一、简单介绍
Redis是完全开源免费、一个高性能的key-value数据库,包含多种数据结构、支持网络、基于内存、可选持久性的键值对存储数据库。
二、优缺点
- 优点
- 读写性能优异
- 支持数据持久化,支持AOF和RDB两种持久化方式
- 支持主从复制,主机会自动将数据同步到从机,可以进行读写分离。(默认主写,从读)
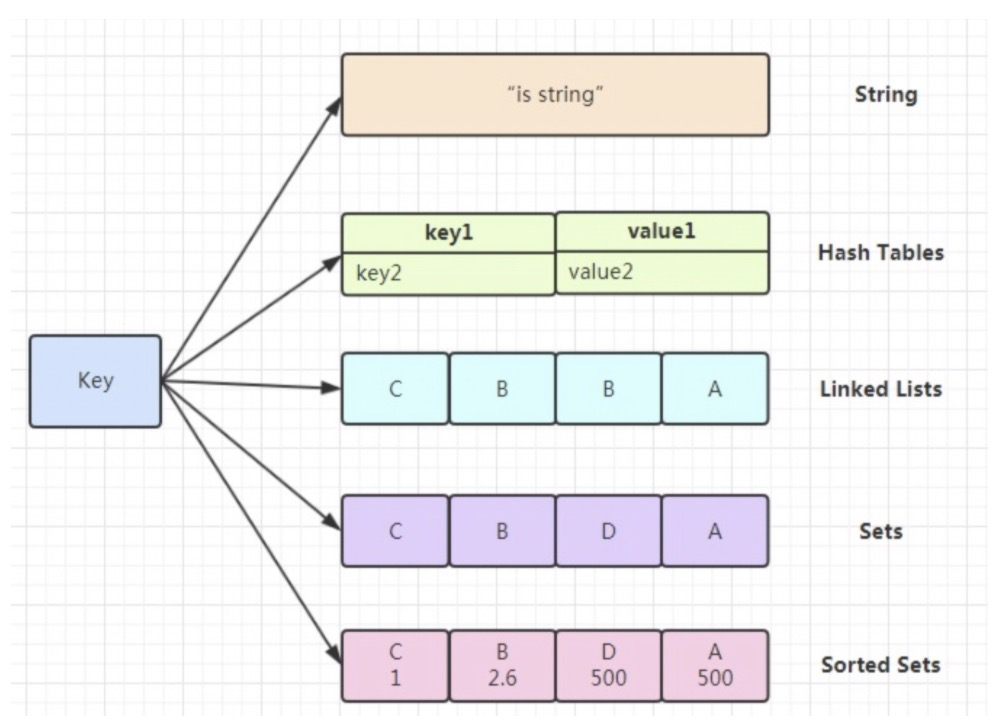
- 数据结构丰富:除了支持string类型的value外还支持hash、set、sortedset、list等数据结构
缺点
- 由于是内存数据库,所以单台机器存储的数据量跟机器本身的内存大小有关。
- redis的主从复制采用全量复制,复制过程中主机会fork出一个子进程对内存做一份快照,并将子进程的内存快照保存为文件发送给从机,这一过程需要确保主机有足够多的空余内存。若快照文件较大,对集群的服务能力会产生较大的影响,而且复制过程是在从机新加入集群或者从机和主机网络断开重连时都会进行,也就是网络波动都会造成主机和从机间的一次全量的数据复制,这对实际的系统运营造成了不小的麻烦。
- 修改配置文件,进行重启,将硬盘中的数据加载进内存,时间比较久。在这个过程中,redis不能提供服务。
三、简单使用
3.1 字符串 (String)
Redis 字符串数据类型的相关命令用于管理 redis 字符串值。’ set 成功 返回 字符串 ‘OK’,set失败返回 空(nil)
set key value [expiration EX seconds|PX milliseconds] [NX|XX] ```shell
设置
127.0.0.1:6699> set name wangchao ex 20
设置setNX SET if Not eXists(如果不存在则set)
127.0.0.1:6699> set name dog nx
设置 带超时时间的 setNX
127.0.0.1:6699> set name king ex 20 nx
设置setXX SET if eXists(如果存在则set)
127.0.0.1:6699> set name king ex 20 xx
- expire key seconds 设置过期时间- del key [key ...] 删除一个或者多个key```shell127.0.0.1:6699> del name1 name2 name3
mget key [key …] 查询多个key
127.0.0.1:6699> mget name1 name21) "king"2) "dog"
显示所有的key
127.0.0.1:6379> keys *
mset key value [key value …] 新建多个key,value
127.0.0.1:6699> mset name1 king name2 dog
-
3.2 列表(List)
Redis列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边) 一个列表最多可以包含 2^32 - 1 个元素 (4294967295, 每个列表超过40亿个元素)。
从左边或者右边进入list,一次可以进入多个 ```shell
lpush / rpush (key values…)
127.0.0.1:6699> lpush name 1 2 3 4 5
lpop / rpop key value
127.0.0.1:6699> lpop name “5” 127.0.0.1:6699> lpop name “4” 127.0.0.1:6699> lpop name “3” 127.0.0.1:6699> lpop name “2” 127.0.0.1:6699> lpop name “1”
lpop key value
127.0.0.1:6699> lpush name 1 2 3 4 127.0.0.1:6699> lpop name 2 1) “4” 2) “3”
- 查询list中的元素,索引从start开始到end结束的元素```shell127.0.0.1:6699> lpush name 1 2 3 4 5# 从0开始127.0.0.1:6699> lrange name 0 51) "5"2) "4"3) "3"4) "2"5) "1"# end 是 -1 时,显示所有元素127.0.0.1:6379> lrange name1 0 -1
查询list的长度
127.0.0.1:6699> llen name
linsert key BEFORE|AFTER pivot value 在list中某个元素的前/后插入一个元素
