Java基础知识知识点总结:
3月28号:
1,a是int类型,13/5得到一个浮点类型,浮点类型转成整数类型的原则是,不四舍五入,直接截断小数点后的部分。
2,容器的左上角被确定为坐标的起点。
3,Java自带的三大注解:@Override@Deprecated @SuppressWarnings()
4,HashMap不能保证元素的顺序,HashMap能够将键设为null,也可以将值设为null,与之对应的是Hashtable,(注意大小写:不是HashTable),Hashtable于能将键和值设为null,否则运行时会报空指针异常错误;
HashMap线程不安全,Hashtable线程安全
5, 同步器是一些使线程能够等待另一个线程的对象,允许它们协调动作。最常用的同步器是CountDownLatch和Semaphore,不常用的是Barrier 和Exchanger
6,A,Java 并发库 的Semaphore 可以很轻松完成信号量控制,Semaphore可以控制某个资源可被同时访问的个数,通过 acquire() 获取一个许可,如果没有就等待,而 release() 释放一个许可。
B,CyclicBarrier 主要的方法就是一个:await()。await() 方法没被调用一次,计数便会减少1,并阻塞住当前线程。当计数减至0时,阻塞解除,所有在此 CyclicBarrier 上面阻塞的线程开始运行。
C,直译过来就是倒计数(CountDown)门闩(Latch)。倒计数不用说,门闩的意思顾名思义就是阻止前进。在这里就是指CountDownLatch.await() 方法在倒计数为0之前会阻塞当前线程。
D,Counter不是并发编程的同步器
7,当前用户上下文信息:session
appication:当前应用
pageContext:当前页面
request:当前请求
8,JSP 四大作用域: page (作用范围最小)、request、session、application(作用范围最大)。
存储在application对象中的属性可以被同一个WEB应用程序中的所有Servlet和JSP页面访问。(属性作用范围最大)
存储在session对象中的属性可以被属于同一个会话(浏览器打开直到关闭称为一次会话,且在此期间会话不失效)的所有Servlet和JSP页面访问。
存储在request对象中的属性可以被属于同一个请求的所有Servlet和JSP页面访问(在有转发的情况下可以跨页面获取属性值),例如使用PageContext.forward和PageContext.include方法连接起来的多个Servlet和JSP页面。
存储在pageContext对象中的属性仅可以被当前JSP页面的当前响应过程中调用的各个组件访问,例如,正在响应当前请求的JSP页面和它调用的各个自定义标签类。
9,A:HashMap和Hashtable两个类都实现了Map接口,二者保存K-V对(key-value对)
B:HashTable不允许null值(key和value都不可以),HashMap允许null值(key和value都可以)。
C:Hashtable的方法是Synchronize的,而HashMap不是,在多个线程访问Hashtable时,不需要自己为它的方法实现同步,而HashMap 就必须为之提供外同步。
D:由所有HashMap类的“collection 视图方法”所返回的迭代器都是快速失败的:在迭代器创建之后,如果从结构上对映射进行修改,除非通过迭代器本身的 remove 方法,其他任何时间任何方式的修改,迭代器都将抛出ConcurrentModificationException。Hashtable和HashMap的区别主要是前者是同步的,后者是快速失败机制保证
10,HttpServletRequest类主要处理:
1.读取和写入HTTP头标
2.取得和设置cookies
3.取得路径信息
4.标识HTTP会话
11,A: request.getCookies();
B: request.getHeader(String s);
C: response.setContentType(“text/html;charset=utf-8”);
D: request.getContextPath();/request.getServletPath();
12, 1.start方法
用 start方法来启动线程,是真正实现了多线程,通过调用Thread类的start()方法来启动一个线程,这时此线程处于就绪(可运行)状态,并没有运行,一旦得到cpu时间片,就开始执行run()方法。但要注意的是,此时无需等待run()方法执行完毕,即可继续执行下面的代码。所以run()方法并没有实现多线程。
2.run方法
run()方法只是类的一个普通方法而已,如果直接调用Run方法,程序中依然只有主线程这一个线程,其程序执行路径还是只有一条,还是要顺序执行,还是要等待run方法体执行完毕后才可继续执行下面的代码。
13,HashTable和HashMap区别
①继承不同。
public class Hashtable extends Dictionary implements Map publicclass HashMap extends AbstractMap implements Map
②
Hashtable 中的方法是同步的,而HashMap中的方法在缺省情况下是非同步的。在多线程并发的环境下,可以直接使用Hashtable,但是要使用HashMap的话就要自己增加同步处理了。
③
Hashtable中,key和value都不允许出现null值。
在HashMap中,null可以作为键,这样的键只有一个;可以有一个或多个键所对应的值为null。当get()方法返回null值时,即可以表示 HashMap中没有该键,也可以表示该键所对应的值为null。因此,在HashMap中不能由get()方法来判断HashMap中是否存在某个键, 而应该用containsKey()方法来判断。
④两个遍历方式的内部实现上不同。
Hashtable、HashMap都使用了 Iterator。而由于历史原因,Hashtable还使用了Enumeration的方式 。
⑤
哈希值的使用不同,HashTable直接使用对象的hashCode。而HashMap重新计算hash值。
⑥
Hashtable和HashMap它们两个内部实现方式的数组的初始大小和扩容的方式。HashTable中hash数组默认大小是11,增加的方式是 old*2+1。HashMap中hash数组的默认大小是16,而且一定是2的指数。
13,先继承再实现
14,初始化块在构造器执行之前执行,类初始化阶段先执行最顶层父类的静态初始化块,依次向下执行,最后执行当前类的静态初始化块;创建对象时,先调用顶层父类的构造方法,依次向下执行,最后调用本类的构造方法。
15,执行顺序:“静态初始化块 ”先于 “非静态初始化” 先于 “构造函数执行”
父类静态代码块-》子类静态代码块-》父类构造代码块-》父类构造函数-》子类构造代码块-》子类构造函数
16,一句话 向上转型是无条件的
3月29号:
17,Java关键字:abstract,boolean,break,back,continue,case,catch,char,class,do,double,default,else,extends,final,finally,float,for,long,if,implements,import,new,instanceof,int,interface,package,private,public,protected,return,short,static,super,switch,sychronized,this,while,void,throw,throws,try,volatile
保留字:const,goto
18,加载驱动方法
1.Class.forName(“com.microsoft.sqlserver.jdbc.SQLServerDriver”);
2. DriverManager.registerDriver(new com.mysql.jdbc.Driver());
3.System.setProperty(“jdbc.drivers”,”com.mysql.jdbc.Driver”);
19,DriverManager.getConnection方法返回一个Connection对象,这是加载驱动之后才能进行的
20,1.首先,需要明白类的加载顺序。
(1) 父类静态代码块(包括静态初始化块,静态属性,但不包括静态方法)
(2) 子类静态代码块(包括静态初始化块,静态属性,但不包括静态方法 )
(3) 父类非静态代码块( 包括非静态初始化块,非静态属性 )
(4) 父类构造函数
(5) 子类非静态代码块 ( 包括非静态初始化块,非静态属性 )
(6) 子类构造函数
其中:类中静态块按照声明顺序执行,并且(1)和(2)不需要调用new类实例的时候就执行了(意思就是在类加载到方法区的时候执行的)
2.其次,需要理解子类覆盖父类方法的问题,也就是方法重写实现多态问题。
Base b = new Sub();它为多态的一种表现形式,声明是Base,实现是Sub类, 理解为 b 编译时表现为Base类特性,运行时表现为Sub类特性。
当子类覆盖了父类的方法后,意思是父类的方法已经被重写,题中父类初始化调用的方法为子类实现的方法,子类实现的方法中调用的baseName为子类中的私有属性。
由1.可知,此时只执行到步骤4.,子类非静态代码块和初始化步骤还没有到,子类中的baseName还没有被初始化。所以此时 baseName为空。 所以为null。
21,(单选题)下面代码的输出是什么?public class Base { private String baseName =”base”; public Base() {callName(); }public void callName() {System. out. println(baseName);} static class Sub extends Base{ private StringbaseName = “sub”; public voidcallName() {System. out.println (baseName) ; }} public static void main(String[] args){ Base b = newSub(); } }
图2个
22,Java语言中的异常处理包括声明异常、抛出异常、捕获异常和处理异常四个环节。
throw用于抛出异常。
throws关键字可以在方法上声明该方法要抛出的异常,然后在方法内部通过throw抛出异常对象。
try是用于检测被包住的语句块是否出现异常,如果有异常,则抛出异常,并执行catch语句。
cacth用于捕获从try中抛出的异常并作出处理。
finally语句块是不管有没有出现异常都要执行的内容。
23,A 选项在 final 定义的方法里,不是必须要用 final 定义变量。
B final 定义的变量,可以在不是必须要在定义的同时完成初始化,也可以在构造方法中完成初始化。
C 正确,final修饰方法,不能被子类重写,但是可以被重载。
D final 定义变量,可以用 static 也可以不用。
24,顶层容器是指可以不能被其他容器包含 ,是容纳其他容器的容器组件,
顶层容器包含JApplet、JDialog、JFrame和JWindow及其子类.
JFrame中就可以放Jtree(树形组件)
所以B不是
25,String类不可变,指的是String对象内容不可变,因为’String对象存在常量池中,而String的引用是可以可变,可以为String引用赋予新的对象字符串。
26,当编写一个java源代码文件时,此文件通常被称为编译单元(有时也被称为转译单元)。每个编译单元都必须有一个后缀名.java,而在编译单元内则可以有一个public类,该类的名称必须与文件的名称相同(包括大小写,但不包括文件的后缀名.java)。每个编译单元只能有一个public类,否则编译器就不会接受。如果在该编译单元之中还有额外的类的话,那么在包之外的世界是无法看见这些类的,这是因为它们不是public类,而且它们主要用来为主public类提供支持。 —《Java 编程思想》
注:public类不是必须的,但是如果源文件中有一个(只能有一个)public类的话,文件名必须与这个public类同名,原因 是为了方便虚拟机在相应的路径中找到相应的类所对应的字节码文件。所以在没有public类的Java文件中,文件名和类名都没什么联系。
27,Java两种数组声明方式
1.int[] nums;
2.int nums[];
28,使用super()或者this()方法是必须放在构造函数的第一行
由于this函数指向的构造函数默认有super()方法,所以规定this()和super()不能同时出现在一个构造函数中。
因为staic方法或者语句块没有实例时可以使用,而此时不需要构造实例,所以不能用this()和super()
图
29,1. 粉红色的是受检查的异常(checkedexceptions),其必须被 try{}catch语句块所捕获,或者在方法签名里通过throws子句声明.受检查的异常必须在编译时被捕捉处理,命名为 Checked Exception 是因为Java编译器要进行检查,Java虚拟机也要进行检查,以确保这个规则得到遵守.
2. 绿色的异常是运行时异常(runtime exceptions),需要程序员自己分析代码决定是否捕获和处理,比如 空指针,被0除…
3. 而声明为Error的,则属于严重错误,如系统崩溃、虚拟机错误、动态链接失败等,这些错误无法恢复或者不可能捕捉,将导致应用程序中断,Error不需要捕捉。
30,request.getAttribute()方法返回request范围内存在的对象,而request.getParameter()方法是获取http提交过来的数据。getAttribute是返回对象,getParameter返回字符串。
31,getAttribute()接受从request域中传过来的参数,getParameter()接受从页面传过来的参数
32,HttpServletResponse完成:设置http头标,设置cookie,设置返回数据类型,输出返回数据;读取路径信息是HttpServletRequest做的
33,CopyOnWriteArrayList适合使用在读操作远远大于写操作的场景里,比如缓存。
ReadWriteLock 当写操作时,其他线程无法读取或写入数据,而当读操作时,其它线程无法写入数据,但却可以读取数据 。适用于 读取远远大于写入的操作。
ConcurrentHashMap是一个线程安全的Hash Table,它的主要功能是提供了一组和HashTable功能相同但是线程安全的方法。ConcurrentHashMap可以做到读取数据不加锁,并且其内部的结构可以让其在进行写操作的时候能够将锁的粒度保持地尽量地小,不用对整个ConcurrentHashMap加锁。
34,在集合框架中,有些类是线程安全的,这些都是jdk1.1中的出现的。在jdk1.2之后,就出现许许多多非线程安全的类。 下面是这些线程安全的同步的类:
vector:就比arraylist多了个同步化机制(线程安全),因为效率较低,现在已经不太建议使用。在web应用中,特别是前台页面,往往效率(页面响应速度)是优先考虑的。
statck:堆栈类,先进后出
hashtable:就比hashmap多了个线程安全
enumeration:枚举,相当于迭代器
除了这些之外,其他的都是非线程安全的类和接口。
35,喂,she!即线程安全的是vector,stack,hashtable,enumeration
36,A和B中long和float,正常定义需要加l和f,但是long和float属于基本类型,会进行转化,所以不会报出异常。AB正确
boolean类型不能和任何类型进行转换,会报出类型异常错误。所以C错。
D选项可以这样定义,D正确。
E选项中,byte的取值范围是-128—127。报出异常: cannot convert from int to byte.所以E选项错误。
37,ApplicationContext初始化时会检验,而BeanFactory在第一次使用时未注入,才会抛出异常
38,java类是单继承的。 java接口可以多继承。不允许类多重继承的主要原因是,如果A同时继承B和C,而B和C同时又有一个D方法,A如何决定该继承那一个呢? 但接口不存在这样的问题,接口全都是抽象方法继承谁都无所谓,所以接口可以继承多个接口
39,Java不支持多继承,但是通过一些巧妙的设计来达到和多继承同样的效果
通过接口、内隐类,继承、实现,互相配合,达到多继承的效果
1、Java中一个类不能继承多个具体class。
2、一个类只可继承自一个具体 class,但可实现多个接口。
interface不涉及到实现细节,不与任何存储空间有关连。
可以实现合并多个 interface ,达到可向上转型为多种基类的目的。
新类可继承自一个具象class,其余继承都得是interfaces。
3、outer class不可继承自多个具体 class,可在其内部设多个inner class,每个inner class都能各自继承某一实现类。
inner class不受限于outer class 是否已经继承自某一实现类。
4、inner class可以说是多重继承问题的完整解决方案。
inner class 可 “继承自多个具象或抽象类”。
一个类不能继承自多个一般类。但我们可以让其内部的多个innerclass各自继承某一实现类达到类似的目的。
40,A.非抽象类继承抽象类,必须将抽象类中的方法重写,否则需将方法再次申明为抽象。所以这个方法还可再次声明为抽象,而不用重写。而用重载也错了,重载是在同一个类中,重写、覆盖才是在父子类中。
B.抽象类可以没有抽象方法,接口是完全的抽象,只能出现抽象方法。
C.抽象类无法实例化,无法创建对象。现实生活中也有抽象类的类子,比如说人类是一个抽象类,无法创建一个叫人类的对象,人继承人类来创建对象。况且抽象类中的抽象方法只有声明,没有主体,如果实例化了,又如何去实现调用呢?
D因为类是单继承的,类继承了一个抽象类以后,就不能再继承其他类了。
41,web容器:给处于其中的应用程序组件(JSP,SERVLET)提供一个环境,使 JSP,SERVLET直接更容器中的环境变量接**互,不必关注其它系统问题。主要有WEB服务器来实现。例如:TOMCAT,WEBLOGIC,WEBSPHERE等。该容器提供的接口严格遵守J2EE规范中的WEB APPLICATION 标准。我们把遵守以上标准的WEB服务器就叫做J2EE中的WEB容器。
EJB容器:Enterprise java bean 容器。更具有行业领域特色。他提供给运行在其中的组件EJB各种管理功能。只要满足J2EE规范的EJB放入该容器,马上就会被容器进行高效率的管理。并且可以通过现成的接口来获得系统级别的服务。例如邮件服务、事务管理。
JNDI:(Java Naming & Directory Interface)JAVA命名目录服务。主要提供的功能是:提供一个目录系,让其它各地的应用程序在其上面留下自己的索引,从而满足快速查找和定位分布式应用程序的功能。
JMS:(Java Message Service)JAVA消息服务。主要实现各个应用程序之间的通讯。包括点对点和广播。
JTA:(Java Transaction API)JAVA事务服务。提供各种分布式事务服务。应用程序只需调用其提供的接口即可。
JAF:(Java Action FrameWork)JAVA安全认证框架。提供一些安全控制方面的框架。让开发者通过各种部署和自定义实现自己的个性安全控制策略。
RMI/IIOP:(Remote Method Invocation /internet对象请求中介协议)他们主要用于通过远程调用服务。例如,远程有一台计算机上运行一个程序,它提供股票分析服务,我们可以在本地计算机上实现对其直接调用。当然这是要通过一定的规范才能在异构的系统之间进行通信。RMI是JAVA特有的。
图2
42,运行时异常: 都是RuntimeException类及其子类异常,如NullPointerException(空指针异常)、IndexOutOfBoundsException(下标越界异常)等,这些异常是不检查异常,程序中可以选择捕获处理,也可以不处理。这些异常一般是由程序逻辑错误引起的,程序应该从逻辑角度尽可能避免这类异常的发生。
运行时异常的特点是Java编译器不会检查它,也就是说,当程序中可能出现这类异常,即使没有用try-catch语句捕获它,也没有用throws子句声明抛出它,也会编译通过。
非运行时异常 (编译异常): 是RuntimeException以外的异常,类型上都属于Exception类及其子类。从程序语法角度讲是必须进行处理的异常,如果不处理,程序就不能编译通过。如IOException、SQLException等以及用户自定义的Exception异常,一般情况下不自定义检查异常。
图
43,含有abstract修饰符的class即为抽象类,abstract类不能创建的实例对象。含有abstract方法的类必须定义为abstract class,abstract class类中的方法不必是抽象的。abstract class类中定义抽象方法必须在具体(Concrete)子类中实现,所以,不能有抽象构造方法或抽象静态方法。如果的子类没有实现抽象父类中的所有抽象方法,那么子类也必须定义为abstract类型。
接口(interface)可以说成是抽象类的一种特例,接口中的所有方法都必须是抽象的。接口中的方法定义默认为public abstract类型,接口中的成员变量类型默认为public staticfinal。
下面比较一下两者的语法区别:
1.抽象类可以有构造方法,接口中不能有构造方法。
2.抽象类中可以有普通成员变量,接口中没有普通成员变量
3.抽象类中可以包含非抽象的普通方法,接口中的所有方法必须都是抽象的,不能有非抽象的普通方法。
4. 抽象类中的抽象方法的访问类型可以是public,protected和(默认类型,虽然
eclipse下不报错,但应该也不行),但接口中的抽象方法只能是public类型的,并且默认即为public abstract类型。
5. 抽象类中可以包含静态方法,接口中不能包含静态方法
6. 抽象类和接口中都可以包含静态成员变量,抽象类中的静态成员变量的访问类型可以任意,但接口中定义的变量只能是public static final类型,并且默认即为public staticfinal类型。
7. 一个类可以实现多个接口,但只能继承一个抽象类。
3月31号:
44,A、Semaphore:类,控制某个资源可被同时访问的个数;
B、ReentrantLock:类,具有与使用synchronized方法和语句所访问的隐式监视器锁相同的一些基本行为和语义,但功能更强大;
C、 Future:接口,表示异步计算的结果;
D、 CountDownLatch: 类,可以用来在一个线程中等待多个线程完成任务的类。
45, 1、答案选C。
a、它是个接口。
b、别的类都处理线程间的关系,处理并发机制,但该类只用于获取线程结果。
2、Future表示获取一个正在指定的线程的结果。对该线程有取消和判断是否执行完毕等操作。
3、CountDownLatch 是个锁存器,他表示我要占用给定的多少个线程且我优先执行,我执行完之前其他要使用该资源的都要等待。
4、 Semaphore,就像是一个许可证发放者,也想一个数据库连接池。证就这么多,如果池中的证没换回来,其他人就不能用。
5、 ReentrantLock 和synchronized一样,用于锁定线程。
46,B选项中J2SDK是编程工具,不是API.
C选项中 Appletviewer.exe 就是用来解释执行java applet应用程序的,简单理解就是没有main函数的继承applet类的java类。
D选项中 能被Appletviewer成功运行的java class文件没有main()方法
47,abstract修饰一个类,这个类肯定可以被继承,但是final类是不能继承的,所以有矛盾,肯定不能同时用
48,A一个类有多个构造方法便是重载的表现。重载参数列表不同。所以A是正确的。
B构造方法是在对象创建时就被调用,用于初始化。
C构造方法是给与之对应的对象进行初始化,初始化的动作只执行一次。
D构造方法必须与所在类的名称同名。
49,重载(overload)和重写(override)的区别:重载就是同一个类中,有多个方法名相同,但参数列表不同(包括参数个数和参数类型),与返回值无关,与权限修饰符也无关。调用重载的方法时通过传递给它们不同的参数个数和参数类型来决定具体使用哪个方法,这叫多态。
50,重写就是子类重写基类的方法,方法名,参数列表和返回值都必须相同,否则就不是重写而是重载。权限修饰符不能小于被重写方法的修饰符。重写方法不能抛出新的异常或者是比被重写方法声明更加宽泛的检查型异常。
51,Servlet 与 CGI 的比较
和CGI程序一样,Servlet可以响应用户的指令(提交一个FORM等等),也可以象CGI程序一样,收集用户表单的信息并给予动态反馈(简单的注册信息录入和检查错误)。
然而,Servlet的机制并不仅仅是这样简单的与用户表单进行交互。传统技术中,动态的网页建立和显示都是通过CGI来实现的,但是,有了Servlet,您可以大胆的放弃所有CGI(perl?php?甚至asp!),利用Servlet代替CGI,进行程序编写。
对比一:当用户浏览器发出一个Http/CGI的请求,或者说调用一个CGI程序的时候,服务器端就要新启用一个进程 (而且是每次都要调用),调用CGI程序越多(特别是访问量高的时候),就要消耗系统越多的处理时间,只剩下越来越少的系统资源,对于用户来说,只能是漫长的等待服务器端的返回页面了,这对于电子商务激烈发展的今天来说,不能不说是一种技术上的遗憾。
而Servlet充分发挥了服务器端的资源并高效的利用。每次调用Servlet时并不是新启用一个进程,而是在一个Web服务器的进程敏感词享和分离线程,而线程最大的好处在于可以共享一个数据源,使系统资源被有效利用。
对比二:传统的CGI程序,不具备平台无关性特征,系统环境发生变化,CGI程序就要瘫痪,而Servlet具备Java的平台无关性,在系统开发过程中保持了系统的可扩展性、高效性。
对比三:传统技术中,一般大都为二层的系统架构,即Web服务器+数据库服务器,导致网站访问量大的时候,无法克服CGI程序与数据库建立连接时速度慢的瓶颈,从而死机、数据库死锁现象频繁发生。而我们的Servlet有连接池的概念,它可以利用多线程的优点,在系统缓存中事先建立好若干与数据库的连接,到时候若想和数据库打交道可以随时跟系统”要”一个连接即可,反应速度可想而知。
51,A,Thread可以被继承,用于创建新的线程
B,Number类可以被继承,Integer,Float,Double等都继承自Number类
C,Double类的声明为
public final class Doubleextends NumberimplementsComparable
D,Math类的声明为
public final class Mathextends Object
不能被继承
E,ClassLoader可以被继承,用户可以自定义类加载器
4月2号:
52,finally一定会在return之前执行,但是如果finally使用了return或者throw语句,将会使trycatch中的return或者throw失效
53,A. ConcurrentHashMap使用ReentrantLock来保证线程安全。
B. HashMap没有实现Collection接口。
C. Array.asList方法返回java.util.Arrays.ArraytList对象。
D. SimpleDateFormat是线程不安全的。
54,java不允许单独的方法,过程或函数存在,需要隶属于某一类中。——AB错
java语言中的方法属于对象的成员,而不是类的成员。不过,其中静态方法属于类的成员。——C错
55,A:明显正确,不懂的可以去看看网上博客
B:throws是用来声明一个成员方法可能抛出的各种异常情况,错误!因为很多运行时异常,不会显示的抛出(当然你愿意的话,也可以,只不过你的代码会乱成翔)
C:final用于可以声明属性和方法,分别表示属性的不可变及方法的不可覆盖。不是方法的不可继承
D:throw是用来明确地抛出一个异常情况。错误,throw不仅仅可以抛出异常,还可以抛出Error以及Throwable.
