一:mapreduce
1:hadoop1.x的mapreduce
1):JobTracker
负责接收客户端提交的任务请求, 分配系统资源, 分配任务给TaskTracker, 管理任务的失败/重启等操作.
2):TaskTracker
负责接收并执行JobTracker分配的任务, 并与JobTracker保持心跳机制, 向JobTracker报告自己任务的运行状况
3):存在问题
- 所有的任务都在JobTracker上面进行分配, 调度和监控, 处理. 造成了过多的资源消耗, 当job比较多的时候, 增大了JobTracker机器fail的风险.
- JobTracker 是 Map-reduce 的集中处理点,存在单点故障。
- 在 TaskTracker 端,以 map/reduce task 的数目作为资源的表示过于简单,没有考虑到 cpu/ 内存的占用情况,如果两个大内存消耗的 task 被调度到了一块,很容易出现 OOM。
- 在 TaskTracker 端,把资源强制划分为 map task slot 和 reduce task slot, 如果当系统中只有 map task 或者只有 reduce task 的时候,会造成资源的浪费,也就是前面提过的集群资源利用的问题。
2:hadoop2.x的mapreduce
新版的MapReduce也叫作Yarn框架, 其最重要的重构在于将资源分配与任务调度/监控进行了分离.1)ResourceManager: 资源调度器
首先保持和NodeManager的心跳机制, 接受客户端的任务请求, 根据NodeManager报告的资源情况, 启动调度任务, 分配Container给ApplicationMaster, 监控AppMaster的存在情况, 负责作业和资源分配调度, 资源包括CPU, 内存, 磁盘, 网络等, 它不参与具体任务的分配和监控, 也不能管理具体任务的失败和重启等.2)ApplicationMaster: 任务管理器
在其中一台Node机器上, 负责一个Job的整个生命周期. 包括任务的分配调度, 任务的失败和重启管理, 具体任务的所有工作全部由ApplicationMaster全权管理, 就像一个大管家一样, 只向ResourceManager申请资源, 向NodeManager分配任务, 监控任务的运行, 管理任务的失败和重启.3)NodeManager: 任务处理器
负责处理ApplicationMaster分配的任务, 并保持与ResourceManager的心跳机制, 监控资源的使用情况并向RM报告进行报告, 支持RM的资源分配工作.4)流程
Input -> Map -> Sort -> Combine -> Partition -> Reduce -> Output
二:yarn
1:架构图
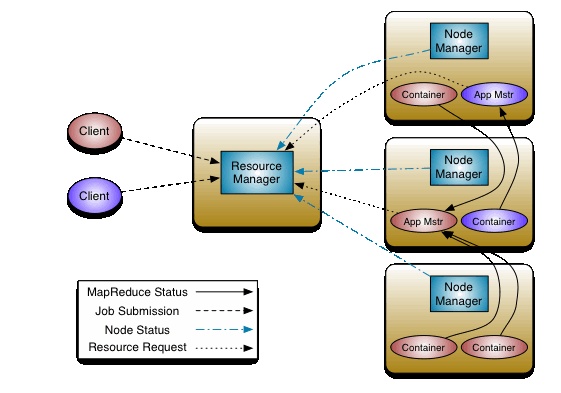
2:ResourceManager
负责接受客户端提交的 job,分配和调度资源
启动 ApplicationMaster,判断 job 所需资源
监控 ApplicationMaster,在其失败的时候进行重启
监控 NodeManager
3:ApplicationMaster
为 MapReduce 类型的程序申请资源,并分配任务
负责相关数据的切分
监控任务的执行及容错
4:NodeManager
管理单个节点的资源,向 ResourceManager 进行汇报
接收并处理来自 ResourceManager 的命令
接收并处理来自 ApplicationMaster 的命令

若有收获,就点个赞吧
0 人点赞