# 在 1 之前加个元素11127.0.0.1:6699> linsert name before 1 11
lset key index value 更新list指定位置的值 ```shell
更新name的2号位置的值为11
127.0.0.1:6699> lset name 2 11
下标 0.1.2.3
127.0.0.1:6699> lrange name 0 6 1) “5” 2) “4” 3) “11” 4) “2” 5) “11” 6) “1”
- lrem key count value 删除value```shell# 根据 count 的值移除列表中与value相等的元素# 移除 name 中 key是1的数据,一共1个127.0.0.1:6699> lrem name 1 1
3.3 哈希(Hash)
Redis hash 是一个 string 类型的 field(字段) 和 value(值) 的映射表,hash 特别适合用于存储对象。Redis 中每个 hash 可以存储 2^32 - 1 键值对(40多亿)。类似以java中的Map。
hset key field value 设置键值对
127.0.0.1:6699> hset person name king127.0.0.1:6699> hset person age 20
hget key field 获取键值对
127.0.0.1:6699> hget person name"dog"127.0.0.1:6699> hget person age"20"
hdel key field [field …] 删除数据
# 删除 name和age127.0.0.1:6699> hdel person name age
hmset key field value [field value …] 批量创建键值对
# 创建 <name,king> <age,20>127.0.0.1:6699> hmset person name king age 20
hmget key field [field …] 批量获取键值对
127.0.0.1:6699> hmget person name age1) "king"2) "20"
hkeys key 获取key中所有的field
127.0.0.1:6699> hkeys person1) "name"2) "age"
hvals key 获取key中所有的value
127.0.0.1:6699> hvals person1) "king"2) "20"
hexists key field 检查hash是否存在当前 field
127.0.0.1:6699> hexists person name(integer) 1
hlen key 获取当前key中所有的键值对数
127.0.0.1:6699> hlen person(integer) 2
使用场景:购物车
sadd key member [member …] 增加元素
# 不能重复创建127.0.0.1:6699> sadd address nanjing beijing shanghai
smembers key 查看元素
127.0.0.1:6699> smembers address1) "danyang"
sismember key member 判断元素是否存在
127.0.0.1:6699> sismember address danyang(integer) 1
srem key member [member …] 删除元素
127.0.0.1:6699> srem address danyang(integer) 1
scard key 获取元素中的个数
127.0.0.1:6699> scard address(integer) 3
127.0.0.1:6699> srandmember key [count]
- 随机获取set中count个元素(count>0无重复,count<0可能有重复),
- 如果只提供key则会随机返回一个value ```shell 127.0.0.1:6699> srandmember address 5 1) “beijing” 2) “nanjing” 3) “shanghai”
127.0.0.1:6699> srandmember address -1 1) “beijing”
127.0.0.1:6699> srandmember address -4 1) “nanjing” 2) “nanjing” 3) “nanjing” 4) “beijing”
