 2021 04:14:03.288 # +promoted-slave slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 0.0.0.0 63792821:X 19 Apr 2021 04:14:03.288 # +failover-state-reconf-slaves master mymaster 0.0.0.0 63792821:X 19 Apr 2021 04:14:03.340 * +slave-reconf-sent slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 0.0.0.0 63792821:X 19 Apr 2021 04:14:04.312 * +slave-reconf-inprog slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 0.0.0.0 63792821:X 19 Apr 2021 04:14:04.312 * +slave-reconf-done slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 0.0.0.0 63792821:X 19 Apr 2021 04:14:04.378 # +failover-end master mymaster 0.0.0.0 63792821:X 19 Apr 2021 04:14:04.378 # +switch-master mymaster 0.0.0.0 6379 127.0.0.1 63802821:X 19 Apr 2021 04:14:04.379 * +slave slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 63802821:X 19 Apr 2021 04:14:04.379 * +slave slave 0.0.0.0:6379 0.0.0.0 6379 @ mymaster 127.0.0.1 63802821:X 19 Apr 2021 04:14:34.411 # +sdown slave 0.0.0.0:6379 0.0.0.0 6379 @ mymaster 127.0.0.1 6380
此时Master从79转移到了80
127.0.0.1:6380> info replication# Replicationrole:masterconnected_slaves:1slave0:ip=127.0.0.1,port=6381,state=online,offset=4615,lag=1master_failover_state:no-failovermaster_replid:872d3e4c9538abb9f117dcc47de99ac57791433amaster_replid2:612af05d7a22d2b35e595f43be74ddd771765798master_repl_offset:4615second_repl_offset:1212repl_backlog_active:1repl_backlog_size:1048576repl_backlog_first_byte_offset:1repl_backlog_histlen:4615
79重新连接
[root@wangpengliang bin]# ./redis-server conf/redis.conf[root@wangpengliang bin]# ./redis-cli -p 6379127.0.0.1:6379> pingPONG127.0.0.1:6379> info replication# Replicationrole:slavemaster_host:127.0.0.1master_port:6380master_link_status:upmaster_last_io_seconds_ago:1master_sync_in_progress:0slave_repl_offset:35074slave_priority:100slave_read_only:1connected_slaves:0master_failover_state:no-failovermaster_replid:872d3e4c9538abb9f117dcc47de99ac57791433amaster_replid2:0000000000000000000000000000000000000000master_repl_offset:35074second_repl_offset:-1repl_backlog_active:1repl_backlog_size:1048576repl_backlog_first_byte_offset:32735repl_backlog_histlen:2340
79重新连接后只能是从机了,master已经被80抢占
Cluster 集群模式
Redis Cluster是一种服务器 Sharding 技术,3.0版本开始正式提供。 Redis 的哨兵模式基本已经可以实现高可用,读写分离 ,但是在这种模式下每台 Redis 服务器都存储相同的数据,很浪费内存,所以在 Redis3.0上加入了 Cluster 集群模式,实现了 Redis 的分布式存储。 也就是说每台 Redis 节点上存储不同的内容
