数组和集合的区别
数组
- 长度开始时必须指定,而且一旦指定,就不能更改
- 保存的数据必须为同一类型的元素
使用数组进行增加、删除元素的代码比较复杂。创建新数组—>拷—>然后增删
集合
可移动动态保存任意多个对象,使用比较方便
- 提供了一系列方便的操作对象的方法,add、remove、set、get等
- 使用集合添加、删除新元素的代码简介
集合框架体系
集合主要分为两组,分比为单列集合、双列结合单例集合
主要有List、Set两个重要接口,以及下面的实现类,
Set->Treeset,HashSet, LinkedHashSet
List->ArrayList,LinkedList,Vector
HashSet,TreeSet和LinkedHashSet是Set的类型。从输出中可以看到,Set仅保存每个相同项中的一个,并且不同的Set实现存储元素的方式也不同。HashSet使用相当复杂的方法存储元素。现在只需要知道,这种技术是检索元素的最快方法,因此,存储顺序看上去没有什么意义(通常只关心某事物是否是Set的成员,而存储顺序并不重要)。
如果存储顺序很重要,则可以使用TreeSet,它将按比较结果的升序保存对象)或LinkedHashSet,它按照被添加的先后顺序保存对象。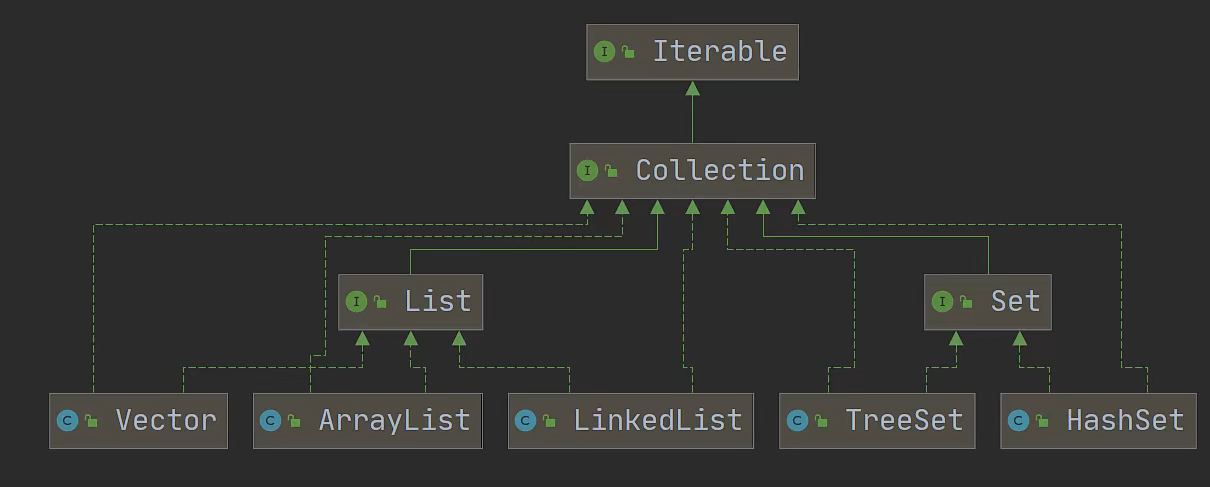
双列集合
键值对类型
