⚫ 垂直拆分
➢ 场景
在业务系统中, 涉及以下表结构 ,但是由于用户与订单每天都会产生大量的数据, 单台服务器的数据存储及处理能力是有限的, 可以对数据库表进行拆分, 原有的数据库表如下。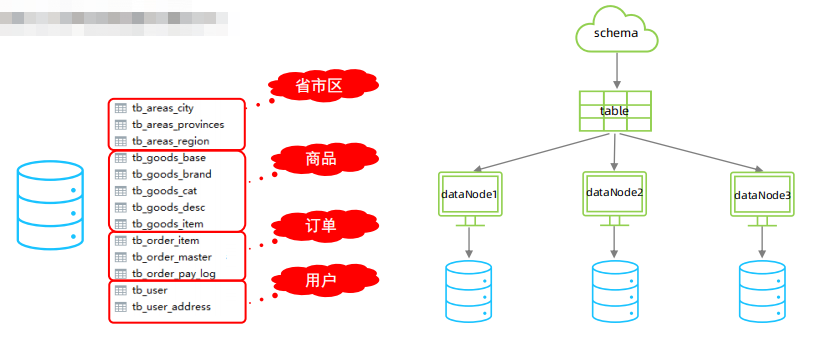
⚫ 垂直拆分
➢ 准备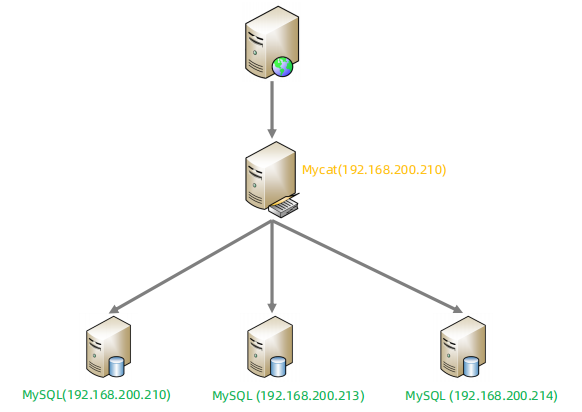
分别在三台MySQL中创建数据库 shopping。
⚫ 垂直拆分
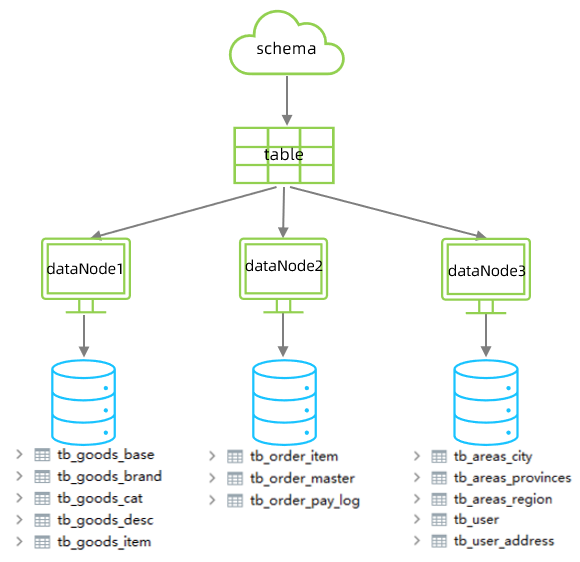
➢ 配置(schema.xml )
➢ 测试
在mycat的命令行中,通过source指令导入表结构,以及对应的数据,查看数据分布情况。
source /root/shopping-table.sql
source /root/shopping-insert.sql
查询用户的收件人及收件人地址信息(包含省、市、区)。
