4.1 ReentrantReadWriteLock
多个线程读一份共享变量不涉及线程安全问题,只有读写交替才会可能产生问题。当读操作远远高于写操作时,这时使用 读写锁 让 读-读 可以并发,提高性能。类似数据库中的共享锁,select … from … lock in share mode.
提供一个 数据容器类 内部分别使用读锁保护数据的 read() 方法,写锁保护数据的 write() 方法
import java.util.concurrent.locks.ReentrantReadWriteLock;public class ReadAndWriteTest {public static void main(String[] args) {// 多个线程使用同一个dataContainer对象中的lock锁,这样才会实现互斥阻塞DataContainer dataContainer = new DataContainer();new Thread(()->{dataContainer.read();},"t1").start();new Thread(()->{dataContainer.read();},"t2").start();}}class DataContainer{private Object data;private ReentrantReadWriteLock lock = new ReentrantReadWriteLock();private ReentrantReadWriteLock.ReadLock r = lock.readLock();private ReentrantReadWriteLock.WriteLock w = lock.writeLock();public Object read(){System.out.println("获取读锁");r.lock();try {System.out.println("读取锁");Thread.sleep(1000);return data;} catch (InterruptedException e) {e.printStackTrace();} finally {System.out.println("释放读锁");r.unlock();}}public void write(){System.out.println("获取写锁");w.lock();try{System.out.println("写入");}finally {System.out.println("释放写锁");w.unlock();}}}
read()方法读取数据,write()方法写入数据,多线程编程思路下,方法可能被多个线程调用,所以write方法加写锁,read方法加读锁。
经测试,加读锁与写锁后,多线程可以读-读 ,但 读-写,写-写 均受到限制。
总结:读-读并发可以,读-写、写-写并发不可以
注意事项
- 读锁不支持条件变量
- 重入时升级不支持:即对于同一个线程,持有读锁的情况下去再去获取写锁,会导致获取写锁永久等待;升级是指,写锁等级高于读锁
- 重入时降级支持:即持有写锁的情况下获取读锁是成立的,可理解为,拿到写的权力当然可以行使读的权力;
*读写锁应用之缓存
应用场景:当需要数据时,要从数据库中获取数据。如果每次获取的数据相同,或者相同的sql语句频繁执行,从数据库中取不是一个较好的方式。可以考虑增加缓存,如果缓存中有则从缓存中取即可;如果缓存没有,再从数据库中取出,并存放进缓存;当向数据库中执行插入等操作时,清空缓存,直接向数据库中更新,防止缓存数据与数据库数据不一致。
上述应用场景对应的框架为:Redis,实现代码如下:
//装饰器模式,将待装饰的对象作为属性传入,套一层外壳。类似service、daopublic class GenericDaoCached extends GenericDao{private GenericDao dao = new GenericDao();//定义缓存Mapprivate Map<SqlPair,Object> map = new HashMap<>();@Overridepublic <T> T queryOne(Class<T> beanClass,String sql,Object ... args){// 先从缓存中找,找到直接返回SqlPair key = new SqlPair(sql,args);T value = (T)map.get(key);if(value!=null){return value;}// 缓存中没有,查询数据库T t = dao.queryOne(beanClass,sql,args);map.put(key,value);return value;}@Overridepublic int update(String sql,Object... args){//清空缓存,再去修改,否则会使得缓存中数据版本与数据库中数据版本不一致map.clear();return dao.update(sql,args);}//内部类class SqlPair{private String sql;private Object[] args;public SqlPair(String sql,Object[] args){this.sql = sql;this.args = args;}// SqlPair对象需要作为Map的key值,故需要重写hashCode、equals方法@Overridepublic boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;SqlPair sqlPair = (SqlPair) o;return Objects.equals(sql, sqlPair.sql) && Arrays.equals(args, sqlPair.args);}@Overridepublic int hashCode() {int result = Objects.hash(sql);result = 31 * result + Arrays.hashCode(args);return result;}}}
其中使用内部类SqlPair是常见写法,GenericDaoCached extends GenericDao,继承GenericDao类并对其封装,涉及设计模式中的装饰器模式。定义的Map集合对象用以实现缓存功能。
问题分析:
1、集合对象map是属于线程不安全对象,queryOne与update方法均涉及对map的读写操作,多线程环境下,会产生线程安全问题。
2、queryOne方法中,如果缓存为空(刚启动情形),多线程还是会执行dao.queryOne方法,这一步使得缓存的设置在多线程环境下变得无意义。
@Overridepublic <T> T queryOne(Class<T> beanClass,String sql,Object ... args){// 先从缓存中找,找到直接返回SqlPair key = new SqlPair(sql,args);T value = (T)map.get(key);if(value!=null){return value;}// 缓存中没有,查询数据库T t = dao.queryOne(beanClass,sql,args);map.put(key,value);return value;}
3、缓存更新策略存在问题
先清缓存
B线程执行update操作,A线程执行queryOne操作,由于无锁保证原子性,所以可能会产生方法间指令交错问题。如下所示,线程B清空缓存,这时发生线程上下文切换,线程A开始查询数据库,由于缓存被清空,线程B只能从数据库中查询旧值,并将查询到的旧值放入缓存中。线程切换回来,线程A将新数据存入数据库中,但由于缓存中存在数据,之后的查询均要从缓存中查询数据,可悲的是缓存中存放的是旧值,出大问题!
