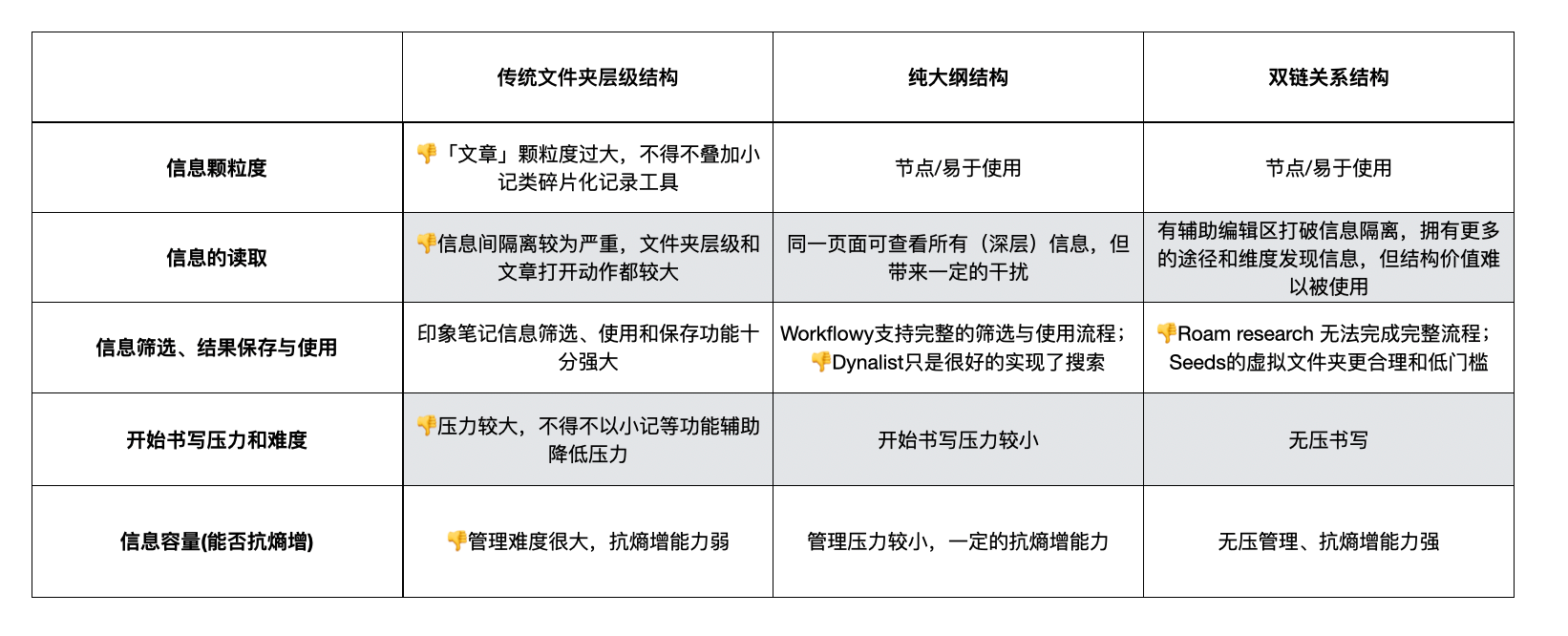
对「传统文件夹层级结构」、「纯大纲结构」和「双链结构」三种信息结构及其代表性工具进行横向分析,研究不同信息结构的优劣势。
信息价值与可用性
信息使用颗粒度
纯大纲结构在信息颗粒度方面有着天然的优势。大纲结构下所有信息都以节点为单位储存,不仅降低信息颗粒度,而且在书写过程中引导用户更佳简洁。通过不同层级关系可以自由选择信息颗粒度的大小,最小颗粒度就是一个节点。
大多以双链为核心信息关系的工具都选择大纲编辑器,以此来为信息的灵活使用做基础。但双链结构中信息不再拘泥于单一结构中存储位置,可以随意的聚合和解散,相较于纯大纲结构来说更能适应不同的使用场景和分类体系
传统文件夹层级结构以「文章」为单位的信息颗粒度太粗。所以此类工具大多选择以段落、卡片和block为单位来实现有效的关联和使用。
信息的读取
纯大纲结构中信息读取最为方便。信息都处于同一页面中,收起和展开动作也足够简单,这意味着能够轻松且直观的看到更多层级内(深层级)的内容。但读取便利的代价是一定程度上的信息干扰,特别是信息数量较大时,我们难以快速的区分哪些信息我们而言更为「重要」。
双链结构中信息可以通过更多维度被找到。在双链笔记中每条信息都会携带更多属性,也与其他信息有着更多维度的关联关系,除搜索之外可以通过多种途径和线索找到“正确”信息。但目前的双链结构工具在信息结构价值的表现力方面十分有限,特别是知识图谱,能够展示的结构价值比其他两种结构都要少。
在传统文件夹层级结构中信息的读取较为困难。一方面相较于纯大纲结构,文件夹与文章的展开和关闭动作成本更高,导致信息跨文章读取和使用难度大,另一方面又不如双链结构下有更多寻找的途径。如果不借助搜索和筛选功能,在传统文件夹层级结构中隐藏过深的内容被一次性正确找到的难度很大,必需辅助标签、编号、索引列表等工具提升读取效率
信息筛选、结果保存与使用
信息筛选和使用指我们对特定信息有需求时,需要将这些信息筛选并独立分离出来的动作。这个需求的实现取决于搜索及相关功能的设计,每个工具都有不同的表现。
所以这一部分我们将选择一些有代表性的产品,传统文件夹层级工具印象笔记,纯大纲结构工具Workflowy,大纲+文件夹工具Dynalist,双链工具代表Roam research和Seeds,具体分析相关功能的价值和体验。
印象笔记信息筛选、使用和保存功能十分强大:在传统文件夹层级中想要快速找到某个信息难度是很大的,但发展至已经有了许多五花八门的解决方法。比如印象笔记可以直接跳过文件夹层级进行笔记内容搜索,支持增加筛选条件,能够很好的实现信息的筛选功能;对于筛选结果可以进行不同样式的排序和展示、筛选标签、保存搜索结果,甚至支持直接进行共享、合作、保存、创建目录、演示和移动笔记功能,可以说是十分强大了。
Workflowy能够支持完整的筛选与使用流程。Workflowy有着强大的搜索和筛选功能,并且可以对筛选条件进行收藏。虽然没有直接提供管理功能,但可以轻松对所有搜索结果进行复制或者镜像操作(镜像功能特别棒),极大的保证信息的精简和实时更新。虽然相较于虚拟文件夹不够直观,操作也相对复杂,但完整实现信息筛选和使用的流程。