重要Map接口,Map->HashMap,TreeMap,Hashtable, LinkedHashMap
键和值保存在HashMap中的顺序不是插入顺序,因为HashMap实现使用了非常快速的算法来控制顺序。
TreeMap通过比较结果的升序来保存键,LinkedHashMap在保持HashMap查找速度的同时按键的插入顺序保存键。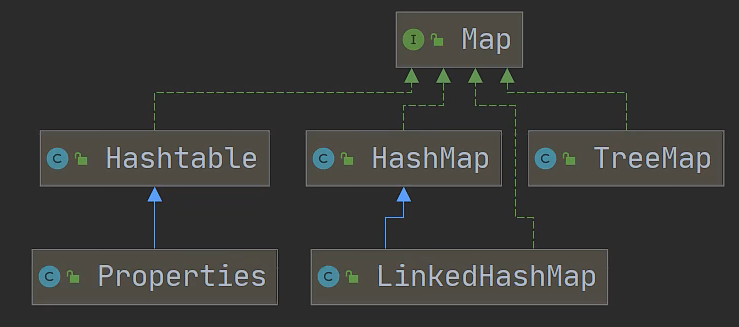
Collection接口和常用方法

Collection接口实现类的特点
- Collection实现子类可以存放多个元素,每个元素可以是Object
- 有些Collection的实现类,可以存放重复的元素,有些不可以
- 有些Collection的实现类,有些是有序的List,有些不是有序的Set
Collection接口没有直接的实现类,是通过它的子接口Set和List来实现的
常用方法
遍历元素方式
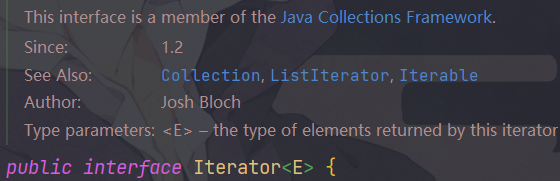
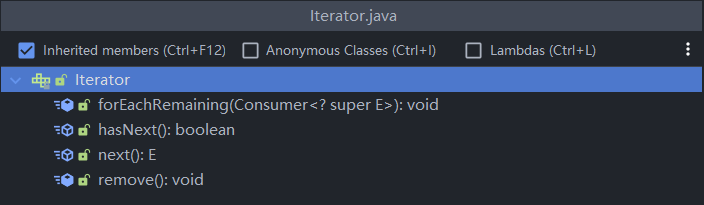
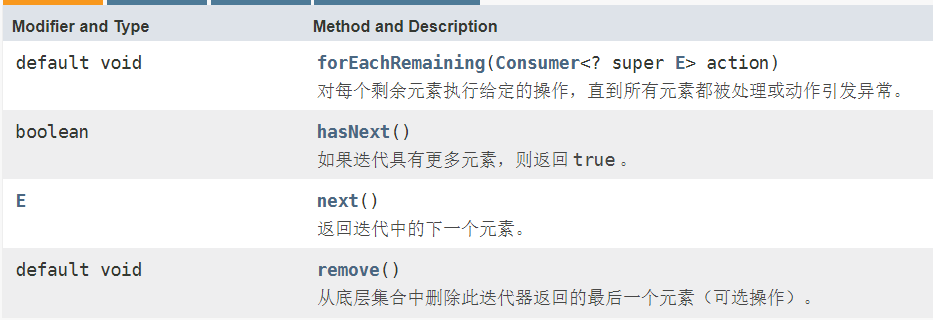
方式一:使用Iterator(迭代器)
Iterator对象称为迭代器,主要用于遍历Collection集合中的元素
