一:HDFS和YARN
HDFS和YARN是两个概念,一个是文件存储技术,一个是文件读写技术
二:搭建
1:规划
NN NN JN ZKFC ZK DN RM NM<br /> node01 * * *<br /> node02 * * * * * *<br /> node03 * * * * *<br /> node04 * * * *
2:配置
1):mapred-site.xml > mapreduce on yarn
<property><name>mapreduce.framework.name</name><value>yarn</value></property>
2):yarn-site.xml
<property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.resourcemanager.ha.enabled</name><value>true</value></property><property><name>yarn.resourcemanager.zk-address</name><value>node02:2181,node03:2181,node04:2181</value></property><property><name>yarn.resourcemanager.cluster-id</name><value>mashibing</value></property><property><name>yarn.resourcemanager.ha.rm-ids</name><value>rm1,rm2</value></property><property><name>yarn.resourcemanager.hostname.rm1</name><value>node03</value></property><property><name>yarn.resourcemanager.hostname.rm2</name><value>node04</value></property>
3:root操作
node01
cd $HADOOP_HOME/etc/hadoopcp mapred-site.xml.template mapred-site.xmlvi mapred-site.xmlvi yarn-site.xmlscp mapred-site.xml yarn-site.xml node02:`pwd`scp mapred-site.xml yarn-site.xml node03:`pwd`scp mapred-site.xml yarn-site.xml node04:`pwd`vi slaves //可以不用管,搭建hdfs时候已经改过了。。。start-yarn.sh
node03~04
yarn-daemon.sh start resourcemanager
访问
http://node03:8088
http://node04:8088
This is standby RM. Redirecting to the current active RM: http://node03:8088/
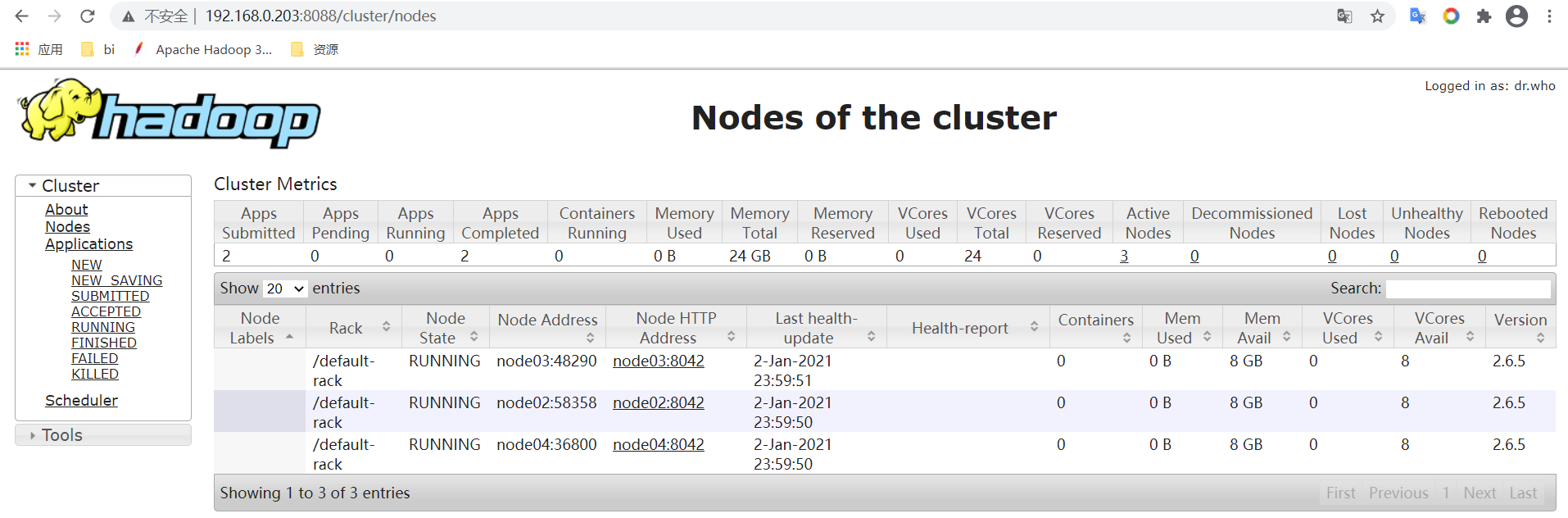
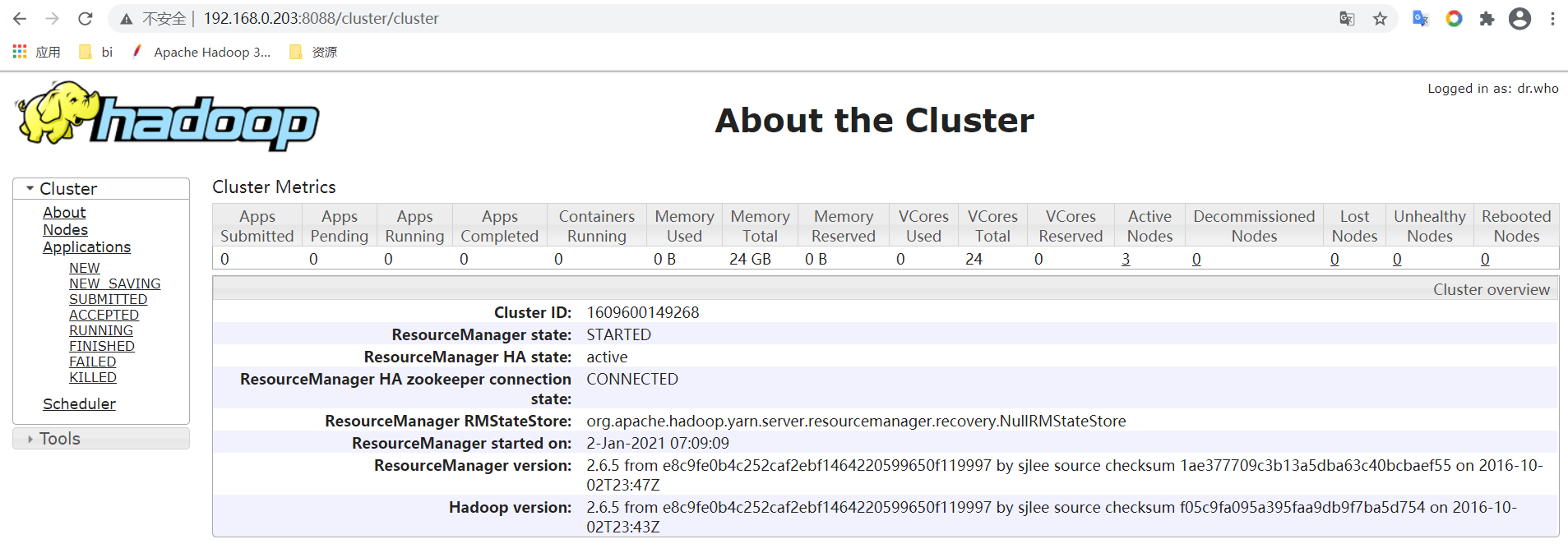
4: 官方案例使用wc
实战:MR ON YARN 的运行方式:hdfs dfs -mkdir -p /data/wc/inputhdfs dfs -D dfs.blocksize=1048576 -put data.txt /data/wc/input
cd $HADOOP_HOME
