第一,能用普通字符串处理的,坚决用普通字符串处理。第二,能写注释的正则表达式,一定要写注释。第三,能用多个简单正则表达式解决的,一定不要苛求一个复杂的正则表达式。
有这样的一个案例: 常见的密码要求“必须包含数字、小写字母、大写字母、特殊符号中的至少两种,且长度在 8 到 16 之间”。我们当然可以实现一个强大的正则可以解决所有问题,也可以将此需求拆解,分别验证每一个条件,这样的方案虽繁琐但是简洁高效。
拆分后的规则校验可以实现如下:
const numberRegx = /[0-9]/; // 校验数字const lowerCaseRegx = /[a-z]/; // 小写字母const upperCaseRegx = /[A-Z]/; // 大写字母const superCharRegx = /[_-]/; // 特殊字符const lengthRegx = /.{8,16}/; // 长度校验/**word 需要校验的字符串 matchNum 需要匹配的规则次数*/function passwordCheck(word='',matchNum=2){let matchRuleFrequency=0;if(!lengthRegx.test(word)){return {result: false,msg: '输入长度不满足要求'};}const baseRule=[numberRegx,lowerCaseRegx,upperCaseRegx,superCharRegx];baseRule.forEach(item=>{if(item.test(word)){matchRuleFrequency++;}})if(matchRuleFrequency>=matchNum){return {result: true,msg: '校验通过'};}else {return {result: false,msg: '密码需要包含大写字母、小写字母、数字和特殊符号中的至少两种'};}}