56,我来普及下时间复杂度
一、时间复杂度
(1)时间频度
一个算法执行所耗费的时间,从理论上是不能算出来的,必须上机运行测试才能知道。但我们不可能也没有必要对每个算法都上机测试,只需知道哪个算法花费的时间多,哪个算法花费的时间少就可以了。并且一个算法花费的时间与算法中语句的执行次数成正比例,哪个算法中语句执行次数多,它花费时间就多。一个算法中的语句执行次数称为语句频度或时间频度。记为T(n)。
(2)时间复杂度
在刚才提到的时间频度中,n称为问题的规模,当n不断变化时,时间频度T(n)也会不断变化。但有时我们想知道它变化时呈现什么规律。为此,我们引入时间复杂度概念。
一般情况下,算法中基本操作重复执行的次数是问题规模n的某个函数,用T(n)表示,若有某个辅助函数f(n),使得当n趋近于无穷大时,T(n)/f(n)的极限值为不等于零的常数,则称f(n)是T(n)的同数量级函数。记作T(n)=O(f(n)),称O(f(n)) 为算法的渐进时间复杂度,简称时间复杂度。
在各种不同算法中,若算法中语句执行次数为一个常数,则时间复杂度为O(1),另外,在时间频度不相同时,时间复杂度有可能相同,如T(n)=n2+3n+4与T(n)=4n2+2n+1它们的频度不同,但时间复杂度相同,都为O(n2)。
按数量级递增排列,常见的时间复杂度有:
常数阶O(1),对数阶O(log2n),线性阶O(n),
线性对数阶O(nlog2n),平方阶O(n2),立方阶O(n3),…,
k次方阶O(nk),指数阶O(2n)。随着问题规模n的不断增大,上述时间复杂度不断增大,算法的执行效率越低。
2、空间复杂度
与时间复杂度类似,空间复杂度是指算法在计算机内执行时所需存储空间的度量。记作:
S(n)=O(f(n))
我们一般所讨论的是除正常占用内存开销外的辅助存储单元规模
二、常见算法时间复杂度:
O(1): 表示算法的运行时间为常量
O(n): 表示该算法是线性算法
O(㏒2n): 二分查找算法
O(n2): 对数组进行排序的各种简单算法,例如直接插入排序的算法。
O(n3): 做两个n阶矩阵的乘法运算
O(2n): 求具有n个元素集合的所有子集的算法
O(n!): 求具有N个元素的全排列的算法
优<—————————————-<劣
O(1)
三、算 法的时间复杂度(计算实例)
定义:如果一个问题的规模是n,解这一问题的某一算法所需要的时间为T(n),它是n的某一函数 T(n)称为这一算法的“时间复杂性”。
当输入量n逐渐加大时,时间复杂性的极限情形称为算法的“渐近时间复杂性”。
我们常用大O表示法表示时间复杂性,注意它是某一个算法的时间复杂性。大O表示只是说有上界,由定义如果f(n)=O(n),那显然成立f(n)=O(n^2),它给你一个上界,但并不是上确界,但人们在表示的时候一般都习惯表示前者。
此外,一个问题本身也有它的复杂性,如果某个算法的复杂性到达了这个问题复杂性的下界,那就称这样的算法是最佳算法。
“大O记法”:在这种描述中使用的基本参数是 n,即问题实例的规模,把复杂性或运行时间表达为n的函数。这里的“O”表示量级(order),比如说“二分检索是 O(logn)的”,也就是说它需要“通过logn量级的步骤去检索一个规模为n的数组”记法 O ( f(n) )表示当 n增大时,运行时间至多将以正比于 f(n)的速度增长。
这种渐进估计对算法的理论分析和大致比较是非常有价值的,但在实践中细节也可能造成差异。例如,一个低附加代价的O(n2)算法在n较小的情况下可能比一个高附加代价的 O(nlogn)算法运行得更快。当然,随着n足够大以后,具有较慢上升函数的算法必然工作得更快。
O(1)
Temp=i;i=j;j=temp;
以上三条单个语句的频度均为1,该程序段的执行时间是一个与问题规模n无关的常数。算法的时间复杂度为常数阶,记作T(n)=O(1)。如果算法的执行时 间不随着问题规模n的增加而增长,即使算法中有上千条语句,其执行时间也不过是一个较大的常数。此类算法的时间复杂度是O(1)。
O(n^2)
2.1. 交换i和j的内容
sum=0;(一次)
for(i=1;i<=n;i++) (n次 )
for(j=1;j<=n;j++) (n^2次 )
sum++; (n^2次)
解:T(n)=2n^2+n+1 =O(n^2)
2.2.
for (i=1;i
y=y+1; ①
for(j=0;j<=(2n);j++)
x++; ②
}
解: 语句1的频度是n-1
语句2的频度是(n-1)(2n+1)=2n^2-n-1
f(n)=2n^2-n-1+(n-1)=2n^2-2
该程序的时间复杂度T(n)=O(n^2).
O(n)
2.3.
a=0;
b=1;①
for (i=1;i<=n;i++) ②
{
s=a+b; ③
b=a; ④
a=s; ⑤
}
解: 语句1的频度:2,
语句2的频度:n,
语句3的频度:n-1,
语句4的频度:n-1,
语句5的频度:n-1,
T(n)=2+n+3(n-1)=4n-1=O(n).
O(log2n )
2.4.
i=1; ①
while (i<=n)
i=i2; ②
解: 语句1的频度是1,
设语句2的频度是f(n), 则:2^f(n)<=n;f(n)<=log2n
取最大值f(n)= log2n,
T(n)=O(log2n)
O(n^3)
2.5.
for(i=0;i
for(j=0;j
for(k=0;k
}
}
解:当i=m, j=k的时候,内层循环的次数为k当i=m时, j 可以取0,1,…,m-1 , 所以这里最内循环共进行了0+1+…+m-1=(m-1)m/2次所以,i从0取到n, 则循环共进行了: 0+(1-1)
我们还应该区分算法的最坏情况的行为和期望行为。如快速排序的最坏情况运行时间是 O(n^2),但期望时间是 O(nlogn)。通过每次都仔细地选择基准值,我们有可能把平方情况 (即O(n^2)情况)的概率减小到几乎等于 0。在实际中,精心实现的快速排序一般都能以 (O(nlogn)时间运行。
下面是一些常用的记法:
访问数组中的元素是常数时间操作,或说O(1)操作。一个算法如 果能在每个步骤去掉一半数据元素,如二分检索,通常它就取O(logn)时间。用strcmp比较两个具有n个字符的串需要O(n)时间 。常规的矩阵乘算法是O(n^3),因为算出每个元素都需要将n对 元素相乘并加到一起,所有元素的个数是n^2。
指数时间算法通常来源于需要求出所有可能结果。例如,n个元 素的集合共有2n个子集,所以要求出所有子集的算法将是O(2n)的 。指数算法一般说来是太复杂了,除非n的值非常小,因为,在 这个问题中增加一个元素就导致运行时间加倍。不幸的是,确实有许多问题 (如著名 的“巡回售货员问题” ),到目前为止找到的算法都是指数的。如果我们真的遇到这种情况,通常应该用寻找近似最佳结果的算法替代之。
57,首先要了解static的意思。
static表示“全局”或者“静态”的意思,用来修饰成员变量和成员方法,也可以形成静态static代码块,但是Java语言中没有全局变量的概念。
static变量在第一次使用的时候初始化,但只会有一份成员对象。
所以这里不仅可以调用,而且每一次调用都确实修改了x的值,也就是变化情况是这样的:
x=101
x=102
x=103
x=102
58,jar 将许多文件组合成一个jar文件
javac 编译
javadoc 它从程序源代码中抽取类、方法、成员等注释形成一个和源代码配套的API帮助文档。
javah 把java代码声明的JNI方法转化成C\C++头文件。JNI可参考java核心技术卷二第12章
59,定义数组,等号左边不能出现数字,也就是数组的不管什么大小 不能出现在左边
图
60,直接用欧陆词典翻译了。。。
为什么一个负责任的Java程序员想使用嵌套类?
为了让非常专门的类的代码与和它一起工作的类联系起来
为了支持产生特定事件的新的用户界面。
为了用Java知识给打动老板,到处使用嵌套类
使用嵌套类,其中有几个令人信服的理由:
加强封装—考虑两个顶级类,A和B,如果B需要访问A的private成员,通过在A类隐藏B类,那么即使A的成员声明为private,那么B也可以访问它们。更多的是,B本身也可以隐藏于外部。
更可读性,可维护性的代码—在顶级类里嵌套小类,让代码更靠近使用的地方。
61,一,进程:
较典型的定义:1进程是程序的一次执行。2进程是一个程序及其数据在处理机上顺序执行时所发生的活动。3.进程是具有独立功能的程序在一个数据集合上运行的过程,它是系统进行资源分配和调度的一个独立单位。
进程的特征:1动态性。2.并发性。3.独立性。4.异步性。
进程的三种基本状态:1.就绪(Ready)状态。2.执行(Running)状态。3.阻塞(Block)状态。
二,线程:
线程运行的三个状态:
1.执行状态,表示线程已经获得处理机而正在运行;
2.就绪状态,指线程已经具备了各种执行条件,只需再获得cpu即可立即执行;
3.阻塞状态,指线程在执行中因某件事受阻而处于暂停状态,例如,当一个线程执行从键盘读入数据的系统调用时,该线程就被阻塞。
三进程与线程的比较:
线程又称之为轻型进程(Light-Weight Process);传统进程称为重型进程(Heavy-WeightProcess)。它相当于只有一个线程的任务。
1调度的基本单位。传统OS中,进程是作为独立调度和分配的基本单位,因而进程是能独立运行的基本单位。而在引入线程的OS中,已经把线程是作为独立调度和分配的基本单位,因而线程是能独立运行的基本单位。在同一进程中,线程的切换不会引起进程的切换,但从一个进程中的线程切换到另一个进程中的线程时,必然会引起进程的切换。
2.并发性。在引入线程的OS中,不仅进程之间可以并发执行,而且一个进程中的多个线程之间亦可以并发执行,甚至还允许在一个进程中的所有线程都能并发执行。同样,不同进程中的线程也能并发执行。这使得OS具有更好的并发性,从而能更加有效地提高系统资源的利用率和系统的吞吐量。
此外,有的应用程序需要执行多个相似的任务。
3.拥有资源。进程可以拥有资源,并作为系统中拥有资源的一个基本单位。然而,线程本身并不拥有系统资源,而是仅有一点必不可少的、能保证独立运行的资源。
线程除了拥有自己少量的资源外,还允许多个线程共享该进程所拥有的资源。
4.独立性。
5.系统开销。
6.支持多处理机系统。
62,4.同一进程中的不同线程之间的独立性要比不同进程之间的独立性低的多。
5.在创建或撤销进程时,系统都要为之分配和回收进程控制块、分配或回收其他资源,如内存空间和I/o设备等。OS为此所付出的开销,明显大于线程创建或撤销时所付出的开销。类似地,在进程切换时,涉及到进程上下文的切换,而线程的切换代价远低于进程的。此外,由于一个进程中的多个线程具有相同的地址空间,线程之间的同步和通信也比进程的简单。因此,在一些OS中,线程的切换、同步和通信都无需操作系统内核的干预。
6.传统的进程,即单线程进程,不管有多少处理机,该进程只能运行在一个处理机上。但对于多线程进程,就可以将一个进程中的多个线程分配到多个处理机上,使它们并行执行,这无疑将加速进程的完成。因此,现代多处理机OS都无一例外地引入了多线程。
4月7号:
63,方法调用时,会创建栈帧在栈中,调用完是程序自动出栈释放,而不是gc释放
64,这个类虽然继承了Thread类,但是并没有真正创建一个线程。
创建一个线程需要覆盖Thread类的run方法,然后调用Thread类的start()方法启动
这里直接调用run()方法并没有创建线程,跟普通方法调用一样,是顺序执行的
图2
65,exception是JSP九大内置对象之一,其实例代表其他页面的异常和错误。只有当页面是错误处理页面时,即isErroePage为 true时,该对象才可以使用。对于C项,errorPage的实质就是JSP的异常处理机制,发生异常时才会跳转到 errorPage指定的页面,没必要给errorPage再设置一个errorPage。所以当errorPage属性存在时, isErrorPage属性值为false
66,记住一句话,synchronized很强大,既可以保证可见性,又可以保证原子性,而volatile只能保证可见性,不能保证原子性!
67,构造方法每次都是构造出新的对象,不存在多个线程同时读写同一对象中的属性的问题,所以不需要同步 。
如果父类中的某个方法使用了 synchronized关键字,而子类中也覆盖了这个方法,默认情况下子类中的这个方法并不是同步的,必须显示的在子类的这个方法中加上 synchronized关键字才可。当然,也可以在子类中调用父类中相应的方法,这样虽然子类中的方法并不是同步的,但子类调用了父类中的同步方法,也就相当子类方法也同步了。详见:http://blog.csdn.net/welcome000yy/article/details/8941644
接口里面的变量为常量,其实际是 public static final ;接口里面的方法为抽象方法,其实际是publicabstract。
68,-Xmx10240m:代表最大堆
-Xms10240m:代表最小堆
-Xmn5120m:代表新生代
-XXSurvivorRatio=3:代表Eden:Survivor =3 根据Generation-Collection算法(目前大部分JVM采用的算法),一般根据对象的生存周期将堆内存分为若干不同的区域,一般情况将新生代分为Eden ,两块Survivor;计算Survivor大小,Eden:Survivor = 3,总大小为5120,3x+x+x=5120 x=1024
新生代大部分要回收,采用Copying算法,快!
老年代 大部分不需要回收,采用Mark-Compact算法
69,-Xmx:最大堆大小
-Xms:初始堆大小
-Xmn:年轻代大小
-XXSurvivorRatio:年轻代中Eden区与Survivor区的大小比值
年轻代5120m, Eden:Survivor=3,Survivor区大小=1024m(Survivor区有两个,即将年轻代分为5份,每个Survivor区占一份),总大小为2048m。
-Xms初始堆大小即最小内存值为10240m
70,目前的问题:父类的功能无法满足子类的需求。
方法重写的前提:必须要存在继承的关系。
方法的重写: 子父类出了同名的函数,这个我们就称作为方法的重写。
什么是时候要使用方法的重写:父类的功能无法满足子类的需求时。
方法重写要注意的事项:
1.方法重写时, 方法名与形参列表必须一致。
2.方法重写时,子类的权限修饰符必须要大于或者等于父类的权限修饰符。
3.方法重写时,子类的返回值类型必须要小于或者 等于父类的返回值类型。
4.方法重写时, 子类抛出的异常类型要小于或者等于父类抛出的异常类型。
Exception(最坏)
RuntimeException(小坏)
方法的重载:在一个类中存在两个或者两个 以上的同名函数,称作为方法重载。
方法重载的要求
1. 函数名要一致。
2. 形参列表不一致(形参的个数或形参 的类型不一致)
3. 与返回值类型无关。
71,解析:Webservice是跨平台,跨语言的远程调用技术;
它的通信机制实质就是xml数据交换;
它采用了soap协议(简单对象协议)进行通信
72,Web service顾名思义是基于web的服务,它是一种跨平台,跨语言的服务。
我们可以这样理解它,比如说我们可以调用互联网上查询天气信息的web服务,把它嵌入到我们的B/S程序中,当用户从我们的网点看到天气信息时,会认为我们为他提供很多的服务,但其实我们什么也没做,只是简单的调用了一下服务器上的一端代码而已。Web service 可以将你的服务发布到互联网上让别人去调用,也可以调用别人发布的webservice,和使用自己的代码一样。
它是采用XML传输格式化的数据,它的通信协议是SOAP(简单对象访问协议).
73,WSDL 指网络服务描述语言(Web Services Description Language)。
WSDL 是一种使用 XML 编写的文档。这种文档可描述某个 Web service。它可规定服务的位置,以及此服务提供的操作(或方法)
74,1.session用来表示用户会话,session对象在服务端维护,一般tomcat设定session生命周期为30分钟,超时将失效,也可以主动设置无效; 2.cookie存放在客户端,可以分为内存cookie和磁盘cookie。内存cookie在浏览器关闭后消失,磁盘cookie超时后消失。当浏览器发送请求时,将自动发送对应cookie信息,前提是请求url满足cookie路径; 3.可以将sessionId存放在cookie中,也可以通过重写url将sessionId拼接在url。因此可以查看浏览器cookie或地址栏url看到sessionId; 4.请求到服务端时,将根据请求中的sessionId查找session,如果可以获取到则返回,否则返回null或者返回新构建的session,老的session依旧存在,请参考API。 以上是个人总结,请多指教。
75,Java的跨平台特性是因为JVM的存在,它可以执行.class字节码文件,而不是.java源代码
76,switch语句后的控制表达式只能是short、char、int、long整数类型和枚举类型,不能是float,double和boolean类型。String类型是java7开始支持。
77,方法的重写(override)两同两小一大原则:
方法名相同,参数类型相同
子类返回类型小于等于父类方法返回类型,
子类抛出异常小于等于父类方法抛出异常,
子类访问权限大于等于父类方法访问权限。
78,一个算法应该具有以下五个重要的特征:
1、有穷性(Finiteness)
算法的有穷性是指算法必须能在执行有限个步骤之后终止
2、确切性(Definiteness)
算法的每一步骤必须有确切的定义;
3、输入项(Input)
一个算法有0个或多个输入,以刻画运算对象的初始情况,所谓0个输入是指算法本身定出了初始条件;
4、输出项(Output)
一个算法有一个或多个输出,以反映对输入数据加工后的结果.没有输出的算法是毫无意义的;
5、可行性(Effectiveness)
算法中执行的任何计算步都是可以被分解为基本的可执行的操作步,即每个计算步都可以在有限时间内完成.(也称之为有效性)
79,原来空间复杂度指的是额外的空间呀。。。
百度百科:空间复杂度(Space Complexity)是对一个算法在运行过程中临时占用存储空间大小的量度,记做S(n)=O(f(n))。比如直接 插入排序 的 时间复杂度 是O(n^2),空间复杂度是O(1) 。而一般的 递归 算法就要有O(n)的空间复杂度了,因为每次递归都要存储返回信息。一个算法的优劣主要从算法的执行时间和所需要占用的存储空间两个方面衡量 。
80,选择排序中涉及到交换位置,因此是不稳定的排序算法,
选择排序的核心思想是从未排序数列中找到最小的数,和未排序数列中的首位交换位置,继而继续执行以上操作
81,1、基于比较的排序算法有:(1)直接插入排序;(2)冒泡排序;(3)简单选择排序;(4)希尔排序;(5)快速排序;(6)堆排序;(7)归并排序。
2、基数排序、桶排序都属于分配式排序,且都是稳定排序算法。
82,length 返回浏览器历史列表中的URL数量
back() 加载 history 列表中的前一个URL
forward() 加载 history 列表中的下一个URL
go() 加载history列表中的某个具体页面。
83,SNMP:(Simple Network Management Protocol)简单网络管理协议, 是专门设计用于在 IP 网络管理网络节点(服务器、工作站、路由器、交换机及HUBS等)的一种标准协议,它是一种应用层协议。 SNMP 使网络管理员能够管理网络效能,发现并解决网络问题以及规划网络增长。通过 SNMP 接收随机消息(及事件报告)网络管理系统获知网络出现问题。 SNMP是一系列协议组和规范,它们提供了一种从网络上的设备中收集网络管理信息的方法,也为设备向网络管理工作站报告问题和错误提供了一种方法。
SNMP基于传输层UDP用户数据报协议,在管理者和被管理设备(确切的说是agent)之前传递信息。
SNMP管理包括下面三个部分:
1.MIB管理信息库
2.SMI管理信息的结构和标识(也称管理信息接口SMI)
3.SNMP简单网络管理协议
84,BTREE索引和 HASH 索引的差异:
(1)HASH索引只用于使用 = 或 <=> 操作符的等式比较。如果一定要使用范围查询 的话,只能使用BTREE索引。
(2)优化器不能使用 Hash 索引来加速order by 操作。
(3)使用 Hash 索引时 MySQL 不能确定在两个值之间大约有多少行。如果将一个MyISAM表改为的 Hash 索引 memory 表,
会影响一些查询的执行效率。
(4)Hash索引只能使用整个关键字来搜索一行。
85,HASH索引:利用哈希函数,计算存储地址,检索时不需要像Btree那样,从根节点开始遍历,逐级查找。
优点: 查找效率高。(C选项)
局限:
仅仅满足=,in,<=>,查询,不能范围查询(原先有序的键值经过哈希函数运算,可能不再连续);(A选项)
无法用于排序操作(order by);(B选项)
当重复值时,效率并不比BTree高;
不能利用部分索引键查询;(D选项)
86,1、在MySQL中,关于HASH索引,描述正确的有:(1)只用于使用=或者< = >操作符的等式比较;(2)优化器不能使用HASH索引来加速OrderBy操作;(3)只能使用整个关键字来索引 一行。
2、BTREE索引和HASH索引的差异:
(1)HASH索引只用于使用=或<=>操作符的等式比较。如果一定要使用范围查询的话,只能使用BTREE索引。
(2)优化器不能使用Hash索引来加速OrderBy 操作。
(3)使用Hash索引时,MySQL不能确定在两个值之间大约有多少行。如果将一个MyISAM表改为Hash索引memory表,会影响一些查询的执行效率。
(4)Hash索引只能使用整个关键字来索引一行。
87,DHCP 有 8 种消息类型,分别是 Discover、Request、Release、Inform、Decline、Offer、ACK、NAK。
其中前 5 种可由主机发起,后 3 种只能是DHCP 服务端向主机发送,故 AB 正确。
88,以下关于读屏障、写屏障、通用屏障和 优化屏障说法正确的有:
(1)读屏障用于保证读操作有序。屏障之前的读操作一定会优于屏障之后的读操作完成,写操作不受影响;
(2)优化屏障则用于限制编译器的指令重排;
(3)通用屏障对读写操作都有作用;
(4)注意:写屏障只能限制写操作,读操作不受影响。
89,Yahoo! User Interface 库 (YUI) 包含一个 bucketload 。
和 YUI 一样, ExtJS 包含大量开箱即用的组件,其中有很多功能强大的网格控件,支持内联编辑、分页、筛选、分组、汇总、缓冲和数据绑定。
MooTools 和 Prototype 、 jQuery 不包含开箱即用的 UI 控件和小部件.