Cluster特点
- 多主多从,去中心化:从节点作为备用,复制主节点,不做读写操作,不提供服务
- 不支持处理多个key:因为数据分散在多个节点,在数据量大高并发的情况下会影响性能
- 支持动态扩容节点:Rerdis Cluster最大的优点之一
- 节点之间相互通信,相互选举,不再依赖Sentinel:准确来说是主节点之间相互“监督”,保证及时故障转移
Cluster集群模式对比
- 相比哨兵模式:多个master节点保证主要业务(比如master节点主要负责写)稳定性,不需要搭建多个sentinel实例监控一个master节点
- 相比一主多从模式:不需要手动切换,具有自我故障检测,故障转移的特点
- 相比其哨兵和主从:对数据进行分片(sharding),不同节点存储数据不一样支持动态扩容
从某种程度上来说,Sentinel模式主要针对高可用(HA),而Cluster模式是不仅针对大数据量,高并发,同时也支持HA
数据存储设计
- 通过算法设计,计算出key应该保存的位置
- 将所有的存储空间计划切割成
16384份,每台主机保存一部分每份代表的是一个存储空间,不是一个key的保存空间 - 将
key按照计算出的结果放到对应的存储空间
1):key通过hash算法计算出一个值,然后拿这个值%16384
2):得到一个数(假如是37)为key的保存位置,然后再存入相应的存储空间位置
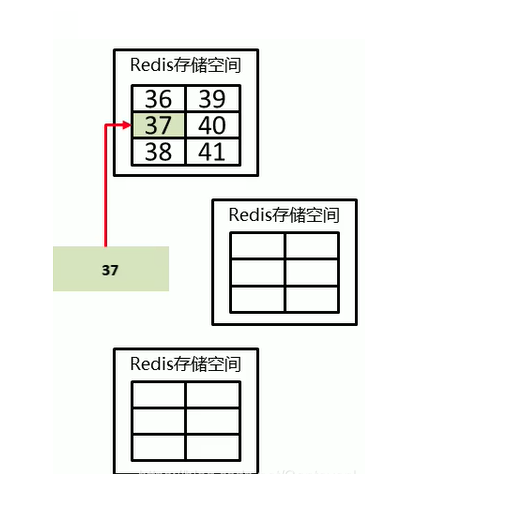
3):假如又增加了一个节点,之前每个节点都会拿出部分槽给新的节点
4):如果是去除节点,则把被去除节点的槽加入到存在的节点当中
哈希槽Slot
Redis集群使用一种称作一致性哈希的复合分区形式(组合了哈希分区和列表分袂的特征来计算键的归属实例),键的CRC16哈希值被称为哈希槽。比如对于三个Redis节点,哈希槽的分配方式如下:
- 第一节点拥有
0-5500哈希槽 - 第二节点拥有
5501-11000哈希槽 - 第三节点拥有剩余的
11001-16384哈希槽
一个键的对应的哈希槽通过计算键的CRC16 哈希值,然后对16384进行取模得到:HASH_SLOT=CRC16(key) modulo 16383,Redis提供了CLUSTER KEYSLOT命令来执行哈希槽的计算:
注意:集群节点保存键值对以及键值对过期时间的处理方式与Redis单机模式是一样的,唯一不同就是节点只能使用0号数据库,而单机Redis服务器则没有限制
集群内部通讯机制
各个数据库互相通信,保存各个库中槽的编号数据
1):客户端发出一个key访问A,通过算法计算出key的存储位置
2):如果一次命中,直接返回
3):一次未命中,告知具体位置
4):一次命中或者两次命中提高数据访问效率
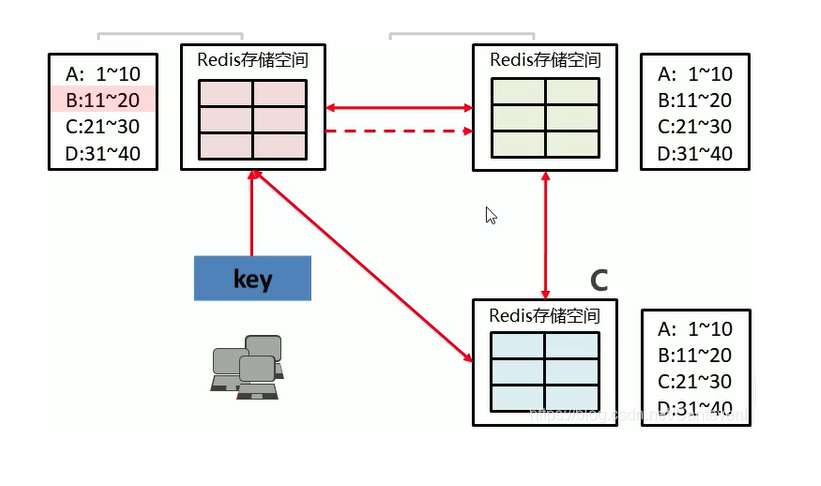
集群(Cluster)搭建
1):单虚机运行6个redis实例(三主三从),端口号为(79-84)
[root@wangpengliang local]# cd /usr/local/redis/bin[root@wangpengliang bin]# lsconf redis-benchmark redis-check-aof redis-check-rdb redis-cli redis-sentinel redis-server[root@wangpengliang bin]# cd conf[root@wangpengliang conf]# lsredis80.conf redis81.conf redis.conf sentinel.conf[root@wangpengliang conf]# cp redis.conf redis82.conf[root@wangpengliang conf]# cp redis.conf redis83.conf[root@wangpengliang conf]# cp redis.conf redis84.conf[root@wangpengliang conf]#
| 端口 | 配置文件 |
|---|---|
| 6379 | redis.conf |
| 6380 | redis80.conf |
| 6381 | redis81.conf |
| 6382 | redis82.conf |
| 6383 | redis83.conf |
| 6384 | redis84.conf |
2):修改配置
daemonize yes # 后台启动protected-mode no ; # 允许外部访问port 6379 # 修改端口号,从79~84cluster-enabled yes # 开启cluster,去掉注释cluster-config-file nodes-6379.conf # 自动生成cluster-node-timeout 15000 # 节点通信时间logfile /usr/local/redis/bin/6379.logdbfilename 6379dump.rdb # 做伪集群的时候,一定要修改rdb文件的名字,如果aof也开的话也需要修改,否则扩容的时候会出现提示说新增扩容节点存在数据,需要先删除数据的提示。
3):启动Redis
