- 《一》、Java基础
- Java容器
- Java Collection(集合)框架:
- 1、你所知道的集合类都有哪些?主要方法?
- 2、Collection 和 Collections的区别。(宝典142)
- 3、List 和Map 区别?
- 4、Set和List的区别(菜鸟教程)
- 5、List、Map、Set三个接口,存取元素时,各有什么特点?
- 6、Set里的元素是不能重复的,那么用什么方法来区分重复与否呢? 是用==还是equals()? 它们有何区别?
- 7.ArrayList和LinkedList的区别?
- 8、ArrayList、Vector和LinkedList的区别(宝典135)
- 9、说出ArrayList,Vector, LinkedList的存储性能和特性
- 10、去掉一个Vector集合中重复的元素
- 11、HashMap和HashTable的区别?
- 12、HashMap、HashTable、TreeMap和WeakHashMap有哪些区别(宝典136)
- 《二》、JavaWeb
- 《三》、框架
- SpringBoot面试总结一
- 1、什么是springboot
- 2、Spring Boot的优点(为什么要用 Spring Boot?)
- 3、Spring Boot的缺点
- 4、springboot读取配置文件的方式
- 5、Spring Boot 的核心配置文件有哪几个?它们的区别是什么?
- 6、Spring Boot 的配置文件有哪几种格式?它们有什么区别?
- 7、Spring Boot 的核心注解是哪个?它主要由哪几个注解组成的?
- 8、开启 Spring Boot 特性有哪几种方式?
- 9、如何重新加载Spring Boot上的更改,而无需重新启动服务器?
- 10、Spring Boot中的监视器是什么?
- 11、什么是YAML?
- 12、springboot常用的starter有哪些
- 13、springboot自动配置的原理
- 14、springboot集成mybatis的过程
- 15、Spring Boot 需要独立的容器运行吗?
- 16、运行 Spring Boot 有哪几种方式?
- 17、Spring Boot 自动配置原理是什么?
- 18、Spring Boot 的目录结构是怎样的?
- 19、你如何理解 Spring Boot 中的 Starters?
- 20、如何在 Spring Boot 启动的时候运行一些特定的代码?
- 21、Spring Boot 有哪几种读取配置的方式?
- 22、Spring Boot 支持哪些日志框架?推荐和默认的日志框架是哪个?
- 23、SpringBoot 实现热部署有哪几种方式?
- 24、你如何理解 Spring Boot 配置加载顺序?
- 25、Spring Boot 如何定义多套不同环境配置?
- 26、Spring Boot 可以兼容老 Spring 项目吗,如何做?
- 27、如何集成Spring Boot和ActiveMQ?
- 28、保护 Spring Boot 应用有哪些方法?
- 29、Spring Boot 2.X 有什么新特性?与 1.X 有什么区别?
- SpringBoot面试总结二
- 《四》、Jvm
- JVM面试必备知识点学习
- 一)名词解释:
- 二)JVM内存模型
- 三)GC(垃圾收集)
- 1 Java GC机制(重要程度:★★★★★) (对Java GC了解多少)
- 另一篇文章总结
- 2、你知道哪些或者你们线上使⽤什么GC策略?它有什么优势,适⽤于什么场景?
- 3、GC是什么?为什么要有GC?
- 4、做GC时,⼀个对象在内存各个Space中被移动的顺序是什么?
- 5、堆内存设置的参数是什么?
- 6、Perm Space中保存什么数据?会引起OutOfMemory吗?
- 7、你有没有遇到过OutOfMemory问题?你是怎么来处理这个问题的?处理过程中有哪些收获?
- 8、JDK 1.8之后Perm Space有哪些变动? MetaSpace⼤⼩默认是⽆限的么? 还是你们会通过什么⽅式来指定⼤⼩?
- 9、jstack 是⼲什么的? jstat 呢?如果线上程序周期性地出现卡顿,你怀疑可 能是 GC 导致的,你会怎么来排查这个问题?线程⽇志⼀般你会看其中的什么部分?
- 10、StackOverflow异常有没有遇到过?⼀般你猜测会在什么情况下被触发?如何指定⼀个线程的堆栈⼤⼩?⼀般你们写多少?
- 11. 既然有GC机制,为什么还会有内存泄露的情况 (2017-11-16-wl)
- 12.如和判断一个对象是否存活?(或者GC对象的判定方法)
- 13.简述java垃圾回收机制?
- 14.java中垃圾收集的方法有哪些?
- 15、垃圾回收的优点和原理。并考虑2种回收机制。
- 16、垃圾回收器的基本原理是什么?垃圾回收器可以马上回收内存吗?有什么办法主动通知虚拟机进行垃圾回收?
- 17. Java中为什么会有GC机制呢?(2017-11-16-wl)
- 18. 对于Java的GC哪些内存需要回收(2017-11-16-wl)
- 19 Java的GC什么时候回收垃圾(2017-11-16-wl)
- 20 在Java中,对象什么时候可以被垃圾回收?
- 21 JVM的永久代中会发生垃圾回收么?
- 四)类加载机制
- 五)其他
- 《五》、计算机网络
- 计算机网络常考面试题
- 一,OSI与TCP/IP各层的结构、功能、协议
- 2 运输层
- 3 网络层
- 4 数据链路层
- 5 物理层
- 二,TCP 三次握手和四次挥手(面试常客)
- 三,TCP、UDP 协议的区别
- 四,在浏览器中输入url地址 ->> 显示主页的过程
- 五,各种协议与HTTP协议之间的关系
- 六,TCP协议如何保证可靠传输
- 七、状态码
- 八、HTTP长连接、短连接
- 《六》、Linux
- Linux面试必备
- 《七》、Git
- Git面试必备知识点
《一》、Java基础
Java容器
Java Collection(集合)框架:
| Collecion:接口 | ||||||
|---|---|---|---|---|---|---|
| List:接口 【有序的,可以重复、和数组类似,可以动态增长,根据实际存储的数据的长度自动增长List的长度。查找元素效率高,插入删除效率低,因为会引起其他元素位置改变 <实现类有ArrayList,LinkedList,Vector> 。】 |
Set:接口 【无序的、不能重复、检索效率低下,删除和插入效率高,插入和删除不会引起元素位置改变 <实现类有HashSet,TreeSet>】、 |
Queue | ||||
| AbstractList:接口 | AbstractSet:接口 | SortedSet:接口 | ||||
| Vector:实现类 【大多数方法是synchronization同步的;线程安全的;性能比ArrayList低】 |
ArrayList:实现类 【ArrayList的方法是不同步的;线程不安全的;】 |
AbstractSequentialList:接口 | HashSet:实现类 | TreeSet:实现类 | TreeSet:实现类 | |
| Stack | LinkedList:实现类 【双向列表来实现的;随机访问效率低,插入效率高;线程不安全的】 |
LinkedHashSet:实现类 |
| Map:接口 【值value可以重复,但键key是唯一的,不能重复】 |
|||||
|---|---|---|---|---|---|
| AbstractMap:接口 | SortedMap:接口 | ||||
| HashMap:实现类 【基于散列表实现的】 |
WeakHashMap:实现类 | HashTable:实现类 | IdentityHashMap | TreeMap:实现类 | TreeMap:实现类 【基于红黑树实现的】 |
| LinkedHashMap 【采用列表来维护内部的顺序的】 |
1、你所知道的集合类都有哪些?主要方法?
最常用的集合类是 List 和Map。
List 的具体实现包括 ArrayList 和 Vector,它们是可变大小的列表,比较适合构建、存储和操作任何类型对象的元素列表。 List 适用于按数值索引访问元素的情形。
Map 提供了一个更通用的元素存储方法。 Map 集合类用于存储元素对(称作”键”和”值”),其中每个键映射到一个值。
ArrayList/Vector—List
Collection
HashSet/TreeSet—Set
Propeties—HashTable
Map
Treemap/HashMap
我记的不是方法名,而是思想,我知道它们都有增删改查的方法,但这些方法的具体名称,我记得不是很清楚,对于set,大概的方法是add,remove, contains;对于map,大概的方法就是put,remove,contains等,因为,我只要在eclispe下按点操作符,很自然的这些方法就出来了。我记住的一些思想就是List类会有get(int index)这样的方法,因为它可以按顺序取元素,而set类中没有get(int index)这样的方法。List和set都可以迭代出所有元素,迭代时先要得到一个iterator对象,所以,set和list类都有一个iterator方法,用于返回那个iterator对象。map可以返回三个集合,一个是返回所有的key的集合,另外一个返回的是所有value的集合,再一个返回的key和value组合成的EntrySet对象的集合,map也有get方法,参数是key,返回值是key对应的value。
Vector(add、insert、remove、set、equals、hashcod)
2、Collection 和 Collections的区别。(宝典142)
Collection是集合类的上级接口,继承与他的接口主要有Set 和List.
Collection是一个集合接口。它提供了对集合对象进行基本操作的通用接口方法。实现该接口的类主要有List和Set,该接口的设计目标是为各种具体的集合提供最大化的统一操作方式。
Collections是针对集合类的一个包装类。它提供一系列静态方法以实现对各种集合的搜索、排序、线程安全化等操作,其中大多数方法都是用来处理线性表。Collections类不能实例化,如同一个工具类,服务于Collection框架。若在使用Collections类的方法时,对应的Collection的对象为null,则这些方法都会抛出NullPointerException。
3、List 和Map 区别?
一个是存储单列数据的集合,另一个是存储键和值这样的双列数据的集合,List中存储的数据是有顺序,并且允许重复;Map中存储的数据是没有顺序的,其键是不能重复的,它的值是可以有重复的。
4、Set和List的区别(菜鸟教程)
- Set 接口实例存储的是无序的,不重复的数据。List 接口实例存储的是有序的,可以重复的元素。
2. Set检索效率低下,删除和插入效率高,插入和删除不会引起元素位置改变 <实现类有HashSet,TreeSet>。
3. List和数组类似,可以动态增长,根据实际存储的数据的长度自动增长List的长度。查找元素效率高,插入删除效率低,因为会引起其他元素位置改变 <实现类有ArrayList,LinkedList,Vector>。5、List、Map、Set三个接口,存取元素时,各有什么特点?
这样的题属于随意发挥题:这样的题比较考水平,两个方面的水平:一是要真正明白这些内容,二是要有较强的总结和表述能力。如果你明白,但表述不清楚,在别人那里则等同于不明白。
首先,List与Set具有相似性,它们都是单列元素的集合,所以,它们有一个功共同的父接口,叫Collection。Set里面不允许有重复的元素,所谓重复,即不能有两个相等(注意,不是仅仅是相同)的对象,即假设Set集合中有了一个A对象,现在我要向Set集合再存入一个B对象,但B对象与A对象equals相等,则B对象存储不进去,所以,Set集合的add方法有一个boolean的返回值,当集合中没有某个元素,此时add方法可成功加入该元素时,则返回true,当集合含有与某个元素equals相等的元素时,此时add方法无法加入该元素,返回结果为false。Set取元素时,没法说取第几个,只能以Iterator接口取得所有的元素,再逐一遍历各个元素。
List表示有先后顺序的集合,注意,不是那种按年龄、按大小、按价格之类的排序。当我们多次调用add(Obj e)方法时,每次加入的对象就像火车站买票有排队顺序一样,按先来后到的顺序排序。有时候,也可以插队,即调用add(int index,Obj e)方法,就可以指定当前对象在集合中的存放位置。一个对象可以被反复存储进List中,每调用一次add方法,这个对象就被插入进集合中一次,其实,并不是把这个对象本身存储进了集合中,而是在集合中用一个索引变量指向这个对象,当这个对象被add多次时,即相当于集合中有多个索引指向了这个对象,如图x所示。List除了可以以Iterator接口取得所有的元素,再逐一遍历各个元素之外,还可以调用get(index i)来明确说明取第几个。
Map与List和Set不同,它是双列的集合,其中有put方法,定义如下:put(obj key,obj value),每次存储时,要存储一对key/value,不能存储重复的key,这个重复的规则也是按equals比较相等。取则可以根据key获得相应的value,即get(Object key)返回值为key 所对应的value。另外,也可以获得所有的key的结合,还可以获得所有的value的结合,还可以获得key和value组合成的Map.Entry对象的集合。
List 以特定次序来持有元素,可有重复元素。Set 无法拥有重复元素,内部排序。Map保存key-value值,value可多值。
HashSet按照hashcode值的某种运算方式进行存储,而不是直接按hashCode值的大小进行存储。例如,”abc” —-> 78,”def”—-> 62,”xyz” —-> 65在hashSet中的存储顺序不是62,65,78,这些问题感谢以前一个叫崔健的学员提出,最后通过查看源代码给他解释清楚,看本次培训学员当中有多少能看懂源码。LinkedHashSet按插入的顺序存储,那被存储对象的hashcode方法还有什么作用呢?学员想想!hashset集合比较两个对象是否相等,首先看hashcode方法是否相等,然后看equals方法是否相等。new 两个Student插入到HashSet中,看HashSet的size,实现hashcode和equals方法后再看size。
同一个对象可以在Vector中加入多次。往集合里面加元素,相当于集合里用一根绳子连接到了目标对象。往HashSet中却加不了多次的。6、Set里的元素是不能重复的,那么用什么方法来区分重复与否呢? 是用==还是equals()? 它们有何区别?
Set里的元素是不能重复的,元素重复与否是使用equals()方法进行判断的。
equals()和==方法决定引用值是否指向同一对象equals()在类中被覆盖,为的是当两个分离的对象的内容和类型相配的话,返回真值。7.ArrayList和LinkedList的区别?