因此答案应该是AC
90,一般在文件系统建立aquoto.user文件是这样的:
# touch /home/aquota.user
# chmod 600 /aquota.user
所以是600
91,软件生命期一般包括以下各阶段:
·软件计划与可行性研究(问题定义、可行性研究)
·需求分析
·软件设计(概要设计和详细设计)
·编码
·软件测试
·运行与维护
92,onBlur:文本域失去焦点
onFocus:得到焦点
onchange:焦点状态改变
93,Margin(外边距) -清除边框外的区域,外边距是透明的。
Border(边框) - 围绕在内边距和内容外的边框。
Padding(内边距) - 清除内容周围的区域,内边距是透明的。
Content(内容) - 盒子的内容,显示文本和图像。
Margin
margin清除周围的元素(外边框)的区域。margin没有背景颜色,是完全透明的
Padding(填充)
当元素的 Padding(填充)(内边距)被清除时,所”释放”的区域将会受到元素背景颜色的填充。
4月8号:
94,根据《Introduction to Java Programming》原书第10版277页,“构造方法是一种特殊的方法:
它必须具备和所在类相同的名字;
没有返回值类型,甚至连void也没有;
构造方法是在创建一个对象使用new操作符时调用的,作用是初始化对象。”
以及第278页:“一个类可以不定义构造方法,在这种情况下,类中隐含定义一个方法体为空的无参构造方法。这个构造方法称为默认构造方法,当且仅当类中没有明确定义任何构造方法时才会自动提供它。”这里说明构造方法可以默认提供而不显式定义。
而类必须有构造方法来初始化用;可见性修饰符方面,使用private也是可以的,能有一些特殊的作用比如在单例模式下。
95,构造方法 必须满足以下语法规则:
(1)方法名必须与类名相同;
(2)不要声明返回类型;
(3)不能被static、final、synchronized、abstract和native修饰;
(4)构造方法用final和abstract修饰没有意义。
96,a是类中的成员变量,存放在堆区
b、c都是方法中的局部变量,存放在栈区
97,堆区:只存放类对象,线程共享;
方法区:又叫静态存储区,存放class文件和静态数据,线程共享;
栈区:存放方法局部变量,基本类型变量区、执行环境上下文、操作指令区,线程不共享;
98,常量区:未经 new 的常量
堆区:成员变量的引用,new 出来的变量
栈区:局部变量的引用
classA{ privateString a = “aa”; // a 为成员变量的引用,在堆区,“aa”为未经 new 的常量,在常量区 publicboolean methodB() {String b = “bb”; // b 为局部变量的引用,在栈区,“bb”为未经 new 的常量,在常量区final String c = “cc”; // c 为局部变量的引用,在栈区,“cc”为未经 new 的常量,在常量区} }
图3
99,Java通过方法重写和方法重载实现多态
方法重写是指子类重写了父类的同名方法
方法重载是指在同一个类中,方法的名字相同,但是参数列表不同
100,应该是AC,即是堆和字符串常量池中,当你new String(“abc”)时,其实会先在字符串常量区生成一个abc的对象,然后new String()时会在堆中分配空间,然后此时会把字符串常量区中abc复制一个给堆中的String,故abc应该在堆中和字符串常量区
101,java中的数据类型分类:
基本数据类型(或叫做原生类、内置类型)8种:
整数:byte,short,int,long(默认是int类型)
浮点类型: float,double(默认是double类型)
字符类型:char
布尔类型:boolean
引用数据类型3种:数组,类,接口
其中,基本数据类型之间除了boolean,其他数据类型之间可以任意的相互转换(强制转化或默认转换),这个与c++中有点区别。
个人认为c定义数组的方式是正确的,只不过少了一个分号。java中定义数组有两种方式,一种是int[ ] number,一种是int number[ ],推荐第一种,可读性更高。
102,Java中的那些基本类型属于原生类,而数组是引用类型,不属于原生类,可以看成是一种对象。
而C中的数组声明和初始化的格式不对
数组的大小一旦指定,就不可以进行改变。
103,run()方法用来执行线程体中具体的内容
start()方法用来启动线程对象,使其进入就绪状态
sleep()方法用来使线程进入睡眠状态
suspend()方法用来使线程挂起,要通过resume()方法使其重新启动
104,A是静态方法,可以直接用如下形式调用 Test.method();
B是普通public方法,必须实例化类,Testtest = new Test(); test.method();
C是protected方法,用法同B,只是对于其他的外部class,protected就变成private;
D是抽象方法,必须被子类继承并重写,然后调用的方式同B。
105,Hashtable不允许null 值(key 和 value 都不可以),HashMap允许 null 值(key和value都可以)。 ArrayList和LinkedList均实现了List接口
ArrayList基于数组实现,随机访问更快
LinkedList基于链表实现,添加和删除更快
图3
106,Collection主要的子接口:
List:可以存放重复内容
Set:不能存放重复内容,所有重复的内容靠hashCode()和equals()两个方法区分
Queue:队列接口
SortedSet:可以对集合中的数据进行排序
Map没有继承Collection接口,Map提供key到value的映射。一个Map中不能包含相同的key,每个key只能映射一个value。Map接口提供3种集合的视图,Map的内容可以被当作一组key集合,一组value集合,或者一组key-value映射。
107,a选项linkedlist类是实现了List接口,而不是继承
b选项AbstractSet类实现Set接口
c选项HashSet继承AbstractSet类,同时也实现set
d选项WeakMap是js里面的玩意儿吧,,不太懂
108,这道题其实只要把java集合框架给看了,就一目了然了。
首先这道题很多人都对接口以及抽象实现类认识混乱。
A.LinkedList是继承自AbstractSequentialList(抽象类,实现了List接口)的,并且实现了List接口。所以A错误。
B.AbstractSet是实现了Set接口的,本身是一个抽象类。继承自AbstractCollection(抽象类,实现了Collection接口)。所以B错误。
C.HashSet是继承自AbstractSet,实现了Set接口。所以C正确。
D.WeakMap不存在于java集合框架的。只有一个叫做WeakHashMap(继承自AbstractMap)。
图2
109,解析copy自网友tihualong
goto和const是保留字也是关键字。
1,Java 关键字列表 (依字母排序共50组):
abstract, assert, boolean, break, byte, case, catch, char, class,const(保留关键字), continue, default, do, double, else,enum, extends, final, finally, float, for, goto(保留关键字),if, implements, import, instanceof, int, interface, long, native, new, package,private, protected, public, return, short, static, strictfp, super, switch,synchronized, this, throw, throws, transient, try, void, volatile, while
2,保留字列表 (依字母排序 共14组),Java保留字是指现有Java版本尚未使用,但以后版本可能会作为关键字使用:
byValue, cast, false, future, generic, inner, operator, outer, rest,true, var, goto (保留关键字) , const (保留关键字) , null
110,——————知识点——————
Java表达式转型规则由低到高转换:
1、所有的byte,short,char型的值将被提升为int型;
2、如果有一个操作数是long型,计算结果是long型;
3、如果有一个操作数是float型,计算结果是float型;
4、如果有一个操作数是double型,计算结果是double型;
5、被fianl修饰的变量不会自动改变类型,当2个final修饰相操作时,结果会根据左边变量的类型而转化。
———————解析———————
语句1错误:b3=(b1+b2);自动转为int,所以正确写法为b3=(byte)(b1+b2);或者将b3定义为int;
语句2正确:b6=b4+b5;b4、b5为final类型,不会自动提升,所以和的类型视左边变量类型而定,即b6可以是任意数值类型;
语句3错误:b8=(b1+b4);虽然b4不会自动提升,但b1仍会自动提升,所以结果需要强转,b8=(byte)(b1+b4);
语句4错误:b7=(b2+b5); 同上。同时注意b7是final修饰,即只可赋值一次,便不可再改变。
111,HashMap的底层是由数组加链表实现的,对于每一个key值,都需要计算哈希值,然后通过哈希值来确定顺序,并不是按照加入顺序来存放的,因此可以认为是无序的,但不管是有序还是无序,它都一个自己的顺序。故A错。
最开始有Hashtable,Hashtable是不允许key和value的值为空的,但后来开发者认为有时候也会有key值为空的情况,因为可以允许null为空,通过查看HashMap的源代码就知道:if(key = null){putForNullKey(value);};
Map底层都是用key/value键值对的形式存放的
112,abstract可以修饰方法和类,不能修饰属性。抽象方法没有方法体,即没有大括号{}
113,C.混合赋值运算符的使用
<<表示左移位
>>表示带符号右移位
>>>表示无符号右移
但是没有<<<运算符
114,鲁棒性(Robust,即健壮性)
Java在编译和运行程序时,都要对可能出现的问题进行检查,以消除错误的产生。它提供自动垃圾收集来进行内存管理,防止程序员在管理内存时容易产生的错误。通过集成的面向对象的例外处理机制,在编译时,Java揭示出可能出现但未被处理的例外,帮助程序员正确地进行选择以防止系统的崩溃。另外, Java在编译时还可捕获类型声明中的许多常见错误,防止动态运行时不匹配问题的出现。
感觉B选项虽然描述也对,但是,不应该把它归结于鲁棒性,B选项主要是体现Java的由于虚拟机,实现了一次编译,到处运行,跨平台性的特点。因此,我选B。
115,静态变量只能在类主体中定义,不能在方法中定义
116,final修饰的成员变量为基本数据类型是,在赋值之后无法改变。当final修饰的成员变量为引用数据类型时,在赋值后其指向地址无法改变,但是对象内容还是可以改变的。
final修饰的成员变量在赋值时可以有三种方式。1、在声明时直接赋值。2、在构造器中赋值。3、在初始代码块中进行赋值。
117,final修饰的方法,不允许被子类覆盖。
final修饰的类,不能被继承。
final修饰的变量,不能改变值。
final修饰的引用类型,不能再指向别的东西,但是可以改变其中的内容。
118,1.静态代码块 2.构造代码块3.构造方法的执行顺序是1>2>3;明白他们是干嘛的就理解了。
1.静态代码块:是在类的加载过程的第三步初始化的时候进行的,主要目的是给类变量赋予初始值。
2.构造代码块:是独立的,必须依附载体才能运行,Java会把构造代码块放到每种构造方法的前面,用于实例化一些共有的实例变量,减少代码量。
3.构造方法:用于实例化变量。
1是类级别的,2、3是实例级别的,自然1要优先23.
在就明白一点:对子类得主动使用会导致对其父类得主动使用,所以尽管实例化的是子类,但也会导致父类的初始化和实例化,且优于子类执行。
119,其中涉及:静态初始化代码块、构造代码块、构造方法
当涉及到继承时,按照如下顺序执行:
1、执行父类的静态代码块
static {
System.out.println(“static A”);
}
输出:static A
2、执行子类的静态代码块
static {
System.out.println(“static B”);
}
输出:static B
3、执行父类的构造代码块
{
System.out.println(“I’m A class”);
}
输出:I’m A class
4、执行父类的构造函数
public HelloA() {
}
输出:无
5、执行子类的构造代码块
{
System.out.println(“I’m B class”);
}
输出:I’m B class
6、执行子类的构造函数
public HelloB() {
}
输出:无
那么,最后的输出为:
static A
static B
I’m A class
I’m B class
正确答案:C
120,只要记住,不论怎样,必定先执行静态代码,子由父生,所以父类必先执行,由此可以筛选出答案C
121,A.java用来运行一个.class文件
B.javadoc用来生成api文档
C.jar用来生成jar包
D.javac用来把.java文件编译为.class文件
122,线程安全概念:
如果你的代码所在的进程中有多个线程在同时运行,而这些线程可能会同时运行这段代码。如果每次运行结果和单线程运行的结果是一样的,而且其他的变量的值也和预期的是一样的,就是线程安全的。
线程安全问题都是由全局变量及静态变量引起的。
若每个线程中对全局变量、静态变量只有读操作,而无写操作,一般来说,这个全局变量是线程安全的;若有多个线程同时执行写操作,一般都需要考虑线程同步,否则的话就可能影响线程安全。
图
LinkedList 和 ArrayList 都是不同步的,线程不安全; Vector 和 Stack 都是同步的,线程安全; Set是线程不安全的; Hashtable的方法是同步的,线程安全; HashMap的方法不是同步的,线程不安全;
123,简单记忆线程安全的集合类: 喂! SHE ! 喂是指 vector , S 是指 stack , H 是指 hashtable , E 是指: Eenumeration
124,两个最基本的java回收算法:复制算法和标记清理算法
复制算法:两个区域A和B,初始对象在A,继续存活的对象被转移到B。此为新生代最常用的算法
标记清理:一块区域,标记可达对象(可达性分析),然后回收不可达对象,会出现碎片,那么引出
标记-整理算法:多了碎片整理,整理出更大的内存放更大的对象
两个概念:新生代和年老代
新生代:初始对象,生命周期短的
永久代:长时间存在的对象
整个java的垃圾回收是新生代和年老代的协作,这种叫做分代回收。
P.S:Serial New收集器是针对新生代的收集器,采用的是复制算法
Parallel New(并行)收集器,新生代采用复制算法,老年代采用标记整理
Parallel Scavenge(并行)收集器,针对新生代,采用复制收集算法
Serial Old(串行)收集器,新生代采用复制,老年代采用标记整理
Parallel Old(并行)收集器,针对老年代,标记整理
CMS收集器,基于标记清理
G1收集器:整体上是基于标记 整理 ,局部采用复制
综上:新生代基本采用复制算法,老年代采用标记整理算法。cms采用标记清理。
125,您好, Serial Old(串行)收集器应该是标记整理,G1也是标记整理
126,System.out.println(1+”10”+3+”2”);//11032System.out.println(1+2+”10”+3+”2”);//31032System.out.println(1+”10”+3+1+”2”);//110312 注意“+”的两边的类型
127,应该是:public>protected>默认(包访问权限)>private,因为protected除了可以被同一包访问,还可以被包外的子类所访问
图
128,默认值取值范围 示例
字节型 : 0 -2^7—-2^7-1 byte b=10;
字符型 : ‘ \u0000′ 0—-2^16-1char c=’c’ ;
short : 0 -2^15—-2^15-1 short s=10;
int : 0 -2^31—-2^31-1 int i=10;
long : 0 -2^63—-2^63-1long o=10L;
float : 0.0f -2^31—-2^31-1 float f=10.0F
double : 0.0d -2^63—-2^63-1 double d=10.0;
boolean: false true\false boolean flag=true;
129,建议看看这篇博客 入门 通俗易懂 http://blog.csdn.net/sivyer123/article/details/17139443
简单的来说 java的堆内存分为两块:permantspace(持久带) 和 heap space。
持久带中主要存放用于存放静态类型数据,如 Java Class, Method 等, 与垃圾收集器要收集的Java对象关系不大。
而heapspace分为年轻带和年老带
年轻代的垃圾回收叫 Young GC, 年老代的垃圾回收叫 Full GC。
在年轻代中经历了N次(可配置)垃圾回收后仍然存活的对象,就会被复制到年老代中。因此,可以认为年老代中存放的都是一些生命周期较长的对象
年老代溢出原因有 循环上万次的字符串处理、创建上千万个对象、在一段代码内申请上百M甚至上G的内存,既A B D选项
持久代溢出原因 动态加载了大量Java类而导致溢出
4月9号:
130,静态成员变量未被final时,它的值可以被更改;所以t.a = 2;
131,先来看一段代码:
public abstract class Test { public staticvoid main(String[] args) {System.out.println(beforeFinally());} publicstatic int beforeFinally(){ inta = 0; try{a = 1;returna; }finally{a = 2;} } }/output: 1 */从结果上看,貌似finally 里的语句是在return 之后执行的,其实不然,实际上finally 里的语句是在在return 之前执行的。那么问题来了,既然是在之前执行,那为什么a 的值没有被覆盖了?
实际过程是这样的:当程序执行到try{}语句中的return方法时,它会干这么一件事,将要返回的结果存储到一个临时栈中,然后程序不会立即返回,而是去执行finally{}中的程序, 在执行a = 2时,程序仅仅是覆盖了a的值,但不会去更新临时栈中的那个要返回的值 。执行完之后,就会通知主程序“finally的程序执行完毕,可以请求返回了”,这时,就会将临时栈中的值取出来返回。这下应该清楚了,要返回的值是保存至临时栈中的。
再来看一个例子,稍微改下上面的程序:
public abstract class Test { public staticvoid main(String[] args) {System.out.println(beforeFinally());}public static int beforeFinally(){int a = 0;try{a = 1;returna; }finally{a = 2;returna; } } }/output: 2 /在这里,finally{}里也有一个return,那么在执行这个return时,就会更新临时栈中的值。同样,在执行完finally之后,就会通知主程序请求返回了,即将临时栈中的值取出来返回。故返回值是2.
132, StringBuffer a= newStringBuffer(“A”);
StringBuffer b= newStringBuffer(“B”);
此时内存中的状态如下图所示:

publicstaticvoidoperator(StringBuffer x, StringBuffer y) {
x.append(y); y = x;
}
进入如下方法后,内存中的状态为:

x.append(y);
这条语句执行后,内存的状态为:

y = x;
这条语句执行后,内存的状态为:

当operator方法执行完毕后内存中的状态为:因为方法执行完毕,局部变量消除。

有内存中的状态,可以知道最后的结果。
133,ServletContext对象:servlet容器在启动时会加载web应用,并为每个web应用创建唯一的servlet context对象,可以把ServletContext看成是一个Web应用的服务器端组件的共享内存,在ServletContext中可以存放共享数据。ServletContext对象是真正的一个全局对象,凡是web容器中的Servlet都可以访问。
整个web应用只有唯一的一个ServletContext对象
servletConfig对象:用于封装servlet的配置信息。从一个servlet被实例化后,对任何客户端在任何时候访问有效,但仅对servlet自身有效,一个servlet的ServletConfig对象不能被另一个servlet访问。
134,之前我一直有一个误区!就是认为静态块一定是最先初始化的!但是,阿里爸爸今天又用一记重拳猛击我的脸,额,好疼….当时的情况是这样的:
我在牛客网找虐中,碰到了这样的一道题,心中充满了鄙夷,心想”这tm还用看吗,肯定先是静态块,再接着三个构造块,弱鸡题”,但是 = = ,答案却是”构造块 构造块 静态块 构造块”.
……[黑线|||||||||] 于是总结了一下,以警后世 - -
正确的理解是这样的:
并不是静态块最先初始化,而是静态域.(BM:啊!多么痛的领悟!)
而静态域中包含静态变量、静态块和静态方法,其中需要初始化的是静态变量和静态块.而他们两个的初始化顺序是靠他们俩的位置决定的!
So!
初始化顺序是 t1 t2 静态块
135,A、final修饰的类为终态类,不能被继承,而抽象类是必须被继承的才有其意义的,因此,final是不能用来修饰抽象类的。
B、 final修饰的方法为终态方法,不能被重写。而继承抽象类,必须重写其方法。
C、抽象方法是仅声明,并不做实现的方法。
136,1、抽象类不能被实例化,实例化的工作应该交由它的子类来完成,它只需要有一个引用即可。
2、抽象方法必须由子类来进行重写。
3、只要包含一个抽象方法的类,该类必须要定义成抽象类,不管是否还包含有其他方法。
4、抽象类中可以包含具体的方法,当然也可以不包含抽象方法。
5、abstract不能与final并列修饰同一个类。
6、abstract 不能与private、static、final或native并列修饰同一个方法。、
137,编译器将Java源代码编译成字节码class文件
类加载到JVM里面后,执行引擎把字节码转为可执行代码
执行的过程,再把可执行代码转为机器码,由底层的操作系统完成执行。
138,1)不论有什么运算,小括号的优先级都是最高的,先计算小括号中的运算,得到x+y +””+25+y
2)任何字符与字符串相加都是字符串,但是是有顺序的,字符串前面的按原来的格式相加,字符串后面的都按字符串相加,得到25+“”+25+5
3)上面的结果按字符串相加得到25255
139,if(a+b!=c&&a
相信这个条件大家都知道怎么计算。
140,单目运算符:+,-,++,—
算数运算符:+,-,
移位运算符:<<,>>
关系运算符:>,<,>=,<=,==,!=
位运算符:&,|,~,^,
逻辑运算符:&&,||
三目运算符:表达式1?表达式2:表达式3;
赋值运算符:=等
141,括号>单元操作符>算术运算符>移位操作符>关系运算符>位运算符>逻辑运算符>三元操作符>赋值运算符
142,口诀:淡云一笔安洛三福 单目>算数运算符>移位>比较>按位>逻辑>三目>赋值
143,Spring Framework是一个开源的Java/Java EE全功能栈(full-stack)的应用程序框架,Spring中包含的关键特性:
1.强大的基于JavaBeans的采用控制翻转(Inversion of Control,IoC)原则的配置管理,使得应用程序的组建更加快捷简易。
2.一个可用于从applet到JavaEE等不同运行环境的核心Bean工厂。
数据库事务的一般化抽象层,允许声明式(Declarative)事务管理器,简化事务的划分使之与底层无关。
3.内建的针对JTA和单个JDBC数据源的一般化策略,使Spring的事务支持不要求Java EE环境,这与一般的JTA或者EJB CMT相反。
4.JDBC 抽象层提供了有针对性的异常等级(不再从SQL异常中提取原始代码),简化了错误处理,大大减少了程序员的编码量。再次利用JDBC时,你无需再写出另一个’终止’(finally)模块。并且面向JDBC的异常与Spring通用数据访问对象(Data Access Object)异常等级相一致。
5.以资源容器,DAO实现和事务策略等形式与Hibernate,JDO和iBATISSQL Maps集成。利用众多的翻转控制方便特性来全面支持,解决了许多典型的Hibernate集成问题。所有这些全部遵从Spring通用事务处理和通用数据访问对象异常等级规范。
6.灵活的基于核心Spring功能的MVC网页应用程序框架。开发者通过策略接口将拥有对该框架的高度控制,因而该框架将适应于多种呈现(View)技术,例如JSP、FreeMarker、Velocity、Tiles、iText以及POI。值得注意的是,Spring中间层可以轻易地结合于任何基于MVC框架的网页层,例如Struts、WebWork或Tapestry。
7.提供诸如事务管理等服务的面向方面编程框架。
另外,Spring并没有提供日志系统,我们需要使用AOP(面向方面编程)的方式,借助Spring与日志系统log4j实现我们自己的日志系统。
144,题目:总是为一个类提供了一个默认的构造函数是Java语言的一个重要特性。
事实上只有在我们没有显示声明任何构造方法时java才会为我们提供一个默认的无参构造函数。
145,查看javaapi文档会写两种创建新线程的方法 1.将类声明为thred类然后重写thred的run方法 2.声明实现runnable的接口的类实现run方法
图
146,Java锁的种类以及辨析 锁作为并发共享数据,保证一致性的工具,在JAVA平台有多种实现(如synchronized 和 ReentrantLock等等) 。这些已经写好提供的锁为我们开发提供了便利,但是锁的具体性质以及类型却很少被提及。本系列文章将分析JAVA中常见的锁以及其特性,为大家答疑解惑。
1、自旋锁 2、自旋锁的其他种类 3、阻塞锁 4、可重入锁 5、读写锁
6、互斥锁 7、悲观锁 8、乐观锁 9、公平锁 10、非公平锁
11、偏向锁 12、对象锁 13、线程锁 14、锁粗化 15、轻量级锁
16、锁消除 17、锁膨胀 18、信号量
147,方法重写应遵循“三同一小一大”原则:
“三同”:即方法名相同,形参列表相同,返回值类型相同;
“一小”:子类方法声明抛出的异常比父类方法声明抛出的异常更小或者相等;
“一大”:子类方法的访问修饰符应比父类方法更大或相等。
A选项是重写,但是默认访问修饰符比父类小,插入第五行编辑器会报错。
B、D不是重写。因为形参列表和返回值类型不同,不满足“三同”。所以写在第五行以普通方法对待,插入第五行没有错误。
C选项满足重写的各项条件,是正确的重写,所以插入第五行没有错误。
148,在说内联函数之前,先说说函数的调用过程。
调用某个函数实际上将程序执行顺序转移到该函数所存放在内存中某个地址,将函数的程序内容执行完后,再返回到
转去执行该函数前的地方。这种转移操作要求在转去前要保护现场并记忆执行的地址,转回后先要恢复现场,并按原来保
存地址继续执行。也就是通常说的压栈和出栈。因此,函数调用要有一定的时间和空间方面的开销。那么对于那些函数体
代码不是很大,又频繁调用的函数来说,这个时间和空间的消耗会很大。
那怎么解决这个性能消耗问题呢,这个时候需要引入内联函数了。内联函数就是在程序编译时,编译器将程序中出现
的内联函数的调用表达式用内联函数的函数体来直接进行替换。显然,这样就不会产生转去转回的问题,但是由于在编译
时将函数体中的代码被替代到程序中,因此会增加目标程序代码量,进而增加空间开销,而在时间代销上不象函数调用时
那么大,可见它是以目标代码的增加为代价来换取时间的节省。
在大学里学习写C代码时,我们都学到将一些简短的逻辑定义在宏里。这样做的好处是,在编译器编译的时候会将用
到该宏的地方直接用宏的代码替换。这样就不再需要象调用方法那样的压栈、出栈,传参了。性能上提升了。内联函数的
处理方式与宏类似,但与宏又有所不同,内联函数拥有函数的本身特性(类型、作用域等等)
写过C++代码的应该都知道,在C++里有个内联函数,使用inline关键字修饰。另外,写在Class定义内的函数也会被
编译器视为内联函数。
那么,在java中的内联函数长什么模样呢?在java中使用final关键字来指示一个函数为内联函数,例如:
Java代码 
public final void method1() {
//TODO something
}
这个指示并不是必需的。final关键字只是告诉编译器,在编译的时候考虑性能的提升,可以将final函数视为内联函数。
但最后编译器会怎么处理,编译器会分析将final函数处理为内联和不处理为内联的性能比较了。
149,正确答案应该选C。 类的初始化顺序是: 1、初始化父类中的静态成员变量和静态代码块。 2、初始化子类中的静态成员变量和静态代码块。 3、初始化父类中的普通成员变量和代码块,在执行父类中的构造方法。 4、初始化子类中的普通成员变量和代码块,在执行子类中的构造方法。
150,静态优先,父类优先
151,Math.cos为计算弧度的余弦值,Math.toRadians函数讲角度转换为弧度
152,计算余弦值使用Math类的cos()方法
toRadians()是将角度转换为弧度
toDegrees()是将弧度转换为角度
4月11号:
153,A: java中”包”的引入的主要原因是java本身跨平台特性的需求。实现跨平台的是JVM。
B: package语句是Java源文件的第一条语句。(若缺省该语句,则指定为无名包。),如果想在另一个类里面引用包里面的类,要把名字写全。(相当用文件的绝对路径访问)或者用import导入。
D:java中并无#include关键字,如果想在另一个类里面引用包里面的类,要把名字写全。(相当用文件的绝对路径访问)或者用import导入。
154,包的作用
1 把功能相似或相关的类或接口组织在同一个包中,方便类的查找和使用。
2 如同文件夹一样,包也采用了树形目录的存储方式。同一个包中的类名字是不同的,不同的包中的类的名字是可以相同的,当同时调用两个不同包中相同类名的类时,应该加上包名加以区别。因此,包可以避免名字冲突。
3 包也限定了访问权限,拥有包访问权限的类才能访问某个包中的类。
package必须放在import的前面
不是include,而是import
155,notify()就是对对象锁的唤醒操作。但有一点需要注意的是notify()调用后,并不是马上就释放对象锁的,而是在相应的synchronized(){}语句块执行结束,自动释放锁后,JVM会在wait()对象锁的线程中随机选取一线程,赋予其对象锁,唤醒线程,继续执行。这样就提供了在线程间同步、唤醒的操作。
156,执行obj.wait();时已释放了锁,所以t2可以再次获得锁,然后发消息通知t1执行,但这时t2还没有释放锁,所以肯定是执行t2,然后释放锁,之后t1才有机会执行。
