https://zhuanlan.zhihu.com/p/104631505
一、倒排索引
倒排索引源于实际应用中需要根据属性的值来查找记录。这种索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址。由于不是由记录来确定属性值,而是由属性值来确定记录的位置,因而称为倒排索引(inverted index)。带有倒排索引的文件我们称为倒排索引文件,简称倒排文件(inverted file)。 ElasticSearch引擎把文档数据写入到倒排索引(Inverted Index)的数据结构中,倒排索引建立的是分词(Term)和文档(Document)之间的映射关系,在倒排索引中,数据是面向词(Term)而不是面向文档的。一个倒排索引由文档中所有不重复词的列表构成,对于其中每个词,有一个包含它的文档列表。
倒排索引包含两个部分
1、由不同的索引词(index term)组成的索引表,称为“词典”(Term Dictionary)。其中包含了各种词汇,以及这些词汇的统计信息(如出现频率nDocs),这些统计信息可以直接用于各种排名算法。词典一般用 FST(Finite State Transducer)结构实现。
2、由每个索引词出现过的文档集合,以及命中位置等信息构成。也称为“倒排列表”(Posting List)。就是正排索引产生的那张表。当然这部分可以没有。具体看自己的业务需求了。
倒排列表记录了单词对应的文档集合,有倒排索引项(Posting)组成。
倒排索引项主要包含如下信息:
1.文档id用于获取原始信息
2.单词频率(TF,Term Frequency),记录该单词在该文档中出现的次数,用于后续相关性算分
3.位置(Posting),记录单词在文档中的分词位置(多个),用于做词语搜索(Phrase Query)
4.偏移(Offset),记录单词在文档的开始和结束位置,用于高亮显示
下面就是一组正排索引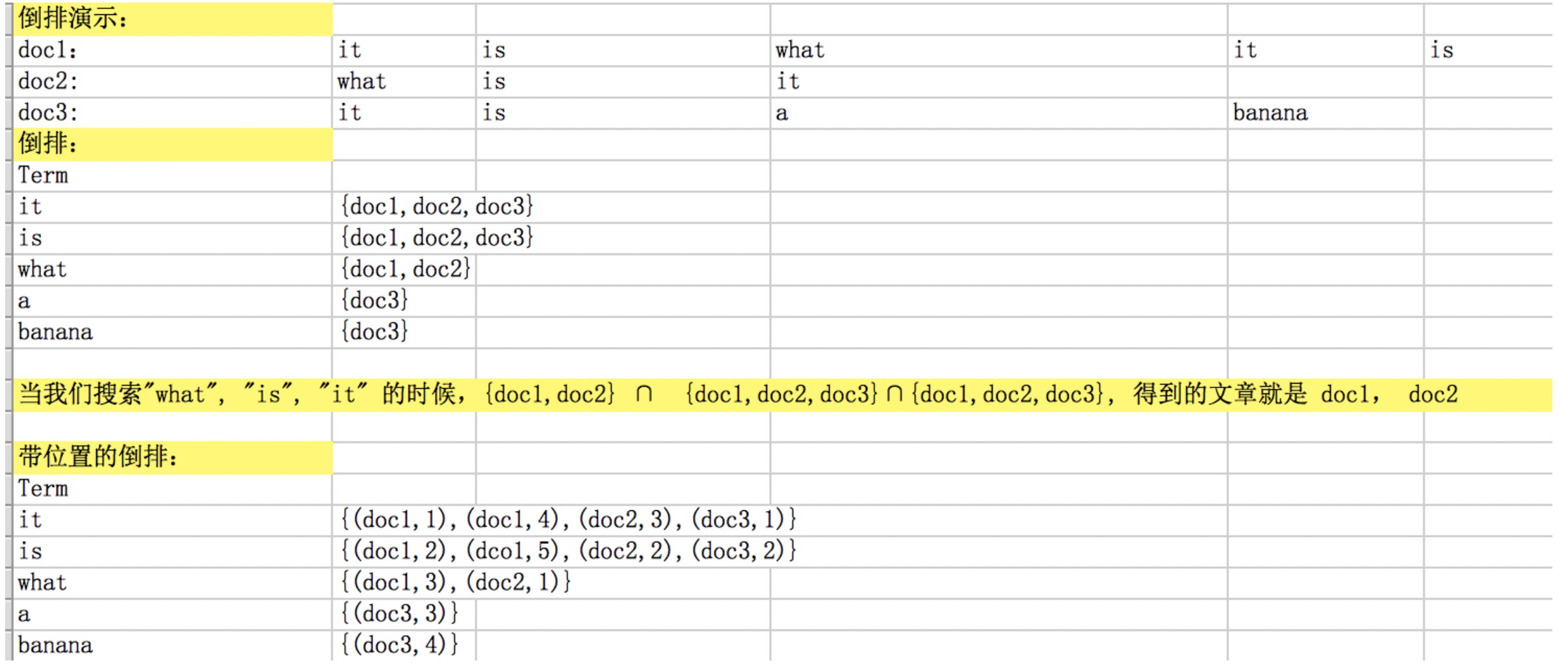
FST
lucene从4开始大量使用的数据结构是FST(Finite State Transducer)。FST有两个优点:1)空间占用小。通过对词典中单词前缀和后缀的重复利用,压缩了存储空间;2)查询速度快。O(len(str))的查询时间复杂度。

若有收获,就点个赞吧
0 人点赞