select ua.user_id, ua.contact, p.province, c.city, r.area, ua.address
from
tb_user_address ua, tb_area_city c, tb_areas_provinces p, tb_areas_region r
where
ua.province_id = p.province
and
ua.city_id = c.cityid
and
ua.town_id = r.areaid;
查询每一笔订单及订单的收件地址信息(包含省、市、区)。
SELECT order_id,payment,reciver,province,city,area
FROM
tb_order_master o,tb_areas_provinces p,tb_areas_city c,tb_areas_region r
WHERE
o.receiver_province = p.provinceid
and
o.receiver_city = c.cityid
and
o.receiver_region =r.areaid;
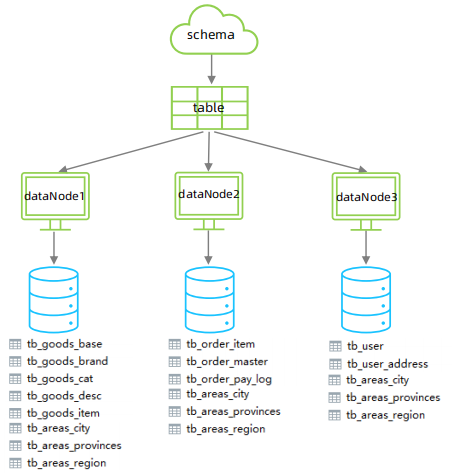
➢ 全局表配置
对于省、市、区/县表tb_areas_provinces , tb_areas_city , tb_areas_region,是属于数据
字典表,在多个业务模块中都可能会遇到,可以将其设置为全局表,利于业务操作。 
⚫ 水平拆分
➢ 场景
在业务系统中, 有一张表(日志表), 业务系统每天都会产生大量的日志数据 , 单台服务器的数据存储及处理能力是有限的, 可以对数据库表进行拆分。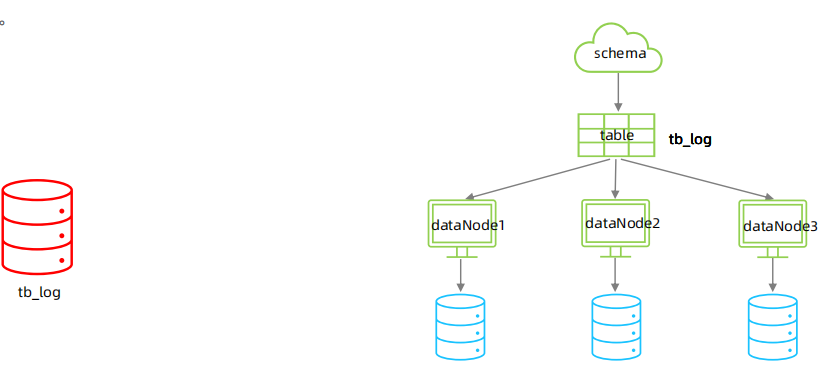
➢ 准备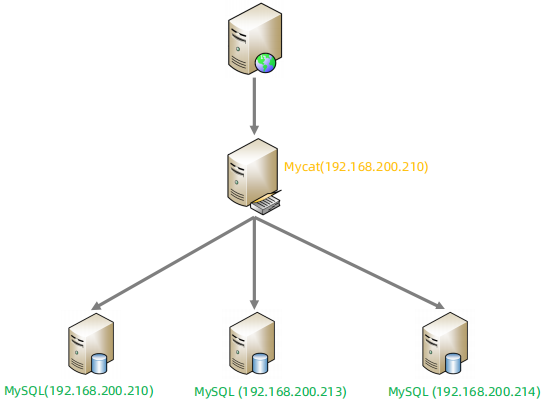