cd share/hadoop/mapreduce
hadoop jar hadoop-mapreduce-examples-2.6.5.jar wordcount /data/wc/input /data/wc/output
1)webui:需要查看
2)cli:命令行hdfs dfs -ls /data/wc/output
-rw-r—r— 2 root supergroup 0 2019-06-22 11:37 /data/wc/output/_SUCCESS //标志成功的文件
-rw-r—r— 2 root supergroup 788922 2019-06-22 11:37 /data/wc/output/part-r-00000 //数据文件
如果是reduce文件:part-r-00000
如果是map文件:part-m-00000
如果是map/reduce:r/mhdfs dfs -cat /data/wc/output/part-r-00000hdfs dfs -get /data/wc/output/part-r-00000 ./
5:开发简易MR程序
1:yarn-site.xml
2:mapred-site.xml
3:pom.xml
<dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>2.6.5</version></dependency>
4:MyWordCount
package com.hadoop.fastdfs.mapreduce.wc;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;import org.apache.hadoop.util.GenericOptionsParser;public class MyWordCount {//bin/hadoop command [genericOptions] [commandOptions]// hadoop jar ooxx.jar ooxx -D ooxx=ooxx inpath outpath// args : 2类参数 genericOptions commandOptions// 人你有复杂度: 自己分析 args数组//public static void main(String[] args) throws Exception {Configuration conf = new Configuration(true);//GenericOptionsParser parser = new GenericOptionsParser(conf, args); //工具类帮我们把-D 等等的属性直接set到conf,会留下commandOptions//String[] othargs = parser.getRemainingArgs();//让框架知道是windows异构平台运行//conf.set("mapreduce.app-submission.cross-platform","true");// conf.set("mapreduce.framework.name","local");// System.out.println(conf.get("mapreduce.framework.name"));Job job = Job.getInstance(conf);// FileInputFormat.setMinInputSplitSize(job,2222);// job.setInputFormatClass(ooxx.class);// job.setJar("C:\\Users\\admin\\IdeaProjects\\msbhadoop\\target\\hadoop-hdfs-1.0-0.1.jar");//必须必须写的job.setJarByClass(MyWordCount.class);job.setJobName("mashibing");// Path