- 所有实现了Collection接口的结合类都有一个iterator()方法,用以放回一个实现了Iterator接口的对象,即可以返回一个迭代器
- Iterator结构图以及方法如下
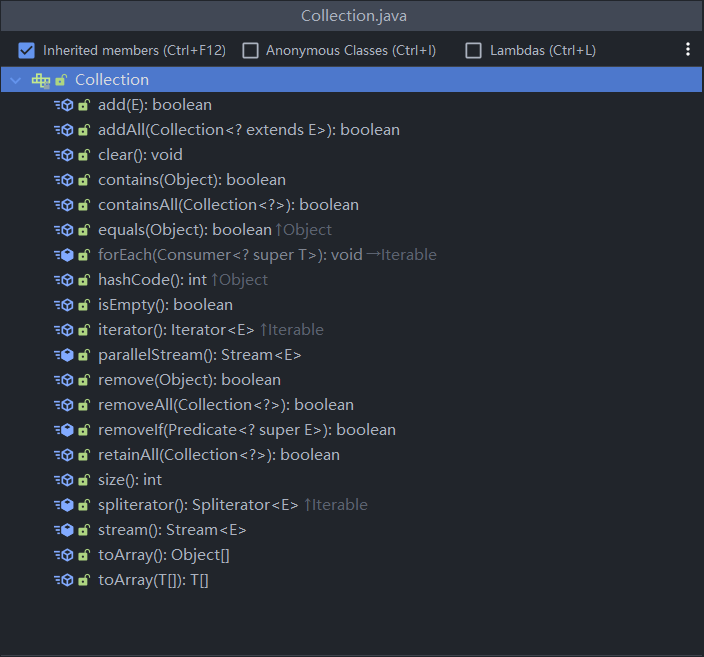

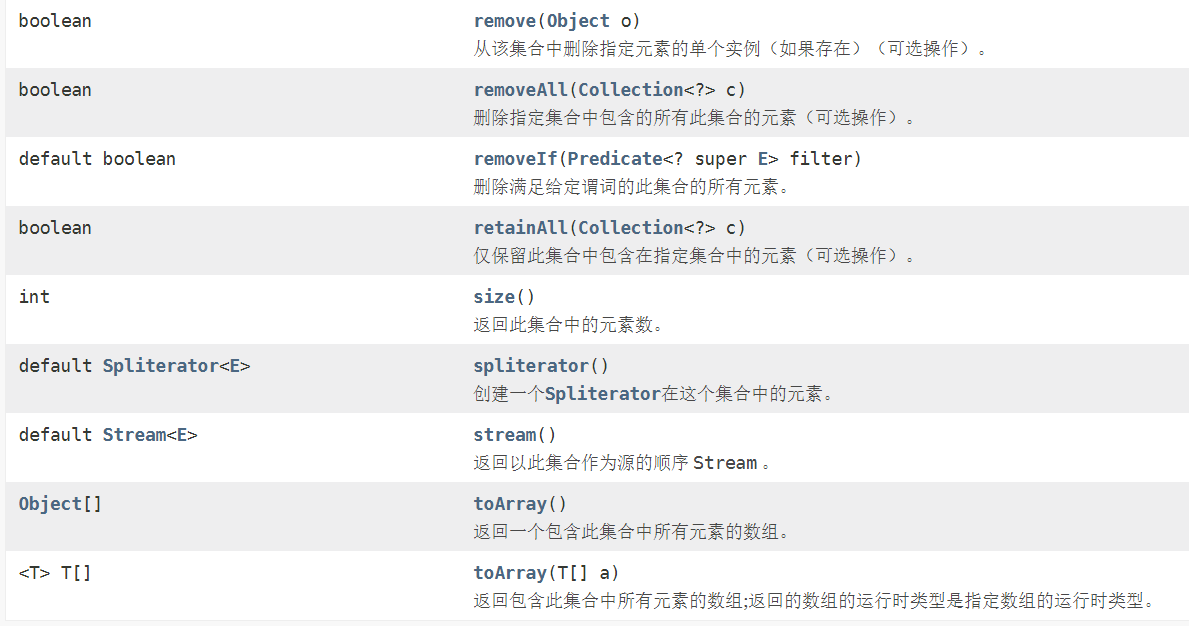
- Iterator仅用于遍历集合,Iterator本身并不存放对象
Iterator执行原理
注:在调用next()方法之前必须调用hasNext()进行检测。若不检测,且下一条记录无效时,直接调用next()会抛出NoSuchElementException异常
如果需要再次遍历,需要重置迭代器(重新获取迭代器)
方式二:for循环增强
增强for循环,可以代替iterator迭代器,特点:增强for就是简化版的iterator,本质一样,只能用于遍历集合或者数组
基本语法:
for(元素类型 元素 : 集合名或数组名){}
底层依旧是iterator
List接口和常用方法
基本介绍
List接口是Collection接口的子接口
- List集合类中元素有序(即添加顺序和取出顺序一致)、且可重复
- List集合中的每个元素都有其对应的顺序索引,即支持索引
List集合中的元素都对应一个整数型的序号记在其在集合中的位置,可以根据序号存取集合中的元素