分别在三台MySQL中创建数据库 mycat_test。
➢ 配置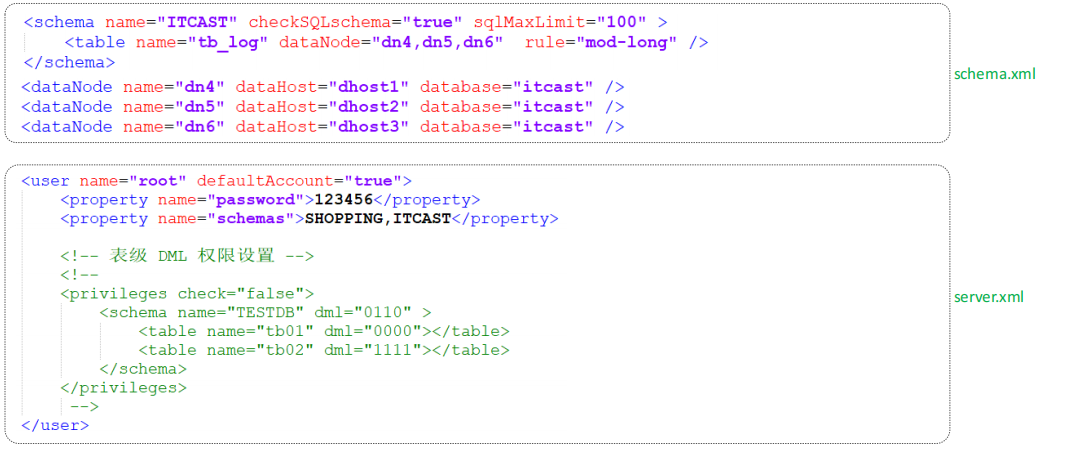
➢ 测试
在mycat的命令行中,执行如下SQL创建表、并插入数据,查看数据分布情况。
CREATE TABLE tb_log(
id bigint(20)NOT NULL COMMENT ‘ID’,
model_name varchar(200) DEFAULT NULL COMMENT’模块名’,
model_value varchar(200) DEFAULT NULL COMMENT ‘模块值,
return_valuevarchar(200)DEFAULT NULL COMMENT ‘返回值”,
return_class varchar(200)DEFAULT NULL COMMENT’返回值类型”,