157,引用数据类型是引用传递(call by reference),基本数据类型是值传递(call by value)
值传递不可以改变原变量的内容和地址—-》原因是java方法的形参传递都是传递原变量的副本,在方法中改变的是副本的值,而不适合原变量的
引用传递不可以改变原变量的地址,但可以改变原变量的内容—-》原因是当副本的引用改变时,原变量 的引用并没有发生变化,当副本改变内容时,由于副本引用指向的是原变量的地址空间,所以,原变量的内容发生变化。
结论:1.值传递不可以改变原变量的内容和地址;
2.引用传递不可以改变原变量的地址,但可以改变原变量的内容;
总之,值传递,不值:即都不可以。
引用, 不改地址可改内容。
再总结为,地址无论如何都不能改变。
158, Java程序的种类有:
(a)内嵌于Web文件中,由浏览器来观看的_Applet
(b)可独立运行的 Application
(c)服务器端的 Servlets
159,Application
―Java应用程序”是可以独立运行的Java程序。
由Java解释器控制执行。
Applet
―Java小程序”不能独立运行(嵌入到Web页中)。
由Java兼容浏览器控制执行。
Serverlets
是Java技术对CGI 编程的解决方案。
是运行于Web server上的、作为来自于Web browser 或其他HTTP client端的请求和在server上的数据库及其他应用程序之间的中间层程序。
Serverlets的工作是:
读入用户发来的数据(通常在web页的form中)
找出隐含在HTTP请求中的其他请求信息(如浏览器功能细节、请求端主机名等。
产生结果(调用其他程序、访问数据库、直接计算)
格式化结果(网页)
设置HTTP response参数(如告诉浏览器返回文档格式)
将文档返回给客户端。
160,A:错误{company:4399} 首先,其为json对象。但json对象要求属性必须加双引号。
C:错误 {[4399,4399,4399]} 。使用 {} 则为json对象。json对象必须由一组有序的键值对组成。
另参考(摘自<
JSON语法可以表示以下三种类型的值:
1.简单值:使用与JavaScript 相同的语法,可以在JSON中表示字符串,数值,布尔值和null。
2.对象:对象作为一种复杂数据类型,表示的是一组有序的键值对。而每组键值对中的值可以是简单值,也可以是复杂数据类型的值。
3.数组:数组也是一种复杂数据类型,表示一组有序的值的列表,可以通过数值索引来访问其中的值。数组的值也可以是任意类型—简单值,对象或数组。
161,A,java的内存回收是自动的,Gc在后台运行,不需要用户手动操作
B,java中不允许使用指针
D,内存回收线程可以释放无用的对象内存
162,如果有public类的话,是要求源文件名称和外部公共类一样的,如果文件中没有公共类的话,则文件名和类名不做强制要求
当编写一个java源代码文件时,此文件通常被称为编译单元(有时也被称为转译单元)。每个编译单元都必须有一个后缀名.java,而在编译单元内则可以有一个public类,该类的名称必须与文件的名称相同(包括大小写,但不包括文件的后缀名.java)。每个编译单元只能有一个public类,否则编译器就不会接受。如果在该编译单元之中还有额外的类的话,那么在包之外的世界是无法看见这些类的,这是因为它们不是public类,而且它们主要用来为主public类提供支持。 —《Java 编程思想》
注:public类不是必须的,但是如果源文件中有一个(只能有一个)public类的话,文件名必须与这个public类同名,原因 是为了方便虚拟机在相应的路径中找到相应的类所对应的字节码文件。所以在没有public类的Java文件中,文件名和类名都没什么联系。
163,公共外部类
公共—>public—->外部类的public代表的是此类是否是“主类”—>一个java文件可能有多个类,但只有一个主类
外部类—>不考虑内部类
164,首先:创建并启动线程的过程为:定义线程—》实例化线程—》启动线程。
一 、定义线程: 1、扩展java.lang.Thread类。 2、实现java.lang.Runnable接口。
二、实例化线程: 1、如果是扩展java.lang.Thread类的线程,则直接new即可。
2、如果是实现了java.lang.Runnable接口的类,则用Thread的构造方法:
Thread(Runnable target)
Thread(Runnable target, Stringname)
Thread(ThreadGroup group, Runnabletarget)
Thread(ThreadGroup group, Runnabletarget, String name)
Thread(ThreadGroup group, Runnabletarget, String name, long stackSize)
三、启动线程:在线程的Thread对象上调用start()方法,而不是run()或者别的方法。
所以B的启动线程方法错误。
图
165,java object默认的基本方法中没有copy(),含有如下方法:
getClass(), hashCode(), equals(), clone(), toString(), notify(),notifyAll(), wait(), finalize()
166,ArrayList的构造函数总共有三个:
(1)ArrayList()构造一个初始容量为 10 的空列表。
(2)ArrayList(Collection<? extends E> c)构造一个包含指定 collection 的元素的列表,这些元素是按照该 collection 的迭代器返回它们的顺序排列的。
(3)ArrayList(int initialCapacity)构造一个具有指定初始容量的空列表。
调用的是第三个构造函数,直接初始化为大小为20的list,没有扩容,所以选择A
167,有点迷惑人,大家都知道默认ArrayList的长度是10个,所以如果你要往list里添加20个元素肯定要扩充一次(扩充为原来的1.5倍),但是这里显示指明了需要多少空间,所以就一次性为你分配这么多空间,也就是不需要扩充了。
168,full GC触发的条件
除直接调用System.gc外,触发Full GC执行的情况有如下四种。
1. 旧生代空间不足
旧生代空间只有在新生代对象转入及创建为大对象、大数组时才会出现不足的现象,当执行Full GC后空间仍然不足,则抛出如下错误:
java.lang.OutOfMemoryError: Java heap space
为避免以上两种状况引起的FullGC,调优时应尽量做到让对象在Minor GC阶段被回收、让对象在新生代多存活一段时间及不要创建过大的对象及数组。
2. Permanet Generation空间满
PermanetGeneration中存放的为一些class的信息等,当系统中要加载的类、反射的类和调用的方法较多时,Permanet Generation可能会被占满,在未配置为采用CMS GC的情况下会执行Full GC。如果经过Full GC仍然回收不了,那么JVM会抛出如下错误信息:
java.lang.OutOfMemoryError: PermGen space
为避免Perm Gen占满造成Full GC现象,可采用的方法为增大Perm Gen空间或转为使用CMS GC。
3. CMS GC时出现promotion failed和concurrent mode failure
对于采用CMS进行旧生代GC的程序而言,尤其要注意GC日志中是否有promotion failed和concurrent mode failure两种状况,当这两种状况出现时可能会触发FullGC。
promotionfailed是在进行Minor GC时,survivor space放不下、对象只能放入旧生代,而此时旧生代也放不下造成的;concurrentmode failure是在执行CMS GC的过程中同时有对象要放入旧生代,而此时旧生代空间不足造成的。
应对措施为:增大survivorspace、旧生代空间或调低触发并发GC的比率,但在JDK 5.0+、6.0+的版本中有可能会由于JDK的bug29导致CMS在remark完毕后很久才触发sweeping动作。对于这种状况,可通过设置-XX:CMSMaxAbortablePrecleanTime=5(单位为ms)来避免。
4. 统计得到的Minor GC晋升到旧生代的平均大小大于旧生代的剩余空间
这是一个较为复杂的触发情况,Hotspot为了避免由于新生代对象晋升到旧生代导致旧生代空间不足的现象,在进行MinorGC时,做了一个判断,如果之前统计所得到的Minor GC晋升到旧生代的平均大小大于旧生代的剩余空间,那么就直接触发Full GC。
例如程序第一次触发MinorGC后,有6MB的对象晋升到旧生代,那么当下一次Minor GC发生时,首先检查旧生代的剩余空间是否大于6MB,如果小于6MB,则执行Full GC。
当新生代采用PSGC时,方式稍有不同,PS GC是在MinorGC后也会检查,例如上面的例子中第一次Minor GC后,PSGC会检查此时旧生代的剩余空间是否大于6MB,如小于,则触发对旧生代的回收。
除了以上4种状况外,对于使用RMI来进行RPC或管理的Sun JDK应用而言,默认情况下会一小时执行一次Full GC。可通过在启动时通过- java-Dsun.rmi.dgc.client.gcInterval=3600000来设置Full GC执行的间隔时间或通过-XX:+ DisableExplicitGC来禁止RMI调用System.gc。
169,1,新生代:(1)所有对象创建在新生代的Eden区,当Eden区满后触发新生代的MinorGC,将Eden区和非空闲Survivor区存活的对象复制到另外一个空闲的Survivor区中。(2)保证一个Survivor区是空的,新生代Minor GC就是在两个Survivor区之间相互复制存活对象,直到Survivor区满为止。
2,老年代:当Survivor区也满了之后就通过Minor GC将对象复制到老年代。老年代也满了的话,就将触发Full GC,针对整个堆(包括新生代、老年代、持久代)进行垃圾回收。
3,持久代:持久代如果满了,将触发Full GC。
170,finally一定会在return之前执行,但是如果finally使用了return或者throw语句,将会使trycatch中的return或者throw失效
图
答案:D
171,Java致力于检查程序在编译和运行时的错误。
Java虚拟机实现了跨平台接口
类型检查帮助检查出许多开发早期出现的错误。
Java自己操纵内存减少了内存出错的可能性。
Java还实现了真数组,避免了覆盖数据的可能。
注意,是避免数据覆盖的可能,而不是数据覆盖类型
172,真数组: 数组元素在内存中是一个接着一个线性存放的,通过第一个元素就能访问随后的元素,避免了数据覆盖的可能性,和数据类型覆盖并没有关系。
173,非静态成员只能被类的实例化对象引用,因此这里在静态方法中访问x会造成编译出错
174,Base base = new Son();这句new 了一个派生类,赋值给基类,所以下面的操作编译器认为base对象就是Base类型的
Base类中不存在methodB()方法,所以编译不通过
175,Base base=new Son(); 是多态的表示形式。父类对象调用了子类创建了Son对象。
base调用的method()方法就是调用了子类重写的method()方法。
而此时base还是属于Base对象,base调用methodB()时Base对象里没有这个方法,所以编译不通过。
要想调用的话需要先通过SON son=(SON)base;强制转换,然后用son.methodB()调用就可以了。
176,A. request.getAttribute:getAttribute是在服务器端的操作。
比如说 request.setAttribute(k,v),其行为动作在服务器端。
而在服务端放入cookies是通过response.addCookie(cookie)。因此,A错了
B. Accept 浏览器可接受的MIME类型
Accept-Charset 浏览器支持的字符编码
Accept-Encoding 浏览器知道如何解码的数据编码类型(如 gzip)。Servlets 可以预先检查浏览器是否支持gzip并可以对支持gzip的浏览器返回gzipped的HTML页面,并设置Content-Encoding回应头(response header)来指出发送的内容是已经gzipped的。在大多数情况下,这样做可以加快网页下载的速度。
Accept-Language 浏览器指定的语言,当Server支持多语种时起作用。
Authorization 认证信息,一般是对服务器发出的WWW-Authenticate头的回应。
Connection 是否使用持续连接。如果servlet发现这个字段的值是Keep-Alive,或者由发出请求的命令行发现浏览器支持 HTTP 1.1 (持续连接是它的默认选项),使用持续连接可以使保护很多小文件的页面的下载时间减少。
Content-Length (使用POST方法提交时,传递数据的字节数)
Cookie (很重要的一个Header,用来进行和Cookie有关的操作,详细的信息将在后面的教程中介绍)
Host (主机和端口)
If-Modified-Since (只返回比指定日期新的文档,如果没有,将会反回304”Not Modified”)
Referer (URL)
User-Agent (客户端的类型,一般用来区分不同的浏览器)
C.request.getParameter()方法获取从客户端中通过get 或者post方式传送到服务器端的参数。行为操作在服务器端。所以cookies明显不是通过url或者form表单提交过来的。C错
D.看方法名字就行了。
做错了 查阅一下了资料,记录一下~~各位共勉
177,request.getParameter()取得是通过容器的实现来取得通过类似post,get等方式传入的数据,request.setAttribute()和getAttribute()只是在web容器内部流转,仅仅是请求处理阶段。
两个WEB间为转发关系时,转发目的WEB可以用getAttribute()方法来和转发源WEB共享request范围内的数据
4月12号:
178,泛型只在编译的时候保证数据类型的正确性,和运行期间的性能无关
179,在这篇文章看到的一个解释:
泛型仅仅是java的语法糖,它不会影响java虚拟机生成的汇编代码,在编译阶段,虚拟机就会把泛型的类型擦除,还原成没有泛型的代码,顶多编译速度稍微慢一些,执行速度是完全没有什么区别的.
180,A 抽象方法不能有方法体,仔细点可以看到有大括号。
B 接口里的方法只能用 public 和abstract 修饰,如果你不写也没关系,默认的也是 public abstract 修饰.
181,A 你说的不对,是接口内部的方法不能有大括号,抽象类中的方法可以有大括号!
182,抽象方法不能有方法体 亘古不变的真理
183, 我们都知道一个对象只要实现了Serilizable接口,这个对象就可以被序列化,java的这种序列化模式为开发者提供了很多便利,我们可以不必关系具体序列化的过程,只要这个类实现了Serilizable接口,这个类的所有属性和方法都会自动序列化。
这个类的有些属性需要序列化,而其他属性不需要被序列化;
java 的transient关键字为我们提供了便利,你只需要实现Serilizable接口,将不需要序列化的属性前添加关键字transient,序列化对象的时候,这个属性就不会序列化到指定的目的地中。
184,一、序列化使用场景
对象的序列化:目的:将一个具体的对象进行持久化,写入到硬盘上。(注意:静态数据不能被序列化,因为静态数据不在堆内存中,而是在静态方法区中)
Serializable:用于启动对象的序列化功能,可以强制让指定类具备序列化功能,该接口中没有成员,这是一个标记接口。这个标记接口用于给序列化类提供UID。这个uid是依据类中的成员的数字签名进行运行获取的。如果不需要自动获取一个uid,可以在类中,手动指定一个名称为serialVersionUID id号。依据编译器的不同,或者对信息的高度敏感性。最好每一个序列化的类都进行手动显示的UID的指定。
二、非序列化使用场景
如何将非静态的数据不进行序列化?用transient 关键字修饰此变量即可。使用场景:为了安全起见,有时候我们不需要在网络间
传输一些数据(如身份证号码,密码,银行卡号等)
185,思路:
首先排除include和最后一个
其次:
1.PrintWriter
2.OutputStreamWriter
注意:
在创建OutputStreamWriter的时候,使用的是类的全名称。所以不需要使用import
186,解题要点:
1、try中没有抛出异常,则catch语句不执行,如果有finally语句,则接着执行finally语句,继而接着执行finally之后的语句;
2、try中抛出异常,有匹配的catch语句,则catch语句捕获,如果catch中有return语句,则要在finally执行后再执行;
187,先要理解什么是类的方法,所谓类的方法就是指类中用static 修饰的方法(非static 为实例方法),比如main 方法,那么可以以main 方法为例,可直接调用其他类方法,必须通过实例调用实例方法,this 关键字不是这么用的
188,我来说几句:
A. ArrayList是实现了基于动态数组的数据结构,LinkedList基于链表的数据结构。 //正确,这里的所谓动态数组并不是那个“ 有多少元素就申请多少空间 ”的意思,通过查看源码,可以发现,这个动态数组是这样实现的,如果没指定数组大小,则申请默认大小为10的数组,当元素个数增加,数组无法存储时,系统会另个申请一个长度为当前长度1.5倍的数组,然后,把之前的数据拷贝到新建的数组。
———————————————————————————————————
B. 对于随机访问get和set,ArrayList觉得优于LinkedList,因为LinkedList要移动指针。//正确,ArrayList是数组,所以,直接定位到相应位置取元素,LinkedLIst是链表,所以需要从前往后遍历。
———————————————————————————————————-
C. 对于新增和删除操作add和remove,LinedList比较占优势,因为ArrayList要移动数据。//正确,ArrayList的新增和删除就是数组的新增和删除,LinkedList与链表一致。
————————————————————————————————————-
D. ArrayList的空间浪费主要体现在在list列表的结尾预留一定的容量空间,而LinkedList的空间花费则体现在它的每一个元素都需要消耗相当的空间。//正确,因为ArrayList空间的增长率为1.5倍,所以,最后很可能留下一部分空间是没有用到的,因此,会造成浪费的情况。对于LInkedList的话,由于每个节点都需要额外的指针,所以,你懂的。
189,一旦一个共享变量(类的成员变量、类的静态成员变量)被volatile修饰之后,那么就具备了两层语义:
1)保证了不同线程对这个变量进行操作时的可见性,即一个线程修改了某个变量的值,这新值对其他线程来说是立即可见的。
2)禁止进行指令重排序。
volatile只提供了保证访问该变量时,每次都是从内存中读取最新值,并不会使用寄存器缓存该值——每次都会从内存中读取。
而对该变量的修改,volatile并不提供原子性的保证。
由于及时更新,很可能导致另一线程访问最新变量值,无法跳出循环的情况
多线程下计数器必须使用锁保护。
190,所谓 volatile的措施,就是
1. 每次从内存中取值,不从缓存中什么的拿值。这就保证了用 volatile修饰的共享变量,每次的更新对于其他线程都是可见的。
2. volatile保证了其他线程的立即可见性,就没有保证原子性。
3.由于有些时候对 volatile的操作,不会被保存,说明不会造成阻塞。不可用与多线程环境下的计数器。
191,原子性就是不可分割,比如赋值操作 i = 0;这就是一个原子性的代码,但是i++;这种就是i= i+1;是两个操作,先加一后赋值,所以不是原子性,volatile关键字只保证了线程可见性,但是线程操作上没有规定必须原子性。
192,synchronized方法保证了原子性,但是可能会造成线程阻塞,而volatile虽然能实现了同样的锁的机制,但性能没有其好,不过优势在于他不会造成阻塞,开销要小得多。
4月16号:
193,static修饰某个字段时,肯定会改变字段创建的方式(每个被static修饰的字段对于每一个类来说只有一份存储空间,而非static修饰的字段对于每一个对象来说都有一个存储空间)
static属性是属于类的,所以对象共同拥有,所以既可以通过类名.变量名进行操作,又可以通过对象名.变量名进行操作
194,由于构造器的名字必须与类名相同,而匿名类没有类名,所以匿名类不能有构造器。
195,匿名内部类的创建格式为: new 父类构造器(参数列表)|实现接口(){
//匿名内部类的类体实现
}
使用匿名内部类时,必须继承一个类或实现一个接口
匿名内部类由于没有名字,因此不能定义构造函数
匿名内部类中不能含有静态成员变量和静态方法
196,\d 是数字的意思,\D是非数字的意思
元字符
描述
\
将下一个字符标记符、或一个向后引用、或一个八进制转义符。例如,“\n”匹配\n。“\n”匹配换行符。序列“\”匹配“\”而“(”则匹配“(”。即相当于多种编程语言中都有的“转义字符”的概念。
^
匹配输入字符串的开始位置。如果设置了RegExp对象的Multiline属性,^也匹配“\n”或“\r”之后的位置。
$
匹配输入字符串的结束位置。如果设置了RegExp对象的Multiline属性,$也匹配“\n”或“\r”之前的位置。
匹配前面的子表达式任意次。例如,zo能匹配“z”,也能匹配“zo”以及“zoo”。等价于o{0,}
+
匹配前面的子表达式一次或多次(大于等于1次)。例如,“zo+”能匹配“zo”以及“zoo”,但不能匹配“z”。+等价于{1,}。
?
匹配前面的子表达式零次或一次。例如,“do(es)?”可以匹配“do”或“does”中的“do”。?等价于{0,1}。
{n}
n是一个非负整数。匹配确定的n次。例如,“o{2}”不能匹配“Bob”中的“o”,但是能匹配“food”中的两个o。
{n,}
n是一个非负整数。至少匹配n次。例如,“o{2,}”不能匹配“Bob”中的“o”,但能匹配“foooood”中的所有o。“o{1,}”等价于“o+”。“o{0,}”则等价于“o”。
{n,m}
m和n均为非负整数,其中n<=m。最少匹配n次且最多匹配m次。例如,“o{1,3}”将匹配“fooooood”中的前三个o为一组,后三个o为一组。“o{0,1}”等价于“o?”。请注意在逗号和两个数之间不能有空格。
?
当该字符紧跟在任何一个其他限制符(*,+,?,{n},{n,},{n,m})后面时,匹配模式是非贪婪的。非贪婪模式尽可能少的匹配所搜索的字符串,而默认的贪婪模式则尽可能多的匹配所搜索的字符串。例如,对于字符串“oooo”,“o+”将尽可能多的匹配“o”,得到结果[“oooo”],而“o+?”将尽可能少的匹配“o”,得到结果[‘o’, ‘o’, ‘o’, ‘o’]
.点
匹配除“\r\n”之外的任何单个字符。要匹配包括“\r\n”在内的任何字符,请使用像“[\s\S]”的模式。
(pattern)
匹配pattern并获取这一匹配。所获取的匹配可以从产生的Matches集合得到,在VBScript中使用SubMatches集合,在JScript中则使用$0…$9属性。要匹配圆括号字符,请使用“(”或“)”。
(?:pattern)
非获取匹配,匹配pattern但不获取匹配结果,不进行存储供以后使用。这在使用或字符“(|)”来组合一个模式的各个部分时很有用。例如“industr(?:y|ies)”就是一个比“industry|industries”更简略的表达式。
(?=pattern)
非获取匹配,正向肯定预查,在任何匹配pattern的字符串开始处匹配查找字符串,该匹配不需要获取供以后使用。例如,“Windows(?=95|98|NT|2000)”能匹配“Windows2000”中的“Windows”,但不能匹配“Windows3.1”中的“Windows”。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。
(?!pattern)
非获取匹配,正向否定预查,在任何不匹配pattern的字符串开始处匹配查找字符串,该匹配不需要获取供以后使用。例如“Windows(?!95|98|NT|2000)”能匹配“Windows3.1”中的“Windows”,但不能匹配“Windows2000”中的“Windows”。
(?<=pattern)
非获取匹配,反向肯定预查,与正向肯定预查类似,只是方向相反。例如,“(?<=95|98|NT|2000)Windows”能匹配“2000Windows”中的“Windows”,但不能匹配“3.1Windows”中的“Windows”。
(?<!pattern)
非获取匹配,反向否定预查,与正向否定预查类似,只是方向相反。例如“(?<!95|98|NT|2000)Windows”能匹配“3.1Windows”中的“Windows”,但不能匹配“2000Windows”中的“Windows”。这个地方不正确,有问题
此处用或任意一项都不能超过2位,如“(?<!95|98|NT|20)Windows正确,“(?<!95|980|NT|20)Windows 报错,若是单独使用则无限制,如(?<!2000)Windows正确匹
x|y
匹配x或y。例如,“z|food”能匹配“z”或“food”(此处请谨慎)。“[zf]ood”则匹配“zood”或“food”。
[xyz]
字符集合。匹配所包含的任意一个字符。例如,“[abc]”可以匹配“plain”中的“a”。
[^xyz]
负值字符集合。匹配未包含的任意字符。例如,“[^abc]”可以匹配“plain”中的“plin”。
[a-z]
字符范围。匹配指定范围内的任意字符。例如,“[a-z]”可以匹配“a”到“z”范围内的任意小写字母字符。
注意:只有连字符在字符组内部时,并且出现在两个字符之间时,才能表示字符的范围; 如果出字符组的开头,则只能表示连字符本身.
[^a-z]
负值字符范围。匹配任何不在指定范围内的任意字符。例如,“[^a-z]”可以匹配任何不在“a”到“z”范围内的任意字符。
\b
匹配一个单词边界,也就是指单词和空格间的位置(即正则表达式的“匹配”有两种概念,一种是匹配字符,一种是匹配位置,这里的\b就是匹配位置的)。例如,“er\b”可以匹配“never”中的“er”,但不能匹配“verb”中的“er”。
\B
匹配非单词边界。“er\B”能匹配“verb”中的“er”,但不能匹配“never”中的“er”。
\cx
匹配由x指明的控制字符。例如,\cM匹配一个Control-M或回车符。x的值必须为A-Z或a-z之一。否则,将c视为一个原义的“c”字符。
\d
匹配一个数字字符。等价于[0-9]。grep 要加上-P,perl正则支持
\D
匹配一个非数字字符。等价于[^0-9]。grep要加上-P,perl正则支持
\f
匹配一个换页符。等价于\x0c和\cL。
\n
匹配一个换行符。等价于\x0a和\cJ。
\r
匹配一个回车符。等价于\x0d和\cM。
\s
匹配任何不可见字符,包括空格、制表符、换页符等等。等价于[ \f\n\r\t\v]。
\S
匹配任何可见字符。等价于[^ \f\n\r\t\v]。
\t
匹配一个制表符。等价于\x09和\cI。
\v
匹配一个垂直制表符。等价于\x0b和\cK。
\w
匹配包括下划线的任何单词字符。类似但不等价于“[A-Za-z0-9]”,这里的”单词”字符使用Unicode字符集。
\W
匹配任何非单词字符。等价于“[^A-Za-z0-9]”。
枚举类有三个实例,故调用三次构造方法,打印三次It is a account type
一个类可以有多个构造器,多个构造器用的是方法重载,所以方法名要相同,不同的是参数列表(参数个数、参数类型和参数的顺序),当自己没有定义构造器时,系统会自动地添加一个默认构造器,子类可以调用父类的构造器。
197,算法包括0个或多个输入,1个或多个输出,中间有穷个处理过程。
存储结构不属于算法结构
198,MVC全名是Model ViewController,是模型(model)-视图(view)-控制器(controller)的缩写,一种软件设计典范,用一种业务逻辑、数据、界面显示分离的方法组织代码,将业务逻辑聚集到一个部件里面,在改进和个性化定制界面及用户交互的同时,不需要重新编写业务逻辑。MVC被独特的发展起来用于映射传统的输入、处理和输出功能在一个逻辑的图形化用户界面的结构中。
MVC只是将分管不同功能的逻辑代码进行了隔离,增强了可维护和可扩展性,增强代码复用性,因此可以减少代码重复。但是不保证减少代码量,多层次的调用模式还有可能增加代码量
198,声明为public类型的类名必须与文件名相同,默认权限的可以不同
并且内部类的类名一般与文件名不同
199,Ant和Maven都是基于Java的构建(build)工具。理论上来说,有些类似于(Unix)C中的make ,但没有make的缺陷。Ant是软件构建工具,Maven的定位是软件项目管理和理解工具。
Ant特点 ›
没有一个约定的目录结构›必须明确让ant做什么,什么时候做,然后编译,打包 ›没有生命周期,必须定义目标及其实现的任务序列 ›没有集成依赖管理
Maven特点
›拥有约定,知道你的代码在哪里,放到哪里去›拥有一个生命周期,例如执行 mvn install 就可以自动执行编译,测试,打包等构建过程 ›只需要定义一个pom.xml,然后把源码放到默认的目录,Maven帮你处理其他事情 ›拥有依赖管理,仓库管理
200,A.vector是线程安全的ArrayList,在内存中占用连续的空间。初始时有一个初始大小,当数据条数大于这个初始大小后会重写分配一个更大的连续空间。如果Vector定义为保存Object则可以存放任意类型。
B.try{}catch{}会增加额外的开销
C.接口中声明的’变量’必须为public final static,所以为常量
D.子类可以访问父类受保护的成员
201,接口中只有常量定义,没有变量声明。
202,A.可以不必事先知道对象类型,默认就Object类型
B.错误可以捕获异常也可以手动抛出
C.接口有函数声明和变量声明。函数没有函数体,变量是final类型。
D.子类可以访问父类protected类型成员,不可以访问private类型的成员。
203,简单地说,字符流是字节流根据字节流所要求的编码集解析获得的
可以理解为字符流=字节流+编码集
所以本题中和字符流有关的类都拥有操作编码集(unicode)的能力。
204,字节流继承于InputStream OutputStream,字符流继承于InputStreamReader OutputStreamWriter
链接:https://www.nowcoder.com/questionTerminal/1585b178f50b4681a82cd9cee46d6d1e?toCommentId=402435
来源:牛客网
字节流:
InputStream
|— FileInputStream (基本文件流)
|— BufferedInputStream
|— DataInputStream
|— ObjectInputStream
字符流
Reader
|— InputStreamReader (byte->char 桥梁)
|— BufferedReader (常用)
Writer
|— OutputStreamWriter (char->byte 桥梁)
|— BufferedWriter
|— PrintWriter (常用)
205,单例模式,obj1和obj2其实是一个对象,应该返回true!
