volatile 的底层实现原理是内存屏障,Memory Barrier(Memory Fence)
- 对 volatile 变量的写指令后会加入写屏障
- 对 volatile 变量的读指令前会加入读屏障
一、保护可见性
写屏障(sfence)保证在该屏障之前的,对共享变量的改变,都同步到主存中,而不是cpu缓存中。
public void actor2(I_result r){num=2;ready=true;//对ready的赋值是写操作,其后会加入写屏障// 写屏障}
可理解为,在写指令之后加上限制,如果写的指令不是将新内容写进主存中,则会受到限制,该限制强迫写指令将最新内容写入主存中。
读屏障保证在该屏障之后,对共享变量的读取,加载的是主存中的最新数据
//线程1执行此方法public void actor1(I_result r){//读屏障//ready被volatile修饰,所以在读ready值之前要加读屏障if(ready){r.r1=num+num;}else{r.r1=1;}}
可理解为,在读指令之前加上限制,该限制强迫读取的是主存中的最新内容。
流程图如下: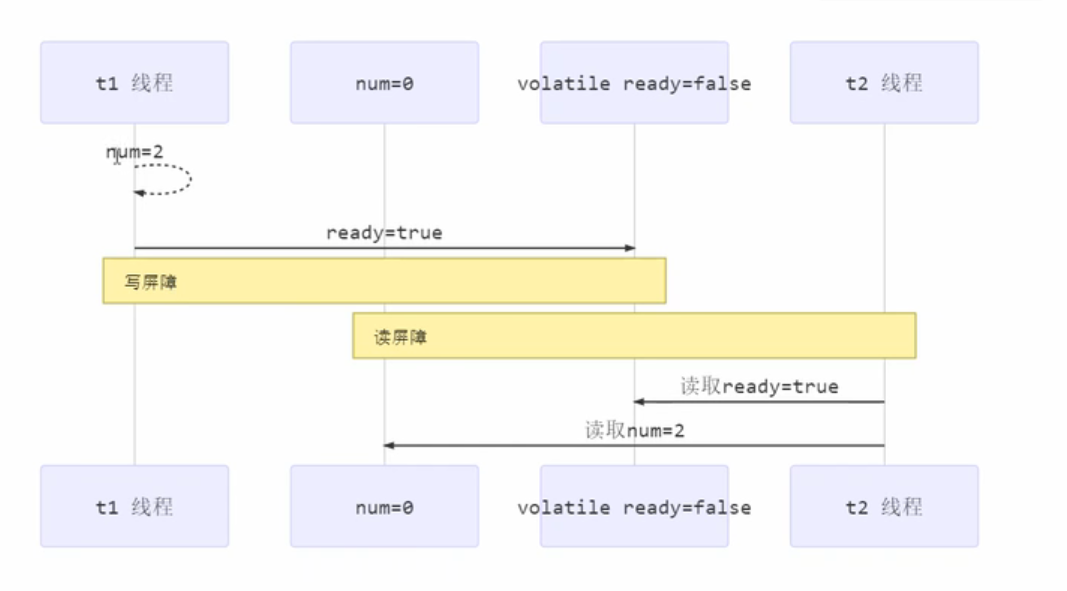
二、保护有序性
写屏障会确保指令重排序时,不会将写屏障之前的代码排在写屏障之后
public void actor2(I_result r){num=2;ready=true;//对ready的赋值是写操作,其后会加入写屏障//写屏障}
读屏障会确保指令重排序时,不会将读屏障之后的代码排在读屏障之前
