当有任务出现,如果每个任务均需创建一个新线程去处理任务,会过度浪费系统资源。线程池的做法则是:将线程存储起来,重复利用线程去处理任务。
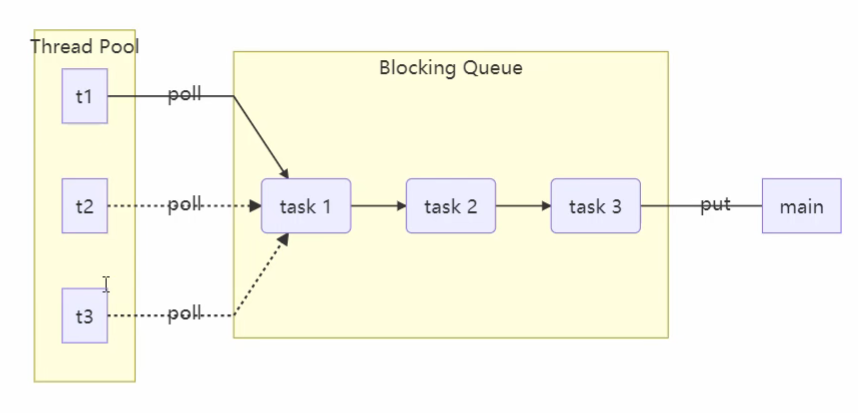
整体是生产者-消费者结构,左侧Thread Pool存放可重用线程,中间的Blocking Queue用来平衡速度差异。Thread Pool消费tasks,main生产tasks.
如果tasks过多,线程处理不过来,Blocking Queue用来存储tasks,如果tasks过少,线程池中的消费者线程则需要在Blocking Queue中等待.
阻塞队列实现:
class BlockingQueue<T>{// 1.任务队列private Deque<T> queue = new ArrayDeque<>();// 2.锁private ReentrantLock lock = new ReentrantLock();// 3.生产者条件变量private Condition fuulWaitSet = lock.newCondition();// 4.消费者条件变量private Condition emptyWaitSet = lock.newCondition();// 5.容量private int capcity;public BlockingQueue(int capcity) {this.capcity = capcity;}//带超时的阻塞获取public T poll(long timeout, TimeUnit unit){lock.lock();try {// 将timeout 统一转换为纳秒long nanos = unit.toNanos(timeout);while(queue.isEmpty()){try {if(nanos<=0){return null;}emptyWaitSet.awaitNanos(nanos);//能够自动解决虚假唤醒问题,返回的是剩余时间} catch (InterruptedException e) {e.printStackTrace();}}//获取队列头元素并返回T t =queue.removeFirst();fuulWaitSet.signal();return t;}finally {lock.unlock();}}// 阻塞获取public T take(){lock.lock();try {while(queue.isEmpty()){try {emptyWaitSet.await();} catch (InterruptedException e) {e.printStackTrace();}}//获取队列头元素并返回T t =queue.removeFirst();fuulWaitSet.signal();return t;}finally {lock.unlock();}}//阻塞添加public void put(T element){lock.lock();try{while(queue.size()==capcity){try {fuulWaitSet.await();} catch (InterruptedException e) {e.printStackTrace();}}queue.addLast(element);emptyWaitSet.signal();}finally {lock.unlock();}}//获取大小,当然这里可以不加锁,完全只读public int size(){lock.lock();try {return queue.size();}finally {lock.unlock();}}}
阻塞队列的实现:ReentrantLock锁+两种情况的wait-notify实现(队列空、队列满)
线程池实现(无超时时间):
class ThreadPool{//线程池中需要用到阻塞队列(任务队列)private BlockingQueue<Runnable> taskQueue;// 线程集合,如果是Thread对象所包含的信息有限,所以将线程类包装成Worker类private HashSet<Worker> workers = new HashSet<>();// 核心线程数private int coreSize;// 获取任务的超时时间,如果线程限定时间内获取不到任务,释放线程private long timeout;private TimeUnit timeUnit;// 执行任务public void execute(Runnable task){//当任务数没有超过 coreSize时,直接交给 worker对象执行//如果任务数超过 coreSize时,加入任务队列暂存。synchronized (workers){//线程数小于任务if (workers.size() < coreSize){Worker worker = new Worker(task);workers.add(worker);worker.start();}else {taskQueue.put(task);}}}public ThreadPool(int coreSize, long timeout, TimeUnit timeUnit,int queueCapacity) {this.coreSize = coreSize;this.timeout = timeout;this.timeUnit = timeUnit;this.taskQueue = new BlockingQueue<>(queueCapacity);}class Worker extends Thread{private Runnable task;public Worker(Runnable task){this.task = task;}@Overridepublic void run() {//执行任务// 1 当 task不为空,执行任务// 2 当task执行完毕,再接着从任务队列获取任务并执行while(task!=null||(task = taskQueue.take())!=null)){try {task.run();}catch (Exception e){}finally {task = null;}}synchronized (workers){workers.remove(this);}}}}