206,饿汉式单例模式,在调用Chinese.getInstance()时,进行初始化,由于初始化只会执行一次,所以可以实现单例
207,1、类变量的调用:(1)静态、非静态方法中,可以直接调用。
2、成员变量的调用有2种方法:(1)非静态方法中,可以通过this关键字直接调用。因为成员变量的初始化时间先于类的构造函数执行前,自然保证了成员变量已经被赋值。(2)静态方法中,先实例化类,利用实例化类的引用才能调用。
3、this关键字:(1)不能在静态方法中使用。
208,存根类是一个类,它实现了一个接口,它的作用是:如果一个接口有很多方法,如果要实现这个接口,就要实现所有的方法。但是一个类从业务来说,可能只需要其中一两个方法。如果直接去实现这个接口,除了实现所需的方法,还要实现其他所有的无关方法。而如果通过继承存根类就实现接口,就免去了这种麻烦。
RMI 采用stubs 和skeletons 来进行远程对象(remote object)的通讯。stub 充当远程对象的客户端代理,有着和远程对象相同的远程接口,远程对象的调用实际是通过调用该对象的客户端代理对象stub来完成的。
每个远程对象都包含一个代理对象stub,当运行在本地Java虚拟机上的程序调用运行在远程Java虚拟机上的对象方法时,它首先在本地创建该对象的代理对象stub, 然后调用代理对象上匹配的方法。每一个远程对象同时也包含一个skeleton对象,skeleton运行在远程对象所在的虚拟机上,接受来自stub对象的调用。这种方式符合等到程序要运行时将目标文件动态进行链接的思想
209,在单行文本输入区(Textfield)构件上可能发生的事件包括FocusEvent焦点事件,所对应的事件监听器是FocusListener;ActionEvent动作事件,所对应的事件监听器是ActionListener;MouseEvent鼠标事件,所对应的事件监听器是MouseMotionListener;
210,其实都是引用传递,只是因为String是个特殊的final类,所以每次对String的更改都会重新创建内存地址并存储(也可能是在字符串常量池中创建内存地址并存入对应的字符串内容),但是因为这里String是作为参数传递的,在方法体内会产生新的字符串而不会对方法体外的字符串产生影响。
211,1. 对象存储在堆区。
2. 数组是一种对象。
212,Java把内存分成两种,一种叫做栈内存,一种叫做堆内存。
在函数中定义的一些基本类型的变量和对象的引用变量都是在函数的栈内存中分配。当在一段代码块中定义一个变量时,java就在栈中为这个变量分配内存空间,当超过变量的作用域后,java会自动释放掉为该变量分配的内存空间,该内存空间可以立刻被另作他用。
堆内存用于存放由new创建的对象和数组。在堆中分配的内存,由java虚拟机自动垃圾回收器来管理。在堆中产生了一个数组或者对象后,还可以在栈中定义一个特殊的变量,这个变量的取值等于数组或者对象在堆内存中的首地址,在栈中的这个特殊的变量就变成了数组或者对象的引用变量,以后就可以在程序中使用栈内存中的引用变量来访问堆中的数组或者对象,引用变量相当于为数组或者对象起的一个别名,或者代号。
引用变量是普通变量,定义时在栈中分配内存,引用变量在程序运行到作用域外释放。而数组&对象本身在堆中分配,即使程序运行到使用new产生数组和对象的语句所在地代码块之外,数组和对象本身占用的堆内存也不会被释放,数组和对象在没有引用变量指向它的时候(比如先前的引用变量x=null时),才变成垃圾,不能再被使用,但是仍然占着内存,在随后的一个不确定的时间被垃圾回收器释放掉。这个也是java比较占内存的主要原因。
以上段落来自于某一本Java程序设计的书中,实际上,栈中的变量指向堆内存中的变量,这就是Java中的指针。
总结起来就是对象存储在堆内存,引用变量存储在栈内存。栈内存指向堆内存。
213,重载是在同一个类中,有多个方法名相同,参数列表不同(参数个数不同,参数类型不同),与方法的返回值无关,与权限修饰符无关,B中的参数列表和题目的方法完全一样了。
214,方法的重载是指:
1、在同一个类中
2、方法名相同
3、方法的形参列表不同
具体的不同表现为:
类型、个数、顺序的不同才可以构成重载
4、#比较容易忽略的一点#
与方法的返回值类型与访问权限无关
215,A,“任何对象”锁定,太绝对了,你能锁住你没有权限访问的对象吗?
B,前半句话讲的是创建线程的方式,后半句讲的是锁定,驴头不对马嘴。
D,线程调度分为协同式调度和抢占式调度,Java使用的是抢占式调度,也就是每个线程将由操作系统来分配执行时间,线程的切换不由线程本身来决定(协同式调度)。这就是平台独立的原因。
4月17号:
216,DBMS:数据库管理系统(DatabaseManagement System)是一种操纵和管理数据库的大型软件,用于建立、使用和维护数据库,简称DBMS。
DBMS对数据库的保护通过4个方面来实现:
数据库的恢复
数据库的并发控制
数据库的完整性控制
数据库安全性控制
DBMS中实现事务持久性的子系统是恢复管理子系统。
217,原子性-事务管理子系统。一致性-完整子系统。隔离性-并发控制子系统。持久性-恢复管理子系统
218,先出现字符串,后面的内容自动强制转换为string进行拼接 先出现数字,则进行加减运算先算括号里面,数字
219,JUnit是一个Java语言的单元测试框架,有程序员自测,就是所谓的白盒测试,主要四个方向 1、用于测试期望结果的断言(Assertion) 2、用于共享共同测试数据的测试工具 3、用于方便的组织和运行测试的测试套件 4、图形和文本的测试运行器
220,多态==晚绑定或动态绑定
不要把函数重载理解为多态,因为多态是一种运行期行为,不是编译器行为。
多态:父类的引用指向子类的实例。
比如 Parent p = new Child()
当使用多态方式调用方法时,首先检查父类中是否有该方法,如果没有,则编译错误;
如果有,再去调用子类的同名方法。
静态方法特殊,静态方法只能继承,不能覆盖,如果子类有和父类相同的静态方法,只是起到隐藏父类方法的作用。这时候,谁的引用就调用谁的方法。
221, 复制的效率System.arraycopy>clone>Arrays.copyOf>for循环,这个有兴趣自己测试一下就知道了。这里面在System类源码中给出了arraycopy的方法,是native方法,也就是本地方法,肯定是最快的。而Arrays.copyOf(注意是Arrays类,不是Array)的实现,在源码中是调用System.copyOf的,多了一个步骤,肯定就不是最快的。前面几个说System.copyOf的不要看,System类底层根本没有这个方法,自己看看源码就全知道了。
还是疏忽写错一句话,在Arrays.copyOf方法中调用的是System.arraycopy方法!
222, Java中的多线程是一种抢占式的机制,而不是分时机制。抢占式的机制是有多个线程处于可运行状态,但是只有一个线程在运行。
共同点 :
1. 他们都是在多线程的环境下,都可以在程序的调用处阻塞指定的毫秒数,并返回。
2. wait()和sleep()都可以通过interrupt()方法 打断线程的暂停状态 ,从而使线程立刻抛出InterruptedException。
如果线程A希望立即结束线程B,则可以对线程B对应的Thread实例调用interrupt方法。如果此刻线程B正在wait/sleep/join,则线程B会立刻抛出InterruptedException,在catch() {} 中直接return即可安全地结束线程。
需要注意的是,InterruptedException是线程自己从内部抛出的,并不是interrupt()方法抛出的。对某一线程调用 interrupt()时,如果该线程正在执行普通的代码,那么该线程根本就不会抛出InterruptedException。但是,一旦该线程进入到 wait()/sleep()/join()后,就会立刻抛出InterruptedException。
不同点 :
1.每个对象都有一个锁来控制同步访问。Synchronized关键字可以和对象的锁交互,来实现线程的同步。
sleep方法没有释放锁,而wait方法释放了锁,使得其他线程可以使用同步控制块或者方法。
2.wait,notify和notifyAll只能在同步控制方法或者同步控制块里面使用,而sleep可以在任何地方使用
3.sleep必须捕获异常,而wait,notify和notifyAll不需要捕获异常
4.sleep是线程类(Thread)的方法,导致此线程暂停执行指定时间,给执行机会给其他线程,但是监控状态依然保持,到时后会自动恢复。调用sleep不会释放对象锁。
5.wait是Object类的方法,对此对象调用wait方法导致本线程放弃对象锁,进入等待此对象的等待锁定池,只有针对此对象发出notify方法(或notifyAll)后本线程才进入对象锁定池准备获得对象锁进入运行状态。
4月19号:
223,在Applet中:
init(): 初始化;
start() 激活;
stop(): 当Applet被覆盖时,可用stop()方法停止线程, 典型作用是挂起一个线程;
destroy() :终止Applet,释放Applet的所有资源
224,这个说法说反了
Arraylist的内存结构是数组,当超出数组大小时创建一个新的数组,吧原数组中元素拷贝过去。其本质是顺序存储的线性表,插入和删除操作会引发后续元素移动,效率低,但是随机访问效率高
LinkedList的内存结构是用双向链表存储的,链式存储结构插入和删除效率高,不需要移动。但是随机访问效率低,需要从头开始向后依次访问
225,解析:
//ArrayList源码 public classArrayList
—————————————————————
ArrayList的大小是可以改变的,通过源码可以发现,它是基于数组实现的,往ArrayList里添加数据时,它首先会判断数组大小,是否已满(这个与HashMap不同,那个有装载因子),如果满了,则扩充数组,其实就是新建一个数组,然后把数据拷贝过去,新数组的大小与旧数组的大小关系如下。相信大伙都看得懂。
int newCapacity = oldCapacity + (oldCapacity >> 1);
LinkedList是节点结构如下,可以看出,item是存储数据的,next是指向下一个Node,prev是指向前一个Node的,所以说,LinkedList是双向的
Node(Node
———————————————————————————-
ArrayList是基于数组的,所以,具备随机访问特点,但LinkedList就不一样了,虽然,也可以通过也支持随机访问,但却付出了一定的代价。在LInkedLIst中,如果想返回某个位置的元素,就是从前往后遍历。如下。很明显,LinkedLIst不支持高效的随机访问。因此,C错误。
Node
———————————————————————————————————-
LinkedList是基于双链表的,增加是在尾部增加,增加和删除都只需要修改指针,不需要移动元素。
ArrayList插入或删除一个元素的开销不是固定的。在插入时,如果索引正确,容量够,则直接插入,插入位置之后的都需要移动,如果容易不够,还得扩充容量,开销当然不一样。删除操作同理。
226,静态块:用static申明,JVM加载类时执行,仅执行一次
构造块:类中直接用{}定义,每一次创建对象时执行
执行顺序优先级:静态块>main()>构造块>构造方法
静态块按照申明顺序执行,先执行Test t1 = new Test();
所有先输出blockA,然后执行静态块,输出blockB,最后执行main
方法中的Test t2 = new Test();输出blockA。
227, 1.首先,需要明白类的加载顺序。
(1) 父类静态对象和静态代码块
(2) 子类静态对象和静态代码块
(3) 父类非静态对象和非静态代码块
(4) 父类构造函数
(5) 子类 非静态对象和非静态代码块
(6) 子类构造函数
其中:类中静态块按照声明顺序执行,并且(1)和(2)不需要调用new类实例的时候就执行了(意思就是在类加载到方法区的时候执行的)
2.因而,整体的执行顺序为
public static Test t1 = new Test();//(1)
static
{
System.out.println(“blockB”);//(2)
}
Test t2 =newTest(); //(3)
在执行(1)时创建了一个Test对象,在这个过程中会执行非静态代码块和缺省的无参构造函数,在执行非静态代码块时就输出了blockA;然后执行(2)输出blockB;执行(3)的过程同样会执行非静态代码块和缺省的无参构造函数,在执行非静态代码块时输出blockA。因此,最终的结果为
blockA blockB blockA
228, A:静态成员变量或静态代码块>main方法>非静态成员变量或非静态代码块>构造方法
B:think in java中提到构造器本身并没有任何返回值。
C: 构造方法的主要作用是完成对类的对象的初始化工作。
D: 一般在创建(new)新对象时,系统会自动调用构造方法。
229, ThreadLocal继承Object,相当于没继承任何特殊的。
ThreadLocal没有实现任何接口。
ThreadLocal并不是一个Thread,而是Thread的局部变量。
230, ThreadLocal不是使用在多线程之间共享数据,使变量在每个线程中都有独立拷贝,不会出现一个线程读取变量时而被另一个线程修改的现象。
231,1、ThreadLocal的类声明:
public class ThreadLocal
可以看出ThreadLocal并没有继承自Thread,也没有实现Runnable接口。所以AB都不对。
2、ThreadLocal类为每一个线程都维护了自己独有的变量拷贝。每个线程都拥有了自己独立的一个变量。
所以ThreadLocal重要作用并不在于多线程间的数据共享,而是数据的独立,C选项错。
由于每个线程在访问该变量时,读取和修改的,都是自己独有的那一份变量拷贝,不会被其他线程访问,
变量被彻底封闭在每个访问的线程中。所以E对。
3、ThreadLocal中定义了一个哈希表用于为每个线程都提供一个变量的副本:
static class ThreadLocalMap {
static class Entry extendsWeakReference
/ The value associatedwith this ThreadLocal. */
Object value;
Entry(ThreadLocal k,Object v) {
super(k);
value = v;
}
}
/
The table, resized as necessary.
table.length MUST always be apower of two.
*/
private Entry[] table;
}
232,在Java中,变量有两种类型,一种是原始类型,一种是引用类型。
原始类型一共有8种,它们分别是char,boolean,byte,short,int,long,float,double。在Java API中,有它们对应的包装类,分别是(首字母大写)Character,Boolean,Byte,Short,Integer,Long,Float,Double(char,int的变化稍微大点)。
JAVA JVM对于不同的原始类型会分配不同的存储空间,具体分配如下:
byte : 1个字节 8位
最大值: 127 (有符号)
short : 2个字节 16位32767
int : 4个字节 32位2147483647
long: 8个字节 64位9223372036854775807
float: 4个字节 32位3.4028235E38
double:8个字节 64位1.7976931348623157E308
枚举(enum)类型是Java 5新增的特性,它是一种新的类型,允许用常量来表示特定的数据片断,而且全部都以类型安全的形式来表示,是特殊的类,可以拥有成员变量和方法。
图
233,一个文件中的字符要写到另一个文件中,首先需要读取这个文件,所以要先建立输入流,然后写到另一个文件,这时再建立输出流.
所以要先建立输入流,再建立输出流.
234,面试很喜欢问的:
首先,重载和重写都是多态的一种体现方式。重载是编译期间的活动,重写是运行期间的活动。
其次,重载是在一个类中定义相同的名字的方法,方法的参数列表或者类型要互相不同,但是返回值类型不作为是否重载的标准,可以修改可见性;
重写是不同的,要求子类重写基类的方法时要与父类方法具有相同的参数类型和返回值,可见性需要大于等于基类的方法
235,具体说来,重载与重写的区别:
一、重写(override)
override是重写(覆盖)一个方法,以实现不同的功能。一般是用于子类在继承父类时,重写(重新实现)父类中的方法。
重写(覆盖)的规则:
1、重写方法的参数列表必须完全与被重写的方法的相同,否则不能称其为重写而是重载.
2、重写方法的访问修饰符一定要大于被重写方法的访问修饰符(public>protected>default>private)。
3、重写的方法的返回值必须和被重写的方法的返回一致;
4、重写的方法所抛出的异常必须和被重写方法的所抛出的异常一致,或者是其子类;
5、被重写的方法不能为private,否则在其子类中只是新定义了一个方法,并没有对其进行重写。
6、静态方法不能被重写为非静态的方法(会编译出错)。
二、重载(overload)
overload是重载,一般是用于在一个类内实现若干重载的方法,这些方法的名称相同而参数形式不同。
重载的规则:
1、在使用重载时只能通过相同的方法名、不同的参数形式实现。不同的参数类型可以是不同的参数类型,不同的参数个数,不同的参数顺序(参数类型必须不一样);
2、不能通过访问权限、返回类型、抛出的异常进行重载;
3、方法的异常类型和数目不会对重载造成影响;
多态的概念比较复杂,有多种意义的多态,一个有趣但不严谨的说法是:继承是子类使用父类的方法,而多态则是父类使用子类的方法。一般,我们使用多态是为了避免在父类里大量重载引起代码臃肿且难于维护。
236,可能,有些人能够看懂 override 和 overload ,但是就是不懂他娘的怎么翻译成中文,因为一堆乱七八糟的名字。
这里 有个小诀窍,
overload 是单纯自己一个类在瞎搞,load是下载的意思。那这个就是重载的意思了。
首先 override 是子类与父类之间的关系,这个你经常写 注解@Override就清楚了,再无法记住,你就看那个 ride 是骑的意思,理解成儿子骑在老子头上。 那这个就是 重写 或者 覆盖。
随便理解一下。
237,1.构造方法也是类的方法,可以在创建对象时为成员变量赋值
2.构造方法可以进行重载,但是参数列表必须不相同,不以返回值和访问级别进行区分
3.构造方法没有返回值
4.构造方法一定要与定义为public的类同名
238,类中静态语句块仅在类加载时被执行一次
静态代码块优先于主方法,且只执行一次
239,被static修饰的语句或者变量有如下特点:
1.随着类的加载而加载
2.优先于对象存在
3.被所有对象所共享
4.可以直接被类名所调用
使用注意:
1.静态方法只能访问静态成员
2.静态方法中不可以写this,super关键字
3.主函数是静态的
240,面向对象的五大基本原则
单一职责原则(SRP)
开放封闭原则(OCP)
里氏替换原则(LSP)
依赖倒置原则(DIP)
接口隔离原则(ISP)
241,五个基本原则:
单一职责原则(Single-Resposibility Principle):一个类,最好只做一件事,只有一个引起它的变化。单一职责原则可以看做是低耦合、高内聚在面向对象原则上的引申,将职责定义为引起变化的原因,以提高内聚性来减少引起变化的原因。
开放封闭原则(Open-Closed principle):软件实体应该是可扩展的,而不可修改的。也就是,对扩展开放,对修改封闭的。
Liskov替换原则(Liskov-Substituion Principle):子类必须能够替换其基类。这一思想体现为对继承机制的约束规范,只有子类能够替换基类时,才能保证系统在运行期内识别子类,这是保证继承复用的基础。
依赖倒置原则(Dependecy-Inversion Principle):依赖于抽象。具体而言就是高层模块不依赖于底层模块,二者都同依赖于抽象;抽象不依赖于具体,具体依赖于抽象。
接口隔离原则(Interface-Segregation Principle):使用多个小的专门的接口,而不要使用一个大的总接口
242,1、一个类可以有多个接口; 2、一个类只能继承一个父类; 3、接口中可以不声明任何方法,和成员变量 interfacetestinterface{ } 4、抽象类可以不包含抽象方法,但有抽象方法的类一定要声明为抽象类 abstract class abstclass{ abstractvoid meth(); }
243,简单的做个关于抽象类和接口的总结吧:
区别1:抽象类体现继承关系,一个类只能単继承。接口体现实现关系,一个类可以多实现。
区别2:抽象类中可以定义非抽象方法和抽象方法,子类继承后可以直接使用非抽象方法。接口的方法都是抽象的,必须由子类去实现。接口中的成员都有固定的修饰符。
区别3:抽象类有构造方法,用于给子类对象初始化。而接口没有构造方法。
特点1:抽象类不可以实例化,即不能用new创建对象。抽象类必须由其子类覆盖了所有的抽象方法后,该子类才可以实例化,否则,这个子类也是抽象类。
特点2:抽象类abstract关键字不能和哪些关键字共存:
final 因为final修饰的方法不能被继承。
static因为类.方法(),此方法没有方法体,没有意义。
private 因为抽象方法是要被子类覆盖的,加上private子类就不知道这个方法了。
特点3:接口中声明变量必须是final、public、static的,接口中定义的方法都是abstract、 public的。接口里的数据成员必须初始化,且全是常量,不是变量。
特点4:接口是抽象类的 变体( 你没看错 ), 接口也可以通过关键字extends来继承其他接口。格式如下所示:
class 类名称 implements 接口A,接口B{//接口的实现}
interface 子接口名称 extends 父接口1,父接口2,…{}
244,总结了一下,顺便发个福利
1. 一个子类只能继承一个抽象类,但能实现多个接口
2. 抽象类可以有构造方法,接口没有构造方法
3. 抽象类可以有普通成员变量,接口没有普通成员变量
4. 抽象类和接口都可有静态成员变量,抽象类中静态成员变量访问类型任意,接口只能public static final(默认)
5. 抽象类可以没有抽象方法,抽象类可以有普通方法,接口中都是抽象方法
6. 抽象类可以有静态方法,接口不能有静态方法
7. 抽象类中的方法可以是public、protected;接口方法只有public

245,个人想法:
解析:(借他人总结)
含有abstract修饰符的class即为抽象类,abstract类不能创建的实例对象。含有abstract方法的类必须定义为abstract class,abstract class类中的方法不必是抽象的。abstract class
类中定义抽象方法必须在具体
(Concrete)子类中实现,所以,不能有抽象构造方法或抽象静态方法。如果的子类没有实现抽象父类中的所有抽象方法,那么子类也必须定义为abstract类型。
接口(interface)可以说成是抽象类的一种特例,接口中的所有方法都必须是抽象的。接口中的方法定义默认为public abstract类型,接口中的成员变量类型默认为public staticfinal。
下面比较一下两者的语法区别:
1.抽象类可以有构造方法,接口中不能有构造方法。
2.抽象类中可以有普通成员变量,接口中没有普通成员变量
3.抽象类中可以包含非抽象的普通方法,接口中的所有方法必须都是抽象的,不能有非抽象的普通方法。
4. 抽象类中的抽象方法的访问类型可以是public,protected和(默认类型,虽然
eclipse下不报错,但应该也不行),但接口中的抽象方法只能是public类型的,并且默认即为public abstract类型。
5. 抽象类中可以包含静态方法,接口中不能包含静态方法
6. 抽象类和接口中都可以包含静态成员变量,抽象类中的静态成员变量的访问类型可以任意,但接口中定义的变量只能是public static final类型,并且默认即为public staticfinal类型。
246,1、子类构造函数调用父类构造函数用super
2、子类重写父类方法后,若想调用父类中被重写的方法,用super
3、未被重写的方法可以直接调用。
247,方法重载满足的条件 1. 同一个类中,方法名相同,参数列表不同的2个或多个方法构成方法的重载 2.参数列表不同指参数的类型,参数的个数,参数的顺序至少一项不同 3.方法的返回值类型,方法的修饰符可以不同。
248,Integer的范围是-128~127
249,静态成员和静态方法,可以直接通过类名进行调用;其他的成员和方法则需要进行实例化成对象之后,通过对象来调用。
250,//直接看源码的定义public class Hashtable
图
251,前三个都至少需要先读取,再操作,非原子操作。而D的话,直接赋值。
252,同步是害怕在操作过程的时候被其他线程也进行读取操作,一旦是原子性的操作就不会发生这种情况。
因为一步到位的操作,其他线程不可能在中间干涉。另外三项都有读取、操作两个步骤,而X=1则是原子性操作。
253,ABC不是原子性操作,例如想x++,先获取x的值,自增一,然后再把值赋给x,三步,中间任何一步执行时都可能被其他线程访问或者修改。所以需要同步。
254,定义在类中的变量是类的成员变量,可以不进行初始化,Java会自动进行初始化,如果是引用类型默认初始化为null,如果是基本类型例如int则会默认初始化为0
局部变量是定义在方法中的变量,必须要进行初始化,否则不同通过编译
被static关键字修饰的变量是静态的,静态变量随着类的加载而加载,所以也被称为类变量
被final修饰发变量是常量
255,D:含有抽象方法的类(包括直接定义了抽象方法;继承一个抽象父类,但没有完全实现父类包含的抽象方法;实现一个接口,但没有完全实现接口包含的抽象方法)只能被定义成抽象类。
A:用于修饰抽象类或者抽象方法
B:final修饰的类不能被继承
C:抽象类不能被实例化,无法使用new关键字调用抽象类的构造器创建抽象类的实例,即使抽象类不包含抽象方法,也不能被实例化。
256,A 正确的;
B 正确的;//final类中只能含有非抽象的方法;
D 错误的;//对于abstract类的子类来说有两种途径,一种是实现其超类的所有abstract方法;或者是 //子类也声明为abstract类,将全部实现抽象方法的责任交给它的子类。
257,包装类的“==”运算在不遇到算术运算的情况下不会自动拆箱
包装类的equals()方法不处理数据转型
258,ABC3 个选项很明显,不同类型引用的 == 比较,会出现编译错误,不能比较。
DEF 调用 equals 方法,因为此方法先是比较类型,而 i , d , l 是不同的类型,所以返回假。
选项 G ,会自动装箱,将 42L 装箱成Long 类型,所以调用 equals 方法时,类型相同,且值也相同,因此返回真。
259,public:可以被所有其他类所访问;
protected:自身、子类及同一个包中类可以访问;
default:同一包中的类可以访问;
private:只能被自己访问和修改。
public>protcted>default>priavte
260,在java中一个unicode占2个字节(byte)。
一个字节等于8比特位(bit)。
所以每个Unicode码占用16个比特位。
答案:C
261,application对象是共享的,多个用户共享一个,以此实现数据共享和通信
JSP内置对象和属性列举如下:
1.request对象
客户端的请求信息被封装在request对象中,通过它才能了解到客户的需求,然后做出响应。它是HttpServletRequest类的实例。
2.response对象
response对象包含了响应客户请求的有关信息,但在JSP中很少直接用到它。它是HttpServletResponse类的实例。
3.session对象
session对象指的是客户端与服务器的一次会话,从客户连到服务器的一个WebApplication开始,直到客户端与服务器断开连接为止。它是HttpSession类的实例.