public void actor1(I_result r){//读屏障//ready被volatile修饰,所以在读ready值之前要加读屏障if(ready){r.r1=num+num;}else{r.r1=1;}}
注意:
读写屏障(volatile)不能解决指令交错问题
- 写屏障仅仅是保证之后的读能够读到最新的结果,但不能保证读跑到它前面去
- 有序性的保证也只是保证了本线程内相关代码不被重排序,但是多线程间由于cpu调度而产生的指令交错(因时间片用完而造成的线程上下文切换问题)无法通过volatile解决。
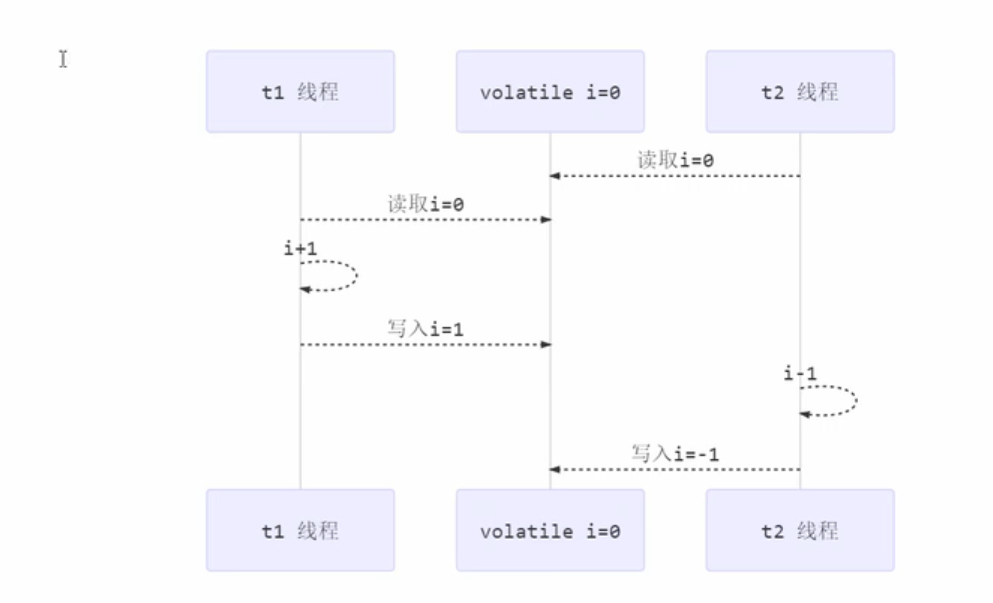
比如即使变量i被 volatile 修饰,每次读取的i是最新的值,但仍然可能存在t2线程在t1线程执行前就读到错误i值的情况
总结来讲,volatile能保证线程可见性、线程内指令有序性(指令重排序禁用),但是不能保证代码的原子性。
三、double-checked locking 问题
单例模式中,著名的double-checked locking代码实现方式如下所示,当类实例已经被创建出,再调用getINSTANCE()方法的线程会直接查询INSTANCE是否为空,而无需进入synchronized块中查询,因为synchronized属于重量级操作,dcl的方式能够节省系统资源。
import com.sun.scenario.animation.shared.SingleLoopClipEnvelope;public class Singleton {//构造方法设置为private,类外部不可以new出对象private