01 元字符:正则表达式的基础元件
学习正则的一切基础前提是,了解正则的基本构成单元:元字符。
所谓元字符就是那些在正则表达式中表示特定含义的专用字符。
元字符大致分成这几类:

英文的点”.”表示除换行以外的任意单个字符,\d 表示任意单个数字,\w 表示任意数字字母下划线,\s 表示任意空白符。与之相对应的还有 \D、\W 和 \S , \D 表示任意非数字,\W 表示任意非数字字母下划线,\S 表示任意非空白符。
- 元字符 \d 测试用例:https://regex101.com/r/XHpDoS/1
- 元字符 \w 测试用例: https://regex101.com/r/XHpDoS/2
- 元字符 \s 测试用例:https://regex101.com/r/XHpDoS/3
空白符
回车符 \r ,换行符 \n,TAB 制表符 \t 等等,大部分场景使用 \s 就可以满足需求,\s 代表任意单个空白符号。
量词
上述的基础元字符,或者空白元字符都只是用来匹配单个字符,想要匹配多个字符需要通过量词进行。
量词元字符可用的场景通常有: 重复N次,出现0次或1次,最多出现三次……
在正则中,英文的星号(*)代表出现 0 到多次,加号(+)代表 1 到多次,问号(?)代表 0 到 1 次,{m,n}代表 m 到 n 次。
比如,在文本中“颜色”这个单词,可能是带有 u 的 colour,也可能是不带 u 的 color,我们使用 colou?r 就可以表示两种情况了
范围
管道符号 |,用来隔开多个正则,表示满足其中任意一个就行,比如 ab|bc 能匹配上 ab,也能匹配上 bc
中括号[]代表多选一,可以表示里面的任意单个字符。
中括号中,还可以用中划线表示范围,比如 [a-z] 可以表示所有小写字母。如果中括号第一个是脱字符(^),那么就表示非,表达的是不能是里面的任何单个元素。
本节练习题
请写出一个正则,验证如下规则:
- 第 1 位固定为数字 1;
