- 1 基础
- 表示注释一行,注释内容不执行,仅作为解释说明使用;
print为Python中的输出函数;
双引号之间表示要打印的内容,实际上是一个字符串。 - 1.2 注释
- 1.3 输出与输入
- 1.4 数据类型概述
- 1.5 标识符
- 2 变量和常量
- 3 数字类型
- 从序列的元素中随机挑选一个元素
- —>1
- —>0
- —>e
- 产生一个1~100之间的随机数
- 随机产生[0,1)之间的数(浮点数)
- —>0.6100463969067899
- 将序列的所有元素随机排序
- —>[5, 3, 2, 4, 1]
- 随机生产一个实数,他在[3, 9]范围
- —>3.2690590821215757
- 5 字符串
- —>97
- —>A
- ignore忽略错误
- —>b’sunck is a good man\xe5\x87\xaf’
- —>
- 解码 注意:要与编码时的编码格式一致
- —>sunck is a good man鍑
- 6 布尔值与空值
- 7 列表
- 方法二
- 8 元组
- 9 字典
- tom 60
- lilei 70
- 0 tom
- 1 lilei
- set没有索引的
- print(s7[3])
- 11 迭代器
1 基础
1.1 程序执行
交互模式
调取“cmd”,输入“python”命令,直接输入代码。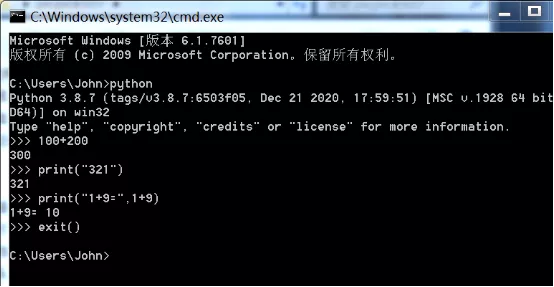
该模式下运行成功,首先应设置环境变量,保证python写入路径。
使用“exit()”命令退出交互模式。
命令行模式
1. 编写一个python程序
Python程序文件以.py后缀结尾,创建名为hello.py的文件。
# 输出print("你好,python!")#-->你好,python!
表示注释一行,注释内容不执行,仅作为解释说明使用;
print为Python中的输出函数;
双引号之间表示要打印的内容,实际上是一个字符串。
2. 调取python程序并执行
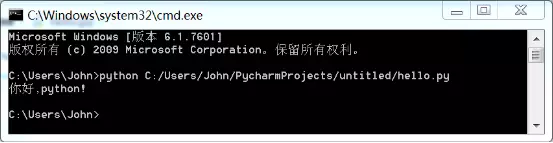
- 绝对路径
从根目录开始链接的路径,例如“C:\Users\John\Desktop\Python-1704\day01”。 - 相对路径
不从根目录开始链接的路径,如“John\Desktop\Python-1704\day01”。 - 其他
<dir>:查看当前目录下的所有文件<cd xxx>:跳转到指定目录,代码中xxx为路径。<cd ..:返回上一级目 录
1.2 注释
注释单行
# 注释内容
注释多行
- 方式一:’’’
'''注释内容'''
- 方式二:”””
"""注释内容"""
示例:
# 我是单行注释'''我是多行注释1我是多行注释1'''"""我是多行注释2我是多行注释2"""
其实注释是语句,只不过是字符串。注释错误的话也会无法执行,如:带“\”的注释语句。
1.3 输出与输入
输出print
打印到屏幕上一些信息,可以接受多个字符串,用逗号“,”隔开,遇到逗号“,”会输出一个空格。
示例1:
#打印到屏幕上一些信息#可以接受多个字符串,用逗号分隔,遇到逗号会输出一个空格print("hello,A!", "hello,B")print(18)print(10 + 8)print("10 + 8 =", 10+8)#-->hello,A! hello,B#-->18#-->18#-->10 + 8 = 18
示例2:
num = 1print("%2d" % (num))print("%-2d" % (num))print("%.2d" % (num))#--> 1#-->1#-->01
输入input
从外部获取变量的值,并存入变量中。input方法只能有一个参数。
#等待输入,输入的内容保存在age里age = input("请输入您的年龄:")print("age =", age)
1.4 数据类型概述
计算机顾名思义就是可以做数学计算的机器,因此,计算机程序理所当然地可以处理各种数值。但是,计算机能处理的远不止数值,还可以处理文本、图形、音频、视频、网页等各种各样的数据。不同的数据,需要定义不同的数据类型。
Python数据类型可以分为Number(数字)、String(字符串)、Boolean(布尔值)、None(空值)、list(列表)、tuple(元组)、dict(字典)、set(集合)。
1.5 标识符
标识符是一串字符串,但字符串未必是标识符。
命名规则
(1)只能由字母、数字、下划线组成;
(2)开头不能是数字;
(3)不能是Python的关键字;
(4)区分大小写;
(5)见名知意;
(6)遵循驼峰原则;
首单词的正常的,从第二个单词开始首字母大写。如:helloWorld。
Python关键字如下:
[‘False’, ‘None’, ‘True’, ‘and’, ‘as’, ‘assert’, ‘break’, ‘class’, ‘continue’, ‘def’, ‘del’, ‘elif’, ‘else’, ‘except’, ‘finally’, ‘for’, ‘from’, ‘global’, ‘if’, ‘import’, ‘in’, ‘is’, ‘lambda’, ‘nonlocal’, ‘not’, ‘or’, ‘pass’, ‘raise’, ‘return’, ‘try’, ‘while’, ‘with’, ‘yield’]
import keywordprint(keyword.kwlist)#-->['False', 'None', 'True', 'and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']
作用
给变量、函数等命名。
注意:在Python3中,非ASCII标识符也是允许的。
2 变量和常量
2.1 变量
程序可操作的存储区的名称,程序运行期间能改变的数据,每个变量都有特定的类型。
(1)变量的定义
变量名 = 初始值
(为了确定变量类型)
_02-_05. 变量与常量2、number(数字)1
(2)数据的存储
变量名 = 数据值
注意:变量在使用前必须先“定义”(即赋予变量一个值),否则会出现错误。
(3)删除变量
del 变量名
删除后变量无法引用。
(4)查看变量类型
type (变量)
(5)查看某变量是否某类型
isinstance (变量, 类型)
(6)查看变量地址
id (变量)
2.2 常量
程序运行期间不能改变的数据。
示例:
age = 18age = "good"#del age#print(age)#-->NameError: name 'age' is not definedprint("age = ", age)#-->age = good#查看变量的类型print(type(age))#--><class 'str'>print(isinstance(age, str))#-->True#查看变量的地址print(id(age))#-->37090352
3 数字类型
3.1 概述
分为整数、浮点数(小数)、复数。
1. 整数
Python可以处理任意大小的整数(包括负整数),不区分short、long等类型,在程序中表示和数学的写法一样。
num1 = 10# 查看变量num1的地址print(id(num1))num2 = num1print(id(num2))num1=18print(id(num1))#-->8791511271376#-->8791511271376#-->8791511271632# 连续定义多个变量num3 = num4 = num5 = 1print(num3, num4, num5)#-->1 1 1#交互式赋值定义变量num6, num7 = 26, 13print(num6, num7)#-->26 13
- num2=num1,num2和num1的地址一样。
- num1重新赋值后,地址变了。
2. 浮点数
浮点型由整数部分与小数部分组成,浮点数运算可能会有四舍五入的误差。
f1 = 1.1f2 = 2.2f3 = f1 + f2print(f3)#-->3.3000000000000003
3. 复数
由实数部分和虚数部分构成。
_02-_06. number(数字)2
3.2 数字类型转换
数据类型(需转换的数据)
如int(1.9),int(“123”)。
浮点型转换成整数会直接舍去小数部分,非“四舍五入”。
print(int(1.9))#-->1print(float(1))print(int("123"))print(float("12.3"))#-->1.0#-->123#-->12.3#如果有其他无用字符会报错#例如:print(int("abc"))#例如:print(int("123abc"))#+-只有作为正负号才有意义print(int("+123"))#print(int("12+3"))报错print(int("-123"))#print(int("12-3"))报错
3.3 数学函数
1. 常规函数