常用方法
注意事项
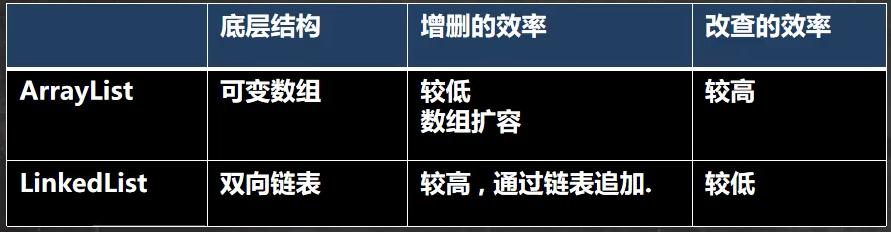
permits all elements, including null, ArrayList可以加入null,并且可以多个
- ArrayList是由数组来实现数组存储的
Arraylist基本等同于Vector,除了ArrayList是线程不安全(执行效率高),在多线程情况下,不推荐使用ArrayList
ArrayList底层结构和源码分析
基本介绍
ArrayList中维护了一个Object类型的数组elementData
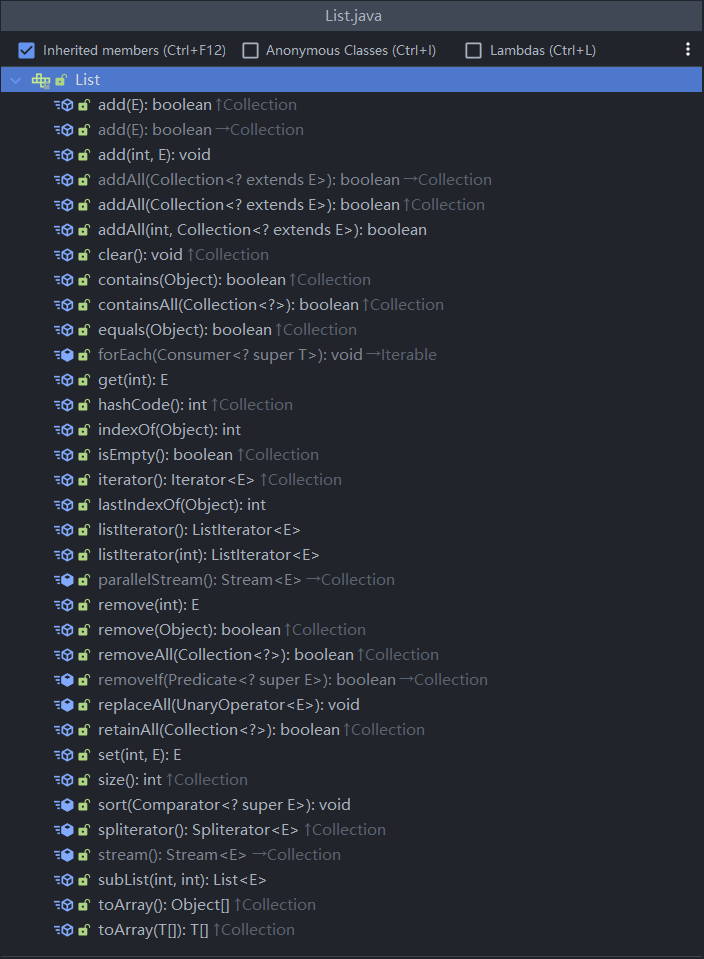

- 当创建ArrayList对象时,如果使用的是无参构造器,则初始elementData容量为0,第1次添加,则扩容elementData为10,如需要再次扩容,则扩容elementData为1.5倍
- 如果使用的是指定大小的构造器,则初始elementData容量为指定大小,如果需要扩容,则直接扩容elementData为1.5倍
属性
```java private static final long serialVersionUID = 8683452581122892189L;
/**
- Default initial capacity.
