- 一、ES 介绍
- 二、Mapping 详解
- 三、Analysis 分析
- 结果
- 查看es健康状况
- 查看主节点
- 查看所有索引
- ageAgg是自定义的名字
- 不看详细信息
- 五、分词器的使用
- https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.4.0/elasticsearch-analysis-ik-6.4.0.zip">/opt/apps/elasticsearch-6.4.0/bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.4.0/elasticsearch-analysis-ik-6.4.0.zip
- sudo /opt/apps/elasticsearch-6.4.0/bin/elasticsearch-plugin list
本文依据的ES版本是 elasticsearch-7.12.1 6.x和7.x存在些差异,本文只讲 7.x 的,6.x已过时。
一、ES 介绍
1、什么是ES
ElasticSearch基于全文搜索引擎库Lucene开发,提供了一套RESTful风格的API接口,天生支持分布式特性,易于扩展,不论是结构化还是非结构化数据,都可以提供近实时的搜索和分析功能。
2、搜索流程
通常一个搜索流程如下图所示,分为创建索引和查询索引两个流程,ElasticSearch搜索流程也基本类似。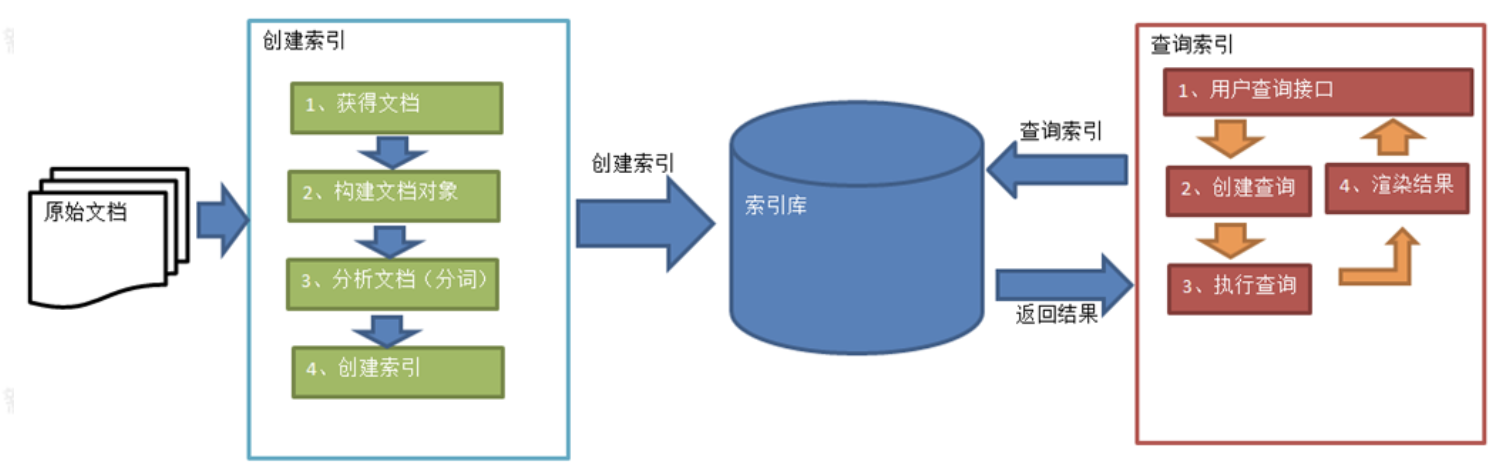
3、ES 核心概念
3.1 对比 mysql 数据库

- 关系型数据库中的数据库(DataBase),等价于ES中的索引(Index);
- 一个数据库下面有N张表(Table),等价于1个索引Index下面有N多类型(Type)——同一个索引中的多个Type的field不能冲突;
- 一个数据库表(Table)下的数据由多行(row)多列(column,属性)组成,等价于1个Type由多个文档(Document)和多Field组成;
- 在一个关系型数据库里面,schema 定义了表、每个表的字段,还有表和字段之间的关系。 与之对应的,在ES中:Mapping 定义索引下的 Type 的字段处理规则,即索引如何建立、索引类型、是否保存原始索引 JSON 文档、是否压缩原始 JSON 文档、是否需要分词处理、如何进行分词处理等;
- 在数据库中的增insert、删delete、改update、查search操作等价于ES中的增PUT/POST、删Delete、改_update、查GET;
3.2 Document(文档)
文档是索引中的基本单元,文档中采用JSON格式存储。一个文档包含多个Field字段,每个字段都有一个名称和值(键值对),Mapping映射中负责定义Field的类型及索引方式。文档类似于数据库表中的一条记录,记录中包含多个字段,ES文档中包含多个索引字段Field。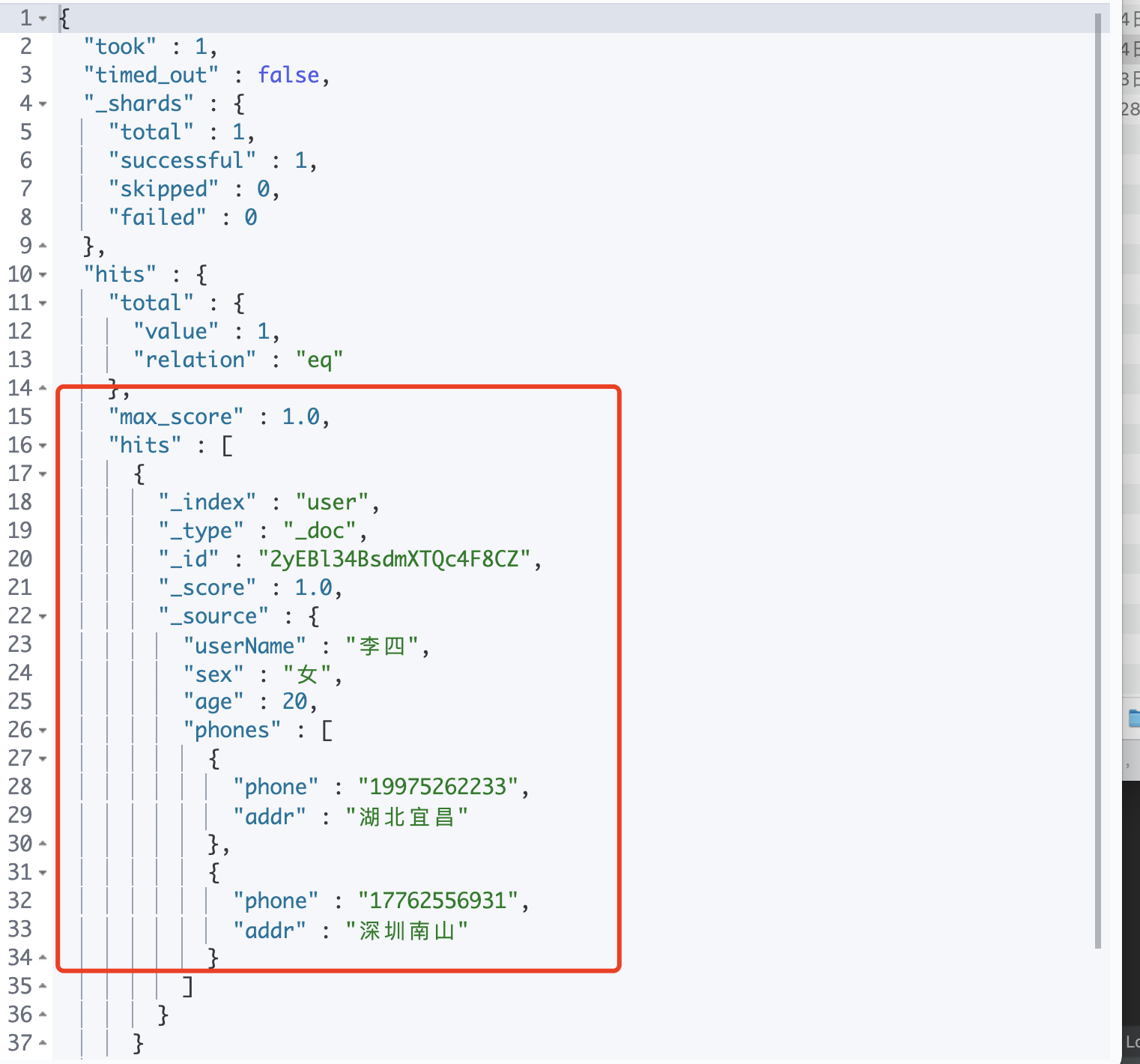
3.3 Index(索引)
索引是具有相似特征的文档集合,创建索引时,ES要求索引名称必须为英文小写。索引作为动词,表示创建索引这个操作,作为名词时,表示索引。ES中的索引可以类比成数据库中的库,每一个数据库都会有不同的表,表中会定义Scheme,而ES索引中可以包含不同的Type(ES6.X后只支持单个Type,ES7.X后将不支持Type),Type中会定义Mapping映射,用于指定不同字段的类型。
索引的创建,可以参照后面的 ES 常用操作。3.4 Type(类型)
Type即Mapping Type,类似于数据库中的schema,在ES6.X之前版本支持多个Type,但是不利于维护,数据稀疏问题严重,6.X开始只支持单个Type,7.x 已废弃,这里不在具体描述。7.x建议不支持type,8.x将永远不会支持。 为啥不支持type:是因为es是基于lucene开发的搜索引擎,而es中不同type下名称相同的filed最终在Lucene中的处理方式是一样的。
- 两个不同type下的两个useName,在es中统一索引下其实被认为是同一个filed,你必须在两个不同的type中定义相同的filed映射。否则,不同type中的相同字段名称就会在处理中出现冲突的情况,导致Lucene处理效率下降。
- 去掉type是为了提高Es处理数据的效率。
3.5 Cluster(集群)
集群由一个或者多个ES节点组成,整个集群负责存储数据、提供索引和搜索数据的功能。同一个网络中,具有相同cluster.name的节点会自动加入集群,因此不同环境的cluster.name需要进行区分,防止加入错误的集群。
- settings:索引库的设置
- number_of_shards:分片数量
- number_of_replicas:副本数量
索引内的数据被拆分为3份,即3个分片Shard,每个分片有一个备份数据——副本Replica。
PUT /user{"settings": {"number_of_shards": 3,"number_of_replicas": 1}}
集群是否正常运行可以通过健康状态反映,通过GET /_cat/health?v查看status,包括green、yellow、red三种状态。
green:每个索引的primary shard和replica shard都是active状态的;yellow:每个索引的primary shard都是active状态的,但是部分replica shard不是active状态,处于不可用的状态;red:不是所有索引的primary shard都是active状态的,部分索引有数据丢失了;3.6 Node(节点)
每一个ES实例都是集群中的一个节点,节点名称默认是一串随机的UUID字符串,集群中通过node.name 唯一标识一个节点,可以在elasticsearch.yml配置节点的名称。节点具体地负责索引数据的创建和存储,处理前端搜索请求。
根据节点的不同职责,可以划分为以下几种类型:Master-eligible node和Mater node:每个节点默认都是一个Master-eligible node,通过选主流程,会有一个节点成为Master节点,可以通过配置禁止节点参与选主流程。每个节点都会保存集群状态信息,但是只有Master节点才能修改集群状态信息;
- Data node:可以保存数据的节点,负责保存分片数据,在数据扩展上至关重要;
- Coordinating node:协调节点,每个节点默认都是协调节点,负责接受客户端请求,然后将请求路由到合适的节点上,最终将结果汇总,返回给客户端;
3.7 Shards(主分片)
单个节点,当存储大量文档时,很容易超过单机限制。为了解决这个问题,ElasticSearch采用分片来切割索引中的数据,在创建索引时可以指定分片数,默认为5分片。每个分片都是一个功能完备的Lucene索引,ES中的索引是一个逻辑索引。分片机制为ES提供了扩展性,多个分片提供了并行处理请求的能力,能有效提高系统吞吐量。3.8 Replicas(副本分片)