- 第 2 位可能是 3,4,5,6,7,8,9;
- 第 3 位到第 11 位我们认为可能是 0-9 任意数字
const regx = /1[3-9]\d{9}/;console.log(regx.test('125566')); // falseconsole.log(regx.test('1255-66'));console.log(regx.test('1255w66'));console.log(regx.test('12556666666'));console.log(regx.test('14556666666')); // true
02 量词与贪婪:正则的匹配模式
正则中有三种模式:贪婪匹配、非贪婪匹配和独占模式。
贪婪模式,简单说就是尽可能进行最长匹配。非贪婪模式呢,则会尽可能进行最短匹配。
贪婪匹配(Greedy)
在正则中,表示次数的量词默认是贪婪的,在贪婪模式下,会尝试尽可能最大长度去匹配。
看一个例子:在字符串 aaabb 中使用正则 /a*/ 的匹配过程。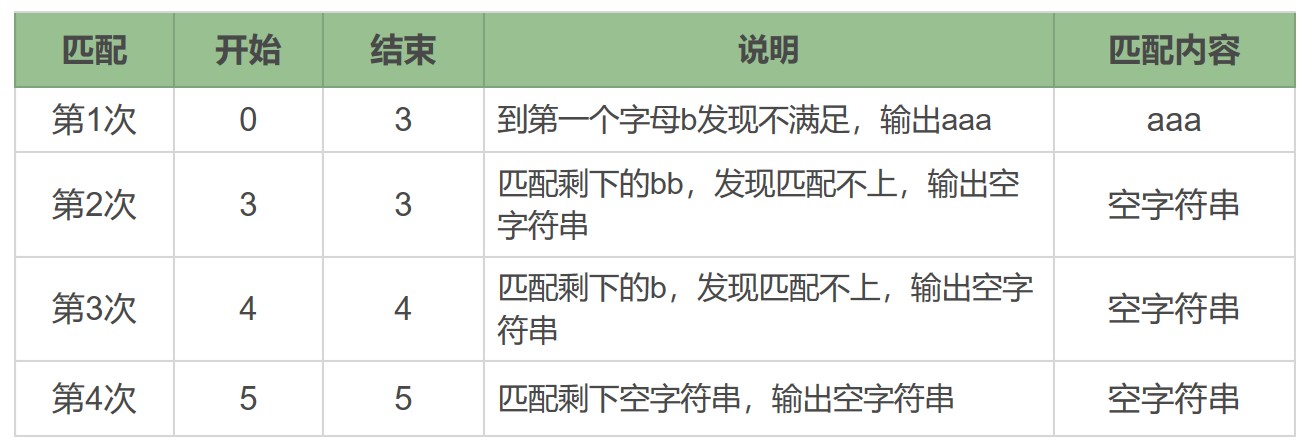
贪婪匹配示例
a* 在匹配开头的 a 时,会尝试尽量匹配更多的 a,直到第一个字母 b 不满足要求为止,匹配上三个 a,后面每次匹配时都得到了空字符串。
非贪婪匹配(Lazy)
在量词后面加上英文的问号 (?)即可将贪婪模式变成非贪婪模式。
案例演示: https://regex101.com/r/XHpDoS/4
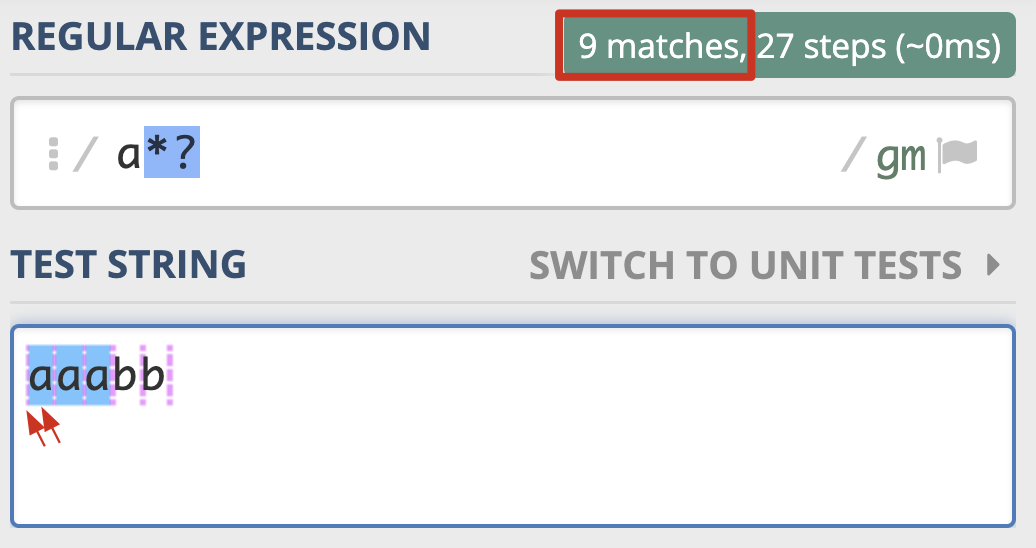
非贪婪匹配
通过示例图可以看到修改为非贪婪模式后不再是匹配 aaa ,每个 a 都会被单独匹配一次,也会匹配到 a 周围的空白。
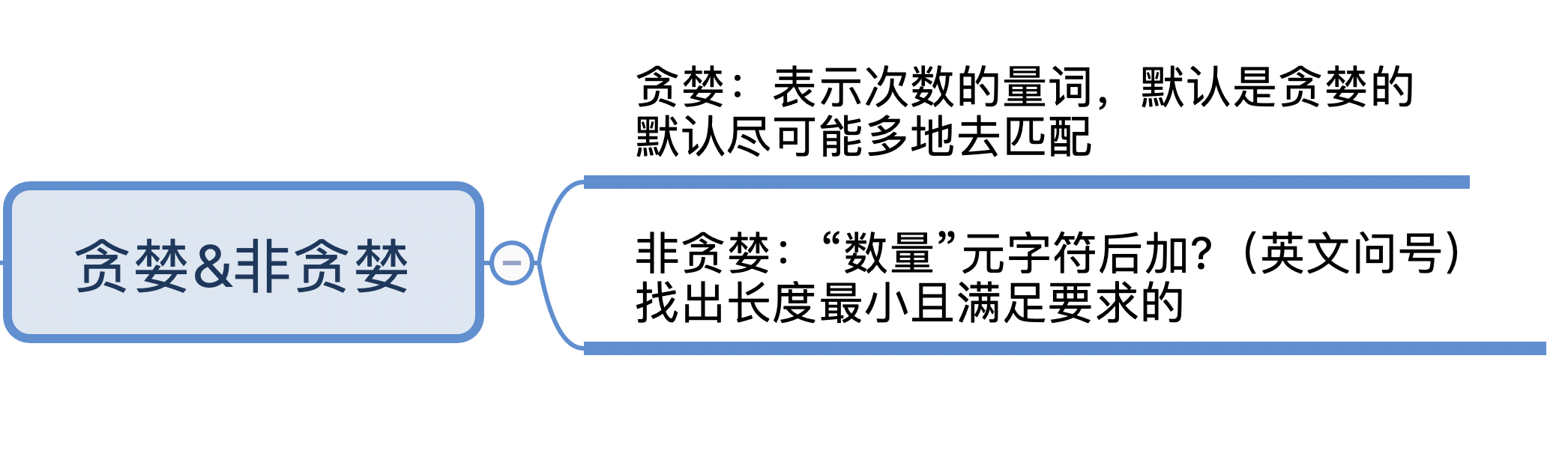
独占模式(Possessive)
