一、概述
1、ES简介以及发展历史
Search is something that any application should have
1.1、ES应用领域
- 订单搜索
- 商品推荐
- 集中化日志管理
- 风险控制
- IT运维
- 安全监控
开源分布式搜索分析引擎,基于Lucene引擎。
Lucene具有高性能、易扩展的优点
Lucene的局限性:
- 只能基于java开发
- 类库的接口学习曲线陡峭
- 原生不支持水平扩展
2004基于Lucene开发了Compass
2010重写了Compass取名为ElasticSearch
- 支持分布式,可水平扩展
- 降低全文搜索的学习曲线,可以被任何编程语言使用
支持多种方式集成接入
多种编程语言的类库(java/,NET/Python/Ruby/PHP/Groovy/Perl)
Restful API
JDBC&ODBC
1.2、Elasticsearch 的主要功能
- 海量数据的分布式存储以及集群管理
- 近实时搜索,性能卓越
-
1.3、ElasticSearch版本特性
新特性5.X版本
1、Lucene 6.X,性能提升,默认打分机制从TF-IDF改为BM25
2、支持Ingest节点/Painless Scripting/Completion suggested 支持/原生的Java REST客户端
3、TYPE标记成deprecated,支持了Keyword类型
4、性能优化 内部引擎移除了避免同意文档并发更新的竞争锁,带来15%-20%的性能提升
- Instant aggregation,支持分片上聚合的缓存
-
新特性6.X版本
1、Lucene 7.X
2、新功能(跨集群复制CCR、索引生命周期管理、SQL的支持)
3、更友好的升级及数据迁移
4、性能优化 有效存储稀疏字段的新方法,降低了存储成本
-
新特性7.X版本
1、Lucene 8.0
2、重大改进——正式废除一个索引下多个Type的支持
3、7版本开始有安全认证Security功能
4、ECK——Elasticsearch Operator On Kubernetes
5、新功能 New Cluster coordination
- Feature——Complete High Level REST Client
- Script Score Query

6、性能优化
- 默认的主分片数从5该为1,避免over sharding
- 性能优化,更快的TOP K
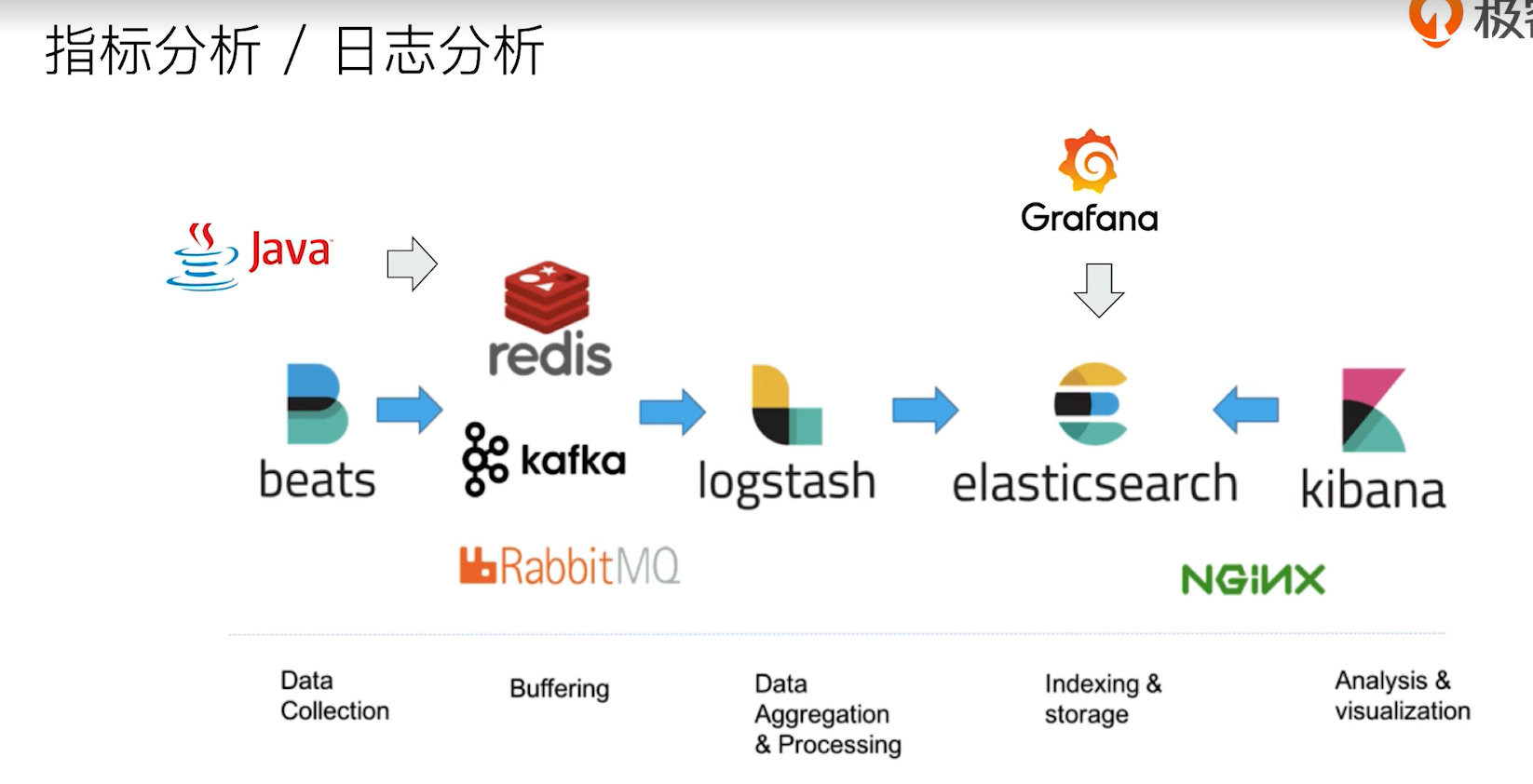
2、Elastic Stack家族成员及其应用
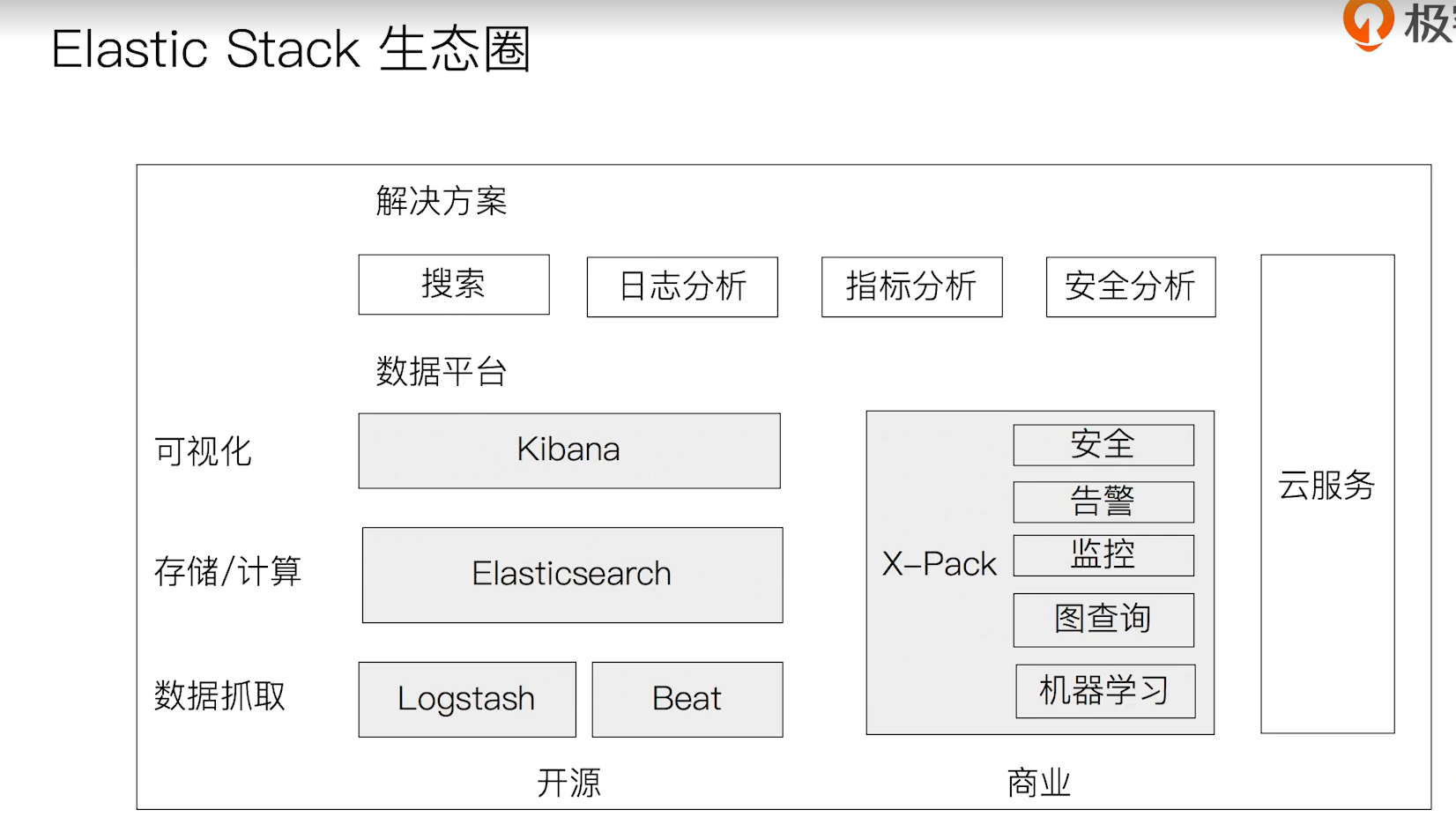
Logstash:开源的服务器端数据处理管道,支持从不通来源采集数据,转换数据,并将数据发送到不通的存储库中