127.0.0.1:6379> srandmember address “nanjing”
- smove source destination member 将源set的值移到目的set,一次只能移动一个```shell# 将key=address中的nanjing 移动到 address2中127.0.0.1:6699> smove address address2 nanjing
sdiff key [key …] 计算两个set的差,在第一个set而不在第二个set中
## address有,但是address2中没有127.0.0.1:6699> sdiff address address21) "beijing"2) "shanghai"
SDIFFSTORE destination key [key …] 将给定集合之间的差集存储在指定的集合中。如果指定的集合 key 已存在,则会被覆盖 ```shell 127.0.0.1:6699> SADD myset “hello” (integer) 1 127.0.0.1:6699> SADD myset “foo” (integer) 1 127.0.0.1:6699> SADD myset “bar” (integer) 1 127.0.0.1:6699> SADD myset2 “hello” (integer) 1 127.0.0.1:6699> SADD myset2 “world” (integer) 1
将myset和myset2的差集存储在destset中
127.0.0.1:6699> SDIFFSTORE destset myset myset2 (integer) 2 127.0.0.1:6699> SMEMBERS destset 1) “bar” 2) “foo”
- sinter key [key ...] 计算几个set之间的交集```shellmyset和myset2 的交集127.0.0.1:6699> sinter myset myset21) "hello"
- sinterstore destination key [key …] 将给定集合之间的交集存储在指定的集合中。如果指定的集合已经存在,则将其覆盖。
sunion key [key …] 计算并集
127.0.0.1:6699> sunion myset myset21) "hello"2) "bar"3) "world"4) "foo"
sunionstore destination key [key …] 将给定集合的并集存储在指定的集合 destination 中。如果 destination 已经存在,则将其覆盖。
使用场景
- 抽奖:spop key 1 随机弹出一个。
- 统计有多少人参与了:scard key
- 随机抽N个人:Srandmember key 2 随机抽2人,SPOP key 3 随机弹出2人
3.5 有序集合(Sorted set)
Redis 有序集合和集合一样也是 string 类型元素的集合,且不允许重复的成员。 不同的是每个元素都会关联一个 double 类型的分数。redis 正是通过分数来为集合中的成员进行从小到大的排序。 有序集合的成员是唯一的,但分数(score)却可以重复。 集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1)。 集合中最大的成员数为 2^32 - 1 (4294967295, 每个集合可存储40多亿个成员)。
zadd key [NX|XX] [CH] [INCR] score member [score member …]
- XX: 仅仅更新存在的成员,不添加新成员。
- NX: 不更新存在的成员。只添加新成员。
- CH: 修改返回值为发生变化的成员总数,原始是返回新添加成员的总数 (CH 是 changed 的意思)。更改的元素是新添加的成员,已经存在的成员更新分数。 所以在命令中指定的成员有相同的分数将不被计算在内。注:在通常情况下,ZADD返回值只计算新添加成员的数量。
- INCR: 当ZADD指定这个选项时,成员的操作就等同ZINCRBY命令,对成员的分数进行递增操作。
127.0.0.1:6699> zadd mysortedSet 1 "one"(integer) 1127.0.0.1:6699> zadd mysortedSet 1 "two"(integer) 1127.0.0.1:6699> zadd mysortedSet 2 "three"(integer) 1
zcard key 获取集合中元素个数
127.0.0.1:6699> zcard mysortedSet(integer) 3