不管是贪婪模式,还是非贪婪模式,都需要发生回溯才能完成相应的功能。但是在一些场景下,我们不需要回溯,匹配不上返回失败就好了,因此正则中还有另外一种模式:独占模式。它类似贪婪匹配,但匹配过程不会发生回溯,因此在一些场合下性能会更好。
独占模式和贪婪模式很像,独占模式会尽可能多地去匹配,如果匹配失败就结束,不会进行回溯,这样的话就比较节省时间。具体的方法就是在量词后面加上加号(+)。

如上图所示,当用正则: /xy{1,3}+yz/ 检验文本 ‘xyyz’ 时 xy{1,3}+ 将会匹配上 xyy,当使用剩下的规则匹配时,yz 匹配 z 不成功,因此匹配失败。
独占模式性能比较好,可以节约匹配的时间和 CPU 资源,但有些情况下并不能满足需求,要想使用这个模式还要看具体需求,以及项目使用的语言是否支持。
ps: 目前独占模式的支持性不高,Python 和 Go 的标准库目前都不支持独占模式,JavaScript 也不支持。
正则匹配回溯
一个因为回溯引发的问题的案例: https://zhuanlan.zhihu.com/p/38229530
这个案例有解释了什么是回溯,也阐述了因为回溯可能会引起的实际问题,其他的内容可以不用过多阅读。
对于这个案例,有几个明显的错误是,没有对点号符进行转义,匹配URL中的点直接使用了“ .”,而在正则中,“.”意味着匹配所有字符。此正则中还存在的问题是校验“http”或“https”的规则写的很混乱,可以说这个案例中的正则是相当的“复杂”了 。
(关于回溯这部分需要继续结合正则的工作原理重新整理~~~Todo)
本节练习题
一篇英文文章,除了通过空格分隔的可以认为是单词,引号包裹的部分也被视为是一个单词,编写一个正则,取出文章中的所有单词:
we found “the little cat” is in the hat, we like “the little cat”。
本题解答:https://regex101.com/r/XHpDoS/5