本段代码逻辑稍微复杂些,ThreadPool中的 coreSize 表示线程池能承受的最大线程数。
这段代码实现的逻辑是:线程池中每个线程处理一个任务,传进task任务后,如果线程池当前线程数还没到满,则新创建线程并执行该任务,如果线程池已经满,则没有线程可以处理该任务,则将该任务存入任务队列中。
public void execute(Runnable task){//当任务数没有超过 coreSize时,直接交给 worker对象执行//如果任务数超过 coreSize时,加入任务队列暂存。synchronized (workers){//线程数小于任务if (workers.size() < coreSize){Worker worker = new Worker(task);workers.add(worker);worker.start();}else {taskQueue.put(task);}}}
Worker implements Thread,所以Worker类是线程类,所以其要重写run方法,run方法要根据构造方法中传入的task来判断此任务是否可以执行。
注意run方法处于等待任务状态,如果新传进来的任务已经执行完毕,则其会去阻塞队列中查找任务执行,如果阻塞队列中已经没有任务可以执行,那么就会陷入【WAITING】状态,take()的实现细节:如果队列为空,则一直等待下去。
这种思路的弊端是:线程如果没有任务可执行,会陷入空等,下边的销毁线程代码实际没有起到作用
注意taskQueue.task()方法的线程安全问题,已经在BlockingQueue类中的解决。
@Overridepublic void run() {//执行任务// 1 当 task不为空,执行任务// 2 当task执行完毕,再接着从任务队列获取任务并执行while(task!=null||(task = taskQueue.take())!=null)){try {task.run();}catch (Exception e){}finally {task = null;}}synchronized (workers){workers.remove(this);}}
线程池实现(有超时时间):
class Worker extends Thread{private Runnable task;public Worker(Runnable task){this.task = task;}@Overridepublic void run() {//执行任务// 1 当 task不为空,执行任务// 2 当task执行完毕,再接着从任务队列获取任务并执行while(task!=null||(task = taskQueue.poll(timeout,timeUnit))!=null)){try {task.run();}catch (Exception e){}finally {task = null;}}synchronized (workers){workers.remove(this);}}}
Worker类中run方法实现细节改变,taskQueue.take()改为taskQueue.poll(),如果超时等待不到任务,taskQueue.poll()返回null值,run方法内的while循环结束,线程经过workers.remove()方法得以销毁。
阻塞队列满-拒绝策略:
如果任务数过多,阻塞队列中存放不下,主线程会陷入等待状态,应该使得主线程有选择空间。
public class TestThreadPool {public static void main(String[] args) {//由主线程向线程池中提交任务ThreadPool threadPool = new ThreadPool(2,1000,TimeUnit.MILLISECONDS,10);for (int i=0;i<15;i++){int j =i;threadPool.execute(()->{System.out.println(j);});}}}
向阻塞队列中输入任务的代码改为超时限制的添加:
//带超时时间的阻塞添加public boolean offer(T task, long timeout, TimeUnit timeUnit){lock.lock();try {long nanos = timeUnit.toNanos(timeout);while (queue.size()==capcity){try {if(nanos<=0){return false;}nanos = fuulWaitSet.awaitNanos(nanos);} catch (InterruptedException e) {e.printStackTrace();}}queue.addLast(task);emptyWaitSet.signal();return true;}finally {lock.unlock();}}
向阻塞队列中输入任务有多种实现策略,如下:死等(最原始)、超时等待、调用者放弃任务的执行、调用者抛出异常、调用者自己执行任务
public void execute(Runnable task){//当任务数没有超过 coreSize时,直接交给 worker对象执行//如果任务数超过 coreSize时,加入任务队列缓存。synchronized (workers){//线程数小于任务if (workers.size() < coreSize){Worker worker = new Worker(task);workers.add(worker);worker.start();}else {taskQueue.put(task);// 1.死等// 2.带超时等待// 3.让调用者放弃任务执行// 4.让调用者抛出异常// 5.让调用者自己执行任务}}}
如果将五种代码逻辑均写到execute方法中(多个if-else),明显代码灵活度不够,解决办法:策略模式,将方法抽象成接口,具体选择那种实现方式交给调用者,通过调用时传递进来。
声明函数式接口:
@FunctionalInterface //拒绝策略,函数式接口interface RejectPolicy<T>{void reject(BlockingQueue<T> queue,T task);}