(1)绝对值
abs(x)
#返回数字的绝对值a1 = -10a2 = abs(a1)print(a2)
(2)比较数大小
a>b
#比较两个数的大小a1 = 100a2 = 9print((a1>a2)-(a1<a2))#-->1a1 = 100a2 = 100print((a1>a2)-(a1<a2))#-->0a1 = 9a2 = 100print((a1>a2)-(a1<a2))#-->-1
(3)最大值、最小值
max(x, y, z)
min(x, y, z)
#返回给定参数的最大值print(max(1, 2, 3, 4, 5, 6, 7, 8))#返回给定参数的最小值print(min(1, 2, 3, 4, 5, 6, 7, 8))
(4)x的y次方
pow(x, y)
#求x的y次方 2^5print(pow(2, 5))
(5)四舍五入
round(x[, n])
返回浮点数x的四舍五入的值,如果给出n值,则代表舍入到小数点后n位。
print(round(3.456))#-->3print(round(3.556))#-->4print(round(3.456, 2))#-->3.46print(round(3.546, 1))#-->3.5
2. 不常用函数
#math:数学相关的库import math#向上取整print(math.ceil(18.1))print(math.ceil(18.9))#-->19#-->19#向下取整print(math.floor(18.1))print(math.floor(18.9))#-->18#-->18#返回整数部分与小数部分print(math.modf(22.3))#-->(0.3000000000000007, 22.0)#开方print(math.sqrt(16))#-->4.0
_02-_07. number(数字)3
3. 随机数
- choice
```python
import random
从序列的元素中随机挑选一个元素
print(random.choice([1,3,5,7,9])) print(random.choice(range(5))) #range(5) == [0,1,2,3,4] print(random.choice(“test”)) #”test”==[“t”,”e”,”s”,”t”]—>1
—>0
—>e
产生一个1~100之间的随机数
r1 = random.choice(range(100)) + 1 print(r1)
- randrangerandom.randrange([start,] stop[, step])```python#从指定范围内,按指定的基数递增的集合中选取一个随机数#random.randrange([start,] stop[, step])#start--指定范围的开始值,包含在范围内,默认是0#stop--指定范围的结束值,不包含在范围内#step--指定的递增基数,默认是1print(random.randrange(1, 100, 2))#从0-99选取一个随机数print(random.randrange(100))
list = [1,2,3,4,5]
将序列的所有元素随机排序
random.shuffle(list) print(list)
—>[5, 3, 2, 4, 1]
随机生产一个实数,他在[3, 9]范围
print(random.uniform(3, 9))
—>3.2690590821215757
<a name="68743559"></a># 4 运算符与表达式> 02-08. number(数字)4、运算符与表达式1**表达式**<br />由变量、常量和运算符组成的式子称为表达式。<a name="1e837f78"></a>## 算数运算符| + | - | * | / | % | ** | // || --- | --- | --- | --- | --- | --- | --- || 加 | 减 | 乘 | 除 | 取模(求余) | 求幂 | 取整 |算术运算表达式:进行相关符号的数学运算,不会改变变量的值,如1+1,2*3,a/3等。<a name="dac6cd23"></a>## 赋值运算符变量=表达式<br />功能:计算等号右侧“表达式”的值,并赋值给等号左侧的“变量”;<br />值:赋值结束后变量的值变换。> 03-01. 作业、运算符与表达式3<a name="2459bd62"></a>## 位运算符位运算符是把数字看作二进制来进行计算的。**&:按位与运算符**<br />参与运算的两个值,如果两个相应位都为1,则该位的结果为1,否则为0。如:print(5 & 7)-->5**|:按位或运算符**<br />只要对应的二个二进位有一个为1时,结果位就为1。如:print(5 | 7)-->7^:**按位异或运算符**<br />当两对应的二进位相异时,结果为1。如:print(5 ^ 7)-->2> _02-_02. 运算符与表达式4**~:按位取反运算符**<br />对数据的每个二进制位取反,即把1变为0,把0变为1。如:print(~5)-->-6<<:**左移动运算符**<br />运算数的各二进位全部左移若干位,由“<<”右边的数指定移动的位数,高位丢弃,低位补0。print(2 << 2)-->8>>:**右移动运算符**<br />把“>>”左边的运算数的各二进位全部右移若干位,“>>”右边的数指定移动的位数。如:print(13>>2)-->3<a name="f5de3b4f"></a>## 关系运算符== 等于<br />!= 不等于<br />> 大于<br />< 小于<br />>= 大于等于<br /><= 小于等于```pythonage = 18if 17<age<19:print('True')#-->Trueif 17<age and age<19:print('True')#-->True
注意:“17<age<19”相当于“17<age and age<19”,这在其他语言中是不允许的。
逻辑运算符
_03-_03. 运算符与表达式5、string字符串1
逻辑与 and
逻辑或 or
逻辑非 not
if 1 and 2:print('11111')if 1 and 0:print('22222')#-->11111if 1 or 2:print('33333')if 1 or 0:print('44444')if False or 0:print('55555')#-->33333#-->44444if not 1:print('66666')if not 0:print('77777')#-->77777
成员运算符
in:如果在指定的序列中找到值返回True,否则返回False;
not in:如果在指定的序列中没有找到值返回True,否则返回False。
身份运算符
is:判断两个标识符是不是引用自一个对象;
is not:判断两个标识符是不是引用自不同对象。
三元操作符
变量 = 结果1 if 条件 else 结果2
x = 13y = 19if x < y:min = xelse:min = yprint(min)# -->13min = x if x < y else yprint(min)# -->13
练习题
03-01. 作业、运算符与表达式3
从控制台输入一个三位数,如果是水仙花数就打印“是水仙花数”,否则打印“不是水仙花数”。如:153=1^3+5^3+3^3
注意:求百位,不能像c#一样,直接a=136/100,应该a=int(136/100)n = int(input())bai = n // 100shi = n // 10 % 10ge = n % 10if (n == bai ** 3 + shi ** 3 + ge ** 3):print(n)
从控制台输入一个五位数,如果是回文数就打印“是回文数”,否则打印“不是回文数”如:11111 12321 12221
5 字符串
5.1 基础
什么是字符串
字符串是以单引号或双引号括起来的任意文本。例如,’abc’、”def”。
字符串不可变。
#创建字符串str = "test word"
字符串连接
#字符串连接str1 = "sunck is a "str2 = "good man"str3 = str1 + str2print("str1 =", str1)print("str2 =", str2)print("str3 =", str3)#-->str1 = sunck is a#-->str2 = good man#-->str3 = sunck is a good man
字符串复制
#字符串复制str = "good"str2 = str * 3print("str2 =", str2)
访问字符串中的某一个字符
_03-_04. string字符串2
通过索引下标查找字符,索引从0开始
str = "test"print(str[1])#-->e#str[1] = "a"#-->错误,字符串不可变print("str =", str)