- 默认初始容量 */ private static final int DEFAULT_CAPACITY = 10;
/**
- Shared empty array instance used for empty instances.
- 用于空实例的共享空数组实例 */ private static final Object[] EMPTY_ELEMENTDATA = {};
/**
- Shared empty array instance used for default sized empty instances. We
- distinguish this from EMPTY_ELEMENTDATA to know how much to inflate when
- first element is added.
- 用于默认大小的空实例的共享空数组实例。我们将其与 EMPTY_ELEMENTDATA 区分开来,
- 以了解添加第一个元素时要膨胀多少。 */ private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
/**
- The array buffer into which the elements of the ArrayList are stored.
- The capacity of the ArrayList is the length of this array buffer. Any
- empty ArrayList with elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA
- will be expanded to DEFAULT_CAPACITY when the first element is added.
- 存储 ArrayList 元素的数组缓冲区。 ArrayList 的容量就是这个数组缓冲区的长度。
- 当添加第一个元素时,任何具有 elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA
- 的空 ArrayList 都将扩展为 DEFAULT_CAPACITY。 */ transient Object[] elementData; // non-private to simplify nested class access
/**
- The size of the ArrayList (the number of elements it contains).
- ArrayList 的大小(它包含的元素数量)
- @serial */ private int size;
/**
- The maximum size of array to allocate.
- Some VMs reserve some header words in an array.
- Attempts to allocate larger arrays may result in
- OutOfMemoryError: Requested array size exceeds VM limit
- 要分配的数组的最大大小。一些 VM 在数组中保留一些标题字。
- 尝试分配更大的数组可能会导致 OutOfMemoryError:请求的数组大小超过 VM 限制
*/
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
```
方法
计算容量
- 计算容量:若elementData为空,表明第一次使用,使用默认长度10,若不是第一次使用,则返回minCapacity所需的最小容量(比如,原始长度为3,要添加一个元素,那么minCapacity=4)
确保显示容量:最minCapactiy和size对比,若minCapacity > size,则进行扩容 ```java /**
- 如有必要,增加此ArrayList实例的容量,以确保它至少可以容纳最小容量参数指定的元素数量。
- 参数:
minCapacity – 所需的最小容量 */ public void ensureCapacity(int minCapacity) { int minExpand = (elementData != DEFAULTCAPACITY_EMPTY_ELEMENTDATA)
// any size if not default element table? 0// larger than default for default empty table. It's already// supposed to be at default size.: DEFAULT_CAPACITY;
if (minCapacity > minExpand) {