operate_uservarchar(20) DEFAULT NULL COMMENT ‘操作用户’,
operate_timevarchar(20) DEFAULT NULL COMMENT’操作时间’,
param_and_value varchar(500) DEFAULT NULL COMMENT’请求参数名及参数值’,
operate_classvarchar(200) DEFAULT NULL COMMENT ‘操作类’,
operate_method varchar(200) DEFAULT NULL COMMENT ‘操作方法”,
cost_time bigint(20) DEFAULT NULL COMMENT ‘执行方法耗时,单位ms’,
source int(1) DEFAULT NULL COMMENT ‘来源:1 PC , 2 Android , 3 IOS’,PRIMARY KEY (id)
)ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
⚫ 分片规则-范围
根据指定的字段及其配置的范围与数据节点的对应情况, 来决定该数据属于哪一个分片。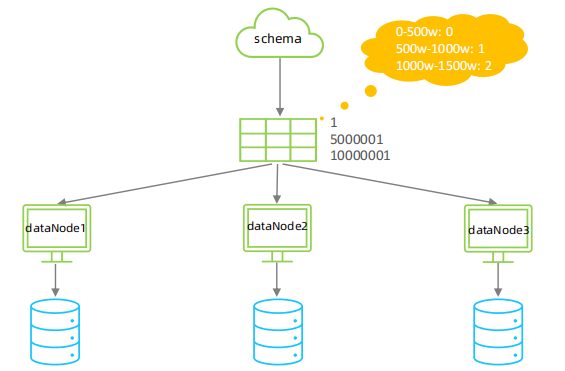
⚫ 分片规则-范围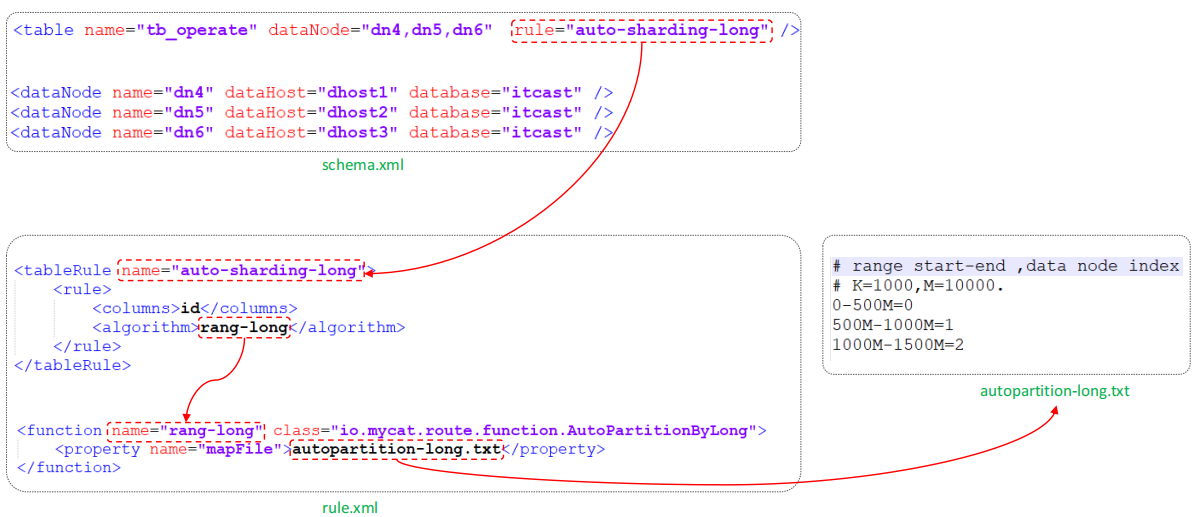
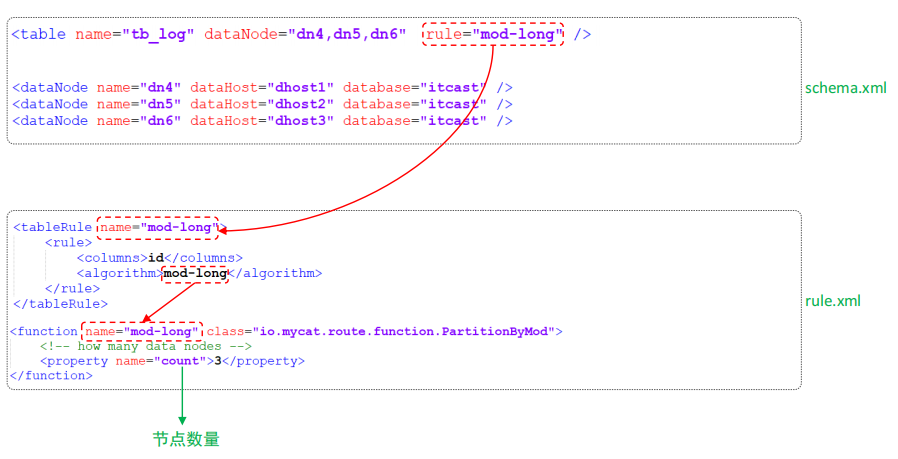
⚫ 分片规则-取模
根据指定的字段值与节点数量进行求模运算,根据运算结果, 来决定该数据属于哪一个分片。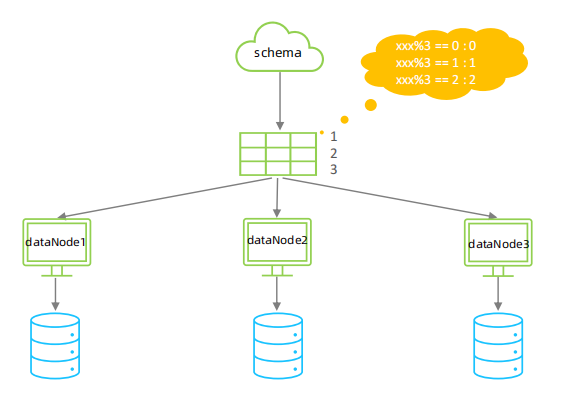
⚫ 分片规则-一致性hash
所谓一致性哈希, 相同的哈希因子计算值总是被划分到相同的分区表中,不会因为分区节点的增加而改变原来数据的分区位置。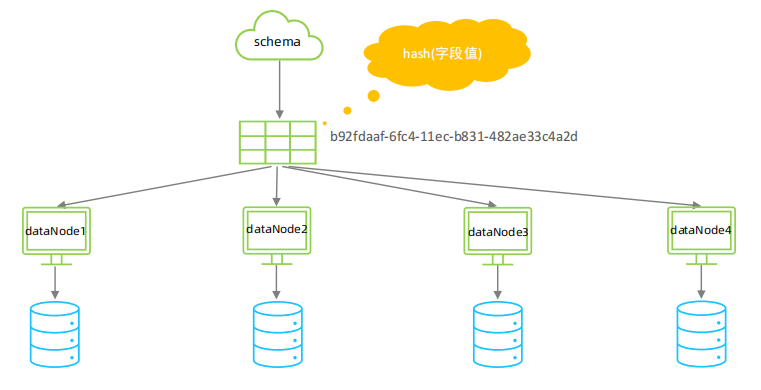