截取字符串
| t | e | s | t | w | o | r | d | ! | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
#截取字符串中的一部分str = "test word!"#从给定下标出开始截取到给定下标之前,如“st wor”str1 = str[2:8]#从头截取到给定下标之前,如“tes”str2 = str[:3]#从给定下标处开始截取到结尾,如"rd!"str3 = str[7:]print("str3 =", str3)
判断某字符串是否在整个字符串中
str = "sunck is a good man"print("good" in str)print("good1" not in str)
5.2 格式化输出
format()方法接收位置参数和关键字参数(位置参数和关键字参数在第X章中有详细讲解),二者均传递到一个名为replacement的字段。而这个replacement字段在字符串内用大括号({})表示。
print("{0} old {1} {2}".format("How", "are", "you"))print("{a} old {b} {c}".format(a="How", b="are", c= "you"))print("{0} old {b} {c}".format("How", b="are", c= "you"))
字符串中的{0}、{1}和{2}与位置有关,被称为位置参数。
{a}、{b}和{c}就相当于三个目标标签,format()将参数中等值的字符串替换进去,这就是关键字参数。
如果将位置参数和关键字参数综合在一起使用,那么位置参数必须在关键字参数之前,否则就会出错。
#格式化输出print("sunck is a good man")#-->sunck is a good mannum = 10str19 = "sunck is a nice man!"ft = 10.1267print("num =", num, "str19 =", str19)#-->num = 10 str19 = sunck is a nice man!# %d %s %f 占位符#浮点数默认小数点后面有6位,不够6位默认用0补充够6位。%.3f精确到小数点后3位,会四舍五入print("num = %d, str19 = %s, ft = %.3f" % (num, str19, ft))#-->num = 10, str19 = sunck is a nice man!, ft = 10.127
Python格式化符号及含义
| 符 号 | 含 义 |
|---|---|
| %c | 格式化字符及其ASCII码 |
| %s | 格式化字符串 |
| %d | 格式化整数 |
| %o | 格式化无符号八进制数 |
| %x | 格式化无符号十六进制数 |
| %X | 格式化无符号十六进制数(大写) |
| %f | 格式化浮点数字,可指定小数点后的精度 |
| %e | 用科学计数法格式化浮点数 |
| %E | 作用同%e |
| %g | 根据值的大小决定使用%?或%e |
| %G | 作用同%g |
5.3 转义字符
将一些字符转换成有特殊含义的字符,是一个字符。
03-05. string字符串3
num = 10str19 = "sunck is a nice man!"ft = 10.1267#\n 换行print("num = %d\nstr19 = %s\nft = %.3f" % (num, str19, ft))#如果字符串内有很多换行,用\n写在一行不好阅读print("good\nnice\nhandsome")print('''goodnicehandsome''')# \\ 输出\print("sunck \\ is")#-->sunck \ is# \' \" 输出‘ “# tom is a 'good' manprint('tom is a \'good\' man')print("tom is a \'good\' man")print("tom is a \"good\" man")# \t 制表符print("sunck\tgood")#-->sunck good#如果字符中有好多字符串都需要转义,就需要加入好多\,为了简化,Python允许用r表示内部的字符串默认不转义# \\\t\\print(r"\\\t\\")print(r"C:\Users\xlg\Desktop\Python-1704\day03")print("C:\\Users\\xlg\\Desktop\\Python-1704\\day03")
Windows下路径与Linux路径的区别:
windows路径:“C:\Users\xlg\Desktop\Python-1704\day03”
linux路径:“/root/user/sunck/Desktop/Python-1704/day03”。
5.4 函数
Python字符串的方法及含义
| 方法 | 含义 |
|---|---|
| capitalize() | 将字符串的第一个字符修改为大写,其他字符全部改为小写 |
| casefold() | 将字符串的所有字符修改为小写 |
| center(width[, fillchar]) | 当字符个数大于width时,字符串不变; 当字符个数小于width时,字符串居中,并在左右填充空格以达到width指定宽度;fillchar参数可选,指定填充的字符(默认是空格) |
| count(sub[,start[,end]]) | 返回sub参数在字符串里边出现的次数:start和end参数可选,指定统计范围 |
| encode(encoding=’utf-8’, errors=’strict’) | 以encoding参数指定的编码格式对字符串进行编码,并返回errors参数指定出错时的处理方式,默认是抛出UnicodcError异常,还可以使用’ignore’、’replace’、’xmlcharrefreplace’、’backslashreplace’等处理方式 |
| endswith(sub[,start[,end]]) | 检查字符串是否以sub参数结束,如果是返回True,否则返回False;start和end参数可选,指定范围 |
| expandtabs(tabsize=8) | 把字符串中的制表符(\t)转换为空格代替 |
| find(sub[,start[,end]]) | 检查sub参数是否包含在字符串中,如果有则返回第一个出现位置的索引值,否则返回-1;start和end参数可选,表示范围 |
| index(sub[,start[,end]]) | 跟find()方法一样,不过该方法如果找不到将抛出一个ValueError异常 |
| isalnum() | 如果字符串仅由字母或数字构成则返回True,否则返回False |
| isalpha() | 如果字符串仅由字母构成则返回True,否则返回False |
| isdecimal() | 如果字符串仅由十进制数字构成则返回True,否则返回False |
| isdigit() | 如果字符串仅由数字构成则返回True,否则返回False |
| islower() | 如果字符串仅由小写字母构成则返回True,否则返回False |
| isnumeric() | 如果字符串仅由数值构成则返回True,否则返回False |
| isspace() | 如果字符串仅由空白字符构成则返回True,否则返回False |
| istitle() | 如果是标题化(所有的单词均以大写字母开始,其余字母皆小写)字符串则返回True,否则返回False |
| isupper() | 如果字符串仅由大写字母构成则返True,否则返回False |
| join(iterable) | 以字符串作为分隔符,插入到iterable参散迭代出来的所有字符串之间: 如果iterable中包含任何非字符串值,将抛出TypeError弃常 |
| ljust(width[, fillchar]) | 当字符个数大于width时,字符串不变: 当字符个数小于width时,左对齐字符串,并在右边填充空格以达到width指定宽度: fillchar参数可选,指定填充的字符(默认是空格) |
| lower() | 将字符串的所有大写字母修改为小写字母 |
| lstrip([chars]) | 删除字符串左边的所有空白字符:chars参数可选.指定待删除的字符集 |
| partition(sep) | 找到sep参数第一次出现的位置,并将字符串切分成一个三元组(sep前面的子字符串,sep,sep后面的子字符串;如果字符串中不包含sep,则返回三元组(’原字符串’,’’,’’) |
| replace(old, new[, count]) | 将字符串中的old参数指定的字符串替换成new参数指定的字符串: count参数可选,表示最多替换次数不超过count |