ensureExplicitCapacity(minCapacity);
} } /**
- 计算容量,如果elementData为空,则返回默认长度10与minCapacity的最大值,
- 否则返回minCapacity
*/
private static int calculateCapacity(Object[] elementData, int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
} return minCapacity; }return Math.max(DEFAULT_CAPACITY, minCapacity);
/**
- 确保内部容量 */ private void ensureCapacityInternal(int minCapacity) { ensureExplicitCapacity(calculateCapacity(elementData, minCapacity)); }
/**
确保显示容量 */ private void ensureExplicitCapacity(int minCapacity) { modCount++; //当前集合修改次数,
// overflow-conscious code if (minCapacity - elementData.length > 0)
grow(minCapacity);
grow 扩容
- 储存旧容器长度oldCapacity
- 计算新容器长度newCapacity = 1.5 * oldCapacity,第一次为10(new ArrayList时未指定长度,使用空参构造器)
- 如果newCapacity < minCapacity,则newCapacity = minCapacity
- 如果newCapacity > 最大数组长度MAX_ARRAY_SIZE ,则newCapacity = (minCapacity > MAX_ARRAY_SIZE) ? Integer.MAX_VALUE : MAX_ARRAY_SIZE;
进行数组拷贝扩容
/*** 增加容量以确保它至少可以容纳最小容量参数指定的元素数量。* 参数:* minCapacity – 所需的最小容量*/private void grow(int minCapacity) {// overflow-conscious codeint oldCapacity = elementData.length;int newCapacity = oldCapacity + (oldCapacity >> 1);if (newCapacity - minCapacity < 0)newCapacity = minCapacity;if (newCapacity - MAX_ARRAY_SIZE > 0)newCapacity = hugeCapacity(minCapacity);// minCapacity is usually close to size, so this is a win:elementData = Arrays.copyOf(elementData, newCapacity);}
add
/*** Appends the specified element to the end of this list.** @param e element to be appended to this list* @return <tt>true</tt> (as specified by {@link Collection#add})** 将指定元素附加到此列表的末尾。* 参数:* e – 要附加到此列表的元素* 回报:* true (由Collection.add指定)*/public boolean add(E e) {ensureCapacityInternal(size + 1); // Increments modCount!!elementData[size++] = e;return true;}
Vector底层结构和源码分析
基本介绍

底层也是一个对象数组,

- Vector是线程同步的,即线程安全,Vector类的操作方法带有synchronized
在开发中,需要线程同步安全时,考虑使用Vector,但是不推荐用,可以使用其他方法代替,CopyOnWriteArrayList等方法
与ArrayList对比

源码和ArrayList基本差不多,只不过一些操作方法都加了synchronized 关键字
比如:public synchronized void addElement(E obj) {modCount++;ensureCapacityHelper(elementCount + 1);elementData[elementCount++] = obj;}