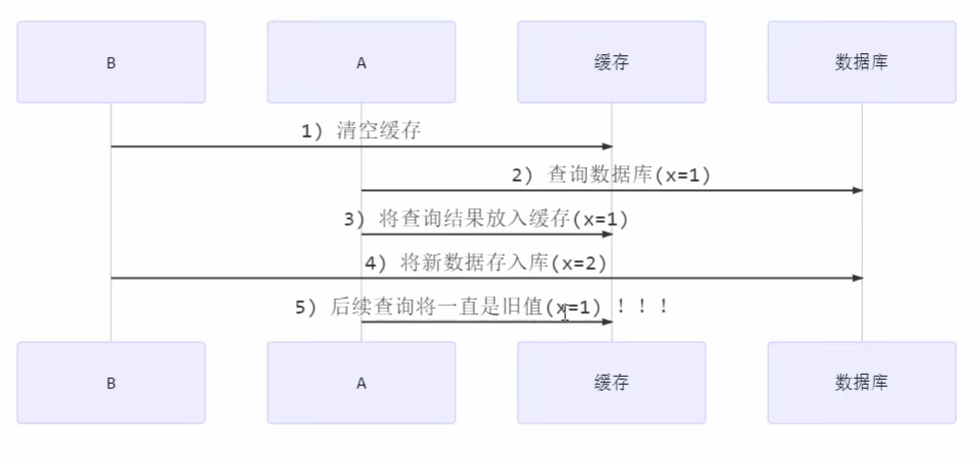
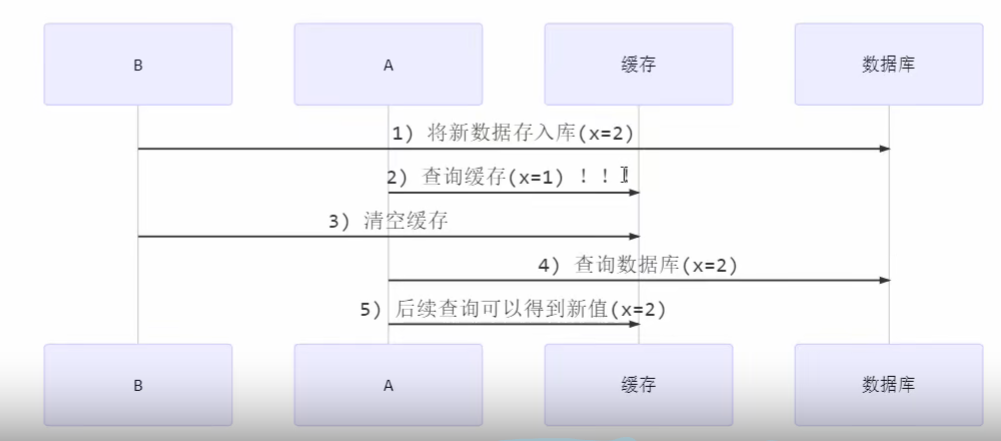
先更新数据库
改用先更新数据库再清空缓存,B线程将新数据存入库中后。线程上下文切换,A线程从缓存中查询到旧值,但旧值只存在一段时间,线程再切换,B线程清空缓存,A线程再查询数据则是从数据库中查询新值,因为此时缓存已经清空。此种方法虽然存在错误,但只是瞬间的数据不一致。此种方法比”先清缓存”的更新策略好些。

若有收获,就点个赞吧
0 人点赞