| rfind(sub[,start[,end]]) | 类似find()方法,不过是从右边开始查找 |
| rindex(sub[,start[,end]]) | 类似于index()方法,不过是从右边开始查找 |
| rjust(width[,fillchar]) | 当字符个数大于width时,字符串不变: 当字符个数小于width时,右对齐字符串,并在右边填充空格以达到width指定宽度; fillchar参数可选,指定填充的字符(默认是空格〉 |
| rpartition(sep) | 类似于partition()方法,不过是从右边开始查找 |
| rstrip([chars]) | 删除字符串右边的所有空白字符:chars参数可选,指定待删除的字符集 |
| split(sep=None, maxsplit=-1) | 以空白字符作为分隔符对字符串进行分割; sep参数指定分隔符,默认是空白字符:maxsplit设置最大分割次数,默认是不限制 |
| splitlines([keepends]) | 以换行符(‘\r’, ‘\r\n’, ‘\n’)作为分隔符对字符中进行分割:如果keepends == True,会保留换行符 |
| startswith(prefix(,start[,end]]) | 检查字符串是否以prefix参数开头,如果是则返回True,否则返回False: start和end参数可选,表示范围 |
| strip([chars]) | 删除字符串前边和后边所有空白字符:chars参数可选,指定待删除的字符集 |
| swapcase() | 将字符串中所有的大写字母修改为小写,将小写字母修改为大写 |
| title() | 以标题化(所有的单词均以大写字母开始,其余字母皆小写)的形式格式化字符串 |
| translate(table) | 根据table的规则(可以由str.maketrans(‘a’,’b’)定制)转换字符串中的字符 |
| upper() | 将字符串的所有小写字母修改为大写字母 |
| zfill(width) | 当字符个数大于width时,字符串不变; 当字符个数小于width时,返回长度为width的字符串,原字符串右对齐,前边用0进行填充 |
03-06. string字符串4
eval(str)
功能:将字符串str当成有效的表达式来求值,并返回计算结果num1 = eval("123")print(num1)print(type(num1))print(eval("+123"))print(eval("-123"))print(eval("12+3"))print(eval("12-3"))#print(eval("a123")) 必须为有意义的表达式#print(eval("12a3"))#-->123#--><class 'int'>#-->123#-->-123#-->15#-->9
len(str)
返回字符串的长度(字符个数)print(len("sunck is a good man凯"))
lower()
转换字符串中大写字母为小写字母str20 = "SUNCK is a Good Man!凯"str21 = str20.lower()print(str21) #sunck is a good man!凯print("str20 = %s" %(str20)) #str20 = SUNCK is a Good Man!凯
upper()
转换字符串中小写字母为大写字母str21 = "SUNCK is a Good Man!"print(str21.upper()) #SUNCK IS A GOOD MAN!
swapcase()
转换字符串中小写字母为大写字母,大写字母为小写字母str22 = "SUNCK is a gOOd mAn!"print(str22.swapcase()) #sunck IS A GooD MaN!
capitalize()
首字母大写,其他小写str23 = "SUNCK is a gOOd mAn!"print(str23.capitalize()) #Sunck is a good man!
title()
每个单词的首字母大写str24 = "SUNCK is a gOOd mAn!"print(str24.title()) #Sunck Is A Good Man!
center()
center(width[, fillchar])
返回一个指定宽度的居中字符串,fillchar为填充的字符串,默认空格填充
str25 = "kaige is a nice man"print(str25.center(40, "*"))#-->**********kaige is a nice man***********
- ljust()
ljust(width[, fillchar])
返回一个指定宽度的左对齐字符串,fillchar为填充字符,默认空格填充
str26 = "kaige is a nice man"print(str26.ljust(40, "%"))#-->kaige is a nice man%%%%%%%%%%%%%%%%%%%%%
- rjust()
rjust(width[, fillchar])
返回一个指定宽度的右对齐字符串,fllchar为填充字符,默认空格填充
str27 = "kaige is a nice man"print(str26.rjust(40, "%"))#-->%%%%%%%%%%%%%%%%%%%%%kaige is a nice man
03-07. string字符串5
- zfill()
zfill(width)
返回一个长度为width的字符串,原字符串右对齐,前面补0
str28 = "kaige is a nice man"print(str28.zfill(40))#-->000000000000000000000kaige is a nice man
- count()
count(str[, start][, end])
返回字符串中str出现的次数,可以指定一个范围,默认从头到尾
str29 = "kaige is a very very nice man"print(str29.count("very")) #2print(str29.count("very", 15, len(str29) )) #1
- find()
find(str[, start][, end])
从左向右检测str字符串是否包含在字符串中,可以指定范围,默认从头到尾。得到的是第一次出现的开始下标,没有返回-1
str30 = "kaige is a very very nice man"print(str30.find("very")) #11print(str30.find("good")) #-1print(str30.find("very", 15, len(str30))) #16
rfind()
rfind(str[, start][, end])]str = "kaige is a very very nice man"print(str.rfind("very")) #16,从右开始数,very第一次出现在下标16print(str.rfind("very", 0, 15)) #11,从左到右0-15个字符中,very出现在下标11
index()
index(str, start=0, end=len(str))
跟find()一样,只不过如果str不存在的时候,会报一个异常
str31 = "kaige is a very very nice man"#print(str31.index("good"))报错print(str31.index("very")) #11
- rindex()
rindex(str, start=0, end=len(str))
跟rfind()一样,只不过如果str不存在的时候,会报一个异常
str32 = "kaige is a very very nice man"print(str32.rindex("very")) #16
strip()
截掉字符串两头指定的字符,默认为空格str = "*******test*********"print(str.strip("*"))#-->teststr = "*******test***test*********"print(str.strip("*"))#-->test***test,只截取两头的字符
rstrip()
截掉字符串右侧指定的字符,默认为空格str = "test*********"print(str.rstrip("*"))#-->testprint(str.rstrip())#-->test*********str = "test "print(str.rstrip(), "*")#-->test*
lstrip()
截掉字符串左侧指定的字符,默认为空格str = "*******test"print(str.lstrip("*")) #test