zcount key min max 返回分数在min到max之间的元素个数
127.0.0.1:6699> zcount mysortedSet 0 2(integer) 3
zrangebyscore key min max [WITHSCORES] [LIMIT offset count] 返回分数在min到max之间的元素分页
# 返回mysortedSet中分数在[0,6]之间(闭区间) 的元素127.0.0.1:6699> zrangebyscore mysortedSet 1 2 withscores limit 0 31) "one"2) "1"3) "two"4) "1"5) "three"6) "2"
zrange key start stop [WITHSCORES] 查询start到stop区间的元素
# mysortedSet 从1开始,到2结束127.0.0.1:6699> zrange mysortedSet 1 21) "two"2) "three"127.0.0.1:6699> zrange mysortedSet 1 41) "two"2) "three"127.0.0.1:6699> zrange mysortedSet 0 11) "one"2) "two"127.0.0.1:6699> zrange mysortedSet 0 01) "one"
zscore key member 查询元素的分数
# 查看mysortedSet 中 one 的分数127.0.0.1:6699> zscore mysortedSet one"1"
zrem key member [member …] 移除集合中的元素
# 移除集合mysortedSet中的元素 one127.0.0.1:6699> zrem mysortedSet one(integer) 1
使用场景
- 热榜排名
四、持久化
4.1 RDB(快照)
是redis默认的持久化方案,在指定的时间间隔内,执行指定次数的写操作,则会将内存中的数据写入到磁盘中。即在指定目录下生成一个dump.rdb文件。Redis 重启会通过加载dump.rdb文件恢复数据。优缺点
1,适合大规模的数据恢复
2,数据的完整性和一致性不高,RDB可能在最后一次备份时宕机
3,备份时占用内存,因为Redis 在备份时会独立创建一个子进程,将数据写入到一个临时文件(此时内存中的数据是原来的两倍哦),最后再将临时文件替换之前的备份文件。所以Redis 的持久化和数据的恢复要选择在夜深人静的时候执行是比较合理的。4.2 AOF
Redis 默认不开启。它的出现是为了弥补RDB的不足(数据的不一致性),所以它采用日志的形式来记录每个写操作,并追加到文件中。Redis 重启的会根据日志文件的内容将写指令从前到后执行一次以完成数据的恢复工作。
当AOF文件的大小超过所设定的阈值时,Redis就会对AOF文件的内容压缩。Redis 会fork出一条新进程,读取内存中的数据,并重新写到一个临时文件中,最后替换旧的aof文件。优缺点
1,数据完整性和一致性更高
2,AOF记录数据内容多,文件大,数据恢复会越来越慢五、分布式锁
当多个进程不在同一个系统中,用分布式锁控制多个进程对资源的访问,通过setnx来实现,只有插入成功的客户端会返回1,其他的都返回0。通过返回值判断是否获得锁,通过删除该key来实现解锁,或者set ex设置key的过期时间
某个客户端要加锁。如果该客户端面对的是一个redis cluster集群,他首先会根据hash节点选择一台机器,只选择一台机器。
回顾字符串的 set nx 操作 https://www.yuque.com/wangchao-volk4/whmpo0/qdbyyb#FACjX ```java // 第一种 public static String setNXSilent(StringRedisTemplate redisTemplate, String cacheKey, int timeout) { try { return redisTemplate.execute((RedisCallback) redisConnection -> {
}); } catch (Exception e) { LOGGER.error(“SET If Not Exists error!,key:{}”, cacheKey); throw new RuntimeException(e); } }JedisCommands commands = (JedisCommands) redisConnection.getNativeConnection();return commands.set(cacheKey, "user", SetParams.setParams().nx().ex(timeout));