ArrayList底层使用的是数组,LinkedList使用的是链表。
数组具有索引,查询特定的元素比较快,而插入和删除,修改比较慢 (数组在内存中是一块连续的内存,如果插入或删除时需要移动内存)。
链表不要求内存时连续的,在当前元素中存放下一个或上一个元素的地址,查询时需要从头开始,一个一个地找,查询效率低,而插入时不需要移动内存,只需要改变引用指向即可。所以插入或删除效率高。
ArrayList适用于查询比较多,但是插入和删除比较少的情况。
而LinkedList使用在查询比较少,但是插入和删除比较多的情况。8、ArrayList、Vector和LinkedList的区别(宝典135)
一,相同点:
ArrayList、Vector和LinkedList类均在java.util包中,均为可伸缩数组,即可以动态改变长度的数组。
ArrayList和Vector都是基于存储元素的Object[] array来实现的、都有一个初始化的容量大小,当里面存储的元素超过这个大小时就需要动态地扩充它们的存储空间。其中ArrayList默认扩充为原来的1.5倍(没有提供方法来设置空间扩充的方法),Vector默认扩充为原来的2倍(每次扩充空间的大小都是可以设置的)。
二,不同:
ArrayList、Vector最大的区别就是Synchronization(同步)的使用:
ArrayList的方法是不同步的、线程不安全、性能高。
Vector的绝大多数方法(add、insert、remove、set、equals、hashcod)都是同步的、线程安全的、性能低。
LinkedList是采用双向列表来实现的,对数据的索引需要从列表头开始遍历,因此用于随机访问则效率比较低,但是插入元素时不需要对数据进行移动,因此插入效率比较高。同时,LinkedList是线程不安全的。
三,实际应用中,该如何选择合适的容器:
当对数据的主要操作为索引或只在集合的末端增加、删除元素时,使用ArrayList或Vector效率比较高;
当对数据的操作主要为指定位置的插入或删除操作时,使用LinkedList效率比较高;
当在多线程中使用容器(即多个线程会同时访问该容器)时,使用Vector比较安全;
9、说出ArrayList,Vector, LinkedList的存储性能和特性
ArrayList和Vector都是使用数组方式存储数据,此数组元素数大于实际存储的数据以便增加和插入元素,它们都允许直接按序号索引元素,但是插入元素要涉及数组元素移动等内存操作,所以索引数据快而插入数据慢,Vector由于使用了synchronized方法(线程安全),通常性能上较ArrayList差,而LinkedList使用双向链表实现存储,按序号索引数据需要进行前向或后向遍历,但是插入数据时只需要记录本项的前后项即可,所以插入速度较快。
LinkedList也是线程不安全的,LinkedList提供了一些方法,使得LinkedList可以被当作堆栈和队列来使用。10、去掉一个Vector集合中重复的元素
Vector newVector =new Vector();
For (inti=0;i
Object obj = vector.get(i);
if(!newVector.contains(obj);
newVector.add(obj);
}
还有一种简单的方式,HashSetset = new HashSet(vector);11、HashMap和HashTable的区别?
1.HashMap和HashTable都可以使用来存储key-value的数据。
2.HashMap是可以把null作为key或者value的,而hashTable是不可以的。
3.HashMap是线程不安全的,效率较高。HashTable是线程安全的,效率较低。
问题:我想线程安全又想效率高?
答:使用CurrentHashMap。通过把整个Map分为N个Segment(类似于HashTable),可以提供相同的线程安全,但效率提升N倍,默认是提升16倍。
12、HashMap、HashTable、TreeMap和WeakHashMap有哪些区别(宝典136)
HashMap是Hashtable的区别:
1 HashMap是Hashtable的轻量级实现(非线程安全的实现),他们都完成了Map接口,主要区别在于HashMap允许空(null)键值(key)(但需要注意,最多只允许一条记录的键为null,不允许多条记录的值为null),而Hashtable不允许。由于非线程安全,在只有一个线程访问的情况下,效率要高于Hashtable。
2 HashMap把Hashtable的contains方法去掉了,改成containsvalue和containsKey。因为contains方法容易让人引起误解。 Hashtable继承自Dictionary类,而HashMap是Java1.2引进的Map interface的一个实现。
3 Hashtable的方法是线程安全的,而HashMap不支持线程的同步,所以它不是线程安全的。在多个线程访问Hashtable时,不需要开发人员对它进行同步,而HashMap 就必须为之提供额外的同步机制。所以就效率而言,HashMap》Hashtable
4 Hashtable使用Enumeration,HashMap使用Iterator。
5 Hashtable和HashMap采用的hash/rehash算法都大概一样,所以性能不会有很大的差异。
6 在Hashtable中,hash数组默认大小是11,增加的方式是old*2+1;
在HashMap中,,hash数组默认大小是16,而且一定是2的指数。
7 hash值的使用不同。Hashtable直接使用对象的hashCode。
就HashMap与HashTable主要从三方面来说。
一.历史原因:Hashtable是基于陈旧的Dictionary类的,HashMap是Java 1.2引进的Map接口的一个实现
二.同步性:Hashtable是线程安全的,也就是说是同步的,而HashMap是线程序不安全的,不是同步的
三.值:只有HashMap可以让你将空值作为一个表的条目的key或value
在map中插入、删除和定位元素,HashMap是最后的选择。
如果需要按自然顺序或自定义顺序遍历键,那么TreeMap会更好。
如果需要输出的顺序和输入的相同,那么用LinkedHashMap可以实现,它还可以按读取顺序来排列。WeakHashMap于HashMap的区别:
WeakHashMap于HashMap类似,二者的不同在于WeakHashMap中key采用的是“弱引用”的方式,只要WeakHashMap中的key不再被外部引用,它就可以被垃圾回收器回收。而HashMap中key采用的是“强引用”的方式,当HashMap中的key没有被外部引用时,只有在这个key从HashMap中删除后,才可以被垃圾回收器回收。
《二》、JavaWeb
《三》、框架
SpringBoot面试总结一
1、什么是springboot
答案1:
用来简化spring应用的初始搭建以及开发过程使用特定的方式来进行配置(properties或yml文件)、
创建独立的spring引用程序main方法运行、
嵌入的Tomcat 无需部署war文件、
简化maven配置、
自动配置spring添加对应功能starter自动化配置
答:spring boot来简化spring应用开发,约定大于配置,去繁从简,just run就能创建一个独立的,产品级别的应用
答案2:
Spring Boot是Spring开源组织下的子项目,是Spring组件一站式解决方案,主要是简化了使用Spring的难度,简省了繁重的配置,提供了各种启动器,开发者能快速上手。
答案3:
Spring Boot是由Pivotal团队提供的全新框架,其设计目的是用来简化新Spring应用的初始搭建以及开发过程。该框架使用了特定的方式来进行配置,从而使开发人员不再需要定义样板化的配置。用我的话来理解,就是spring boot其实不是什么新的框架,它默认配置了很多框架的使用方式,就像maven整合了所有的jar包,spring boot整合了所有的框架(不知道这样比喻是否合适)。
2、Spring Boot的优点(为什么要用 Spring Boot?)
答案1:
使用spring boot有什么好处,其实就是简单、快速、方便!
平时如果我们需要搭建一个springweb项目的时候需要怎么做呢:
1)配置web.xml,加载spring和springmvc
2)配置数据库连接、配置spring事务
3)配置加载配置文件的读取,开启注解
4)配置日志文件
…
配置完成之后部署tomcat 调试
…
现在非常流行微服务,如果我这个项目仅仅只是需要发送一个邮件,如果我的项目仅仅是生产一个积分;我都需要这样折腾一遍!
答案2:
1 快速创建独立运行的spring项目与主流框架集成
2 使用嵌入式的servlet容器,应用无需打包成war包
3 starters自动依赖与版本控制
4 大量的自动配置,简化开发,也可修改默认值
5 准生产环境的运行应用监控
6 与云计算的天然集成
答案3:
独立运行、简化配置、自动配置、无代码生成和XML配置、应用监控、快速上手。。。
1独立运行
Spring Boot而且内嵌了各种servlet容器,Tomcat、Jetty等,现在不再需要打成war包部署到容器中,Spring Boot只要打成一个可执行的jar包就能独立运行,所有的依赖包都在一个jar包内。
2 简化配置
spring-boot-starter-web启动器自动依赖其他组件,简少了maven的配置。
+-org.springframework.boot:spring-boot-starter-web:jar:1.5.6.RELEASE:compile
+-org.springframework.boot:spring-boot-starter-tomcat:jar:1.5.6.RELEASE:compile
| +-org.apache.tomcat.embed:tomcat-embed-core:jar:8.5.16:compile
| +- org.apache.tomcat.embed:tomcat-embed-el:jar:8.5.16:compile
| -org.apache.tomcat.embed:tomcat-embed-websocket:jar:8.5.16:compile
+- org.hibernate:hibernate-validator:jar:5.3.5.Final:compile
| +- javax.validation:validation-api:jar:1.1.0.Final:compile
| +- org.jboss.logging:jboss-logging:jar:3.3.1.Final:compile
| - com.fasterxml:classmate:jar:1.3.3:compile
- org.springframework:spring-webmvc:jar:4.3.10.RELEASE:compile
3 自动配置
Spring Boot能根据当前类路径下的类、jar包来自动配置bean,如添加一个spring-boot-starter-web启动器就能拥有web的功能,无需其他配置。
4 无代码生成和XML配置
Spring Boot配置过程中无代码生成,也无需XML配置文件就能完成所有配置工作,这一切都是借助于条件注解完成的,这也是Spring4.x的核心功能之一。
5 应用监控
Spring Boot提供一系列端点可以监控服务及应用,做健康检测。
6 快速上手
3、Spring Boot的缺点
Spring Boot虽然上手很容易,但如果你不了解其核心技术及流程,所以一旦遇到问题就很棘手,而且现在的解决方案也不是很多,需要一个完善的过程。
4、springboot读取配置文件的方式
springboot默认读取配置文件为application.properties或者是application.yml
5、Spring Boot 的核心配置文件有哪几个?它们的区别是什么?
Spring Boot 的核心配置文件
application (.yml 或者 .properties)
bootstrap (.yml 或者 .properties)
bootstrap/ application 的区别
Spring Cloud 构建于 Spring Boot 之上,在 Spring Boot 中有两种上下文,一种是 bootstrap, 另外一种是 application, bootstrap 是应用程序的父上下文,也就是说bootstrap 加载优先于 applicaton。bootstrap 主要用于从额外的资源来加载配置信息,还可以在本地外部配置文件中解密属性。这两个上下文共用一个环境,它是任何Spring应用程序的外部属性的来源。bootstrap 里面的属性会优先加载,它们默认也不能被本地相同配置覆盖。
因此,对比application 配置文件,bootstrap 配置文件具有以下几个特性:
1 boostrap 由父 ApplicationContext 加载,比 applicaton 优先加载
2 boostrap 里面的属性不能被覆盖
bootstrap/ application 的应用场景
application 配置文件这个容易理解,主要用于 Spring Boot 项目的自动化配置。
bootstrap 配置文件有以下几个应用场景:
1 使用 Spring Cloud Config 配置中心时,这时需要在 bootstrap 配置文件中添加连接到配置中心的配置属性来加载外部配置中心的配置信息;
2 一些固定的不能被覆盖的属性;
3 一些加密/解密的场景;
6、Spring Boot 的配置文件有哪几种格式?它们有什么区别?
.properties和 .yml,它们的区别主要是书写格式不同。
1).properties
app.user.name = javastack
2).yml
app:
user:
name: javastack
另外,.yml 格式不支持 @PropertySource 注解导入配置。
7、Spring Boot 的核心注解是哪个?它主要由哪几个注解组成的?
启动类上面的注解是@SpringBootApplication,它也是 Spring Boot 的核心注解。
主要组合包含了以下 3个注解:
1 @SpringBootConfiguration:组合了 @Configuration 注解,实现配置文件的功能。
2 @EnableAutoConfiguration:打开自动配置的功能,也可以关闭某个自动配置的选项,
如关闭数据源自动配置功能:
@SpringBootApplication(exclude= { DataSourceAutoConfiguration.class })。
3 @ComponentScan:Spring组件扫描。
8、开启 Spring Boot 特性有哪几种方式?
1)继承spring-boot-starter-parent项目
2)导入spring-boot-dependencies项目依赖
具体请参考这篇文章《Spring Boot开启的2种方式》。
9、如何重新加载Spring Boot上的更改,而无需重新启动服务器?
这可以使用DEV工具来实现。通过这种依赖关系,您可以节省任何更改,嵌入式tomcat将重新启动。
Spring Boot有一个开发工具(DevTools)模块,它有助于提高开发人员的生产力。Java开发人员面临的一个主要挑战是将文件更改自动部署到服务器并自动重启服务器。
开发人员可以重新加载Spring Boot上的更改,而无需重新启动服务器。这将消除每次手动部署更改的需要。Spring Boot在发布它的第一个版本时没有这个功能。
这是开发人员最需要的功能。DevTools模块完全满足开发人员的需求。该模块将在生产环境中被禁用。它还提供H2数据库控制台以更好地测试应用程序。
org.springframework.boot
spring-boot-devtools
true
10、Spring Boot中的监视器是什么?
Spring boot actuator是spring启动框架中的重要功能之一。Spring boot监视器可帮助您访问生产环境中正在运行的应用程序的当前状态。
有几个指标必须在生产环境中进行检查和监控。即使一些外部应用程序可能正在使用这些服务来向相关人员触发警报消息。监视器模块公开了一组可直接作为HTTP URL访问的REST端点来检查状态。
11、什么是YAML?
YAML是一种人类可读的数据序列化语言。它通常用于配置文件。
与属性文件相比,如果我们想要在配置文件中添加复杂的属性,YAML文件就更加结构化,而且更少混淆。可以看出YAML具有分层配置数据。
12、springboot常用的starter有哪些
spring-boot-starter-web 嵌入tomcat和web开发需要servlet与jsp支持
spring-boot-starter-data-jpa 数据库支持
spring-boot-starter-data-redis redis 数据库支持
spring-boot-starter-data-solr solr支持
mybatis-spring-boot-starter 第三方的mybatis集成starter
13、springboot自动配置的原理
在spring程序main方法中添加@SpringBootApplication或者@EnableAutoConfiguration会自动去maven中读取每个starter中的spring.factories文件。该文件里配置了所有需要被创建spring容器中的bean。
14、springboot集成mybatis的过程
添加mybatis的startermaven依赖
org.mybatis.spring.boot
mybatis-spring-boot-starter
1.2.0
在mybatis的接口中 添加@Mapper注解
在application.yml配置数据源信息
15、Spring Boot 需要独立的容器运行吗?
16、运行 Spring Boot 有哪几种方式?
1)打包用命令或者放到容器中运行
2)用 Maven/ Gradle 插件运行
3)直接执行 main 方法运行
17、Spring Boot 自动配置原理是什么?
注解 @EnableAutoConfiguration,@Configuration, @ConditionalOnClass 就是自动配置的核心,首先它得是一个配置文件,其次根据类路径下是否有这个类去自动配置。
具体看这篇文章《Spring Boot自动配置原理、实战》。
18、Spring Boot 的目录结构是怎样的?
cn
+-javastack
+-MyApplication.java
|
+-customer
| +- Customer.java
| +- CustomerController.java
| +- CustomerService.java
| +- CustomerRepository.java
|
+-order
+- Order.java
+- OrderController.java
+- OrderService.java
+- OrderRepository.java
这个目录结构是主流及推荐的做法,而在主入口类上加上@SpringBootApplication 注解来开启 Spring Boot 的各项能力,如自动配置、组件扫描等。具体看这篇文章《Spring Boot 主类及目录结构介绍》。
19、你如何理解 Spring Boot 中的 Starters?
Starters是什么?