ASCII码 ```python str36 = “a” print(ord(str36))
—>97
str37 = chr(65) print(str37)
—>A
| ASCII值 | 控制字符 | ASCII值 | 控制字符 | ASCII值 | 控制字符 | ASCII值 | 控制字符 || --- | --- | --- | --- | --- | --- | --- | --- || 0 | NUT | 32 | (space) | 64 | @ | 96 | 、 || 1 | SOH | 33 | ! | 65 | A | 97 | a || 2 | STX | 34 | " | 66 | B | 98 | b || 3 | ETX | 35 | # | 67 | C | 99 | c || 4 | EOT | 36 | $ | 68 | D | 100 | d || 5 | ENQ | 37 | % | 69 | E | 101 | e || 6 | ACK | 38 | & | 70 | F | 102 | f || 7 | BEL | 39 | , | 71 | G | 103 | g || 8 | BS | 40 | ( | 72 | H | 104 | h || 9 | HT | 41 | ) | 73 | I | 105 | i || 10 | LF | 42 | * | 74 | J | 106 | j || 11 | VT | 43 | + | 75 | K | 107 | k || 12 | FF | 44 | , | 76 | L | 108 | l || 13 | CR | 45 | - | 77 | M | 109 | m || 14 | SO | 46 | . | 78 | N | 110 | n || 15 | SI | 47 | / | 79 | O | 111 | o || 16 | DLE | 48 | 0 | 80 | P | 112 | p || 17 | DCI | 49 | 1 | 81 | Q | 113 | q || 18 | DC2 | 50 | 2 | 82 | R | 114 | r || 19 | DC3 | 51 | 3 | 83 | S | 115 | s || 20 | DC4 | 52 | 4 | 84 | T | 116 | t || 21 | NAK | 53 | 5 | 85 | U | 117 | u || 22 | SYN | 54 | 6 | 86 | V | 118 | v || 23 | TB | 55 | 7 | 87 | W | 119 | w || 24 | CAN | 56 | 8 | 88 | X | 120 | x || 25 | EM | 57 | 9 | 89 | Y | 121 | y || 26 | SUB | 58 | : | 90 | Z | 122 | z || 27 | ESC | 59 | ; | 91 | [ | 123 | { || 28 | FS | 60 | < | 92 | / | 124 | | || 29 | GS | 61 | = | 93 | ] | 125 | } || 30 | RS | 62 | > | 94 | ^ | 126 | ` || 31 | US | 63 | ? | 95 | _ | 127 | DEL |- **比较大小**> 04-01. 作业、布尔值与空值、列表list从第一个字符开始比较,谁的ASCII值大谁就大,如果相等会比较下一个字符的ASCII值大小,那么谁的值大谁就大。如"b" > "a" 、"bdreer" > "azdqe"返回True。<br />如果前几个字符相等,一个字符串结束,那会自动填充"\0" 以开始比较。如"msdjfqiue" > "ms" 返回True。**如果需判断一个字符是不是数字,使用str[i]>="0" and str[i]<="9"即可判断。**> 05-02. 列表list2- **split()**- split(str, num)<br />以str为分隔符截取字符串,指定num,则仅截取num个字符串。提取分隔符之间的字符串,如果为连续的分隔符,则返回空字符串””。```pythonstr = "sunck**is******a***good*man"list = str.split("*")#-->['sunck', '', 'is', '', '', '', '', '', 'a', '', '', 'good', 'man']c = 0for s in list:if len(s) > 0:c += 1print(c)#-->5
- splitlines([keepends])
按照(‘\r’, ‘\r\n’, ‘\n’)分隔,如果keepends == True,会保留换行符。
str40 = '''sunck is a good man!sunck is a nice man!sunck is handsome man!'''print(str40.splitlines())#-->['sunck is a good man!', 'sunck is a nice man!', 'sunck is handsome man!']print(str40.splitlines(True))#-->['sunck is a good man!\n', 'sunck is a nice man!\n', 'sunck is handsome man!\n']
join()
以指定的字符串分隔符,将seq中的所有元素组合成一个字符串list41 = ['test1', 'test2', 'test3']str42 = "--".join(list41)print(str42)#-->test1--test2--test3
max()/min()
str43 = "sunck is a good man!z"print(max(str43)) #zprint(min(str43)) #“ ”
replace()
replace(oldstr, newstr, count)
用newstr替换oldstr,默认是全部替换。如果指定了count,那么只替换前count个。
str = "sunck is a good good good man"str1 = str.replace("good", "nice")print(str1)#-->sunck is a nice nice nice manstr2 = str.replace("good", "nice", 1)print(str2)#-->sunck is a nice good good man
- maketrans()
maketrans(oldstr, newstr)
创建一个字符串映射表,将oldstr映射成newstr,逐字符映射,然后将字符串中的所有旧字符替换成新字符。
kw = str.maketrans("ac", "65")# a替换成6 c替换成5str1 = "sunck is a good man"str2 = str1.translate(kw)print(str2)#-->sun5k is 6 good m6n
05-03. 列表list3
- startswith()
startswith(str[, start][, end])
在给定的范围内判断是否是以给定的字符串开头,如果没有指定范围,默认整个字符串
str49 = "sunck is a good man"print(str49.startswith("sunck", 5, 16)) #False
- endswith()
endswith(str, start=0, end=len(str))
在给定的范围内判断是否是以给定的字符串结尾,如果没有指定范围,默认整个字符串
str50 = "sunck is a nice man"print(str50.endswith("man")) #True
- 编码
encode(encoding=”utf-8”, errors=”strict”) ```python str51 = “sunck is a good man凯”ignore忽略错误
data52 = str51.encode(“utf-8”, “ignore”) print(data52) print(type(data52))—>b’sunck is a good man\xe5\x87\xaf’
—>
解码 注意:要与编码时的编码格式一致
str53 = data52.decode(“gbk”, “ignore”) print(str53)
—>sunck is a good man鍑
- **isalpha()**<br />如果字符串中至少有一个字符且所有的字符都是字母返回True,否则返回False。```pythonstr = "sunckisagoodman"print(str.isalpha()) #Truestr1 = "sunck is a good man"print(str1.isalpha()) #False
