1 主要应用场景
1.1 日志类
日志类,主要特点是不会数据修改,有冷热特性,需要分词模糊匹配,数据量也是从几十亿到千亿数据,很适合用ES存储查询。
按天建索引,冷热分离,标准分词。例如云日志,安全访问日志等。
1.2 时序监控类
时序监控类,ES做为时序数据库使用,特点也是数据不会修改,主要查询聚合指标,较少查询明细。
按天建索引,定时rollup, 存储聚合后的值。例如物联网设备上传指标,访问接口调用量,响应时间聚合指标等。
1.3 业务搜索类
业务搜索类,主要特点是,近实时,多条件组合查询,有些字段需要分词,建索引,数据可能会进行多次修改,需要较低的响应时间一般,秒级以下,数据量在几千万到上百亿不等。
数据量大,推荐按业务时间进行分区,业务时间保持不变,定期清理过期数据。 保证数据的版本一致性,可以指定Version版本写入。
运单,订单类,地址分词类,库存类,促销折扣,路由信息,用户画像信息等。
2 其他组件的对比
2.1 mysql
传统的关系型数据库,严格的原子性,事务性,实时。数据量级从几万到千万,再往上,需要分库分表,通过数据主从备份,解决安全问题,数据库代理中间件,解决单点故障及查询分发结果汇总。
mysql VS elasticsearch
事务性: mysql 有事务,严格的原子性,es有version实现乐观锁,但没事务。实时性:mysql 实时,es近实时(最小1秒)。数量级: mysql 几万到千万,ES 千万到百亿。
数据量小(几千-几十万),没有like模糊查询,或需要事务,推荐mysql数据库。
2.2 hbase
一个分布式的、面向列的开源数据库, 底层存储主要为分布式文件系统(hdfs等),数量级为几亿到千亿,支持多版本及时间搓TTL(自动过期数据清理)。
非常适合,高并发,响应时间低(几毫秒), 主键(key-value)查询场景。需要注意的,主键rowkey设计,防止数据倾斜,不均衡。
hbase VS elastic
都是适合上亿级别数据的查询处理,主要区别是key-value查询hbase, 多条件组合查询ES
2.3 clickhouse
ClickHouse是近年来备受关注的开源列式数据库,主要用于数据分析(OLAP)领域。目前国内社区火热,各个大厂纷纷跟进大规模使用。也是不支持事务,写少读多,不修改数据,或少量修改数据的场景,数据量级也是几亿到千亿级别。非常适合数据分析(聚合查询场景)。
clickhouse VS elastic
大数据下的聚合分析查询clickhouse较优,多条件组合查询,需要数据修改,更多的是明细查询业务搜索场景推荐ES
3 ES架构解析
3.1 ES 基础概念
节点(Node)
运行了单个实例的ES主机称为节点,它是集群的一个成员,可以存储数据、参与集群索引及搜索操作。
集群(cluster)
多个节点(Node),构成集群,为了实现容错和高可用性,大数据量读写。
分片(Shard)
ES的“分片(shard)”机制可将一个索引内部的数据分布地存储于多个节点,每一个物理的Lucene索引称为一个分片(shard)。这样的好处是可以把一个大的索引拆分成多个,分布到不同的节点上。降低单服务 器的压力,构成分布式搜索,提高整体检索的效率
副本(Replica)
副本是一个分片的精确复制,每个分片可以有零个或多个副本。副本的作用一是提高系统的容错性,当某个节点某个分片损坏或丢失时可以从副本中恢复。二是提高es的查询效率,es会自动对搜索请求进行负载均衡。
3.2 ES 数据架构
索引(index)
ES将数据存储于一个或多个索引中,索引是具有类似特性的文档的集合。类比传统的关系型数据库领域来说,索引相当于SQL中的一个数据库表(2.2之前喜欢类比为库, 不是太合理,6以上已经慢慢取消 type)。
类型(Type)
类型是索引内部的逻辑分区(category/partition),然而其意义完全取决于用户需求。类型将在Elasticsearch 7.0.0中的API中弃用,并在8.0.0中完全删除。
文档(Document)
文档是Lucene索引和搜索的原子单位,它是包含了一个或多个域的容器,基于JSON格式进行表示。文档由一个或多个域组成,每个域拥有一个名字及一个或多个值。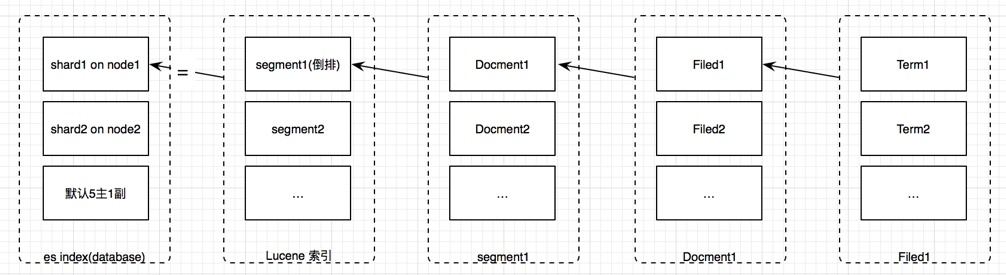
3.3 ES 写流程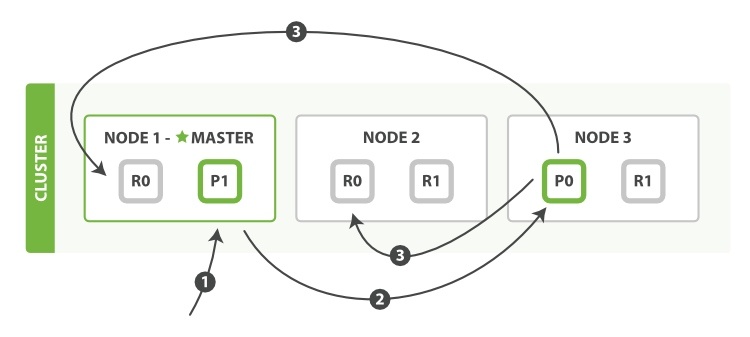
PUT 数据请求会发发送到集群的其中一个节点,节点会分析请求,没有id会自动构建Id, 没有指定route的情况下,会根据id进行hash 获取到具体分片,根据路由信息,请求会转发到分片节点,
主分片节点(版本6以上会生成sequence no), 再写数据,写完后转发请求到副本节点,多副本并行操作,全部写入完返回结果给客户端。
更新不会修改原来的 segment,更新和创建操作都会生成新的一个 segment。先会存在内存的 bugger 中,然后持久化到 segment 。
数据持久化步骤如下:write -> refresh -> flush -> merge
3.4 ES 读流程
ES 读取过程主要依赖lucene的文档搜索功能,ES汇聚查询的结果,主要流程:
search 阶段,向所有满足条件的index shard 发送请求,匹配排序,(GET查询,能通过id计算出所属分片,不需要每个分片去查询)。
fetch 阶段,根据search返回的数据,获取前面top n id,然后再向具体的节点,fetch具体的source
注意为什么不推荐深度分页,假如20分片,第一次请求0-10,那每个分片只需要返回10条,总共1020=200条,取top 10。如果深度分页 990-1000, 那每个分片需要返回1000条,总共201000,取top 1000,再分页取990-1000。

若有收获,就点个赞吧
0 人点赞
