1. 什么是MVCC
MVCC是多版本并发控制,主要是提高数据库的读写性能,让数据库在读写的时候不用加锁,这里的读指的是快照读。
2. MVCC的实现原理
MVCC的实现原理主要是三个隐藏字段、undo log、read view。
2.1 三个隐藏字段
DB_TRX_ID—-最近被修改的事务的id编号 DB_ROLL_PTR—-回滚指针 DB_ROW_ID—-当我们没有定义主键的时候会自动生成主键
2.2 undo log
2.3 read view
多个事务之间能否读到彼此的数据
几个重要参数: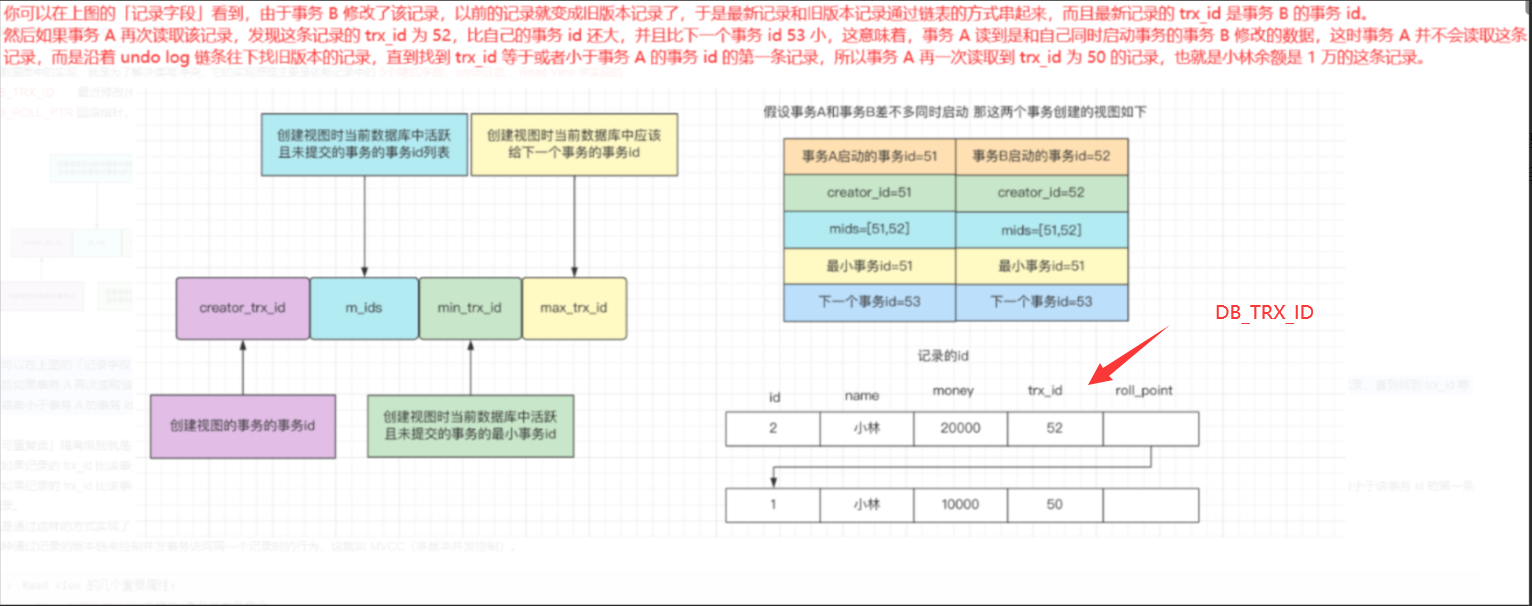
creator_trx_id—-创建视图的事务的事务id m_ids—-创建视图时活跃(未提交)的事务的列表 min_trx_id—-列表中活跃的且未提交的最小事务id max_trx_id—-创建视图是应该赋给下一个事务的事务id
比较规则:
DB_TRX_ID<min_trx_id—-当前活跃的事务是没有提交的,最近被修改的事务的id小于min_trx_id,说明该事务提交了,可以被访问到;
DB_TRX_ID>max_trx_id—-max_trx_id是在read view创建只有生成的,只能读取版本链中的数据,大于max_trx_id,已经超出了版本链的范围,不能被访问到;
DB_TRX_ID<creator_trx_id—-如果记录的 trx_id 比该事务的 Read View 中的 creator_trx_id 要小,且不在 m_ids 列表里,这意味着这条记录的事务早就在该事务前提交过了,所以该记录对该事务可见;
DB_TRX_ID>creator_trx_id—-如果记录的 trx_id 比该事务的 Read View 中的 creator_trx_id 要大,且在 m_ids 列表里,这意味着该事务读到的是和自己同时启动的另外一个事务修改的数据,这时就不应该读取这条记录,而是沿着 undo log 链条往下找旧版本的记录,直到找到 trx_id 等于或者小于该事务 id 的第一条记录