isalnum()
如果字符串中至少有一个字符且所有的字符都是字母或数字返回True,否则返回Falseprint("nu1".isalnum())#-->True
isupper()
如果字符串中至少有一个英文字符且所有的英文字符都是大写的英文字母返回True,否则返回Falseprint("ABC".isupper()) #Trueprint("1".isupper()) #Falseprint("ABC1".isupper()) #Trueprint("aBC1".isupper()) #Falseprint("ABC#".isupper()) #True
islower()
如果字符串中至少有一个英文字符且所有的英文字符都是小写的英文字母返回True,否则返回False- istitle()
如果字符串是标题化(单词的首字母大写)的返回True,否则返回False - isdigit()
如果字符串中只包含数字字符,返回True,否则返回False - isnumeric()
同上 - isdecimal()
字符串中是否只包含十进制字符(基本不怎么用) - isspace()
如果字符中只包含空格(或空白符)则返回True,否则返回Falseprint(" ".isspace()) #Trueprint(" Z ".isspace()) #Falseprint("\t".isspace()) #Trueprint("\n".isspace()) #Trueprint("\r".isspace()) #True
5.5 练习
06-01. 作业(时间下一秒、歌词解析1)
- 输入一个时间后(如12:23:59),输出下一秒。 ```python timeStr = input()
timeList = timeStr.split(“:”)
h = int(timeList[0]) m = int(timeList[1]) s = int(timeList[2])
s += 1
if s == 60: m += 1 s = 0 if m == 60: h += 1 m = 0 if h == 24: h = 0
print(“%.2d:%.2d:%.2d” %(h, m, s))
2. 歌词解析```pythonimport timemusicLrc = """[00:03.50]传奇[00:19.10]作词:刘兵 作曲:李健[00:20.60]演唱:王菲[00:26.60][04:40.75][02:39.90][00:36.25]只是因为在人群中多看了你一眼[04:49.00][02:47.44][00:43.69]再也没能忘掉你容颜[02:54.83][00:51.24]梦想着偶然能有一天再相见[03:02.32][00:58.75]从此我开始孤单思念[03:08.15][01:04.30][03:09.35][01:05.50]想你时你在天边[03:16.90][01:13.13]想你时你在眼前[03:24.42][01:20.92]想你时你在脑海[03:31.85][01:28.44]想你时你在心田[03:38.67][01:35.05][04:09.96][03:39.87][01:36.25]宁愿相信我们前世有约[04:16.37][03:46.38][01:42.47]今生的爱情故事 不会再改变[04:24.82][03:54.83][01:51.18]宁愿用这一生等你发现[04:31.38][04:01.40][01:57.43]我一直在你身旁 从未走远[04:39.55][04:09.00][02:07.85]"""lrcDict = {}musicLrcList = musicLrc.splitlines()#print(musicLrcList)for lrcLine in musicLrcList:#[04:40.75][02:39.90][00:36.25]只是因为在人群中多看了你一眼#[04:40.75 [02:39.90 [00:36.25 只是因为在人群中多看了你一眼#[00:20.60]演唱:王菲lrcLineList = lrcLine.split("]")for index in range(len(lrcLineList) - 1):timeStr = lrcLineList[index][1:]#print(timeStr)#00:03.50timeList = timeStr.split(":")time1 = float(timeList[0]) * 60 + float(timeList[1])#print(time)lrcDict[time1] = lrcLineList[-1]print(lrcDict)allTimeList = []for t in lrcDict:allTimeList.append(t)allTimeList.sort()#print(allTimeList)'''while 1:getTime = float(input("请输入一个时间"))for n in range(len(allTimeList)):tempTime = allTimeList[n]if getTime < tempTime:breakif n == 0:print("时间太小")else:print(lrcDict[allTimeList[n - 1]])'''getTime = 0while 1:for n in range(len(allTimeList)):tempTime = allTimeList[n]if getTime < tempTime:breaklrc = lrcDict.get(allTimeList[n - 1])if lrc == None:passelse:print(lrc)time.sleep(1)getTime += 1
6 布尔值与空值
04-01. 作业、布尔值与空值、列表list
布尔值:一个布尔值只有True、False两种值。
空值:是Python里一个特殊的值,用None表示。None不能理解为0,因为0是有意义的,而None是一个特殊值。
n = Noneprint(n) #None
7 列表
7.1 基础概念
_04-_02. 列表list2
要存储100个人的年龄,就需要使用列表。列表的本质,是一种有序的集合。
1. 列表的创建
列表名 = [列表选项1, 列表选项2, ……, 列表选项n]
#创建了一个空列表list1 = []print(list1) #[]#创建带有元素的列表list2 = [18, 19, 20, 21, 22]#注意:列表中的元素数据可以是不同类型的list3 = [1, 2, "sunck", "good", True]print(list3)
2. 列表的访问和替换
列表名[下标]
#列表元素的访问list4 = [1, 2, 3, 4, 5]print(list4[2]) #3#注意不要越界(下标超出了可表示的范围)#替换list4[2] = 300print(list4) #[1, 2, 300, 4, 5]#二维列表list11 = [[1,2,3], [4,5,6], [7,8,9]]print(list11[1][1]) #5
3. 列表的操作
#列表组合list5 = [1,2,3]list6 = [4,5,6]list7 = list5 + list6print(list7) #[1, 2, 3, 4, 5, 6]#列表的重复list8 = [1,2,3]print(list8 * 3) #[1, 2, 3, 1, 2, 3, 1, 2, 3]#判断元素是否在列表中list9 = [1,2,3,4,5]print(3 in list9) #Trueprint(6 in list9) #False
7.2 添加数据
- append()
在列表中末尾添加新的元素,append()方法只支持一个参数。
list12 = [1, 2, 3, 4, 5]list12.append(6)print(list12) #[1, 2, 3, 4, 5, 6]list12.append([7, 8, 9])print(list12) #[1, 2, 3, 4, 5, 6, [7, 8, 9]]
- extend()
在末尾一次性追加另一个列表中的多个值,它的参数是另一个列表。
list13 = [1, 2, 3, 4, 5]list13.extend([6,7,8]) #[1, 2, 3, 4, 5, 6, 7, 8]
_04-_03. 列表list3
- insert()
在下标处添加一个元素,不覆盖原数据,原数据向后顺延。
insert()方法有两个参数:第一个参数指定待插入的位置(索引值),第二个参数是待插入的元素值。
list = [1,2,3,4,5]list.insert(2, 100) #[1, 2, 100, 3, 4, 5]list.insert(2, [200, 300]) #[1, 2, [200, 300], 100, 3, 4, 5]