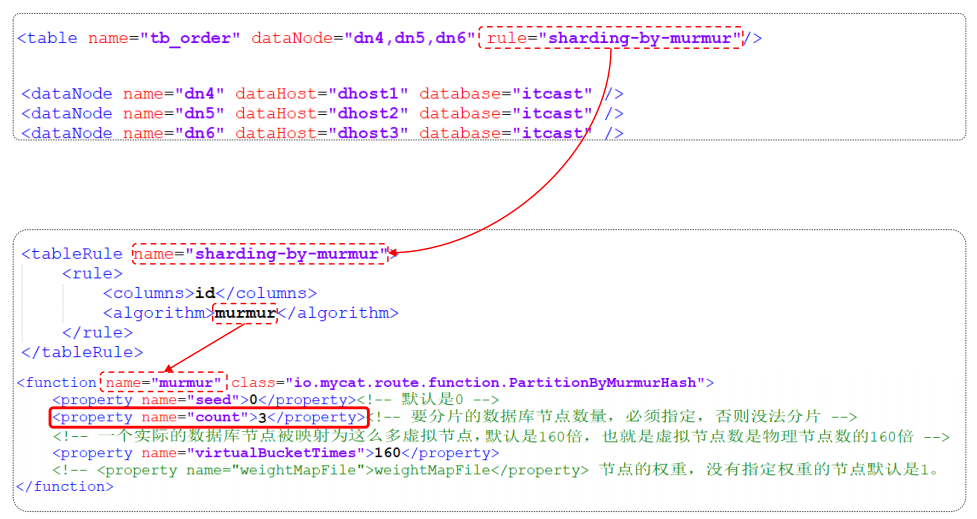
⚫ 分片规则-枚举
通过在配置文件中配置可能的枚举值, 指定数据分布到不同数据节点上, 本规则适用于按照省份、性别、状态拆分数据等业务 。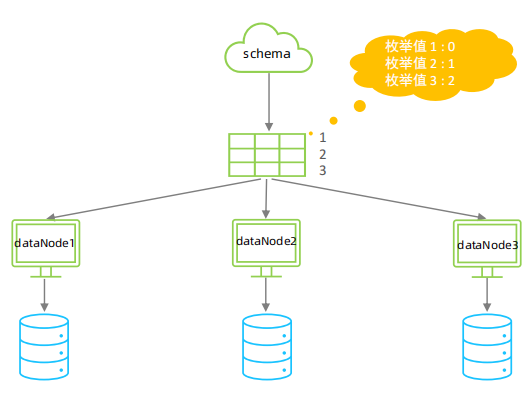
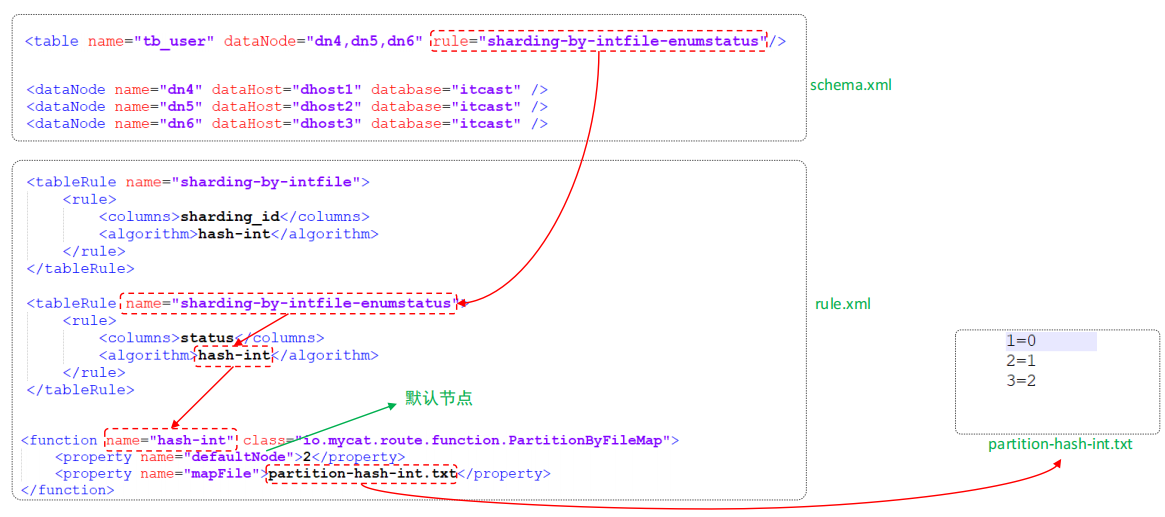
⚫ 分片规则-应用指定
运行阶段由应用自主决定路由到那个分片 , 直接根据字符子串(必须是数字)计算分片号。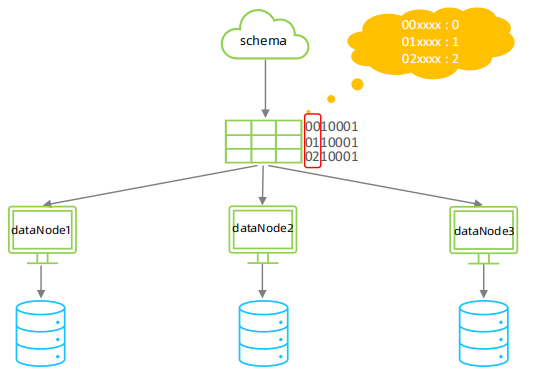

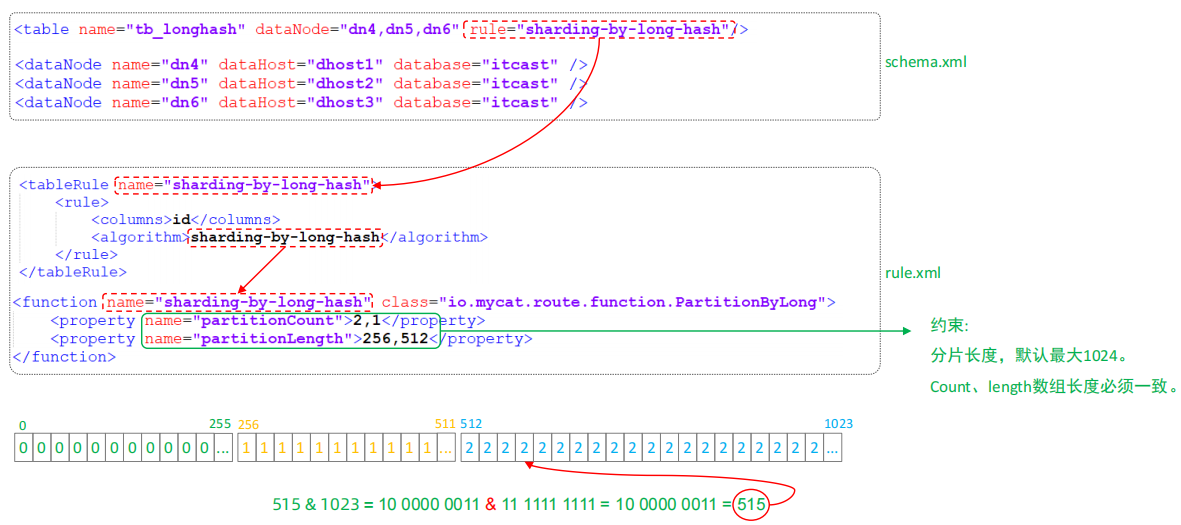
⚫ 分片规则-固定分片hash算法