Singleton(){}private static Singleton INSTANCE = null;public static synchronized Singleton getINSTANCE(){if(INSTANCE==null){synchronized (Singleton.class){if(INSTANCE==null){INSTANCE = new Singleton();}}}return INSTANCE;}}
以上dcl方式的实现特点是:
- 懒惰实例化
- 首次使用 getInstance() 才使用 synchronized 加锁后,后续使用时无需加锁
- 有隐含的,但很关键的一点:第一个if使用了INSTANCE变量,是在同步块之外
但在多线程环境下,上面的代码是有问题的,getINSTANCE()方法对应的字节码为:
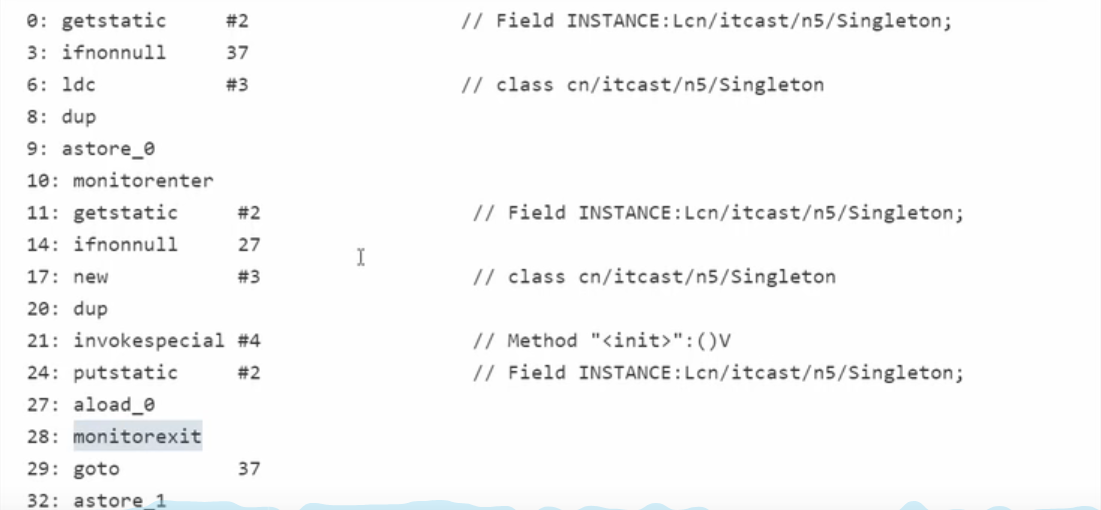
其中
- 17 表示创建对象,将对象引用入栈 //new Singleton
- 20 表示复制一份引用 //引用地址
- 21 表示利用一个对象引用,调用构造方法 //根据引用地址调用
- 24 表示利用一个对象引用,赋值给static INSTANCE //
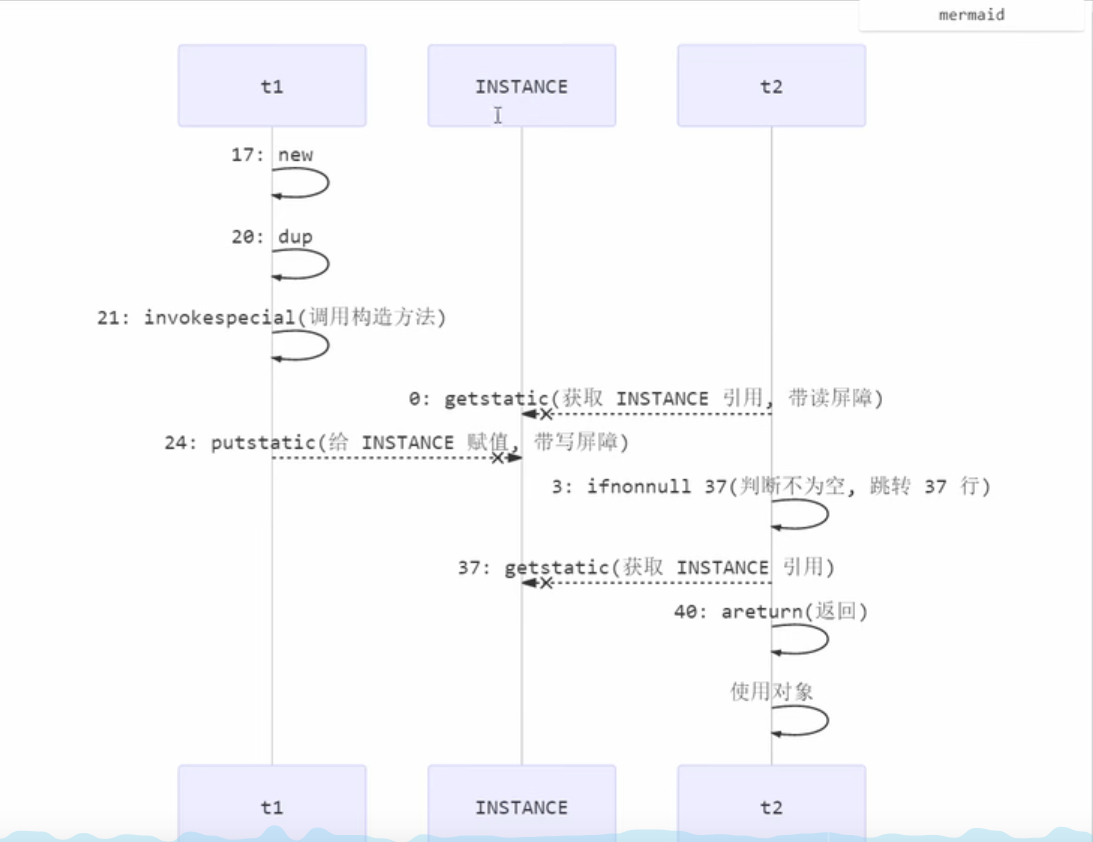
也许jvm会优化为:先执行24,再执行21。如果两个线程t1,t2按如下时间序列执行: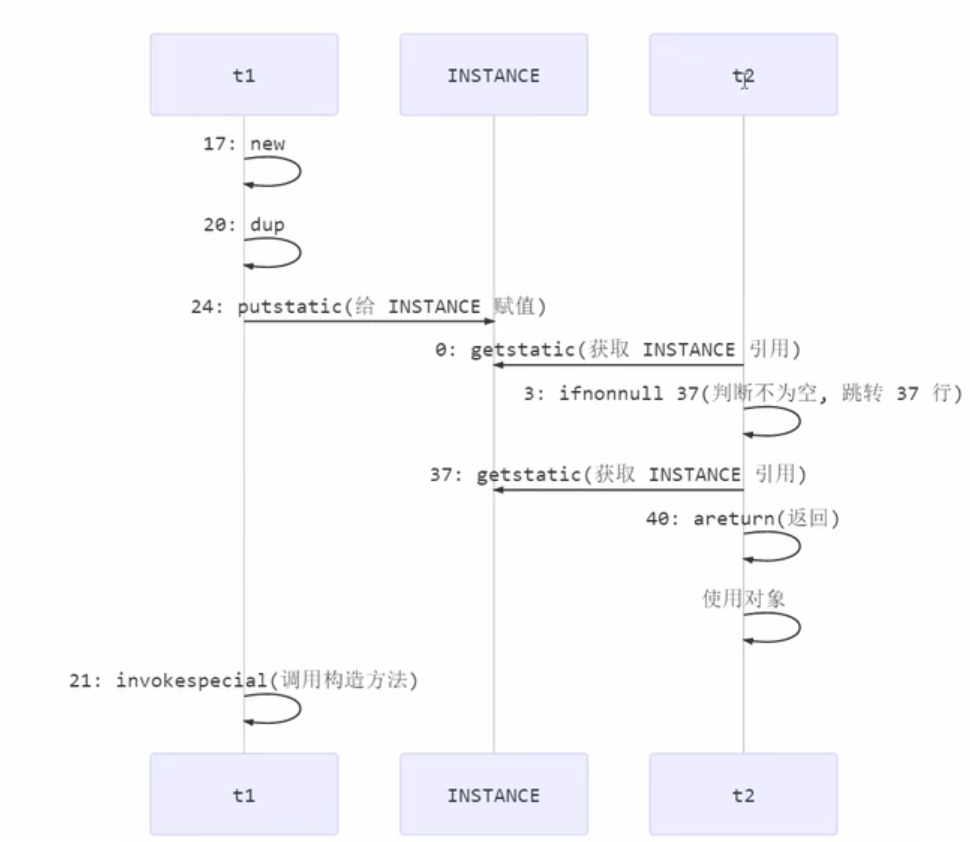
