———————————————————创建表结构————————————————————-
CREATE TABLE tb_sku (
id int(11) NOT NULL,
sn varchar(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
name varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
price decimal(10, 2) NULL DEFAULT NULL,
num int(11) NULL DEFAULT NULL,
alter_num int(11) NULL DEFAULT NULL,
image varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
images varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
weight double NULL DEFAULT NULL,
create_time varchar(30) NULL DEFAULT NULL,
update_time varchar(30) NULL DEFAULT NULL,
category_name varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
brand_name varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
spec varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
sale_num int(11) NULL DEFAULT NULL,
comment_num int(11) NULL DEFAULT NULL,
status char(1) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
PRIMARY KEY (id) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
导入1000w数据(由于1000w的数据量较大 , 如果直接加载1000w , 会非常耗费CPU及内存 ; 已经拆分为5个部分 , 每一个部分为200w数据 , load 5次即可 ;)
windows:
load data local infile ‘C:\Users\Allen\Desktop\tb_sku1.sql’ into table tb_sku fields terminated by ‘,’lines terminated by ‘\n’;
如果报Permission denied:secure-file-priv=”/“
Linux:
load data local infile ‘/root/sql/tb_sku1.sql’ into table tb_sku fields terminated by ‘,’ lines terminated by ‘\n’;
⚫ 验证索引效率
在未建立索引之前,执行如下SQL语句,查看SQL的耗时。
SELECT FROM tb_sku WHERE sn=’1000000003145001’
⚫针对字段创建索引
create index idx_sku_sn on tb_sku(sn);
⚫然后再次执行相同的SQL语句,再次查看SQL的耗时。
SELECT FROM tb_sku WHERE sn=’1000000003145001’
(1) 最左前缀法则
如果索引了多列(联合索引),要遵守最左前缀法则。最左前缀法则指的是查询从索引的最左列开始,并且不跳过索引中的列。
如果跳跃某一列,索引将部分失效(后面的字段索引失效)。
(1)EXPLAIN SELECT FROM tb_user WHERE profession =’软件工程师’ and age=’31’ and status=’0’;
(2)EXPLAIN SELECT FROM tb_user WHERE profession =’软件工程师’ and age=’31’ ;
(3)EXPLAIN SELECT FROM tb_user WHERE profession =’软件工程师’ ;
(4)EXPLAIN SELECT FROM tb_user WHERE age=’31’ and status=’0’;
(5)EXPLAIN SELECT * FROM tb_user WHERE status=’0’;
思考:下面的sql语句索引会不会失效?
(1)EXPLAIN SELECT * FROM tb_user WHERE age=’31’ and status=’0’ and profession =’软件工程师’;
(2)范围查询
联合索引中,出现范围查询(>,<),范围查询右侧的列索引失效
EXPLAIN SELECT FROM tb_user WHERE profession =’软件工程师’ and age>’30’ and status=’0’;
EXPLAIN SELECT FROM tb_user WHERE profession =’软件工程师’ and age>=’31’ and status=’0’;
(3)索引列运算
不要在索引列上进行运算操作, 索引将失效
explain select * from tb_user where substring(phone,10,2) =’15’;
(4) 字符串不加引号
字符串类型字段使用时,不加引号, 索引将失效。
EXPLAIN SELECT FROM tb_user WHERE profession =’软件工程师’ and age=30 and status=0;
EXPLAIN SELECT FROM tb_user WHERE phone=17267171393;
(5) 模糊查询
如果仅仅是尾部模糊匹配,索引不会失效。如果是头部模糊匹配,索引失效。
explain select from tb_user where profession like ‘软件%’;
explain select from tb_user where profession like ‘%工程’;
explain select * from tb_user where profession like ‘%工%’;
(6) or连接的条件
用or分割开的条件, 如果or前的条件中的列有索引,而后面的列中没有索引,那么涉及的索引都不会被用到。
explain select from tb_user where id =10 or age =30;
explain select from tb_user where phone =’17267171393’ or age =30;
由于age没有索引,所以即使id、phone有索引,索引也会失效。所以需要针对于age也要建立索引。
(7)数据分布影响
如果MySQL评估使用索引比全表更慢,则不使用索引。
explain select from tb_user where phone >=’17799990020’;
explain select from tb_user where phone >=’17799990000’;
explain select from tb_user where phone >=’17799990010’;
explain select from tb_user where phone >=’17799990015’;
(8)SQL提示
SQL提示,是优化数据库的一个重要手段,简单来说,就是在SQL语句中加入一些人为的提示来达到优化操作的目的。
为profession创建单列索引:create index idx_user_pro on tb_user(profession);
思考:
根据最左前缀法则会用到联合索引,单列索引也满足条件,那么到底会走那个索引呢?