Starters可以理解为启动器,它包含了一系列可以集成到应用里面的依赖包,你可以一站式集成 Spring 及其他技术,而不需要到处找示例代码和依赖包。如你想使用 SpringJPA 访问数据库,只要加入 spring-boot-starter-data-jpa 启动器依赖就能使用了。
Starters包含了许多项目中需要用到的依赖,它们能快速持续的运行,都是一系列得到支持的管理传递性依赖。
Starters命名
Spring Boot官方的启动器都是以spring-boot-starter-命名的,代表了一个特定的应用类型。
第三方的启动器不能以spring-boot开头命名,它们都被Spring Boot官方保留。一般一个第三方的应该这样命名,像mybatis的mybatis-spring-boot-starter。
Starters分类
1. Spring Boot应用类启动器

2. Spring Boot生产启动器

3. Spring Boot技术类启动器
4. 其他第三方启动器
更多可以参考下面链接。
https://github.com/spring-projects/spring-boot/blob/master/spring-boot-starters/README.adoc
20、如何在 Spring Boot 启动的时候运行一些特定的代码?
Runner启动器
如果你想在Spring Boot启动的时候运行一些特定的代码,你可以实现接口 ApplicationRunner或者 CommandLineRunner,这两个接口实现方式一样,它们都只提供了一个run方法。
CommandLineRunner:启动获取命令行参数。
public interface CommandLineRunner {/*** Callback used to run the bean.* @param args incoming main method arguments* @throws Exception on error*/void run(String... args) throws Exception;}
ApplicationRunner:启动获取应用启动的时候参数。
public interface ApplicationRunner {/*** Callback used to run the bean.* @param args incoming application arguments* @throws Exception on error*/void run(ApplicationArguments args) throws Exception;}
使用方式
import org.springframework.boot.*import org.springframework.stereotype.*@Componentpublic class MyBean implements CommandLineRunner {public voidrun(String... args) {//Do something...}}
或者这样
@Beanpublic CommandLineRunner init() {return(String... strings) -> {};}
启动顺序
如果启动的时候有多个ApplicationRunner和CommandLineRunner,想控制它们的启动顺序,可以
实现org.springframework.core.Ordered接口,或者
使用 org.springframework.core.annotation.Order注解。
21、Spring Boot 有哪几种读取配置的方式?
读取application文件
在application.yml或者properties文件中添加:
info.address=USA
info.company=Spring
info.degree=high
@Value注解读取方式
importorg.springframework.beans.factory.annotation.Value;import org.springframework.stereotype.Component;@Componentpublic class InfoConfig1 {@Value("${info.address}")private String address;@Value("${info.company}")private String company;@Value("${info.degree}")private String degree;public String getAddress() {return address;}public void setAddress(String address) {this.address = address;}public String getCompany() {return company;}public void setCompany(String company) {this.company = company;}public String getDegree() {return degree;}public void setDegree(String degree) {this.degree = degree;}}
@ConfigurationProperties注解读取方式
@Component@ConfigurationProperties(prefix = "info")public class InfoConfig2 {private String address;private String company;private String degree;public String getAddress() {return address;}public void setAddress(String address) {this.address = address;}public String getCompany() {return company;}public void setCompany(String company) {this.company = company;}public String getDegree() {return degree;}public void setDegree(String degree) {this.degree = degree;}}
读取指定文件
资源目录下建立config/db-config.properties:
db.username=root
db.password=123456
@PropertySource+@Value注解读取方式
@Component@PropertySource(value = { "config/db-config.properties" })public class DBConfig1 {@Value("${db.username}")private String username;@Value("${db.password}")private String password;public String getUsername() {return username;}public void setUsername(String username) {this.username = username;}public String getPassword() {return password;}public void setPassword(String password) {this.password = password;}}
@PropertySource+@ConfigurationProperties注解读取方式
@Component@ConfigurationProperties(prefix = "db")@PropertySource(value = { "config/db-config.properties" })public class DBConfig2 {private String username;private String password;public String getUsername() {return username;}public void setUsername(String username) {this.username = username;}public String getPassword() {return password;}public void setPassword(String password) {this.password = password;}}
Environment读取方式
以上所有加载出来的配置都可以通过Environment注入获取到。
@Autowiredprivate Environment env;// 获取参数String getProperty(String key);
总结
Spring Boot 可以通过 ,
@PropertySource,@Value,@Environment,@ConfigurationProperties 来绑定变量。
22、Spring Boot 支持哪些日志框架?推荐和默认的日志框架是哪个?
Spring Boot 支持 Java Util Logging, Log4j2, Lockback 作为日志框架,如果你使用 Starters 启动器,Spring Boot 将使用 Logback 作为默认日志框架,具体请看这篇文章《Spring Boot日志集成》。
23、SpringBoot 实现热部署有哪几种方式?
主要有两种方式:
1 Spring Loaded
2 Spring-boot-devtools
Spring-boot-devtools使用方式可以参考这篇文章《Spring Boot实现热部署》。
24、你如何理解 Spring Boot 配置加载顺序?
在 SpringBoot 里面,可以使用以下几种方式来加载配置。
1)properties文件;
2)YAML文件;
3)系统环境变量;
4)命令行参数;
等等……
具体请看这篇文章《SpringBoot 配置加载顺序详解》。
25、Spring Boot 如何定义多套不同环境配置?
提供多套配置文件,如:
applcation.properties
application-dev.properties
application-test.properties
application-prod.properties
运行时指定具体的配置文件,具体请看这篇文章《Spring Boot Profile 不同环境配置》。
26、Spring Boot 可以兼容老 Spring 项目吗,如何做?
可以兼容,使用 @ImportResource 注解导入老 Spring 项目配置文件。
27、如何集成Spring Boot和ActiveMQ?
对于集成Spring Boot和ActiveMQ,我们使用spring-boot-starter-activemq依赖关系。它只需要很少的配置,并且不需要样板代码。
28、保护 Spring Boot 应用有哪些方法?
在生产中使用HTTPS
使用Snyk检查你的依赖关系
升级到最新版本
启用CSRF保护
使用内容安全策略防止XSS攻击
…
更多请看这篇文章《10 种保护Spring Boot 应用的绝佳方法》。
29、Spring Boot 2.X 有什么新特性?与 1.X 有什么区别?
配置变更
JDK 版本升级
第三方类库升级
响应式 Spring 编程支持
HTTP/2 支持
配置属性绑定
更多改进与加强…
具体请看这篇文章《Spring Boot 2.x 新特性总结及迁移指南》。
SpringBoot面试总结二
1、Spring Boot是什么
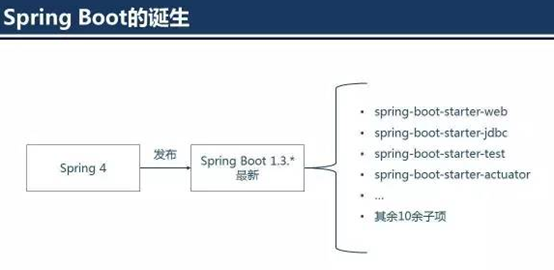
SpringBoot是伴随着Spring4.0诞生的;
从字面理解,Boot是引导的意思,因此SpringBoot帮助开发者快速搭建Spring框架;
SpringBoot帮助开发者快速启动一个Web容器;
SpringBoot继承了原有Spring框架的优秀基因;
SpringBoot简化了使用Spring的过程。
2、Spring Boot解决了哪些问题
1) Spring Boot使编码变简单

2) Spring Boot使配置变简单
Spring由于其繁琐的配置,一度被人认为“配置地狱”,各种XML、Annotation配置,让人眼花缭乱,而且如果出错了也很难找出原因。
Spring Boot更多的是采用Java Config的方式,对Spring进行配置。
3) Spring Boot使部署变简单

4) Spring Boot使监控变简单

3、Spring Boot的不足
可以看到,采用了spring-boot-start-actuator之后,直接以REST的方式,获取进程的运行期性能参数。
当然这些metrics有些是有敏感数据的,spring-boot-start-actuator为此提供了一些BasicAuthentication认证的方案,这些方案在实际应用过程中也是不足的。
4、Spring Boot在平台中的定位,相关技术如何融合
Spring Boot作为一个微框架,离微服务的实现还是有距离的。
没有提供相应的服务发现和注册的配套功能,自身的acturator所提供的监控功能,也需要与现有的监控对接。没有配套的安全管控方案,对于REST的落地,还需要自行结合实际进行URI的规范化工作。
SpringBoot相关技术
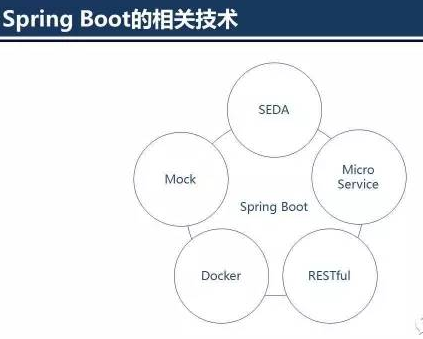
SpringBoot与SEDA +MicroService +RESTful
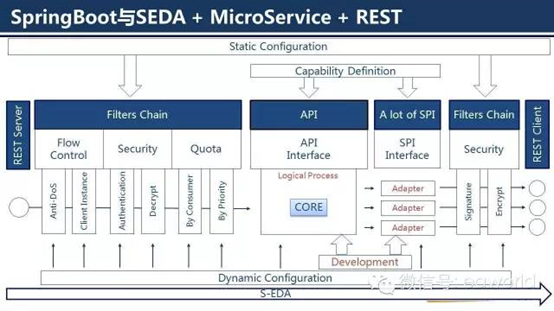
上图比较复杂,整体是采用SEDA,也就是Stage-EDA。可以看到,整体是以处理顺序进行展示的,响应过程类似。在处理过程中,主要会有前置过滤,核心功能处理,后置过滤几大部分。
图中的过滤器都是可插拔式的,并且可以根据实际场景进行扩展开发。每个过滤器都是Stage,比如ClientInstance合法性检查、调用鉴权、解密、限流等等。
一个请求Stage与Stage的转换,实现上是切换不同的线程池,并以EDA的方式驱动。
对于业务逻辑的开发者而言,只需要关心CORE部分的业务逻辑实现,其他的非功能都由框架进行统一实现。
SpringBoot与Mock
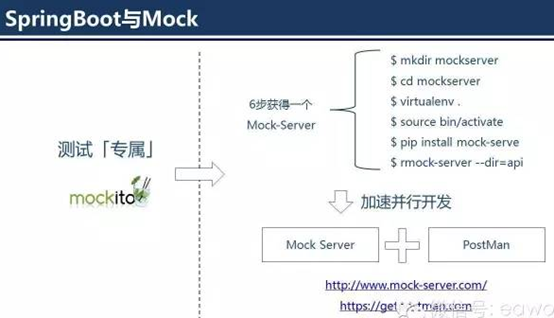
Mock不应当再是测试的专有名词了,当然对于测试这个角色而言,mockito这样的工具,依然可以为他们提升不少效率。
SpringBoot为创建REST服务提供了简便的途径,相比之下,采用阿里的dubbo在做多团队、多进程联调时,mock的难度就陡增。
Mock是解耦并行开发的利器,在理性的情况下,软件从开发期Mock联调,到开发与开发的真实联调,只需要切换一个依赖的域名即可,比如:
mockURI:http://mock.service.net/v1/function?param1=value1
devURI:http://dev.service.net/v1/function?param1=value1
而上述的域名切换,只需要在开发期定义好一个配置项,在做环境切换的时候自动注入即可,省时、省心、省力。
SpringBoot与Docker

如上图和docker的集成可以有AB两种方案:
• A方案的核心是,把docker作为操作系统环境的交付基线,也就是不同的fat jar 使用相同的操作系统版本、相同的JVM环境。但对于docker image来说都是一样的。
• B方案的核心是,不同的fat jar,独立的编译为docker image,在启动时直接启动带有特定版本的image。
A相比与B方案的特点是对于dockerregistry(也就是docker的镜像仓库)的依赖性较低,对于前期编译过程的要求也较低。
采用了SpringBoot之后,技术管理应该如何进行?
正因为SpringBoot是与Spring一脉相承的,所以对于广大的Java开发者而言,对于Spring的学习成本几乎为零。
在实践SpringBoot时学习重点,或者说思维方式改变的重点在于:
1)对于REST的理解,这一点尤为重要,需要从设计、开发多个角色达成共识,很多时候都是对于HTTP 1.1协议以及REST的精髓不理解,导致REST被「盲用」而产生一些不好的效果。
2)对于YAML的理解和对于JavaConfig的理解,这两点相对较为简单,本质上是简化了xml文件,并提供等价的配置表述能力。
1. 丰富的工具链为SpringBoot的推广带来了利好。
2. SpringBoot的工具链主要来自于两个方面:
1)原有Spring积累的工具链;
2)SpringMVC或者其他REST框架使用HTTP协议,使得HTTP丰富的工具成为SpringBoot天然的资源。
SpringBoot自身对于前面提到的配置文件:“application.yml”提供了多个「Profile」,可以便于开发者描述不同环境的配置,这些配置例如数据库的连接地址、用户名和密码。
但是对于企业用户而言,把不同环境的配置,写到同一个配置文件中,是极其不安全的,是一个非常危险的动作。
有一个经常被提及的例子是,随着开源的进行,很多互联网公司,都由于把相关的代码提交到github之类的开源代码社区,并且没有对代码进行严格的配置审查,导致一些”password”被公开。有些不良用心的人,就利用搜索工具,专门去挖掘这些关键字,进而导致数据库被「拖库」。
所以对于企业用户,更多的应该是采用集中式的配置管理系统,将不同环境的配置严格区分地存放。
虽然SpringBoot的actuator自身提供了基于「用户名+口令」的最简单的认证方式,但它保护的是对框架自身运行期的性能指标敏感数据的最基本的保护。这种保护在实际应用过程中,「用户名+口令」的管理是缺乏的,「用户名+口令」的安全配置过程是缺失的。
SpringBoot也不提供对于我们自己开发的功能的任何防护功能。
一般来讲,一个安全的信道(信息传输的通道),需要通信双方在进行正式的信息传输之前对对方进行身份认证,服务提供方还需要在此基础之上,对请求方的请求进行权限的校验,以确保业务安全。这些内容也需要基于SpringBoot进行外围的安全扩展,例如采用前面提到的S-EDA进行进程级别的安全管控。这些还需要配套的安全服务提供支持。
一般来说,只要企业与互联网对接,那么随便一个面向消费者的「市场活动」,就有可能为企业带来井喷的流量。
传统企业内,更多的系统是管理信息类的支撑系统,这类系统在设计时的主要用户是企业内部员工以及有限的外部供应商。这类系统存在于企业内部的时间一直很长,功能耦合也很多,在功能解耦前,是非常不适合的,或者说绝对不可以直接为互联网的用户进行服务的。
SpringBoot自身并没有提供这样的流控措施,所以需要结合前面提到的S-EDA进行流量的控制,并结合下层的水平扩展能力(例如,Kubernets)进行流量负载合理的动态扩容。
另外,在长业务流程的设计上,也尽可能地采用异步的方式,比如接口调用返回的是一个「受理号」,而不是业务的处理结果,避免井喷业务到来时,同步调用所带来的阻塞导致系统迅速崩溃,这些也都是SpringBoot自身并不解决的问题。
5、总结

《四》、Jvm
JVM面试必备知识点学习
一)名词解释:
一,常用:
Garbage Collection(GC) 垃圾收集
Heap 堆
Stack 栈
Stack Frame 栈帧
VM Stack 虚拟机栈
StackOverflowError xx异常
OutOfMemoryError 内存不足异常
二,Java内存区域:(运行时数据区域)
Program Counter Register 程序计数器
Java Virtual Machine Stacks Java虚拟机栈
Native Method Stack本地方法栈
Java Heap Java堆
Method Area 方法区
Runtime Constant Pool 运行时常量池 (是方法区的一部分)
Direct Memory 直接内存
(并不是虚拟机运行时数据区域的一部分,也不是jvm规范中定义的内存区域,,只是经常使用这部分内存,且也可能导致OutOfMemoryError)
三,对象已死吗?