let regx = (\w+)|(“[\w\s]+”);console.log('we found “the little cat” is in the hat, we like “the little cat”'.match(/(\w+)|(“[\w\s]+”)/gm));

03 分组与引用:查找和替换
假设我们现在要去查找 15 位或 18 位数字,根据前面学习的知识,使用量词可以表示出现次数,使用管道符号可以表示多个选择,很快就能写出 \d{15}|\d{18}。但是经过测试,发现这个正则并不能很好地完成任务,因为 18 位数字也会匹配上前 15 位。
当把正则的顺序变为 \d{18}|\d{15} 后,正则可以正常使用了,这是因为在大多数正则实现中,多分支选择都是左边的优先。类似的还有可以使用“北京市?” 来实现来查找 “北京” 和 “北京市”。
针对 15 或 18 位数字这个问题,可以看成是 15 位数字,后面 3 位数字有或者没有,这个在逻辑上市没有问题的,对此可以写出正则 \d{15}\d{3}? ,那么这个正则是否正确呢?
通过第一节我们知道 \d{3} 表示数字出现3次,可以匹配一个长度为3的数字串,? 在第一节当中说了表示的是出现0到1次,而到了第二节在量词之后跟上一个 ? 表示将贪婪模式改为非贪婪模式,因此在现在的写法下\d{15}\d{3}? 表示的含义是前面出现15位数字,后面出现3位数字,即匹配18位长度的数字。
想要让 ? 保持原有的0到1次的含义,我们需要借助其他符号:() 。使用括号将表示“三个数字”的\d{3}这一部分括起来,也就是表示成\d{15}(\d{3})?这样。
括号在正则中的功能就是用于分组。简单来理解就是,由多个元字符组成某个部分,应该被看成一个整体的时候,可以用括号括起来表示一个整体。
分组与编号
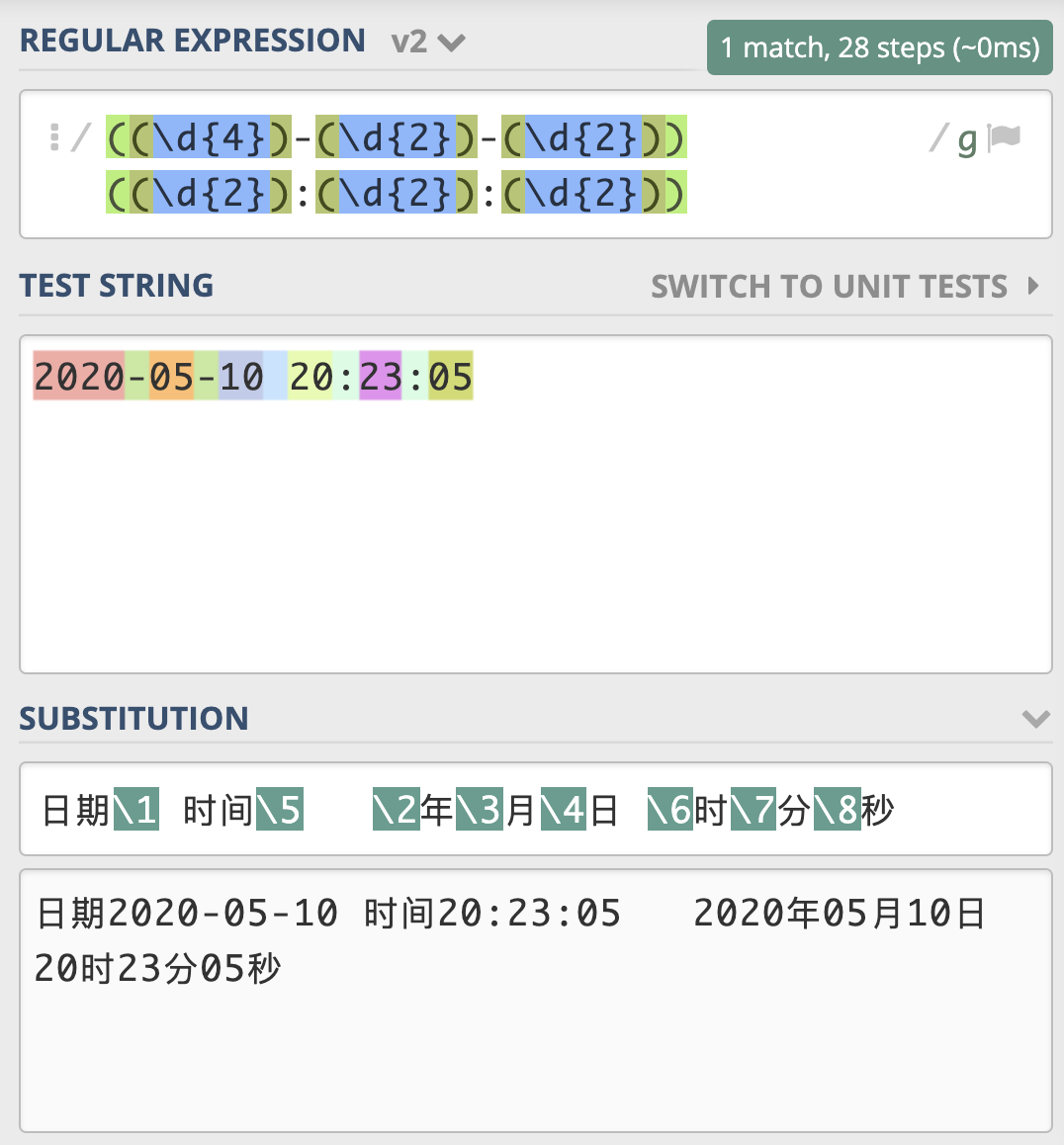
括号在正则中可以用于分组,被括号括起来的“子表达式”部分会被保存成一个子组。从正则左起向右数,第几个括号就是第几个分组。
