1. 索引的数据结构
1. 为什么不用hash表
hash表示key-value存储,可能发生hash冲突,引出链表的概念。 hash存储是无序的,对于范围查询非常慢。
2. 为什么不用数组
数组的更新成本太高
3. 为什么不用二叉树
二叉树虽然支持范围查询,但是会出现极端失衡的问题。
4. 考虑到以上的问题,对于索引的数据结构,我们采用B+树
2. B+树
2.1 B树和B+树的区别?
- B树每个节点存储的是key和value两个值,而B+树非叶子节点存储的是key,叶子节点存储的是key和value;
- B+树叶子节点有指针
- B树可能在非叶子节点查到数据,而B+树一定在叶子节点查到数据
3. 不同存储引擎索引的实现
3.1 MySAM存储引擎
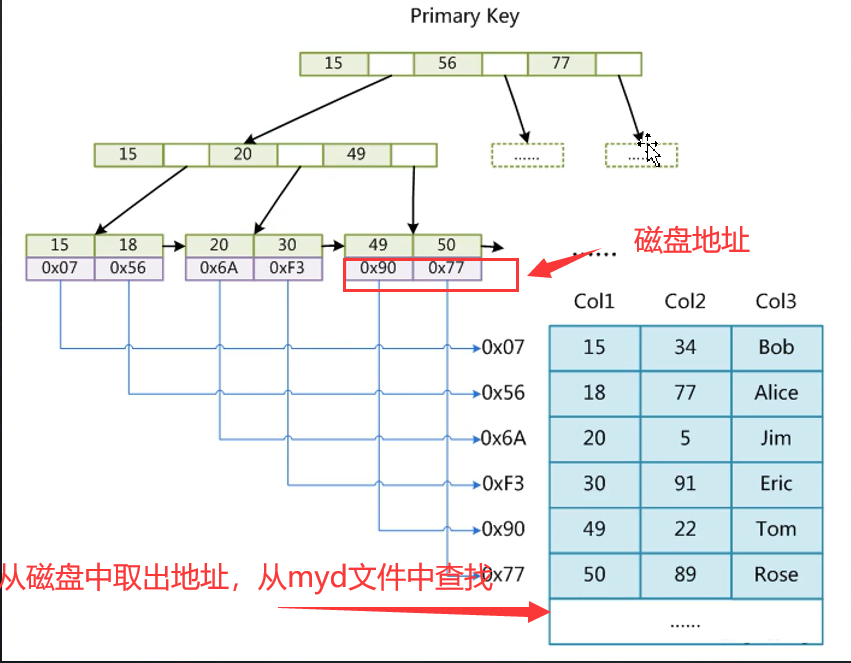
使用的是非聚集存储,就是索引文件和数据文件是分离的。叶子节点存储的是磁盘的地址。
3.2 innodb存储引擎

4. 主键索引和普通索引
4.1 主键索引的查找方式
5.2 普通索引的查找方式(回表)
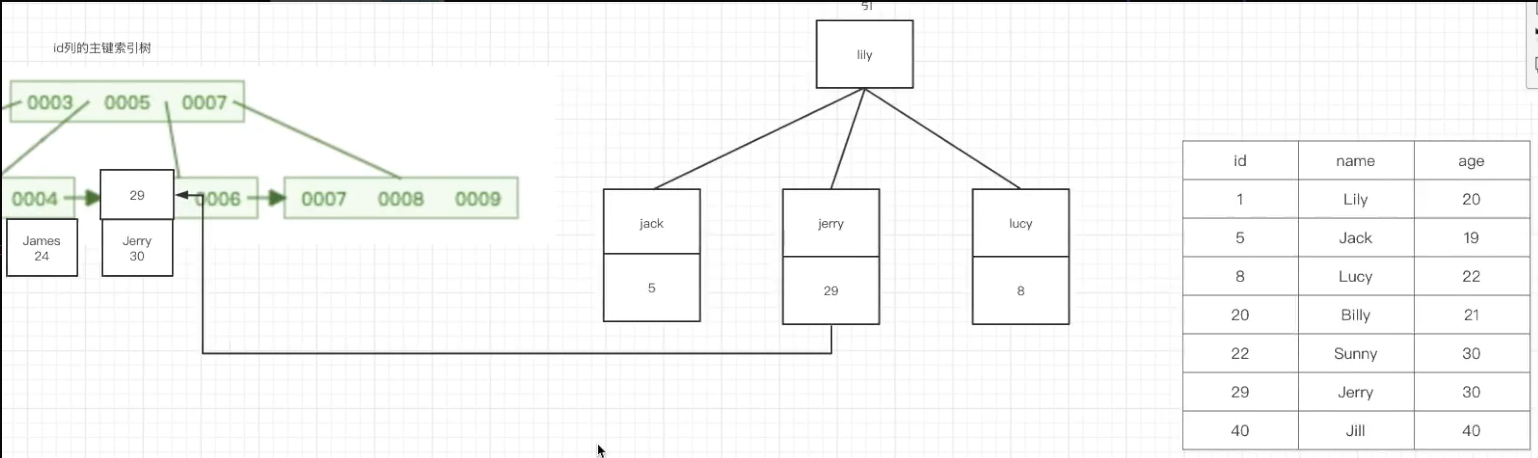
普通索引的叶子节点存储的是主键ID,当在普通索引树查找到对应的ID,在回到主键索引树进行查找其他的数据,这个过程叫做回表。

若有收获,就点个赞吧
0 人点赞