Reference Counting 引用计数算法
Reachability Analysis可达性分析算法
Strong Reference 强引用
Weak Reference 弱引用
Phantom Reference 虚引用
四,垃圾收集算法:(GC算法)
Mark-Sweep 标记-清除算法
Copying 复制算法
Mark-Compact 标记-整理算法
Generational Collection分代收集算法
五,垃圾收集器:(Java中垃圾回收器的类型)
Serial收集器
ParNew收集器
Parallel Scavenge收集器
Serial Old收集器
Parallel Old收集器
CMS收集器
G1收集器
六,JDK命令行工具:
jps:虚拟机进程状况工具(JVM Process Status Tool)
jstat:虚拟机统计信息监视工具(JVM Monitoring Tool)
jinfo:Java配置信息工具(Configuration Info for Java)
jmap:Java内存映像工具(Memory Map for Java)
jhat:虚拟机堆转储快照分析工具(JVM Heap AnalysisTool)
jstack:Java堆栈跟踪工具(Stack Trace for Java)
HSDIS:JIT生成代码反汇编
七,堆内存分为三个部分:
Permanent Generation永久代
Young Generation 新生代
Tenured / Old Generation –>老年代
八,其他:
Memory Leak 内存泄漏
Bump the Pointer 指针碰撞
Free List 空闲列表
Header 对象头
Instance Data 实例数据
Padding 对齐填充
Minor GC 新生代GC
Major GC / Full GC 老年代GC
二)JVM内存模型
一 Java内存区域:(运行时数据区域)
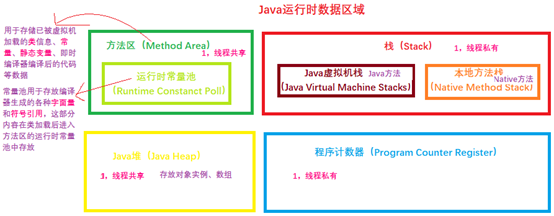
Program Counter Register 程序计数器
Java Virtual Machine Stacks Java虚拟机栈
Native Method Stack 本地方法栈
Java Heap Java堆
Method Area 方法区
Runtime Constant Pool 运行时常量池 (是方法区的一部分)
Direct Memory 直接内存(并不是虚拟机运行时数据区域的一部分,也不是jvm规范中定义的内存区域,,只是经常使用这部分内存,且也可能导致OutOfMemoryError)
1.JVM内存分哪几个区,每个区的作用是什么?(JVM内存模型(jvm内存分布))
Java虚拟机主要分为以下一个区:
方法区:
- 有时候也成为永久代,在该区内很少发生垃圾回收,但是并不代表不发生GC,在这里进行的GC主要是对方法区里的常量池和对类型的卸载
2. 方法区主要用来存储已被虚拟机加载的类的信息、常量、静态变量和即时编译器编译后的代码等数据。
3. 该区域是被线程共享的。
4. 方法区里有一个运行时常量池,用于存放静态编译产生的字面量和符号引用。该常量池具有动态性,也就是说常量并不一定是编译时确定,运行时生成的常量也会存在这个常量池中。虚拟机栈:
虚拟机栈也就是我们平常所称的栈内存,它为java方法服务,每个方法在执行的时候都会创建一个栈帧,用于存储局部变量表、操作数栈、动态链接和方法出口等信息。
2. 虚拟机栈是线程私有的,它的生命周期与线程相同。
3. 局部变量表里存储的是基本数据类型、returnAddress类型(指向一条字节码指令的地址)和对象引用,这个对象引用有可能是指向对象起始地址的一个指针,也有可能是代表对象的句柄或者与对象相关联的位置。局部变量所需的内存空间在编译器间确定
4.操作数栈的作用主要用来存储运算结果以及运算的操作数,它不同于局部变量表通过索引来访问,而是压栈和出栈的方式
5.每个栈帧都包含一个指向运行时常量池中该栈帧所属方法的引用,持有这个引用是为了支持方法调用过程中的动态连接.动态链接就是将常量池中的符号引用在运行期转化为直接引用。本地方法栈
本地方法栈和虚拟机栈类似,只不过本地方法栈为Native方法服务。
堆
java堆是所有线程所共享的一块内存,在虚拟机启动时创建,几乎所有的对象实例都在这里创建,因此该区域经常发生垃圾回收操作。
程序计数器
内存空间小,字节码解释器工作时通过改变这个计数值可以选取下一条需要执行的字节码指令,分支、循环、跳转、异常处理和线程恢复等功能都需要依赖这个计数器完成。该内存区域是唯一一个java虚拟机规范没有规定任何OOM情况的区域。
2.简述java内存分配与回收策率以及Minor GC和Major GC
1 对象优先在堆的Eden区分配。
2 大对象直接进入老年代.
3 长期存活的对象将直接进入老年代.
当Eden区没有足够的空间进行分配时,虚拟机会执行一次MinorGC.Minor Gc通常发生在新生代的Eden区,在这个区的对象生存期短,往往发生Gc的频率较高,回收速度比较快;Full Gc/Major GC 发生在老年代,一般情况下,触发老年代GC的时候不会触发Minor GC,但是通过配置,可以在Full GC之前进行一次Minor GC这样可以加快老年代的回收速度。3.java内存模型
java内存模型(JMM)是线程间通信的控制机制.JMM定义了主内存和线程之间抽象关系。线程之间的共享变量存储在主内存(mainmemory)中,每个线程都有一个私有的本地内存(localmemory),本地内存中存储了该线程以读/写共享变量的副本。本地内存是JMM的一个抽象概念,并不真实存在。它涵盖了缓存,写缓冲区,寄存器以及其他的硬件和编译器化。Java内存模型的抽象示意图如下:
从上图来看,线程A与线程B之间如要通信的话,必须要经历下面2个步骤:
1. 首先,线程A把本地内存A中更新过的共享变量刷新到主内存中去。
2. 然后,线程B到主内存中去读取线程A之前已更新过的共享变量。
写的很好:http://www.infoq.com/cn/articles/java-memory-model-1三)GC(垃圾收集)
1 Java GC机制(重要程度:★★★★★) (对Java GC了解多少)
主要从三个方面回答:
1 GC是针对什么对象进行回收(可达性分析法),
2 什么时候开始GC(当新生代满了会进行MinorGC,升到老年代的对象大于老年代剩余空间时会进行Major GC),
3 GC做什么(新生代采用复制算法,老年代采用标记-清除或标记-整理算法),
感觉回答这些就差不多了,也可以补充一下可以调优的参数(-XX:newRatio,-Xms,-Xmx等等)。详细的可以看我另一篇博客(Java中的垃圾回收机制
https://yemengying.com/2016/05/13/jvm-GC/)。另一篇文章总结
· 为了分代垃圾回收,Java堆内存分为3代:新生代,老年代和永久代。
· 新的对象实例会优先分配在新生代,在经历几次Minor GC后(默认15次),还存活的会被移至老年代(某些大对象会直接在老年代分配)。
· 永久代是否执行GC,取决于采用的JVM。
· MinorGC发生在新生代,当Eden区没有足够空间时,会发起一次Minor GC,将Eden区中的存活对象移至Survivor区。Major GC发生在老年代,当升到老年代的对象大于老年代剩余空间时会发生MajorGC。
· 发生MajorGC时用户线程会暂停,会降低系统性能和吞吐量。
· JVM的参数-Xmx和-Xms用来设置Java堆内存的初始大小和最大值。依据个人经验这个值的比例最好是1:1或者1:1.5。比如,你可以将-Xmx和-Xms都设为1GB,或者-Xmx和-Xms设为1.2GB和1.8GB。
· Java中不能手动触发GC,但可以用不同的引用类来辅助垃圾回收器工作(比如:弱引用或软引用)。2、你知道哪些或者你们线上使⽤什么GC策略?它有什么优势,适⽤于什么场景?
3、GC是什么?为什么要有GC?
GC是垃圾收集的意思(Gabage Collection),内存处理是编程人员容易出现问题的地方,忘记或者错误的内存回收会导致程序或系统的不稳定甚至崩溃,Java提供的GC功能可以自动监测对象是否超过作用域从而达到自动回收内存的目的,Java语言没有提供释放已分配内存的显示操作方法。
4、做GC时,⼀个对象在内存各个Space中被移动的顺序是什么?
标记清除法,复制算法,标记整理、分代算法。
新生代一般采用复制算法 GC,老年代使用标记整理算法。
垃圾收集器:串行新生代收集器、串行老生代收集器、并行新生代收集器、并行老年代收集器。
CMS(Current Mark Sweep)收集器是一种以获取最短回收停顿时间为目标的收集器,它是一种并发收集器,采用的是Mark-Sweep算法。
详见 Java GC机制。5、堆内存设置的参数是什么?
1 -Xmx 设置堆的最大空间大小
2 -Xms 设置堆的最小空间大小6、Perm Space中保存什么数据?会引起OutOfMemory吗?
加载class文件。
会引起,出现异常可以设置 -XX:PermSize 的大小。JDK 1.8后,字符串常量不存放在永久带,而是在堆内存中,JDK8以后没有永久代概念,而是用元空间替代,元空间不存在虚拟机中,二是使用本地内存。
详细查看Java8内存模型—永久代(PermGen)和元空间(Metaspace)7、你有没有遇到过OutOfMemory问题?你是怎么来处理这个问题的?处理过程中有哪些收获?
permgen space、heap space 错误。
常见的原因
1 内存加载的数据量太大:一次性从数据库取太多数据;
2 集合类中有对对象的引用,使用后未清空,GC不能进行回收;
3 代码中存在循环产生过多的重复对象;
4 启动参数堆内存值小。
详见 Java 内存溢出(java.lang.OutOfMemoryError)的常见情况和处理方式总结。8、JDK 1.8之后Perm Space有哪些变动? MetaSpace⼤⼩默认是⽆限的么? 还是你们会通过什么⽅式来指定⼤⼩?
JDK 1.8后用元空间替代了 Perm Space;字符串常量存放到堆内存中。
MetaSpace大小默认没有限制,一般根据系统内存的大小。JVM会动态改变此值。
1 -XX:MetaspaceSize:分配给类元数据空间(以字节计)的初始大小(Oracle逻辑存储上的初始高水位,the initial high-water-mark)。此值为估计值,MetaspaceSize的值设置的过大会延长垃圾回收时间。垃圾回收过后,引起下一次垃圾回收的类元数据空间的大小可能会变大。
2 -XX:MaxMetaspaceSize:分配给类元数据空间的最大值,超过此值就会触发Full GC,此值默认没有限制,但应取决于系统内存的大小。JVM会动态地改变此值。9、jstack 是⼲什么的? jstat 呢?如果线上程序周期性地出现卡顿,你怀疑可 能是 GC 导致的,你会怎么来排查这个问题?线程⽇志⼀般你会看其中的什么部分?
jstack 用来查询 Java 进程的堆栈信息。
jvisualvm 监控内存泄露,跟踪垃圾回收、执行时内存、cpu分析、线程分析。
详见Java jvisualvm简要说明,可参考 线上FullGC频繁的排查。10、StackOverflow异常有没有遇到过?⼀般你猜测会在什么情况下被触发?如何指定⼀个线程的堆栈⼤⼩?⼀般你们写多少?
栈内存溢出,一般由栈内存的局部变量过爆了,导致内存溢出。出现在递归方法,参数个数过多,递归过深,递归没有出口。
11. 既然有GC机制,为什么还会有内存泄露的情况 (2017-11-16-wl)
理论上 Java 因为有垃圾回收机制(GC)不会存在内存泄露问题(这也是 Java 被广泛使用于服务器端编程的一个重要原因)。然而在实际开发中,可能会存在无用但可达的对象,这些对象不能被 GC 回收,因此也会导致内存泄露的发生。
例如 hibernate 的 Session(一级缓存)中的对象属于持久态,垃圾回收器是不会回收这些对象的,然而这些对象中可能存在无用的垃圾对象,如果不及时关闭(close)或清空(flush)一级缓存就可能导致内存泄露。
下面例子中的代码也会导致内存泄露。
1. import java.util.Arrays;
2. import java.util.EmptyStackException;
3. public class MyStack{
4.private T[] elements;
5.private int size = 0;
6.private static final int INIT_CAPACITY = 16;
7.public MyStack() {
8.elements = (T[]) new Object[INIT_CAPACITY];
9. }
10.public void push(T elem) {
11.ensureCapacity();
12.elements[size++] = elem;
13.}
14.public T pop() {
15.if(size == 0)throw new EmptyStackException();
16.return elements[—size];
17. }
18.private void ensureCapacity() {
19.if(elements.length == size) {
20.elements = Arrays.copyOf(elements, 2 * size + 1);
21.}
22. }
23. }
上面的代码实现了一个栈(先进后出(FILO))结构,乍看之下似乎没有什么明显的问题,它甚至可以通过你编写的各种单元测试。然而其中的 pop 方法却存在内存泄露的问题,当我们用 pop 方法弹出栈中的对象时,该对象不会被当作垃圾回收,即使使用栈的程序不再引用这些对象,因为栈内部维护着对这些对象的过期引用(obsolete reference)。在支持垃圾回收的语言中,内存泄露是很隐蔽的,这种内存泄露其实就是无意识的对象保持。如果一个对象引用被无意识的保留起来了,那么垃圾回收器不会处理这个对象,也不会处理该对象引用的其他对象,即使这样的对象只有少数几个,也可能会导致很多的对象被排除在垃圾回收之外,从而对性能造成重大影响,极端情况下会引发 Disk Paging (物理内存与硬盘的虚拟内存交换数据),甚至造成OutOfMemoryError。12.如和判断一个对象是否存活?(或者GC对象的判定方法)
判断一个对象是否存活有两种方法:
1. 引用计数法
所谓引用计数法就是给每一个对象设置一个引用计数器,每当有一个地方引用这个对象时,就将计数器加一,引用失效时,计数器就减一。当一个对象的引用计数器为零时,说明此对象没有被引用,也就是“死对象”,将会被垃圾回收.