kibana:可视化分析利器,Kiwifruit+Banana
Beats:轻量的数据采集器
X-Pack:商业化套件
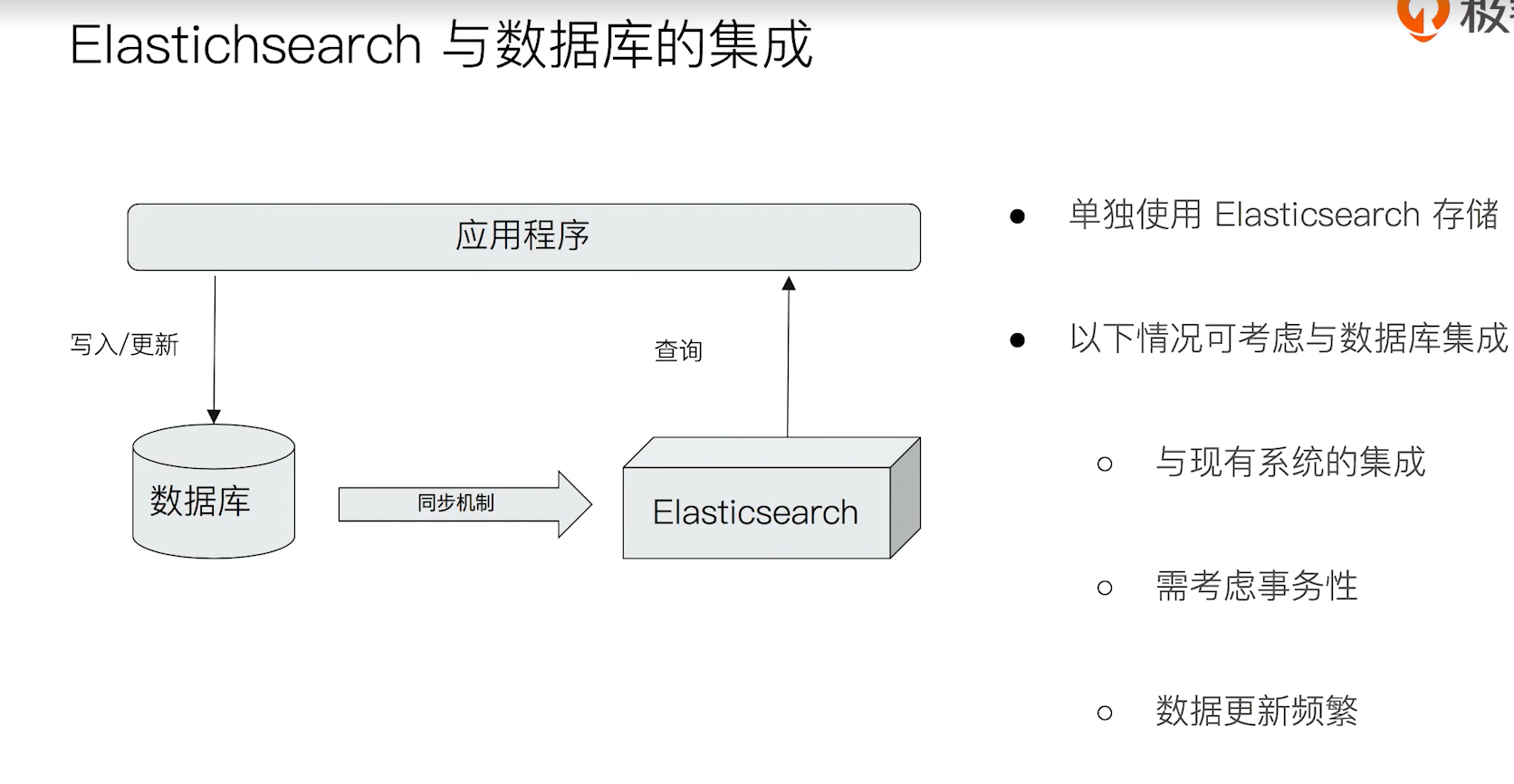
二、安装上手
1、Es的安装与简单配置
es的相关目录结构
| 目录 | 配置文件 | 相关描述 |
|---|---|---|
| bin | 脚本文件,启动es,安装插件,运行统计数据等 | |
| config | elasticsearch.yml | 集群配置文件 |
| JDK | java运行环境 | |
| data | path.data | 数据文件 |
| lib | java类库 | |
| logs | path.log | 日志文件 |
| modules | 包含所有es模块 | |
| plugins | 包含所有已安装插件 |
JVM配置
修改jvm-jvm.options
- xmx和xms设置程一样的
- xmx不要超过内存的50%
- 不要超过30GB
三、ElasticSearch入门
1、基本概念:索引、文档和RESTAPI
1.1、文档
Elasticsearch是面向文档的,文档是所有可搜索数据的最小单位
eg:日志中的日志项、一部电影的具体信息
文档会序列化成json格式,保存在es中,json对象由字段组成、每个字段都有对应的字段类型
