参考链接:链接
(一)所用环境及Scrapy本身
环境:
- ubuntu 20.04.1
- pycharm for linux
终端中通过pip install Scrapy安装Scrapy及其依赖
在pycharm的terminal中通过scrapy startproject tutorial创建一个scrapy项目 // tutorial为项目名称
因此可得出scrapy项目框架为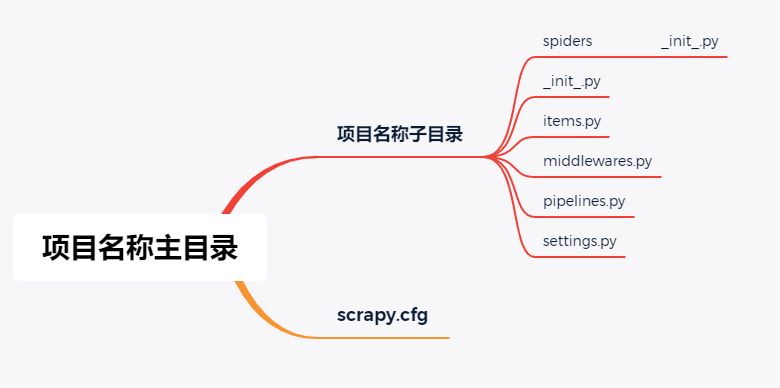
- scrapy.cfg # 部署配置文件
- items.py # 项目项定义文件
- pipelines.py # 项目管道文件
- settings.py # 项目设置文件
- spiders # 我们的爬虫/蜘蛛 目录
(二)一层爬取
爬取简单的一层
import scrapyclass QuotesSpider(scrapy.Spider): #class声明类,括号里表示继承的父类name = "blog"def start_requests(self):#def定义的类内的方法urls = ['http://witherc.top/',]for url in urls:yield scrapy.Request(url=url, callback=self.parse)def parse(self, response):page = response.url.split("/")[-2]filename = 'quotes-%s.html' % pagewith open(filename, 'wb') as f:f.write(response.body)self.log('Saved file %s' % filename)
name:爬虫的唯一标识名,同一项目中不可重复。
urls:爬取目标网站,可放多条同时爬取,单引号括起来逗号分隔。
filename:使用scrapy crawl (爬虫)name 后生成爬取文件的名称。
例如此处爬虫名为blog 命令则为scrapy crawl blog。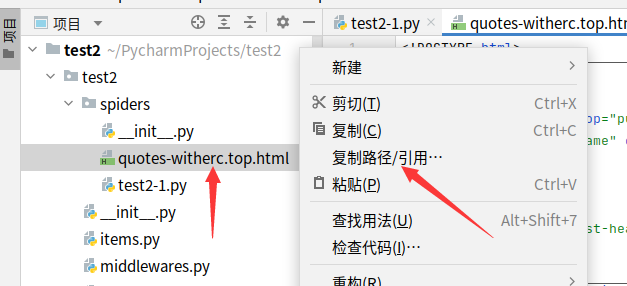
找到爬取后的文件,右键可找到绝对路径,再根据绝对路径可以找到该文件,打开即可看见爬取的内容,mac中可以command+空格 直接放入绝对路径的上一级路径即可找到爬取后的文件(爬取后存放位置可优化:爬取后文件固定存放位置)。

若有收获,就点个赞吧
0 人点赞
