一.那么关于遇到hash冲突时候这个数据是头插呢?还是尾插呢?
关于HashMap链表插入问题,java8之前是头插法
头插法:就是说新来的值会取代原有的值,原有的值就顺推到链表中去,就像上面的例子一样,因为写这个代码的作者认为后来的值被查找的可能性更大一点,提升查找的效率。
在java8之后,都是所用尾部插入了。
解决上面的问题需要一些预备知识
hashmap的扩容原理
hashmap扩容分为两步
- 扩容:创建一个新的Entry空数组,长度是原数组的2倍。
- ReHash:遍历原Entry数组,把所有的Entry重新Hash到新数组。
为什么要重新Hash呢,不直接复制过去呢?
因为长度扩大以后,Hash的规则也随之改变。
Hash的公式—-> index = HashCode(Key) & (Length - 1)
原来长度(Length)是8你位运算出来的值是2 ,新的长度是16你位运算出来的值明显不一样了,之前的所有数据的hash值得到的位置都需要变化。
如下图:
扩容前: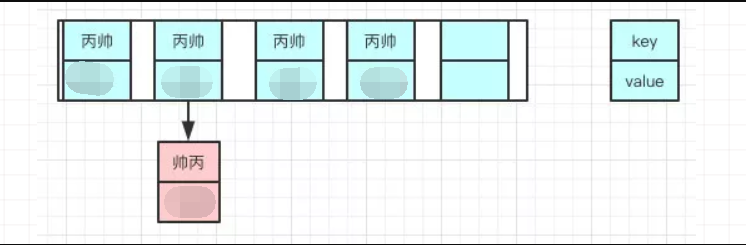
扩容后:

主要是为了安全,防止环化
因为resize的赋值方式,也就是使用了单链表的头插入方式,同一位置上新元素总会被放在链表的头部位置,在旧数组中同一条Entry链上的元素,通过重新计算索引位置后,有可能被放到了新数组的不同位置上。
就可能出现下面的情况,大家发现问题没有?
B的下一个指针指向了A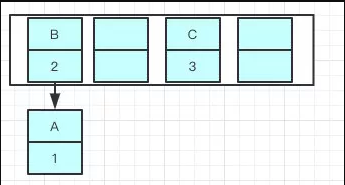
一旦几个线程都调整完成,就可能出现环形链表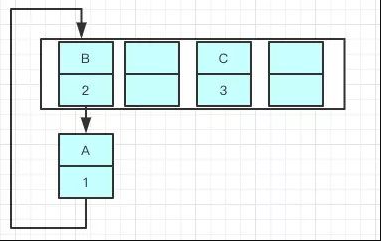
如果这个时候去取值,就出现了无限循环的状态..
使用头插会改变链表的上的顺序,但是如果使用尾插,在扩容时会保持链表元素原本的顺序,就不会出现链表成环的问题了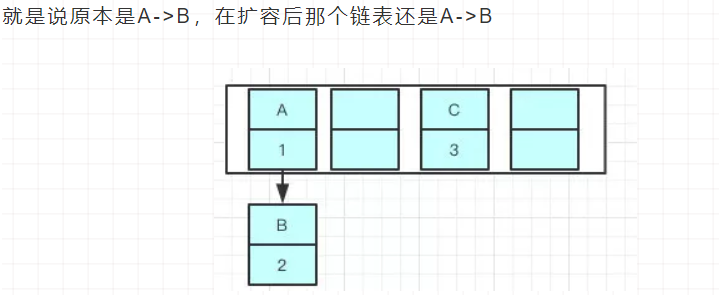
Java8在同样的前提下并不会引起死循环,原因是扩容转移后前后链表顺序不变,保持之前节点的引用关系。
那是不是意味着Java8就可以把HashMap用在多线程中呢?
那是必然不可以的,HashMap put/get方法都没有加同步锁,这里存在一个并发修改的问题,ConcurrentModifyExcption,所以线程安全还是无法保证。
二 .那我问你HashMap的默认初始化长度是多少?16,为啥是16呢?
为了能让 HashMap 存取高效,尽量较少碰撞,也就是要尽量把数据分配均匀。我们上面也讲到了过了,Hash 值的范围值-2147483648到2147483647,前后加起来大概40亿的映射空间,只要哈希函数映射得比较均匀松散,一般应用是很难出现碰撞的。但问题是一个40亿长度的数组,内存是放不下的。所以这个散列值是不能直接拿来用的。用之前还要先做对数组的长度取模运算,得到的余数才能用来要存放的位置也就是对应的数组下标。这个数组下标的计算方法是“ (n - 1) & hash ”。(n代表数组长度)。这也就解释了 HashMap 的长度为什么是2的幂次方。
这个算法应该如何设计呢?
我们首先可能会想到采用%取余的操作来实现。但是,
(也就是说 hash%length==hash&(length-1)的前提是 length 是2的 n 次方;)。”
详情请看https://www.jianshu.com/p/3e541a11a9f0
至于为啥初始长度是16我觉得就是大家都觉得16通常情况够用了吧
三 .为啥我们重写equals方法的时候需要重写hashCode方法呢?
因为在java中,所有的对象都是继承于Object类。
Ojbect类中有两个方法equals、hashCode,这两个方法都是用来比较两个对象是否相等的。
在未重写equals方法我们是继承了object的equals方法,那里的 equals是比较两个对象的内存地址,显然我们new了2个对象内存地址肯定不一样
对于值对象,==比较的是两个对象的值
对于引用对象,比较的是两个对象的地址
所以如果我们对equals方法进行了重写,建议一定要对hashCode方法重写,以保证相同的对象返回相同的hash值,不同的对象返回不同的hash值。
不然一个链表的对象,你哪里知道你要找的是哪个,到时候发现hashCode都一样,这不是完犊子嘛。

若有收获,就点个赞吧
0 人点赞