- 热榜排名
// 第二种 Boolean aBoolean = redisTemplate.opsForValue().setIfAbsent(“username”, “king”, 10, TimeUnit.SECONDS);
不能在事务中使用<a name="g77tH"></a># 六、Redis 集群的三种方式<a name="EqFmD"></a>## 6.1 主从复制1.从服务器连接主服务器,发送SYNC命令; <br />2.主服务器接收到SYNC命名后,开始执行BGSAVE命令生成RDB文件并使用缓冲区记录此后执行的所有写命令; <br />3.主服务器BGSAVE执行完后,向所有从服务器发送快照文件,并在发送期间继续记录被执行的写命令; <br />4.从服务器收到快照文件后丢弃所有旧数据,载入收到的快照; <br />5.主服务器快照发送完毕后开始向从服务器发送缓冲区中的写命令; <br />6.从服务器完成对快照的载入,开始接收命令请求,并执行来自主服务器缓冲区的写命令;(**从服务器初始化完成**)<br />7.主服务器每执行一个写命令就会向从服务器发送相同的写命令,从服务器接收并执行收到的写命令(**从服务器初始化完成后的操作)**<br />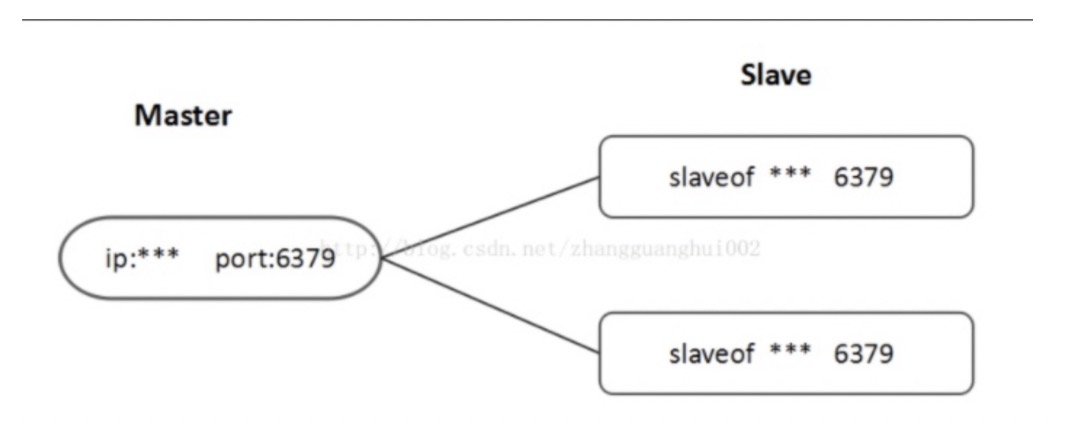<br />一个Master,两个Slave,Slave只能读不能写;当Slave与Master断开后需要重新slave of连接才可建立之前的主从关系;Master挂掉后,Master关系依然存在,Master重启即可恢复。<br />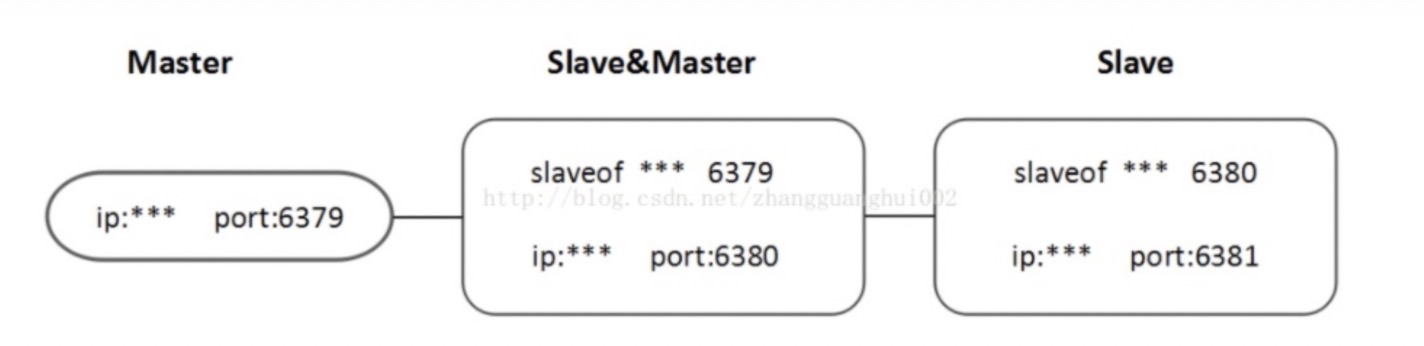<br />上一个Slave可以是下一个Slave的Master,Slave同样可以接收其他slaves的连接和同步请求,那么该slave作为了链条中下一个slave的Master,如此可以有效减轻Master的写压力。 当Master挂掉后,Slave可键入命令 slaveof no one使当前redis停止与其他Master redis数据同步,转成 Master redis。<a name="piXur"></a>### 主从同步策略主从刚刚连接的时候,进行全量同步;全同步结束后,进行增量同步。当然,如果有需要,slave 在任何时候都可以发起全量同步。redis 策略是,无论如何,首先会尝试进行增量同步,如不成功,要求从机进行全量同步。<a name="A7HF7"></a>### 优缺点1.读写分离减少redis的主库压力。<br />2.主库向从库同步的时候存在延时。<br />3.复制过程中主机会fork出一个子进程对内存做一份快照,并将子进程的内存快照保存为文件发送给从机,这一过程需要确保主机有足够多的空余内存。<a name="fNUek"></a>## 6.2 哨兵模式当主服务器中断服务后,可以将一个从服务器升级为主服务器,以便继续提供服务,但是这个过程需要人工手动来操作。 为此,Redis 2.8中提供了哨兵工具来实现自动化的系统监控和故障恢复功能。哨兵的作用就是监控Redis系统的运行状况。它的功能包括以下两个。<br />**(1)监控主服务器和从服务器是否正常运行。 **<br />**(2)主服务器出现故障时自动将从服务器转换为主服务器。**<br />配置哨兵监控一个系统时,只需要配置其监控主数据库即可,哨兵会自动发现所有复制该主数据库的从数据库,哨兵只用配置一个。```shellsentinel monitor mymaster 47.100.57.17 6379 1
优点
哨兵模式是基于主从模式的,所有主从的优点,哨兵模式都具有。主从可以自动切换,系统更健壮,可用性更高。
6.3 Redis-cluster集群
redis的哨兵模式基本已经可以实现高可用,读写分离 ,但是在这种模式下每台redis服务器都存储相同的数据,很浪费内存,所以在redis3.0上加入了cluster模式,实现的redis的分布式存储,也就是说每台redis节点上存储不同的内容。使用集群,只需要将每个数据库节点的cluster-enable配置打开即可。每个集群中至少需要三个主数据库才能正常运行。集群至少需要3主3从,且每个实例使用不同的配置文件,主从不用配置,集群会自己选。
七、其他
7.1 redis-cli使用
redis-cli -h host -p port -a password# 查看版本号redis -server -v

若有收获,就点个赞吧
0 人点赞