BlockingQueue类中,增加tryPut方法:
public void tryPut(RejectPolicy<T> rejectPolicy, T task){lock.lock();try {//判断队列是否为满if(queue.size()==capcity){//传入就好,权力下放给调用者,妙!rejectPolicy.reject(this,task);}else{queue.addLast(task);}}finally {}}
如果队列满,那么调用rejectPolicy.reject()方法,将阻塞队列与task传进去,因为毕竟此操作是对阻塞队列而言。
因为tryPut方法中要使用rejectPolicy对象,且ThreadPool类中的execute方法需要调用tryPut方法,所以ThreadPool类中需要添加RejectPolicy类引用属性,并在构造方法中初始化:
public ThreadPool(int coreSize, long timeout, TimeUnit timeUnit,int queueCapacity, RejectPolicy<Runnable> rejectPolicy) {this.coreSize = coreSize;this.timeout = timeout;this.timeUnit = timeUnit;this.taskQueue = new BlockingQueue<>(queueCapacity);this.rejectPolicy = rejectPolicy;}
主线程内,在ThreadPool初始化时,指定RejectPolicy
ThreadPool threadPool = new ThreadPool(2,1000,TimeUnit.MILLISECONDS,10,(queue,task)->{// 1.死等queue.put(task);});
本例完整代码:
import com.sun.corba.se.spi.orbutil.threadpool.Work;import javafx.concurrent.Worker;import java.io.Closeable;import java.sql.Time;import java.util.ArrayDeque;import java.util.Deque;import java.util.HashSet;import java.util.concurrent.TimeUnit;import java.util.concurrent.locks.Condition;import java.util.concurrent.locks.ReentrantLock;public class TestThreadPool {public static void main(String[] args) {//由主线程向线程池中提交任务ThreadPool threadPool = new ThreadPool(2,1000,TimeUnit.MILLISECONDS,10,(queue,task)->{// 1.死等queue.put(task);});for (int i=0;i<15;i++){int j =i;threadPool.execute(()->{System.out.println(j);});}}}@FunctionalInterface //拒绝策略,函数式接口interface RejectPolicy<T>{void reject(BlockingQueue<T> queue,T task);}class ThreadPool{//线程池中需要用到阻塞队列,任务队列private BlockingQueue<Runnable> taskQueue;// 线程集合,如果是Thread对象所包含的信息有限,所以将线程类包装成Worker类private HashSet<Worker> workers = new HashSet<>();// 核心线程数private int coreSize;// 获取任务的超时时间,如果线程限定时间内获取不到任务,释放线程private long timeout;private TimeUnit timeUnit;private RejectPolicy<Runnable> rejectPolicy;// 执行任务public void execute(Runnable task){//当任务数没有超过 coreSize时,直接交给 worker对象执行//如果任务数超过 coreSize时,加入任务队列缓存。synchronized (workers){//线程数小于任务if (workers.size() < coreSize){Worker worker = new Worker(task);workers.add(worker);worker.start();}else {taskQueue.put(task);// 1.死等// 2.带超时等待// 3.让调用者放弃任务执行// 4.让调用者抛出异常// 5.让调用者自己执行任务taskQueue.tryPut(rejectPolicy,task);}}}public ThreadPool(int coreSize, long timeout, TimeUnit timeUnit,int queueCapacity, RejectPolicy<Runnable> rejectPolicy) {this.coreSize = coreSize;this.timeout = timeout;this.timeUnit = timeUnit;this.taskQueue = new BlockingQueue<>(queueCapacity);this.rejectPolicy = rejectPolicy;}class Worker extends Thread{private Runnable task;public Worker(Runnable task){this.task = task;}@Overridepublic void run() {//执行任务// 1 当 task不为空,执行任务// 2 当task执行完毕,再接着从任务队列获取任务并执行while(task!=null||(task = taskQueue.poll(timeout,timeUnit))!