副本机制通过冗余分片数据(主分片和副本分片不允许分配在一个节点上),保证系统中某个节点宕机时,系统的高可用。同时,增加的副本分片,能够有效提高查询的性能和吞吐量。创建索引时,默认副本分片数为1。3.9 Near Realtime(近实时)
NRT 即 Near Realtime,ES 是一个近实时的搜索平台,从索引一个文档 到 文档能够被搜索出来,有短暂延迟,通常为1s。3.10 集群、节点、主分片和副本分片的关系
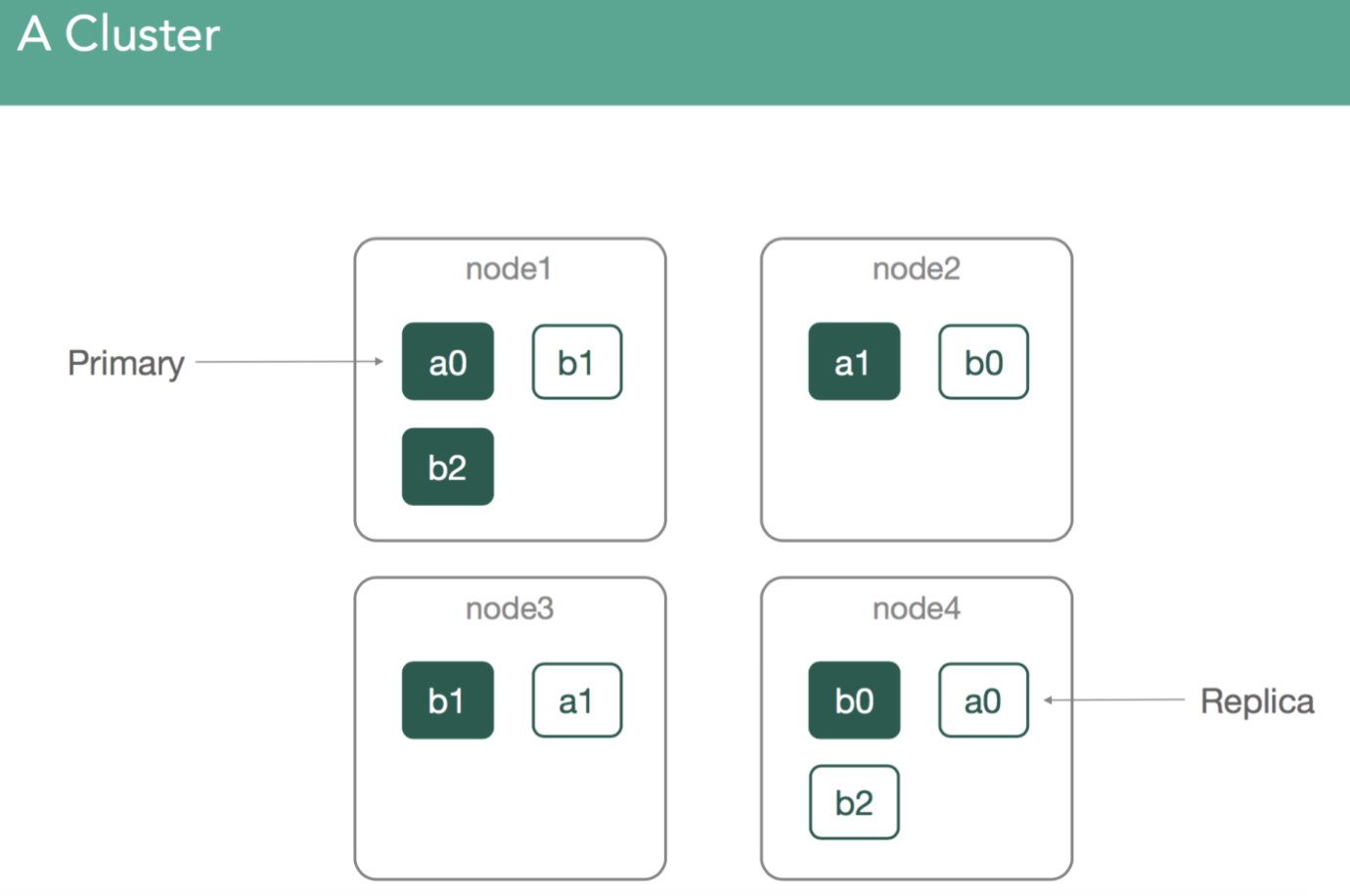
集群(Cluster)、节点(Node)、主分片(Primary Shard)和副本分片(Replica Shard)的关系如上图,上图集群由四个节点node1、node2、node3和node4组成,每一个节点中,分配了不同数量的分片,绿色节点为主分片(Primary Shard),白色节点为副本分片(Replica Shard)。
索引(Index)由一个或多个主分片组成,每个主分片负责存储部分索引数据。副本分片是主分片的拷贝,用于保证系统高可用,提升系统吞吐量。索引查询时,可以通过所有分片(包括主分片和副本分片)进行,而索引创建、删除、更新时,只能通过主分片进行,然后再同步到副本分片。为了保证高可用,主分片和副本分片不允许存储在同一个节点上,当主分片所在节点宕机时,副本分片会被提升为主分片,处理索引的写操作。3.11 Mapping
Mapping映射用于定义索引中的Document,以及其中包含了哪些字段Field,这些字段是如何被索引(Index)和存储的(Stored)。
每个索引中包含一个Mapping Type,它决定了文档是如何索引的。Mapping Type中包含了两种类型的字段,一种是元字段,一种是用户自定义字段。元字段(Meta Fields)用于描述文档自身的信息,包括_index, _type, _id(这三个属性唯一指向一条文档)和_source(存储文档原始数据,用于数据查询和更新)。
已经存在的字段类型不允许进行修改,因为改变现有字段数据类型,意味着已有数据全部要失效。通常,都是重新创建一个索引,然后reindex数据,或者增加新的字段替代原有字段。新版本中,允许给字段设置别名来进行更新查询操作,字段类型更新时,可以添加新的字段,然后修改mapping中的别名类型,指向新添加的字段。二、Mapping 详解
1、创建 Mapping
PUT /user{"mappings": {"properties": {"userName": {"type": "text","doc_values": true,"index": true,"analyzer": "ik_max_word","search_analyzer": "ik_max_word","fields": {"pinyin": {"type": "text","doc_values": true,"index": true,"analyzer": "ik_smart"},"fuzzy": {"type": "text","index": true,"analyzer": "ik_smart"},"raw":{"type":"keyword","index": true}}},"sex": {"type": "keyword","index": true,"doc_values": false},"age": {"type": "long"},"phones": {"type": "nested","properties": {"phone": {"type": "keyword"},"addr": {"type": "text","index":true}}}}}}
2、Mapping 参数描述
2.1 dynamic
dynamic参数——控制mapping动态添加字段。true:mapping映射之外的新字段会自动检测类型,并添加到索引中; false:mapping映射之外的新字段不会添加到索引中,但是会添加到source字段中存储; strict:如果检测到新字段,会抛出异常;
2.2 type
type参数——定义字段类型,包含了以下数据类型,其中text类型也被称为全文本类型,会进行分词处理,然后再建立倒排索引。keyword、long、integer等类型都是精确类型,查询时会精确匹配。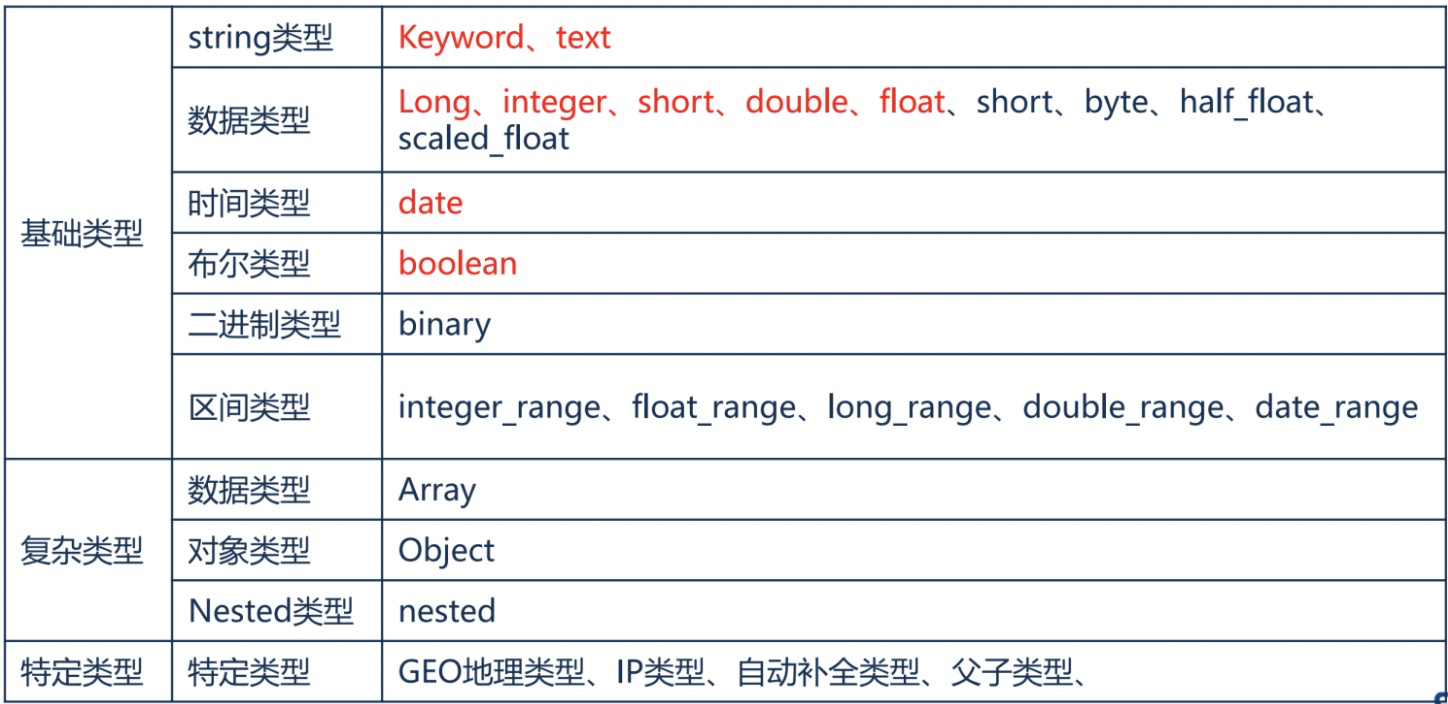
2.3 index
index参数——决定字段是否索引,默认为true,text类型字段使用倒排索引存储,数值和地理类型使用BKD Tree存储。
true:建立索引,可供用户搜索; false:不建立索引,无法搜索该字段;
倒排索引是ES中的核心数据结构,适合快速地进行全文搜索。一个倒排索引由文档中所有不重复词的列表构成,对于其中的每一个词,都有一个包含该词的文档列表与之对应。
如果我们想查询包含brown和dog的文档,只需要分别获取brown和dog对应的文档,然后取交集可以得到Doc_1。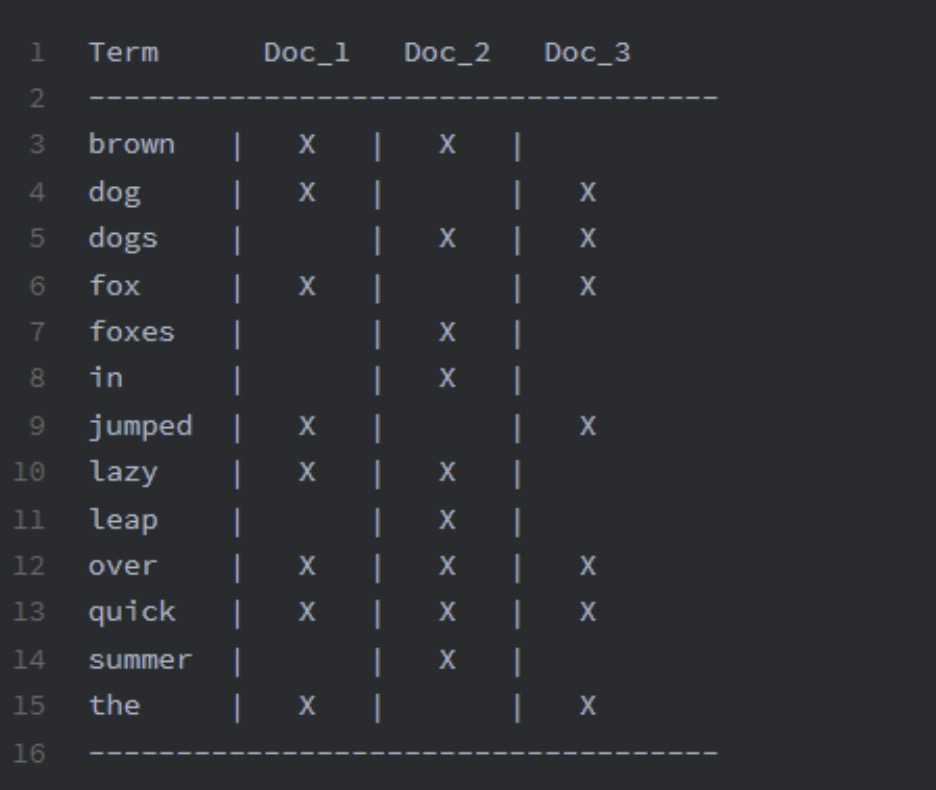
2.4 store
store参数——字段是否存储,默认为false,字段会存储在_source字段中。
true:存储该字段,通常只在不想从_source字段中获取无用数据时才开启; false:不存储该字段;
2.5 doc_values
doc_values参数——用于字段排序和聚合操作,默认为true,不支持text字段。
true:存储文档到词的映射;倒排索引(主要用于查询) false:正排索引(排序和聚合)
doc_values其实是Lucene在构建倒排索引时,会额外建立一个有序的正排索引(基于document => field value的映射列表)。另外,mapping中的字段我们确定以后不会基于这个字段做排序或者聚合,可以把它关掉,但是一定要非常明确你的这个操作,因为如果要重新打开doc_values,需要重建索引,这个在生产环境下还是要谨慎。

2.5.1 排序和聚合
排序和聚合的场景中,我们需要知道每个文档包含了哪些词,根据词来对文档进行排序。如果使用倒排索引结构,就需要遍历所有词到Doc的映射,浪费时间。
所以按照以下方式(正排索引)维护,会极大提升效率。(只看了三个文档)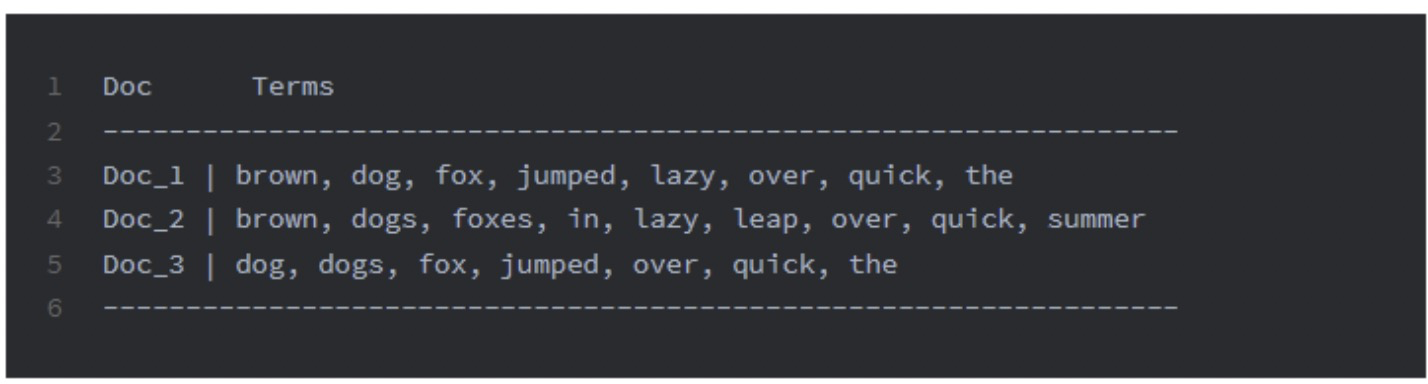
按照如下方式,就非常耗时。(看了3*13个文档)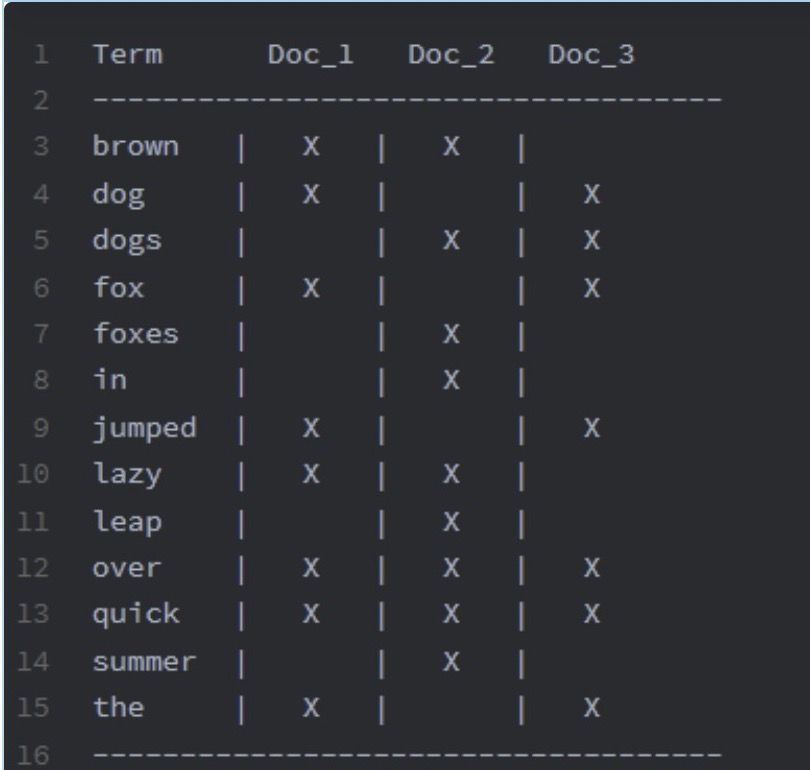
2.5.2 查询
如果是查询的话,即根据词去找文档,先找到词,再排序文档。
正排索引:13*3 次
倒排:最多13次
2.6 field
fields参数——同一个字段使用不同的方式进行索引,从而满足不同的使用场景。例如要对username字段进行排序,但是因为搜索时需要支持模糊查询,已经进行了ngram分词处理,直接对分词结果进行排序,毫无意义。这时可以通过fileds可以定义一个keyword类型,对原字段内容进行排序。
