启动redis:
打开一个 cmd 窗口 使用 cd 命令切换目录到 C:\redis 运行:
redis-server.exe redis.windows.conf
这时候另启一个 cmd 窗口,原来的不要关闭,不然就无法访问服务端了。
切换到 redis 目录下运行:redis-cli.exe -h 127.0.0.1 -p 6379设置键值对:set myKey abc取出键值对:get myKey
缓存数据库:默认端口6379,版本6.0.8最文档
两个查看版本号的命令:redis- service -v、info
命令不区分大小写,而key是区分大小写的
命令help @类型名称:查看类型方法
数据类型使用场景
| 数据类型 | 使用场景 |
|---|---|
| String | 比如说,想知道什么时候封锁IP地址(访问频繁)。使用Incrby命令获取访问次数。 String数据结构是简单的key-value类型,value其实不仅可以是String,也可以是数字。 常规key-value缓存应用。 常用命令:set、get、mset、mget、incr、decr、setnx 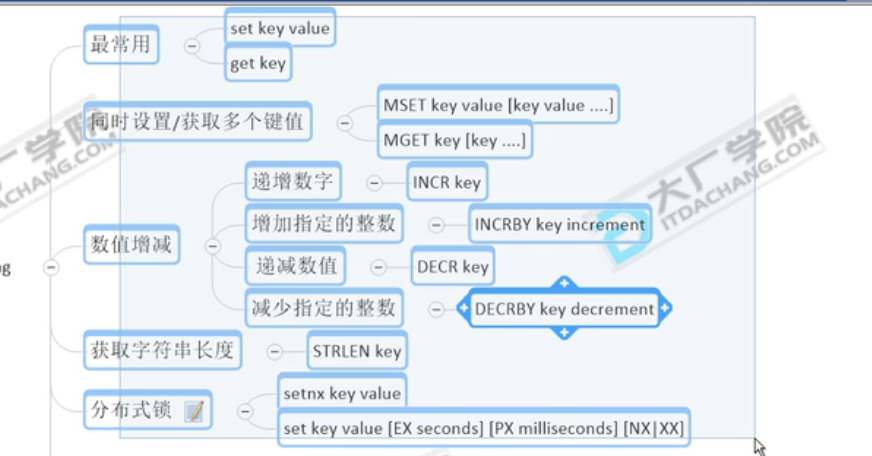 分布式锁命令:点赞 incr item:001 每次执行+1 |
| Hash | 存储用户信息【id,name,age】 Hset(key,field,vlue); Hset(userKey,id,101); Hset(userKey,name,admin); Hset(userKey,age,10); 修改案例:Hget(userKey,id);Hset(userKey,id,102);为什么不使用String类型存储:Set(userKey,用户信息的字符串);Get(userKey);反序列化把用户所有信息都取出来了,增加IO次数。 相当于=Map  场景:购物车早期 |
| List | 实现最新消息的排行;还可以利用List的push命令将任务存在List集合中,同时使用另一个命令将任务从集合中取出(pop)。Redis—list数据类型来模拟消息队列。【电商在的秒杀就可以采用这种方式来完成一个秒杀活动】。 |
| Set | 特殊之处:可以自动排重。比如微博中将每个人的好友存在集合(Set)中,这样求两个人的共同好友的擦做。只需求交集即可。 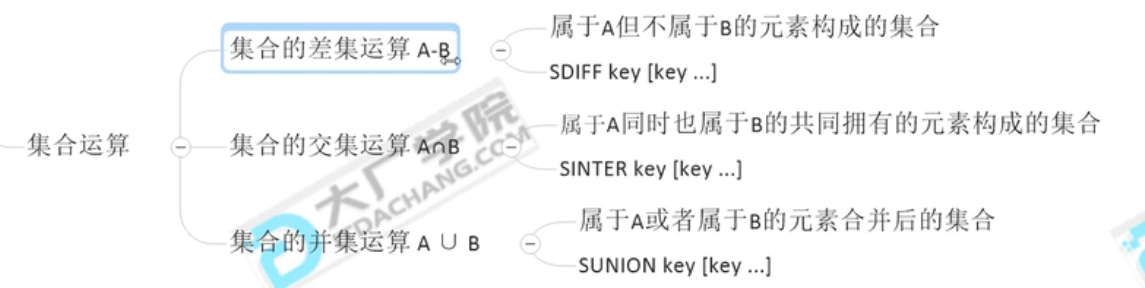    SINTER:交集,共同关注。 SDIFF:求交集 |
| Zset | 以某一个条件为权重,进行排序。京东:综合排名和查询。 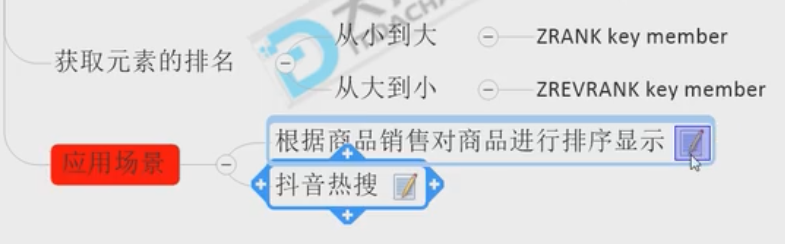 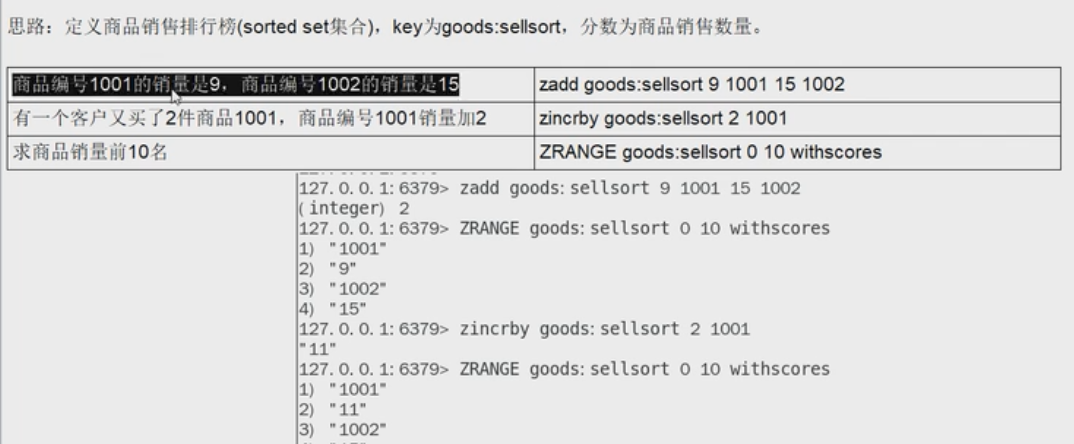  |
除了上述五大类型,其他类型:bitmap、Hyperloglogs、GEO、Stream
缓存穿透问题
先来看一个常见的缓存使用方式:读请求来了,先查下缓存,缓存有值命中,就直接返回;缓存没命中,就去查数据库,然后把数据库的值更新到缓存,再返回。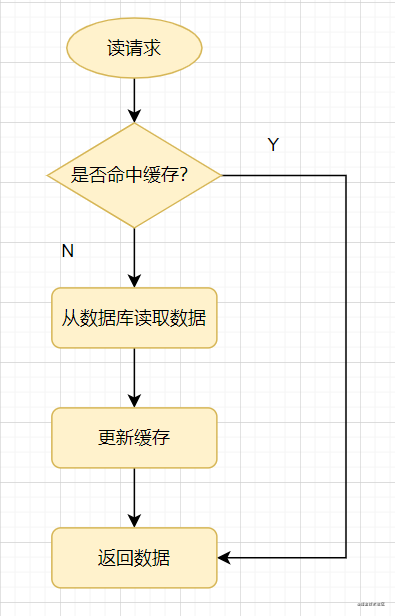