我们可以写出如图所示的正则,将日期和时间都用括号括起来。这个正则中一共有两个分组,日期是第 1 个,时间是第 2 个。
分组嵌套
前面讲完了子组和编号,但有些情况会比较复杂,比如在括号嵌套的情况里,我们要看某个括号里面的内容是第几个分组。我们只需要数左括号(开括号)是第几个,就可以确定是第几个子组。
日期分组编号是 1,时间分组编号是 5,年月日对应的分组编号分别是 2,3,4,时分秒的分组编号分别是 6,7,8。
上面这样的情况是所有的括号都保存为子组,有的时候我们也会不保存子组。
不保存子组
在括号里面的会保存成子组,但有些情况下,只想用括号将某些部分看成一个整体,后续不会再用它,类似这种情况,在实际使用时,是没必要保存子组的。这时我们可以在括号里面使用 ?: 不保存子组。
如果正则中出现了括号,那么我们就认为,这个子表达式在后续可能会再次被引用,所以不保存子组可以提高正则的性能。
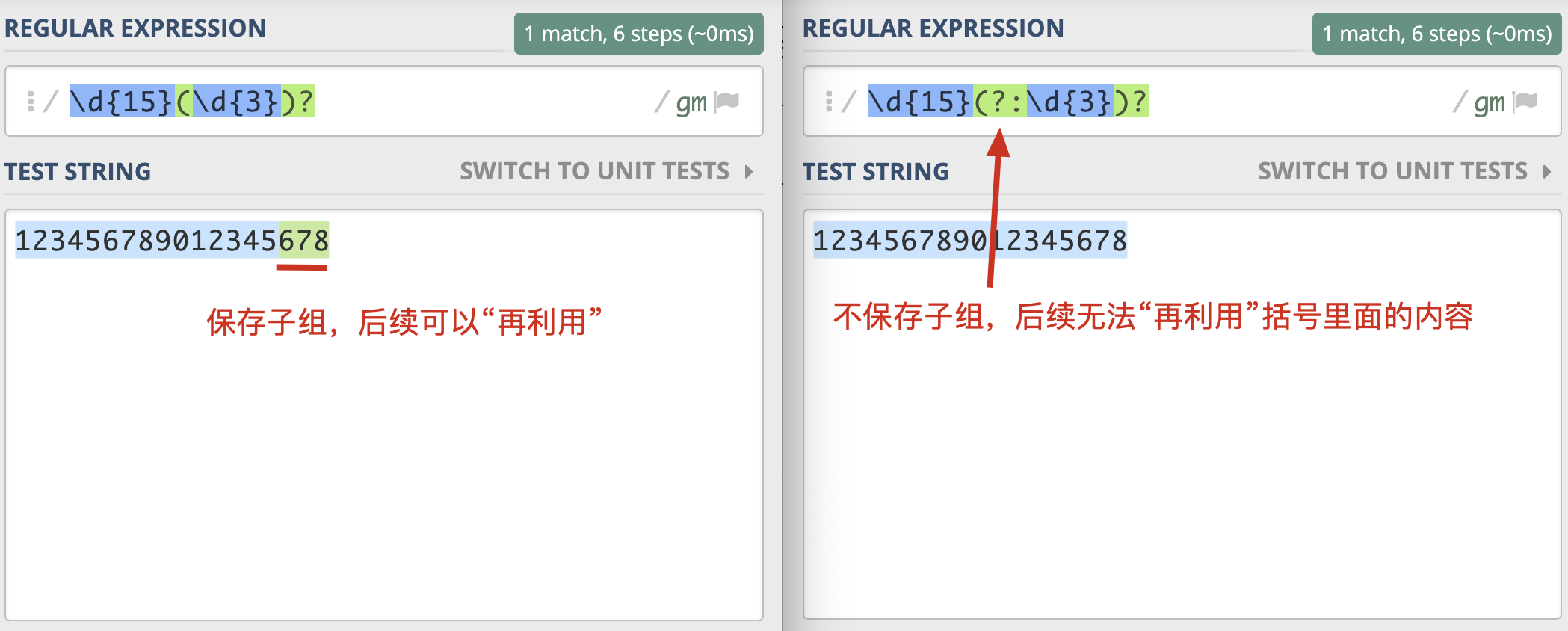
let reg = /([\u4e00-\u9fa5])[\u4e00-\u9fa5](\1)/g;let reg1 = /(?:[\u4e00-\u9fa5])[\u4e00-\u9fa5](\1)/g;let str = '好不好,美不美'

命名分组
由于通过编号分组得数在第几个位置,后续如果发现正则有问题,改动了括号的个数,还可能导致编号发生变化,因此一些编程语言提供了命名分组(named grouping),这样和数字相比更容易辨识,不容易出错。
命名分组的格式为(?P<分组名>正则),如 (?P
并不是所有的语言都支持了这一特性,使用前需要查询确认一下自己使用的语言是否支持。
分组引用
在知道了分组引用的编号 (number)后,大部分情况下,我们就可以使用 “反斜扛 + 编号”,即 \number 的方式来进行引用。
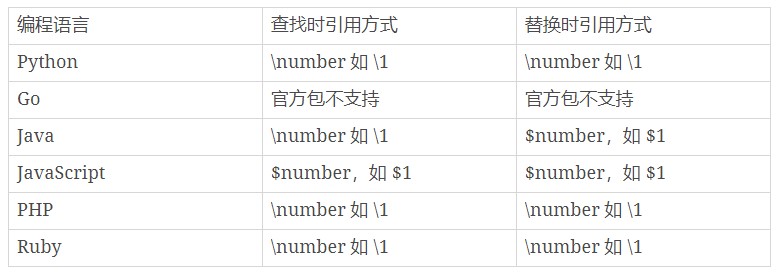
分组引用在查找中使用