3. 隔离级别和MVCC
3.1 隔离级别
读未提交:事务a读取一条数据,事务b修改了该条数据但没有提交,这时事务a能读到未提及的数据,当事务b回滚之后,提交了,事务a又会读取到原来的数据,造成了脏读。
读已提交:事务a读取不到事务b修改但没提交的数据,能读到修改提交后的数据,造成两次读取结果不一致,造成了虚读。
可重复读:事务a读取不到事务b修改并提交后的数据,但是当事务a提交之后,又读取到了事务b修改后的数据。 串行化:当串行化的隔离级别的时候,一个事务修改操作的时候,其他事务没有提交,这时候会阻塞事务,不会别修改
3.2 MVCC和隔离级别
读已提交:每次读的时候,都会创建一个新的read view,这样每次提交的数据都能被读取到。 可重复读:启动事务之后,第一次查询的时候就会创建一个read view,以后的每次查询用的都是这个read view,这样,之后提交的数据就不会被查询到。
4. ACID和MVCC
4.1 ACID实现原理
1. 原子性的实现原理
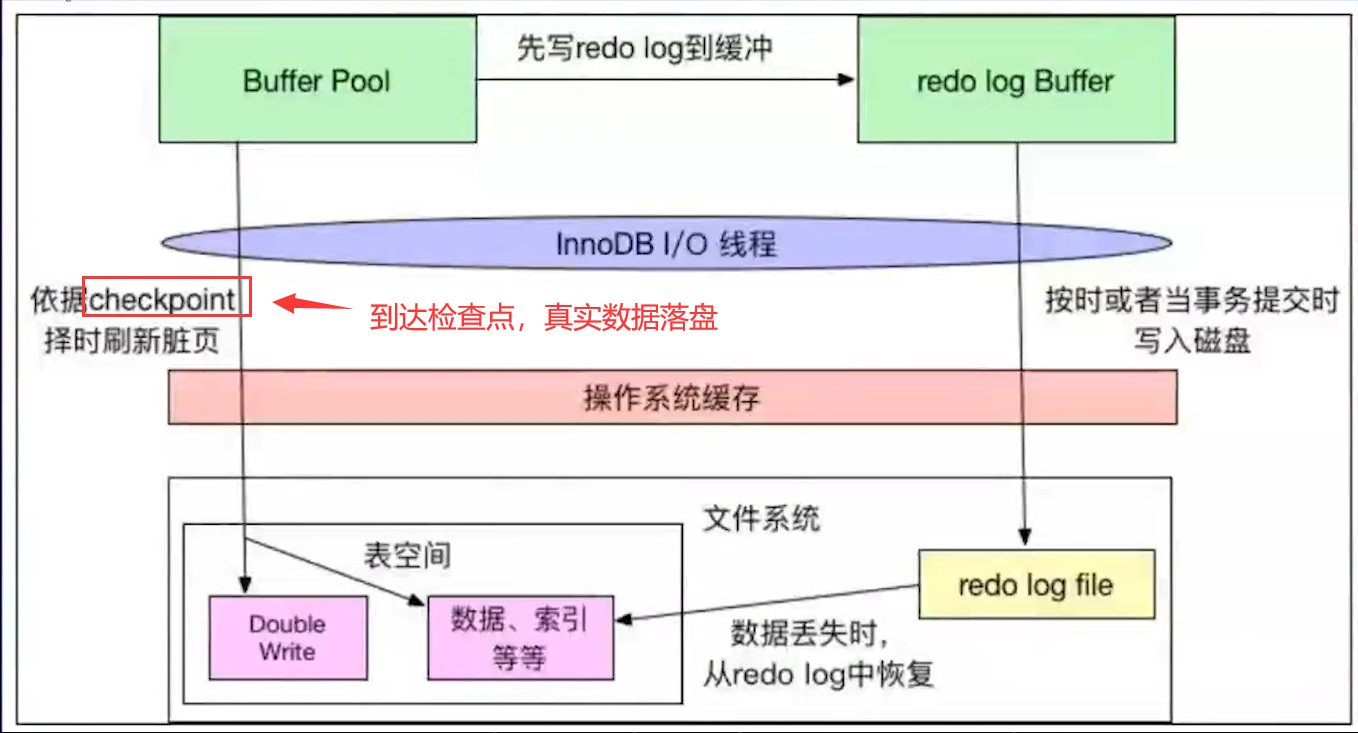
每一个写事务,都会修改Buffer pool,产生响应的redo/undo日志,日志信息被写入到日志文件中,然后进行WAL操作,当Buffer pool中的数据没有提交时,数据库挂了,可以通过redo log日志找回数据,当提交了数据,数据库挂了,可以通过undo log实现。
2. 隔离性的实现原理
MVCC和加锁
3. 持久性的实现原理
在系统进行重启或者其他的情况时,可以通过redo log修复数据 。
4. 一致性的实现原理
4.2 WAL操作
1.什么是WAL
WAL叫做预写日志
2.为什么要用WAL
数据库在存储数据的时候,是存储在磁盘中的,磁盘中的存储是随机的,存进去之后我们要获取一个地址,这时候就很慢。为了解决这个问题,数据库就用了日志存储,在把数据正式存进磁盘之前,先写入日志,日志存储时有顺序的,我们只需要获取第一个地址,后边记录偏移量就可以了,提高了性能。
4.3 redo log的写入机制

若有收获,就点个赞吧
0 人点赞