infile = new Path(othargs[0]);Path infile = new Path("/data/wc/input");TextInputFormat.addInputPath(job, infile);//Path outfile = new Path(othargs[1]);Path outfile = new Path("/data/wc/output1");if (outfile.getFileSystem(conf).exists(outfile)) outfile.getFileSystem(conf).delete(outfile, true);TextOutputFormat.setOutputPath(job, outfile);job.setMapperClass(MyMapper.class);job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(IntWritable.class);job.setReducerClass(MyReducer.class);// job.setNumReduceTasks(2);// Submit the job, then poll for progress until the job is completejob.waitForCompletion(true);}}
5:MyMapper
package com.hadoop.fastdfs.mapreduce.wc;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;import java.util.StringTokenizer;public class MyMapper extends Mapper<Object, Text, Text, IntWritable> {//hadoop框架中,它是一个分布式 数据 :序列化、反序列化//hadoop有自己一套可以序列化、反序列化//或者自己开发类型必须:实现序列化,反序列化接口,实现比较器接口//排序 -》 比较 这个世界有2种顺序: 8 11, 字典序、数值顺序private final static IntWritable one = new IntWritable(1);private Text word = new Text();//hello hadoop 1//hello hadoop 2//TextInputFormat//key 是每一行字符串自己第一个字节面向源文件的偏移量public void map(Object key, Text value, Context context) throws IOException, InterruptedException {StringTokenizer itr = new StringTokenizer(value.toString());while (itr.hasMoreTokens()) {word.set(itr.nextToken());context.write(word, one);}}}
6:MyReducer