我们要找重复出现的单词,使用正则可以很方便地使“前面出现的单词再次出现”,可以使用 \w+ 来表示一个单词,(\w+) \1 这个正则表达式即用 \1 表示 (\w+) “再一次出现”。如果使用(\w+)(\w+) 我们知道 \w+ 匹配的是任意字符,(\w+)(\w+)表示的并不是单词重复。
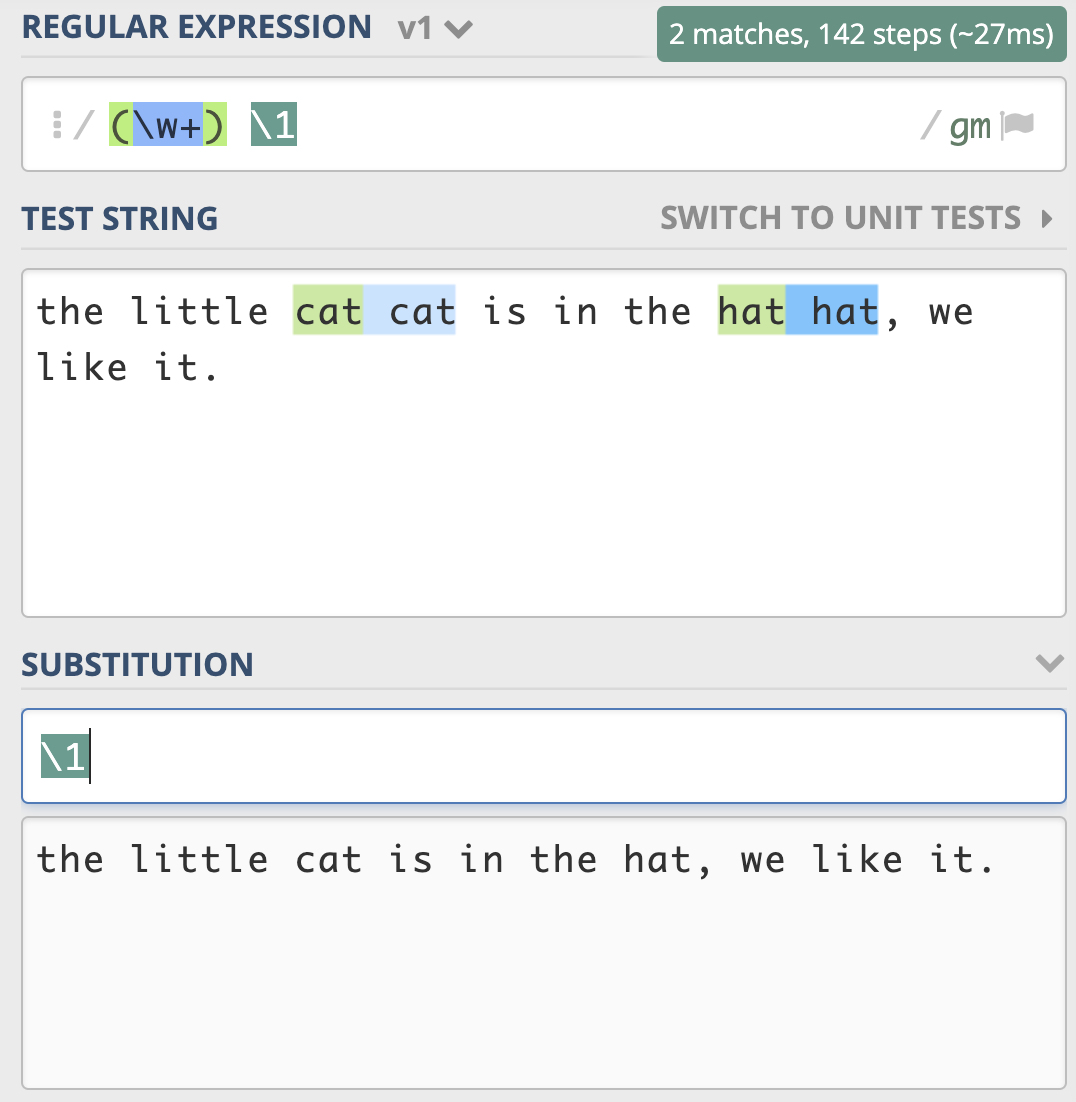
分组引用在替换中使用
和查找类似,我们可以使用反向引用,在得到的结果中,去拼出来我们想要的结果。
总结与练习
括号可以将某部分括起来,看成一个整体,也可以保存成一个子组,在后续查找替换的时候使用。分组编号是指,在正则中第几个括号内就是第几个分组,而嵌套括号我们只要看左括号是第几个就可以了。如果不想将括号里面的内容保存成子组,可以在括号里面加上?: 来解决。
练习:
有一篇英文文章,里面有一些单词连续出现了多次,我们认为连续出现多次的单词应该是一次,比如:the little cat cat is in the hat hat hat, we like it. 其中 cat 和 hat 连接出现多次,要求处理后结果是:the little cat is in the hat, we like it.
答案是:
let str = 'the little cat cat is in the hat hat hat, we like it.'let reg = /(\w+)(?:\s+\1)+/gm;

04 匹配模式:四种匹配模式
所谓匹配模式,指的是正则中一些改变元字符匹配行为的方式,比如匹配时不区分英文字母大小写。常见的匹配模式有 4 种,分别是不区分大小写模式、点号通配模式、多行模式和注释模式。
不区分大小写
当我们把模式修饰符放在整个正则前面时,就表示整个正则表达式都是不区分大小写的。模式修饰符是通过 (? 模式标识) 的方式来表示的。 我们只需要把模式修饰符放在对应的正则前,就可以使用指定的模式了。在不区分大小写模式中,由于不分大小写的英文是 Case-Insensitive,那么对应的模式标识就是 I 的小写字母 i,所以不区分大小写的 cat 就可以写成 (?i)cat。(js中不支持)