如下的 raw 字段。
"userName": {"type": "text", // 字段类型"doc_values": false, // true:存储doc到term数据结构,用于排序和聚合"index": true, // 是否索引,false:将不能用于查询"analyzer": "ik_max_word", // 指定分词分析器"search_analyzer": "ik_smart", // 指定查询分词分析器,不指定则使用analyzer"fields": { // 多字段类型,一般可以使这个字段具备多种查询方式(又想精确,又想模糊)"pinyin": {"type": "text","store": false,"analyzer": "pinyin_analyzer"},"fuzzy": {"type": "text","store": false,"analyzer": "ik_ngram_analyzer"},"raw": {"type": "keyword"}}
2.7 analyzer
analyzer参数——定义为text类型的字段,在建立索引之前,会使用analyzer进行分析,将一个字符串转换成一系列单词,然后建立这些单词到文档的倒排索引结构,在查询时,使用同样的分词方式进行查询。
2.8 search_analyzer
search_analyzer——指定询分词分析器,不指定则使用analyzer
2.9 fielddata
doc_values和fielddata就是用来给文档建立正排索引的。他俩一个很显著的区别是,前者的工作地盘主要在磁盘,而后者的工作地盘在内存。
fielddata默认不开启;doc_values默认是开启
| 维度 | doc_values | fielddata |
|---|---|---|
| 创建时间 | index时创建 | 使用时动态创建 |
| 创建位置 | 磁盘 | 内存(jvm heap) |
| 优点 | 不占用内存空间 | 不占用磁盘空间 |
| 缺点 | 索引速度稍低 | 文档很多时,动态创建开销比较大,而且占内存 |
| 字段类型 | keyword | text |
虽然速度稍慢,doc_values的优势还是非常明显的。一个很显著的点就是他不会随着文档的增多引起OOM问题。正如前面说的,doc_values在磁盘创建排序和聚合所需的正排索引。这样我们就避免了在生产环境给ES设置一个很大的HEAP_SIZE,也使得JVM的GC更加高效,这个又为其它的操作带来了间接的好处。 而且,随着ES版本的升级,对于doc_values的优化越来越好,索引的速度已经很接近fielddata了,而且我们知道硬盘的访问速度也是越来越快(比如SSD)。所以 doc_values 现在可以满足大部分场景,也是ES官方重点维护的对象。 所以我想说的是,doc values相比field data还是有很多优势的。所以 ES2.x 之后,支持聚合的字段属性默认都使用doc_values,而不是fielddata。
三、Analysis 分析
1、什么是 Analysis
Analysis is the process of converting text, like the body of any email, into tokens or terms which are added to the inverted index for searching. Analysis is performed by an analyzer which can be either a built-in analyzer or a
[custom](https://www.elastic.co/guide/en/elasticsearch/reference/6.4/analysis-custom-analyzer.html)analyzer defined per index. Analysis分析是指将文本(如邮件正文)转换成token或term的过程,token或term会被添加到倒排索引中用于搜索。分析是通过每个索引中定义的内置分析器Analyzer或用户自定义分析器实现。
Analysis分析过程是通过分析器Analyzer实现的,分析器Analyzer负责将文本解析成term,进而存储到倒排索引中。搜索时会采用同样的分析器,对原始的搜索文本进行分析,然后匹配到相应的文档。ES中提供了内置的分析器,也提供了自定义分析器的方式,可以对现有分析器中的功能进行组合。
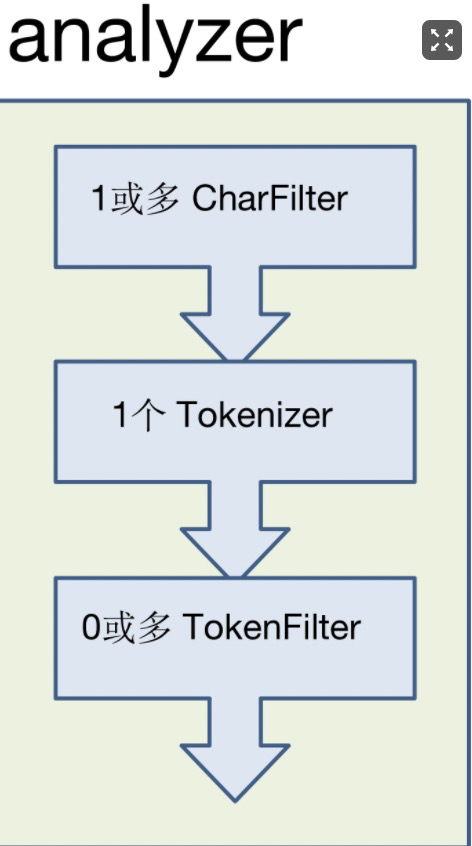
分析器analyzer包好了三个模块:
- charfilter:负责对原始的文本进行字符过滤,可以有多个,按照顺序执行;
- tokenizer:负责将过滤过的文本进行分词,得到一个个的语汇单元token,同时负责记录这些token在原文本中的位置。只能包含一个分词器tokenizer;
- filter:接受处理好的token,进行过滤转换处理,例如:小写转换、停用词过滤、转拼音等,最后得到一个个term。可以包含多个,按照顺序执行;
2、分词器安装
https://github.com/medcl/elasticsearch-analysis-ik/releases 下载ik
下载分词器到plugs文件下,一般下载ik分词器
Mac 下注意删除文件 rm .DS_Store
常用命令
进入bin目录下 elasticsearch-plugin list
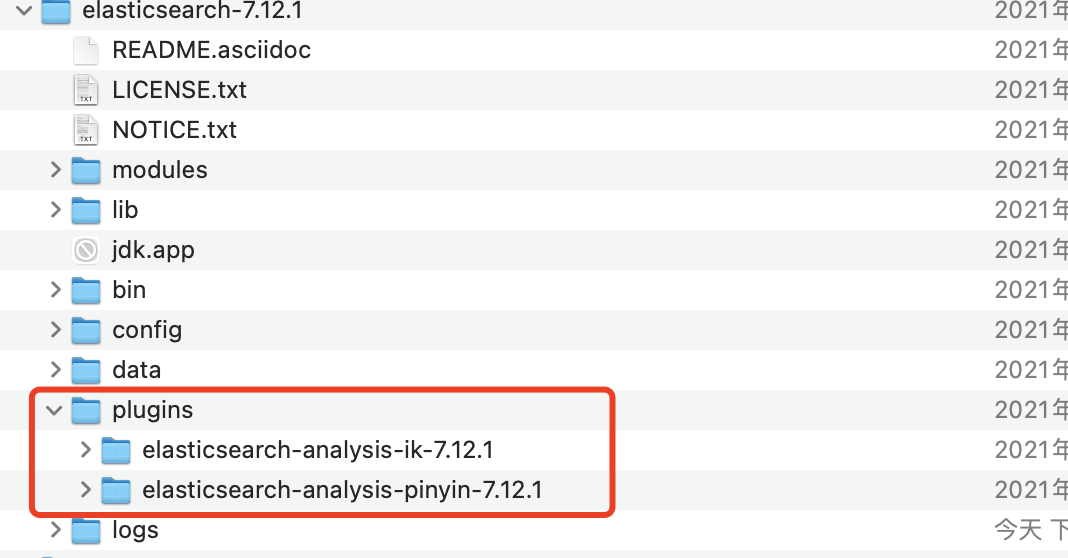
3、常用的分词器
2.1 Standard 分词器
standard分析器是ES的默认分析器,根据字符边界(英文根据空格,汉字根据单字)拆分,对于类似英语的语言效果较好,对汉语分词效果比较差,测试效果如下:
POST user/_analyze{"analyzer": "standard","text": ["宝马X5 2018"]}// 结果{"tokens" : [{"token" : "宝","start_offset" : 0,"end_offset" : 1,"type" : "<IDEOGRAPHIC>","position" : 0},{"token" : "马","start_offset" : 1,"end_offset" : 2,"type" : "<IDEOGRAPHIC>","position" : 1},{"token" : "x5","start_offset" : 2,"end_offset" : 4,"type" : "<ALPHANUM>","position" : 2},{"token" : "2018","start_offset" : 5,"end_offset" : 9,"type" : "<NUM>","position" : 3}]}
2.2 IK 分词器
IK分词器是一款著名的中文分词器,用户可以配置词库来达到很好的分词效果,ES的IK插件提供了 ik_smart 和ik_max_word 分析器,同时也提供了 ik_smart 和 ik_max_word的分词器Tokenizer,用户可以引用,然后自定义自己的Analyzer分析器。