引用计数法有一个缺陷就是无法解决循环引用问题,也就是说当对象A引用对象B,对象B又引用者对象A,那么此时A,B对象的引用计数器都不为零,也就造成无法完成垃圾回收,所以主流的虚拟机都没有采用这种算法。
2.可达性算法(引用链法)
该算法的思想是:从一个被称为GC Roots的对象开始向下搜索,如果一个对象到GCRoots没有任何引用链相连时,则说明此对象不可用。
在java中可以作为GC Roots的对象有以下几种:
·虚拟机栈中引用的对象
·方法区类静态属性引用的对象
·方法区常量池引用的对象
·本地方法栈JNI引用的对象
虽然这些算法可以判定一个对象是否能被回收,但是当满足上述条件时,一个对象比不一定会被回收。当一个对象不可达GCRoot时,这个对象并 不会立马被回收,而是出于一个死缓的阶段,若要被真正的回收需要经历两次标记
如果对象在可达性分析中没有与GC Root的引用链,那么此时就会被第一次标记并且进行一次筛选,筛选的条件是是否有必要执行finalize()方法。当对象没有覆盖finalize()方法或者已被虚拟机调用过,那么就认为是没必要的。
如果该对象有必要执行finalize()方法,那么这个对象将会放在一个称为F-Queue的对队列中,虚拟机会触发一个Finalize()线程去执行,此线程是低优先级的,并且虚拟机不会承诺一直等待它运行完,这是因为如果finalize()执行缓慢或者发生了死锁,那么就会造成F-Queue队列一直等待,造成了内存回收系统的崩溃。GC对处于F-Queue中的对象进行第二次被标记,这时,该对象将被移除”即将回收”集合,等待回收。13.简述java垃圾回收机制?
在java中,程序员是不需要显示的去释放一个对象的内存的,而是由虚拟机自行执行。在JVM中,有一个垃圾回收线程,它是低优先级的,在正常情况下是不会执行的,只有在虚拟机空闲或者当前堆内存不足时,才会触发执行,扫面那些没有被任何引用的对象,并将它们添加到要回收的集合中,进行回收。
14.java中垃圾收集的方法有哪些?
标记-清除:
这是垃圾收集算法中最基础的,根据名字就可以知道,它的思想就是标记哪些要被回收的对象,然后统一回收。这种方法很简单,但是会有两个主要问题:1.效率不高,标记和清除的效率都很低;2.会产生大量不连续的内存碎片,导致以后程序在分配较大的对象时,由于没有充足的连续内存而提前触发一次GC动作。复制算法:
为了解决效率问题,复制算法将可用内存按容量划分为相等的两部分,然后每次只使用其中的一块,当一块内存用完时,就将还存活的对象复制到第二块内存上,然后一次性清楚完第一块内存,再将第二块上的对象复制到第一块。但是这种方式,内存的代价太高,每次基本上都要浪费一般的内存。
于是将该算法进行了改进,内存区域不再是按照1:1去划分,而是将内存划分为8:1:1三部分,较大那份内存交Eden区,其余是两块较小的内存区叫Survior区。每次都会优先使用Eden区,若Eden区满,就将对象复制到第二块内存区上,然后清除Eden区,如果此时存活的对象太多,以至于Survivor不够时,会将这些对象通过分配担保机制复制到老年代中。(java堆又分为新生代和老年代)标记-整理
该算法主要是为了解决标记-清除,产生大量内存碎片的问题;当对象存活率较高时,也解决了复制算法的效率问题。它的不同之处就是在清除对象的时候现将可回收对象移动到一端,然后清除掉端边界以外的对象,这样就不会产生内存碎片了。分代收集
现在的虚拟机垃圾收集大多采用这种方式,它根据对象的生存周期,将堆分为新生代和老年代。在新生代中,由于对象生存期短,每次回收都会有大量对象死去,那么这时就采用复制算法。老年代里的对象存活率较高,没有额外的空间进行分配担保,所以可以使用标记-整理 或者 标记-清除。
15、垃圾回收的优点和原理。并考虑2种回收机制。
Java语言中一个显著的特点就是引入了垃圾回收机制,使c++程序员最头疼的内存管理的问题迎刃而解,它使得Java程序员在编写程序的时候不再需要考虑内存管理。由于有个垃圾回收机制,Java中的对象不再有”作用域”的概念,只有对象的引用才有”作用域”。垃圾回收可以有效的防止内存泄露,有效的使用可以使用的内存。垃圾回收器通常是作为一个单独的低级别的线程运行,不可预知的情况下对内存堆中已经死亡的或者长时间没有使用的对象进行清楚和回收,程序员不能实时的调用垃圾回收器对某个对象或所有对象进行垃圾回收。回收机制有分代复制垃圾回收和标记垃圾回收,增量垃圾回收。
16、垃圾回收器的基本原理是什么?垃圾回收器可以马上回收内存吗?有什么办法主动通知虚拟机进行垃圾回收?
对于GC来说,当程序员创建对象时,GC就开始监控这个对象的地址、大小以及使用情况。通常,GC采用有向图的方式记录和管理堆(heap)中的所有对象。通过这种方式确定哪些对象是”可达的”,哪些对象是”不可达的”。当GC确定一些对象为”不可达”时,GC就有责任回收这些内存空间。程序员可以手动执行System.gc(),通知GC运行,但是Java语言规范并不保证GC一定会执行。
17. Java中为什么会有GC机制呢?(2017-11-16-wl)
Java中为什么会有GC机制呢?
• 安全性考虑;— forsecurity.
• 减少内存泄露;— erasememory leak in some degree.
• 减少程序员工作量。—Programmers don’t worry about memory releasing.
18. 对于Java的GC哪些内存需要回收(2017-11-16-wl)
内存运行时 JVM 会有一个运行时数据区来管理内存。它主要包括 5 大部分:程序计数器(Program Counter Register)、虚拟机栈(VM Stack)、本地方法栈(Native Method Stack)、方法区(Method Area)、堆(Heap). 而其中程序计数器、虚拟机栈、本地方法栈是每个线程私有的内存空间,随线程而生,随线程而亡。例如栈中每一个栈帧中分配多少内存基本上在类结构确定是哪个时就已知了,因此这 3 个区域的内存分配和回收都是确定的,无需考虑内存回收的问题。
但方法区和堆就不同了,一个接口的多个实现类需要的内存可能不一样,我们只有在程序运行期间才会知道会创建哪些对象,这部分内存的分配和回收都是动态的,GC主要关注的是这部分内存。
总而言之,GC 主要进行回收的内存是JVM中的方法区和堆;
19 Java的GC什么时候回收垃圾(2017-11-16-wl)
在面试中经常会碰到这样一个问题(事实上笔者也碰到过):如何判断一个对象已经死去?
很容易想到的一个答案是:对一个对象添加引用计数器。每当有地方引用它时,计数器值加1;当引用失效时,计数器值减 1.而当计数器的值为 0 时这个对象就不会再被使用,判断为已死。是不是简单又直观。然而,很遗憾。这种做法是错误的!为什么是错的呢?事实上,用引用计数法确实在大部分情况下是一个不错的解决方案,而在实际的应用中也有不少案例,但它却无法解决对象之间的循环引用问题。比如对象 A中有一个字段指向了对象B,而对象B中也有一个字段指向了对象A,而事实上他们俩都不再使用,但计数器的值永远都不可能为0,也就不会被回收,然后就发生了内存泄露。
所以,正确的做法应该是怎样呢?
在Java,C#等语言中,比较主流的判定一个对象已死的方法是:可达性分析(Reachability Analysis). 所有生成的对象都是一个称为”GCRoots”的根的子树。从 GC Roots 开始向下搜索,搜索所经过的路径称为引用链(Reference Chain),当一个对象到GC Roots没有任何引用链可以到达时,就称这个对象是不可达的(不可引用的),也就是可以被GC 回收了。
无论是引用计数器还是可达性分析,判定对象是否存活都与引用有关!那么,如何定义对象的引用呢?
我们希望给出这样一类描述:当内存空间还够时,能够保存在内存中;如果进行了垃圾回收之后内存空间仍旧非常紧张,则可以抛弃这些对象。所以根据不同的需求,给出如下四种引用,根据引用类型的不同,GC回收时也会有不同的操作:
1)强引用(StrongReference):Object obj = new Object();只要强引用还存在,GC永远不会回收掉被引用的对象。
2)软引用(SoftReference):描述一些还有用但非必需的对象。在系统将会发生内存溢出之前,会把这些对象列入回收范围进行二次回收(即系统将会发生内存溢出了,才会对他们进行回收。)
3)弱引用(WeakReference):程度比软引用还要弱一些。这些对象只能生存到下次GC之前。当GC 工作时,无论内存是否足够都会将其回收(即只要进行GC,就会对他们进行回收。)
虚引用(Phantom Reference):一个对象是否存在虚引用,完全不会对其生存时间构成影响。
关于方法区中需要回收的是一些废弃的常量和无用的类。
1.废弃的常量的回收。这里看引用计数就可以了。没有对象引用该常量就可以放心的回收了。
2.无用的类的回收。什么是无用的类呢?
A.该类所有的实例都已经被回收。也就是Java堆中不存在该类的任何实例;
B.加载该类的ClassLoader已经被回收;
C.该类对应的java.lang.Class对象没有任何地方被引用,无法在任何地方通过反射访问该类的方法。
总而言之:
对于堆中的对象,主要用可达性分析判断一个对象是否还存在引用,如果该对象没有任何引用就应该被回收。而根据我们实际对引用的不同需求,又分成了4中引用,每种引用的回收机制也是不同的。
对于方法区中的常量和类,当一个常量没有任何对象引用它,它就可以被回收了。而对于类,如果可以判定它为无用类,就可以被回收了。
20 在Java中,对象什么时候可以被垃圾回收?
当对象对当前使用这个对象的应用程序变得不可触及的时候,这个对象就可以被回收了。
21 JVM的永久代中会发生垃圾回收么?
垃圾回收不会发生在永久代,如果永久代满了或者是超过了临界值,会触发完全垃圾回收(FullGC)。如果你仔细查看垃圾收集器的输出信息,就会发现永久代也是被回收的。这就是为什么正确的永久代大小对避免FullGC是非常重要的原因。请参考下Java8:从永久代到元数据区
(注:Java8中已经移除了永久代,新加了一个叫做元数据区的native内存区)
Java中
四)类加载机制
1.java类加载过程?(简单说一下类加载过程,里面执行了哪些操作?)
java类加载需要经历一下7个过程:
加载
加载时类加载的第一个过程,在这个阶段,将完成一下三件事情:
1. 通过一个类的全限定名获取该类的二进制流。
2. 将该二进制流中的静态存储结构转化为方法去运行时数据结构。
3. 在内存中生成该类的Class对象,作为该类的数据访问入口。
验证
验证的目的是为了确保Class文件的字节流中的信息不回危害到虚拟机.在该阶段主要完成以下四钟验证:
1. 文件格式验证:验证字节流是否符合Class文件的规范,如主次版本号是否在当前虚拟机范围内,常量池中的常量是否有不被支持的类型.
2. 元数据验证:对字节码描述的信息进行语义分析,如这个类是否有父类,是否集成了不被继承的类等。
3. 字节码验证:是整个验证过程中最复杂的一个阶段,通过验证数据流和控制流的分析,确定程序语义是否正确,主要针对方法体的验证。如:方法中的类型转换是否正确,跳转指令是否正确等。
4. 符号引用验证:这个动作在后面的解析过程中发生,主要是为了确保解析动作能正确执行。
准备
准备阶段是为类的静态变量分配内存并将其初始化为默认值,这些内存都将在方法区中进行分配。准备阶段不分配类中的实例变量的内存,实例变量将会在对象实例化时随着对象一起分配在Java堆中。
public static int value=123;//在准备阶段value初始值为0 。在初始化阶段才会变为123 。
解析
该阶段主要完成符号引用到直接引用的转换动作。解析动作并不一定在初始化动作完成之前,也有可能在初始化之后。
初始化
初始化时类加载的最后一步,前面的类加载过程,除了在加载阶段用户应用程序可以通过自定义类加载器参与之外,其余动作完全由虚拟机主导和控制。到了初始化阶段,才真正开始执行类中定义的Java程序代码。
2. 简述java类加载机制?
虚拟机把描述类的数据从Class文件加载到内存,并对数据进行校验,解析和初始化,最终形成可以被虚拟机直接使用的java类型。
3. 类加载器双亲委派模型机制?
当一个类收到了类加载请求时,不会自己先去加载这个类,而是将其委派给父类,由父类去加载,如果此时父类不能加载,反馈给子类,由子类去完成类的加载。
4.什么是类加载器,类加载器有哪些?
实现通过类的权限定名获取该类的二进制字节流的代码块叫做类加载器。
主要有一下四种类加载器:
1. 启动类加载器(BootstrapClassLoader)用来加载java核心类库,无法被java程序直接引用。
2. 扩展类加载器(extensionsclass loader):它用来加载 Java 的扩展库。Java 虚拟机的实现会提供一个扩展库目录。该类加载器在此目录里面查找并加载 Java 类。
3. 系统类加载器(systemclass loader):它根据 Java 应用的类路径(CLASSPATH)来加载 Java 类。一般来说,Java 应用的类都是由它来完成加载的。可以通过ClassLoader.getSystemClassLoader()来获取它。
4. 用户自定义类加载器,通过继承java.lang.ClassLoader类的方式实现。
5、Java类加载器包括⼏种?它们之间的⽗⼦关系是怎么样的?双亲委派机制是什么意思?有什么好处?