缓存穿透:指查询一个一定不存在的数据,由于缓存是不命中时需要从数据库查询,查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到数据库去查询,进而给数据库带来压力。
通俗点说,读请求访问时,缓存和数据库都没有某个值,这样就会导致每次对这个值的查询请求都会穿透到数据库,这就是缓存穿透。
缓存穿透一般都是这几种情况产生的:
- 业务不合理的设计,比如大多数用户都没开守护,但是你的每个请求都去缓存,查询某个userid查询有没有守护。
- 业务/运维/开发失误的操作,比如缓存和数据库的数据都被误删除了。
- 黑客非法请求攻击,比如黑客故意捏造大量非法请求,以读取不存在的业务数据。
如何避免缓存穿透呢? 一般有三种方法。
- 如果是非法请求,我们在API入口,对参数进行校验,过滤非法值。
- 如果查询数据库为空,我们可以给缓存设置个空值,或者默认值。但是如有写请求进来的话,需要更新缓存哈,以保证缓存一致性,同时,最后给缓存设置适当的过期时间。(业务上比较常用,简单有效)
- 使用布隆过滤器快速判断数据是否存在。即一个查询请求过来时,先通过布隆过滤器判断值是否存在,存在才继续往下查。
布隆过滤器原理:它由初始值为0的位图数组和N个哈希函数组成。一个对一个key进行N个hash算法获取N个值,在比特数组中将这N个值散列后设定为1,然后查的时候如果特定的这几个位置都为1,那么布隆过滤器判断该key存在。
缓存雪崩问题
缓存雪奔: 指缓存中数据大批量到过期时间,而查询数据量巨大,请求都直接访问数据库,引起数据库压力过大甚至down机。
- 缓存雪奔一般是由于大量数据同时过期造成的,对于这个原因,可通过均匀设置过期时间解决,即让过期时间相对离散一点。如采用一个较大固定值+一个较小的随机值,5小时+0到1800秒酱紫。
Redis 故障宕机也可能引起缓存雪奔。这就需要构造Redis高可用集群啦。
缓存击穿问题
缓存击穿: 指热点key在某个时间点过期的时候,而恰好在这个时间点对这个Key有大量的并发请求过来,从而大量的请求到db。
缓存击穿看着有点像,其实它两区别是,缓存雪奔是指数据库压力过大甚至down机,缓存击穿只是大量并发请求到了DB数据库层面。可以认为击穿是缓存雪奔的一个子集吧。有些文章认为它俩区别,是区别在于击穿针对某一热点key缓存,雪崩则是很多key。
解决方案就有两种:1.使用互斥锁方案。缓存失效时,不是立即去加载db数据,而是先使用某些带成功返回的原子操作命令,如(Redis的setnx)去操作,成功的时候,再去加载db数据库数据和设置缓存。否则就去重试获取缓存。
- 2. “永不过期”,是指没有设置过期时间,但是热点数据快要过期时,异步线程去更新和设置过期时间。
缓存热key问题
在Redis中,我们把访问频率高的key,称为热点key。如果某一热点key的请求到服务器主机时,由于请求量特别大,可能会导致主机资源不足,甚至宕机,从而影响正常的服务。
而热点Key是怎么产生的呢?主要原因有两个:- 用户消费的数据远大于生产的数据,如秒杀、热点新闻等读多写少的场景。