- ik_smart分析器效果: ```json POST part/_analyze { “analyzer”: “ik_smart”, “text”: [“宝马X5 2018”] }
//结果 { “tokens” : [ { “token” : “宝马”, “start_offset” : 0, “end_offset” : 2, “type” : “CN_WORD”, “position” : 0 }, { “token” : “x5”, “start_offset” : 2, “end_offset” : 4, “type” : “LETTER”, “position” : 1 }, { “token” : “2018”, “start_offset” : 5, “end_offset” : 9, “type” : “ARABIC”, “position” : 2 } ] }
- ik_max_word分析器效果:```jsonPOST part/_analyze{"analyzer": "ik_max_word","text": ["宝马X5 2018"]}//结果{"tokens" : [{"token" : "宝马","start_offset" : 0,"end_offset" : 2,"type" : "CN_WORD","position" : 0},{"token" : "马","start_offset" : 1,"end_offset" : 2,"type" : "CN_WORD","position" : 1},{"token" : "x5","start_offset" : 2,"end_offset" : 4,"type" : "LETTER","position" : 2},{"token" : "x","start_offset" : 2,"end_offset" : 3,"type" : "ENGLISH","position" : 3},{"token" : "5","start_offset" : 3,"end_offset" : 4,"type" : "CN_WORD","position" : 4},{"token" : "2018","start_offset" : 5,"end_offset" : 9,"type" : "ARABIC","position" : 5},{"token" : "0","start_offset" : 6,"end_offset" : 7,"type" : "CN_WORD","position" : 6},{"token" : "8","start_offset" : 8,"end_offset" : 9,"type" : "CN_WORD","position" : 7}]}
2.3 pinyin 分词器
pinyin分析器插件提供了 pinyin分析器、pinyin 分词器以及一个语汇单元过滤器token-filterpinyin。
pinyin分析器效果如下:
POST part/_analyze{"analyzer": "pinyin","text": ["宝马"]}//结果{"tokens" : [{"token" : "bao","start_offset" : 0,"end_offset" : 0,"type" : "word","position" : 0},{"token" : "ma","start_offset" : 0,"end_offset" : 0,"type" : "word","position" : 1},{"token" : "bm","start_offset" : 0,"end_offset" : 0,"type" : "word","position" : 1}]}
2.4 自定义分词器
实际使用中,对于分词的场景多种多样,有的需要使用拼音分词品牌,有的需要使用ik中文分词匹配,有的字段需要实现类似于like的模糊搜索,所以我们需要自定义分析器来满足各种场景。
如下的语句中,定义了三个自定义分析器:
- pinyin_analyzer——使用ik_smart分词,然后转换成拼音,包含首字母拼音和全拼;
- ngram_analyzer——使用ngram分词,然后进行小写转化;
- ik_ngram_analyzer——先使用ik_smart分词,然后再进行ngram分词,然后进行小写转换;
PUT part{"settings": {"index": {"translog": {"sync_interval": "5s","durability": "async"},"refresh_interval": "5s","analysis": {"analyzer": {"pinyin_analyzer": {"tokenizer": "ik_smart","filter": ["pinyin_filter"]},"ngram_analyzer": {"tokenizer": "ngram_tokenizer","filter": ["lowercase"]},"ik_ngram_analyzer": {"tokenizer": "ik_smart","filter": ["ngram_filter","lowercase"]}},"tokenizer": {"ngram_tokenizer": {"type": "ngram","min_gram": 1,"max_gram": 25,"token_chars": ["letter","digit","punctuation"]},"edge_ngram_tokenizer": {"type": "edge_ngram","min_gram": 1,"max_gram": 25,"token_chars": ["letter","digit","punctuation"]}},"filter": {"pinyin_filter": {"type": "pinyin","keep_first_letter": true,"keep_full_pinyin": true,"keep_joined_full_pinyin": true,"keep_none_chinese_in_joined_full_pinyin": true,"limit_first_letter_length": 50,"lowercase": true,"remove_duplicated_term": true},"ngram_filter": {"type": "nGram","min_gram": 1,"max_gram": 25}}}}}}
4、自定义分词器
基于 IK
- 首先安装nginx,在 /mydata/nginx/html/es 里创建一个文本 ```java vim fenci.txt
写入两行,这两个词不会被分词
王超 老罗
- 进入es配置文件/mydata/es/plugins/ik/config 编辑文件```javavim IKAnalyzer.cfg.xml