用括号把修饰符和正则 cat 部分括起来,加括号相当于作用范围的限定,让不区分大小写只作用于这个括号里的内容:((?i)cat)。
有一点需要注意,上面讲到的通过修饰符指定匹配模式的方式,在大部分编程语言中都是可以直接使用的,但在 JS 中我们需要使用 /regex/i 来指定匹配模式。在编程语言中通常会提供一些预定义的常量,来进行匹配模式的指定。
总结不区分大小写模式的要点:
英文的点(.)可以匹配上任何符号,但不能匹配换行。当我们需要匹配真正的“任意”符号的时候,可以使用 [\s\S] 或 [\d\D] 或 [\w\W] 等。
需要注意的是,JavasScript 不支持此模式,那么我们就可以使用前面说的[\s\S]等方式替代。在 Ruby 中则是用 Multiline,来表示点号通配模式(单行匹配模式),我猜测设计者的意图是把点(.)号理解成“能匹配多行”。
多行匹配模式
单行单配模式
练习
题目: HTML 标签是不区分大小写的,比如我们要提取网页中的 head 标签中的内容,用正则如何实现呢?
答案:/([\s\S])+<\/head>/gi (javaScript) 提取网页标签内容:RegExp.$1
RegExp.$1 获取分组内容
面试题:

方法之一:
function isMatch(str) {if(typeof str !== 'string'){return false;}const reg = /(\(\))|(\[\])|(\{\})/g;let tempStr = str.replace(reg,'');while(reg.test(tempStr)) {tempStr = tempStr.replace(reg,'');}return !temp;}

若有收获,就点个赞吧
0 人点赞