每个文档都有一个唯一id(可以指定ID,或者es自动生成)
文档的元数据:用于标注文档的相关信息
- _index:文档所属的索引名
- _type:文档所属的类型名
- _id:文档唯一ID
- _source:文档的原始json数据
- _all:整合所有字段内容到该字段,已被废除
- _version:文档的版本信息
- _score:相关性打分
{"_index" : "myindex","_type" : "_doc","_id" : "4WPt6nwBm15aYb-7A4VW","_score" : 1.0,"_source" : {"id" : 1,"name" : "wayne"}}
1.2、索引
Index索引是文档的容器,是一类文档的结合
index体现了逻辑空间的概念,每个索引都有自己的mapping,用于定义包含的文档字段名和字段类型
Shard体现了物理空间的概念,索引中的数据分散在shard上
索引的mapping设置字段的映射关系,setting设置不同的数据分布
索引的不同语义GET /myindex?pretty{"myindex" : {"aliases" : { },"mappings" : {"properties" : {"id" : {"type" : "long"},"name" : {"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}}}},"settings" : {"index" : {"creation_date" : "1636028973699","number_of_shards" : "1","number_of_replicas" : "1","uuid" : "zJSEZbokTEWQ3rcxcEagUw","version" : {"created" : "7060099"},"provided_name" : "myindex"}}}}
名词:一个es集群中,可以创建很多个不同的索引
动词:保存一个文档到es集群的索引中的这个过程
抽象和类比
| RDBMS | ElasticSearch |
|---|---|
| table | index |
| row | doc |
| colounm | filed |
| schema | mappig |
| sql | dsl |
1、在7.0版本之前,一个index可以设置多个type
2、目前Type已经被废弃,现在一个索引只能建一个type “_doc”
3、传统关系型数据库和es的区别
es —Schemaless/相关性/高性能全文检索
rdms—事务性/Join
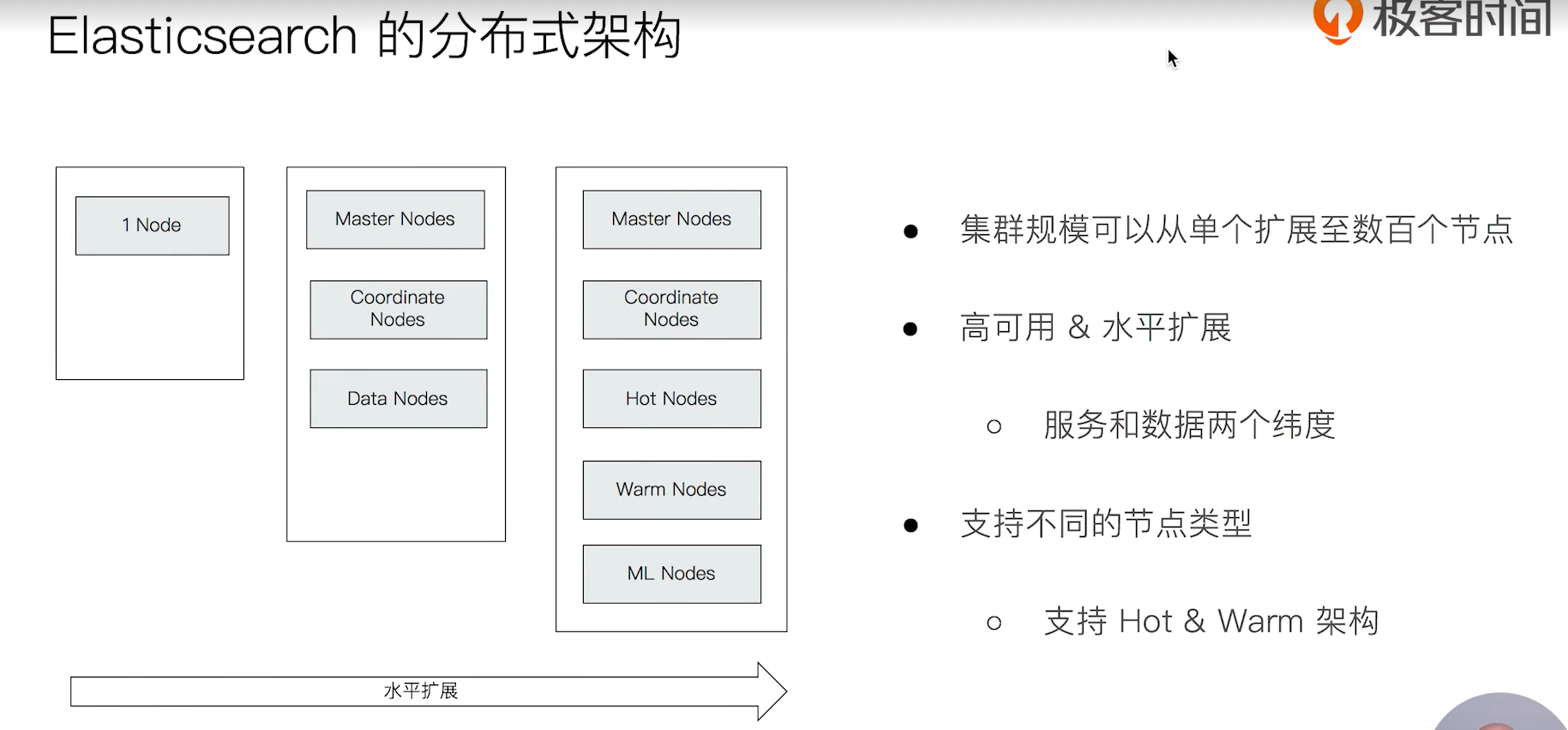
2、基本概念:节点、集群、分片及副本

若有收获,就点个赞吧
0 人点赞