insert()方法中代表位置的第一个参数还支持负数,表示与列表末尾的相对距离:
list = [1, 2, 3, 4, 5]list.insert(-1, 100)#-->[1, 2, 3, 4, 100, 5]
7.3 删除数据
- pop()
移除列表中指定下标处的元素(默认为-1,即移除最后一个元素),并返回删除的数据
list15 = [1,2,3,4,5]list15.pop() #[1, 2, 3, 4]list15.pop(2) #[1, 2, 4]print(list15.pop(1)) #2print(list15) #[1, 4]
- remove()
移除列表中的某个元素第一个匹配的结果,后面的不变。使用remove()删除元素,并不需要知道这个元素在列表中的具体位置。但是如果指定的元素不存在于列表中,程序就会报错。
list16 = [1, 2, 3, 4, 5, 4, 6, 4]list16.remove(4) #[1, 2, 3, 5, 4, 6, 4]
- clear()
清除列表中所有的数据。
list = [1,2,3,4,5]list.clear() #[]
- del
它是一个Python语句,而不是del列表的方法,或者BIF(内置函数build-in-function)。
list = [1, 2, 3, 4, 5]del list[3]#-->[1, 2, 3, 5]
del语句在Python中的用法非常丰富,不仅可以用来删除列表中的某个(些)元素,还可以直接删除整个变量。
list = [1, 2, 3, 4, 5]del list
7.4 列表的截取
列表切片(截取)并不会修改列表自身的组成结构和数据,它其实是为列表创建一个新的拷贝(副本)并返回。
list = [1, 2, 3, 4, 5, 6, 7, 8, 9]print(list[2:6]) #[3, 4, 5, 6],左包含,右不包含print(list[3:]) #[4, 5, 6, 7, 8, 9]print(list[-3:]) #[7, 8, 9]print(list[:5]) #[1, 2, 3, 4, 5]print(list[::-1]) #[9, 8, 7, 6, 5, 4, 3, 2, 1]
如果将del语句作用于列表切片,del直接作用于原始列表。
list = [1, 2, 3, 4, 5, 6, 7, 8, 9]del list[3:]print(list)#-->[1, 2, 3]
7.5 常用方法
- index()
从列表中找出某个值第一个匹配的索引值
list = [1, 2, 3, 4, 5, 3, 4, 5, 6]index1 = list.index(3)#圈定范围index2 = list.index(3, 3, 7) #在下标3-7中查找数字3print(index1, index2) #2 5
- len()
列表中元素个数
list20 = [1, 2, 3, 4, 5]print(len(list20)) #5
- max()
获取列表中的最大值
list21 = [1,2,3,4,5]print(max(list21)) #5
- min()
获取列表中的最小值
list22 = [1,2,3,4,5]print(min(list22)) #1
- count()
查看元素在列表中出现的次数
list23 = [1, 2, 3, 4, 5, 3, 4, 5, 3, 3, 5, 6]print(list23.count(3)) #4
_04-_04. 列表list4
- reverse()
将列表的顺序反方向记录。
list = [1, 2, 3, 4, 5]list.reverse()print(list) #[5, 4, 3, 2, 1]
- sort()
sort(func, key, reverse)
排序,默认升序。
func和key参数用于设置排序的算法和关键字,默认是使用归并排序,算法问题不在这里讨论。
第三个参数:reverse,同reverse()方法。默认值是sort(reverse=False),表示不颠倒顺序。因此,只需要把False改为True,列表则变为降序。
list = [2, 1, 3, 5, 4]list.sort()print(list)#-->[1, 2, 3, 4, 5]list.sort(reverse= True)print(list)#-->[5, 4, 3, 2, 1]
- copy与=
list2=list1,这为浅拷贝,又称之为引用拷贝,修改list2会同时修改list1。
list1 = [1, 2, 3, 4, 5]list2 = list1list2[1] = 200print(list2) #[1, 200, 3, 4, 5]print(list1) #[1, 200, 3, 4, 5]print(id(list2)) #39172032print(id(list1)) #39172032
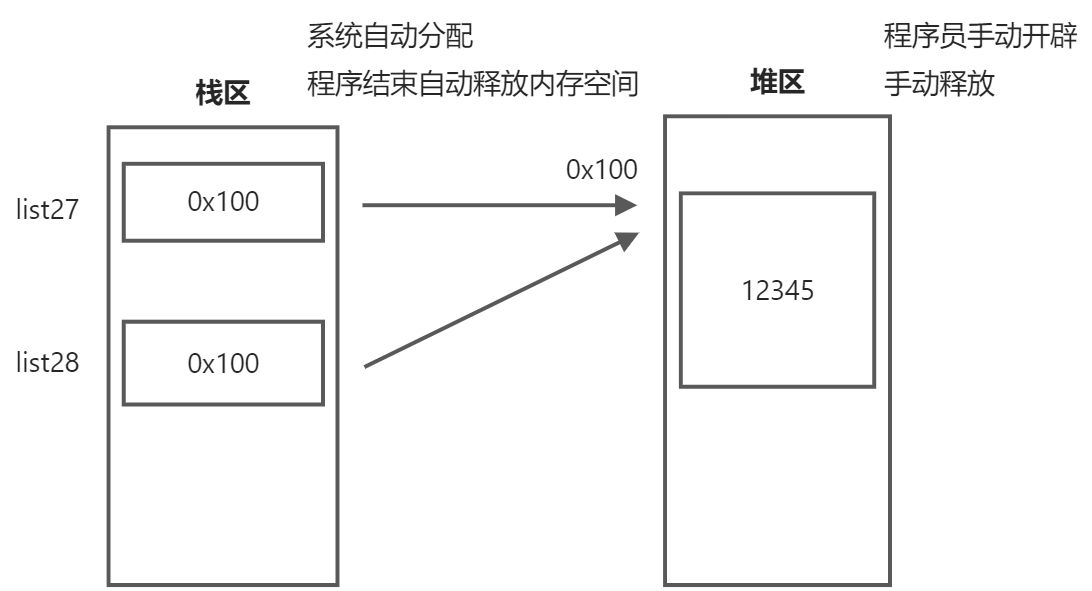
copy为深拷贝,为内存的拷贝。list2=list1.copy(),修改list2不会改变list1。
list1 = [1, 2, 3, 4, 5]list2 = list1.copy()list2[1] = 200print(list1) #[1, 2, 3, 4, 5]print(list2) #[1, 200, 3, 4, 5]print(id(list1)) #39172160print(id(list2)) #39237696
例:找出列表中倒数第二大的值
#方法一listNum = []num = 0while num < 5:val = int(input())listNum.append(val)num += 1print(listNum)#升序排序listNum.sort()count = listNum.count(listNum[len(listNum) - 1])c = 0while c < count:listNum.pop()c += 1print(listNum[len(listNum) - 1])
方法二
list=[]n=0while n<5:val=int(input())list.append(val)n+=1n=0max=0secMax=0while n<5:if list[n]>max:secMax=maxmax=list[n]if list[n]<max and list[n]>secMax:secMax=list[n]n+=1print(secMax)
8 元组
8.1 基础概念
tuple,本质是一种有序集合。
特点:
- 与列表非常相似;
- 一旦初始化就不能修改;
- 使用小括号。
1. 创建元组
元组名 = (元组元素1, 元组元素2, ……, 元组元素n)
tuple1 = ( )print(tuple1)#-->( )#创建带有元素的元组#元组中的元素的类型可以不同tuple2 = (1, 2, 3, "good", True)print(tuple2)#-->(1, 2, 3, 'good', True)#定义只有一个元素的元组tuple3 = (365)print(type(tuple3))#--><class 'int'>tuple4 = (365, )print(type(tuple4))#--><class 'tuple'>
2. 元素的访问
元组名[下标]
tuple4 = (1,2,3,4,5)print(tuple4[0])#print(tuple4[5]) #下标超过范围(越界)print(tuple4[-1]) #获取最后一个元素print(tuple4[-2]) #获取倒数第二个元素
3. 修改元素
tuple不可以修改元素,但是如果tuple里包含列表,列表的某个值可以修改。
tuple5 = (1, 2, 3, 4,[5, 6, 7])#tuple5[0] = 100 #报错,元组不能变#tuple5[-1] = [7,8,9] #错误tuple5[-1][0] = 500print(tuple5)#-->(1, 2, 3, 4, [500, 6, 7])
4. 删除元组
del 元组名
5. 元组的操作
#元组的操作t7 = (1,2,3)t8 = (4,5,6)t9 = t7 + t8 #(1, 2, 3, 4, 5, 6)#元组重复t10 = (1,2,3)print(t10 * 3) #(1, 2, 3, 1, 2, 3, 1, 2, 3)#判断元素是否在元组中t11 = (1,2,3)print(4 in t11) #False
6. 元组的截取
元组名 [ 开始下标 : 结束下标 ]
从开始下标开始截取,截取到结束下标之前
t12 = (1,2,3,4,5,6,7,8,9)print(t12[3:7]) #(4, 5, 6, 7)print(t12[3:]) #(4, 5, 6, 7, 8, 9)print(t12[:7]) #(1, 2, 3, 4, 5, 6, 7)
7. 二维元组
元素为一维元组的元组