4.out对象
out对象是JspWriter类的实例,是向客户端输出内容常用的对象
5.page对象
page对象就是指向当前JSP页面本身,有点象类中的this指针,它是java.lang.Object类的实例
6.application对象
application对象实现了用户间数据的共享,可存放全局变量。它开始于服务器的启动,直到服务器的关闭,在此期间,此对象将一直存在;这样在用户的前后连接或不同用户之间的连接中,可以对此对象的同一属性进行操作;在任何地方对此对象属性的操作,都将影响到其他用户对此的访问。服务器的启动和关闭决定了application对象的生命。它是ServletContext类的实例。
7.exception对象
exception对象是一个例外对象,当一个页面在运行过程中发生了例外,就产生这个对象。如果一个JSP页面要应用此对象,就必须把isErrorPage设为true,否则无法编译。他实际上是java.lang.Throwable的对象
8.pageContext对象
pageContext对象提供了对JSP页面内所有的对象及名字空间的访问,也就是说他可以访问到本页所在的SESSION,也可以取本页面所在的application的某一属性值,他相当于页面中所有功能的集大成者,它的本类名也叫pageContext。
9.config对象
config对象是在一个Servlet初始化时,JSP引擎向它传递信息用的,此信息包括Servlet初始化时所要用到的参数(通过属性名和属性值构成)以及服务器的有关信息(通过传递一个ServletContext对象)
262,其实解释就一句话,application服务器就创建了一个,C选项后面错误了,不是多个
application对象保存了一个应用系统中的公有数据,一旦创建了application对象,除非服务器关闭,否则application对象就会一直存在,而且只有一个。
263,注意,题目中是问“进程”的哪个区,而不是JVM的哪个区。
“进程的区”属于操作系统里面的
【下面来自博客http://www.cnblogs.com/liulipeng/archive/2013/09/13/3319675.html】
一条进程的栈区、堆区、数据区和代码区在内存中的映射
1>栈区:主要用来存放局部变量, 传递参数, 存放函数的返回地址。.esp 始终指向栈顶, 栈中的数据越多, esp的值越小。
2>堆区:用于存放动态分配的对象, 当你使用 malloc和new 等进行分配时,所得到的空间就在堆中。动态分配得到的内存区域附带有分配信息, 所以你 能够 free和delete它们。
3>数据区:全局,静态和常量是分配在数据区中的,数据区包括bss(未初始化数据区)和初始化数据区。
注意:
1)堆向高内存地址生长;
2)栈向低内存地址生长;
3)堆和栈相向而生,堆和栈之间有个临界点,称为stkbrk。
1、一条进程在内存中的映射
假设现在有一个程序,它的函数调用顺序如下:
main(…) ->; func_1(…) ->; func_2(…)->; func_3(…),即:主函数main调用函数func_1; 函数func_1调用函数func_2;函数func_2调用函数func_3。
当一个程序被操作系统调入内存运行, 其对应的进程在内存中的映射如下图所示:
图
4月25号:
264,我感觉主要原因应该是main方法和静态私有变量处在同一个类中,变量对main方法是可见的,所以可以访问,如果不在同一个类里面的话,是不可以访问私有变量的
265,因为x的 修饰符为 static所以x为类变量,即对于所有的实例来说,他们访问的x为同一个x,类变量存储在方法区,不属于每个实例的私有,
刚开始x=100
调用hs1.x++ x为101;
调用hs2.x++ x为102;
调用hs1.x++ x为103 (此时hs1指向了一个新的HasStatic实例,但是依然访问的是同一个X)
调用HasStatic.x— x为102
266,ArrayList是基于数组实现的,所以查询快,增删慢;LinkedList是基于链表实现的,所以查找慢,增删快。
267,java的数据类型分为两大类:基本类型和引用类型;
基本类型只能保存一些常量数据,引用类型除了可以保存数据,还能提供操作这些数据的功能;
为了操作基本类型的数据,java也对它们进行了封装, 得到八个类,就是java中的基本类型的封装类;他们分别是:
八种基本类型: byte shortint long float double char boolean
对应的包装类 : Byte Short Integer Long Float Double Character Boolean
268,接口中声明的数据成员,默认是public static final 的。并且interface只能被public ,abstract修饰。 这里的数据成员修饰符也就是public。
269,AWT :是通过调用操作系统的native方法实现的,所以在Windows系统上的AWT窗口就是Windows的风格,而在Unix系统上的则是XWindow风格。AWT 中的图形函数与 操作系统 所提供的图形函数之间有着一一对应的关系,我们把它称为peers。也就是说,当我们利用 AWT 来构件图形用户界面的时候,我们实际上是在利用 操作系统 所提供的图形库。由于不同操作系统 的图形库所提供的功能是不一样的,在一个平台上存在的功能在另外一个平台上则可能不存在。为了实现Java语言所宣称的”一次编译,到处运行”的概念,AWT 不得不通过牺牲功能来实现其平台无关性,也就是说,AWT 所提供的图形功能是各种通用型操作系统所提供的图形功能的交集。由于AWT 是依靠本地方法来实现其功能的,我们通常把AWT控件称为重量级控件。
Swing :是所谓的Lightweight组件,不是通过native方法来实现的,所以Swing的窗口风格更多样化。但是,Swing里面也有heaveyweight组件。比如JWindow,Dialog,JFrame
Swing是所谓的Lightweight组件,不是通过native方法来实现的,所以Swing的窗口风格更多样化。但是,Swing里面也有heaveyweight组件。比如JWindow,Dialog,JFrame
Swing由纯Java写成,可移植性好,外观在不同平台上相同。所以Swing部件称为轻量级组件( Swing是由纯JAVA CODE所写的,因此SWING解决了JAVA因窗口类而无法跨平台的问题,使窗口功能也具有跨平台与延展性的特性,而且SWING不需占有太多系统资源,因此称为轻量级组件!!!)
270,创建Servlet的实例是由Servlet容器来完成的,且创建Servlet实例是在初始化方法init()之前
271,Servlet的生命周期分为5个阶段:加载、创建、初始化、处理客户请求、卸载。
(1)加载:容器通过类加载器使用servlet类对应的文件加载servlet
(2)创建:通过调用servlet构造函数创建一个servlet对象
(3)初始化:调用init方法初始化
(4)处理客户请求:每当有一个客户请求,容器会创建一个线程来处理客户请求
(5)卸载:调用destroy方法让servlet自己释放其占用的资源
272,getParameter()是获取POST/GET传递的参数值;
getInitParameter获取Tomcat的server.xml中设置Context的初始化参数
getAttribute()是获取对象容器中的数据值;
getRequestDispatcher是请求转发。
273,C,java不完全算是编译型语言,他编译的字节码文件运行时是解释执行的,其次,java和C++的类也不都完全是静态绑定的,比如C+++的虚函数,java的父类引用子类对象等情况。
D,java也可以数组溢出,溢出是会抛出异常,也就是ArrayIndexOutOfBoundsException
274,java1.8实测,抽象类中的抽象方法和非抽象方法在不加修饰符的情况下,都是默认的default
275,servlet在多线程下其本身并不是线程安全的。
如果在类中定义成员变量,而在service中根据不同的线程对该成员变量进行更改,那么在并发的时候就会引起错误。最好是在方法中,定义局部变量,而不是类变量或者对象的成员变量。由于方法中的局部变量是在栈中,彼此各自都拥有独立的运行空间而不会互相干扰,因此才做到线程安全。
276,DynaVaidatorActionForm动态验证表单Validation确认的意思。
277,1、答案应该是C、D。
2、能够对对象进行传输的貌似只有ObjectOutputStream和ObjectInputStream这些以Object开头的流对象。
3、D项继承Seriallizable接口是经常见到的,这毋庸置疑。
4、transient 修饰的变量在对象串化的时侯并不会将所赋值的值保存到传中,串化的对象从磁盘读取出来仍然是null。
5、这值得说下Volatile这个修饰符,它是针对多线程情况下出现的。当线程读取它修饰的变量时,都会强迫从主存中重新读取。
278,1. HashMap,TreeMap 未进行同步考虑,是线程不安全的。
2. HashTable 和 ConcurrentHashMap 都是线程安全的。区别在于他们对加锁的范围不同,HashTable 对整张Hash表进行加锁,而ConcurrentHashMap将Hash表分为16桶(segment),每次只对需要的桶进行加锁。
3. Collections 类提供了synchronizedXxx()方法,可以将指定的集合包装成线程同步的集合。比如,
List list = Collections.synchronizedList(new ArrayList());
Set set = Collections.synchronizedSet(new HashSet());
4月27号:
279,java程序种类:
1.内嵌于web文件中,有浏览器观看的applet
2.可独立运行的application
3.服务器端的servlets
280,一个类的内部可以有多个方法名为main的方法啊,是有定义为 public static void的main方法才是主类吧
281,this()才必须是构造函数中的第一个可执行语句,用this调用语句并不需要。
282,Java的异常分为两种,一种是运行时异常(RuntimeException),一种是非运行异常也叫检查式异常(CheckedException)。
1、运行时异常不需要程序员去处理,当异常出现时,JVM会帮助处理。常见的运行时异常有:
ClassCastException(类转换异常)
ClassNotFoundException
IndexOutOfBoundsException(数组越界异常)
NullPointerException(空指针异常)
ArrayStoreException(数组存储异常,即数组存储类型不一致)
还有IO操作的BufferOverflowException异常
2、非运行异常需要程序员手动去捕获或者抛出异常进行显示的处理,因为Java认为Checked异常都是可以被修复的异常。常见的异常有:
IOException
SqlException
283,1)抽象类可以包括抽象方法和非抽象方法
2)如果类里面有抽象方法的话,那么类一定要声明为抽象的!
284,private当前类使用,public无使用限制 protected同一包或子类中使用 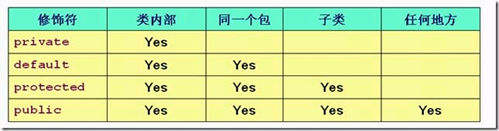
285,Java中数组是对象,不是基本数据类型(原生类),大小不可变且连续存储,因为是对象所以存在堆中。
286,动态 INCLUDE 用jsp:include 动作实现
静态 INCLUDE 用 include 伪码实现 , 定不会检查所含文件的变化 , 适用于包含静态页面 <%@ include file=”included.htm” %> 。先将文件的代码被原封不动地加入到了主页面从而合成一个文件,然后再进行翻译,此时不允许有相同的变量。
以下是对 include 两种用法的区别 , 主要有两个方面的不同 ;
一 : 执行时间上 :
<%@ include file=”relativeURI”%> 是在翻译阶段执行
二 : 引入内容的不同 :
<%@ include file=”relativeURI”%>
引入静态文本 (html,jsp), 在 JSP 页面被转化成 servlet 之前和它融和到一起 .
287,静态的include不允许变量同名
288,A this指当前对象只能在实际方法和构造函数中调用。C 可以调用其他类的非私有类方法。D 不能直接调用,到先生成对象。通过对象即可调用实例方法。
289,最简单的想法就是,,,想一想主函数,Java中的main函数不就是static的吗?……………………,这样想一直使用的main可以做什么,不能做什么…………这样答案不就出来了吗?
290,抽象类
特点:
1.抽象类中可以构造方法
2.抽象类中可以存在普通属性,方法,静态属性和方法。
3.抽象类中可以存在抽象方法。
4.如果一个类中有一个抽象方法,那么当前类一定是抽象类;抽象类中不一定有抽象方法。
5.抽象类中的抽象方法,需要有子类实现,如果子类不实现,则子类也需要定义为抽象的。
接口
1.在接口中只有方法的声明,没有方法体。
2.在接口中只有常量,因为定义的变量,在编译的时候都会默认加上
public static final
3.在接口中的方法,永远都被public来修饰。
4.接口中没有构造方法,也不能实例化接口的对象。
5.接口可以实现多继承
6.接口中定义的方法都需要有实现类来实现,如果实现类不能实现接口中的所有方法
7.则实现类定义为抽象类。
291,被final修饰的变量是常量,这里的b6=b4+b5可以看成是b6=10;在编译时就已经变为b6=10了
而b1和b2是byte类型,java中进行计算时候将他们提升为int类型,再进行计算,b1+b2计算后已经是int类型,赋值给b3,b3是byte类型,类型不匹配,编译不会通过,需要进行强制转换。
Java中的byte,short,char进行计算时都会提升为int类型。
292,以下翻译来自java8的官方文档:
1、LinkedBlockingQueue:基于链接节点的可选限定的blocking queue 。 这个队列排列元素FIFO(先进先出)。 队列的头部是队列中最长的元素。队列的尾部是队列中最短时间的元素。 新元素插入队列的尾部,队列检索操作获取队列头部的元素。 链接队列通常具有比基于阵列的队列更高的吞吐量,但在大多数并发应用程序中的可预测性能较低。
blocking queue说明:不接受null元素;可能是容量有限的;实现被设计为主要用于生产者 - 消费者队列;不支持任何类型的“关闭”或“关闭”操作,表示不再添加项目实现是线程安全的;
2、PriorityQueue:
2.1、基于优先级堆的无限优先级queue 。 优先级队列的元素根据它们的有序natural ordering ,或由一个Comparator在队列构造的时候提供,这取决于所使用的构造方法。优先队列不允许null元素。 依靠自然排序的优先级队列也不允许插入不可比较的对象(这样做可能导致ClassCastException )。
2.2、该队列的头部是相对于指定顺序的最小元素。 如果多个元素被绑定到最小值,那么头就是这些元素之一 - 关系被任意破坏。 队列检索操作poll , remove , peek和element访问在队列的头部的元件。
2.3、优先级队列是无限制的,但是具有管理用于在队列上存储元素的数组的大小的内部容量 。 它始终至少与队列大小一样大。 当元素被添加到优先级队列中时,其容量会自动增长。没有规定增长政策的细节。
2.4、该类及其迭代器实现Collection和Iterator接口的所有可选方法。 方法iterator()中提供的迭代器不能保证以任何特定顺序遍历优先级队列的元素。如果需要有序遍历,请考虑使用Arrays.sort(pq.toArray()) 。
2.5、请注意,此实现不同步。 如果任何线程修改队列,多线程不应同时访问PriorityQueue实例。而是使用线程安全的PriorityBlockingQueue类。
实现注意事项:此实现提供了O(log(n))的时间入队和出队方法(offer , poll , remove()和add ); remove(Object)和contains(Object)方法的线性时间; 和恒定时间检索方法( peek , element和size)。
3、ConcurrentLinkedQueue:基于链接节点的无界并发deque(deque是双端队列) 。 并发插入,删除和访问操作可以跨多个线程安全执行。 A ConcurrentLinkedDeque是许多线程将共享对公共集合的访问的适当选择。像大多数其他并发集合实现一样,此类不允许使用null元素。
293,JAVA的初始化顺序:
父类的静态成员初始化>父类的静态代码块>子类的静态成员初始化>子类的静态代码块>父类的代码块>父类的构造方法>子类的代码块>子类的构造方法
注意:
1.静态成员和静态代码块只有在类加载的时候执行一次,再次创建实例时,不再执行,因为只在方法区存在一份,属于一整个类。
2.上述的是通用的加载顺序,如果没有则省略。
294,java 没有静态构造函数,只有静态初始化块!!!这道题说法不专业,看题目答案推断,静态构造函数指的是静态初始化块
295,Java 语言是一个面向对象的语言,但是Java中的基本数据类型却是不面向对象的,这在实际使用时存在很多的不便,为了解决这个不足,在设计类时为每个基本数据类型设计了一个对应的类进行代表,即包装类。对应的基本类型和包装类如下表: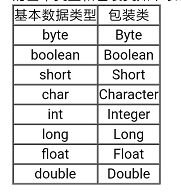
296,这些都是JSP内置对象
JSP内置对象有:
1.request对象
客户端的请求信息被封装在request对象中,通过它才能了解到客户的需求,然后做出响应。它是HttpServletRequest类的实例。
2.response对象
response对象包含了响应客户请求的有关信息,但在JSP中很少直接用到它。它是HttpServletResponse类的实例。
3.session对象
session对象指的是客户端与服务器的一次会话,从客户连到服务器的一个WebApplication开始,直到客户端与服务器断开连接为止。它是HttpSession类的实例.
4.out对象
out对象是JspWriter类的实例,是向客户端输出内容常用的对象
5.page对象
page对象就是指向当前JSP页面本身,有点象类中的this指针,它是java.lang.Object类的实例
6.application对象
application对象实现了用户间数据的共享,可存放全局变量。它开始于服务器的启动,直到服务器的关闭,在此期间,此对象将一直存在;这样在用户的前后连接或不同用户之间的连接中,可以对此对象的同一属性进行操作;在任何地方对此对象属性的操作,都将影响到其他用户对此的访问。服务器的启动和关闭决定了application对象的生命。它是ServletContext类的实例。
7.exception对象
exception对象是一个例外对象,当一个页面在运行过程中发生了例外,就产生这个对象。如果一个JSP页面要应用此对象,就必须把isErrorPage设为true,否则无法编译。他实际上是java.lang.Throwable的对象
8.pageContext对象
pageContext对象提供了对JSP页面内所有的对象及名字空间的访问,也就是说他可以访问到本页所在的SESSION,也可以取本页面所在的application的某一属性值,他相当于页面中所有功能的集大成者,它的本类名也叫pageContext。
9.config对象
config对象是在一个Servlet初始化时,JSP引擎向它传递信息用的,此信息包括Servlet初始化时所要用到的参数(通过属性名和属性值构成)以及服务器的有关信息(通过传递一个ServletContext对象)
297,A:正确main方法是入口
B:J2SDK当然不仅仅包含javaAPI
C:jar选项是java.exe 的选项
D:Appletviewer是运行applet的, applet 不用main方法,继承applet类即可。
298,java程序的种类
1.Application:Java应用程序,是可以由Java解释器直接运行的程序。
2.Applet:即Java小应用程序,是可随网页下载到客户端由浏览器解释执行的Java程序。
3.Servlet:Java服务器端小程序,由Web服务器(容器)中配置运行的Java程序。
299,我是这么记的,substring后面跟的两个int值的索引下标是一个左闭右开的集合。包含左边的,不包含右边的
300,程序的逻辑很简单。程序必须打开两个文件,以可读的方式打开一个已有文件和以可写的方式打开一个新文件,后将已有文件中的内容,暂时存放在内存中,再写入新的文件,后关闭所有文件,程序结束。
根据题意,首先需要读入一个文件中的字符,需要FileInputStream fin = new FileInputStream(this.filename);
301,mark一下:jdk8之后,接口可以定义 static方法 与 default方法。 static方法只能通过接口调用,不能通过实现类调用。default只能通过接口实现类调用,不能通过接口名调用。
302,—y会获得y-1之后的结果,为4
x/=—y相当于x=x/4,x为double类型,4转换为double类型,得到小数0.75
303,由于String不可变,故当执行change方法时候,str的地址会指向“test ok”,但是当执行完以后,依旧会输出原来地址指向的“good”,而char类型是可变的故选择B
304,注意:
1、java语言参数之间只有值传递,包括按值调用和按引用调用。 一个方法可以修改传递引用所对应的变量值,而不能修改传递值调用所对应的变量值。
按值调用:包括八大基本数据类型都是按值调用。传值的时候,也就是说方法得到的是所有参数值的一个拷贝。
按引用调用:数组、对象。传值时候,传递的是引用地址的拷贝,但是都是指向同一个对象。
2、String是不可变类(finaland Immutable),这里只是把副本的指向修改成指向“testok”,原地址str的指向的值没有发生改变。
305,instanceof 用来判断某个实例变量是否属于某种类的类型。这句话不准确,instanceof可以用来判断某个实例变量是否属于某种类的类型,但它的功能不局限于此,比如还可以判断某个类是否属于某个类的子类的类型。
5月1号:
306,javac.exe是编译功能javaCompilerjava.exe是执行class,如果没有编译的话是不能执行的,同理,javac.exe编译完以后如果没有java.exe执行的话也是没有运行的
307,定义线程,按照题目中说的应该是Thread类
其中start()是线程开始执行
init()看名字就知道睡是初始化了
run()才是定义线程内部执行的方法
synchronized()这个是什么方法就不知道了。。 synchronized是同步用的关键字,但 synchronized()方法就没见过了。
308,抽象类可以申明对象吧,只是不能实例化
309,Vector & ArrayList 的主要区别
1) 同步性:Vector是线程安全的,也就是说是同步的,而ArrayList 是线程序不安全的,不是同步的 数2。
2)数据增长:当需要增长时,Vector默认增长为原来一倍,而ArrayList却是原来的50% ,这样,ArrayList就有利于节约内存空间。
如果涉及到堆栈,队列等操作,应该考虑用Vector,如果需要快速随机访问元素,应该使用ArrayList 。
扩展知识:
1. Hashtable & HashMap
Hashtable和HashMap它们的性能方面的比较类似 Vector和ArrayList,比如Hashtable的方法是同步的,而HashMap的不是。
2. ArrayList & LinkedList
ArrayList的内部实现是基于内部数组Object[],所以从概念上讲,它更象数组,但LinkedList的内部实现是基于一组连接的记录,所以,它更象一个链表结构,所以,它们在性能上有很大的差别:
从上面的分析可知,在ArrayList的前面或中间插入数据时,你必须将其后的所有数据相应的后移,这样必然要花费较多时间,所以,当你的操作是在一列数据的后面添加数据而不是在前面或中间,并且需要随机地访问其中的元素时,使用ArrayList会提供比较好的性能; 而访问链表中的某个元素时,就必须从链表的一端开始沿着连接方向一个一个元素地去查找,直到找到所需的元素为止,所以,当你的操作是在一列数据的前面或中间添加或删除数据,并且按照顺序访问其中的元素时,就应该使用LinkedList了。
310,collection类型的集合(ArrayList,LinkedList)只能装入对象类型的数据,该题中装入了0,是一个基本类型,但是JDK5以后提供了自动装箱与自动拆箱,所以int类型自动装箱变为了Integer类型。编译能够正常通过。
将list1的引用赋值给了list2,那么list1和list2都将指向同一个堆内存空间。instanceof是Java中关键字,用于判断一个对象是否属于某个特定类的实例,并且返回boolean类型的返回值。显然,list1.get(0)和list2.get(0)都属于Integer的实例
311,A: 垃圾回收在jvm中优先级相当相当低。
B:垃圾收集器(GC)程序开发者只能推荐JVM进行回收,但何时回收,回收哪些,程序员不能控制。
C:垃圾回收机制只是回收不再使用的JVM内存,如果程序有严重BUG,照样内存溢出。
D:进入DEAD的线程,它还可以恢复,GC不会回收
312,析构函数(destructor) 与 构造函数 相反,当对象结束其 生命周期时(例如对象所在的函数已调用完毕),系统自动执行析构函数。析构函数往往用来做“清理善后”的工作(例如在建立对象时用new开辟了一片内存空间,应在退出前在析构函数中用delete释放)。
313,====目测答案从C修改为D了,所以大家若碰到,就选D咯(lll¬ω¬)=====
public Method[] getDeclaredMethods()返回类或接口声明的所有方法,包括public, protected, default (package) 访问和private方法的Method对象,但不包括继承的方法。当然也包括它所实现接口的方法。
public Method[] getMethods()返回类的所有public方法,包括其继承类的公用方法,当然也包括它所实现接口的方法。
314,A,D是正确的;创建Statement是不传参的,PreparedStatement是需要传入sql语句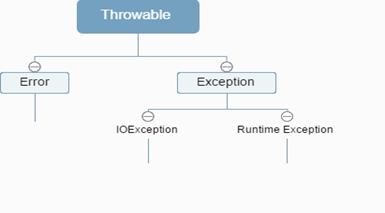
315,抽象类
特点:
1.抽象类中可以构造方法
2.抽象类中可以存在普通属性,方法,静态属性和方法。
3.抽象类中可以存在抽象方法。
4.如果一个类中有一个抽象方法,那么当前类一定是抽象类;抽象类中不一定有抽象方法。
5.抽象类中的抽象方法,需要有子类实现,如果子类不实现,则子类也需要定义为抽象的。
6,抽象类不能被实例化,抽象类和抽象方法必须被abstract修饰
关键字使用注意:
抽象类中的抽象方法(其前有abstract修饰)不能用private、static、synchronized、native访问修饰符修饰。
接口
1.在接口中只有方法的声明,没有方法体。
2.在接口中只有常量,因为定义的变量,在编译的时候都会默认加上public staticfinal
3.在接口中的方法,永远都被public来修饰。
4.接口中没有构造方法,也不能实例化接口的对象。(所以接口不能继承类)
5.接口可以实现多继承
6.接口中定义的方法都需要有实现类来实现,如果实现类不能实现接口中的所有方法则实现类定义为抽象类。
7,接口可以继承接口,用extends
316,1、抽象类和方法都不能被实例化
2、抽象类可以实现接口
3、抽象类方法默认访问权限都是default
4、接口就是访问的,默认访问权限都是public
317,非纯数字的字符串转化为Integer对象会报数字格式异常。
318,1、抽象类中的抽象方法(其前有abstract修饰)不能用private、static、synchronized、native访问修饰符修饰。原因如下:抽象方法没有方法体,是用来被继承的,所以不能用private修饰;static修饰的方法可以通过类名来访问该方法(即该方法的方法体),抽象方法用static修饰没有意义;使用synchronized关键字是为该方法加一个锁。。而如果该关键字修饰的方法是static方法。则使用的锁就是class变量的锁。如果是修饰 类方法。则用this变量锁。但是抽象类不能实例化对象,因为该方法不是在该抽象类中实现的。是在其子类实现的。所以。锁应该归其子类所有。所以。抽象方法也就不能用synchronized关键字修饰了;native,这个东西本身就和abstract冲突,他们都是方法的声明,只是一个吧方法实现移交给子类,另一个是移交给本地操作系统。如果同时出现,就相当于即把实现移交给子类,又把实现移交给本地操作系统,那到底谁来实现具体方法呢?