Dynalist仅仅是很好的实现了搜索。Dynalist的运算符搜索理论上更为强大,但却很难对筛选结果进行保存和使用。不仅没有提供进一步操作的功能,而且将搜索结果按照文章分隔,完全无法进行跨文章的管理和使用。就像你将选择出来的内容汇总在一个虚拟的文件夹中,但不可以对这个文件夹里的内容进一步操作一样鸡肋。
很大程度上是因为Dynalist过分强调文档和文件夹属性,文件夹一定程度上解决了信息分区上的难题,对许多用户来说降低了使用门槛,但将文件夹和文章凌驾于大纲结构之上,严重损伤了大纲结构的灵活性,甚至成为了束缚的枷锁。
Roam research 无法轻松完成完整流程。在Roam research中,得益于辅助编辑区,能够轻松实现复杂、反复的筛选,极大的便利了信息的查看、筛选和使用。但对筛选结果的保存功能仅是辅助编辑区置顶(而且是单个信息置顶),很难实现搜索结果的复用,增加无意义的重复工作。
Seeds的虚拟文件夹实现了更合理和低门槛的方式完成了筛选与使用流程。虚拟文件夹不会改变信息位置,完全无需顾虑是否会带来信息的重复和丢失,而且文件夹是最为熟悉和直观的信息区分方式,用户可以自由的将信息能够以不同属性和关系任意组合,以新的视角观察已有的知识。
是否有较大的书写压力
纯大纲结构工具开始书写的压力并不是很大。因为结构管理的成本很低,完全可以先随便在某个位置书写,之后在寻找合适的位置进行管理。
- Dynalist在纯大纲结构之上增加了文章概念,新建文章和标题成了书写的必要前提,大大增加开始书写压力,所以不得不以inbox功能作为弥补
双链工具Roam research和Seeds开始书写的压力也极低。因为提供了无压记录空间每日画布,让开始书写的动作自然而然。同时以许多辅助功能(例如Seeds的智能关联、智能回顾等)保证信息最大程度上的可用,减少用户对于信息丢失和混乱的焦虑。
而传统文件夹层级结构工具开始书写的压力都比较大。由于结构僵化,导致对内容的调整和更改困难,在书写前需花费较多精力在寻找正确的文档位置和文章标题。
虽然目前许多工具选择增加小记(语雀)类适合碎片化记录的辅助功能,增加信息缓冲区域,降低开始书写焦虑感,但对碎片信息的有效管理和使用依旧很难做到像双链结构一样灵活和自由。
能否有效抵御熵增
传统层级文件夹结构和大纲结构本质上都是将信息按照一个严格的框架进行管理,信息本就是属性复杂,想要在一个相互独立、完全穷尽的系统内合理放置所有信息十分困难,随着新信息的增加,原有的结构常常需要更新甚至重新架构,这对于结构灵活性和人的精力投入都有很大挑战。
- 纯大纲结构内层级结构的调整十分简洁,当然这也有一定的学习成本,极致流畅体验一定程度上依赖于对快捷键的使用,而且结构越是简单的工具,越是需要成熟的管理方法和知识基础支持。总之在管理上的相对轻松是抗熵增能力极重要的要素,
- 传统层级文件夹则结构僵化,调整困难,抗熵增能力较弱。而且对信息的管理的方式需耗费巨大精力,随着信息数量爆发而指数级增长,这种精力需求会超出人的承受能力。