启动Bootstrap类加载、扩展Extension类加载、系统System类加载。
父子关系如下:
1 启动类加载器 ,由C++ 实现,没有父类;
2 扩展类加载器,由Java语言实现,父类加载器为null;
3 系统类加载器,由Java语言实现,父类加载器为扩展类加载器;
4 自定义类加载器,父类加载器肯定为AppClassLoader。
双亲委派机制:类加载器收到类加载请求,自己不加载,向上委托给父类加载,父类加载不了,再自己加载。
优势避免Java核心API篡改。详细查看:深入理解Java类加载器(ClassLoader),
https://blog.csdn.net/javazejian/article/details/73413292/
6、如何⾃定义⼀个类加载器?你使⽤过哪些或者你在什么场景下需要⼀个⾃定义的类加载器吗?
自定义类加载的意义:
1 加载特定路径的class文件
2 加载一个加密的网络class文件
3 热部署加载class文件
7. 描述一下JVM加载class
JVM 中类的装载是由类加载器(ClassLoader)和它的子类来实现的,Java 中的类加载器是一个重要的 Java 运
行时系统组件,它负责在运行时查找和装入类文件中的类。
由于 Java 的跨平台性,经过编译的Java 源程序并不是一个可执行程序,而是一个或多个类文件。当 Java 程序
需要使用某个类时,JVM 会确保这个类已经被加载、连接(验证、准备和解析)和初始化。类的加载是指把类的.class
文件中的数据读入到内存中,通常是创建一个字节数组读入.class 文件,然后产生与所加载类对应的 Class 对象。加
载完成后,Class 对象还不完整,所以此时的类还不可用。当类被加载后就进入连接阶段,这一阶段包括验证、准备
(为静态变量分配内存并设置默认的初始值)和解析(将符号引用替换为直接引用)三个步骤。最后 JVM 对类进行
初始化,包括:
如果类存在直接的父类并且这个类还没有被初始化,那么就先初始化父类;
如果类中存在初始化语句,就依次执行这些初始化语句。类的加载是由类加载器完成的,类加载器包括:根加载器
(BootStrap)、扩展加载器(Extension)、系统加载器(System)和用户自定义类加载器(java.lang.ClassLoader
的子类)。
从 Java 2(JDK 1.2)开始,类加载过程采取了父亲委托机制(PDM)。PDM 更好的保证了 Java平台的安全
性,在该机制中,JVM 自带的Bootstrap是根加载器,其他的加载器都有且仅有一个父类加载器。类的加载首先请求
父类加载器加载,父类加载器无能为力时才由其子类加载器自行加载。JVM不会向Java 程序提供对 Bootstrap 的引
用。
下面是关于几个类加载器的说明:
•Bootstrap:一般用本地代码实现,负责加载 JVM 基础核心类库(rt.jar);
•Extension:从 java.ext.dirs 系统属性所指定的目录中加载类库,它的父加载器是 Bootstrap;
•System:又叫应用类加载器,其父类是 Extension。它是应用最广泛的类加载器。它从环境变量classpath
或者系统属性 java.class.path 所指定的目录中记载类,是用户自定义加载器的默认父加载器。
8 jvm加载类的机制是什么?
Java中的所有类,都需要由类加载器装载到JVM中才能运行。类加载器本身也是一个类,而它的工作就是把class文件从硬盘读取到内存中。
在写程序的时候,我们几乎不需要关心类的加载,因为这些都是隐式装载的,除非我们有特殊的用法,像是反射,就需要显式的加载所需要的类。
Java类的加载是动态的,它并不会一次性将所有类全部加载后再运行,而是确保程序运行的基础类(像是基类)完全加载到jvm中,至于其他类,则在需要的时候才加载。
这当然就是为了节省内存开销。
9 委托模型机制是什么?
委托模型机制的工作原理很简单:
当类加载器需要加载类的时候,先请示其Parent(即上一层加载器)在其搜索路径载入,如果找不到,才在自己的搜索路径搜索该类。
这样的顺序其实就是加载器层次上自顶而下的搜索,因为加载器必须确保基础类的加载。之所以是这种机制,
还有一个安全上的考虑:如果某人将一个恶意的基础类加载到jvm,委托模型机制会搜索其父类加载器,显然是不可能找到的,自然就不会将该类加载进来。
五)其他
什么是Java虚拟机?为什么Java被称作是“平台无关的编程语言”?
答:Java虚拟机是一个可以执行Java字节码的虚拟机进程。Java源文件被编译成能被Java虚拟机执行的字节码文件。
Java被设计成允许应用程序可以运行在任意的平台,而不需要程序员为每一个平台单独重写或者是重新编译。Java虚拟机让这个变为可能,因为它知道底层硬件平台的指令长度和其他特性。
JDK和JRE的区别是什么?
答:Java运行时环境(JRE)。它包括Java虚拟机、Java核心类库和支持文件。它不包含开发工具(JDK)—编译器、调试器和其他工具。
Java开发工具包(JDK)是完整的Java软件开发包,包含了JRE,编译器和其他的工具(比如:JavaDoc,Java调试器),可以让开发者开发、编译、执行Java应用程序。
jvm原理
jvm gc过程
gc 项目中遇到的问题 如何解决的
平时在tomcat里面有没有进行相关的配置?
Jvm老年代与新生代的比例?
YGC和FGC发生的具体场景?
Jstack,Jmap,Jutil分别的意义?如何在线上排查jvm相关的问题?
gc垃圾回收算法;
jvm堆内存和栈内存,如何查看堆内存;
《五》、计算机网络
计算机网络常考面试题
七层网络结构
TCP三次握手和四次挥手
TCP、UDP协议的区别
在浏览器中输入url地址->>显示主页的过程
TCP 协议如何保证可靠传输
HTTP和HTTPS的区别
常见的状态码。
一,OSI与TCP/IP各层的结构、功能、协议
体系结构
学习计算机网络时我们一般采用折中的办法,也就是中和OSI和TCP/IP的优点,采用一种只有五层协议的体系结构,这样既简洁又能将概念阐述清楚。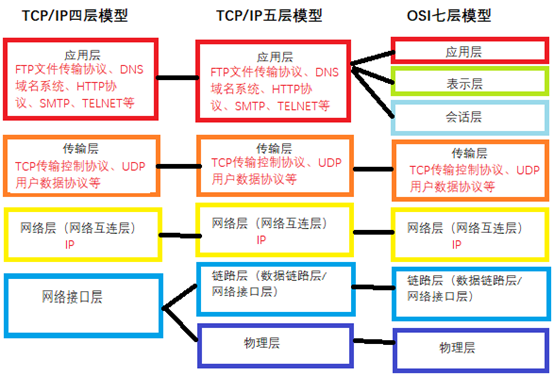
网络分层结构
结合互联网的情况,自上而下地,非常简要的介绍一下各层的作用。
1 应用层
应用层(application-layer)的任务是通过应用进程间的交互来完成特定网络应用。应用层协议定义的是应用进程(进程:主机中正在运行的程序)间的通信和交互的规则。对于不同的网络应用需要不同的应用层协议。在互联网中应用层协议很多,如域名系统DNS,支持万维网应用的HTTP协议,支持电子邮件的SMTP协议等等。我们把应用层交互的数据单元称为报文。
域名系统
域名系统(Domain Name System缩写DNS,Domain Name被译为域名)是因特网的一项核心服务,它作为可以将域名和IP地址相互映射的一个分布式数据库,能够使人更方便的访问互联网,而不用去记住能够被机器直接读取的IP数串。(百度百科)例如:一个公司的Web网站可看作是它在网上的门户,而域名就相当于其门牌地址,通常域名都使用该公司的名称或简称。例如上面提到的微软公司的域名,类似的还有:IBM公司的域名是www.ibm.com、Oracle公司的域名是www.oracle.com、Cisco公司的域名是www.cisco.com等。
HTTP协议
超文本传输协议(HTTP,HyperText Transfer Protocol)是互联网上应用最为广泛的一种网络协议。所有的WWW文件都必须遵守这个标准。设计HTTP最初的目的是为了提供一种发布和接收HTML页面的方法。(百度百科)
2 运输层
运输层(transport layer)的主要任务就是负责向两台主机进程之间的通信提供通用的数据传输服务。应用进程利用该服务传送应用层报文。“通用的”是指并不针对某一个特定的网络应用,而是多种应用可以使用同一个运输层服务。由于一台主机可同时运行多个线程,因此运输层有复用和分用的功能。所谓复用就是指多个应用层进程可同时使用下面运输层的服务,分用和复用相反,是运输层把收到的信息分别交付上面应用层中的相应进程。
运输层主要使用以下两种协议
1 传输控制协议TCP(TransmissonControl Protocol)—提供面向连接的,可靠的数据传输服务。
2 用户数据协议UDP(User DatagramProtocol)—提供无连接的,尽最大努力的数据传输服务(不保证数据传输的可靠性)。
UDP的主要特点
1 UDP是无连接的;
2 UDP使用尽最大努力交付,即不保证可靠交付,因此主机不需要维持复杂的链接状态(这里面有许多参数);
3 UDP是面向报文的;
4 UDP没有拥塞控制,因此网络出现拥塞不会使源主机的发送速率降低(对实时应用很有用,如IP电话,实时视频会议等);
5 UDP支持一对一、一对多、多对一和多对多的交互通信;
6 UDP的首部开销小,只有8个字节,比TCP的20个字节的首部要短。
TCP的主要特点
1 TCP是面向连接的。(就好像打电话一样,通话前需要先拨号建立连接,通话结束后要挂机释放连接);
2 每一条TCP连接只能有两个端点,每一条TCP连接只能是点对点的(一对一);
3 TCP提供可靠交付的服务。通过TCP连接传送的数据,无差错、不丢失、不重复、并且按序到达;
4 TCP提供全双工通信。TCP允许通信双方的应用进程在任何时候都能发送数据。TCP连接的两端都设有发送缓存和接收缓存,用来临时存放双方通信的数据;
5 面向字节流。TCP中的“流”(stream)指的是流入进程或从进程流出的字节序列。“面向字节流”的含义是:虽然应用程序和TCP的交互是一次一个数据块(大小不等),但TCP把应用程序交下来的数据仅仅看成是一连串的无结构的字节流。
3 网络层
网络层(network layer)负责为分组交换网上的不同主机提供通信服务。在发送数据时,网络层把运输层产生的报文段或用户数据报封装成分组和包进行传送。在TCP/IP体系结构中,由于网络层使用IP协议,因此分组也叫IP数据报,简称数据报。
这里要注意:不要把运输层的“用户数据报UDP”和网络层的“IP数据报”弄混。另外,无论是哪一层的数据单元,都可笼统地用“分组”来表示。
网络层的另一个任务就是选择合适的路由,使源主机运输层所传下来的分株,能通过网络层中的路由器找到目的主机。
这里强调指出,网络层中的“网络”二字已经不是我们通常谈到的具体网络,而是指计算机网络体系结构模型中第三层的名称.
互联网是由大量的异构(heterogeneous)网络通过路由器(router)相互连接起来的。互联网使用的网络层协议是无连接的网际协议(Intert Prococol)和许多路由选择协议,因此互联网的网络层也叫做网际层或IP层。
4 数据链路层
数据链路层(data link layer)通常简称为链路层。两台主机之间的数据传输,总是在一段一段的链路上传送的,这就需要使用专门的链路层的协议。在两个相邻节点之间传送数据时,数据链路层将网络层交下来的IP数据报组装程帧,在两个相邻节点间的链路上传送帧。每一帧包括数据和必要的控制信息(如同步信息,地址信息,差错控制等)。
在接收数据时,控制信息使接收端能够知道一个帧从哪个比特开始和到哪个比特结束。这样,数据链路层在收到一个帧后,就可从中提出数据部分,上交给网络层。控制信息还使接收端能够检测到所收到的帧中有误差错。如果发现差错,数据链路层就简单地丢弃这个出了差错的帧,以避免继续在网络中传送下去白白浪费网络资源。如果需要改正数据在链路层传输时出现差错(这就是说,数据链路层不仅要检错,而且还要纠错),那么就要采用可靠性传输协议来纠正出现的差错。这种方法会使链路层的协议复杂些。
5 物理层
在物理层上所传送的数据单位是比特。物理层(physical layer)的作用是实现相邻计算机节点之间比特流的透明传送,尽可能屏蔽掉具体传输介质和物理设备的差异。使其上面的数据链路层不必考虑网络的具体传输介质是什么。“透明传送比特流”表示经实际电路传送后的比特流没有发生变化,对传送的比特流来说,这个电路好像是看不见的。
在互联网使用的各种协中最重要和最著名的就是TCP/IP两个协议。现在人们经常提到的TCP/IP并不一定单指TCP和IP这两个具体的协议,而往往表示互联网所使用的整个TCP/IP协议族。
上面我们对计算机网络的五层体系结构有了初步的了解,下面附送一张七层体系结构图总结一下。

图片来源:https://blog.csdn.net/yaopeng_2005/article/details/7064869
二,TCP 三次握手和四次挥手(面试常客)
为了准确无误地把数据送达目标处,TCP协议采用了三次握手策略。
漫画图解: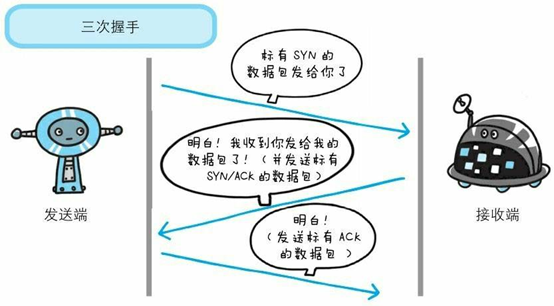
TCP三次握手
简单示意图: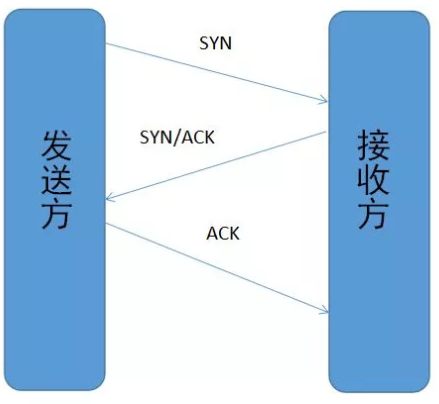
TCP三次握手
客户端–发送带有 SYN 标志的数据包–一次握手–服务端
服务端–发送带有 SYN/ACK 标志的数据包–二次握手–客户端
客户端–发送带有带有 ACK 标志的数据包–三次握手–服务端
为什么要三次握手?