该算法类似于十进制的求模运算,但是为二进制的操作,例如,取 id 的二进制低 10 位 与 1111111111 进行位 & 运算。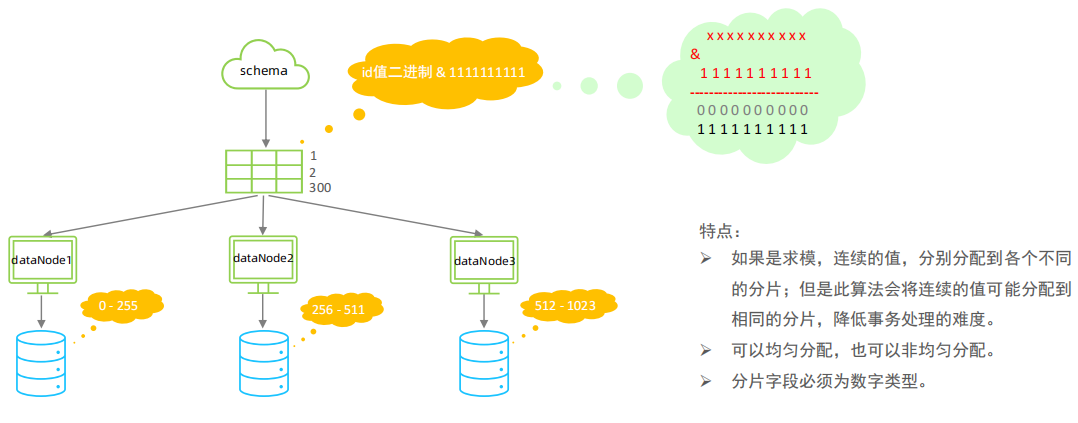
⚫ 分片规则-字符串hash解析
截取字符串中的指定位置的子字符串, 进行hash算法, 算出分片。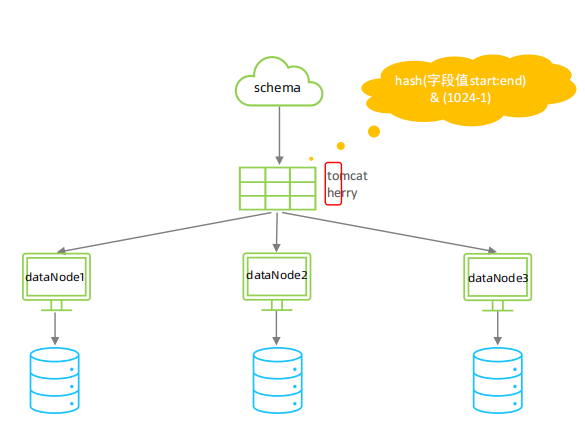
⚫ 分片规则-字符串hash解析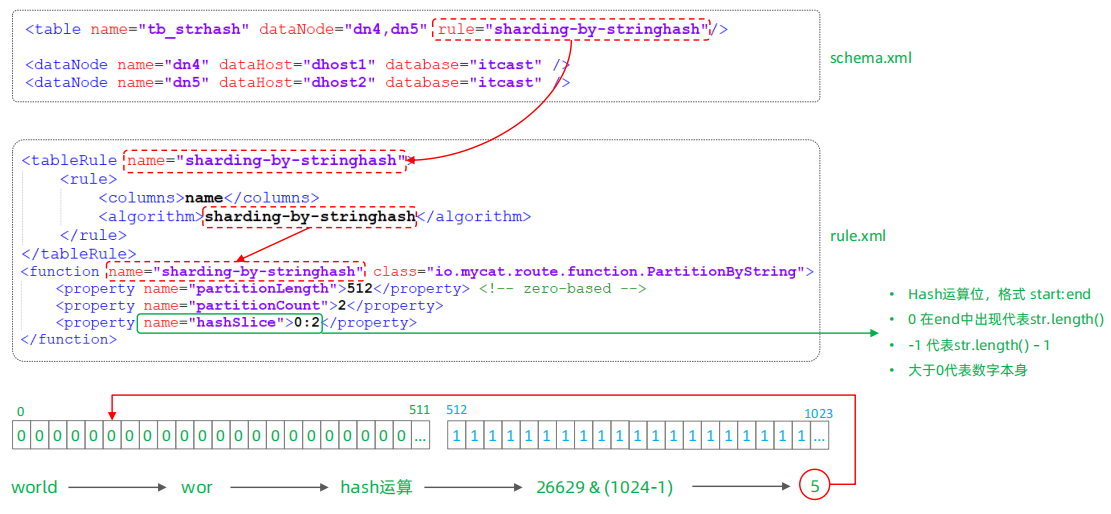
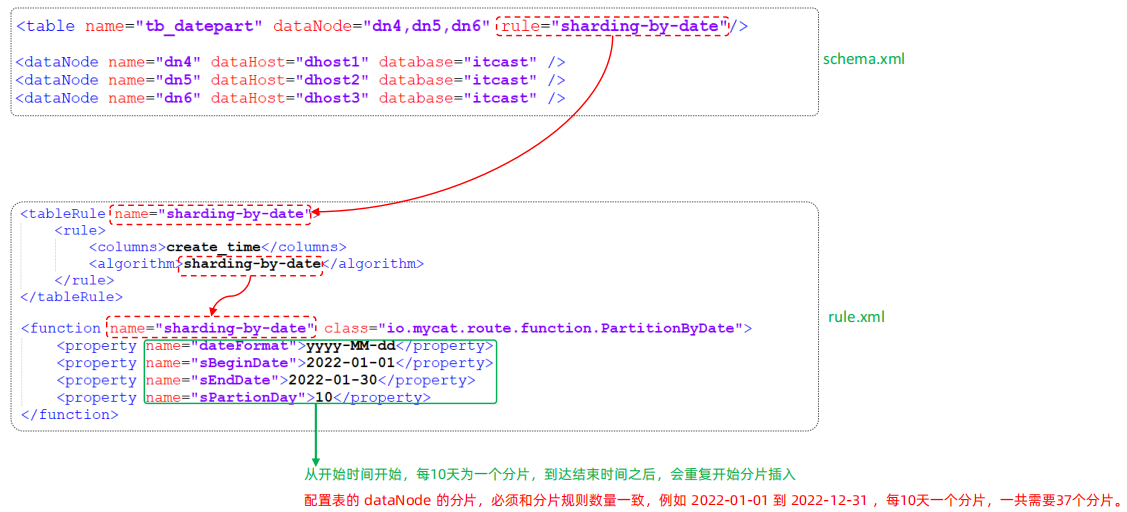
⚫ 分片规则-按(天)日期分片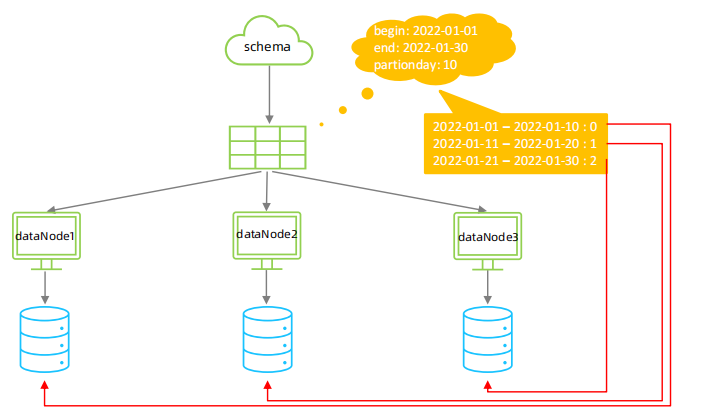
⚫ 分片规则-自然月
使用场景为按照月份来分片, 每个自然月为一个分片。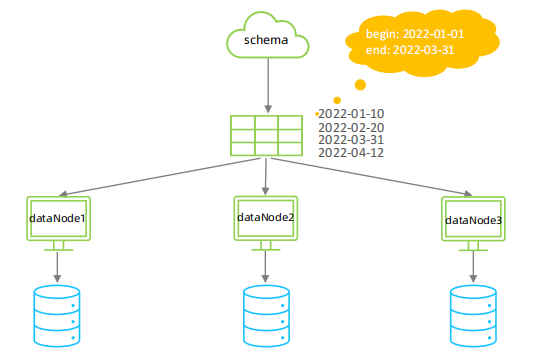


若有收获,就点个赞吧
0 人点赞