- 效果 ```json POST _analyze { “analyzer”: “ik_smart”, “text”: “王超” }
结果
{ “tokens” : [ { “token” : “王超”, “start_offset” : 0, “end_offset” : 2, “type” : “CN_WORD”, “position” : 0 } ] }
<a name="MueNB"></a># 四、ES 常用操作<a name="Dtr87"></a>## 1、查看集群信息
查看所有节点 GET /_cat/nodes?v
查看es健康状况
GET /_cat/health?v
查看主节点
GET /_cat/master?v
查看所有索引
GET /_cat/indices?v
// 删除索引 delete user
<a name="lg0e0"></a>## 2、索引操作- 删除索引```jsondelete user
- 别名操作
```json
// 创建别名
POST /_aliases
{
“actions”: [
{
} ] }"add": {"index": "user","alias": "user_alias"}
// 删除别名 POST /_aliases { “actions”: [ { “remove”: { “index”: “user”, “alias”: “user_alias” } } ] }
// 重新命名别的别名 { “actions”: [ {“remove”: {“index”: “user”, “alias”: “user_alias”}}, {“add”: {“index”:”user”, “alias”: “alias2”}} ] }’
// 将多个index赋予一个别名 这样只能查询操作,无法进行写操作,因为不知道写哪个index { “actions”: [ {“add”: {“index”: “test1”, “alias”:”alias1”}}, {“add”: {“index”: “test2”, “alias”:”alias1”}} ] }
- 修改索引```json// 增加字段PUT /user/_mapping{"properties": {"school": {"type": "text","index": false}}}
- 迁移数据
POST _reindex{"source": {"index": "user"},"dest": {"index": "person"}}
3、添加\更新文档
2.1 PUT 操作
1、正常添加/更新
添加文档到索引,PUT操作为创建文档,默认操作类似于put-if-absent,不存在时则创建,存在时则更新(文档覆盖更新),PUT操作需要指定文档Id ,格式如下 ```json PUT /user/_doc/1 { “id”: 3, “username”: “关1羽”, “birthday”: “2000-01-01 00:00:00”, “birthdayTimestamp”: 21313131231131, “gender”: 1, “address”: “南京” }
// 第一次返回结果 { “_index” : “user”, “_type” : “_doc”, “_id” : “2”, “_version” : 1, “result” : “created”, “_shards” : { “total” : 2, “successful” : 1, “failed” : 0 }, “_seq_no” : 2, “_primary_term” : 1 }
// 第二次返回结果 { “_index” : “user”, “_type” : “_doc”, “_id” : “2”, “_version” : 2, “result” : “updated”, “_shards” : { “total” : 2, “successful” : 1, “failed” : 0 }, “_seq_no” : 3, “_primary_term” : 1 }
请求里面的1 指的是 文档的Id,不是业务上的Id,不过一般也可以指定为业务id<br /><a name="Z7dZe"></a>#### 2、如果想实现只创建文档,存在了不覆盖更新,可以使用op_type=create参数进行控制,已存在文档则会报错。```jsonPUT /user/_doc/2?op_type=create{"id": 3,"username": "关1羽","birthday": "2000-01-01 00:00:00","birthdayTimestamp": 21313131231131,"gender": 1,"address": "南京"}// 或PUT /user/_doc/2/_create{"id": 3,"username": "关1羽","birthday": "2000-01-01 00:00:00","birthdayTimestamp": 21313131231131,"gender": 1,"address": "南京"}
3、乐观锁
注意:乐观锁 _seq_no参数的使用:
场景:A和B同时发送更新请求,B请求先到达es并修改了数据例如:a=1—>a=2;A后到达,A的本意是将a=1—>a=3,但此时a已经被B修改了。这时就会用到 seq_no这参数。老板用version参数。 使用方式:更新的时候携带?if_seq_no=0&if_primary_term=1;满足这个条件才进行修改。
// 如果 seq_no=23,则更新PUT /user/_doc/2?if_seq_no=23&if_primary_term=1{"id": 3,"username": "关1羽","birthday": "2000-01-01 00:00:00","birthdayTimestamp": 21313131231131,"gender": 1,"address": "南京"}
2.2 POST 操作
支持存在则更新(覆盖原文档)、不存在则新建、也支持局部更新、更新也支持乐观锁
上面的示例中,我们都指定了index、type和id,其实ES也可以实现自动生成文档ID的操作(使用POST请求),但是实际中会使用业务ID:
1、新增生产随机Id
// 新增 生产随机IdPOST /user/_doc{"id": 3,"username": "关1羽","birthday": "2000-01-01 00:00:00","birthdayTimestamp": 21313131231131,"gender": 1,"address": "南京"}// 返回结果{"_index" : "user","_type" : "_doc",// 自动生产的Id"_id" : "6SF6mX4BsdmXTQc4csA2","_version" : 1,"result" : "created","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 4,"_primary_term" : 1}