LinkedList底层结构
基本介绍
LinkedList底层实现了双向链表和双端队列的特点
- 可以添加任意元素(元素可以重复),包括null
- 线程不安全,没有实现同步

- LinkedList底层维护了一个双向链表
- LinkedList中维护了两个属性first和last分别指向首节点和尾结点
每个节点(Node对象),里面又维护了prev、next、item三个属性,prev指向前一个,next指向后一个,从而实现双向链表
属性
size 长度
- first 首节点
last 尾结点
transient int size = 0;/*** Pointer to first node.* Invariant: (first == null && last == null) ||* (first.prev == null && first.item != null)*/transient Node<E> first;/*** Pointer to last node.* Invariant: (first == null && last == null) ||* (last.next == null && last.item != null)*/transient Node<E> last;// 内部类private static class Node<E> {E item;Node<E> next;Node<E> prev;Node(Node<E> prev, E element, Node<E> next) {this.item = element;this.next = next;this.prev = prev;}}
和ArrayList对比
Set接口和常用方法
基本介绍
无序(添加和取出的顺序不一致),没有索引
- 取出的顺序虽然不是添加时候的顺序,但是取出的顺序是固定的,不会每次取出顺序都不一样
- 不允许重复元素,所以对多包含一个null
-
常用方法
和List接口一样,Set接口也是Collection的子接口,因此,常用方法和Collection接口一样
遍历方法
同Collection的遍历方式一样,因为Set接口是Collection接口的子接口,所以
可以使用迭代器
- 增强for循环
-
HashSet底层结构和源码分析
基本介绍
实现接口

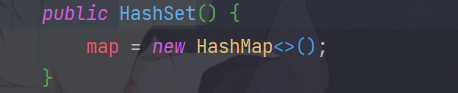
- 构造器,实际是HashMap
- 可以存放null,但是只能有一个null
- HashSet不保证元素是有序的,取决于hash后,在确定索引的结果
- 不能有重复元素/对象
底层机制:
- HashSet底层是HashMap
- 添加一个元素时,先得到hash值- 会转成—>索引值
- 找到存储数据表table,看这个索引位置是否已经存放元素
- 如果没有,直接加入
- 如果有,调用equals比较,如果相同,则放弃添加,如果不相同,则添加到最后
- 在Java8中,如果一条链表的元素个数到了TREEIFY_THRESHOLD(默认为8),并且table的大小>=MIN_TREEIFY_CAPACTIY(64)就会树化(红黑树)
- 如果table的大小
属性
HashSet底层其实是HashMap,而HashMap是键值类型的数据结构,所以HashSet存储的值是键key,与键对应的值是下面的PRESENT,一个空对象,而由于所存储的是键key,所以不允许出现重复的键key ```java static final long serialVersionUID = -5024744406713321676L;
private transient HashMap
// Dummy value to associate with an Object in the backing Map private static final Object PRESENT = new Object();
<a name="YcCUa"></a>## hash算法每个key通过哈希函数的计算都会得到一个唯一的index,但并不是每个index都对应一个唯一的key,就是说可能有两个以上的key映射到同一个index,这就产生了哈希冲突的问题。```java/**计算 key.hashCode() 并将哈希的较高位传播(XOR)到较低位。* 由于该表使用二次幂掩码,因此仅在当前掩码之上位变化的散列集将始终发生冲突。*(已知的例子是在小表中保存连续整数的 Float 键集。)因此,我们应用了一种变换,* 将高位的影响向下传播。在位扩展的速度、实用性和质量之间存在折衷。* 因为许多常见的散列集已经合理分布(所以不要从传播中受益),* 并且因为我们使用树来处理 bin 中的大量冲突,我们只是以最便宜的方式对一些移位的位进行异或,* 以减少系统损失,以及合并最高位的影响,否则由于表边界,这些最高位将永远不会用于索引计算*/static final int hash(Object key) {int h;return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);}