[root@wangpengliang bin]# ./redis-server conf/redis.conf[root@wangpengliang bin]# ./redis-server conf/redis80.conf[root@wangpengliang bin]# ./redis-server conf/redis81.conf[root@wangpengliang bin]# ./redis-server conf/redis82.conf[root@wangpengliang bin]# ./redis-server conf/redis83.conf[root@wangpengliang bin]# ./redis-server conf/redis84.conf
3):查看Redis进程信息
[root@wangpengliang bin]# ps -ef|grep redisroot 3538 1 0 13:37 ? 00:00:01 ./redis-server 0.0.0.0:6382 [cluster]root 3545 1 0 13:38 ? 00:00:01 ./redis-server 0.0.0.0:6383 [cluster]root 3551 1 0 13:38 ? 00:00:01 ./redis-server 0.0.0.0:6384 [cluster]root 3797 1 0 13:48 ? 00:00:00 ./redis-server 0.0.0.0:6380 [cluster]root 3803 1 0 13:48 ? 00:00:00 ./redis-server 0.0.0.0:6381 [cluster]root 3816 1 0 13:49 ? 00:00:00 ./redis-server 0.0.0.0:6379 [cluster]root 3826 3494 0 13:49 pts/0 00:00:00 grep --color=auto redis
4):创建集群
--cluster create 192.168.80.251:6379 192.168.80.251:6380 192.168.80.251:6381 192.168.80.251:6382 192.168.80.251:6383 192.168.80.251:6384 --cluster-replicas 1
[root@wangpengliang bin]# ./redis-cli --cluster create 192.168.15.251:6379 192.168.15.251:6380 192.168.15.251:6381 192.168.15.251:6382 192.168.15.251:6383 192.168.15.251:6384 --cluster-replicas 1>>> Performing hash slots allocation on 6 nodes...Master[0] -> Slots 0 - 5460Master[1] -> Slots 5461 - 10922Master[2] -> Slots 10923 - 16383Adding replica 192.168.15.251:6383 to 192.168.15.251:6379Adding replica 192.168.15.251:6384 to 192.168.15.251:6380Adding replica 192.168.15.251:6382 to 192.168.15.251:6381>>> Trying to optimize slaves allocation for anti-affinity[WARNING] Some slaves are in the same host as their masterM: 48f3cbacb014f1d0f89fe99bb494e1cabb1f80f4 192.168.15.251:6379slots:[0-5460] (5461 slots) masterM: ee511eed5a7d08d39ceef29823b98e299435523e 192.168.15.251:6380slots:[5461-10922] (5462 slots) masterM: e4c70b085d10d51a3201c6bf4bfa47adfa000f2e 192.168.15.251:6381slots:[10923-16383] (5461 slots) masterS: 5261a1ccb42ac160a93572beae7344e6b0c7c520 192.168.15.251:6382replicates 48f3cbacb014f1d0f89fe99bb494e1cabb1f80f4S: d420ca1e3ef8edd538286e1c7698783447312148 192.168.15.251:6383replicates ee511eed5a7d08d39ceef29823b98e299435523eS: 235fb6093a7f1c92e7144109aee10d1e341d2fb9 192.168.15.251:6384replicates e4c70b085d10d51a3201c6bf4bfa47adfa000f2eCan I set the above configuration? (type 'yes' to accept): yes>>> Nodes configuration updated>>> Assign