explain select * from tb_user where profession =’软件工程师’
use index:告诉数据库用哪个索引
explain select * from tb_user use index(idx_user_pro) where profession =’软件工程师’
ignore index:告诉数据库不用哪个索引
explain select * from tb_user ignore index(idx_user_pro) where profession =’软件工程师’
force index:告诉数据库必须用哪个索引
explain select * from tb_user force index(idx_user_pro) where profession =’软件工程师’
(9)覆盖索引
尽量使用覆盖索引,减少SELECT *:查询使用了索引,并且需要返回的列,在该索引中已经全部能够找到。
创建了比较多的索引,删除多余索引:
drop index idx_email on tb_user; drop index idx_user_pro on tb_user;
explain select id,profession from tb_user where profession =’软件工程师’ and age =31 and status =’0’;
explain select id,profession,age from tb_user where profession =’软件工程师’ and age =31 and status =’0’;
explain select id,profession,age,status from tb_user where profession =’软件工程师’ and age =31 and status =’0’;
——————————————————————————-
explain select id,profession,age,status,name from tb_user where profession =’软件工程师’ and age =31 and status =’0’;
mysql的版本不一样,Extra展示的信息不一样。以下是8.0以上的版本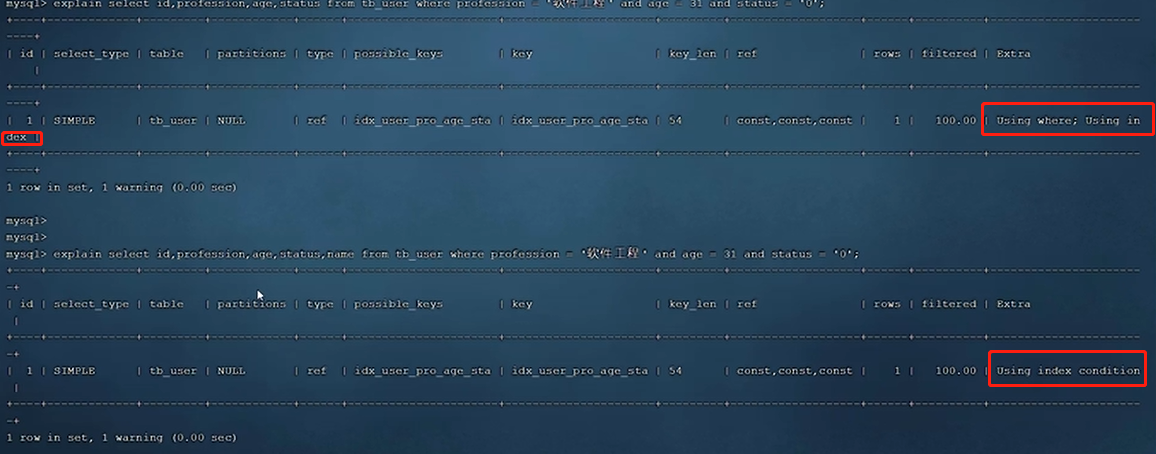
注意:
using index condition :查找使用了索引,但是需要回表查询数据
using where; using index :查找使用了索引,但是需要的数据都在索引列中能找到,所以不需要回表查询数据
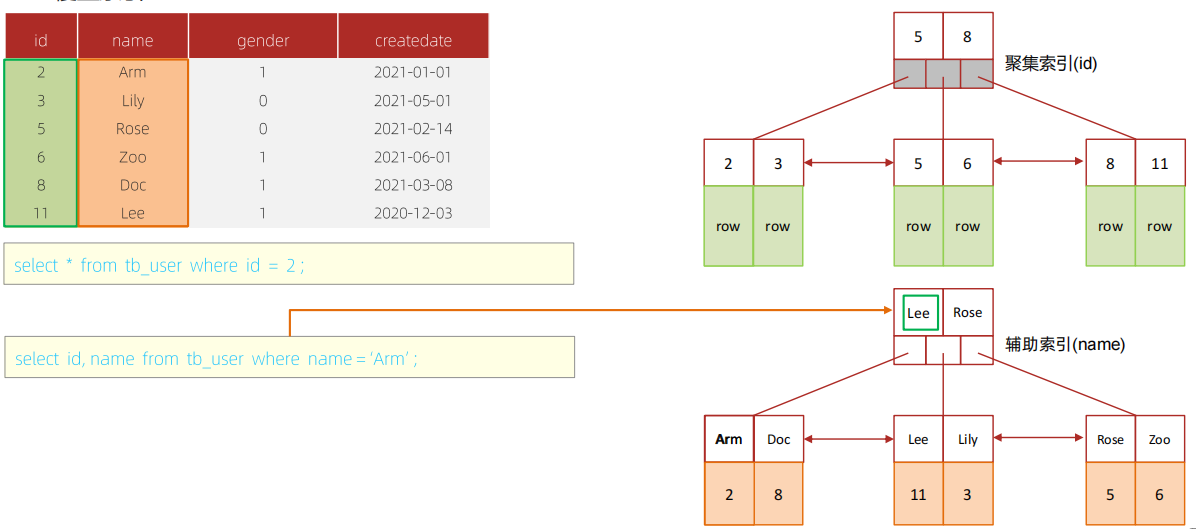
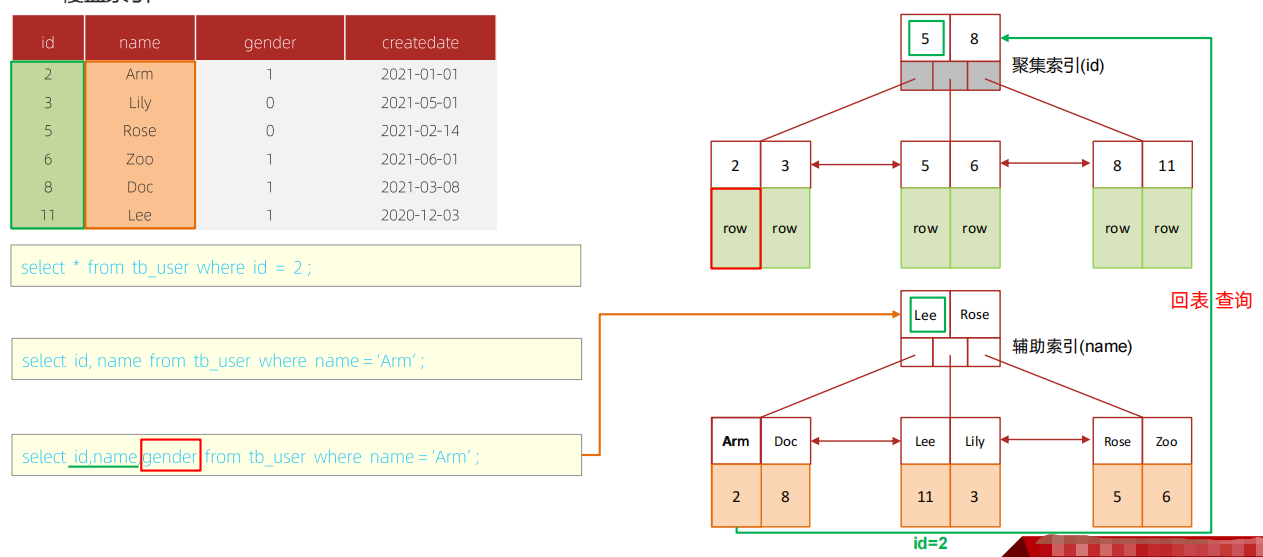
思考:
一张表, 有四个字段(id, username, password, status), 由于数据量大, 需要对以下SQL语句进行优化, 该如何进行才是最优方案:
select id, username, password, status from tb_user where username=’admin’;
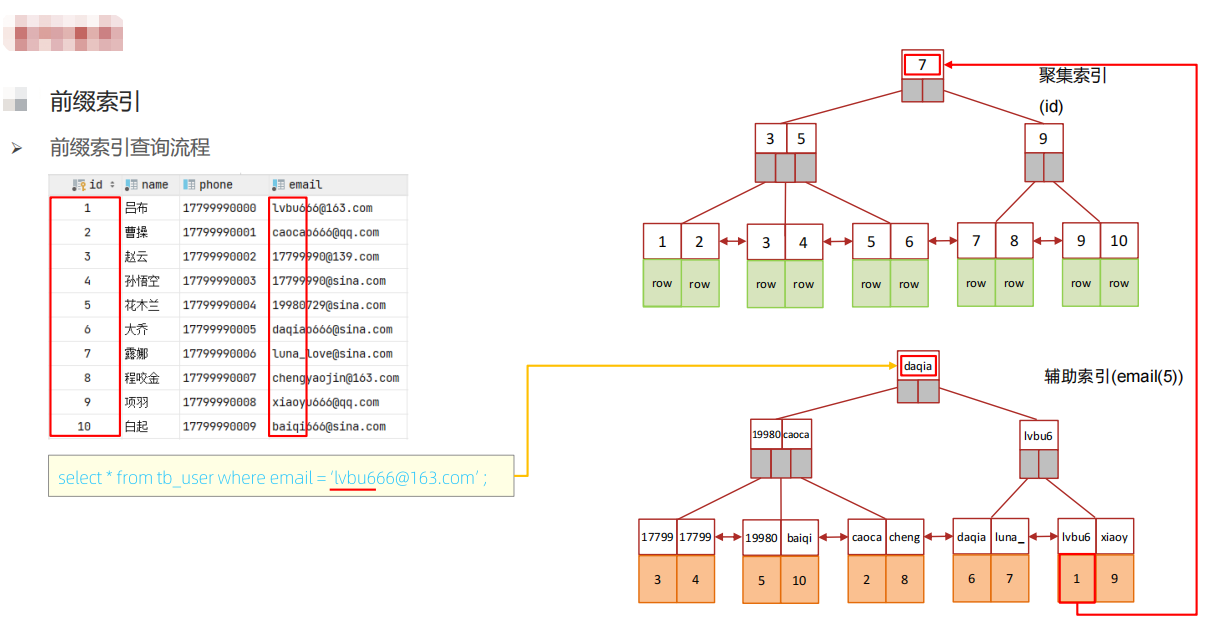
1、前缀索引:
