总结
- 字符集:一个字符对应一个编号,字符集就是字符和对应编号的映射关系的集合
- unicode:unicode学术协会,为了全球化统一标准,研发的通用的字符集
- 字符编码:为了确定字符串中每个字符二进制编码的边界,而定义的字符编号的存储方式
- 定长编码:所有字符的字节长度都相同,优点是编解码快、简单。缺点是,随着收录字符的增加,编号跨度的增加,内存的浪费越加显著
- 变长编码:有固定的标识位确定字节长度和字符的组成,优点是,降低内存的浪费,缺点是,复杂,编解码慢
- go语言的字符串,是记录起始地址和字节长度,通过字节长度确定字符串边界
- go语言的字符串,是存储在只读内存中的,并且相同串共享内存,如果需要修改,先将字符串转换成slice,将会重新分配内存,拷贝字符型内容
- go语言的字符串,如果将字符串转换成slice,并且使用unsafe,可以将地址重新指向字符串地址
字符集
一个bit可以是0,或者是1,八个bit代表一个字节,全是0代表0,全是1代表255
一个字节256个数字,两个字节可以代表65536个数字
如果整数这么存储,那么字符该怎么存储呢?
每个字符对应一个数字编号

将每一个字符一一编号,这就是字符集(字符编号对照表),ascii收录了128个字符,
上述字符集中还有许多未收录的字符集,众多的字符集还会带来编码问题,所以unicode学术学会,就本着全球化统一标准的目的,制作了一个通用的字符集,这个字符集就是Unicode
编码
有了字符集并不代表万事大吉了,如以下内容:
eggo世界
使用unicode字符集的话将会得到下图的内容
这个时候问题就出现了,想要将二进制转换为对应的字符时,如何划分这一串二进制字符的字符边界呢?
所以这个时候就不可以照搬编号
- 定长编码
那么这个时候,可以不管编号多大,都按照最长的的来,位数不够高位补零,如下图
这个就是定长编码,但是这个解决方案,比较浪费内存,而且字符集收录的字符越多,编号的跨度越大,定长编码造成的浪费就越显著
- 变长编码
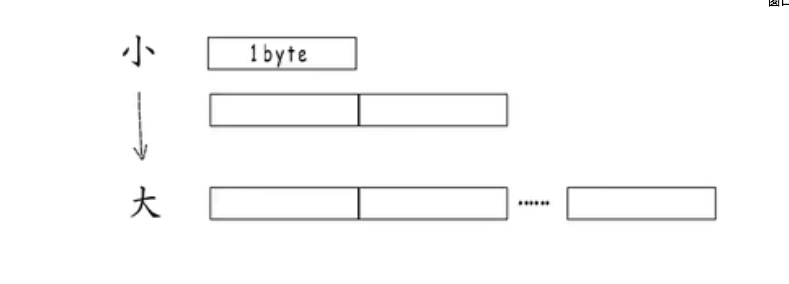
如何划分字符边界呢?
0-127 固定标识位0
128-2047 固定标识位110 10

若有收获,就点个赞吧
0 人点赞