a different config epoch to each node>>> Sending CLUSTER MEET messages to join the clusterWaiting for the cluster to join>>> Performing Cluster Check (using node 192.168.15.251:6379)M: 48f3cbacb014f1d0f89fe99bb494e1cabb1f80f4 192.168.15.251:6379slots:[0-5460] (5461 slots) master1 additional replica(s)M: e4c70b085d10d51a3201c6bf4bfa47adfa000f2e 192.168.15.251:6381slots:[10923-16383] (5461 slots) master1 additional replica(s)M: ee511eed5a7d08d39ceef29823b98e299435523e 192.168.15.251:6380slots:[5461-10922] (5462 slots) master1 additional replica(s)S: 5261a1ccb42ac160a93572beae7344e6b0c7c520 192.168.15.251:6382slots: (0 slots) slavereplicates 48f3cbacb014f1d0f89fe99bb494e1cabb1f80f4S: 235fb6093a7f1c92e7144109aee10d1e341d2fb9 192.168.15.251:6384slots: (0 slots) slavereplicates e4c70b085d10d51a3201c6bf4bfa47adfa000f2eS: d420ca1e3ef8edd538286e1c7698783447312148 192.168.15.251:6383slots: (0 slots) slavereplicates ee511eed5a7d08d39ceef29823b98e299435523e[OK] All nodes agree about slots configuration.>>> Check for open slots...>>> Check slots coverage...[OK] All 16384 slots covered.
Redis-Cluster相关的集群命令
- cluster info :打印集群的信息
- cluster nodes :列出集群当前已知的所有节点( node),以及这些节点的相关信息
- cluster meet :将 ip 和 port 所指定的节点添加到集群当中
- cluster forget
:从集群中移除 node_id 指定的节点 - cluster replicate
:将当前从节点设置为 node_id 指定的master节点的slave节点。只能针对slave节点操作 - cluster saveconfig :将节点的配置文件保存到硬盘里面
- cluster addslots [slot …] :将一个或多个槽( slot)指派( assign)给当前节点
- cluster delslots [slot …] :移除一个或多个槽对当前节点的指派
- cluster flushslots :移除指派给当前节点的所有槽,让当前节点变成一个没有指派任何槽的节点
- cluster setslot node
:将槽 slot 指派给 node_id 指定的节点,如果槽已经指派给 - cluster setslot migrating
:将本节点的槽 slot 迁移到 node_id 指定的节点中 - cluster setslot importing
:从 node_id 指定的节点中导入槽 slot 到本节点 - cluster setslot stable :取消对槽 slot 的导入( import)或者迁移( migrate)
- cluster keyslot :计算键 key 应该被放置在哪个槽上
- cluster countkeysinslot :返回槽 slot 目前包含的键值对数量
- cluster getkeysinslot :返回 count 个 slot 槽中的键
查看Redis数据库信息
info replication
127.0.0.1:6379> info replication# Replication# 角色role:master# 连接的从机数量connected_slaves:0master_failover_state:no-failovermaster_replid:28d568fba5f2ed0f9034a4f63acc4960287099afmaster_replid2:0000000000000000000000000000000000000000master_repl_offset:0second_repl_offset:-1repl_backlog_active:0repl_backlog_size:1048576repl_backlog_first_byte_offset:0repl_backlog_histlen:0

若有收获,就点个赞吧
0 人点赞