2、新增指定Id,存在则更新、不存在则新建
// 指定Id是344POST /user/_doc/344{"id": 9,"username": "关1羽","birthday": "2000-01-01 00:00:00","birthdayTimestamp": 21313131231131,"gender": 1,"address": "南京"}// 乐观锁POST /user/_doc/344?if_seq_no=33&if_primary_term=1{"id": 9,"username": "关1羽","birthday": "2000-01-01 00:00:00","birthdayTimestamp": 21313131231131,"gender": 1,"address": "南京"}
3、局部更新
Elasticsearch的document是基于不可变模式设计的,所有的document更新,其实都创建了一个新的document出来,再把老的document标记为deleted,增量更新也不例外,只是GET全量document数据,整合新的document,替换老的document这三步操作全在一个shard里完成,毫秒级完成。 retry_on_conflict=3
只更新344中的id字段和username字段POST /user/_update/344?retry_on_conflict=3{"doc": {"id": 3,"username": "关11羽"}}// 乐观锁POST /user/_update/344?if_seq_no=32&if_primary_term=1{"doc": {"id": 3,"username": "关11羽"}}
关键字:retry_on_conflict
1 数据库的 update 在修改这条数据的的过程中(这个过程指的是 数据库执行update 到 事务提交的过程中 )为这条数据加上 写锁,阻止 别的事务 对锁定数据的修改,请求后一个修改事务的线程阻塞,直到前一个事务的完成,所以针对这条数据的 2 个修改 是一个一个来的。所以 数据库的 update t1 set a = a+1; 这样的操作 不会导致 a数据的 丢失,因为前一个事务 执行的时候回阻塞后一个事务提交数据。 但是 如果先查询出a=1, 然后 a = 1(这个1 是查询到的 a)+1 ;这样的操作会 丢失 a ,因为 a 两个事务查询的a 可能 会被修改了。 2, es 的 全部修改,如果没有带上 version的 时候,直接替换原来的 文档,没有查询的过程。多线程操作,不区分执行的先后顺序。 但是带上version的时候 version 表示先后顺序。先执行成功的为主,后来的不合法被舍弃(抛出异常)。 3, es 部分修改的时候,修改请求到达 es 的 时候,es会在内部查询 一下原来的文档,然后执行 ,部分更新,注意一下,这时候 是 es 并不阻止 别的线程修改 这条数据,可能这个es 内部的查询 同是有多个( 这个阶段叫做 retrieve ),检索完成 记录一下 这时的 version, 和传过来的新的数据一起生成新的文档,然后把旧的文档改成假删除(这个过程叫做 reindex),这时候会修改 set version=version and version = version,如果另一个 线程做着同样的操作并且慢了 一点点,重建 索引这步 就会出异常。这时候 es会 重 复检索和 重构索引的过程 知道 正常完成 或者 重试次数大于 retry_on_conflict 抛出异常。 总结:数据库 拒绝 第二个事务来修改 已经被修改但是未被提交的数据(事务未提交)。 es 的全更新 不会有自动检索 的过程,直接替换,可以通过version 控制并发。部分更新有自动检索的过程 ,并发修改冲突会重新检索,带上version然后重新新构建索引 重试 retry_on_conflict 次后会抛出异常,并且 也可以通过 version 控制(retry_on_conflict 默认0 次 相当于 自动带上了version,但是不完成等价 , 因为 version 读的 时机 不同,有些情况可能 不同的结果,主要肯写法 和 业务 情景 比如 a = a+1 就没影响,但是 a = 1+1 就有影响,可以细细体会 一下,挺有意思的 )。
4、有时候想要实现upsert操作——存在则更新部分字段,不存在则插入,则需要添加doc_as_upsert参数:
POST /user/_update/344{"doc": {"id": 3,"username": "关11羽"},"doc_as_upsert" : true}
3、批量新建更新
index:既可以新增,也可以更新(全部更新)
create:只能新增
update:只能更新
delete:删除
# 必须使用这种格式(不要格式化json,要缩起来)POST /user/_bulk{"index":{"_id":1,"retry_on_conflict":3}}{"id":1,"username":"关1羽","birthday":"2000-01-01 00:00:00","birthdayTimestamp":21313131231131,"gender":1,"address":"南京"}{"index":{"_id":1,"retry_on_conflict":3}}{"id":1,"username":"关1羽","birthday":"2000-01-01 00:00:00","birthdayTimestamp":21313131231131,"gender":1,"address":"南京"}{"index":{"_id":1,"retry_on_conflict":3}}{"id":1,"username":"关1羽","birthday":"2000-01-01 00:00:00","birthdayTimestamp":21313131231131,"gender":1,"address":"南京"}
# 也可以将索引写在结构体中POST /_bulk{"delete":{"_index":"website","_type":"blog","_id":"123"}}{"create":{"_index":"website","_type":"blog","_id":"123"}}{"title":"my first blog post"}{"index":{"_index":"website","_type":"blog"}}{"title":"my first blog post"}{"update":{"_index":"website","_type":"blog","_id":"123"}}{"doc":{"title":"my updated blog post"}}## 返回结果{"took" : 