=null)){try {task.run();}catch (Exception e){}finally {task = null;}}synchronized (workers){workers.remove(this);}}}}class BlockingQueue<T>{// 1.任务队列private Deque<T> queue = new ArrayDeque<>();// 2.锁private ReentrantLock lock = new ReentrantLock();// 3.生产者条件变量private Condition fuulWaitSet = lock.newCondition();// 4.消费者条件变量private Condition emptyWaitSet = lock.newCondition();// 5.容量private int capcity;public BlockingQueue(int capcity) {this.capcity = capcity;}//带超时的阻塞获取public T poll(long timeout, TimeUnit unit){lock.lock();try {// 将timeout 统一转换为纳秒long nanos = unit.toNanos(timeout);while(queue.isEmpty()){try {if(nanos<=0){return null;}emptyWaitSet.awaitNanos(nanos);//能够自动解决虚假唤醒问题,返回的是剩余时间} catch (InterruptedException e) {e.printStackTrace();}}//获取队列头元素并返回T t =queue.removeFirst();fuulWaitSet.signal();return t;}finally {lock.unlock();}}// 阻塞获取public T take(){lock.lock();try {while(queue.isEmpty()){try {emptyWaitSet.await();} catch (InterruptedException e) {e.printStackTrace();}}//获取队列头元素并返回T t =queue.removeFirst();fuulWaitSet.signal();return t;}finally {lock.unlock();}}//阻塞添加public void put(T element){lock.lock();try{while(queue.size()==capcity){try {fuulWaitSet.await();} catch (InterruptedException e) {e.printStackTrace();}}queue.addLast(element);emptyWaitSet.signal();}finally {lock.unlock();}}//带超时时间的阻塞添加public boolean offer(T task, long timeout, TimeUnit timeUnit){lock.lock();try {long nanos = timeUnit.toNanos(timeout);while (queue.size()==capcity){try {nanos = fuulWaitSet.awaitNanos(nanos);} catch (InterruptedException e) {e.printStackTrace();}}queue.addLast(task);emptyWaitSet.signal();}finally {lock.unlock();}}//获取大小,当然这里可以不加锁,完全只读public int size(){lock.lock();try {return queue.size();}finally {lock.unlock();}}public void tryPut(RejectPolicy<T> rejectPolicy, T task){lock.lock();try {//判断队列是否为满if(queue.size()==capcity){//传入就好,权力下放给调用者,妙!rejectPolicy.reject(this,task);}else{queue.addLast(task);}}finally {}}}
(附)补充知识-函数式接口与Lambda表达式:
Java8 函数式接口,函数式接口(Functional Interface)是一个有且仅有一个抽象方法,但是可以有多个非抽象方法的接口。
函数式接口可以被隐式转换为lambda表达式。
如下定义了一个函数式接口:
@FunctionalInterfaceinterface GreetingService{void sayMessage(String message);}
接口中只有一个抽象方法,该抽象方法的参数是 String message。
使用Lambda表达式来表示该接口的一个实现类对象:
GreetingService greetService1 = message->System.out.println("hello "+ message);
其中message是待实现方法的参数,当有多个参数时用小括号扩起,->后是方法的实现细节
(附)补充知识-接口实现类对象的快捷创建:
与函数式接口+lambda表达式的用法类似,当需要快捷创建一个接口的实现类对象时,无需先定义接口实现类,接着再new impl()对象,而可以直接使用如下语法:
new interface (){// 接口实现类细节...@Override// 实现方法...}
示例代码:
public class TestInterfaceImpl {public static void main(String[] args) {Animal animal = new Animal() {@Overridepublic void run() {System.out.println("I am a dog and I can fly");}};}}interface Animal{void run();}

若有收获,就点个赞吧
0 人点赞