首先 h = key.hashCode()是key对象的一个hashCode,每个不同的对象其哈希值都不相同,其实底层是对象的内存地址的散列值,所以最开始的h是key对应的一个整数类型的哈希值
h >>> 16的意思是将h右移16位,然后高位补0,然后再与(h = key.hashCode()) 异或运算得到最终的h值,为什么是异或运算呢?当然我们知道目的是为了让h的低16位更有散列性,但为什么是异或运算就更有散列性呢?而不是与运算或者或运算呢?网上大多的文章都没有给出一个很好的说明,这里我将证明一下为什么异或就能够得到更好散列性。
为什么异或运算的散列性更好
上面是将0110和0101分别进行与、或、异或三种运算得到不同的结果,我们主要来看计算的过程:
与运算:其中1&1=1,其他三种情况1&0=0, 0&0=0, 0&1=0 都等于0,可以看到与运算的结果更多趋向于0,这种散列效果就不好了,运算结果会比较集中在小的值
或运算:其中0&0=0,其他三种情况 1&0=1, 1&1=1, 0&1=1 都等于1,可以看到或运算的结果更多趋向于1,散列效果也不好,运算结果会比较集中在大的值
异或运算:其中0&0=0, 1&1=0,而另外0&1=1, 1&0=1 ,可以看到异或运算结果等于1和0的概率是一样的,这种运算结果出来当然就比较分散均匀了
总的来说,与运算的结果趋向于得到小的值,或运算的结果趋向于得到大的值,异或运算的结果大小值比较均匀分散,这就是我们想要的结果,这也解释了为什么要用异或运算,因为通过异或运算得到的h值会更加分散,进而 h & (length-1)得到的index也会更加分散,哈希冲突也就更少
putVal
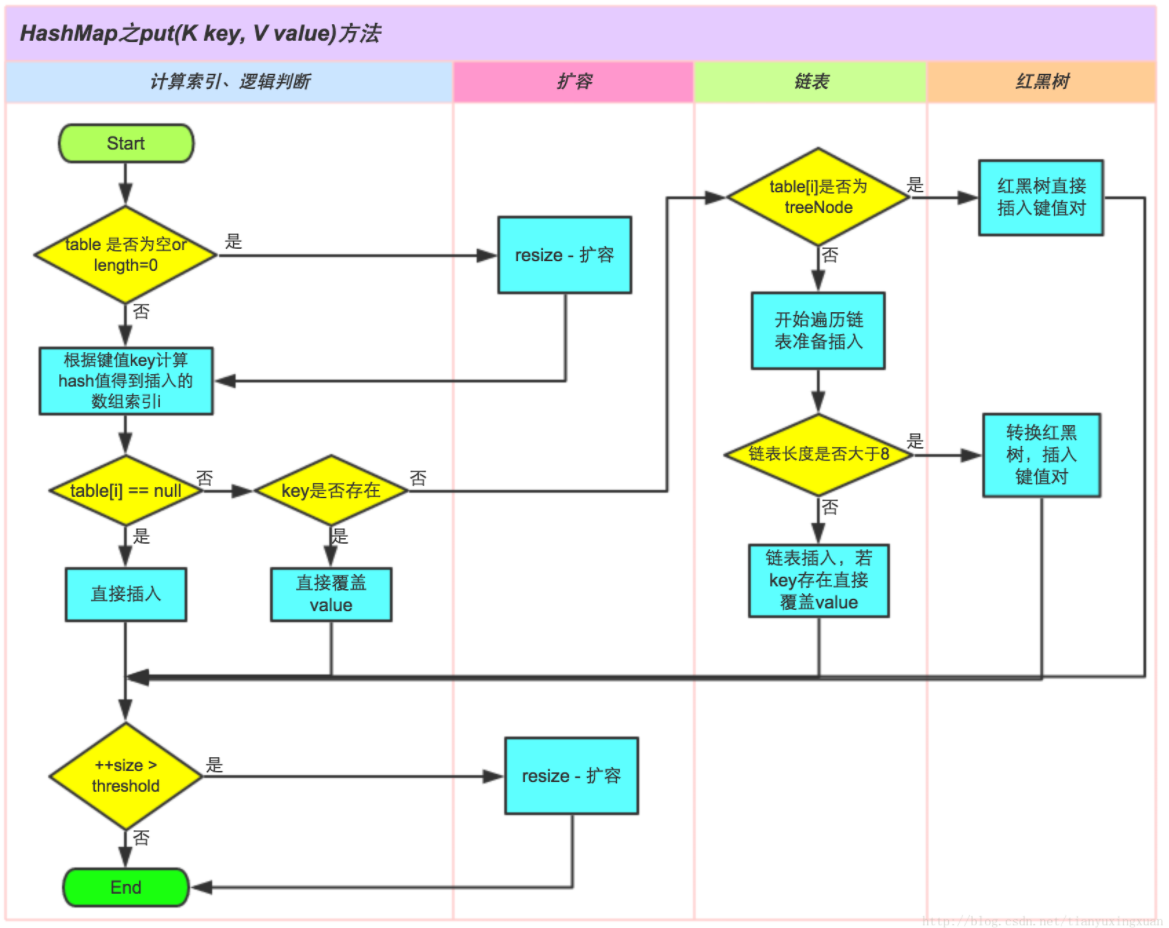
/*** 实现 Map.put 和相关方法。* 参数:* hash – 键的散列* key - 键* value – 要放置的值* onlyIfAbsent – 如果为真,则不更改现有值* evict – 如果为 false,则表处于创建模式。* return: v,如果没有,则为 null*/final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {Node<K,V>[] tab; Node<K,V> p; int n, i;// table为空或长度为0,则执行resize进行扩容if ((tab = table) == null || (n = tab.length) == 0)n = (tab = resize()).length;// 如果table索引i为空,则在索引i处添加新节点if ((p = tab[i = (n - 1) & hash]) == null)tab[i] = newNode(hash, key, value, null);else {Node<K,V> e; K k;if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))e = p;else if (p instanceof TreeNode)e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);else {for (int binCount = 0; ; ++binCount) {if ((e = p.next) == null) {p.next = newNode(hash, key, value, null);if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1sttreeifyBin(tab, hash);break;}if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))break;p = e;}}if (e != null) { // existing mapping for keyV oldValue = e.value;if (!onlyIfAbsent || oldValue == null)e.value = value;afterNodeAccess(e);return oldValue;}}++modCount;if (++size > threshold)resize();afterNodeInsertion(evict);return null;}

若有收获,就点个赞吧
0 人点赞