288,"errors" : false,"items" : [{"delete" : {"_index" : "website","_type" : "blog","_id" : "123","_version" : 1,"result" : "not_found","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 0,"_primary_term" : 1,"status" : 404}},{"create" : {"_index" : "website","_type" : "blog","_id" : "123","_version" : 2,"result" : "created","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 1,"_primary_term" : 1,"status" : 201}},{"index" : {"_index" : "website","_type" : "blog","_id" : "0zthbHYBZ2cmk--VBmpo","_version" : 1,"result" : "created","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 2,"_primary_term" : 1,"status" : 201}},{"update" : {"_index" : "website","_type" : "blog","_id" : "123","_version" : 3,"result" : "updated","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 3,"_primary_term" : 1,"status" : 200}}]}
4、检索
4.1 GET
get api用于根据index、type、id查询某个文档,使用较少:
GET /user/_doc/344// 结果{"_index" : "user","_type" : "_doc","_id" : "344","_version" : 5,"_seq_no" : 35,"_primary_term" : 1,"found" : true,"_source" : {"id" : 3,"username" : "关11羽","birthday" : "2000-01-01 00:00:00","birthdayTimestamp" : 21313131231131,"gender" : 1,"address" : "南京"}}
4.2 Search
4.2.1 match
全文检索,按照评分进行排序,对检索条件进行分词匹配
Match_phrase:短语匹配,必须每个索引都命中同时 索引位置相邻才返回
GET /user/_search{"query": {"match": {"userName.fuzzy": "李四"}}}GET /user/_search{"query": {"match": {"userName": "四"}}}GET user/_search{"query": {"match_phrase": {// 只要address字段里包含789 Madison Street,就会返回结果"address": "789 Madison Street"}}}
查询 nested 类型
详细请看。。。
// 创建数据POST /user/_doc{"userName":"李四","sex":"女","age":20,"phones": [{"phone": "1231231231","addr": "没用到"},{"phone": "121111231","addr": "湖北"}]}// 查询,需要指定 nested,不然会出错GET /user/_search{"query": {"nested": {"path": "phones","query": {"match": {"phones.addr": "没用到"}}}}}
4.2.2 muti_match
多字段匹配
详细介绍,参考 。。。。。
GET user/_search{"query": {"multi_match": {"query": "女","fields": ["userName","sex"]}}}# 综合参数"multi_match": {"query": "小明","fields": ["name", "name.pinyin", "name.fuzzy"],"type": "cross_fields","operator": "and","analyzer": "ik_smart"}
4.2.3 bool
复杂查询,整合多个查询条件
以下几个会贡献相关性得分
Must:必须满足
Must_not:必须不满足
should:可以满足
GET /user/_search{"query": {"bool": {"must": [{"match": {"userName": "王五"}},{"range": {"age": {"gte": 27,"lte": 31}}}],"must_not": [{"match": {"userName": "王五"}}]}}}
4.2.4 filter
filter充分利用了倒排索引,内部还会进行缓存处理,因此查询效率得到了一定的提升,能够实现几十毫秒返回。
不会贡献相关性得分
GET /user/_search{"query": {"bool": {"filter": [{"range": {"age": {"gte": 27,"lte": 31}}}]}}}// filter+boolGET /user/_search{"query": {"bool": {"filter": [{"bool": {"must": [{"match": {"userName": "王五"}},{"range": {"age": {"gte": 27,"lte": 31}}}]}}]}}}
4.2.5 term
适用于精确查询,text类型的不要用term查询,text类型的会被分词。
GET /user/_search{"query": {"term": {"age": {"value": "30"}}}}
4.2.5 must
这里使用了exist和missing
- exist 包含某个字段
- missing 不包含某个字段
1、查询某个公司下有手机号的数据
POST /test/_search?rest_total_hits_as_int=true{"query": {"bool": {## 某个公司下存在手机号"must": [{"term": {"companyId": {"value": "1231231"}}},## 存在手机号{"exists": {"field": "phone"}}]}},"sort": [{"infoId": {"order": "desc"}}],"size": 1}// 不存在手机号应该怎么查呢?"must_not": [{"exists": {"field": "phone"}}]