则很有可能会出现当线程t1执行到第24行的指令时,切换到线程t2执行,而if(INSTANCE==null){} 这行代码没有进入synchronized中,所以线程t2不会立即因为没获得到锁而陷入阻塞状态,而是会执行if(INSTANCE==null){}对应的指令,这完全有可能出现上述的指令执行流程,这样整体结果就会出现问题,整体问题还是:多线程环境下由于指令交错与指令重排综合作用引起的结果错误
if(INSTANCE==null){synchronized (Singleton.class){if(INSTANCE==null){INSTANCE = new Singleton();}}}
关键在于 0:getstatic 这行代码在monitor控制之外,它就像之前举例中不守规则的人,可以越过monitor读取 INSTANCE 变量的值。
这时t1还未完全将构造方法构造完毕,如果在构造方法中要执行很多初始化操作,那么t2拿到的将是一个未初始化完毕的单例。
解决方案:
- 对INSTANCE使用 volatile 修饰即可,可以禁止指令重排,这样synchronized中的指令不会被重新排列,当与线程2的指令交错时也不会出现问题。
- 将 INSTANCE 共享完全放进synchronized同步块中保护,这样利用原子性也可实现有序性。
问题解决分析:
如下图所示,加上volatile后,在字节码中的不同位置加上了读写屏障

加上读写屏障后,线程 t1 内synchronized块内的指令就禁止了重排序,与线程t2再有指令交错即不会再发生问题。

若有收获,就点个赞吧
0 人点赞