- 请求分片集中,超过单Redi服务器的性能,比如固定名称key,Hash落入同一台服务器,瞬间访问量极大,超过机器瓶颈,产生热点Key问题。
那么在日常开发中,如何识别到热点key呢?
- 凭经验判断哪些是热Key;
- 客户端统计上报;
- 服务代理层上报
如何解决热key问题?
- Redis集群扩容:增加分片副本,均衡读流量;
- 对热key进行hash散列,比如将一个key备份为key1,key2……keyN,同样的数据N个备份,N个备份分布到不同分片,访问时可随机访问N个备份中的一个,进一步分担读流量;
- 使用二级缓存,即JVM本地缓存,减少Redis的读请求。
分布式锁
1,redis加锁+过期时间+finally删除锁
redis删除不是原子操作:保证原子操作方式
Lua算法
jedis
加事务,但事务不支持回滚
redis事务相关命令:watch multi exec unwatch
redis分布式锁如何实现缓存续期?
redis异步复制造成锁丢失问题:
- redis:主有了就返回,或导致
- 主从数据不一致,高可用;
- zookeeper,主从一致,高可用下降。
最终分布式锁上面的问题可用RedLock之Redission解决。(Redis分布式锁)
删除key时会遇到哪些问题?
会把异常?加上判断是否是当前线程的所保持的锁,若是则删除
redission底层原理?
主从同步
总结
- 发送 SLAVEOF 命令可以进行主从同步,比如:SLAVEOF 127.0.0.6379
主从同步有同步和命令传播 2 个步骤。
- 同步:将从服务器的数据库状态更新成主服务器当前的数据库状态(一个消耗资源的操作)
- 命令传播:当主服务器数据库状态被修改后,导致主从服务器数据库状态不一致,此时需要让主从数据同步到一致的过程
主从同步分初次复制和断线后重复制两种情况
- 从 2.8 版本开始,在出现断线后重复制情况时,主服务器会根据复制偏移量、复制积压缓冲区和 run id,来确定执行完整重同步还是部分重同步
- 2.8 版本使用 psync 命令来代替 sync 命令去执行同步操作。目的是为了解决同步(sync 命令)的低效操作
哨兵模式
在 redis3.0之前,redis使用的哨兵架构,它借助 sentinel 工具来监控 master 节点的状态;如果 master 节点异常,则会做主从切换,将一台 slave 作为 master。
哨兵模式的缺点:
(1)当master挂掉的时候,sentinel 会选举出来一个 master,选举的时候是没有办法去访问Redis的,会存在访问瞬断的情况;若是在电商网站大促的时候master给挂掉了,几秒钟损失好多订单数据;
(2)哨兵模式,对外只有master节点可以写,slave节点只能用于读。尽管Redis单节点最多支持10W的QPS,但是在电商大促的时候,写数据的压力全部在master上。
(3)Redis的单节点内存不能设置过大,若数据过大在主从同步将会很慢;在节点启动的时候,时间特别长;(从节点上有主节点的所有数据)

若有收获,就点个赞吧
0 人点赞
