1.MySQL为什么要采用B+树的数据结构?
- hash散列算法,不支持排序和范围查询
- 二叉树虽然支持范围查询,但是会出现极端失衡
- 红黑树不能从本质上解决失衡的问题
- B树的每个节点上都存有一份数据,这样每次从磁盘中取回的数据很多
B+树只在叶子节点存贮有数据,这样从磁盘上读取的数据就少得多了
2.请你说说B树和B+树的区别?
B树的叶子节点没有指针,B+树的叶子节点有指针
B树的非叶子节点的数据都冗余了一份到叶子结点,而B+数只有叶子节点有数据
3.InnoDB为什么推荐使用整形自增的id作为主键?
整形可以保证在比较的时候效率更高
-
4.为什么普通索引的叶子结点存储的是主键值?
为了节约空间
冗余的数据会造成空间的浪费
- 为了修改时简化操作
如果在每个索引树上都放上相同的数据,在修改了某个数据之后,所有的索引树的数据都要修改,而不是修改一份
5.简述InooDB和MySAM的区别?
- InnoDB支持事务,而MySAM不支持事务
- InnoDB支持外键,而MySAM不支持外键
- InnoDB支持行锁,而MySAM支持表锁
-
6.请你说说MySQL的事务回滚机制?
当客户端操作数据库的时候,先将数据存储到缓存中,当提交之后才会存储到数据库中,在这个过程中,如果出现了异常,这时候就会清除缓存,撤销提交的操作,这就是回滚机制
7.请你说说MySQL中left join、right join、inner join的区别?
left join
左连接,以左表为主,左表查询出来的数据显示全部,右表查询出来的数据,显示和左表有交集的部分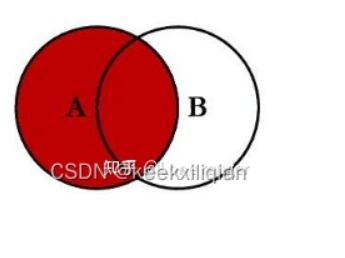
- right join
右连接,以右表为主,右表查询出来的数据显示全部,左表查询出来的数据,显示和右表有交集的部分
- inner join
8.如何理解三大范式?
- 数据表的每一列都不可在分割,保持原子性
- 非主键依赖于主键
- 非主键不能依赖于非主键

若有收获,就点个赞吧
0 人点赞