t13 = ((1,2,3),(4,5,6),(7,8,9))print(t13[1][1])
8.2 元组的方法
- len()
返回元组中元素的个数
- max()
返回元组中的最大值
- min()
返回元组中的最小值
将列表转成元组
list = [1,2,3]t15 = tuple(list)print(t15)
元组的遍历
for i in (1,2,3,4,5):print(i)
9 字典
05-04. dict字典1
9.1 概述
使用 键-值(key-value) 存储,具有极快的查找速度。
注意:字典是无序的。
key的特性:
- 字典中的key必须唯一;
- key必须是不可变对象;
- 字符串、整数等都是不可变的,可以作为key;
- list是可变的,不能作为key。
与list相比,dict具有以下特点:
- 查找和插入的速度极快,不会随着key-value的增加而变慢;
- 需要占用大量的内存,内存浪费多。
9.2 操作字典
定义字典
dict1 = {"tom":60, "lilei":70}
元素的访问
字典名[key]dict1 = {"tom":60, "lilei":70}print(dict1["lilei"]) #70print(dict1["sunck"]) #没有,报错
当key不确定是否在字典中时,可以用get函数,不存在返回“None”。
dict1 = {"tom":60, "lilei":70}print(dict1.get("sunck"))ret = dict1.get("sunck")if ret == None:print("没有")else:print("有")
添加
dict1 = {"tom":60, "lilei":70}dict1["hanmeimei"] = 99#因为一个key对应一个value,所以,多次对一个key的value赋值,其实就是修改值dict1["lilei"] = 80 #对“lilei”这个key的值进行修改
删除
dict1 = {"tom":60, "lilei":70}dict1.pop("tom")
05-05. dict字典2
- 遍历 ```python dict1 = {“tom”:60, “lilei”:70} for key in dict1: print(key, dict1[key])
for value in dict1.values(): #[60,80,90] print(value)
for k, v in dict1.items(): print(k, v)
tom 60
lilei 70
for i, k2 in enumerate(dict1): print(i, k2)
0 tom
1 lilei
<a name="7e1d5c7b"></a># 10 set**10.1 基础方法**> _06-_03. 作业(歌词解析3)、set类似dict,是一组key的集合,不存储value。本质是无序和无重复元素的集合。1. 创建创建set需要一个list或者tuple或者dict作为输入集合,重复元素在set中会自动被过滤。```pythons1 = set([1,2,3,4,5,3,4,5]) #{1, 2, 3, 4, 5}s2 = set((1,2,3,3,2,1)) #{1, 2, 3}s3 = set({1:"good", 2:"nice"}) #{1, 2}
添加
s4 = set([1,2,3,4,5])s4.add(6) #{1, 2, 3, 4, 5, 6}s4.add(3) #可以添加重复的,但是不会有效果#s4.add([7,8,9]) #set的元素不能是列表,因为列表是可变的s4.add((7,8,9)) #{1, 2, 3, 4, 5, 6, (7, 8, 9)}#s4.add({1:"a"}) #set的元素不能是字典,因为字典是可变的
插入
#插入整个list、tuple、字符串,打碎插入s5 = set([1,2,3,4,5])s5.update([6,7,8]) #{1, 2, 3, 4, 5, 6, 7, 8}s5.update((9,10)) #{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}s5.update("sunck") #{'u', 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 'k', 's', 'c', 'n'}
删除
s6 = set([1,2,3,4,5])s6.remove(3) #{1, 2, 4, 5}
遍历 ```python s7 = set([1,2,3,4,5]) for i in s7: print(i)
set没有索引的
print(s7[3])
for index, data in enumerate(s7): print(index, data)
6. 交集与并集```pythons8 = set([1,2,3])s9 = set([2,3,4])#交集a1 = s8 & s9 #{2, 3}#并集a2 = s8 | s9 #{1, 2, 3, 4}
10.2 类型转换
_06-_03. 作业(歌词解析3)、set
#list-->setl1 = [1,2,3,4,5,3,4,5]#tuple-->sett2 = (1,2,3,4,3,2)s2 = set(t2)#set-->lists3 = {1,2,3,4}l3 = list(s3)#set-->tuples4 = {2,3,4,5}t4 = tuple(s4)
10.3 例题
list去重复
l = [1,2,3,4,3,4,5,6]'''s = set(l)l = list(s)'''l = list(set(l))
11 迭代器
_06-_05. 迭代器
可迭代对象:可以直接作用于for循环的对象统称为可迭代对象(Iterable)。可以用isinstance()去判断一个对象是否是Iterable对象(必须引用“from collections import Iterable”,3.8以后版本可以用“from collections.abc import Iterable”代替)。
可以直接作用于for的数据类型一般分两种:
- 集合数据类型,如list、tuple、dict、set、string;
- generator,包括生成器和带yield的generator function。
from collections.abc import Iterableprint(isinstance([], Iterable)) #Trueprint(isinstance((), Iterable)) #Trueprint(isinstance({}, Iterable)) #Trueprint(isinstance("", Iterable)) #Trueprint(isinstance((x for x in range(10)), Iterable)) #Trueprint(isinstance(1, Iterable)) #False
迭代器:不但可以作用于for循环,还可以被next()函数不断调用并返回下一个值,直到最后跑出一个StopIteration错误表示无法继续返回下一个值。
可以使用isinstance()函数判断一个对象是否是Iterator对象。
from collections.abc import Iteratorprint(isinstance([], Iterator)) #Falseprint(isinstance((), Iterator)) #Falseprint(isinstance({}, Iterator)) #Falseprint(isinstance("", Iterator)) #Falseprint(isinstance((x for x in range(10)), Iterator)) #Truel = (x for x in [23,4,5,64,3435])print(next(l))print(next(l))print(next(l))print(next(l))print(next(l))#print(next(l))#转成Iterator对象a = iter([1,2,3,4,5])print(next(a))print(next(a))print(isinstance(iter([]), Iterator)) #Trueprint(isinstance(iter(()), Iterator)) #Trueprint(isinstance(iter({}), Iterator)) #Trueprint(isinstance(iter(''), Iterator)) #True
案例:输入多行字符串并输出
endstr = "end"str = ""for line in iter(input, endstr):str += line + "\n"print(str)

若有收获,就点个赞吧
0 人点赞