4.2.6 must_not
不包含某个条件
1、例如:公司Id不等于xxxx的数据
POST /test/_search?rest_total_hits_as_int=true{"query": {"bool": {## 不等于"must_not": [{"term": {"companyId": {"value": "12313"}}}]}},"sort": [{"Id": {"order": "desc"}}],"size": 1}
2、查询存在address字段,但是address不等于chain的信息
POST user_alias/_search{"query": {"bool": {"must": [{"exists": {"field": "address"}}],"must_not": [{"term": {"address": {"value": "china"}}}]}}}
5、聚合
注意:使用聚合的字段必须doc_value:true, 使用term的话,字段类型必须为keyword
aggregations(执行聚合),类似于group by
- 检索addres中包含mill的所有人的年龄分布以及平均年龄、平均薪资,但不显示这些人的详情
```json
GET bank/_search
{
“query”: {
“match”: {
} }, “aggs”: {"address": "mill"
ageAgg是自定义的名字
“ageAgg”: {
}, “ageAvg”:{# 统计数量"terms": {"field": "age","size": 3}
}, “balanceAvg”:{"avg": {"field": "age"}
} },"avg": {"field": "balance"}
不看详细信息
“size”: 0 }
结果
{ “took” : 1, “timed_out” : false, “_shards” : { “total” : 1, “successful” : 1, “skipped” : 0, “failed” : 0 }, “hits” : { “total” : { “value” : 4, “relation” : “eq” }, “max_score” : null, “hits” : [ ] }, “aggregations” : { “ageAgg” : { “doc_count_error_upper_bound” : 0, “sum_other_doc_count” : 0, “buckets” : [ { “key” : 38, “doc_count” : 2 }, { “key” : 28, “doc_count” : 1 }, { “key” : 32, “doc_count” : 1 } ] }, “ageAvg” : { “value” : 34.0 }, “balanceAvg” : { “value” : 25208.0 } } }
- 按照年龄聚合,并且看这些年龄段人的平均薪资```jsonGET bank/_search{"query": {"match_all": {}},"aggs": {"ageAgg": {"terms": {"field": "age","size": 100},## 子聚合"aggs": {"ageAvg": {"avg": {"field": "age"}}}}},"size": 0}
- 查出所有年龄的分布,并且这些年龄段中m的平均薪资以及这个年龄段的总体平均薪资。
GET bank/_search{"query": {"match_all": {}},"aggs": {"ageAgg": {"terms": {"field": "age","size": 100},# 子聚合 求出性别聚合"aggs": {"genderAgg": {"terms": {"field": "gender.keyword","size": 10},## 子子聚合 求出性别下的薪资聚合"aggs": {"balanceAvg": {"avg": {"field": "balance"}}}},## 子聚合 求出年龄下的薪资聚合"ageBalanceAvg":{"avg": {"field": "balance"}}}}},"size": 0}
五、分词器的使用
1、分词器安装
命令安装
```shell 在线安装ik es插件 命令:/opt/apps/elasticsearch-6.4.0/bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.4.0/elasticsearch-analysis-ik-6.4.0.zip
查看插件安装列表
sudo /opt/apps/elasticsearch-6.4.0/bin/elasticsearch-plugin list
重启ES<a name="OeBqz"></a>##### 直接安装插件```shell# 安装插件到 elasticsearch 下的 plugins 文件夹下面unzip elasticsearch-analysis-ik-7.14.0.zip -d /usr/local/elasticsearch-7.14.0/plugins/
ES通过命令配置
PUT /user/{"settings" : {"analysis" : {"analyzer" : {"pinyin_analyzer" : {"tokenizer" : "my_pinyin"}},// 指定分词器"tokenizer" : {"my_pinyin" : {"type" : "pinyin","keep_separate_first_letter" : false,"keep_full_pinyin" : true,"keep_original" : true,"limit_first_letter_length" : 16,"lowercase" : true,"remove_duplicated_term" : true}}}},"mappings": {"properties": {"id": {"type": "keyword"},"username": {"type": "text","fields": {"fuzzy": {"type": "text","analyzer": "ik_smart"},"pinyin":{"type":"text","analyzer":"pinyin_analyzer"},"keyword":{"type":"keyword"}}},"birthday":{"type": "date","format": "yyyy-MM-dd HH:mm:ss","doc_values": false},"birthdayTimestamp":{"type": "long"},"gender":{"type": "integer"},"address":{"type": "text","analyzer": "ik_smart"}}}}

若有收获,就点个赞吧
0 人点赞