三次握手的目的是建立可靠的通信信道,说到通讯,简单来说就是数据的发送与接收,而三次握手最主要的目的就是双方确认自己与对方的发送与接收是正常的。
第一次握手:Client 什么都不能确认;Server 确认了对方发送正常
第二次握手:Client 确认了:自己发送、接收正常,对方发送、接收正常;Server 确认了:自己接收正常,对方发送正常
第三次握手:Client 确认了:自己发送、接收正常,对方发送、接收正常;Server 确认了:自己发送、接收正常,对方发送接收正常
所以三次握手就能确认双发收发功能都正常,缺一不可。
为什么要传回SYN
接收端传回发送端所发送的 SYN 是为了告诉发送端,我接收到的信息确实就是你所发送的信号了。
SYN 是 TCP/IP 建立连接时使用的握手信号。在客户机和服务器之间建立正常的 TCP 网络连接时,客户机首先发出一个 SYN 消息,服务器使用 SYN-ACK 应答表示接收到了这个消息,最后客户机再以 ACK(Acknowledgement[汉译:确认字符 ,在数据通信传输中,接收站发给发送站的一种传输控制字符。它表示确认发来的数据已经接受无误。 ])消息响应。这样在客户机和服务器之间才能建立起可靠的TCP连接,数据才可以在客户机和服务器之间传递。
传了 SYN,为啥还要传 ACK
双方通信无误必须是两者互相发送信息都无误。传了 SYN,证明发送方到接收方的通道没有问题,但是接收方到发送方的通道还需要 ACK 信号来进行验证。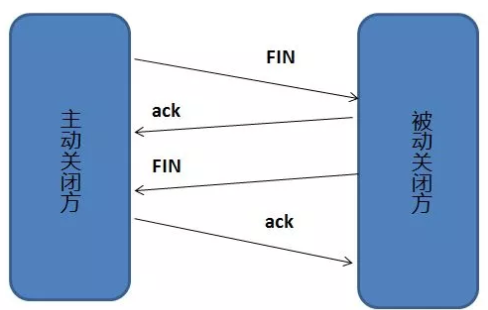
TCP四次挥手
断开一个 TCP 连接则需要“四次挥手”:
1 客户端-发送一个 FIN,用来关闭客户端到服务器的数据传送
2 服务器-收到这个 FIN,它发回一个 ACK,确认序号为收到的序号加1 。和 SYN 一样,一个 FIN 将占用一个序号
3 服务器-关闭与客户端的连接,发送一个FIN给客户端
4 客户端-发回 ACK 报文确认,并将确认序号设置为收到序号加1
为什么要四次挥手
任何一方都可以在数据传送结束后发出连接释放的通知,待对方确认后进入半关闭状态。当另一方也没有数据再发送的时候,则发出连接释放通知,对方确认后就完全关闭了TCP连接。
举个例子:A 和 B 打电话,通话即将结束后,A 说“我没啥要说的了”,B回答“我知道了”,但是 B 可能还会有要说的话,A 不能要求 B 跟着自己的节奏结束通话,于是 B 可能又巴拉巴拉说了一通,最后 B 说“我说完了”,A 回答“知道了”,这样通话才算结束。
上面讲的比较概括,推荐一篇讲的比较细致的文章:
https://blog.csdn.net/qzcsu/article/details/72861891
三,TCP、UDP 协议的区别
| 类型 | 是否面向连接 | 传输可靠性 | 传输形式 | 传输效率 | 所需资源 | 应用场景 | 首部字节 |
|---|---|---|---|---|---|---|---|
| TCP | 面向连接 | 可靠 | 字节流 | 慢 | 多 | 要求通信数据可靠(eg:文件传输、邮件传输) | 20-60 |
| UDP | 面向无连接 | 不可靠 | 数据报文段 | 快 | 少 | 要求通信速度高(eg:域名转换) | 8个字节 (由4个字段组成) |
TCP、UDP协议的区别
UDP 在传送数据之前不需要先建立连接,远地主机在收到 UDP 报文后,不需要给出任何确认。虽然 UDP 不提供可靠交付,但在某些情况下 UDP 确是一种最有效的工作方式(一般用于即时通信),比如: QQ 语音、 QQ 视频、直播等等
TCP提供面向连接的服务。在传送数据之前必须先建立连接,数据传送结束后要释放连接。 TCP 不提供广播或多播服务。由于 TCP 要提供可靠的,面向连接的运输服务(TCP的可靠体现在TCP在传递数据之前,会有三次握手来建立连接,而且在数据传递时,有确认、窗口、重传、拥塞控制机制,在数据传完后,还会断开连接用来节约系统资源),这一难以避免增加了许多开销,如确认,流量控制,计时器以及连接管理等。这不仅使协议数据单元的首部增大很多,还要占用许多处理机资源。TCP 一般用于文件传输、发送和接收邮件、远程登录等场景。
四,在浏览器中输入url地址 ->> 显示主页的过程
1 打开一个网页,整个过程会使用哪些协议(百度好像最喜欢问这个问题。)
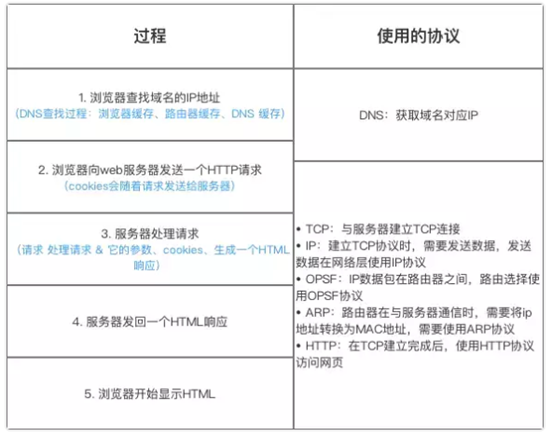
总体来说分为以下几个过程:
1 DNS解析
2 TCP连接
3 发送HTTP请求
4 服务器处理请求并返回HTTP报文
5 浏览器解析渲染页面
6 连接结束
具体可以参考下面这篇文章:
https://segmentfault.com/a/1190000006879700
2假设某用户浏览郑州轻工业学院主页 http://www.zzuli.edu.cn/index.html,简述浏览器与服务器的信息交互过程。
答:用户点击URL后所发生的事件:
(1)浏览器分析超链接指向页面的URL。
(2)浏览器向DNS请求解析www.zzuli.edu.cn的IP地址。
(3)域名系统DNS解析出郑州轻工业学院服务器的IP地址。
(4)浏览器与服务器建立TCP连接。
(5)浏览器发出取文件命名:GET/chn/yxsz/index.html。
(6)服务器给出响应,把文件index.html发送给浏览器。
(7)TCP连接释放。
(8)浏览器显示“郑州轻工业学院院系设置”文件index.html中的所有文本。
五,各种协议与HTTP协议之间的关系
一般面试官会通过这样的问题来考察你对计算机网络知识体系的理解。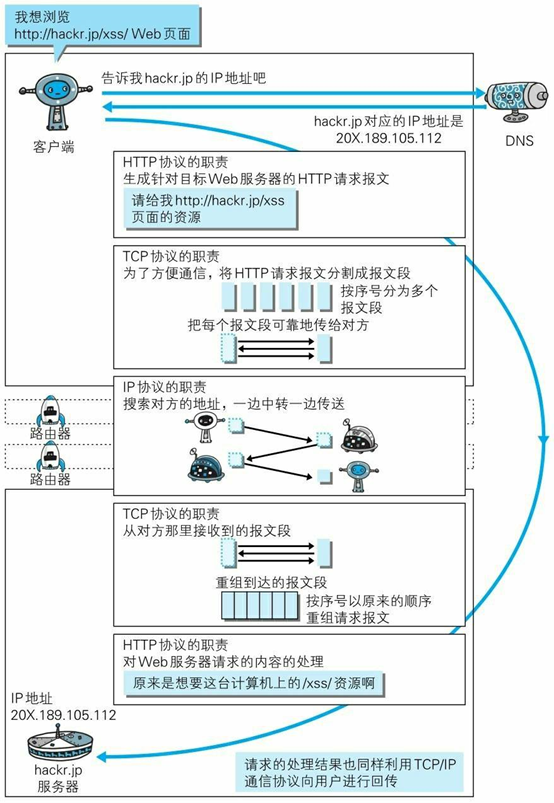
各种协议与HTTP协议之间的关系
六,TCP协议如何保证可靠传输
1 应用数据被分割成TCP认为最适合发送的数据块。
2 超时重传: 当TCP发出一个段后,它启动一个定时器,等待目的端确认收到这个报文段。如果不能及时收到一个确认,将重发这个报文段。
3 TCP给发送的每一个包进行编号,接收方对数据包进行排序,把有序数据传送给应用层。
4 校验和: TCP将保持它首部和数据的检验和。这是一个端到端的检验和,目的是检测数据在传输过程中的任何变化。如果收到段的检验和有差错,TCP将丢弃这个报文段和不确认收到此报文段。
5 TCP的接收端会丢弃重复的数据。
6 流量控制: TCP连接的每一方都有固定大小的缓冲空间,TCP的接收端只允许发送端发送接收端缓冲区能接纳的我数据。当接收方来不及处理发送方的数据,能提示发送方降低发送的速率,防止包丢失。TCP使用的流量控制协议是可变大小的滑动窗口协议。 (TCP利用滑动窗口实现流量控制)
7 拥塞控制: 当网络拥塞时,减少数据的发送。
8 停止等待ARQ协议(stop and wait) 也是为了实现可靠传输的,它的基本原理就是每发完一个分组就停止发送,等待对方确认。在收到确认后再发下一个分组。
超时重传
停止等待协议中超时重传是指只要超过一段时间仍然没有收到确认,就重传前面发送过的分组(认为刚才发送过的分组丢失了)。因此每发送完一个分组需要设置一个超时计时器,其重转时间应比数据在分组传输的平均往返时间更长一些。这种自动重传方式常称为自动重传请求ARQ。另外在停止等待协议中若收到重复分组,就丢弃该分组,但同时还要发送确认。连续ARQ协议可提高信道利用率。发送维持一个发送窗口,凡位于发送窗口内的分组可连续发送出去,而不需要等待对方确认。接收方一般采用累积确认,对按序到达的最后一个分组发送确认,表明到这个分组位置的所有分组都已经正确收到了。
停止等待协议
停止等待协议是为了实现可靠传输的,它的基本原理就是每发完一个分组就停止发送,等待对方确认。在收到确认后再发下一个分组。
为了提高传输效率,发送方可以不使用低效率的停止等待协议,而是采用流水线传输。流水线传输就是发送方可连续发送多个分组,不必每发完一个分组就停下来等待对方确认。这样可使信道上一直有数据不间断的在传送。这种传输方式可以明显提高信道利用率。
滑动窗口
TCP利用滑动窗口实现流量控制的机制。
发送窗口里面的序号表示允许发送的序号。发送窗口后沿的后面部分表示已发送且已收到确认,而发送窗口前沿的前面部分表示不晕与发送。发送窗口后沿的变化情况有两种可能,即不动(没有收到新的确认)和前移(收到了新的确认)。发送窗口的前沿通常是不断向前移动的。一般来说,我们总是希望数据传输更快一些。但如果发送方把数据发送的过快,接收方就可能来不及接收,这就会造成数据的丢失。所谓流量控制就是让发送方的发送速率不要太快,要让接收方来得及接收。
流量控制
流量控制是为了控制发送方发送速率,保证接收方来得及接收。
接收方发送的确认报文中的窗口字段可以用来控制发送方窗口大小,从而影响发送方的发送速率。将窗口字段设置为 0,则发送方不能发送数据。
拥塞控制
在某段时间,若对网络中某一资源的需求超过了该资源所能提供的可用部分,网络的性能就要变坏。这种情况就叫拥塞。拥塞控制就是为了防止过多的数据注入到网络中,这样就可以使网络中的路由器或链路不致过载。拥塞控制所要做的都有一个前提,就是网络能够承受现有的网络负荷。拥塞控制是一个全局性的过程,涉及到所有的主机,所有的路由器,以及与降低网络传输性能有关的所有因素。相反,流量控制往往是点对点通信量的控制,是个端到端的问题。流量控制所要做到的就是抑制发送端发送数据的速率,以便使接收端来得及接收。
为了进行拥塞控制,TCP发送方要维持一个拥塞窗口(cwnd)的状态变量。拥塞控制窗口的大小取决于网络的拥塞程度,并且动态变化。发送方让自己的发送窗口取为拥塞窗口和接收方的接受窗口中较小的一个。
TCP的拥塞控制采用了四种算法,即慢开始、拥塞避免、快重传和快恢复。在网络层也可以使路由器采用适当的分组丢弃策略(如主动队列管理AQM),以减少网络拥塞的发生。
慢开始:
慢开始算法的思路是当主机开始发送数据时,如果立即把大量数据字节注入到网络,那么可能会引起网络阻塞,因为现在还不知道网络的符合情况。经验表明,较好的方法是先探测一下,即由小到大逐渐增大发送窗口,也就是由小到大逐渐增大拥塞窗口数值。cwnd初始值为1,每经过一个传播轮次,cwnd加倍。 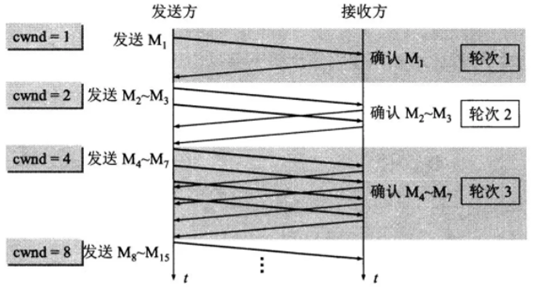
拥塞避免:
拥塞避免算法的思路是让拥塞窗口cwnd缓慢增大,即每经过一个往返时间RTT就把发送放的cwnd加1.