2、接口是一种特殊的抽象类,接口中的方法全部是抽象方法(但其前的abstract可以省略),所以抽象类中的抽象方法不能用的访问修饰符这里也不能用。而且protected访问修饰符也不能使用,因为接口可以让所有的类去 实现(非继承) ,不只是其子类,但是要用public去修饰。接口可以去继承一个已有的接口。
319,1、继承不同。public class Hashtableextends Dictionary implements Map
public class HashMap extends AbstractMapimplements Map
2、Hashtable 中的方法是同步的,而HashMap中的方法在缺省情况下是非同步的。在多线程并发的环境下,可以直接使用Hashtable,但是要使用HashMap的话就要自己增加同步处理了。
3、Hashtable中,key和value都不允许出现null值。
在HashMap中,null可以作为键,这样的键只有一个;可以有一个或多个键所对应的值为null。当get()方法返回null值时,即可以表示 HashMap中没有该键,也可以表示该键所对应的值为null。因此,在HashMap中不能由get()方法来判断HashMap中是否存在某个键, 而应该用containsKey()方法来判断。
4、两个遍历方式的内部实现上不同。
Hashtable、HashMap都使用了 Iterator。而由于历史原因,Hashtable还使用了Enumeration的方式 。
5、哈希值的使用不同,HashTable直接使用对象的hashCode。而HashMap重新计算hash值。
6、Hashtable和HashMap它们两个内部实现方式的数组的初始大小和扩容的方式。HashTable中hash数组默认大小是11,增加的方式是 old2+1。HashMap中hash数组的默认大小是16,而且一定是2的指数
320,Collection
——-List
——-LinkedList 非同步
——ArrayList 非同步,实现了可变大小的元素数组
——Vector 同步
——-Set 不允许有相同的元素
Map
——-HashTable 同步,实现一个key—value映射的哈希表,key和value都不允许出现null值
——-HashMap 非同步,
——-WeakHashMap 改进的HashMap,实现了“弱引用”,如果一个key不被引用,则被GC回收
注:
List接口中的对象按一定顺序排列,允许重复
Set接口中的对象没有顺序,但是不允许重复
Map接口中的对象是key、value的映射关系,key不允许重复
321,在Myeclipse中敲了一下,确实ABDE都可以。也就是说数组命名时名称与[]可以随意排列,但声明的二维数组中第一个中括号中必须要有值,它代表的是在该二维数组中有多少个一维数组。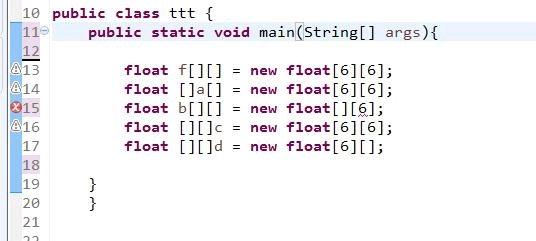
322,Java标识符命名规范是: 1)只能包含字母a-zA-Z,数字0-9,下划线_和美元符号$; 2)首字母不能为数字; 3)关键字和保留字不能作为标识符。 null是关键字,NULL不是关键字,java区分大小写。这题答案D是对的,但C是错的,for是关键字。
323,run()方法是用来定义这个线程在启动的时候需要做什么,但是,直接执行run()方法那就不是线程,必须使用start()启动,那样才是线程。
324,中间件是一种独立的系统软件或服务程序,分布式应用软件借助这种软件在不同的技术之间共享资源。中间件位于客户机/ 服务器的操作系统之上,管理计算机资源和网络通讯。是连接两个独立应用程序或独立系统的软件。相连接的系统,即使它们具有不同的接口,但通过中间件相互之间仍能交换信息。执行中间件的一个关键途径是信息传递。通过中间件,应用程序可以工作于多平台或OS环境。
(简单来说,中间件并不能提高内核的效率,一般只是负责网络信息的分发处理)
325,a,中间件位于操作系统之上,应用软件之下,而不是操作系统内核中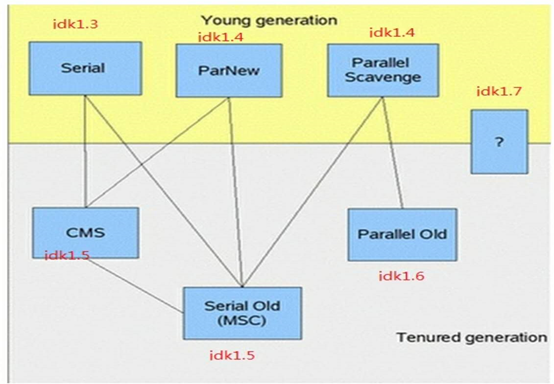
326,G1收集器已在JDK 1.7u4版本正式投入使用。来自百度百科
327,1.Serial收集器
单线程收集器,收集时会暂停所有工作线程(我们将这件事情称之为Stop The World,下称STW),使用复制收集算法,虚拟机运行在Client模式时的默认新生代收集器。
2.ParNew收集器
ParNew 收集器就是Serial的多线程版本,除了使用多条收集线程外,其余行为包括算法、STW、对象分配规则、回收策略等都与Serial收集器一摸一样。对 应的这种收集器是虚拟机运行在Server模式的默认新生代收集器,在单CPU的环境中,ParNew收集器并不会比Serial收集器有更好的效果。
3.Parallel Scavenge收集器
Parallel Scavenge收集器(下称PS收集器)也是一个多线程收集器,也是使用复制算法,但它的对象分配规则与回收策略都与ParNew收集器有所不同,它是 以吞吐量最大化(即GC时间占总运行时间最小)为目标的收集器实现,它允许较长时间的STW换取总吞吐量最大化。
4.Serial Old收集器
Serial Old是单线程收集器,使用标记-整理算法,是老年代的收集器,上面三种都是使用在新生代收集器。
5.Parallel Old收集器
老年代版本吞吐量优先收集器,使用多线程和标记-整理算法,JVM 1.6提供,在此之前,新生代使用了PS收集器的话,老年代除Serial Old外别无选择,因为PS无法与CMS收集器配合工作。
6.CMS(Concurrent Mark Sweep)收集器
CMS 是一种以最短停顿时间为目标的收集器,使用CMS并不能达到GC效率最高(总体GC时间最小),但它能尽可能降低GC时服务的停顿时间,这一点对于实时或 者高交互性应用(譬如证券交易)来说至关重要,这类应用对于长时间STW一般是不可容忍的。CMS收集器使用的是标记-清除算法,也就是说它在运行期间会产生空间碎片,所以虚拟机提供了参数开启CMS收集结束后再进行一次内存压缩。
328,java语言是强类型语言,支持的类型分为两类:基本类型和引用类型。
基本类型包括数值数据类型、字符数据类型、boolean数据类型。数值数据类型有整数类型和浮点类型。整数类型包括:byte、short、int和long;浮点类型包括:float和double。
引用类型包括类、接口和数组类型以及特殊的null类型。 
329,Collection
├List
│├LinkedList
│├ArrayList
│└Vector
│ └Stack
└Set
Map
├Hashtable
├HashMap
└WeakHashMap
330,二维数组的遍历,即每个元素之和
331,a < b && b < c true&& true true
a <= b true
a < ( b + c ) true
! ( a < b ) !true false
332,mock对象:也成为伪对象,在测试中的利用mock对象来代替真实对象,方便测试的进行。
java的封装性:指的是将对象的状态信息隐藏在对象内部,不允许外部程序直接访问对象内部信息,通过该类提供的方法实现对内部信息的操作访问。
反射机制:在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法和属性
333,A.封装
反射破坏代码的封装性,破坏原有的访问修饰符访问限制
334,1、答案选择D。
2、switch case 方法中若,没有break跳出执行则程序就会从第一个匹配上的case一直执行到整个结构结束。
3、所以上述顺序应该执行完是: result = result + i 2;result = result + i * 3;
335,java支持的语言类型分为:基本类型和引用类型。
基本类型包括boolean类型和数值类型,数值类型分为整型和浮点类型,整型包括:byte、short、int、long、char,浮点类型包括float和double。
引用类型包括类、接口和数组
Byte和Float属于基本类型的包装类型,属于引用类型。
336,啥都不说,注意大小写
337,关键的来了,不论向上或者向下转型,都是一句话,“编译看左边,运行看右边”。也就是编译时候,会看左边引用类型是否能正确编译通过,运行的时候是调用右边的对象的方法。
就本题来说,编译时候会发现左边满足条件所以编译通过,运行时候又会调用右边也就是 class B 的方法,所以答案都是150。
338,此题考查的是多态。
对于多态,可以总结它为:
一、使用父类类型的引用指向子类的对象;
二、该引用只能调用父类中定义的方法和变量;
三、如果子类中重写了父类中的一个方法,那么在调用这个方法的时候,将会调用子类中的这个方法;(动态连接、动态调用)
四、变量不能被重写(覆盖),”重写“的概念只针对方法,如果在子类中”重写“了父类中的变量,那么在编译时会报错。
多态的3个必要条件:
1.继承 2.重写 3.父类引用指向子类对象。
向上转型: Person p = new Man() ; //向上转型不需要强制类型转化
向下转型: Man man = (Man)new Person() ; //必须强制类型转化
339,首先是foo(0),在try代码块中未抛出异常,finally是无论是否抛出异常必定执行的语句,
所以 output += “3”;然后是 output += “4”;
执行foo(1)的时候,try代码块抛出异常,进入catch代码块,output += “2”;
前面说过finally是必执行的,即使return也会执行output += “3”
由于catch代码块中有return语句,最后一个output += “4”不会执行。
所以结果是3423
340,A,java是强类型语言,所有的方法必须放在类里面,包括main
B ,java中可以有多个重载的main方法,只有public static void main(String[] args){}是函数入口
C,内部类的类名一般与文件名不同
D,函数都必须用{}括起来,不管是一条语句还是多条语句
341,关于封装:
封住、继承、多态是面向对象的三大特征,其重要性与使用频率不言而喻。———所以B错误。
1 、什么是封装?
封装就是将属性私有化,提供公有的方法访问私有属性。—————————- 所以CD错误。
做法就是:修改属性的可见性来限制对属性的访问,并为每个属性创建一对取值( getter )方法和赋值( setter )方法,用于对这些属性的访问。
如: private String name;
public String getName(){
return;
}
public voidsetName(String name){
this.name=name;
}
2、 为什么需要封装?
通过封装,可以实现对属性的数据访问限制,同时增加了程序的可维护性。
由于取值方法和赋值方法隐藏了实现的变更,因此并不会影响读取或修改该属性的类,避免了大规模的修改,程序的可维护性增强
342,封装主要是隐藏内部代码;
继承主要是复用现有代码;
多态主要是改写对象行为。
343,1.构造方法也是类的方法,可以在创建对象时为成员变量赋值
2.构造方法可以进行重载,但是参数列表必须不相同,不以返回值和访问级别进行区分
3.构造方法没有返回值
4.构造方法一定要与定义为public的类同名
5.构造方法不能被对象调用,只会创建对象,使用new关键字
344,A.正确,因为管道为空,读操作会被阻塞;管道满了,写操作会被阻塞
B.可以有多个进程对其读;也可以有多个进程写,只不过不能同时写。并且题目没有说“同时”,B不对
C.匿名管道只能单向;命名管道可以双向;所以C过于绝对
D.管道是内存中的,所以D不对
345,static成员变量是在类加载的时候生成的
static成员函数既可以通过类名直接调用,也可以通过对象名进行调用
虚函数是C++中的,虚函数不可能是static的
static成员函数可以访问static成员变量
346,Java8的接口方法可以有如下定义
only public, abstract, default, static and strictfp are permitted
347,final修饰类、方法、属性!不能修饰抽象类,因为抽象类一般都是需要被继承的,final修饰后就不能继承了。
final修饰的方法不能被重写而不是重载!
final修饰属性,此属性就是一个常量,不能被再次赋值!
5月2号:
348,能不能被一个包访问是和访问控制符有关系
349,jvm堆分为:新生代(一般是一个Eden区,两个Survivor区),老年代(old区)。
常量池属于 PermGen(方法区)
350,1、为了更好地组织类,Java提供了包机制。包是类的容器,用于分隔类名空间。如果没有指定包名,所有的示例都属于一个默认的无名包。Java中的包一般均包含相关的类,java是跨平台的,所以java中的包和操作系统没有任何关系,java的包是用来组织文件的一种虚拟文件系统。A错
2、import语句并没有将对应的java源文件拷贝到此处仅仅是引入,告诉编译器有使用外部文件,编译的时候要去读取这个外部文件。B错
3、Java提供的包机制与IDE没有关系。C错
4、定义在同一个包(package)内的类可以不经过import而直接相互使用。
351,StringBuffer s = new StringBuffer(x);x为初始化容量长度
s.append(“Y”); “Y”表示长度为y的字符串
length始终返回当前长度即y;
对于s.capacity():
1.当y
2.当x
352,动态 INCLUDE 用jsp:include 动作实现
静态 INCLUDE 用 include 伪码实现 , 定不会检查所含文件的变化 , 适用于包含静态页面 <%@ include file=”included.htm” %> 。先将文件的代码被原封不动地加入到了主页面从而合成一个文件,然后再进行翻译,此时不允许有相同的变量。
以下是对 include 两种用法的区别 , 主要有两个方面的不同 ;
一 : 执行时间上 :
<%@ include file=”relativeURI”%> 是在翻译阶段执行
二 : 引入内容的不同 :
<%@ include file=”relativeURI”%>
引入静态文本 (html,jsp), 在 JSP 页面被转化成 servlet 之前和它融和到一起 .
353,静态的include不允许变量同名
354,A,我们写java程序的时候只是设定事物的隔离级别,而不是去实现它
B,Hibernate是一个java的数据持久化框架,方便数据库的访问
C,事物隔离级别由数据库系统实现,是数据库系统本身的一个功能
D,JDBC是java databaseconnector,也就是java访问数据库的驱动
355,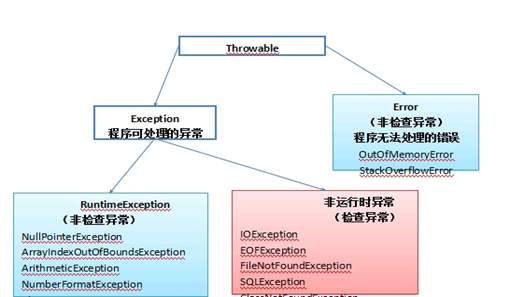
都是Throwable的子类:
1.Exception(异常) :是程序本身可以处理的异常。
2.Error(错误): 是程序无法处理的错误。这些错误表示故障发生于虚拟机自身、或者发生在虚拟机试图执行应用时,一般不需要程序处理。
3.检查异常(编译器要求必须处置的异常): 除了Error,RuntimeException及其子类以外,其他的Exception类及其子类都属于可查异常。这种异常的特点是Java编译器会检查它,也就是说,当程序中可能出现这类异常,要么用try-catch语句捕获它,要么用throws子句声明抛出它,否则编译不会通过。
4.非检查异常(编译器不要求处置的异常): 包括运行时异常(RuntimeException与其子类)和错误(Error)。
356,日志的级别之间的大小关系如右所示:ALL < TRACE
357,不可变类(Immutable Class)是一旦被实例化就不会改变自身状态(或值)的类。
String就是一种典型的不可变类。
不可变类的主要用途是在多线程环境下确保对象的线程安全。
不可变类一般建议使用final来修饰(比如String就是final类),否则子类可以通过继承不可变类的方式,增加setter方法,从而改变对象的状态,破坏了不可变的约束。
这一题我个人认为答案C也可以算作是final的作用,只不过ABD是更加常见和直接的final用法。
358,final在Java中作用:
1、Class:修饰一个不能被继承的类(no-inherited);
2、Math:修饰一个不能被重写的方法(no-overrided);
3、veriable:修饰一个常量;
359,A.文件分为文本文件和二进制文件,计算机只认识二进制,所以实际上都是二进制的不同解释方式。文本文件是以不同编码格式显示的字符,例如Ascii、Unicode等,window中文本文件的后缀名有”.txt”,”.log”,各种编程语言的源码文件等;二进制文件就是用文本文档打开是看不懂乱码,只要能用文本打开的文件都可以算是文本文件,只是显示的结果不是你想要的,二进制文件只有用特殊的应用才能读懂的文件,例如”.png”,”.bmp”等,计算机中大部分的文件还是二进制文件。
B.File类是对文件整体或者文件属性操作的类,例如创建文件、删除文件、查看文件是否存在等功能,不能操作文件内容;文件内容是用IO流操作的。
C.当输入过程中意外到达文件或流的末尾时,抛出EOFException异常,正常情况下读取到文件末尾时,返回一个特殊值表示文件读取完成,例如read()返回-1表示文件读取完成。
D.上面A选项已经说了,不论是文本文件还是二进制文件,在计算机中都是以二进制形式存储的,所以都当做二进制文件读取。
360,说白了private方法只可以在类的内部使用,在类外根本访问不到,而final方法可以在类外访问,但是不可以重写该方法,就是说可以使用该方法的功能但是不可以改变其功能,这就是private方法和final方法的最大区别 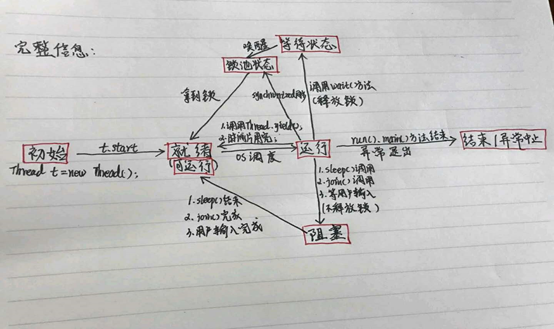
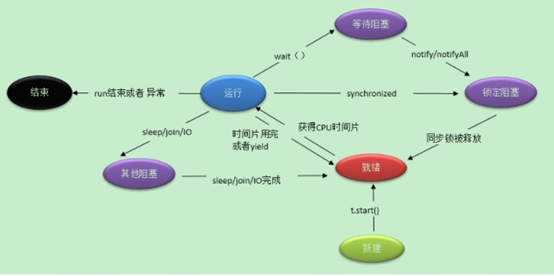
361,1.A选项。一个类中有抽象方法则必须申明为抽象类。
public abstract class HaveAbstractMethod {
public abstract void method1();}
2.B选项。 我建一个接口,然后一个抽象类implements这个接口,并override的所有方法。然后我在建一个类extends这个抽象类,并且不能为任何抽象方法提供任何细节或方法体时,这时这个类必须是抽象类。
public interface MyInterface { public void method1();}
public abstract class MyAbstractClass implements MyInterface{
@Override
public void method1() { } }
public abstract class ChildAbstractClass extends MyAbstractClass{
@Override
public abstract void method1();
}
3.D选项。我建一个接口,然后一个类implements这个接口,并且不能为任何抽象方法提供任何细节或方法体时,这个类必须是抽象类,并override的所有方法。然后我在建一个普通类extends这个抽象类,就可以为所欲为了。这种情况就是java设计模式中的适配器模式。
public interface MyInterface { public void method1();}
public abstract class MyAbstractClass implements MyInterface{
@Override
public void method1() { } }
public class MyNormalClass extends MyAbstractClass{
@Override
public void method1() {System.out.println(“frommethod1”);}
362,jvm classLoader architecture :
a、Bootstrap ClassLoader/启动类加载器
主要负责jdk_home/lib目录下的核心 api 或 -Xbootclasspath 选项指定的jar包装入工作.
B、Extension ClassLoader/扩展类加载器
主要负责jdk_home/lib/ext目录下的jar包或 -Djava.ext.dirs 指定目录下的jar包装入工作
C、System ClassLoader/系统类加载器
主要负责java -classpath/-Djava.class.path所指的目录下的类与jar包装入工作.
B、 User Custom ClassLoader/用户自定义类加载器(java.lang.ClassLoader的子类)
在程序运行期间, 通过java.lang.ClassLoader的子类动态加载class文件, 体现java动态实时类装入特性.
363,B:init方法:负责初始化Servlet对象。在Servlet的整个生命周期类,init()方法只被调用一次。
D:destroy方法:销毁Servlet对象,释放占用的资源,Servlet要被卸载时调用
364,1、整数类型byte(1个字节)short(2个字节)int(4个字节)long(8个字节)
2、字符类型char(2个字节)
3、浮点类型float(4个字节)double(8个字节)
365,A.java继承中对构造函数是不继承的,只是显式或者隐式调用,所以A选项不对
366,对于外部类来说,只有两种修饰,public和默认(default),因为外部类放在包中,只有两种可能,包可见和包不可见。
对于内部类来说,可以有所有的修饰,因为内部类放在外部类中,与成员变量的地位一致,所以有四种可能。
367,构造方法和普通方法的区别,只有权限修饰和方法名(和类名相同),虽然没有返回值,但是它没有返回类型,包括void!!