package com.hadoop.fastdfs.mapreduce.wc;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;public class MyReducer extends Reducer<Text, IntWritable, Text, IntWritable> {private IntWritable result = new IntWritable();//相同的key为一组 ,这一组数据调用一次reduce//hello 1//hello 1//hello 1//hello 1public void reduce(Text key, Iterable<IntWritable> values,/* 111111*/Context context) throws IOException, InterruptedException {int sum = 0;for (IntWritable val : values) {sum += val.get();}result.set(sum);context.write(key, result);}}
7:maven-》package
8:上传到node01
9:运行
hadoop jar hadoop-mapreduce-examples-2.6.5.jar MyWordCount
10:查看
hdfs dfs -ls /data/wc/output1
hdfs dfs -cat /data/wc/output1/part-r-00000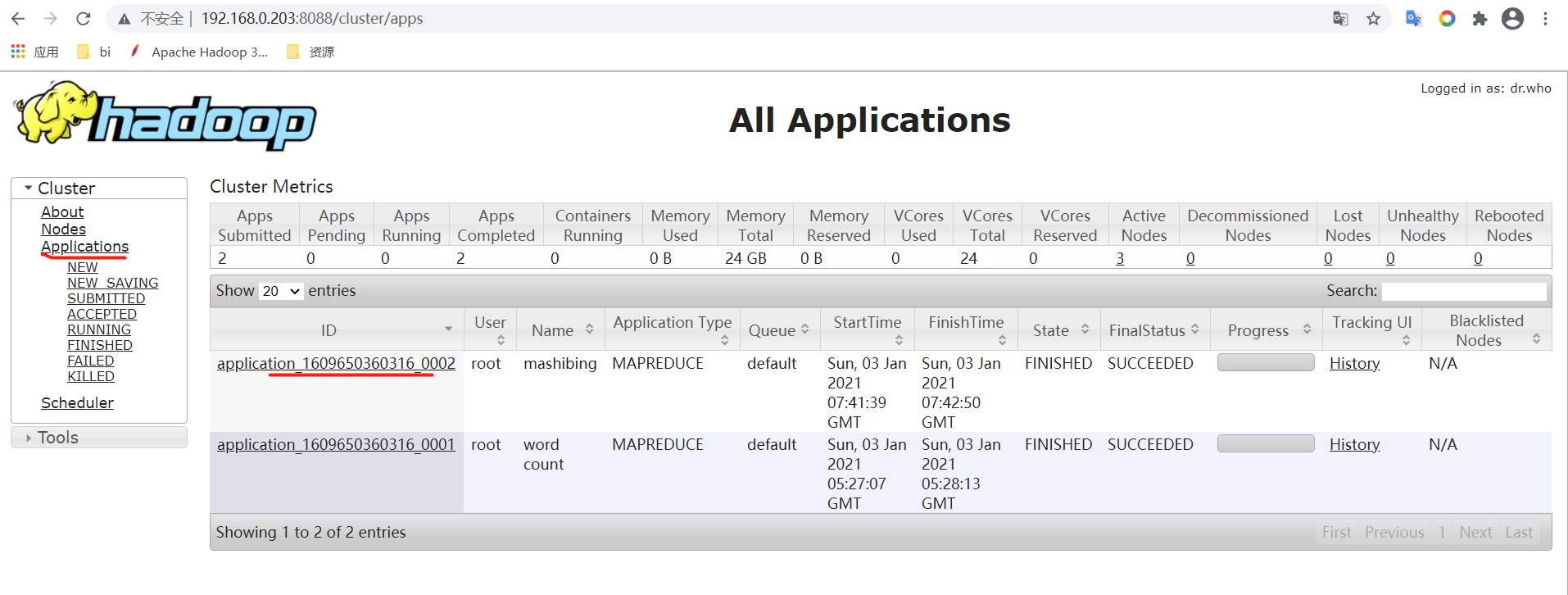
6:MR多种提交方式
1:上传jar到服务器
开发-> jar -> 上传到集群中的某一个节点 -> hadoop jar ooxx.jar ooxx in out
2:嵌入【linux,windows】(非hadoop jar)的集群方式 on yarn
集群:M、R
client -> RM -> AppMaster
//在集群运行
mapreduce.framework.name -> yarn
//异构平台
conf.set(“mapreduce.app-submission.cross-platform”,”true”);
//package打jar包设置本地jar路径
job.setJar(“C:\Users\Administrator\IdeaProjects\msbhadoop\target\hadoop-hdfs-1.0-0.1.jar”);
3:local,单机 自测
mapreduce.framework.name -> local<br /> conf.set("mapreduce.app-submission.cross-platform","true"); //windows上必须配<br /> 1,在win的系统中部署我们的hadoop:<br /> C:\usr\hadoop-2.6.5\hadoop-2.6.5<br /> 2,在我给你的资料中\hadoop-install\soft\bin 文件覆盖到 你部署的bin目录下<br /> 还要将hadoop.dll 复制到 c:\windwos\system32\<br /> 3,设置环境变量:HADOOP_HOME C:\usr\hadoop-2.6.5\hadoop-2.6.5 <br /> <br /> IDE -> 集成开发: <br /> hadoop最好的平台是linux<br /> 部署hadoop,bin
4:参数个性化
GenericOptionsParser parser = new GenericOptionsParser(conf, args); //工具类帮我们把-D 等等的属性直接set到conf,会留下commandOptions<br /> String[] othargs = parser.getRemainingArgs();

若有收获,就点个赞吧
0 人点赞