快重传与快恢复:
在TCP/IP中,快速重传和恢复(fast retransmit and recovery,FRR)是一种拥塞控制算法,它能快速恢复丢失的数据包。没有FRR,如果数据包丢失了,TCP将会使用定时器来要求传输暂停。在暂停的这段时间内,没有新的或复制的数据包被发送。有了FRR,如果接收机接收到一个不按顺序的数据段,它会立即给发送机发送一个重复确认。如果发送机接收到三个重复确认,它会假定确认件指出的数据段丢失了,并立即重传这些丢失的数据段。有了FRR,就不会因为重传时要求的暂停被耽误。 当有单独的数据包丢失时,快速重传和恢复(FRR)能最有效地工作。当有多个数据信息包在某一段很短的时间内丢失时,它则不能很有效地工作。 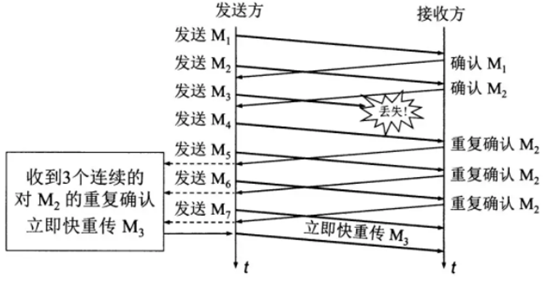
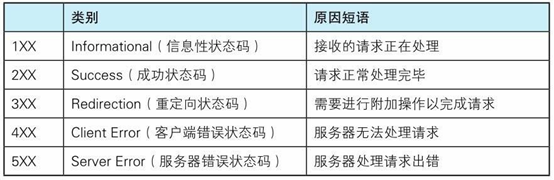
七、状态码
八、HTTP长连接、短连接
在HTTP/1.0中默认使用短连接。也就是说,客户端和服务器每进行一次HTTP操作,就建立一次连接,任务结束就中断连接。当客户端浏览器访问的某个HTML或其他类型的Web页中包含有其他的Web资源(如JavaScript文件、图像文件、CSS文件等),每遇到这样一个Web资源,浏览器就会重新建立一个HTTP会话。
而从HTTP/1.1起,默认使用长连接,用以保持连接特性。使用长连接的HTTP协议,会在响应头加入这行代码:
Connection:keep-alive
在使用长连接的情况下,当一个网页打开完成后,客户端和服务器之间用于传输HTTP数据的TCP连接不会关闭,客户端再次访问这个服务器时,会继续使用这一条已经建立的连接。Keep-Alive不会永久保持连接,它有一个保持时间,可以在不同的服务器软件(如Apache)中设定这个时间。实现长连接需要客户端和服务端都支持长连接。
HTTP协议的长连接和短连接,实质上是TCP协议的长连接和短连接。
《六》、Linux
Linux面试必备
一、简单介绍一下 Linux 文件系统?
1.1、Linux文件系统简介
在Linux操作系统中,所有被操作系统管理的资源,例如网络接口卡、磁盘驱动器、打印机、输入输出设备、普通文件或是目录都被看作是一个文件。
也就是说在LINUX系统中有一个重要的概念:一切都是文件。其实这是UNIX哲学的一个体现,而Linux是重写UNIX而来,所以这个概念也就传承了下来。在UNIX系统中,把一切资源都看作是文件,包括硬件设备。UNIX系统把每个硬件都看成是一个文件,通常称为设备文件,这样用户就可以用读写文件的方式实现对硬件的访问。
1.2、文件类型与目录结构
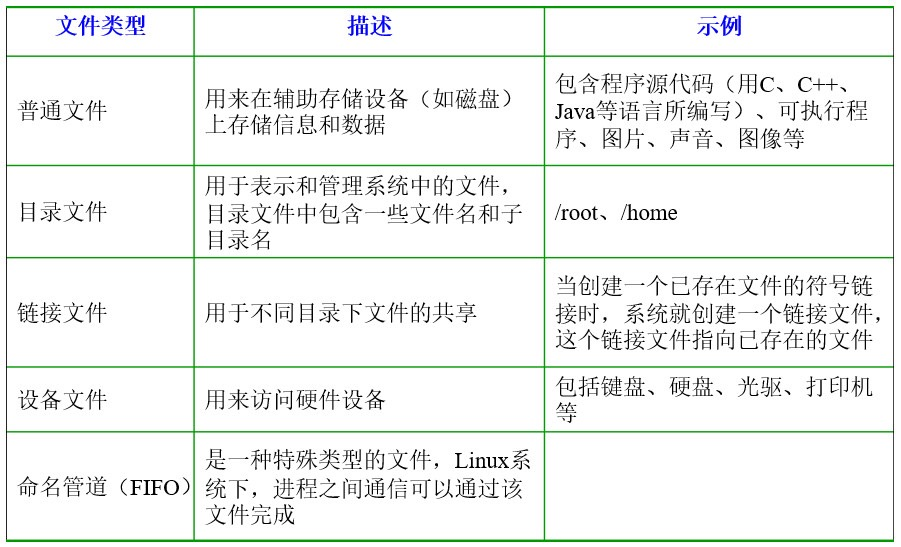
1.2.1、Linux支持5种文件类型:
1.2.2、Linux的目录结构如下:
Linux文件系统的结构层次鲜明,就像一棵倒立的树,最顶层是其根目录: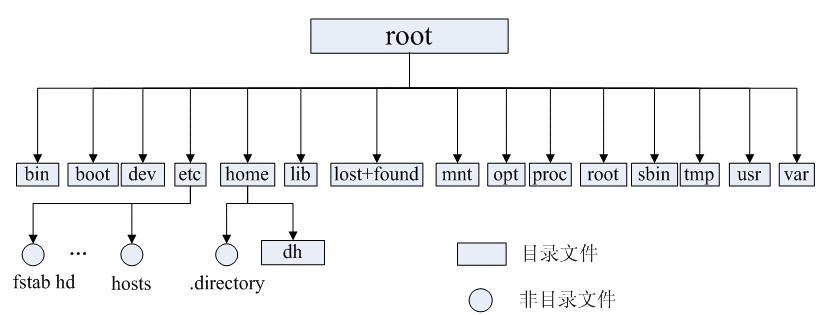
Linux的目录结构
1.2.3、常见目录说明:
/bin: 存放二进制可执行文件(ls,cat,mkdir等),常用命令一般都在这里;
/etc: 存放系统管理和配置文件;
/home: 存放所有用户文件的根目录,是用户主目录的基点,比如用户user的主目录就是/home/user,可以用~user表示;
/usr : 用于存放系统应用程序;
/opt: 额外安装的可选应用程序包所放置的位置。一般情况下,我们可以把tomcat等都安装到这里;
/proc: 虚拟文件系统目录,是系统内存的映射。可直接访问这个目录来获取系统信息;
/root: 超级用户(系统管理员)的主目录(特权阶级^o^);
/sbin: 存放二进制可执行文件,只有root才能访问。这里存放的是系统管理员使用的系统级别的管理命令和程序。如ifconfig等;
/dev: 用于存放设备文件;
/mnt: 系统管理员安装临时文件系统的安装点,系统提供这个目录是让用户临时挂载其他的文件系统;
/boot: 存放用于系统引导时使用的各种文件;
/lib : 存放着和系统运行相关的库文件;
/tmp: 用于存放各种临时文件,是公用的临时文件存储点;
/var: 用于存放运行时需要改变数据的文件,也是某些大文件的溢出区,比方说各种服务的日志文件(系统启动日志等。)等;
/lost+found: 这个目录平时是空的,系统非正常关机而留下“无家可归”的文件(windows下叫什么.chk)就在这里。
二、Linux 常用命令
2.1、目录切换命令
cd usr: 切换到该目录下usr目录cd ..(或cd../): 切换到上一层目录cd /: 切换到系统根目录cd ~: 切换到用户主目录cd -: 切换到上一个所在目录
2.2、增
mkdir 目录名称: 增加目录touch 文件名称: 文件的创建(增)
2.3、删
2.4、改
mv 目录/文件/压缩包名称: 修改目录/文件/压缩包的名称(改)mv 目录/文件/压缩包名称 目录/文件/压缩包的新位置: 移动目录的位置—-剪切(改)
cp -r 目录名称 目录拷贝的目标位置: 拷贝目录(改),-r代表递归拷贝cp 文件/压缩包名称 文件/压缩包拷贝的目标位置: 拷贝文件/压缩包(改)
拷贝文件和压缩包时不用写-r递归
vim 文件: 修改文件的内容(改)
在实际开发中,使用vim编辑器主要作用就是修改配置文件,下面是一般步骤:
vim 文件-——->进入文件——->命令模式———>按i进入编辑模式——->编辑文件 ———->按Esc进入底行模式——->输入:wq/q!(输入wq代表写入内容并退出,即保存;输入q!代表强制退出不保存。)
2.5、查
2.5.1、目录:
**ls**: 查看目录信息**ls -a**: **ls –l (缩写:ll)**: 查看该目录下的所有目录和文件的详细信息 **find 目录 参数**: 寻找目录(查)
2.5.2、文件:
cat/more/less/tail 文件名称: 文件的查看(查)cat: 只能显示最后一屏内容more: 可以显示百分比,回车可以向下一行,空格可以向下一页,q可以退出查看less: 可以使用键盘上的PgUp和PgDn向上 和向下翻页,q结束查看tail-10 : 查看文件的后10行,Ctrl+C结束tail -f 文件:可以对某个文件进行动态监控,例如tomcat的日志文件,会随着程序的运行,日志会变化,可以使用tail -f catalina-2016-11-11.log 监控文件的变化
2.6、压缩文件的操作命令
tar -zcvf 打包压缩后的文件名 要打包压缩的文件: 打包并压缩文件tar [-xvf] 压缩文件: 解压压缩包
z:调用gzip压缩命令进行压缩
c:打包文件
v:显示运行过程
f:指定文件名
1 test目录下有三个文件分别是:aaa.txt bbb.txt ccc.txt,如果我们要打包test目录并指定压缩后的压缩包名称为test.tar.gz
可以使用命令:tar -zcvf test.tar.gz aaa.txt bbb.txt ccc.txt或:tar -zcvf test.tar.gz /test/
2 将/test下的test.tar.gz解压到当前目录下可以使用命令:tar -xvf test.tar.gz
3 将/test下的test.tar.gz解压到根目录/usr下:tar-xvf xxx.tar.gz -C /usr(- C代表指定解压的位置)
2.7、其他常用命令
2.8.1、常见
pwd: 显示当前所在位置grep 要搜索的字符串要搜索的文件 --color: 搜索命令,—color代表高亮显示ps -ef/ps aux: 这两个命令都是查看当前系统正在运行进程,两者的区别是展示格式不同。
如果想要查看特定的进程可以使用这样的格式:ps aux|grep redis(查看包括redis字符串的进程)
如果直接用ps((ProcessStatus))命令,会显示所有进程的状态,通常结合grep命令查看某进程的状态。kill -9 进程的pid: 杀死进程(-9 表示强制终止。)
先用ps查找进程,然后用kill杀掉
2.8.2、网络通信命令
ifconfig:查看当前系统的网卡信息ping 192.168.…:查看与某台机器的连接情况netstat -an:查看当前系统的端口使用
2.8.3、shutdown:
shutdown -h now: 指定现在立即关机;shutdown +5 :“Systemwill shutdown after 5 minutes”:指定5分钟后关机,同时送出警告信息给登入用户。
2.8.4、reboot:
reboot: 重开机。reboot -w: 做个重开机的模拟(只有纪录并不会真的重开机)。
2.8、权限命令
ls -l:查看某个目录下的文件或目录的权限。
示例:在随意某个目录下ls -l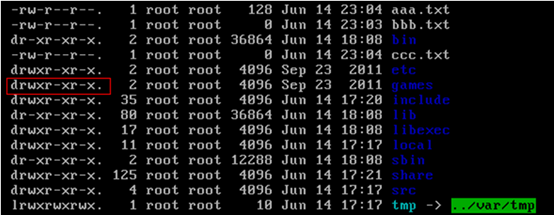
第一列的内容的信息解释如下: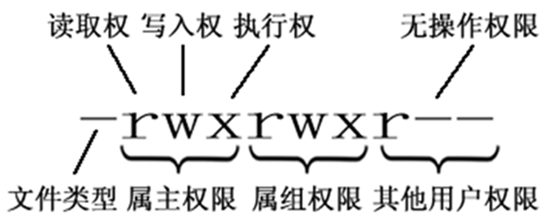
文件的类型:
d:代表目录
-:代表文件
l:代表链接(可以认为是window中的快捷方式)后面的9位分为3组,每3位置一组,分别代表属主的权限,与当前用户同组的用户的权限,其他用户的权限
r:代表权限是可读,r也可以用数字4表示
w:代表权限是可写,w也可以用数字2表示
x:代表权限是可执行,x也可以用数字1表示
| 属主(user) | 属组(group) | 其他用户 | ||||||
|---|---|---|---|---|---|---|---|---|
| r | w | x | r | w | x | r | w | x |
| 4 | 2 | 1 | 4 | 2 | 1 | 4 | 2 | 1 |
chmod:修改文件/目录的权限的命令
示例:
修改/test下的a.txt的权限为属主有全部权限,属主所在的组有读写权限,其他用户只有读的权限: chmodu=rwx,g=rw,o=r a.txt 或者chmod 764 a.txt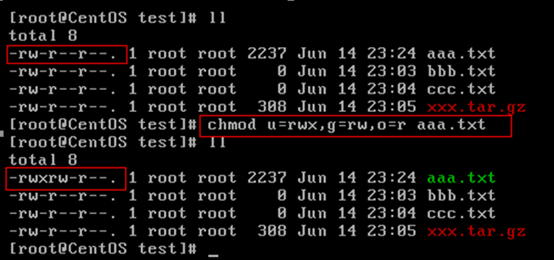
《七》、Git
Git面试必备知识点
git原理图总结
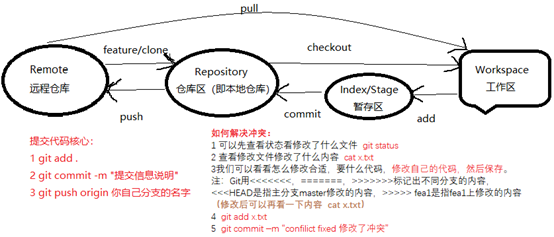
git原理图总结
Git提交文件到版本库有两步:
git add x.txt 或 git add .
git commit –m “xyzshad”
git diff a.txt
git add a.txt
git commit –m “xxxx”
git status
git log 查看历史记录
git log –pretty=oneline
回退
git reset —hard HEAD^ 回退到上一个版本
git reset —hard HEAD^^ 回退到上上个版本
git reset —hard HEAD~100 回退到前100个版本
查看a.txt文件里的内容:cata.txt
回退到上一个版本后我又后悔了,想重新回退到没回退之前那个版本
git reflog查看版本号
git reset —hard xyz(版本号)
如何解决冲突:
假设master分支和fea1分支都修改了x.txt 文件的第3行
假设需要在master分支上来合并分支fea1
git checkout master
git merge fea1
出现了冲突
1, 可以先查看状态看修改了什么文件 git status
2, 查看修改文件修改了什么内容 cat x.txt
3, (Git用<<<<<<<,=======,>>>>>>>标记出不同分支的内容,
其中<<
我们可以修改自己的代码,看要什么,,然后保存。
(修改后可以再看一下内容 catx.txt)
4, git add x.txt
5, git commit –m “confilict fixed 修改了冲突”
查看分支合并情况 git log
多人协作:
(远程仓库origin、主分支master、现在本地的x.txt文件,在master分支)
查看远程仓库的信息 git remote
查看远程仓库的详细信息 git remote -v
1, 推送分支
git push origin master
git push origin dev 把dev分支推送到远程仓库去
2, 抓取分支
1 git add .
2 git commit –m “xxx”
3 git push origin dev
git pull
git branch –set-upstream dev origin/dev
git pull
3,

若有收获,就点个赞吧
0 人点赞