双链结构的最理想状态是依托智能,让结构随着新信息的加入实时生长和变换,无需过多的人力管理。而且目前的双向链接、标签、引用、创建待办等操作交互成本极低,符合人的思维逻辑,可以在书写时自然而然的完成,基本不会带来管理压力。在这样自由的结构中不仅抗熵增能力强,而且更利于灵感的激发和信息价值的挖掘。
其他
传统层级文件夹和线性的文章更适合内容存储、传播与协作
传统文件夹层级结构相较于其他两种结构而言,入门门槛和学习成本都是最低的,是大多数人最为熟悉也能最快上手的信息管理结构。
由于人脑的信息获取方式以及人类语言的特性,线性的文章更便于理解和读取,而文件夹结构天然适合对信息进行明确的分区,视觉上结构展示也较为清晰,适合已有成熟的知识体系或完备的信息库的存储、传播,同时也更适合团队之间的协作。
但如果降低对学习门槛的担忧,未来的数字化的动态存储结构或许是更好的选择,像维基百科一样的知识库,在信息价值和信息管理方面都是比传统文件夹层级结构更好的选择。唯一需要强化的是将大纲笔记转换为线性文章的能力,这一步大多工具呈现都有些简陋。
大纲结构在初期知识学习、体系搭建时价值重大
在我们学习新的知识时,常常需要系统性的获取知识,参考现有成熟的知识框架,慢慢梳理出自己能够理解和记忆的结构,甚至需要借助思维导图工具将大纲更平铺展示,(因为思维导图比大纲能更好的做到精炼提纲,这种铺开一片的展示方式,使得人可以扫一眼就可以瞬间获取整体的思路)了解其结构逻辑,进一步梳理和内化。
大纲类工具能够轻松的调整结构,提供更好的书写体验,同时还可以与思维导图轻松转换。是明确学习目标和方向,形成整体性的认识,反复调整结构的知识搭建阶段的最佳选择。但这并不是纯大纲结构的优势,而是所有好的大纲编辑器都可以做到的。就像Roam research和Seeds就可以覆盖着一类的场景,Roam research的文章+大纲结构与Dynalist别无二致。
唯一的差别是纯大纲结构能够让相关信息更为彻底的陈列、管理,对于初期学习系统行思考和记忆和有一定帮助。
双链关系结构中,更多的是融合、灵感与创新
如果想要在某一领域发现灵感,做出创新,往往需要将该领域的知识融会贯通,并跳脱出现有的知识框架。大家都明白这是一件很难的事情,但双链结构能够让这一过程变得简单。
双链关系结构保留了信息更多的属性和价值,让你的大脑从信息爆炸中解脱出来。同时因为在这个结构中信息没有固定的位置结构,可以随时以更多元、灵活的方式融合,为你提供另一个维度观察、组合信息。
而记录体验的便捷和信息使用的高效让书写习惯自然而然的养成,书写过程更是可以与意想不到的信息的不期而遇,符合人脑更擅长联想而非记忆的特性,为灵感的到来做好一切准备。
但对于初次了解的用户来说依旧有着较高的门槛,因为不仅需要接受信息去结构化概念,减少秩序焦虑,还要拥有较为扎实知识基础,学习在信息关联中发现价值和灵感。
一个保留问题
信息价值与秩序感一定对立吗?
去结构化的信息结构更能自由的组合和携带更多属性信息,但与此同时却会与人们追求秩序和简洁天性相违背。二者一定是对立关系吗,还是我们还未发现更好的解决方式?

若有收获,就点个赞吧
0 人点赞