当字段类型为字符串(varchar,text等)时,有时候需要索引很长的字符串,这会让索引变得很大,查询时,浪费大量的磁盘IO, 影响查询效率。此时可以只将字符串的一部分前缀,建立索引,这样可以大大节约索引空间,从而提高索引效率。
➢ 语法:CREATE INDEX idx_xxx ON 表名(column(n)),n代表这个字段的前n个字符作为索引
➢ 前缀长度
可以根据索引的选择性来决定,而选择性是指不重复的索引值(基数)和数据表的记录总数的比值,索引选择性越高则查询效率越高 , 唯一索引的选择性是1,这是最好的索引选择性,性能也是最好的。
例如:
select count(email) from tb_user/count() from tb_user;
select count(distinct email) from tb_user/count() from tb_user;
我们借助两个公式:
select count(distinct email)/count() from tb_user;
select count(distinct substring(email,1,5)/count(*) from tb_user;
— 前五个区分度比较高了
前缀索引的查找流程:
2、单列索引与联合索引
单列索引:即一个索引只包含单个列。
联合索引:即一个索引包含了多个列。
在业务场景中,如果存在多个查询条件,考虑针对于查询字段建立索引时,建议建立联合索引,而非单列索引。
单列索引情况:
explain select id, phone ,name from tb_user where phone =’1779990010’ and name =’韩信’
多条件联合查询时,MySQL优化器会评估哪个字段的索引效率更高,会选择该索引完成本次查询。

若有收获,就点个赞吧
0 人点赞