类的构造方法:(1)无返回值; (2)其名称与本类名称相同。
368,1. 并发:在 操作系统 中,是指一个时间段中有几个程序都处于已启动运行到运行完毕之间,且这几个程序都是在同一个处理机 上运行。其中两种并发关系分别是同步和互斥
2. 互斥:进程间相互排斥的使用临界资源的现象,就叫互斥。
3. 同步: 进程之间的关系不是相互排斥临界资源的关系,而是相互依赖的关系。进一步的说明:就是前一个进程的输出作为后一个进程的输入,当第一个进程没有输出时第二个进程必须等待。具有同步关系的一组并发进程相互发送的信息称为消息或事件。
其中并发又有伪并发和真并发,伪并发是指单核处理器的并发,真并发是指多核处理器的并发。
4. 并行:在单处理器中多道程序设计系统中,进程被交替执行,表现出一种并发的外部特种;在多处理器系统中,进程不仅可以交替执行,而且可以重叠执行。在多处理器上的程序才可实现并行处理。从而可知,并行是针对多处理器而言的。并行是同时发生的多个并发事件,具有并发的含义,但并发不一定并行,也亦是说并发事件之间不一定要同一时刻发生。
5. 多线程:多线程是程序设计的逻辑层概念,它是进程中并发运行的一段代码。多线程可以实现线程间的切换执行。
6. 异步:异步和同步是相对的,同步就是顺序执行,执行完一个再执行下一个,需要等待、协调运行。异步就是彼此独立,在等待某事件的过程中继续做自己的事,不需要等待这一事件完成后再工作。线程就是实现异步的一个方式。异步是让调用方法的主线程不需要同步等待另一线程的完成,从而可以让主线程干其它的事情。
异步和多线程并不是一个同等关系,异步是最终目的,多线程只是我们实现异步的一种手段。异步是当一个调用请求发送给被调用者,而调用者不用等待其结果的返回而可以做其它的事情。实现异步可以采用多线程技术或则交给另外的进程来处理。
369,A在类中定义的变量称为类的成员变量,在别的类中不可以直接使用局部变量的
C使用别的类的方法需要通过该类的对象引用方法的名字
D只要没有定义任何构造函数,JVM都会为类生成一个默认构造函数
370, load方法来得到一个对象时,此时hibernate会使用延迟加载的机制来加载这个对象,即:当 我们使用session.load()方法来加载一个对象时,此时并不会发出sql语句,当前得到的这个对象其实是一个代理对象,这个代理对象只保存了实 体对象的id值,只有当我们要使用这个对象,得到其它属性时,这个时候才会发出sql语句,从数据库中去查询我们的对象。
相对于load的延迟加载方式,get就直接的多,当我们使用session.get()方法来得到一个对象时,不管我们使不使用这个对象,此时都会发出sql语句去从数据库中查询出来。
371,Hibernate 中get()和load() 的区别:
1.get()采用立即加载方式,而load()采用延迟加载 ; get()方法执行的时候,会立即向数据库发出查询语句, 而load()方法返回的是一个代理(此代理中只有一个id属性),只有等真正使用该对象属性的时候,才会发出 sql语句 2.如果数据库中没有对应的记录,get()方法返回的是null.而load()方法出现异常ObjectNotFoundException
372,垃圾回收过程中的对象销毁–Finalization
就在移除一个对象并回收它的内存空间之前,Java垃圾回收器将会调用各个实例的finalize()方法,这样实例对象就有机会可以释放掉它占用的资源。尽管finalize()方法是保证在回收内存空间之前执行的,但是对具体的执行时间和执行顺序是没有任何保证的。多个实例之间的finalize()执行顺序是不能提前预知的,甚至有可能它们是并行执行的。程序不应该预先假设实例执行finalize()的方法,也不应该使用finalize()方法来回收资源。
在finalize过程中抛出的任何异常都默认被忽略掉了,同时对象的销毁过程被取消
JVM规范并没有讨论关于弱引用的垃圾回收,这是明确声明的。具体的细节留给实现者决定。
垃圾回收是由守护进程执行的
373,我在这里分别把四个选项的api贴过来,自己看看就知道了。
A、 InputStreanReader的构造函数:
InputStreamReader(InputStream in)
创建一个使用默认字符集的 InputStreamReader。InputStreamReader(InputStream in, Charset cs)
创建使用给定字符集的 InputStreamReader。InputStreamReader(InputStream in, CharsetDecoder dec)
创建使用给定字符集解码器的 InputStreamReader。InputStreamReader(InputStream in, String charsetName)
创建使用指定字符集的 InputStreamReader。
B、BufferedReader的构造函数:
BufferedReader(Reader in)
创建一个使用默认大小输入缓冲区的缓冲字符输入流。BufferedReader(Reader in, int sz)
创建一个使用指定大小输入缓冲区的缓冲字符输入流。
C、Writer的构造函数:
protectedWriter()
创建一个新的字符流 writer,其关键部分将同步 writer 自身。protectedWriter(Object lock)
创建一个新的字符流 writer,其关键部分将同步给定的对象。
D、PipedInputStream的构造函数:
PipedInputStream()
创建尚未连接的PipedInputStream。PipedInputStream(int pipeSize)
创建一个尚未连接的PipedInputStream,并对管道缓冲区使用指定的管道大小。PipedInputStream(PipedOutputStream src)
创建PipedInputStream,使其连接到管道输出流src。PipedInputStream(PipedOutputStream src, int pipeSize)
创建一个PipedInputStream,使其连接到管道输出流src,并对管道缓冲区使用指定的管道大小。
374,正确的执行顺序是:父类B静态代码块->子类A静态代码块->父类B非静态代码块->父类B构造函数->子类A非静态代码块->子类A构造函数
也就是说非静态初始化块的执行顺序要在构造函数之前。
375,BC正确,选项B解释,java核心卷I中43页有如下表述:两个数值进行二元操作时,会有如下的转换操作:
如果两个操作数其中有一个是double类型,另一个操作就会转换为double类型。
否则,如果其中一个操作数是float类型,另一个将会转换为float类型。
否则,如果其中一个操作数是long类型,另一个会转换为long类型。
否则,两个操作数都转换为int类型。
故,x==f1[0]中,x将会转换为float类型。
376,StringBuffer类的对象调用toString()方法将转换为String类型 这个正确
两个类都有append()方法 String类没有append方法
可以直接将字符串“test”复制给声明的Stirng类和StringBuffer类的变量 引用类型只有String可以直接复制,其他的都要new出来
两个类的实例的值都能够被改变 StringBuffer类可以直接改变它的内容,不用重新分配地址; String 对象/ 实例是不可以被改变的。
String:
是对象不是原始类型.
为不可变对象,一旦被创建,就不能修改它的值.
对于已经存在的String对象的修改都是重新创建一个新的对象,然后把新的值保存进去.
String 是final类,即不能被继承.
StringBuffer:
是一个可变对象,当对他进行修改的时候不会像String那样重新建立对象
它只能通过构造函数来建立,
StringBuffer sb = new StringBuffer();
!!!:不能通过赋值符号对他进行付值.
sb = “welcome to here!”;//error
对象被建立以后,在内存中就会分配内存空间,并初始保存一个null.向StringBuffer
中赋值的时候可以通过它的append方法.
sb.append(“hello”);
字符串连接操作中StringBuffer的效率要比String高:
String str = new String(“welcome to “);
str += “here”;
的处理步骤实际上是通过建立一个StringBuffer,然后调用append(),最后
再将StringBuffer toSting()(toString方法:StringBuffer类型转化成String类型);
377,A and C
重写Overriding是父类与子类之间多态性的一种表现,重载Overloading是一个类中多态性的一种表现。如果在子类中定义某方法与其父类有相同的名称和参数,我们说该方法被重写 (Overriding)。子类的对象使用这个方法时,将调用子类中的定义,对它而言,父类中的定义如同被“屏蔽”了。如果在一个类中定义了多个同名的方法,它们或有不同的参数个数或有不同的参数类型,则称为方法的重载(Overloading)。
Overloaded的方法是可以改变返回值的类型。
378,构造方法是一种特殊的方法,具有以下特点。
(1)构造方法的方法名必须与类名相同。
(2)构造方法没有返回类型,也不能定义为void,在方法名前面不声明方法类型。
(3)构造方法的主要作用是完成对象的初始化工作,它能够把定义对象时的参数传给对象的域。
(4)一个类可以定义多个构造方法,如果在定义类时没有定义构造方法,则编译系统会自动插入一个无参数的默认构造器,这个构造器不执行任何代码。
(5)构造方法可以重载,以参数的个数,类型,顺序。
379,数组的长度是 .length,而String类型的长度表示的.length(),而集合 的长度表示.size();String 的末尾可以加数字的
5月4号:
380,当你创建一个新的实例对象时,它会得到一块新的内存空间。但是类中的静态成员变量是所有对象共有的,也就是在一片属于类的存储空间中,被所有对象共有。
381,A.抽象类可以有非抽象的方法,而接口中的方法都是抽象方法
B.java中类只能单继承,接口可以‘继承’多个接口
C.抽象类必须有构造方法,接口一定没有构造方法
D.实例化一般指new一个对象,所以抽象类不能实例化
382,只有与类名相同且没有返回值的方法可以叫构造函数
383,服务器端,首先是服务器初始化Socket,然后是与端口进行绑定(blind()),端口创建ServerSocket进行监听(listen()),然后调用阻塞(accept()),等待客户端连接。与客户端发生连接后,会进行相关的读写操作(read(),write()),最后调用close()关闭连接。博客上看的,不知道全面不全面,大神轻喷。
384,HttpServlet容器响应Web客户请求流程如下:
1)Web客户向Servlet容器发出Http请求;
2)Servlet容器解析Web客户的Http请求;
3)Servlet容器创建一个HttpRequest对象,在这个对象中封装Http请求信息;
4)Servlet容器创建一个HttpResponse对象;
5)Servlet容器调用HttpServlet的service方法,这个方法中会根据request的Method来判断具体是执行doGet还是doPost,把HttpRequest和HttpResponse对象作为service方法的参数传给HttpServlet对象;
6)HttpServlet调用HttpRequest的有关方法,获取HTTP请求信息;
7)HttpServlet调用HttpResponse的有关方法,生成响应数据;
8)Servlet容器把HttpServlet的响应结果传给Web客户。
doGet() 或 doPost() 是创建HttpServlet时需要覆盖的方法.
385,Servlet生命周期分为三个阶段:
1.初始化阶段 调用init()方法
2.响应客户请求阶段 调用service()方法
3.终止阶段 调用destroy()方法
386,类中有缺省构造器,不一定要定义构造器
方法可以和类同名,和构造器区别在于必须要有返回值类型
一个类可以定义多个参数列表不同的构造器,实现构造器重载
387,static用来修饰类或类的成员,这时不需要创建实例就能访问(而且不能实例化),在被调用的时候自动实例化,且在内存中产生一个实例。当含有静态成员的非静态类实例化出对象后,这些对象公用这些静态成员,通过类名或对象名都能访问它们
388,方法区: 1.又叫静态区,跟堆一样,被所有的线程共享。方法区包含所有的class和static变量。 2.方法区中包含的都是在整个程序中永远唯一的元素,如class,static变量。
389,方法区和堆内存是线程共享的。
程序计数器、虚拟机栈是线程隔离的。
390,System是java.lang中的一个类,out是System内的一个成员变量,这个变量是一个java.io.PrintStream类的对象,println呢就是一个方法了。
391,带头大哥不能死,中间兄弟不能断!
392,这道题目想考察的知识点是MySQL组合索引(复合索引)的最左优先原则。最左优先就是说组合索引的第一个字段必须出现在查询组句中,这个索引才会被用到。只要组合索引最左边第一个字段出现在Where中,那么不管后面的字段出现与否或者出现顺序如何,MySQL引擎都会自动调用索引来优化查询效率。
根据最左匹配原则可以知道B-Tree建立索引的过程,比如假设有一个3列索引(col1,col2,col3),那么MySQL只会会建立三个索引(col1),(col1,col2),(col1,col2,col3)。
所以题目会创建三个索引(plat_order_id)、(plat_order_id与plat_game_id的组合索引)、(plat_order_id、plat_game_id与plat_id的组合索引)。根据最左匹配原则,where语句必须要有plat_order_id才能调用索引(如果没有plat_order_id字段那么一个索引也调用不到),如果同时出现plat_order_id与plat_game_id则会调用两者的组合索引,如果同时出现三者则调用三者的组合索引。
题目问有哪些sql能使用到索引,个人认为只要Where后出现了plat_order_id字段的SQL语句都会调用到索引,只不过是所调用的索引不同而已,所以选BCDE。如果题目说清楚是调用到三个字段的复合索引,那答案才是BD。 
393,1.String对象不可变、StringBuffer对象可变的含义:举个例子:String str = “aa”; str =”aa”+”bb”; 此时str的值为”aabb”,但是”aabb”不是在开始的字符串”aa”后面直接连接的”bb”,而是又新生成了字符串”aabb”,字符串”aa”一旦被初始化,那么它的值不可能再改变了。 StringBuffer strb = StringBuffer(“aa”);strb.append(“bb”); 此时的strb的值也为”aabb”,但是”aabb”是直接在开始的字符串”aa”后面连接的“bb”,并没有生成新的字符串。
394,stringbuffer是可变长度的,可通过append,insert,remove等方法改变其长度
395,正确答案是B,因为error是系统出错,catch是无法处理的,难以修复的,RuntimeException不需要程序员进行捕获处理,error和exception都是throwable的子类,我们只需要对exception的实例进行捕获即可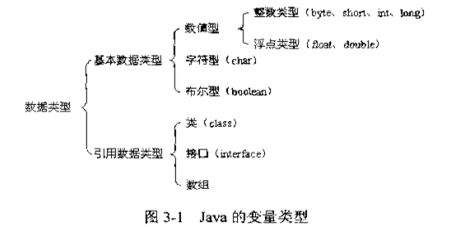
396,通过继承,子类可以拥有所有父类对其可见的方法和域
A.私有方法只能在本类中可见,故不能继承,A错误
B.缺省访问修饰符只在本包中可见,在外包中不可见,B错误
C.保护修饰符凡是继承自该类的子类都能访问,当然可被继承覆盖;C正确
D.static修饰的成员属于类成员,父类字段或方法只能被子类同名字段或方法遮蔽,不能被继承覆盖,D错误
397,记住就行 接口 只能用 public 和 abstract 修饰。only public & abstract arepermitted 。
内部接口 only public, protected, private, abstract & static arepermitted
398,方法重写:
在子类中,出现和父类中一模一样的方法声明的现象。
方法重载:
同一个类中,出现的方法名相同,参数列表不同的现象。
方法重载能改变返回值类型,因为它和返回值类型无关。
Override:方法重写
Overload:方法重载
答案:C
399,编码格式由浏览器决定,浏览器根据html中指定的编码格式进行编码,tomcat根据指定的格式进行解码,另外get请求和post请求对编码格式的处理也是不同的
340,编译后的程序尺寸即class文件大小
过多注释影响编译效率,影响合作开发效率
注释不会影响class文件的执行效率
341,1、abstract类不能用来创建abstract类的对象;
2、final类不能用来派生子类,因为用final修饰的类不能被继承;
3、如2所述,final不能与abstract同时修饰一个类,abstract类就是被用来继承的;
4、类中有abstract方法必须用abstract修饰,但abstract类中可以没有抽象方法,接口中也可以有abstract方法。
5月5号:
342,捕获到的异常不仅可以在当前方法中处理,还可以将异常抛给调用它的上一级方法来处理。
343,效率:StringString(大姐,出生于JDK1.0时代) 不可变字符序列
A,单个与操作的符号& 用在整数上是按位与,用在布尔型变量上跟&&功能类似,但是区别是无论前面是否为真,后面必定执行,因此抛出异常
B,与操作,前半部分判断为假,后面不再执行
C,这里跟 & 和&&的区别类似,后面必定执行,因此抛出异常
D,或语句,前面为真,整个结果必定为真,后面不执行
345,private :修饰私有变量
public : 修饰公有变量
protected: 修饰受保护变量
没有final, final用于保护变量不受改变
因为final不属于访问控制修饰符。
346,( 1 )对于外部类而言,它也可以使用访问控制符修饰,但外部类只能有两种访问控制级别: public 和默认。因为外部类没有处于任何类的内部,也就没有其所在类的内部、所在类的子类两个范围,因此 private 和 protected 访问控制符对外部类没有意义。
( 2 )内部类的上一级程序单元是外部类,它具有 4 个作用域:同一个类( private )、同一个包( protected )和任何位置( public)。
( 3 ) 因为局部成员的作用域是所在方法,其他程序单元永远不可能访问另一个方法中的局部变量,所以所有的局部成员都不能使用访问控制修饰符修饰。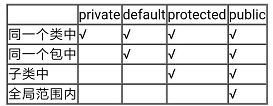
347,Java中基本数据类型大体分为两类 数字类型(byte,short,int,long,float,double,char),布尔类型(boolean); 备注:由于char可以和数字间转换,也可认为大的范围是数字类型的。
348,stream结尾都是字节流,reader和writer结尾都是字符流 两者的区别就是读写的时候一个是按字节读写,一个是按字符。 实际使用通常差不多。 在读写文件需要对内容按行处理,比如比较特定字符,处理某一行数据的时候一般会选择字符流。只是读写文件,和文件内容无关的,一般选择字节流。
349,Float是类,float不是类.
查看JDK源码就可以发现Byte,Character,Short,Integer,Long,Float,Double,Boolean都在java.lang包中.
Float正确复制方式是Float f=1.0f,若不加f会被识别成double型,double无法向float隐式转换.
Float a= new Float(1.0)是正确的赋值方法,但是在1.5及以上版本引入自动装箱拆箱后,会提示这是不必要的装箱的警告,通常直接使用Float f=1.0f.
350,接口方法默认是public abstract的,且实现该接口的类中对应的方法的可见性不能小于接口方法的可见性,因此也只能是public的。
351,public 共有类,可以在包外使用,此时,源文件名必须和类名相同。
abstract 抽象类,抽象类位于继承树的抽象层,抽象类不能被实例化。
final 不能被继承,没有子类,final类中的方法默认是final的。
class 只能在包内使用的类
352,continue是停止本次循环,回到循环起始处,进入下一循环操作。break是直接跳出当前循环。如果需要跳出多重循环,需要在多重循环外面设一个标识flag,然后使用带有标识的break flag,这样就可以跳出多重循环。
353,对于A 既然是构造函数 就没有声明返回值的必要
对于B 构造函数有多种方式 所以是可以用private的 只是在外部这种方法不能给实例化
对于C 既然要构造这个函数 所以肯定是要保持他和类名一样才能实例化这个类
D:构造函数添加参数是可以的,重载方法。(注意* 只写带参数的构造函数程序不会加会把默认的无参数的构造函数)
354,答案选A 解释:这道题考for循环执行顺序 参看 http://jingyan.baidu.com/article/7f766dafaa6ee04101e1d0e6.html
for循环的执行顺序用如下表达式:
for(expression1;expression2;expression3){
expression4;
}
执行的顺序应该是:
1)第一次循环,即初始化循环。
首先执行表达式expression1(一般为初始化语句);再执行expression2(一般为条件判断语句),判断expression1是否符合expression2的条件;如果符合,则执行expression4,否则,停止执行;最后执行expression3。
2)第N(N>=2)次循环
首先执行expression2,判断在expression3是否符合在expression2要求;如果符合,则继续执行在expression4,否则,停止执行。最后执行在expression3。如此往复,直至expression3不满足在expression2条件是为止。
总结:
总的来说,执行的顺序是一致的。先条件判断(expression2),再函数体执行(expression4),最后for执行(expression3)。往复……区别在于,条件判断的对象。第一次判断时,对象为初始化语句(expression1),后续的判断对象为执行后的结果(expression3)。
355,ABD选项的操作符都可用于float和double
只有%取余操作,只适用于整型
356,A.Java中涉及到byte、short和char类型都可以强制转化为int,符合返回类型 A正确
B.方法中定义为void 应该没有返回值,但返回值为boolean类型 B错
C. 方法中类型为int,应该返回int类型值,但是返回值为boolean类型 C错
D.方法应该定义为int(int a,int b),所以D错
357,一个.java文件中定义多个类:
注意一下几点:
(1) public权限类只能有一个(也可以一个都没有,但最多只有一个);
(2)这个.java文件名只能是public权限的类的类名;
(3)倘若这个文件中没有public 类,则它的.java文件的名字是随便的一个类名;
(4)当用javac命令生成编译这个.java文件的时候,则会针对每一个类生成一个.class文件;
358,A 可以调用父类无参的构造函数,子类的有参构造函数和是否调用父类的有参数的构造函数无必然联系。
B 接口继承的时候只能继承接口不能继承类,因为如果类可以存在非抽象的成员,如果接口继承了该类,那么接口必定从类中也继承了这些非抽象成员,这就和接口的定义相互矛盾,所以接口继承时只能继承接口。
C 接口可以多继承可以被多实现,因为接口中的方法都是抽象的,这些方法都被实现的类所实现,即使多个父接口中有同名的方法,在调用这些方法时调用的时子类的中被实现的方法,不存在歧义;同时,接口的中只有静态的常量,但是由于静态变量是在编译期决定调用关系的,即使存在一定的冲突也会在编译时提示出错;而引用静态变量一般直接使用类名或接口名,从而避免产生歧义,因此也不存在多继承的第一个缺点。对于一个接口继承多个父接口的情况也一样不存在这些缺点。所以接口可以多继承。
D 子类即使没有显示构造函数,也会有个无参数的默认构造函数,仍然会调用父类的构造函数。
359,C java命令执行MyTest, a b c 为main函数args实参
答案:CD 思路:对于java命令,类名后面跟着的就是main函数的参数,多个参数则用空格隔开。 main方法的形参是一个string数组所以对于java mytest a b c传入的参数算是一个string数组。 即args[0]=a args[1]=b args[2]=c
360,因为构造方法没有任何返回类型。
361,synchronized 用于方法或者代码块前,使此方法或者代码块变成同步的
static 用于声明静态变量
abstract 用于定义抽象类或者方法
final 用于声明常量,即只能赋值一次的变量
362,抛InterruptedException的代表方法有:
java.lang.Object 类的 wait 方法
java.lang.Thread 类的 sleep 方法
java.lang.Thread 类的 join 方法
363,Object 是基类 Java中的所有的类都直接或间接的继承;所以A对
从一个class派生的必然是另一个class。Object是一个class,如果interface继承自Object,那么interface必然是一个class,所以B错
利用equals()方法进行比较时 会调用== 可以看equals()方法的源码,可以这样说, == 比equal更加强大,所以C错
toString()方法是Object类中 即使不重写也能使用 所以D错
364,这个题选c
java.awt: 包含构成抽象窗口工具集的多个类,用来构建和管理应用程序的图形用户界面
java.lang: 提供java编成语言的程序设计的基础类
java.io: 包含提供多种输出输入功能的类,
java.net: 包含执行与网络有关的类,如URL,SCOKET,SEVERSOCKET,
java.applet: 包含java小应用程序的类
java.util: 包含一些实用性的类
365,异常处理一般格式: 捕获异常: try{ //代码块 }catch(异常类型,例如:Exception e){ //需要抛出的异常,例如:e.printStackTrace(); }catch(异常类型){ //需要抛出的异常 }finally{ //必定执行的代码块 } 所以说在一个异常处理中catch语句块是可以多个的,也就是可以抛出多个异常!
366,八进制,以8为基数的算法,逢8进1.所以8在八进制就是010,前面那个0是为了和十进制区分用的,也叫转译符。
八进制0-7!!!
367,1、List和Set的区别,set中不能放重复的
2、Set中重复的定义,未定义自己的equels方法的话,调用默认的,也就是直接==
由于此题采用的添加的是字符串,而字符串已经实现了equels方法,所以不会产生2中提到的问题,但是自己定义的类就要注意了。
综上所述,题目应该更改为只是为了检测1中的概念
368,list有序可重复,set无序不可重复
369,构造函数不能被继承,构造方法只能被显式或隐式的调用。
370,1.java支持单继承,却可以实现多个接口。a对d错
2.接口没有构造方法,所以不能实例化,抽象类有构造方法,但是不是用来实例化的,是用来初始化的。c对
3.抽象类可以定义普通成员变量而接口不可以,但是抽象类和接口都可以定义静态成员变量,只是接口的静态成员变量要用static final public 来修饰。b错
371,题目的四个选项是构造方法new,序列化对象,反射,克隆分别创建一个对象的方法,,只有new和反射用到了构造方法
372,readObject方法只是从文件中还原对象,clone只是一种复制拷贝对象。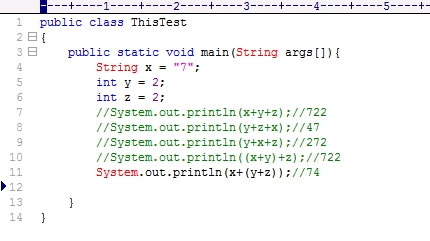
373,还是老话,Java中一切都是对象,Object是所有类的根类!
374,既然是实现接口,就要实现接口的所以方法,相当于重写方法,方法的重写需要满足:三同一大一小(方法名、返回值类型、形参相同;访问权限>=重写前;抛出异常<=重写前)
375,String x=”fmn”; “fmn”是在常量池里的不可变对象。
x.toUpperCase(); 在堆中new一个”FMN”对象,但无任何引用指向它。
String y=x.replace(‘f’,’F’); 在堆中 new一个”Fmn”对象,y指向它。
y=y+”wxy”; 在堆中 重新new一个”Fmnwxy”对象, 修改y指向,现在y指向它。

若有收获,就点个赞吧
0 人点赞
