扩容规则
- ArrayList() 初始时会使用长度为零的数组
- ArrayList(int initialCapacity) 会使用指定容量的数组
- public ArrayList(Collection<? extends E> c) 会使用 c 的大小作为数组容量
- add(Object o) 首次扩容为 10,再次扩容为上次容量的 1.5 倍
- addAll(Collection c)
- 没有元素时,扩容为 Math.max(10, 实际元素个数)
- 有元素时为 Math.max(原容量 1.5 倍, 实际元素个数)
Iterator
Iterator 中两种策略:Fail-Fast 与 Fail-Safe
- Fail-Fast
- ArrayList 是 fail-fast 的典型代表,遍历的同时不能修改,尽快失败
- 一旦发现遍历的同时其它人来修改,则立刻抛异常-ConcurrentModificationException
- Fail-Safe
- CopyOnWriteArrayList 是 fail-safe 的典型代表,遍历的同时可以修改,原理是读写分离
- 发现遍历的同时其它人来修改,应当能有应对策略,例如
**牺牲一致性**来让整个遍历运行完成
增强 for 循环底层调用的是 Iterator ,调用 hasNext 和 next 方法进行遍历,增强for循环只是一种语法糖
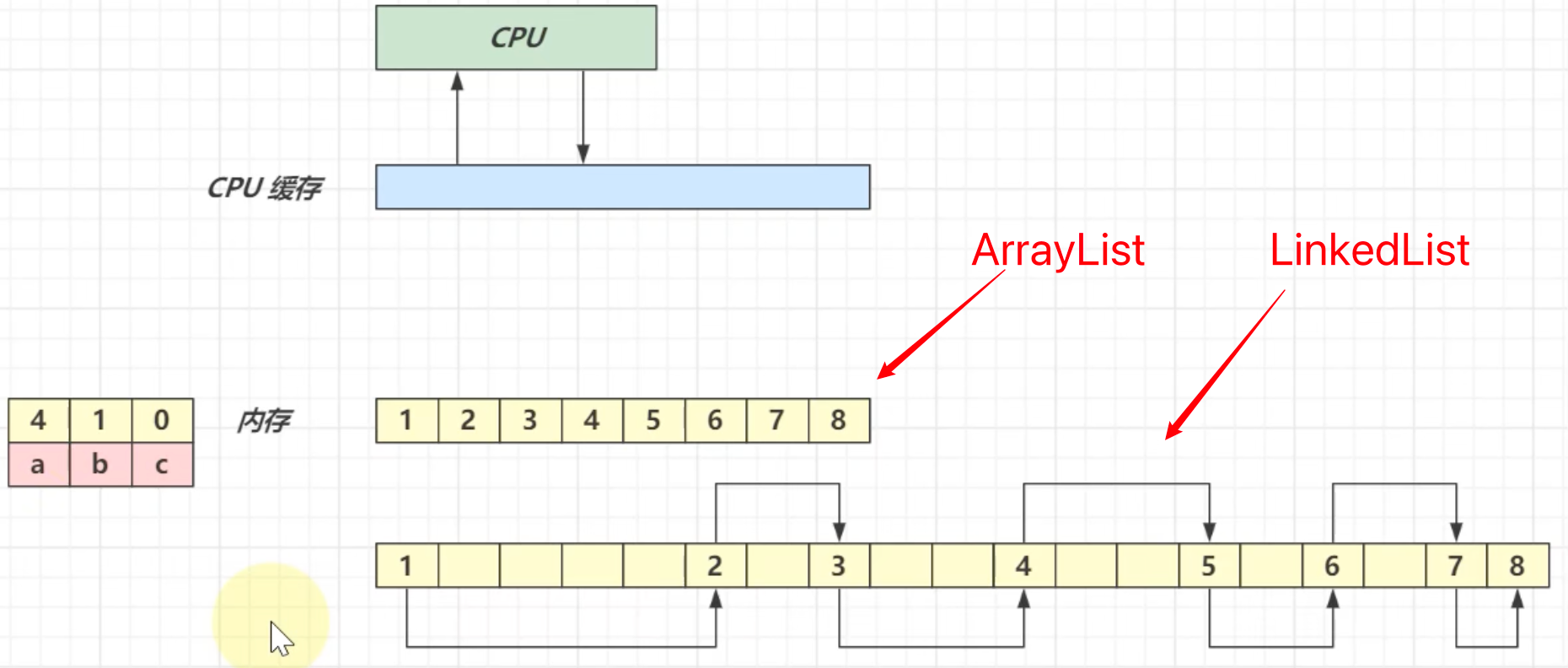
ArrayList 和 LinkedList 却别
LinkedList
- 基于双向链表,无需连续内存
- 随机访问慢(要沿着链表遍历)
- 头尾插入删除性能高
- 占用内存多
ArrayList
- 基于数组,需要连续内存
- 随机访问快(指根据下标访问)
- 尾部插入、删除性能可以,其它部分插入、删除都会移动数据,因此性能会低
- 可以利用 cpu 缓存,局部性原理
局部性原理:CPU 处理速度非常快,而内存和CPU双向写/读数据速度远远小于CPU处理速度,容易导致 CPU 资源浪费。这时引入 CPU 缓存,先把内存中的数据放入到 CPU 缓存中,然后CPU从CPU缓存中读取数据,再往CPU缓存写入数据,CPU 缓存再把数据同步到内存即可。
由于数组是连续的,而链表的内存地。址不一定连续,所以对于数组的局部性更好一些。

若有收获,就点个赞吧
0 人点赞
